
Abstract
New Large Language Models (LLM)-based approaches to medical Question Answering show unprecedented improvements in the fluency, grammaticality, and other qualities of the generated answers. However, the systems occasionally produce coherent, topically relevant, and plausible answers that are not based on facts and may be misleading and even harmful. New types of datasets are needed to evaluate the truthfulness of generated answers and develop reliable approaches for detecting answers that are not supported by evidence. The MedAESQA (Medical Attributable and Evidence Supported Question Answering) dataset presented in this work is designed for developing, fine-tuning, and evaluating language generation models for their ability to attribute or support the stated facts by linking the statements to the relevant passages of reliable sources. The dataset comprises 40 naturally occurring aggregated deidentified questions. Each question has 30 human and LLM-generated answers in which each statement is linked to a scientific abstract that supports it. The dataset provides manual judgments on the accuracy of the statements and the relevancy of the scientific papers.
Similar content being viewed by others

Background & Summary
The unprecedented improvements in the quality of the answers to medical questions generated by AI models are enabled by datasets comprised of question-answer pairs, such as MultiMedQA1. These traditional datasets were generated on the assumption that having pairs of questions and ideal answers along with the sets of relevant documents, such as PubMed abstracts, is sufficient to train and test the answer generation systems2. This assumption held for the answers that were traditionally extracted from the relevant documents. With the advent of Large Language Models (LLMs) capable of generating answers using solely their internal representations of the training data, in so-called zero-shot settings, it became clear that the coherent, grammatically perfect, and topically relevant answers may not necessarily be factual. Studies on the evaluation of LLMs’ abilities to support (ground) generated statements with verifiable evidence from reliable sources have shown that the models may provide harmful answers1, perform significantly worse on lay-user generated questions, and often fail to reference relevant sources3. This can pose a risk to public health4. Unsupported statements are, therefore, a major barrier to using LLMs in any applications that may affect health. Methods for grounding generated statements in reliable sources along with practical evaluation approaches are needed to overcome this barrier. To support these goals, we have developed MedAESQA (Medical attributable and evidence supported question answering) a publicly available dataset of naturally occurring health-related questions asked by the general population paired with sets of human and AI-generated answers. Each answer statement in the dataset is required to be supported by evidence, and the evidence and the documents containing the evidence are judged for accuracy and support. The dataset is designed to be used for developing, fine-tuning, and evaluating language generation models in several approaches that address the model’s ability to attribute or support the stated facts by linking the statements to the relevant passages of reliable sources. The approaches, Retrieval Augmented Generation (RAG)5 and retrofit attribution6, provide sources to the models to guide answer generation or to find support and post-edit the generated output, respectively. Additionally, approaches may interleave retrieval and generation tasks7. The non-medical Question-Answering datasets that were used to support attribution include the Natural Questions dataset8. The questions in this dataset consist of real anonymized aggregated queries seeking factual information using the Google search engine. The answers consist of a Wikipedia page, a bounding box on this page (effectively, a summary of the page), called the long answer, and the short answer, such as one or more named entities mentioned in the Wikipedia article, yes/no, or NULL, if the page does not answer the question.
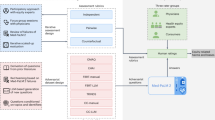
In the medical ___domain, some datasets can be adapted to train models to support attribution. For example, the BioASQ data9 contains factoid, yes/no, list, and summary questions formulated by biomedical experts. The questions are linked to sets of biomedical terms (concepts) related to the question and a set of research articles that are sufficient to answer the question. Text snippets containing one or more sentences that answer the question fully or partially are marked in the articles by the experts. The dataset is primarily focused on drug-target-disease relations for medical investigations. The MEDIQA-AnS dataset10 contains consumer-health questions, the full text from reliable web pages, extracted passages from the full text, and manually created summaries. In general, an attribution verification dataset must contain a question and at least one answer in which each statement of a fact required to answer the question is annotated and linked to a corresponding statement in an evidence source that supports or contradicts the fact stated in the answer. While the above datasets may be retrofitted to adhere to this format, to the best of our knowledge, we present the first medical question answering dataset specifically generated to test attribution to identified sources when assessing the output of natural language generation models. The distinct characteristics of the MedAESQA dataset are as follows: 1) the questions are naturally occurring popular questions submitted by the public to the National Library of Medicine, 2) the questions are annotated with the main concept of interest and with the user’s intent, e.g., to learn a fact or to support a clinical decision; 3) each question has a manually generated answer in which each sentence is linked to a PubMed abstract; 4) each question has 30 answers automatically generated by large language models. Each statement in the automatically generated answers is manually judged as required, unnecessary, or inappropriate. Each PubMed abstract provided by the models to support the specific statements is also manually judged as supporting, contradicting, or topically relevant or not to the answer. Finally, in each document that supports or contradicts the answer statements, a specific passage of text is annotated as evidence that supports the judgment. Figure 1 provides the workflow of the dataset creation and an example of a data entry.

