
Abstract
This study aimed to construct a high-performance prediction and diagnosis model for type 2 diabetic retinopathy (DR) and identify key correlates of DR. This study utilized a cross-sectional dataset of 3,000 patients from the People’s Liberation Army General Hospital in 2021. Logistic regression was used as the baseline model to compare the prediction performance of the machine learning model and the related factors. The recursive feature elimination cross-validation (RFECV) algorithm was used to select features. Four machine learning models, support vector machine (SVM), decision tree (DT), random forest (RF), and gradient boost decision tree (GBDT), were developed to predict DR. The models were optimized using grid search to determine hyperparameters, and the model with superior performance was selected. Shapley-additive explanations (SHAP) were used to analyze the important correlation factors of DR. Among the four machine learning models, the optimal model was GBDT, with predicted accuracy, precision, recall, F1-measure, and AUC values of 0.7883, 0.8299, 0.7539, 0.7901, and 0.8672, respectively. Six key correlates of DR were identified, including rapid micronutrient protein/creatinine measurement, 24-h micronutrient protein, fasting C-peptide, glycosylated hemoglobin, blood urea, and creatinine. The logistic model had 27 risk factors, with an AUC value of 0.8341. A superior prediction model was constructed that identified easily explainable key factors. The number of correlation factors was significantly lower compared to traditional statistical methods, leading to a more accurate prediction performance than the latter.
Similar content being viewed by others
Introduction
The global prevalence of diabetes is increasing rapidly, with estimates suggesting that by the year 2045, around 48% of the world’s population will be affected by the disease1. Predominantly, over 90% of these cases will have type 2 diabetes2. Retinopathy, a prevalent and severe complication of diabetes, is currently the leading cause of blindness worldwide and significantly affects the quality of life of patients3. Research indicates that retinopathy occurs in 20%‒45% of diabetic cases4. In China, the overall prevalence of diabetes reached 14.92% between 2015 and 2021, with retinopathy complicating 22.4% of these cases5.
Scientific research consistently validates that identifying the key factors contributing to the development of diabetic retinopathy (DR) in patients with type 2 diabetes is a pivotal research focus, facilitating early prevention and treatment. Historically, research on DR prediction focused on image analysis6, the screening of DR risk factors using chi-square tests and t-tests, and the development of logistic regression analysis models. However, given the large sample size of type 2 diabetes clinical data, numerous influencing factors, and the risk of uneven sample distribution due to missing and redundant information, there are limitations to relying solely on the use of traditional statistical methods. For instance, it may lead to underfitting, diminished accuracy, and ineffective management of numerous features or variables7,8. Recently, machine learning algorithms have been extensively applied to assist clinicians in swiftly and accurately diagnosing and predicting DR 9,10. These algorithms primarily comprise traditional machine learning models (CML) and neural network (NN) based algorithms11. Despite the extensive research into machine learning algorithms for predicting DR and screening relevant factors, there remains ample scope for enhancing feature selection methods, identifying hyperparameters to improve model performance, and analyzing the significant impact of each feature on the outcome along with complex interactions between features.
In this study, we presented a concept for constructing, interpreting, and comparing machine learning models for DR prediction and the screening of significant correlates for clinical DR prevention and treatment.
This study was approved by the Medical Ethics Committee of Mudanjiang Medical University with the approval number 2022-MYSZR15 before it was conducted. The study followed all relevant ethical guidelines and regulations to ensure the rights and safety of participants.
Methods
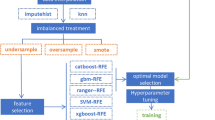
Our study comprised four phases: data pre-processing, model construction, significant correlated feature screening, model interpretation, and the comparison between traditional statistical methods and machine learning models. This study aimed to investigate factors influencing the accuracy of DR diagnosis and screening for significant risk factors. These factors can be outlined as follows: (1) identifying whether all attributes can act as significant predictive features; (2) determining if there are more suitable machine learning models; (3) verifying the importance of correlates screened by the model as crucial risk factors with DR predictive and diagnostic value; (4) examining how these significant risk factors affect the predictive outcomes of models; (5) understanding the benefits of machine learning models over traditional statistical models. Figure 1 graphically illustrates this concept of the study.

The research work process.
Data sources
We utilized the "Diabetes Complication Early Warning Dataset of the General Hospital of the Chinese People’s Liberation Army," which was published by China’s National Population Health Science Data Centre. The study includes 3,000 diabetic patients, divided evenly into 1,500 cases with DR complications and 1,500 cases without such complications. This dataset contains 86 variables, as indicated in Supplementary Table 1.
Data pre-processing
(1) Handling Missing Values: In the dataset, 52 of the 86 features had missing values. Thirteen features, including HEART_RATE (Heart rate), (GLU_2H) 2-h postprandial blood glucose, UPR_24 (Twenty-Four Hours Urinary Protein), UCR (Urine creatinine), CP (C-peptide), INS (Insulin), ESR (Erythrocyte sedimentation rate), LP_A (Lipoprotein-A), PL (Phospholipid), FIBRIN (Fibrin), M1_M2 (M1 macrophages and M2 macrophages), TH2 (T helper 2 cell), and BUN (Blood urea nitrogen), exhibited missing values exceeding 50%. However, except for BUN, all other features were retained due to their significant impact on the study. Upon observing these 12 retained features, the prevalence of DR was determined to be 50.3%, 66.8%, 75.9%, 76.5%, 72.7%, 68.9%, 60.7%, 20.2%, 54.3%, 30.4%, 25%, 35.7%, and 0%. Consequently, BUN was excluded, leaving the remaining 12 features that impacted the study intact.
