
Abstract
According to the World Health Organization (WHO), pneumonia kills about 2 million children under the age of 5 every year. Traditional machine learning methods can be used to diagnose chest X-rays of pneumonia in children, but there is a privacy and security issue in centralizing the data for training. Federated learning prevents data privacy leakage by sharing only the model and not the data, and it has a wide range of application in the medical field. We use federated learning method for classification, which effectively protects data security. And for the data heterogeneity phenomenon existing in the actual scenario, which will seriously affect the classification effect, we propose a method based on two-end control variables. Specifically, based on the classical federated learning FedAvg algorithm, we modify the loss function on the client side by adding a regular term or a penalty term, and add momentum after the average aggregation on the server side. The federated learning approach prevents the data privacy leakage problem compared to the traditional machine learning approach. In order to solve the problem of low classification accuracy due to data heterogeneity, our proposed method based on two-end control variables achieves an average improvement of 2% and an accuracy of 98% on average, and 99% individually, compared to the previous federated learning algorithms and the latest diffusion model-based method. The classification results and methodology of this study can be utilized by clinicians worldwide to improve the overall detection of pediatric pneumonia.
Similar content being viewed by others

Introduction
Pneumonia has long been a leading cause of illness and death in both developed and developing countries1.

Percentage of causes of death of children under 5 years of age in China, 2014.
Pneumonia is an acute inflammatory condition that usually causes infection of the lower respiratory tract and lung parenchyma, leading to clinical syndromes such as coughing, elevated body temperature, shortness of breath and malaise2. Pneumonia affects many people, especially in relatively underdeveloped areas where high levels of pollution, unhygienic living conditions, and overcrowding are relatively common and where healthcare infrastructure is inadequate. About 3.9 million people worldwide die each year from lower respiratory tract infections such as pneumonia, especially in recent years natural disasters and outbreaks of rare viruses have led to an increasing mortality rate of pneumonia, with more than 5.6 million deaths due to pneumonia globally each year3 and pneumonia is the leading cause of death among children under 5 years of age in China, as shown in Fig. 1. Therefore, the detection of pneumonia disease is crucial for discovering the ___location of the lesion as well as improving the cure rate, in addition to the detection of pneumonia can help to promote the development of auxiliary diagnostic and therapeutic decision-making capability. In many clinical studies, lung disease is typically diagnosed using X-ray, Magnetic Resonance Imaging (MRI), and CT imaging4. However, the use of these diagnostic methods to determine whether the diagnosis of pneumonia is confirmed or not requires a lot of time and effort from specialized doctors to analyze the images of the lesions. According to a survey, the annual growth rate of radiologists in China is 4.1%, while the annual growth rate of medical images requiring diagnosis is 30%5. With the increase in the amount of image data processed by radiologists, even far beyond their own load, this will inevitably have an impact on the accuracy of diagnosis and detection efficiency of imaging data.

Traditional machine learning and federated learning frameworks.
At present, chest X-rays are generally used for routine examinations of pneumonia in China6. Since there are many types of pneumonia that are not easy to recognize and the X-ray images of pneumonia usually consist of many opaque areas, radiologists often need a solid theoretical foundation as well as extensive clinical consultation experience in the process of pneumonia diagnosis. More seriously, as the consultation time increases, problems such as visual fatigue and misdiagnosis inevitably occur. With the introduction of artificial intelligence, especially the development of machine learning, the use of technology to achieve pneumonia detection has alleviated these problems. With the emergence of machine learning, the main means in the field of pneumonia detection in addition to the use of traditional image processing, more inclined to use machine learning methods for pneumonia detection. For example, Liang Han used fiber optic sensors to build a pneumonia detection system, and at the same time, combined with the SVM classifier to classify and detect the collected respiratory signal, and the detection accuracy of the final model can reach 94.41%7. Masud et al. proposed a new method for pneumonia detection which utilizes integrated learning to extract features from chest radiography and performs the final classification using Random Forest, which achieves a final classification accuracy of up to 86.3%8. CY Effah et al. investigated the effectiveness of eight machine learning methods in terms of predicting pneumonia based on biomarkers, laboratory parameters, and physical characteristics and demonstrated that RF and XGBoost methods achieve performance accuracy of about 92%9. However, such traditional machine learning methods need to be based on manual design of features and the inaccuracy of the target feature extraction also affects the final detection results, so such traditional methods have gradually faded out of the field of pneumonia detection. Deep learning, as a higher-level form of machine learning, has gradually become a mainstream method in the fields of target detection and image classification due to its powerful learning capability and the fact that it does not require manual feature extraction10,11. And with its excellent performance in target detection tasks, deep learning algorithms have been gradually applied to medical fields. Rajpurkar et al. proposed an algorithm for detecting pneumonia on chest X-rays at the level of a radiologist. The proposed model consists