The schematic workflow of the MedAESQA dataset creation. The dataset creation starts with annotating the question frame ➊ and question metadata, which are the topic and narrative ➋. Thereafter, the medical information expert interacts with PubMed ➌ to retrieve the relevant PubMed articles and generates the reference answer ➍ with the appropriate references for each assertion in the reference answer. In the next step, two assessors formulated the nuggets ➎ from the reference answers. The question and metadata were given to the LLMs ➏, and the LLMs interact (optionally) with the PubMed collections and retrieve the relevant documents ➐, which they used to generate the answers with appropriate references. Once the answers are generated ➑, human assessors read the answers ➒, verify the references, and provide the multi-axis assessments ➓. The dotted arrow shows the optional interaction. The human assessors provided information is shown with a green arrow, while machine-generated answers are shown with a blue arrow.
Methods
Question Formulation
The MedAESQA questions are developed using information requests submitted by self-identified non-clinicians to the MedlinePlus11 service provided by the National Library of Medicine. We chose the previously unseen, most popular, forty questions asked by MedlinePlus users. Each question also includes medical informatics expert-coded topic and narrative to support the efficient retrieval of the relevant documents. The topic signifies the key subject (focus) of the question, whereas narrative provides the context and background information on the question. Additionally, we provide an expert-coded structured representation of the information in the question, which we call question frame12. Frame representation resembles a predicate-argument structure where a predicate is connected to its arguments and their semantic roles, such as THEME and AGENT13. A question frame includes a trigger for the question type, one or more THEME arguments, and optional semantic roles, all tied to their text mentions. In a question frame, question focus is the main theme of the question, which describes the key entities of the question, and the question type signifies the aspect of interest about the question focus (expected answer type). To characterize the disorders, user intents, body systems and anatomical structures, and clinical specialties encompassed by the collection, we also label each question with its ‘Subject Matter’, i.e., the broad medical area, such as genetics, or focus on clinical drugs; ‘Body System’, and ‘Specialty’, i.e., a clinical expert best suited to answer the question, such as cardiology or endocrinology. These labels show that the MedAESQA dataset contains questions that look for a variety of answers: treatment, effect, etiology, etc. In our further fine-grained analysis on Body System on MedAESQA questions, we found that questions cover almost all the body systems, starting from ‘immune’ to ‘vision’. We also analyzed the Clinical Specialty of the medical specialist that would typically address or manage the issue, and we observed that MedAESQA questions cover an array of diverse specialties. We have provided the distribution of the question frame (Task, Answer type, and Subject Matter) and list of all Body Systems and Specialties of MedAESQA questions in Table 1 and 2, respectively.
Expert-curated Answers
Following the work of Attal et al.14, a medical information expert utilizes the question focus and answer type to query PubMed15 and retrieve articles that could potentially provide the answer to the question. In the next step of answer formulation, the expert reads the titles and abstracts of relevant articles and formulates an answer sentence by considering one or more abstracts. For each answer sentence, the expert also includes the appropriate PMIDs to provide evidence for the assertions stated in the answer sentence. By following the aforementioned strategy, an answer (with multiple sentences) is formulated in such a way that it remains complete, accurate, coherent, and evidence-supported with appropriate PubMed identifiers (PMIDs) for each assertion.
