
Abstract
Urban open space (UOS) plays an important environmental role, especially in areas characterized by intense social and economic activity. However, the high interclass similarities, complex surroundings, and scale variations of UOS lead to unsatisfactory UOS mapping performance, and UOS mapping products for major cities around the world are lacking. To fill this gap, we used a deep learning-based method based on a tiny-manual annotation strategy and optical remote sensing imagery to produce a 1.19 m resolution UOS map of 169 megacities, namely the OpenspaceGlobal product. We generated the OpenspaceGlobal product with five urban open space categories. To obtain the final OpenspaceGlobal product, we processed over 8.5 TB of remote sensing images and nearly 90 million polygons in crowdsourced geospatial data. The validation results showed that the OpenspaceGlobal product had an overall accuracy of 79.13 % and a kappa coefficient of 73.47 %. The OpenspaceGlobal product can promote a better understanding of human-made space surfaces in major cities around the world.
Similar content being viewed by others

Background & Summary
Urban open space (UOS) refers to outdoor areas for public activities or other urban functions. UOS usually consists of vegetation areas, parks, squares, and green spaces, as well as roads, parking lots, outdoor stadiums, and other facilities. As a key component of urban nature, UOS offers a wide range of public services and social benefits. Access to UOS is a valuable indicator and a key element in evaluating universal access to safe and inclusive green and public spaces (Sustainable Development Goal 11.7)1,2. Thus, UOS mapping of cities around the world can offer a better understanding of urban space from the perspective of nature and society, provide support for urban planning and disaster emergency response, and promote sustainable urban development.
With the rapid development of Earth observation technologies over the past few decades, the spatial and spectral resolution of satellite images has continuously improved, and large volumes of remote sensing imagery have become easier to acquire and process. Various very-high-resolution (VHR) urban remote sensing imagery studies have performed urban land use (LU) mapping3,4,5,6,7, urban informal settlement mapping8,9,10,11,12, urban village mapping13,14,15, road extraction16,17,18, and urban functional zone mapping19,20,21,22,23,24. The proliferation of VHR remote sensing images and advanced artificial intelligence methods provides a solid basis for mapping UOS at scale.
Many existing techniques rely on visual or geometric assumptions-such as the expectation that pixels of open space areas share similar spectral signatures-but these assumptions can break down in heterogeneous urban environments25,26. To improve spatial accuracy in UOS mapping, studies have increasingly turned to semantic segmentation techniques. For example, Zhang et al.27 introduced a CNN-based semantic segmentation model to capture key spatial structures in geotagged panoramic images of urban park spaces, while Nowruzi et al.28 proposed PolarNet to segment UOS features in parking lot scenarios. U-shaped networks (e.g., U-Net) have also been adopted to refine spatial localization accuracy, as demonstrated by Huerta et al.29, who used high-resolution imagery to map metropolitan-level green spaces. Recent efforts further incorporate attention mechanisms to capture both local and global features, thereby improving segmentation precision. Other work has shifted from pixel-level to patch- or parcel-level analyses, utilizing geometric, color, and textural attributes for more robust UOS identification30.
Nevertheless, generating high-resolution UOS maps at the global scale still poses three primary challenges. First, heterogeneous urban environments, where UOS objects with scale variations are often fragmented or intermixed with buildings and impervious surfaces, lead to ambiguous class boundaries and considerable interclass confusion. Second, deep learning-based methods require large amounts of high-quality training samples, yet acquiring pixel-level labels for extensive urban regions is both resource-intensive and time-consuming. Finally, manual annotation reduces the UOS mapping scalability for global coverage, as even small-scale UOS datasets demand significant human effort. Consequently, global-scale UOS mapping remains both challenging and insufficiently addressed, resulting in the UOS map of the majority of megacities globally still lacking.
To tackle these issues, we developed a deep learning-based method with a tiny-manual annotation strategy and produced a 1.19m resolution UOS map of 169 megacities close to 2021 using remote sensing and crowdsourced geospatial data. We first defined categories of UOS. We then used the tiny-manual annotation strategy to generate a large number of pixel-wise semantic segmentation labels through a visual interpretation to reduce the large human labor of labeling. Subsequently, we used a deep learning-based semantic segmentation model, which consists of a Pyramidal Transformer Encoder to track the issue of UOS scale variations, and a Feature-aligned Pyramid Decoder to track heterogeneous UOS features with high interclass similarities and complex surroundings, to produce the initial UOS map. We then used crowdsourced geospatial data (OpenStreetMap and areas of interest) to post-process the UOS map and obtain a refined map. We thus generated the OpenspaceGlobal dataset of 169 megacities by processing over 8.5TB of remote sensing images with 384,224 930 × 930 pixels grid tiles and nearly 90 million polygons in crowdsourced geospatial data. We evaluated its quality through a visual interpretation of a large number of remote sensing images with 1,620 465 × 465 pixels semantic segmentation labels and 67,201 pixel-wise validation samples. This approach provides a pathway toward comprehensive, high-resolution UOS mapping that can support global urban planning, disaster management, and sustainable urban development.