Categorical feature values were filled with the mode, and continuous eigenvalues were filled with the mean12,13. There were 51 continuous features in the dataset, of which 48 features had missing values, and the number of missing values for 30 features accounted for less than 10% of the overall data. The "Blood urea nitrogen" column was empty, so we deleted it. The number of missing values for the remaining 17 consecutive features accounted for more than 10% of the overall number, and the mean filling method was also used. In subsequent studies, we considered using more complex data imputation methods (such as multiple imputation, model-based methods, etc.) to further improve the data processing. There are 35 category features in this dataset, among which only 1 feature has missing value, and the number of missing values accounts for 0.67% of the total sample number. We used the mode to fill the missing value, which can better reflect the central trend of the data.
(2) Data Normalization: In the Python 3.7.0 programming environment, we utilized Scikit-learn’s Min-Max Scalar to scale the continuous-type feature variables, resulting in data values within the [0,1] interval. This normalization process unified the dimensions of each feature, improved the performance of the model, accelerated the calculation speed, and enhanced the interpretability of the model. This method enabled us to mine the valuable information in the data more efficiently and accurately in the subsequent data analysis and model training process.
Statistical perspective
We used Statistical Package for Social Sciences (version 26.0) for statistical analysis. When comparing the indicators between the two groups of patients, we expressed counting data as percentages (%). The quantitative data were described as "mean ± standard deviation" in the case of a normal distribution and as "median (interquartile spacing)" for a non-normal distribution. Logistic analysis was used to correlate factors following the idea of "single first, then multiple," with p < 0.05 deemed statistically significant. The logistic classification model was used to evaluate R4.2.2. The statistically significant variables in the univariable logistic regression analysis were first included in the logistic regression model to derive the correlates of DR and the AUC values of the model.
Machine learning model and feature selection
In this study, we employed SVM, DT, RF, and GBDT machine learning algorithms, which are commonly used in diabetes-related research for binary classification problems, to construct the model14,15,16,17. The recursive feature elimination cross-validation (RFECV) algorithm was used to select features from the pre-processed dataset. RFECV underwent multiple training cycles, each time removing the least important features from the current feature set. The algorithm validated the performance of different feature combinations through cross-validation. RFECV directly optimizes for a given model, typically identifying a feature subset with superior classification performance and better model generalization capabilities.
Partitioning of training, testing, and external validation sets
To enhance the ability of the four machine learning models to generalize and prevent overfitting, the dataset was divided into three parts: a training set, a verification set, and a test set. Typically, 50% of the samples were used as a training set to fit the model, while 25% of the samples were used as a verification set to estimate the prediction error and provide a basis for model selection. The remaining 25% of the test set was used to assess the generalization error of the final selected model.
Machine learning model optimization
In this investigation, we determined the optimal values for the machine learning algorithm by tuning the hyperparameters of the model. This approach provided superior performance compared to using default parameters. To reduce memory overhead and runtime, we only tuned hyperparameters that substantially contributed to the classification performance of the model.
Performance metrics
In this research, diabetic patient samples with DR were classified as the positive class, while the samples without DR (NDR) were classified as the negative class. The trained machine learning model was employed to make category predictions on the test set, deriving accuracy, precision, F1-measure, sensitivity, and AUC values. Additionally, receiver operating characteristic (ROC) curves were plotted.
Comprehensive analysis of modelling features and model validation
In our evaluation of models using six metrics (accuracy, precision, recall, F-measure, and area under the curve(AUC) value, it was found that the GBDT model demonstrated outstanding performance across all indicators. By analyzing the features used in developing these models, we determined key correlates associated with the occurrence of DR through voting. We used the selected classifiers to predict and assess DR classification for a subset of data containing these features.
Interpretability of classifiers SHAP
Machine learning models often have better predictive accuracy than traditional statistical linear models and are well suited to complex real-world behavior. However, they may lack the interpretability of linear models and are often labeled as ‘black box’ models. In this investigation, we used the shapley additive explanations (SHAP)18,19 method, proposed by Professor Lloyd Shapley of the University of California, Los Angeles (UCLA). This method provides local explanations for the machine learning model predictions, allowing us to identify non-linear interaction effects. The SHAP method has been valuable in discovering new insights in research related to human health, environmental issues20, and socio-economic issues21. This method has allowed us to derive significant correlations between modeling features on predicted outcomes and interactions between features. This enabled us to clearly explain the mechanisms by which the important correlates derived in this study affect DR patients.
Ethics approval and consent to participate
All research methods were conducted in compliance with relevant guidelines and regulations. Ethical approval was secured from the Institutional Review Board (approval number: 2022-MYSZR158). Informed consent was acquired from all participants and/or their legal guardians, and strict confidentiality was maintained throughout the study.