of 121 layers of dense convolutional neural network trained on a huge repository of X-ray images i.e. chest X-ray 14. With a simple modification, the algorithm was extended to detect all 14 diseases on the dataset and obtained an F1 score of 0.43512. R Kundu et al. designed three convolutional neural network models of GoogLeNet, ResNet-18 and DenseNet-121 for use in a pneumonia detection aid, while using a weighted average integration technique to assign weights. The final experimental results show that this method is superior to the widely used integration computation and has better robustness13. Varshni et al. compared pre-trained convolutional neural network models such as DensNet-12l and DensNet-l69 to evaluate their performance using classifiers such as KNN and Random Forests, and ultimately demonstrated that combining multilayer networks and multiple classifiers can improve the classification effect of the model14. Nithya et al. used Multiplied DCGAN to improve the classification of pneumonia15. Deep learning and machine learning models show excellent promise in helping with things like medical diagnosis and treatment, but only if a lot of different data is needed for focused training to show better results16, as shown in Fig. 2a. Although the healthcare field has matured, preserving large amounts of user data is still a daunting task for many hospitals. Therefore, in order to obtain good training results, people will centralize data from several hospitals for training. However, the data are centralized and shared for use, which will result in user data needing to leave the local area for training, especially since healthcare-related data often involves patients’ personal information, and there is a serious privacy leakage problem17,18. Moreover, in the process of chest X-ray, each time the technician who does it is different, and the experience value is different to give different results, which will easily lead to the phenomenon of X-ray image discrepancy. The sensitivity of each manufacturer and brand of instrument is different, which may also lead to error during the examination. The patient’s psychological activity and cooperation during the examination will affect the examination results, all of the above situations will cause data heterogeneity and thus affect the diagnostic effect. Therefore, how to realize the design of a better pneumonia detection model without data leaving the local area and solve real-world data heterogeneity problem will be a further step for the future development of AI technology in the medical field.
In this context, federated learning technology was first proposed in 2016 to solve the problems of data leakage and data silos26. The most important feature of federated learning as a distributed machine learning technique is that data is kept in the data source throughout the training process, which ensures the privacy of user data27 and the server receives the local models from each client and aggregates them to derive the global model, as shown in Fig. 2b. Therefore, we propose a federated learning approach based on two-end control variables to classify pediatric pneumonia. Our proposed federated learning method based on two-end control variables not only prevents data centralized training to protect data security, but also mitigates the impact of data heterogeneity on the classification effect.
Results
Guaranteeing data privacy compared to conventional machine learning
Traditional machine learning methods for classifying pneumonia, like Naive Bayes, K Nearest Neighbour, Support Vector Machine, Random Forest, Logistic Regression, and other methods28, although they can classify childhood pneumonia, none of them consider into data privacy issue. However, federated learning can break the data silos, and the parties can well avoid the privacy leakage problem by uploading the trained model instead of uploading the data.
Secure training does not affect performance of pediatric pneumonia AI models
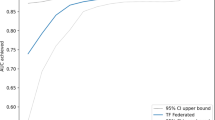
We conduct experiments using one-end based federated learning algorithm (FedProx20, SCAFFOLD21, FedCurv22 and FedNTD23), two-end based approach (FedProxM, SCAFFOLDM, FedCurvM and FedNTDM) and recently proposed diffusion model29 based approach FedDDA19 for data augmentation30 to address data heterogeneity. We have also applied the diffusion model to other methods (FedProx+DM, SCAFFOLD + DM, FedCurv + DM and FedNTD + DM), in Tables 1, 2, 3 and 4, DM stands for diffusion model, which generates high quality data for data augmentation to address data heterogeneity. In Tables 1, 2, 3 and 4, the bolded parts are our methods and experimental results. We can see that using CNN and VGG11 models for experiment, the methods based on two-end control variables are better than both classical federated learning algorithms and diffusion model-based methods for classification, with an average increase of 2% in accuracy, an average increase of 98% in accuracy and individually up to 99%. The classification effect is significant even though the data is non-independently and identically distributed. In Table 1, IID indicates that the data is independent and identically distributed, Sharding represents that data is simulated to be non independent and identically distributed based on the number of user shards in the Sharding method (we are sorting the data by label and dividing the data into pieces of the same size. Specifically, a shard contains similar samples of size \(\frac{\left| D \right| *N}{s}\), where D is the total size of the dataset, N is the total number of clients, and s is the number of shards per user. Heterogeneity is controlled by the number of shards.). In Table 3, S_Max is a sharding method based on the maximum number of shards (Divide the labels of a dataset into a number of shards and assign these shards to multiple clients. Each client can receive at most K shards and the distribution process tries to ensure that the data of each client is reasonably distributed in terms of categories.) and a centralized data sharding method (Distribute the data evenly to multiple clients through a centralized approach, where each client receives an equal number of data.) to simulate that data is non independent and identically distributed.