The innovative contributions of this paper are summarized as follows:
1. Efficient sample labeling strategy. In terms of data and sample aspect, this study introduces a tiny-manual annotation strategy that significantly reduces manual labeling costs, enabling the generation of extensive pixel-level UO segmentation labels.
2. Scale- and heterogeneity-aware deep learning model. In terms of methodology, this paper introduces the UOFormer that addresses multi-scale variations in UOS and captures heterogeneous features in complex urban landscapes automatically, without the cost of human-designed features.
3. First global-scale high-resolution UOS mapping product. This study presents the first UO mapping product, covering 169 megacities globally at a spatial resolution of 1.19 m.
Methods
UOS definition
We first defined categories of UOS into “park and green space,” “outdoor sports space,” “transportation space,” “water body space,” and “background” by referring to the Urban and Rural Land Use Classification and Development Land Planning Standards and the GB/T 21010-2017 Land Use Classification, combined with the Academic Definition, Classification Standards and Research Trends of Urban Open Space. The detailed classification is shown in Table 1. We chose parks and green spaces, outdoor sports spaces, water body spaces, and transportation spaces as distinct types of urban open space (UOS) because these categories support sustainable urban development and are important indicators for SDG 11. Parks and green spaces contribute to ecological resilience and social well-being by enhancing habitat connectivity and providing accessible recreational opportunities. Outdoor sports spaces focus on health promotion and community engagement, aligning with goals to build active and inclusive urban environments in SDG 11. Transportation spaces (e.g., roads, walkways, transit hubs) facilitate mobility and reduce congestion, helping planners design cities that support efficient transit modes. Water body spaces aid in flood mitigation, water resource management, and urban cooling. By distinguishing these four major UOS categories, our UOS classification system offers a detailed understanding of open spaces in cities, and offer deeper insights into the spatial distribution of urban open spaces, allow planners to identify areas with insufficient public amenities and unequal among urban regions, etc. For instance, mapping parks and green spaces can help reveal potential “cool islands”. Similarly, recognizing water body spaces can inform strategies for reducing heat stress and improving flood control. Identifying outdoor sports spaces and transportation spaces with precision aids in optimizing land use for recreation and connectivity, ultimately shaping a more efficient, equitable, and resilient urban landscape.
Data preparation
Study area
We selected 169 cities (as shown in Table 2) from 62 countries (as shown in Table 3) that have an urban population exceeding 3,000,000. The chosen cities span multiple continents encompass diverse climatic, cultural, and economic conditions, and cover a wide range of urban development scenarios, thus providing the basics for our method to be easily adapted for different types of cities globally.
VHR optical remote sensing imagery
We collected VHR optical images from the open-access Google Earth project, which have an approximately 1.19 m resolution. The size of numerous small UOS (e.g., small sports grounds, roads, and parks) is too small to be captured in remote sensing images with a 10 m resolution or lower (e.g., the Sentinel-2 and Landsat series). For this reason, we collected Google Earth imagery with the red, green, and blue bands according to each megacity’s administrative borders.
OpenStreetMap polygon data
OpenStreetMap (OSM) is an open-source data mapping project established by a community of volunteers to provide freely editable maps. Many studies have demonstrated the feasibility of using OSM data for various urban mapping tasks22,31,32,33,34. We used polygons with geographic information for guidance to reduce the manual effort required to label UOS samples,
AOI polygon data
Baidu Maps, one of China’s leading online map services, provides a wealth of polygon AOI data that represent the geographic boundaries of specific areas, such as commercial zones, residential areas, and tourist attractions. The AOI polygon data used in this study included the following categories: residential buildings, office spaces, dormitories, theaters, vacation villages, farmyards, bath/massage facilities, internet cafés, movie theaters, game rooms, parks, botanical gardens, green spaces, golf courses, parking lots, charging stations, gas stations, service areas, bridges, ports, train stations, long-distance bus stops, airports, and bus stops.
Training set and testing set
We use the tiny-manual labeling strategy to label the dataset. We first selected representative cities from multiple continents (e.g., Kabul, Algiers, Luanda, Ouagadougou, Douala, Yaounde, Kinshasa, Mbuji_Mayi, Santo_Domingo, Alexandira, Cairo, Paris, Berlin, Accra, Kumasi, Nagoya, Osaka_Kobe_Kyoto, Tokyo_Yokohama, Amman, Lima, Moscow, StPetersburg, Busan, Seoul_Incheon, Aleppo, Atlanta, Dallas_FortWorth, Miami, Phoenix, SanFrancisco_SanJose, Seattle, Beijing, Chengdu, Guangzhou, Nanchang, Shanghai, Shenzhen, Tianjin, Wuhan, Changsha, Chongqing, etc.) to ensure both geographic diversity and coverage of varied urban morphologies. Within each city, we identified up to 50 grid cells with the highest coverage by OpenStreetMap (OSM) and Areas of Interest (AOI), requiring at least four open-space (OS) categories-one of which had to be a outdoor sports space or transportation space. Using these grids, we clipped the corresponding remote sensing imagery and employed OSM and AOI data as initial labels, resulting in 8,084 samples at a size of 465 × 465 pixels. We then incrementally refined these initial labels through manual annotation, obtaining strongly annotated samples. Finally, we randomly split these samples into a training set and a testing set at a 4:1 ratio (6,464 training and 1,620 testing), ensuring that both datasets encompass multiple OS categories and diverse urban scenes. This strategy provides balanced coverage, minimizes annotation effort, and enables a robust evaluation of the proposed method. The pixels that we labeled manually accounted for only 17.88% of the total sample pixels. The pixels that we manually labeled for the “park and green space,” “outdoor sports space,” “transportation space,” “water body space,” and “background” categories accounted for 27.98%, 24.58%, 11.50%, 13.70%, and 13.30%, respectively.