Expert-curated Nuggets
Additionally, we provide manually generated information nuggets for factual evaluation. An information nugget can be used by an assessor to make a binary decision as to whether the fact represented by said nugget is contained in a response16. An assessor may determine nuggets to be required for an answer and may match nuggets to the sentences that contain them. This allows for a finer level of granularity in the evaluation and the assessment of an atomic fact rather than a sentence as a whole. Nuggets were generated from the 40 expert-curated answers in the MedAESQA dataset, where exactly one nugget was generated for every fact contained in an answer. We used a Predicate (subject, object) form to capture the information nuggets. Each medical concept in a nugget is associated with a Concept Unique Identifier (CUI) from the Unified Medical Language System (UMLS)17. These CUIs were identified by manually searching the UMLS Metathesaurus Browser for the closest match. Some facts required more complex nugget structure including, but not limited to, “if, then” clauses and comparisons. An attempt was made to normalize language across answers with common predicates and formatting (e.g. Treat (treatment, condition) or Prevent (method of prevention, condition)), while retaining information from the original sentence as much as possible. Each nugget was reviewed by at least two reviewers.
Machine-generated Answers
To generate answers with appropriate references, we organized a community evaluation18 at the 2024 Text Retrieval Conference (TREC). The participants proposed their approaches for generating answers. Analyzing the participants’ approaches, we outline a framework that takes an input question along with additional metadata (topic and narrative) and provides the generated answer as output.
The detailed steps include:
-
1.
Query Formulation and Expansion: Given a topic, question, and narrative, a query is formulated to search PubMed articles to obtain the relevant documents from PubMed collection. The query can be formulated by considering either the topic, question, narrative, or any combination of these metadata available with each question. To improve the retrieval process query expansion can also be applied where a query is expanded or transformed with additional terms or phrases that are semantically related or contextually relevant.
-
2.
Document Retrieval: To retrieve the relevant documents, the 2024 annual baseline snapshot of Medline/PubMed, which goes approximately through the end of 2023 was used. We provided a pre-processed set of 20, 727, 695 PMIDs representing the abstracts in the 2023 snapshot. The approaches have primarily used lexical retrieval (BM2519) to retrieve the top-k relevant documents for each question by utilizing the index built upon the title and abstract of the PubMed collection. The approaches also experimented with extracting the relevant snippets from the documents and considered the snippets as the relevant passages for the next stage of the framework.
-
3.
Document Reranking: The ranking of the documents/snippets is an important step to further improve the ranking of documents retrieved in the first stage of the retrieval system. The goal is to reorder the retrieved documents to present the most relevant and high-quality results at the top of the list. Multiple re-rankers were utilized to re-rank the documents/snippets: pointwise (monoT520, TAS-B21, ANCE22), pairwise (duoT5), and listwise (RankGPT23) approaches to rerank the documents/snippets.
-
4.
Answer Generation: The reranked documents along with the corresponding question were used to generate an answer to the question. Various open (Mistral-7B24, Llama3.125) and closed-sourced (gemini-1.5-flash-00126, gpt4o-mini, GPT-4o27) LLMs were utilized to generate the answers, additionally, LLMs were instructed to cite the appropriate PMIDs of the ranked documents while stating the fact in the answer.
-
5.
Post-hoc Citations (Optional): This is an optional alternative step in our framework, where an answer is generated first without referencing any documents, and in the post-hoc stage, each sentence is required to cite supporting documents. LLMs were employed to provide appropriate citations for each sentence from the reranked list of the documents.
Human Judgment on Answers
We evaluated two different aspects of the answers: (a) reference attribution and (b) the quality and factuality of the answers. The former aims to judge the support the referred documents provide for an assertion generated by the machine and the latter focuses on evaluating the answer to a clinical question asked by clinicians to answer health-related questions asked by their patients. We envisioned that clinicians would review each answer and subsequently explain it in plain language. The evaluation was conducted by clinicians employed by Centaur Labs28 in a crowdsourcing manner. Each final judgment is a consensus on the majority vote of at least three annotators. We also computed the inter-annotator agreement score, which is defined as the percentage of annotators who assigned the majority label to the total number of annotators. We have provided the details of inter-annotator agreement scores on different annotation tasks in the creation of the MedAESQA dataset in the Table 3.
We follow a two-step judgment on machine-generated answers:
-
Step 1: Evaluating Answer Alignment with Questions and Answer Quality and Completeness: We begin the evaluation by assessing whether the machine-generated text, as a whole, directly answers the question. In the next step, we examined the relevance of each assertion in the answer sentences to the question. Toward this, we categorized each assertion in the generated answer using one of the following four labels:
-
Required: Given assertion is necessary to have in the generated answer for completeness of the answer.
-
Unnecessary: Given assertion is not required to be included in the generated answer. An assertion can be categorized as unnecessary for multiple reasons including (a) it provides general information on the topic, (b) it recommends seeing a doctor, while the task states the patient has already contacted the provider, or the provider is asking the question.