Results
Comparison of DR and NDR metrics
Table 1 presents a comparison of DR and NDR metrics within the dataset, showing that a comparison of 85 features between the DR Group and the NDR Group found 61 features to be statistically significant.
There were 31 features in the DR Group that were lower than those in the NDR gro-up (P < 0.05), 28 of which were statistically significant, and they were:AGE (Age), MEN (Men), HB (HB), UCR (Urine creatinine), CP (C-peptide), INS (Insulin), PCV (Packed cell volume), and TBILI (Total bilirubin), DBILI(Direct bilirubin), TP (Total protein), ALB (Albumin), ALT (Alanine transaminase), AST (Aspartate transaminase), GGT (Glutamyl transpeptadase), ALP (Alkaline phosphatase), LP_A (Lipoprotein-A), and PT (Prothrombin time), CRP (C-reactive protein), IBILI (Indirectbilirubin), GLO (Globulin), HYPERTENTION (Hypertension), CEREBRAL_APOPLEXTY (Cerebral apoplexty), and FLD (Fatty liver disease), NEPHROPATHY (Nephropathy), RENAL_FALIURE (Renal faliure), LEADDP (Lower extremity arterial disease), HEMATONOSIS (Hematonosis), ENDOCRINE_DISEASE (Endocrine disease), MEN(Men), ALP (Alkaline phosphatase), and FLD (Fatty liver disease) were statistically significant.
There were 30 features in the DR Group that were higher than those in the NDR group (P < 0.05), among which the following 25 features were statistically significant: BP_HIGH (Systolic blood pressure), BP_LOW (Diastolic blood pressure), GLU (Glucose), GLU_2H (2-h postprandial blood glucose), HBA1C (Glycated hemoglobin A1c), GSP (Glycosylated serum protein), TC (Total cholesterol), LDL_C (Low density) lipoprotein cholesterol, FBG (Fibrinogen), BU (Blood urea), SCR (Serum creatinine), SUA (Serum urea), LDH_L (Lactate dehydrogenase), PTA (Prothrombin activity), ALB_CR (Urinary albumin/creatinine ratio), LPS (Lipase), CA199 (Carbohydrate antigen 199), HYPERLIPIDEMIA (Hyperlipidemia), CHD (Coronary heart disease), MI (Myocardial infarction), RHEUMATIC_IMMUNITY (Rheumatic immunity), DIGESTIVE_CARCINOMA (Digestive carcinoma), UROLOGIC_NEOPLASMS (Urologic neoplasms), GYNECOLGICAL_TUMOR (Gynecolgical tumor), LUNG_TUMOR (Lung tumor), OTHER_TUMOR (Other tumor), GLU (Glucose) and GSP (Glycosylated serum pro-tein), LPS (Lipase), RHEUMATIC_IMMUNITY (Rheumatic_immunity), UROLOGIC_NEOPLASMS (Urologic neoplasms) were statistically significant.
Risk factors
The results from both univariable and multivariable logistic analyses were statistically significant, with p < 0.05, as illustrated in Table2. A total of 27 features were identified as correlates affecting DR.
There were 11 significant positive associations with DR, namely: HBA1C (Glycated hemoglobin A1c), NEPHROPATHY (Nephropathy), BP_HIGH(Systolic blood pressure), CEREBRAL_APOPLEXTY(Carotid artery stenosis), CHD (Coronary heart disease), ENDOCRINE_DISEASE(Endocrine disease), GLU_2H(2-h postprandial blood glucose), BU (Blood urea) and ALB_CR(Urinary albumin/creatinine ratio) were consistent with the existing studies22,23,24,25,26,27,28,29.
There were 16 negative correlations, which were as follows: AGE (Age), HYPERLIPIDEMIA (Hyperlipidemia), RENAL_FALIURE (Renal faliure), LEADDP (Lower extremity arterial disease), MEN (Men), DIGESTIVE_CARCINOMA (Digestive carcinoma), GYNECOLGICAL_TUMOR (Gynecolgical tumor), LUNG_TUMOR (Lung tumor), OTHER_TUMOR (Other tumor), GLU (Glucose), UPR_24 (Twenty-Four Hours Urinary Protein), CP (C-peptide), and PCV (Packed cell) volume, ESR (Erythrocyte sedimentation rate), Prothrombin time (PT), and CRP (C-reactive protein).Among these factors, CP as a protective factor is consistent with existing studies29, while the increase of the remaining 15 factors decreases the risk of DR, which may be caused by some specific circumstances, sample selection bias or other unknown confounding factors, requiring further verification and research.
Feature selection analysis
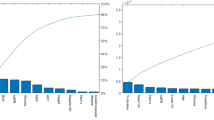
An iterative method revealed that retaining a specific number of features during a 3-fold cross-validation (CV) with RFECV improves the predictive performance of the model. The CV scores for four models, each with a different number of features, are provided in Supplementary Table 2, and Fig. 2. The optimal number of features for modeling corresponds to the highest score, which can be used to derive the most relevant features. Each machine learning model utilizes these optimal features (i.e., features with an importance rating of 1, as illustrated in Supplementary Fig. 1) to create a new data subset.

Feature selection cross-verifies the score curve.