Federal learning flowchart for childhood pneumonia.
Discussion
The problems we address include preventing data leakage and solving data heterogeneity. Data privacy is important in the medical field. Traditional machine learning methods need to share data in order to get good classification results, which has the possibility of data leakage. We use federated learning method without data sharing, which can well prevent data leakage. For the phenomenon of data heterogeneity in the medical field, we propose a federated learning method based on two-end control variables to mitigate it, and the experimental results prove that our classification effect is better compared with other methods for mitigating data heterogeneity.
In this paper, we use a federated learning method based on two-end control variables to classify pneumonia in children, and as can be seen from the results, the classification accuracy is very good. Compared with traditional machine learning methods31,32,33, federated learning can avoid data leakage. Compared to other methods of protecting data34,35, federated learning methods can get better results. For instance, using differential privacy to add noise to protect the data affects the classification results, whereas federated learning does not introduce additional noise and the classification results are better. For the problem of data heterogeneity that exists, methods based on control variables at both ends can further improve the classification accuracy of pneumonia. We believe that this method can be utilized by clinicians worldwide to improve the overall detection of pediatric pneumonia.
Recently, the diffusion model has been widely studied for generating high-quality data, and therefore for solving the problem of data heterogeneity in healthcare. However, it is worth noting that the diffusion model generates data using federated training and then uses the newly generated data to classify pneumonia. Compared to our approach, this method is less efficient in communication because it requires two stages-one for generating data and one for classification. And from Tables 1, 2, 3 and 4, we can also see that the diffusion model based method is also not as effective as our method for classification.
Our contribution is to propose a method based on control variables at both ends to alleviate the low classification effectiveness caused by data heterogeneity in the medical ___domain, which is safer than traditional machine learning methods.
Although federated learning avoids privacy leakage by uploading models without uploading data, it has been shown that the original data can be inferred from the uploaded models36. Therefore further in the future, techniques such as differential privacy37, homomorphic encryption38 and secure multi-party computation39 can be attempted to further prevent data leakage.

Heterogeneity of medical datasets: label, quantity, feature and quality.
Methods
Study design
This paper, unlike other machine learning methods, is a classification study of a federated learning method to diagnose whether a child has pneumonia or not that protects data privacy. For client selection, we randomly select 10 \((K*C)\) clients to participate in training from the given K=100 clients by client selection factor C=0.1. For model aggregation, when obtaining the models uploaded by the participating clients, we perform average aggregation to obtain the global model, and then use momentum to further update the global model. As for convergence criteria, through experimental validation, we found that the model starts to converge after 100 rounds of client-server iteration training, when the model has the highest accuracy and the best classification effect. The specific process is as follows: firstly, the clients participating in training prepare their own data; secondly, the central server initializes the global model and distributes the model weights to the clients participating in training; next, the clients update their local models with the received model weights and data, and upload the local model weights to the central server; lastly, the central server aggregates the received local models to generate a new global model and iteratively trains until the end of convergence, as shown in Fig. 3. Since some previous works have proposed to modify at the client’s loss function in federated learning or at the aggregation stage, but no one has proposed to modify both at the client’s loss function and at the server’s aggregation stage, we propose an approach based on variables at both ends. Specifically, we base on the classical FedAvg algorithm for federated learning, and update at the client-side loss function by adding a regular term or a correction term; and update at the server-side aggregation stage by adding momentum, see Algorithm 1 for the specific part of the additions. In Algorithm 1, the LFU can be a regular term20 or a penalty term22, etc. and w is model weights, T is client-server communication rounds, C is client selection factor, K is number of clients, v is momentum, \(\beta\) is momentum factor, E is local iteration rounds, B is batch size and \(\eta\) is learning rate. Through the experimental results, it is found that the accuracy of the method based on two-end control variables to determine whether a child has pneumonia is 98% on average.