-
Borderline: An assertion can be marked borderline, if it is relevant, possibly even -“good to know”,- but not required to be part of the answer. For example, if the question is about the most commonly used treatments, information about treatments in the early stages of clinical trials is not necessary.
-
Inappropriate: If an assertion may harm the patient if followed, it is marked as inappropriate. E.g., if, according to the answer, physical therapy reduces the pain level, but the patient experiences more pain due to hip mobilization, the patient may start doubting they are receiving adequate treatment.
We have provided examples of the borderline and unnecessary answer sentences for some healthcare questions in Table 4.
Table 4 Sample examples showing the assertion relevance category for borderline and unnecessary labels. -
-
Step 2: Evaluating Answer Alignment with Evidence Support: In the second step, we evaluated the referenced document(s) for each generated answer sentence to determine the relationship between the document and the generated assertion, if any. Each cited document was labeled with one of four possible relationships to the answer sentence: ‘Supports’, ‘Contradicts’, ‘Neutral’, or ‘Not Relevant’. Additionally, the experts also provided a passage from the referenced document to support their assessment of the evidence relation.
-
Supports: A relation between the referenced document and the answer sentence is marked as support, if there is at least one sentence in the referenced document that supports/agrees with the assertion made in the answer sentence, e.g.: “opioids were the mainstay of perioperative pain control”. In addition, no other sentence in the document contradicts the statement.
-
Contradicts: A relation between the referenced document and the answer sentence is marked as contradicts if there is at least one sentence in the referenced document that disagrees with the assertion or states its opposite, e.g.: “Increasing pain levels after the first week postoperatively, for 3 days, are most likely to be caused by the change to more extensive mobilization and physiotherapy in the rehabilitation unit.” (The answer in this case stated that the pain decreases steadily after the surgery.)
-
Neutral: The referenced document is marked neutral, if it is topically relevant, but lacks any information to validate or invalidate the assertion made in the answer sentence.
-
Not relevant: The referenced document is considered Not Relevant if the referenced document is not relevant to the sentence.
-
Data Records
We have archived MedAESQA29 data records with Open Science Framework (OSF), available at https://doi.org/10.17605/OSF.IO/ydbzq. The OSF link contains a directory called MedAESQA. The MedAESQA directory contains the entire dataset in a JSON file, which lists data items. The README file also contains detailed information about each field in the dataset, including sample code to process the data. Each item in the JSON file contains the relevant key (metadata name) and value (metadata information) pairs, which are question_id, question, question_frame, expert_curated_answer, expert_curated_nuggets and machine_generated_answers. The detailed statistics of the MedAESQA dataset are shown in Table 5. Figure 2, shows the JSON tree to visualize the data samples.

An example of a JSON tree for one of the data objects in the MedAESQA dataset. The illustration shows answers for only three machine-generation approaches M1, M2, and M3, however, the dataset has answers from 30 machine-generation approaches (M1 to M30) along with the citation assessment for each answer sentence in the generated answers. The answers and nuggets are truncated in the example.
Technical Validation
To generate multiple answers and validate the MedAESQA dataset, we organized a community evaluation18 at the 2024 Text Retrieval Conference (TREC), in which participants were provided with the questions and PubMed collection and asked to generate the answers in which the appropriate PMIDs supported each assertion (equated to sentences in this evaluation). We acknowledge that in this edition of the TREC evaluation, which resulted in the MedAESQA dataset, we limit ourselves to the title and abstract of the PubMed document, which may inhibit real-world usability of supporting the assertions. In the future, we plan to use the full-text PubMed document to assess the validity of the assertion. Participants were asked to generate the answer sentence that has to be supported by up to three attributions (cited references), with a maximum of 30 documents allowed per answer. Documents had to be cited in the answers using PMIDs enclosed in square brackets, as illustrated in Figure 1. For each question, we received thirty answers generated using different approaches. All the answer-generation approaches are depicted in the Appendix. The different strategies used by the participants offer diverse answers. Furthermore, each answer as a whole and the assertions with corresponding citations are manually evaluated by the experts, which provides the level of correctness of the machine-generated answers. We next describe the metrics we used to validate the answer quality, associations between the citations and assertions, and relevance of the cited documents.
Benchmarking Metrics
We conducted a comprehensive evaluation of machine-generated answers across multiple levels and dimensions.