Hyperparameters
We utilized the GridSearch CV and cross-validation features from the model selection module of Sklearn to assess all possible combinations of discrete hyperparameters in LR, SVM, DT, RF, and GBDT models. This method enabled us to identify the hyperparameter set yielding the highest cross-validation accuracy, which is the subset delivering the best performance (Supplementary Table 3).
Comparison of prediction model performance
We utilized the four trained machine learning models and LR model to make category prediction on the test set, and obtained the correct number of positive samples (TP), incorrect number of negative samples (FN), incorrect number of positive samples (FP) and correct number of negative samples (TN) as shown in Table 3 according to the prediction results.
Key evaluation metrics for each model, including accuracy, precision, sensitivity, F1 value, and AUC value, were generated from testing on the test set (Table 4). The RF and GBDT models outperformed the SVM, DT and LR models in predictive accuracy, with the GBDT model demonstrating the highest accuracy, precision, F1-measure, and AUC value. Figure 3 illustrates the ROC curves for all models, indicating that our optimized machine-learning models hold practical value as the areas under the ROC curves for all models exceed 0.75.

ROC curve.
Comprehensive feature selection and model validation
Supplementary Figs. 1 and 2 depict that among the 85 features analyzed, glycosylated hemoglobin (HBA1C), twenty-four hours urinary protein (UPR_24), serum creatinine (SCR), urinary albumin/creatinine ratio (ALB_CR), blood urea (BU), and c-peptide (CP) are considered critical and relevant factors for DR. A GBDT model was used to analyze the data subset characterized by these factors, resulting in an accuracy of 0.7883 and an AUC of 0.8672. The logistic model, resulting in an accuracy of 0.7733, yielded an AUC value of 0.8341.
SHAP analysis results
Impact of each significant correlate on DR prediction
The SHAP swarm plot (Supplementary Fig. 3a) and violin plot (Supplementary Fig. 3b) provide a comprehensive understanding of how each correlate influences the prediction results. The bar chart displaying the absolute values of SHAP values (Supplementary Fig. 3c) demonstrates the impact of six correlates on the predictive performance of the DR classifier. SHAP dependency plots are utilized to illustrate the effect of each feature on the prediction results (Fig. 4).

Scatter dependence graph of six important factors related to the occurrence of DR. (a) SHAP dependence plot of CP. (b) SHAP dependence plot of SCR. (c) SHAP dependence plot of BU. (d) SHAP dependence plot of ALB_CR. (e) SHAP dependence plot of HBAIC. (f) SHAP dependence plot of UPR_24.
Explanation of feature interactions
The SHAP interaction diagram reveals the impact of interactions between two features on DR prediction (Supplementary Fig. 4). A more detailed analysis of the combined impact of these features on DR prediction is presented in Fig. 5.

SHAP interaction plot of Pairwise factor.
Discussion
Key findings
Comparison of LR model and machine learning models in the analysis of DR related factors
Based on four machine learning models, we identified six key factors related to DR. They were ALB_CR (Urinary albumin/creatinine ratio), UPR_24 (Twenty-Four Hours Urinary Protein), CP (C-peptide), HBA1C (Glycated hemoglobin A1c), BU(Blood urea), and SCR (Serum creatinine). The LR model found 27 related factors, These are HBA1C (Glycated hemoglobin A1c), NEPHROPATHY (Nephropathy), and BP_HIGH (Systolic blood pressure), CEREBRAL_APOPLEXTY (Carotid artery stenosis), CHD(Coronary heart disease), ENDOCRINE_DISEASE(Endocrine disease), GLU_2H (2-h postprandial blood glucose), BU(Blood urea), HB(Hemoglobin), ALB_CR(Urinary albumin/creatinine ratio), AGE (Age), HYPERLIPIDEMIA (Hyperlipidemia), RENAL_FALIURE (Renal faliure), LEADDP (Lower extremity arterial disease), MEN(Men), DIGESTIVE_CARCINOMA (Digestive carcinoma), GYNECOLGICAL_TUMOR (Gynecolgical tumor), LUNG_TUMOR (Lung tumor), OTHER_TUMOR (Other tumor), GLU (Glucose), UPR_24 (Twenty-Four Hours Urinary Protein), CP (C-peptide), and PCV (Packed cell) volume, ESR (Erythrocyte sedimentation rate), PT (Prothrombin time), CRP (C-reactive protein), among the 27 relevant factors, five factors were found by machine learning models.
From the above results, we can find that machine learning models such as GBDT can automatically learn from a large number of features and identify the most important factors, which is easier for doctors or researchers to pay attention to and interpret. The LR model identified 27 disease-related factors, which may contain some redundant or less important factors, failing to identify the most critical factors as accurately as the GBDT, but providing a more comprehensive picture of disease-related factors.
Although machine learning models such as GBDT are often better than LR statistical models in terms of prediction performance and can identify key factors, the internal working mechanism of the models is complex and not as intuitive and easy to understand as LR models. This paper adopts SHAP feature importance analysis method to understand which features contribute more to the prediction results and how they affect the prediction results. The interpretability of GBDT is increased.