Labeling training samples using the tiny-manual annotation strategy
To reduce the manual effort required to label a large number of UOS semantic segmentation samples, we used the tiny-manual labeling strategy to obtain training samples. First, we spatially divided each area into grids. We then obtained the corresponding VHR remote sensing images and crowdsourced geospatial data according to each area’s geological ___location. We automatically obtained many polygons with UOS category labels. We then converted these polygons to rasters with the same resolution as the VHR remote sensing images to obtain weakly annotated UOS samples. Because these samples were incomplete and inaccurate at times, we asked experts to perform a visual interpretation using the Labelme tool (https://github.com/wkentaro/labelme) to correct the incorrect labels and improve the label coverage. Thus, we obtained a refined, strongly annotated UOS dataset consisting of 6,464 semantic segmentation 465 × 465 grid tiles samples.
UOS mapping using a transformer-based semantic segmentation network
To achieve fine UOS mapping, we used semantic segmentation to recognize UOS at the pixel level and developed a transformer-based UOS semantic segmentation neural network called UOFormer, which consists of a Pyramidal Transformer Encoder and a Feature-aligned Pyramid Decoder. Its detailed structure is shown in Fig. 1(2).

The overview illustration of the proposed method.
Pyramidal Transformer Encoder
The Pyramidal Transformer Encoder uses the Mix Transformer (MiT)35 as a backbone and takes an image of shape (C0, H, W) as input and outputs hierarchical multi-scale features from four stacked transformer blocks in the MiT backbone. In the transformer block, the input image \(x\in {{\mathbb{R}}}^{{C}_{0}\times H\times W}\) is fed into an overlapping patch embedding layer, which is defined as
where \(Conv2{d}_{{C}_{i}\times {C}_{i+1}}\) denotes a two-dimensional convolutional layer with in_channels of Ci and out_channels of Ci+1. The kernel size, stride, and padding of \(Conv2{d}_{{C}_{i}\times {C}_{i+1}}\) are set to 7 × 7, 4, and 3 when i is 0 and to 3 × 3, 2, and 1 when i is not 0. M identical self-attention (SA) layers36 with residual connections37 are then added. The output is then fed into a feed-forward network (FFN). The SA layer and the FFN are defined as
where Qi, Ki, Vi and dhead denote the queries, keys, values, and the scaling factor in SA layers36. \({x}_{p}^{i}\) is the feature map obtained from ith SA, and DepthWiseConv2d denotes a two-dimensional depth-wise convolution operator38,39 with 3 × 3 convolution kernels.
Feature-aligned Pyramid Decoder
We obtained multi-scale pyramidal feature maps xi that contained valuable information about UOS. We adopted the Feature-aligned Pyramid Decoder from the FaPN model40. This decoder uses feature-aligned blocks that contain Feature Selection Module (FSM) and Feature Alignment Module (FAM) to select and fuse the pyramidal feature maps across stages. The detailed procedure of the FSM block is as follows:
where GAP represents the global average pooling.
The FAM block uses the feature maps xi from the Pyramidal Transformer Encoder and the feature maps xi+1 from the FSM block as input. In FAM, the deformable convolution is used as a feature alignment function by learning the shifted distances between the points in xi and the corresponding points in xi+1. The FAM procedure is as follows:
where the offset and mask are obtained from the following procedure:
A two-dimensional CNN with a 1 × 1 kernel convolution operator and k out_channels is then added to transform the output into a k channel feature map, where k indicates the number of categories. In this case, k is set to 6, representing the five UOS categories and the ignored mask. Subsequently, a bilinear interpolation operator is added to resize the output to the same size as the input VHR remote sensing image. In the testing process, the values in the channels that correspond to the mask are ignored. Finally, the softmax layer is added to calculate the final predicted UOS categories, which can be represented as \(output=\left\{{a}_{1},{a}_{2},\ldots ,{a}_{k-1}\right\}\), where
z is the input vector of the softmax layer. The category corresponding to the largest value in output is regarded as the final predicted UOS category.