-
Answer Quality: We evaluate the quality of the generated answers considering multiple perspectives: accuracy, precision, recall, and redundancy. The details of the metrics are as follows:
-
Answer Accuracy evaluates the accuracy of the generated answer using human-provided judgment. It measures how many of the answers to the total of 40 questions were deemed acceptable (judged as answering the question at least partially) for each answer generation approach.
$$\,{\rm{Accuracy}}=\frac{{\rm{Number\; of\; Acceptable\; Answers}}}{{\rm{Total\; Number\; of\; Questions}}}$$(1) -
Answer Completeness (Recall) evaluates the extent to which a given answer covers the facts (aspects) deemed required by the assessors. The required aspects are aggregated across all system-generated answers. To identify answer aspects, we cluster the answer sentences using sentence embeddings generated by the SentenceTransformer model (sentence-transformers/all-mpnet-base-v2) and the SimCSE model (princeton-nlp/sup-simcse-roberta-large). We set up multiple evaluation levels for computing recall. In a strict evaluation, only sentences judged required and supported by evidence were considered for grouping. For a lenient evaluation, all sentences judged required were considered. For a relaxed evaluation, the borderline sentences were considered in addition to the required sentences. The number of aspects for the automated grouping is set to 10 using K-means clustering.
$$\,{\rm{Completeness}}=\frac{{\rm{Number\; of\; Distinct\; Clusters\; Containing\; Sentences\; from\; Answer}}}{{\rm{Number\; of\; Clusters}}}$$(2) -
Answer Precision assesses the proportion of the assertions that were judged required or acceptable in the answer.
$$\,{\rm{Precision}}=\frac{{\rm{Number\; of\; Generated\; Required\; Sentences}}}{{\rm{Total\; Number\; of\; Generated\; Sentences}}}$$(3) -
Redundancy Score quantifies unnecessary answer sentences and penalizes a system for generating unnecessary sentences. This score measures the informativeness of the generated answers as a proportion of generated unnecessary answer sentences among all generated answer sentences.
$$\,{\rm{Redundancy\; Score}}=\frac{{\rm{Number\; of\; Generated\; Unnecessary\; Sentences}}}{{\rm{Total\; Number\; of\; Generated\; Sentences}}}$$(4) -
Irrelevancy Score quantifies inappropriate/potentially harmful answer sentences and penalizes a system for generating these sentences. The score measures the potential of the generated answer to mislead the reader.
$$\,{\rm{Irrelevancy\; Score}}=\frac{{\rm{Number\; of\; Generated\; Inappropriate\; Sentences}}}{{\rm{Total\; Number\; of\; Generated\; Sentences}}}$$(5)
-
-
Citation Quality: A system-generated answer statement may be supported or contradicted by the documents provided as references. It is also possible that answer sentences may not include any references or may include references that are only topically relevant or irrelevant. The following metrics are designed to assess the quality of these references:
-
Citation Coverage measures how well the required and borderline generated answer sentences are backed by the appropriate (judged as supports) citations.
$$\,{\rm{Citation\; Coverage}}=\frac{{\rm{Number\; of\; Systems\; Generated\; Answer\; Sentences\; with\; One\; or\; More\; Supportive\; Citation}}}{{\rm{Total\; Number\; of\; Generated\; Answer\; Sentences}}}$$(6) -
Citation Support Rate assesses the proportion of the citations provided by a system that were judged by the experts as supporting the corresponding statement in the generated answer.
$$\,{\rm{Citation\; Support\; Rate}}=\frac{{\rm{Number\; of\; Supports\; Citations}}}{{\rm{Total\; Number\; of\; Citations}}}$$(7) -
Citation Contradiction Rate assesses the proportion of the citations provided by a system that were judged by the experts as contradicting the corresponding statement in the generated answer. In a fact-verification task, this measure can indicate how effectively a system identifies contradictory evidence.
$$\,{\rm{Citation\; Contradict\; Rate}}=\frac{{\rm{Number\; of\; Contradict\; Citations}}}{{\rm{Total\; Number\; of\; Citations}}}$$(8)
-
-
Document Relevancy: By pooling all documents judged relevant to a given topic, we compute standard recall and precision. The set of relevant documents includes documents judged as supporting, contradicting, or neutral.