Significant contributions in model development
Presently, there are two main categories of machine learning-based DR prediction models. The first category of DR prediction models is constructed on the foundation of fundus images. For instance, a study conducted by Indian researchers proposed a multi-path convolutional neural network (CNN) and a machine learning classifier for DR to analyze 36,769 fundus images for model development and validation. Post-feature extraction using the M-CNN approach, machine learning classifiers such as SVM, RF, and DT were employed to classify the images into various categories, achieving a DR prediction accuracy exceeding 90%30. Casanova et al. utilized graded fundus photography and systematic data from 3,443 participants in the ACCORD-Eye study, employing double cross-validation to estimate RF and logistic regression, resulting in a DR prediction accuracy of 75%31. Despite their high performance, these models are mainly used in a few developed countries due to the requirement of specialist ophthalmologists and costly medical equipment32. Numerous developing countries are currently unable to utilize these models for DR screening.
The second category of DR prediction models relies on physiological and biochemical indicators to determine characteristic values. These models primarily use demographic data, medical history, and test results. Most published studies utilize SVM, artificial neural networks (ANN), RF, logistic regression, and decision trees for DR predictive classification. For example, Tsao et al. compared the performance of four machine learning algorithms using 10 features on 536 diabetic patients, employing a fivefold cross-validation. Their findings indicated that SVM achieved 79.5% accuracy in DR classification, outperforming decision trees, artificial neural networks, and logistic regression33. Yao et al. used 530 Chinese residents (including 423 type 2 diabetic patients) as their study population and utilized univariable and multivariable logistic regression (MLR) to analyze the correlation between DR and biochemical metabolic parameters. Based on the MLR results, they developed a Back Propagation Artificial Neural Network (BP-ANN) model to classify the 423 patients, revealing that the AUC values of the BP-ANN model surpassed those of the MLR model (0.84 vs. 0.77)34.
A recent investigation, using data from the Korean National Health and Nutrition Examination Survey (KNHANESV-1 and KNHANESV-2 databases), compared learning models like ridge, elastic net, and LASSO with conventional DR indicators. The LASSO-based sparse learning model demonstrated an AUC of 0.82 and an accuracy of 75.2%, proving effective in predicting DR. Furthermore, Blighe et al. undertook an environment-wide association study using NHANES data, analyzing over 400 laboratory parameters linked to DR for predictive purposes. They employed parallel univariable regression models, principal component analysis (PCA), penalized regression, and Random Forest for the selection of independent variables (features). The RF model outperformed the others, with an AUC of 0.8435.
In comparison to other studies, our research has shown several improvements. First, given the large number of features in the dataset, we employed recursive feature elimination for iterative model construction. This method eliminates irrelevant and redundant dimensions from the 85 features, retaining only those that are beneficial for learning classification. This approach addresses the issues of overfitting, memory consumption, and time overhead of the model while avoiding the subjectivity, inaccuracy, and unstable results that might be introduced by traditional dimensionality reduction approaches. Second, we explored the performance of four machine learning classification models with hyperparameter optimization and selectively constructed the GBDT model. This model showcases high adaptability across various data types and outperforms other data mining techniques in medical tasks for classification prediction. The application of GBDT in DR classification has not been documented in existing literature. Third, when compared to the classical logistic regression model, our model successfully identified six correlated factors for DR with an AUC value of 0.8672. Conversely, the logistic regression model identified 28 correlated factors but achieved a lower AUC value of 0.8341. This demonstrates the superiority of our model in terms of both the number of correlated factors and the classification prediction accuracy.
Examination of influential factors
This research identified ALB_CR (Urinary albumin/creatinine ratio), UPR_24 (Twenty-Four Hours Urinary Protein), BU (Blood urea), HBA1C (Glycated hemoglobin A1c), SCR (Serum creatinine), and CP (C-peptide) as significant correlates of DR, with six pairs of factors demonstrating some interactive effect on the prevalence of DR.
ALB_CR and UPR_24 are commonly used to measure micro-urinary protein levels. The presence of proteinuria, an essential marker of damage to the vascular endothelial system, often indicates widespread microangiopathy in the body36. Studies by Li Rui and Li Meifang suggested that diabetic patients with proteinuria had a higher incidence of DR compared to those without proteinuria. They reported a relative risk of 2.638 for the group with microproteinuria (i.e., higher ALB_CR, UPR_24) and 2.702 for the group with substantial albuminuria, thus concluding that microprotein was closely associated with the development of DR37,38.
Research conducted by Huang Shufang, Ai Wei, and Fan Ruilei suggests that increased levels of micro-urinary protein indicate an independent risk factor for DR. They proposed that testing for micro-urinary protein can serve as a predictive tool for the progression of DR, enabling early detection of diabetic microangiopathy and reducing the incidence of DR through timely clinical intervention39,40,41. The findings of this study are consistent with the SHAP fovea and dependency plots, where elevated ALB_CR and UPR_24 were significantly associated with DR. Furthermore, a notable rise in the incidence of DR was observed with increased ALB_CR levels compared to UPR_24.