Post-processing by overlaying crowdsourced geospatial data
To map the UOS of the 169 megacities, we first obtained the city boundaries based on the GUB_Global urban boundaries dataset41. We then constructed city-wide grids consisting of tiles with a size of 930 × 930 pixels, corresponding to an area of approximately 1 km2, obtaining a total of 384,224 grid tiles. Subsequently, we used these grid polygons to crop the VHR remote sensing images and employed UOFormer to obtain the UOS semantic segmentation results from the remote sensing images with a nonoverlapping sliding window. The size of the sliding window was the same as the input image size of the semantic segmentation model (465 × 465 pixels). We then merged the UOS semantic segmentation results of all grids tiles to obtain the initial UOS map, as shown in Fig. 1(3).
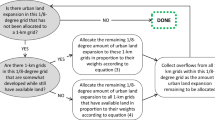
We then post-processed the initial UOS map to refine the results by overlaying the geospatial OSM and AOI data. The overlaying procedure was as follows: (1) We mapped the OSM and AOI vector polygons into the five predefined categories (“park and green space,” “outdoor sports space,” “transportation space,” “water body space,” and “background”). The conception mapping rules are included in Table 4. (2) We constructed buffers for the road network in OSM according to different levels. we set buffer sizes based on the number of lanes and the corresponding road widths. Specifically, we matched each OSM road type (e.g., motorway, trunk, primary, secondary, etc.) to an approximate lane count and assigned an appropriate buffer (e.g., 10 m for motorway/trunk, 6 m for primary, 5 m for secondary, 3 m for tertiary/residential). This approach aligns with China’s multi-level road standards (i.e., first-grade, second-grade, and third-grade roads) by reflecting typical lane widths. We regarded the buffers of the road network as transportation space. (3) We superimposed the mapped OSM and AOI polygons and road network buffers on the initial UOS map in the order of “background,” “park and green space,” “water body space,” “outdoor sports space,” and “transportation space.” The post-processing steps are illustrated in Fig. 2.

Post-processing by overlaying crowdsourced geospatial data.
During the UOS mapping process, we found that some croplands, areas with sparse or no vegetation, and permanent water bodies on the outskirts of urban areas were misclassified as outdoor sports spaces, thus reducing the accuracy of our OpenspaceGlobal product. Therefore, we corrected the outdoor sports space pixels using the ESA_GLC10 product42. The correction procedure was as follows: We obtained the central point of each predicted outdoor sports space and the category corresponding to that point in ESA_GLC1042. If the category was “cropland” or “bare/sparse vegetation” we reidentified the corresponding outdoor sports space as “park and green space.” Similarly, if the category was “permanent water body,” we reidentified the corresponding space as “water body space.” Regarding the blank stripes issue caused by non-overlapping sliding window, we performed an additional morphological post-processing step to fill blank stripes at the boundaries by assigning the left-nearby UOS categories to the pixels of blank stripes, thereby ensuring continuous coverage and preventing abrupt gaps in the final urban grid.
Data Records
The OpenspaceGlobal product and the corresponding user guidelines are available at Science Data Bank43. The product is grouped by 169 city tiles in the GeoTIFF format, packaged in 62 country administrative region folders. Each city tile is named “City.tif”, where “City.tif” explains the city name. For example, the 1.19-meter urban open space map for Wuhan City in China is named as “Wuhan.tif”. Furthermore, each tile contains an open-space label band ranging from 1 to 5, where label 1 denotes park and green space, label 2 denotes outdoor sports space, label 3 denotes transportation space, label 4 denotes water body space, and label 5 denotes the background. The proportions of the UOS categories in the 169 megacities are shown in Fig. 3. Figure 4(a–e) shows the UOS mapping results for some megacities in countries on different continents in our OpenspaceGlobal product.

The illustration of the proportion of urban open space categories. (A) illustrates the proportion of four UOS categories of the 169 megacities and (B) illustrates the average proportion of four UOS categories of megacities in the 62 countries.

Some UOS mapping results of global megacities. a, b, c, d, e, and f indicate regions in Algiers, Beijing, Paris, New York, Lima, and Kumasi.
Technical Validation
Validation datasets
Semantic segmentation testing set
To assess the performance of the proposed OpenspaceGlobal product, we constructed a semantic segmentation testing dataset by manually labeling 1,620 semantic segmentation samples (refer to Subsubsection “Training set and testing set”). The statistics of these samples are illustrated in Figure 5(A). Each validation sample had a length of 465 pixels and a width of 465 pixels. Figure 5(B) shows the proportions of various open spaces on different continents in the semantic segmentation testing dataset. As shown in Fig. 5(A) and (B), the labeled samples were characterized by a significant imbalance in the numbers of pixels in different UOS categories.

The illustration statistic of the validation dataset samples.
Global validation dataset
To assess the performance of the proposed OpenspaceGlobal product, we also constructed a global validation dataset. The spatial distribution of the samples is shown in Fig. 5(C). The global validation dataset consisted of 67,201 pixel-wise validation samples from independent global and open-source data on LU, LC, surface imperviousness, and buildings, along with a large number of visually interpreted remote sensing image samples. We constructed a global validation dataset consisting of 67,201 validation samples, including 11,814 park and green space samples, 13,289 outdoor sports space samples, 10,436 transportation space samples, 10,600 water body space samples, and 21,062 background samples.