$$\,{\rm{Recall}}=\frac{{\rm{Number\; of\; relevant\; retrieved\; documents}}}{{\rm{all\; relevant\; documents}}}$$(9)$$\,{\rm{Precision}}=\frac{{\rm{Number\; of\; relevant\; retrieved\; documents}}}{{\rm{Number\; of\; references\; provided}}}$$(10)
MedAESQA Dataset Analysis
We performed a detailed analysis of the developed MedAESQA dataset by calculating dataset statistics at various levels of granularity. We found 1,108 out of 1,200 machine-generated answers were deemed acceptable by experts. We also analyzed the answer sentence relevancy assessed by the experts and found that 3,958 answer sentences were judged required out of 5,162 generated answer sentences. Similarly, in our analysis of the evidence relation, we found 5489 references out of 8111 supported the assertion made in the generated answers. The detailed analysis of different categories of answer sentence relevancy and evidence relation is presented in Fig. 3.

Distribution of the assessed labels for answer accuracy (a), answer sentence relevance (b), and evidence relation (c) in MedAESQA dataset.
The MedAESQA dataset comprises 40 questions along with their expert-curated and machine-generated answers. Each question is associated with 30 machine-generated answers, resulting in a total of 1,240 answers. For each machine-generated answer, a sentence-level assessment is conducted to evaluate answer accuracy, sentence relevance, and evidence relation. The dataset includes a total of 5,162 answer sentences. In the expert-curated answers, we identified 316 references, with a minimum of 3 and a maximum of 10 references per answer. On the other hand, the machine-generated answers yielded a minimum of 0 and a maximum of 31 references per answer. The MedAESQA dataset also contains a total of 7,651 human-curated evidence excerpts from referring documents to support the assessed evidence relations. A detailed analysis of the MedAESQA dataset is provided in Table 5.
Benchmarking Evaluation
We evaluated the performance of methods used to generate answers in the created MedAESQA dataset on various evaluation metrics. The detailed results are presented in Tables 6, 7 and 8. On the answer accuracy metric, 26 out of 30 methods achieved more than 92% accuracy with a maximum of 100% (11 methods) and a minimum of 92.5% (2 methods). More than one-third of the methods (11 out of 30) achieved perfect accuracy which shows the acceptable quality of the generated answers. For precision of the answer, method M17 achieved the best performance with a precision score of 90.23. The precision score for 17 out of 30 methods was in the range of 73.54 to 85.54 and for 3 out of 30 methods, the precision score was in the range of 85.54 to 90.23. The redundancy scores were high (>15%) for only five methods. Method M4 recorded the lowest redundancy score of 4.04% with a precision of 79.08. Harmfulness is a key metric that aims to assess the tendency of the system to generate harmful sentences. We found that 19 of 30 methods achieved a perfect harmfulness score of 0%. The remaining methods also perform well and seem cautious while generating the answers as the highest harmfulness score we recorded was only 1.88. Nevertheless, we believe the harmful sentences are a good source for training and testing approaches for identifying and mitigating harmful answers.
To measure the answer completeness (recall), we followed a clustering approach where we clustered all the generated answers for a given question together to assess the distinct aspects that are covered in the machine-generated answers. We utilized two different answer sentence representation approaches Sentence Transformer and SimCSE. The comparative results under three different settings (S+R, R, and R+B) are demonstrated in Table 7. S+R, which considers only supported and required facts, is the most strict evaluation and R+B, which includes all required and borderline statements disregarding the support, is the most lenient evaluation. We found that method M24 (Sentence Transfomer) obtained the best recall scores with 40.25 and 42.75 on the S+R and R+B settings respectively. A similar trend is also observed while using SimCSE as the sentence representation. Some methods recorded recall scores of 0 under S+R settings because those methods did not generate the citations for the generated answers.
While analyzing the results of the citation quality of the different approaches to the machine-generated answers, we observed that the majority of the approaches (18) achieved citation coverage in the range of 62 to 93. Method M1 recorded the highest citation coverage of 91.92 and M28 (excluding M25 and M27 as these methods did not generate citations along with the answer) as the lowest citation coverage of 6.38. For the citation support rate (CSR) the method M26 obtained the highest score of 77.88. Citation contradiction rate (CCR) is another key metric to evaluate citation quality as it assesses how often a system is citing a contradictory document with an assertion. We found some of the best CSR score systems, M6 and M26 recorded CCR values of 3.86 and 1.82 which signify that the answer generation systems were good in citing the appropriate documents. We also analyzed the document recall and precision scores and observed that most of the systems yield low recall however the precision scores were moderate. Method M24 achieved the highest document recall of 23.77 with a precision of 74.98.