Serum creatinine (SCR) is a byproduct of meat consumption and muscle tissue metabolism. Variations in SCR concentrations are primarily determined by the glomerular filtration rate (GFR) and the filtering capacity of the kidneys. Elevated SCR levels often signify kidney damage, although they are insensitive indicators of kidney parenchymal damage. Extensive renal damage affecting more than half of the kidney can lead to an increase in SCR. However, SCR levels do not indicate an early or mild decline in renal function. Conversely, our research revealed a significantly higher risk of DR development when SCR levels exceeded 0.02 (60 μM/L before data pre-processing), even within the normal value range (44‒133 μM/L). Therefore, monitoring SCR within the normal range can aid in the early detection of DR rather than raising concerns only when SCR levels exceed normal values. Studies have demonstrated a statistically significant difference in SCR levels between DR and NDR groups (p < 0.05)42,43, proving SCR as an independent risk factor for DR. Individuals with SCR levels exceeding 133 mM/L are 2.006 times more likely to develop DR than those with normal SCR44.
Blood urea (BU) is the primary end product of protein metabolism and is removed from the body through glomerular filtration. Research conducted by Wang Yangzhong, Liu Hongfang, and Ma Yue has revealed that BU levels were significantly higher in the DR group compared to the non-DR group, demonstrating a statistically significant difference (p < 0.05). BU levels in type 2 diabetic patients were associated with DR development45. The SHAP plot results from our study depicted that as BU levels increased, there was a shift from suppression to promotion in the model, predicting a positive result. When the BU index exceeded 0.15 (5 mM/L before data pre-processing), the proportion of DR patients significantly increased, corroborating with the findings of Song Yanan et al46.
UPR_24, ALB_CR, SCR, and BU are key renal function indicators closely associated with DR risk. This might be attributed to the similar characteristics between the kidney and retina, such as their origin, development, capillary network structure, and filtration barrier function47. DR and renal disease may share multiple pathogenic mechanisms. DR development could be influenced by activation of the renin-angiotensin system, impairment of renal function, and genetic, hemodynamic, and lipid metabolism48. Moreover, pathogenesis may involve the accumulation of glycosylation end products, activation of the polyol pathway, oxidative stress, growth factors, endoplasmic reticulum stress, inflammatory mediators, and complement activation49.
HBA1C reflects not only blood glucose control over time but also plays a role in DR onset and progression. Chronic high blood glucose levels are the primary DR development catalyst. In vivo and in vitro studies have demonstrated that high glucose levels induce pericyte apoptosis50. Pericytes provide structural support to capillaries; their loss can lead to localized bulging of capillary walls, contributing to microaneurysm formation, which is the earliest DR clinical sign51. Poor glycemic control may increase DR risk. Higher levels of HbA1c in diabetic patients can exacerbate vessel wall damage and capillary occlusion through increased aggregation of erythrocytes, potentially causing tissue ischemia and hypoxia, which can trigger retinal metabolic disorders52. Our analysis of the SHAP plot data revealed a strong correlation between HBA1C and DR. The DR prevalence risk increased when HBA1C exceeded 7% and also dropped below 6%. As HBA1C values decreased, the resistance to DR prevalence decreased as well, thus elevating the likelihood of DR prevalence, consistent with previous studies53. However, this does not imply that lower glycosylated hemoglobin is always beneficial for diabetic patients. Glycosylated hemoglobin levels maintained below 6% have been associated with increased hypoglycemic episodes and higher mortality. Therefore, it is essential to maintain control over glycosylated hemoglobin. Some scholars recommend maintaining glycosylated hemoglobin levels between 6.5% and 7% for optimal management54.
C-peptide (CP) serves as an indicator of the body’s insulin secretion level and is a reliable gauge of the reserve function of pancreatic islet cells. Numerous domestic and international studies have revealed that CP, an active hormone, specifically binds to endothelial cells in a stereotactic manner. In a high-glucose environment, it stimulates Na+-K+-ATPase on the cell membrane surface of endothelial cells, inhibits nuclear factor-kb, and activates endothelial-type nitric oxide synthase, leading to improved blood flow and vascular permeability within the retinal vasculature55. Furthermore, in diabetic patients, C-peptide activates AMP-activated protein kinase alpha to inhibit intracellular reactive oxygen species-mediated endothelial apoptosis, thereby improving endothelial dysfunction56. A study by Bo et al. observed that the lowest fasting CP levels in type 2 diabetic patients correlated with the highest incidence of DR at baseline and at follow-up, while the risk of retinopathy in diabetic patients negatively correlated with the highest fasting CP levels55. A study by Wang et al. (2018) categorized four different groups (Q1, Q2, Q3, and Q4) based on fasting CP levels57. The results indicated a progressive decrease in the prevalence of DR as fasting CP levels increased. The results of our SHAP plot also confirmed CP as a protective factor against DR. A lower CP value correlated with a higher likelihood of DR, whereas an increase in CP value significantly decreased the likelihood of DR.
The SHAP plot results in this study revealed a significant potential interaction between six pairs of characteristics ‒ UPR_24 and ALB_CR, BU and ALB_CR, CP and ALB_CR, HBA1C and UPR_24, CP and UPR_24, and HBA1C and BU ‒ on the prevalence of DR. Particularly, the interaction between UPR_24 and ALB_CR became evident at lower ALB_CR values. The risk of developing DR increased with increasing UPR_24 levels. BU exhibited a partial interaction with ALB_CR, with changes in BU non-significantly affecting the predicted outcome, but diabetic patients with lower ALB_CR values had a higher risk of developing DR. Moreover, CP displayed interactions with ALB_CR in patients with both higher and lower CP values, influencing the risk of DR. The difference in DR risk linked to UPR_24 was dependent on HBA1C levels, with higher HBA1C levels increasing the risk of DR at lower UPR_24 values. In the interaction between HBA1C and BU, the probability of DR was increased when the HBA1C value was below 7% and the BU value was higher. Conversely, if the HBA1C value exceeded 7%, the likelihood of DR increased even with a lower BU value. These interactions suggest that paying careful attention to one indicator while testing another could provide a more comprehensive prediction of DR. Furthermore, this conclusion offers a new research direction for the pathological mechanism of DR in patients who maintain good control of one indicator.