Semantic segmentation validation
For semantic segmentation validation, we manually labeled and validated 1,620 samples with a length of 465 pixels and a width of 465 pixels. The statistics of these samples are illustrated in Fig. 5. We used accuracy (Acc), overall accuracy (OA), Intersection over Union (IoU), and mean Intersection over Union (mIoU) as evaluation metrics.
The O.A., mIoU, Acc, and IoU of UOFormer (without post-processing) and the OpenspaceGlobal product (after post-processing using crowdsourced geospatial data) are presented in Table 5. UOFormer had an O.A. of 80.29% and an mIoU of 61.51%. In terms of UOS categories, the O.A. of UOFormer for parks and green spaces, water body spaces and backgrounds exceeded 80%. However, UOFormer was significantly less accurate in mapping outdoor sports spaces and transportation spaces, with O.A. of 51.75 % and 57.62%, respectively, and IoU of 39.97% and 45.24 %, respectively. The final OpenspaceGlobal product had an O.A. of 91.41%, FWIoU of 84.30% and an mIoU of 80.40%. In terms of UOS categories, the O.A. of OpenspaceGlobal for transportation spaces, water body spaces and backgrounds exceeded 90%, while that for parks and green spaces, outdoor sports spaces exceeded 85%. Thus, post-processing improved UOS mapping by 11.28% in terms of O.A., by 16.83% in terms of FWIoU, and by 18.89% in terms of mIoU. These results demonstrated the superior quality of OpenspaceGlobal.
Pixel-level validation
For pixel-level validation, we used the global validation dataset described in Section Validation datasets. We used user’s accuracy (UA; a measure of the error of commission), producer’s accuracy (PA; a measure of the error of omission), O.A., and the kappa coefficient as evaluation metrics. The confusion matrix, O.A., UA, PA, and kappa coefficient of OpenspaceGlobal are presented in Table 6. Some pairs of categories (e.g., “park and green space”-“background” and “transportation space”-“background”) were slightly confused due to the visual similarities between these categories. For some UOS categories, namely “park and green space,” and “transportation space,” PA was lower than 80%. In some categories, namely “park and green space,” “transportation space,” and “outdoor sports space,” UA was lower than 80%. These UOS were difficult to classify correctly due to their high interclass diversity. Among all categories, UA was lowest for “park and green space” (70.84 %). Overall, however, OpenspaceGlobal showed satisfactory performance, with an O.A. of 79.13% and a kappa coefficient of 73.47%.
Table 7 shows the validation results for Oceania, Asia, Europe, Africa, North America, and South America. The O.A. and kappa coefficient of OpenspaceGlobal exceed 80% and 70%, respectively, for Oceania, North America, and South America. The product had the highest accuracy for Oceania, with an O.A. and kappa coefficient of 88.26% and 84.67% respectively, and the lowest accuracy for Africa, with an O.A. and kappa coefficient of 64.16% and 55.18%, respectively. Based on our analysis, two primary factors contribute to these discrepancies. First, data quality limitations, e.g. incomplete OpenStreetMap data, can reduce labeling accuracy, and insufficient ground truth in many regions restricts our ability to refine model predictions. Second, urban heterogeneity and the large differences in urbanization levels across African cities add to the complexity of distinguishing UOS in African cities. To address these issues, future directions can be summarized as follows. First, enhancing data quality by integrating higher-resolution imagery and collaborating with local agencies can help refine ground truth and overcome incomplete OpenStreetMap data. Second, refining the model through advanced models, such as semi-supervised/weak supervised learning and ___domain adaptation techniques, can enable better handling of diverse urban morphologies. Overall, however, these results demonstrate the high quality of the proposed product.
Comparisons with existing datasets
We compared our UOS maps with UrbanWatch’s 2017 product44 across the included seven cities (Atlanta, Chicago, Miami, New York City, Philadelphia, Seattle, and Washington D.C.). For consistency evaluation, we randomly sampled 10,000 points per city of the mapped categories (refer to Table 8) for each city, e.g., park and green space, transportation space, and water body space. As shown in Fig. 6-(7)(a) and Fig. 6-(7)(b), our OpenspaceGlobal product shows an overall consistency ranging from 74% to 87%, with parks and green spaces (P) reaching up to 90%. Both transportation spaces (T) and water body spaces (W) exceed 70%.