Data source
These chest X-ray images are selected from a retrospective cohort of pediatric patients aged 1–5 years at Guangzhou Women’s and Children’s Medical Center in Guangzhou, China. All chest X-ray images are performed as part of the patient’s routine clinical care. The Institutional Review Board (IRB)/Ethics Committee of Guangzhou Women’s and Children’s Medical Center, China, approved the data to be able to be used publicly and waived the requirement to participate in informed consent. All methods were implemented in accordance with relevant guidelines and regulations. The dataset is divided into two groups, pneumonia and normal, in which the total number of pneumonia data samples was 3883 cases and the total number of normal data samples is 1349 cases.

FedUBE
Data setting
During chest X-rays, different technologists perform each X-ray, and differences in experience give different results, which can lead to discrepancies in X-ray images. Different sensitivities of each manufacturer and brand of instruments may also lead to errors during the examination. The patient’s psychological activity and cooperation during the examination will affect the results, and all of the above situations will cause data heterogeneity, The four scenarios of data heterogeneity are shown in Fig. 4. Therefore, during the experimental process, we simulate the data to be heterogeneous and non-heterogeneous. In the experiments, the non-heterogeneous data is subject to independent identical distribution and the heterogeneous data is subject to non-independent identical distribution. In order to simulate the existence of non-independent identical distribution of real data, we use the method based on the number of user sharding, the sharding method based on the maximum number of sharding, and the centralized data sharding method to conduct experiments.
Data availability
The Institutional Review Board (IRB)/Ethics Committee of Guangzhou Women’s and Children’s Medical Center, China, approved the data to be able to be used publicly. The Institutional Review Board (IRB)/Ethics Committee of Guangzhou Women’s and Children’s Medical Center, China, also waived the requirement to participate in informed consent. The datasets utilized and/or analyzed in the current study can be found in the public Mendeley database and can be accessed via the link (https://doi.org/10.17632/rscbjbr9sj.3).
References
Pappa, S. et al. Prevalence of depression, anxiety, and insomnia among healthcare workers during the covid-19 pandemic: A systematic review and meta-analysis. Brain Behav. Immun. 88, 901–907 (2020).
Pham, H. T., Nguyen, P. T., Tran, S. T. & Phung, T. T. Clinical and pathogenic characteristics of lower respiratory tract infection treated at the Vietnam national children’s hospital. Can. J. Infect. Dis. Med. Microbiol. 2020, 1–6 (2020).
Pernica, J. M. et al. Short-course antimicrobial therapy for pediatric community-acquired pneumonia: the safer randomized clinical trial. JAMA Pediatr. 175, 475–482 (2021).
Ouyang, X. et al. Dual-sampling attention network for diagnosis of covid-19 from community acquired pneumonia. IEEE Trans. Med. Imaging 39, 2595–2605 (2020).
Duron, L. et al. Assessment of an AI aid in detection of adult appendicular skeletal fractures by emergency physicians and radiologists: a multicenter cross-sectional diagnostic study. Radiology 300, 120–129 (2021).
Jain, R., Gupta, M., Taneja, S. & Hemanth, D. J. Deep learning based detection and analysis of covid-19 on chest x-ray images. Appl. Intell. 51, 1690–1700 (2021).
Liang, H. et al. Children’s pneumonia diagnosis system based on Mach–Zehnder optical fiber sensing technology. Int. J. Biomed. Eng. 207–212 (2022).
Masud, M. et al. A pneumonia diagnosis scheme based on hybrid features extracted from chest radiographs using an ensemble learning algorithm. J. Healthc. Eng. 2021 (2021).
Effah, C. Y. et al. Machine learning-assisted prediction of pneumonia based on non-invasive measures. Front. Public Health 10, 938801 (2022).
Sarker, I. H. Deep learning: a comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2, 420 (2021).
Wu, X. et al. A novel centralized federated deep fuzzy neural network with multi-objectives neural architecture search for epistatic detection. IEEE Trans. Fuzzy Syst. (2024).
Rajpurkar, P. et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv preprint arXiv:1711.05225 (2017).
Kundu, R., Das, R., Geem, Z. W., Han, G.-T. & Sarkar, R. Pneumonia detection in chest x-ray images using an ensemble of deep learning models. PLoS One 16, e0256630 (2021).
Varshni, D., Thakral, K., Agarwal, L., Nijhawan, R. & Mittal, A. Pneumonia detection using CNN based feature extraction. In 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT) 1–7 (IEEE, 2019).
Nithya, T., Kanna, P. R., Vanithamani, S. & Santhi, P. An efficient pm-multisampling image filtering with enhanced CNN architecture for pneumonia classification. Biomed. Signal Process. Control 86, 105296 (2023).
Piccialli, F., Di Somma, V., Giampaolo, F., Cuomo, S. & Fortino, G. A survey on deep learning in medicine: Why, how and when?. Inf. Fusion 66, 111–137 (2021).