Limitations and outlook
Despite the improvements and novel findings in this study, several limitations persist: (1) Our study used a dataset of 3000 records, which is a relatively small sample size, limited to only Chinese patients. It is recommended that the scope of the study be broadened to include diabetic populations from multiple countries, thus allowing our model to predict and diagnose DR more comprehensively. (2) Numerous fields in the sample had missing data, and filling them with mean values introduces a certain level of error, consequently affecting the predictive performance of our model. Future research should consider using cluster interpolation and model interpolation to reduce this error and select a dataset with fewer missing values. (3) The duration of the disease was not included in our data, which has a significant correlation with DR. Hence, future data collection should include the duration of patients’ diseases58,59. (4) The understanding of the impact of the interaction of two characteristics on DR prediction remains in the exploratory stage, with limited literature supporting most of these interactions. Future research should further investigate these potential interactions and their implications for DR prediction and management.
Data availability
The data supporting the findings of this study are freely available from the National Population Health Sciences Data Center data warehousing PHDA. Its website is https://www.ncmi.cn//phda/dataDetails.do?id=CSTR:A0006.11.A0005.201905.000282.
References
Khan, R. M. M. et al. From pre-diabetes to diabetes: Diagnosis, treatments and translational research. Medicina (B Aires) 55(9), 546 (2019).
Li, J. Y. et al. An eye in a culture dish: Ocular organoids and their application. Yan Ke Xue Bao 37(02), 100–110 (2022).
Zhang, F. F. Risk factor analysis of type 2 diabetes mellitus complicated with diabetic retinopathy. Electron. J. Clin. Med. Lit. 6(42), 25–28 (2019).
Deng, Y. X. et al. Meta-analysis of the prevalence of diabetic retinopathy in China. Natl. Med. J. China 100(48), 3846–3852 (2020).
Calderon, G. D. et al. Oxidative stress and diabetic retinopathy: Development and treatment. Eye (Lond.) 31(8), 1–6 (2017).
Rumbold, J. M. M. et al. Big data and diabetes: The applications of big data for diabetes care now and in the future. Diabet. Med. 37(2), 187–193 (2020).
Lundberg, S. M., Lee, S. I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 4765–4774 (2017).
De Fauw, J. et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 24(9), 1342–1350 (2018).
Schüssler-Fiorenza Rose, S. M. et al. A longitudinal big data approach for precision health. NatMed 25(5), 792–804 (2019).
Nicolucci, A. et al. Prediction of complications of type 2 diabetes: A machine learning approach. Diabetes Res. Clin. Pract. 190, 110013. https://doi.org/10.1016/j.diabres.2022.110013 (2022).
Liu, L., Wang, M., Li, G., et al. Construction of predictive model for type 2 diabetic retinopathy based on extreme learning machine. Diabetes Metab. Syndr. Obes. Targets Ther. 15 (2022).
Jianliang, Y. A. N. et al. Research on establishing gastric cancer lymph node metastasis prediction model based on machine learning and routine laboratory indicators. J. Pract. Med. 40(6), 844–848 (2024).
Jiangnan. Prediction of Hemorrhagic Transformation after Intravenous Thrombolysis in Acute Ischemic Stroke Based on Machine Learning. https://doi.org/10.27162/d.cnki.gjlin.2020.007539. (Jilin University, 2021)
Probst, P. Hyperparameters, Tuning and Meta-Learning for Random Forest and Other Machine Learning Algorithms (Informatik und Statistik der Ludwig-Maximilians-Universität München, 2019).
Cristianini, N. & Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods (Cambridge University Press, 2000).
Mujeeb Rahman, K. K. Automatic screening of diabetic retinopathy using fundus images and machine learning algorithms. Diagnostics (Basel) 12(9) (2022).
Hardas, M. Retinal fundus image classification for diabetic retinopathy using SVM predictions. Phys. Eng. Sci. Med. 45(3), 781–791 (2022).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 4765–4774 (2017).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2(1), 56–67. https://doi.org/10.1038/s42256-019-0138-9 (2020).
Gu, J., Yang, B., Brauer, M. & Zhang, K. M. Enhancing the evaluation and interpretability of data-driven air quality models. Atmos. Environ. 246. https://doi.org/10.1016/j.atmosenv.2020.118125 (2021).
Guo, M., Yuan, Z., Janson, B., Peng, Y., Yang, Y. & Wang, W. Older pedestrian traffic crashes severity analysis based on emerging machine learning XGBoost. Sustainability 13(2). https://doi.org/10.3390/su13020926 (2021).
Sun, Z. Expert consensus on screening and prevention of diabetic microvascular disease for primary care. Chin. Gen. Pract. 27(32), 3969–3987 (2024).