The comparisons with existing datasets. (1) is a comparison of Hi-ULCM. (2) is a comparison of UrbanWatch. (3) is a comparison of ESA WorldCover 2021 and ESRI 10m Land Cover. (4) is a comparison of OpenEarthMap Japan. (5) are the water bady samples with labels of GLH-Water. (6) are the water bady space samples with labels of our products. (7) are the cross-validation with existing datasets. In (7), (a) represents the consistency between the UrbanWatch product and our product, (b) represents the consistency between the UrbanWatch product and our product in the categories of the Parks and green spaces (P), Transportation spaces (T), Water body spaces (W), (c) represents the consistency of the P, W, the Background (B) categories between the ESA_GLC10 product and our product, (d) represents the similarity between the ESRI_GLC10 product and our product in P, W, B categories, (e) represents the consistency of P, W, B categories between ESA_GLC10, ESRI_GLC10 and our product. (8) are the comparisons of crowdsourced geospatial data. In (8), (a), (b), (c) represent the comparison of our product, OSM, and Baidu Map of Beijing, China, (d) illustrates the coverage of OSM among different continents (AS: Asia, NA: North America, SA: South America, OA: Oceania, EU: Europe, AF: Africa).
We also extended the comparison to the ESA_GLC10 product42 and the ESRI_GLC10 product45. We randomly selected three sample points from each of the 384,224 grids in urban areas worldwide. Then we removed the sample points that are not of the mapped UOS category (refer to Table 8) in ESA_GLC10, ESRI_GLC10, and our products, and obtained 1,011,923 sample points. As can be seen in Fig. 6-(7)(c) and Fig. 6-(7)(d), P from the ESA_GLC10 product and B from ESRI_GLC10 achieved over 90% consistency with our OpenspaceGlobal dataset. Since there are inconsistencies between the ESA_GLC10 product and the ESRI_GLC10 product, this will interfere with our consistency comparison. To eliminate this interference, we further compared the pixels in the three categories of P, W, and T that are consistent in the above two products and obtained 697,349 sample points. The consistency comparison results are shown in Fig. 6-(7)(e), and it can be found that the consistency of W has been improved. In summary, our products and the compared excellent products have high consistency in the four categories of P, T, W, and B. For the outdoor sports spaces category, we did not make a comparison because we have not found similar products that include this category.
We conducted qualitative comparisons of our dataset with several representative products, including Hi-ULCM46 (Fig. 6-1, UrbanWatch44 (Fig. 6-2, ESA WorldCover 202142 (ESA_GLC10 product) and ESRI 10m Land Cover45 (the ESRI_GLC10 product) in Fig. 6-3 OpenEarthMap Japan47 (Fig. 6-4, and GLH-water48 (Fig. 6-5. Overall, we observe a high degree of agreement in identifying water bodies, green spaces, and built-up areas. For instance, the Hi-ULCM product (Fig. 6-1 closely matches our classification in terms of major land cover types around Wuhan, with some slight differences in small vegetated patches. In Fig. 6-2 comparisons with UrbanWatch across selected U.S. cities confirm robust detection of water, and green spaces, with some slight differences in transportation spaces. Similarly, the ESRI_GLC10 product and ESA_GLC10 product for Beijing (Fig. 6-3 offer more generalized boundaries, while our method delineates smaller green patches and linear spaces with greater precision. A similar pattern emerges in the Kyoto and Tokyo comparisons (Fig. 6-4, where our results capture intricate road networks and fragmented open spaces frequently overlooked in coarser datasets. Finally, the samples of GLH-water product (Fig. 6-5 show a strong correspondence with our water samples, highlighting both large watercourses and minor waterways. Taken together, these qualitative assessments demonstrate that, despite differences in resolution, class definitions, and data sources, our classification framework consistently provides reliable and detailed UOS mapping across a variety of global urban areas.
Notably, while global map service providers (e.g., OpenStreetMap, Baidu Map) can indeed offer vector-based UOS data, these datasets may suffer from several limitations: (1) inconsistent coverage, especially in rapidly evolving or less-documented urban areas (as illustrated in Fig. 6-(8)(b), Fig. 6-(8)(c), and Fig. 6-(8)(d)); (2) high human costs associated with continuous updating and maintenance; and (3) lack of uniform resolution, which may fail to capture fine-scale open space features (e.g., small green patches). Our UOFormer-based approach addresses these gaps in two primary ways. First, the deep learning model provides a fine-grained, pixel-level segmentation that does not depend solely on volunteered or crowdsourced vector mapping. This ensures spatial coherence and can capture subtle open-space features. Second, crowdsourced data such as OpenStreetMap and Areas of Interest (AOI) help refine ambiguous regions, resolve misclassifications, and improve overall boundary accuracy-particularly where large-scale vector data are well-mapped and reliable. Although our UOFormer’s accuracy without post-processing is lower than the final results, the synergy between a high-resolution, deep learning-based segmentation and selectively applied crowdsourced data significantly boosts performance. In essence, the model leverages comprehensive, pixel-wise predictions, while the crowdsourced data serve as an external validation and refinement layer, reducing errors in areas where detailed community-driven vector information is available. As a result, our method outperforms using remote sensing or crowdsourced vectors alone by producing more precise UOS mapping results with fine-grained coverage, ultimately ensuring a higher-quality UOS product.
Usage Notes
The OpenspaceGlobal product is free to use for usage including scientific research and science promotion under proper citation.
Code availability
Code is available at https://github.com/RunyuFan/OpenspaceGlobal.