Expert-curated Answers vs. Machine-generated Answers
We also analyze how close the machine-generated answers are to the expert-curated answers. Towards this, we analyze answer-level and citation-level similarities between two different modes of the answer-curation. For the answer-level similarity, we computed the sentence similarly between the expert-curated and each machine-generated answer and reported the BLEU, BLEU-4, ROUGE-2, and ROUGE-L metrics. Since an answer can be stated in different way, n-gram similarities may not always be the best choice to measure the similarity, therefore, we also reported the semantic similarity by reporting the BERTScore between the the expert-curated and each machine-generated answer. The detailed results are shown in Table 9. On n-gram similarities-based metrics, we found that method M11 achieved the highest BLEU and ROUGE scores (0.0117 and 0.1845) and comparable BERTScore (0.8514). The method M20 records competitive scores to M11 on both n-gram-based evaluation (BLEU: 0.117, ROUGE: 0.1825) and semantic similarity (BERTScore: 0.8517) metrics. For citation-level similarity, we created a list of cited documents in the answer to a given question for expert citation and machine-generated citation. We considered the expert citation list as the ground truth citation and computed the true positives (generated citations that are also present in the expert citation), false positives (generated citations that are not present in the expert citation), and false negatives (expert citations that are not present in the generated citation). With these, we computed the citation precision, recall, and f-score and reported the performance in Table 9. We found that method M1 achieved the highest citation F-score of 13.63, however, method M11 and M20 (best on answer level similarity) also recorded the competitive F-Score of 13.00 and 12.46 respectively.
Usage Notes
We have provided detailed instructions in the README file of the Open Science Framework repository (https://osf.io/ydbzq) describing how to process the MedAESQA datasets. The source code to evaluate the system performance can be found in the GitHub repository (https://github.com/deepaknlp/MedAESQA).
Code availability
The code to process the MedAESQA and evaluate the system can be found at GitHub (https://github.com/deepaknlp/MedAESQA).
References
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172–180 (2023).
Demner-Fushman, D. & Lin, J. Answering clinical questions with knowledge-based and statistical techniques. Computational Linguistics 33, 63–103 (2007).
Bašaragin, B. et al. How do you know that? teaching generative language models to reference answers to biomedical questions. In Demner-Fushman, D., Ananiadou, S., Miwa, M., Roberts, K. & Tsujii, J. (eds.) Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, 536–547, https://doi.org/10.18653/v1/2024.bionlp-1.44 (Association for Computational Linguistics, Bangkok, Thailand, 2024).
Biden, J. R. Executive order on the safe, secure, and trustworthy development and use of artificial intelligence (2023).
Lewis, P. et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33, 9459–9474 (2020).
Gao, L. et al. Rarr: Researching and revising what language models say, using language models. In The 61st Annual Meeting Of The Association For Computational Linguistics (2023).
Jain, P., Baldini Soares, L. & Kwiatkowski, T. From RAG to riches: Retrieval interlaced with sequence generation. In Al-Onaizan, Y., Bansal, M. & Chen, Y.-N. (eds.) Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 8887–8904, https://doi.org/10.18653/v1/2024.emnlp-main.502 (Association for Computational Linguistics, Miami, Florida, USA, 2024).
Kwiatkowski, T. et al. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 452–466, https://doi.org/10.1162/tacl_a_00276 (2019).
Krithara, A., Nentidis, A., Bougiatiotis, K. & Paliouras, G. Bioasq-qa: A manually curated corpus for biomedical question answering. Scientific Data 10, 170 (2023).
Savery, M., Abacha, A. B., Gayen, S. & Demner-Fushman, D. Question-driven summarization of answers to consumer health questions. Scientific Data 7, 322 (2020).
MedlinePlus [Internet]. National Library of Medicine (US) (1998 -). Last accessed 7 April 2025, Available from: https://medlineplus.gov.
Kilicoglu, H. et al. Semantic annotation of consumer health questions. BMC bioinformatics 19, 1–28 (2018).
Gildea, D. & Jurafsky, D. Automatic labeling of semantic roles. Computational linguistics 28, 245–288 (2002).