Hu, K. et al. Federated learning: a distributed shared machine learning method. Complexity 2021, 1–20 (2021).
Wu, X., Wang, H., Shi, M., Wang, A. & Xia, K. DNA motif finding method without protection can leak user privacy. IEEE Access 7, 152076–152087 (2019).
Zhao, Z., Yang, F. & Liang, G. Federated learning based on diffusion model to cope with non-iid data. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 220–231 (Springer, 2023).
Li, T. et al. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2, 429–450 (2020).
Karimireddy, S. P. et al. Scaffold: Stochastic controlled averaging for federated learning. In International Conference on Machine Learning 5132–5143 (PMLR, 2020).
Lee, G., Jeong, M., Shin, Y., Bae, S. & Yun, S.-Y. Preservation of the global knowledge by not-true distillation in federated learning. Adv. Neural. Inf. Process. Syst. 35, 38461–38474 (2022).
Shoham, N. et al. Overcoming forgetting in federated learning on non-iid data. arXiv preprint arXiv:1910.07796 (2019).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25 (2012).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Konečnỳ, J., McMahan, H. B., Ramage, D. & Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv preprint arXiv:1610.02527 (2016).
Liu, Q., Chen, C., Qin, J., Dou, Q. & Heng, P.-A. Feddg: Federated ___domain generalization on medical image segmentation via episodic learning in continuous frequency space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 1013–1023 (2021).
Kuo, K. M., Talley, P. C., Huang, C. H. & Cheng, L. C. Predicting hospital-acquired pneumonia among schizophrenic patients: a machine learning approach. BMC Med. Inform. Decis. Mak. 19, 1–8 (2019).
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural. Inf. Process. Syst. 33, 6840–6851 (2020).
Morafah, M., Reisser, M., Lin, B. & Louizos, C. Stable diffusion-based data augmentation for federated learning with non-iid data. arXiv preprint arXiv:2405.07925 (2024).
Singh, A., Shalini, S. & Garg, R. Classification of pediatric pneumonia prediction approaches. In 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence) 709–712 (IEEE, 2021).
Lissaman, C. et al. Prospective observational study of point-of-care ultrasound for diagnosing pneumonia. Arch. Dis. Child. 104, 12–18 (2019).
Chattopadhyay, S., Kundu, R., Singh, P. K., Mirjalili, S. & Sarkar, R. Pneumonia detection from lung x-ray images using local search aided sine cosine algorithm based deep feature selection method. Int. J. Intell. Syst. 37, 3777–3814 (2022).
Kumar, G. S. et al. Differential privacy scheme using laplace mechanism and statistical method computation in deep neural network for privacy preservation. Eng. Appl. Artif. Intell. 128, 107399 (2024).
Kumar, G. S., Premalatha, K., Maheshwari, G. U. & Kanna, P. R. No more privacy concern: A privacy-chain based homomorphic encryption scheme and statistical method for privacy preservation of user’s private and sensitive data. Expert Syst. Appl. 234, 121071 (2023).
Zhu, L., Liu, Z. & Han, S. Deep leakage from gradients. Adv. Neural Inf. Process. Syst. 32 (2019).
Dwork, C. Differential privacy. In International Colloquium on Automata, Languages, and Programming 1–12 (Springer, 2006).
Ogburn, M., Turner, C. & Dahal, P. Homomorphic encryption. Proc. Comput. Sci. 20, 502–509 (2013).
Goldreich, O. Secure multi-party computation. Manuscript. Preliminary version. 78, 1–108 (1998).
Acknowledgements
We are grateful for the fnancial support from the Zhejiang Provincial Key Research and Development Program Project (Grant 2021C03145), National Natural Science Foundation of China (Grant 61972358), A Project Supported by Scientific Research Fund of Zhejiang University, Zhejiang (Grant Y202454344) and Natural Science Foundation of Zhejiang Province, China (Grant LQ20F020010). Also, the authors would like to extend their appreciation to Zhejiang University of Science and Technology for its supervision support.
Author information
Authors and Affiliations
Contributions
Z.P. and H.W. conceived of the idea and designed this research; Z.P. and J.W. conducted the simulations; L.Z., and J.H. analyzed data; Z.P. wrote the draft; and Z.P. and Y.S. revised the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Pan, Z., Wang, H., Wan, J. et al. Efficient federated learning for pediatric pneumonia on chest X-ray classification. Sci Rep 14, 23272 (2024). https://doi.org/10.1038/s41598-024-74491-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-74491-5