References
Fund, S. Sustainable development goals. Available at this link: https://www.un.org/sustainabledevelopment/inequality (2015).
Colglazier, W. Sustainable development agenda: 2030. Science 349, 1048–1050 (2015).
Zhao, M. et al. Beyond pixel-level annotation: Exploring self-supervised learning for change detection with image-level supervision. IEEE Transactions on Geoscience and Remote Sensing 62, 1–16, https://doi.org/10.1109/TGRS.2024.3379431 (2024).
Tong, X.-Y. et al. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sensing of Environment 237, 111322 (2020).
Huang, B., Zhao, B. & Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sensing of Environment 214, 73–86 (2018).
Yin, J. et al. Integrating remote sensing and geospatial big data for urban land use mapping: A review. International Journal of Applied Earth Observation and Geoinformation 103, 102514 (2021).
Li, W. et al. Multiclass crop interpretation via a lightweight attentive feature fusion network using vehicle-view images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 18, 496–509 (2024).
Tan, X. et al. Hr-uvformer: A top-down and multimodal hierarchical extraction approach for urban villages. IEEE Transactions on Geoscience and Remote Sensing 62, 1–15, https://doi.org/10.1109/TGRS.2024.3387022 (2024).
Fan, R. et al. Urban informal settlements classification via a transformer-based spatial-temporal fusion network using multimodal remote sensing and time-series human activity data. International Journal of Applied Earth Observation and Geoinformation 111, 102831 (2022).
Mast, J., Wei, C. & Wurm, M. Mapping urban villages using fully convolutional neural networks. Remote Sensing Letters 11, 630–639 (2020).
Fan, R. et al. Fine-scale urban informal settlements mapping by fusing remote sensing images and building data via a transformer-based multimodal fusion network. IEEE Transactions on Geoscience and Remote Sensing 60, 1–16 (2022).
Niu, H., Fan, R., Chen, J., Xu, Z. & Feng, R. Urban informal settlements interpretation via a novel multi-modal kolmogorov-arnold fusion network by exploring hierarchical features from remote sensing and street view images. Science of Remote Sensing 11, 100208 (2025).
Chen, B. et al. Multi-modal fusion of satellite and street-view images for urban village classification based on a dual-branch deep neural network. International Journal of Applied Earth Observation and Geoinformation 109, 102794 (2022).
Fan, R., Li, J., Li, F., Han, W. & Wang, L. Multilevel spatial-channel feature fusion network for urban village classification by fusing satellite and streetview images. IEEE Transactions on Geoscience and Remote Sensing 60, 1–13 (2022).
Shi, Q. et al. Domain adaption for fine-grained urban village extraction from satellite images. IEEE Geoscience and Remote Sensing Letters 17, 1430–1434 (2019).
Jiao, C., Heitzler, M. & Hurni, L. A fast and effective deep learning approach for road extraction from historical maps by automatically generating training data with symbol reconstruction. International Journal of Applied Earth Observation and Geoinformation 113, 102980 (2022).
Jiang, X. et al. Roadformer: Pyramidal deformable vision transformers for road network extraction with remote sensing images. International Journal of Applied Earth Observation and Geoinformation 113, 102987 (2022).
Chen, X., Sun, Q., Guo, W., Qiu, C. & Yu, A. Ga-net: A geometry prior assisted neural network for road extraction. International Journal of Applied Earth Observation and Geoinformation 114, 103004 (2022).
Zhang, Y., Chen, N., Du, W., Li, Y. & Zheng, X. Multi-source sensor based urban habitat and resident health sensing: A case study of wuhan, china. Building and Environment 198, 107883 (2021).
Huang, X., Yang, J., Li, J. & Wen, D. Urban functional zone mapping by integrating high spatial resolution nighttime light and daytime multi-view imagery. ISPRS Journal of Photogrammetry and Remote Sensing 175, 403–415 (2021).
Zhang, Y., Zhang, F. & Chen, N. Migratable urban street scene sensing method based on vision language pre-trained model. International Journal of Applied Earth Observation and Geoinformation 113, 102989 (2022).
Fan, R., Feng, R., Han, W. & Wang, L. Urban functional zone mapping with a bibranch neural network via fusing remote sensing and social sensing data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 14, 11737–11749 (2021).
Du, S., Du, S., Liu, B. & Zhang, X. Mapping large-scale and fine-grained urban functional zones from vhr images using a multi-scale semantic segmentation network and object based approach. Remote Sensing of Environment 261, 112480 (2021).
Su, C. et al. A multimodal fusion framework for urban scene understanding and functional identification using geospatial data. International Journal of Applied Earth Observation and Geoinformation 127, 103696 (2024).
Rosina, K. & Kopecká, M. Mapping of urban green spaces using sentinel-2a data: Methodical aspects. In 6th International Conference on Cartography and GIS, Albena. Bulgarian Cartographic Association (in print), 562–568 (2016).
Kumari, B. et al. Assessment of public open spaces (pos) and landscape quality based on per capita pos index in delhi, india. SN Applied Sciences 1, 1–13 (2019).