Attal, K., Ondov, B. & Demner-Fushman, D. A dataset for plain language adaptation of biomedical abstracts. Scientific Data 10, 8 (2023).
PubMed [Internet]. National Library of Medicine (US) (1996 -). Last accessed 7 April 2025, Available from: https://pubmed.ncbi.nlm.nih.gov.
Voorhees, E. M. & Buckland, L. Overview of the trec 2003 question answering track. In TREC, vol. 2003, 54–68 (2003).
Lindberg, D. A., Humphreys, B. L. & McCray, A. T. The unified medical language system. Yearbook of medical informatics 2, 41–51 (1993).
Gupta, D., Demner-Fushman, D., Hersh, W., Bedrick, S. & Roberts, K. Overview of TREC 2024 biomedical generative retrieval (BioGen) track. In The Thirty-Third Text REtrieval Conference Proceedings (TREC 2024) (2024). Last accessed 7 April 2025, https://trec.nist.gov/pubs/trec33/papers/Overview_biogen.pdf.
Robertson, S. & Zaragoza, H. et al. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends in Information Retrieval 3, 333–389 (2009).
Nogueira, R., Jiang, Z., Pradeep, R. & Lin, J. Document ranking with a pretrained sequence-to-sequence model. In Findings of the Association for Computational Linguistics: EMNLP 2020, 708–718 (2020).
Hofstätter, S., Lin, S.-C., Yang, J.-H., Lin, J. & Hanbury, A. Efficiently teaching an effective dense retriever with balanced topic aware sampling. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 113–122 (2021).
Xiong, L. et al. Approximate nearest neighbor negative contrastive learning for dense text retrieval. In International Conference on Learning Representations (2020).
Sun, W. et al. Is chatgpt good at search? investigating large language models as re-ranking agents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 14918–14937 (2023).
Jiang, A. Q. et al. Mistral 7B [Internet] (2023). Last accessed 7 April 2025, https://mistral.ai/news/announcing-mistral-7b.
Dubey, A. et al. The llama 3 herd of models [Internet] (2024). Last accessed 7 April 2025, https://ai.meta.com/research/publications/the-llama-3-herd-of-models/.
Gemini [Internet]. Google (2025). Last accessed 7 April 2025, https://blog.google/technology/ai/google-gemini-ai/.
Achiam, J. et al. Gpt-4 technical report [Internet] (2023). Last accessed 7 April 2025, https://cdn.openai.com/papers/gpt-4.pdf.
Centaur Labs [Internet]. Accurate and scalable health data labeling and model evaluation (2025). Last accessed 7 April 2025, https://centaur.ai.
Gupta, D., Bartels, D. & Demner-Fushman, D. Medaesqa, https://doi.org/10.17605/OSF.IO/YDBZQ (2025).
Acknowledgements
This research was supported by the Intramural Research Program of the National Library of Medicine at the NIH. This work utilized the computational resources of the NIH HPC Biowulf cluster (https://hpc.nih.gov). Creation of this dataset would not have been possible without the LLM-generated answers provided by the teams that participated in the Text REtrieval Conference (TREC) hosted by the National Institute of Standards (NIST): The Information Engineering Lab (University of Queensland, CSIRO), Australia; IIUoT, University of Tsukuba, Japan; UR-IW, University of Regensburg, Webis, Friedrich-Schiller-Universität Jena and Leipzig University; H2oloo, University of Waterloo. The authors thank Srishti Kapur, Centaur Labs for expertly managing the manual evaluation process.
Funding
Open access funding provided by the National Institutes of Health.
Author information
Authors and Affiliations
Contributions
D.G. contributed to project design, implemented data processing code and pipelines conducted baseline and machine learning experiments, contributed to collection creation, and wrote and edited the manuscript. D.B. contributed to the collection creation and writing and editing of the manuscript. D.D.-F. conceived of the project led and contributed to data generation, contributed to writing and editing the manuscript, and otherwise provided feedback on all aspects of the study.
Corresponding author
Ethics declarations
Competing interests
Dina Demner-Fushman is currently an Editorial Board Member for Scientific Data. She has not been involved with any of the editorial aspects or decisions for this publication.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gupta, D., Bartels, D. & Demner-Fushman, D. A Dataset of Medical Questions Paired with Automatically Generated Answers and Evidence-supported References. Sci Data 12, 1035 (2025). https://doi.org/10.1038/s41597-025-05233-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05233-z