Zhang, W., Yang, M. & Zhou, Y. Assessing urban park open space by semantic segmentation of geo-tagged panoramic images. Journal of Digital Landscape Architecture 339–351 (2020).
Nowruzi, F. E. et al. Polarnet: Accelerated deep open space segmentation using automotive radar in polar ___domain. arXiv preprint arXiv:2103.03387 (2021).
Huerta, R. E. et al. Mapping urban green spaces at the metropolitan level using very high resolution satellite imagery and deep learning techniques for semantic segmentation. Remote Sensing13, (2021).
Chen, B. et al. Mapping essential urban land use categories with open big data: Results for five metropolitan areas in the united states of america. ISPRS Journal of Photogrammetry and Remote Sensing 178, 203–218 (2021).
Zhao, W. et al. Exploring semantic elements for urban scene recognition: Deep integration of high-resolution imagery and openstreetmap (osm). ISPRS Journal of Photogrammetry and Remote Sensing 151, 237–250 (2019).
Herfort, B., Lautenbach, S., Porto de Albuquerque, J., Anderson, J. & Zipf, A. A spatio-temporal analysis investigating completeness and inequalities of global urban building data in openstreetmap. Nature Communications 14, 3985 (2023).
Vargas-Munoz, J. E., Srivastava, S., Tuia, D. & Falcao, A. X. Openstreetmap: Challenges and opportunities in machine learning and remote sensing. IEEE Geoscience and Remote Sensing Magazine 9, 184–199 (2020).
Liu, D., Chen, N., Zhang, X., Wang, C. & Du, W. Annual large-scale urban land mapping based on landsat time series in google earth engine and openstreetmap data: A case study in the middle yangtze river basin. ISPRS Journal of Photogrammetry and Remote Sensing 159, 337–351 (2020).
Xie, E. et al. Segformer: Simple and efficient design for semantic segmentation with transformers. CoRRabs/2105.15203, (2021).
Dosovitskiy, A. et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Guo, Y., Li, Y., Wang, L. & Rosing, T. Depthwise convolution is all you need for learning multiple visual domains. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 8368–8375 (2019).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1251–1258 (2017).
Huang, S., Lu, Z., Cheng, R. & He, C. Fapn: Feature-aligned pyramid network for dense image prediction. In Proceedings of the IEEE/CVF international conference on computer vision, 864–873 (2021).
Li, X. et al. Mapping global urban boundaries from the global artificial impervious area (gaia) data. Environmental Research Letters 15, 094044 (2020).
Van De Kerchove, R. et al. Esa worldcover: Global land cover mapping at 10 m resolution for 2020 based on sentinel-1 and 2 data. In AGU Fall Meeting Abstracts, vol. 2021, GC45I–0915 (2021).
Fan, R. & Wang, L. OpenspaceGlobal: the first urban open space product of global 169 megacities, https://doi.org/10.57760/sciencedb.09109 (2024).
Zhang, Y. et al. Urbanwatch: A 1-meter resolution land cover and land use database for 22 major cities in the united states. Remote Sensing of Environment 278, 113106 (2022).
Karra, K. et al. Global land use/land cover with sentinel 2 and deep learning. In 2021 IEEE international geoscience and remote sensing symposium IGARSS, 4704–4707 (IEEE, 2021).
Huang, X. et al. High-resolution urban land-cover mapping and landscape analysis of the 42 major cities in china using zy-3 satellite images. Science Bulletin 65, 1039–1048 (2020).
Yokoya, N., Xia, J. & Broni-Bediako, C. Submeter-level land cover mapping of japan. International Journal of Applied Earth Observation and Geoinformation 127, 103660 (2024).
Li, Y., Dang, B., Li, W. & Zhang, Y. Glh-water: A large-scale dataset for global surface water detection in large-size very-high-resolution satellite imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 22213–22221 (2024).
Acknowledgements
The project was supported by the National Natural Science Foundation of China (No. 42401469) and the “CUG Scholar” Scientific Research Funds at China University of Geosciences (Wuhan) (Project No.2024013).
Author information
Authors and Affiliations
Contributions
Runyu Fan: Conceptualization, Investigation, Data curation, Formal analysis, Writing - original draft, Writing review & editing; Data curation; Hongyang Niu: Data curation, Formal analysis, Quality Assessment; Zijian Xu: Data curation, Formal analysis, Quality Assessment; Jiajun Chen: Data curation, Quality Assessment; Zhaoying Zhou: Data curation, Quality Assessment; Wenyue Li: Data curation, Quality Assessment; Haoyu Wang: Data curation, Quality Assessment; Yuyue Sun: Data curation, Quality Assessment; Ruyi Feng: Data curation, Formal analysis; Lizhe Wang: Conceptualization, Supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fan, R., Wang, L., Xu, Z. et al. The first urban open space product of global 169 megacities using remote sensing and geospatial data. Sci Data 12, 586 (2025). https://doi.org/10.1038/s41597-025-04924-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-04924-x