Yan, Z. et al. Effects of levamlodipine on blood pressure control and vascular endothelial function in patients with diabetic microangiopathy and hypertension. Clin. Res. Pract. 6(1), 32–34 (2021).
Dong-rui, L. et al. Risk factors of diabetic nephropathy with retinopathy. J. Clin. Nephrol. 22(5), 370–374 (2022).
Wang, Z. et al. Exploring modern mechanism of treating diabetic retinopathy and coronary heart disease from perspective of blood stasis under viewpoint of treating different diseases with the same method. Chin. J. Exp. Tradit. Med. Formulae 30(5), 197–205 (2024).
Juanjuan, Z. et al. Prediction and evaluation modelof diabetec rectionpathy based on multiple indicators. Chin. J. Hosp. Stat. 30(6), 401–407 (2023).
Wang, J. & Chu, H. Correlation of blood glucose and glycosylated hemoglobin with lesion grading and visual impairment of patients with diabetic retinopathy. China Med. Herald. 21(13) (2024).
Xinyue, C. et al. Construction and validation of prediction model for diabetic retinopathy. Int. Eye Sci. 24(8), 1297–1302 (2024).
Zhu, E., Niu, B., Tian, L. et al. Risk factor analysis of type 2 diabetic peripheral neuropathy complicated with microangiopathy. J. Kunming Med. Univ. 45(8), 44–51 (2024).
Gayathri, S., Gopi, V. P. & Palanisamy, P. Diabetic retinopathy classifcation based on multipath CNN and machine learning classifers. Phys. Eng. Sci. Med. 44, 639–653 (2021).
Casanova, R. et al. Application of random forests methods to diabetic retinopathy classification analyses. PLoS One 9(6), e98587 (2014).
Liu, L. et al. Construction of predictive model for type 2 diabetic retinopathy based on extreme learning machine. Diabetes Metab. Syndr. Obes. 15, 2607–2617 (2022).
Tsao, H. Y., Chan, P. Y. & Su, E. C. Predicting diabetic retinopathy and identifying interpretable biomedical features using machine learning algorithms. BMC Bioinform. 19, 283 (2018).
Yao, L. et al. Multivariable logistic regression and back propagation artificial neural network to predict diabetic retinopathy. Diabetes Metab. Syndr. Obes. 12, 1943–1951 (2019).
Blighe, K. et al. Diabetic retinopathy environment -wide association study (EWAS) in NHANES 2005–2008. J. Clin. Med. 9, 1–18 (2020).
Wang, Y.-Z. & Wang, Y.-Z. Clinical analysis of correlation between renal function and occurrence of retinopathy in patients with type 2 diabetes mellitus. Int. Eye Sci. 17(1), 107–109 (2017).
Li, M. F. et al. The study of association between urinary albumin creatinine ratio and diabetic retinopathy in type 2diabetic patients. Int. J. Endocrinol. Metab. 33(1), 1–3 (2013).
Lirui. Correlation annalysis of proteinuria and retinopathy in patiens with daibetic nephropathy (Hebei Medical University, 2020).
Huang, S. et al. Microalbuminuria and incidence risk of type 2 diabetic retinopathy: A meta-analysis. Chin. Evid.-Based Nurs. 7(5), 578–584 (2021).
Ai, W., Yang, Y. H., Ruan, Y. X. et al. Discussion of the relationship between urinary albumin creatinine ratio (UACR) and diabetic retinopathy (DR) in patients with type 2 diabetes mellitus (T2DM). Chin. J. Lab. Diagn. 19(06) (2015).
Fan, R., Wei, R., Jin, P. et al. Relationship between urine microalbumin/creatinine ratio, chemokine-like receptor 1,25-hydroxycholecalciferol and diabetic retinopathy. Anhui Med. Pharm. J. 26(10) (2022).
Li, Z. Risk factors for diabetic retinopathy in patients with type 2 diabetes mellitus. J. Xiangnan Univ. (Med. Sci.) 22(01), 18–22 (2020).
Wang, Y. Z. & Liu, H. F. Clinical analysis of correlation between renal function and occurrence of retinopathy in patients with type 2 diabetes mellitus. Int. Eye Sci. 1(17), 107–109 (2017).
Zhang, H. X., Qiu, H. B. & Zhang, Y. Y. Risk factors of diabetic retinopathy. J. Mudanjiang Med. Univ. 6(43), 64–68 (2022).
Yue’e, M. & Yong, Z. Establishment of a nomogram model for predicting the risk of retinopathy in patients with diabetic nephropathy. Sichuan Med. J. 12(43), 1236–1240 (2022).
Song, Y. et al. Risk factors analysis of diabetic retinopathy based on machine learning. Acad. J. Chin. PLA Med. Sch. 42(9), 906–912 (2021).
Wong, C. W. et al. Kidney and eye diseases: Common risk factors, etiological mechanisms, and pathways. Kidney Int. 85(6), 1290–1302 (2014).
Liang, S. et al. Association of angitensin-converting inzyme gene 2350 G/A polymorphism with daibetie retinopathy in Chinese Han population. Mol. Biol. Rep. 40(1), 463–468 (2013).
Haimei, C., Li, Z. & Xiangmei, C. Advances in research on the relationship between diabetic nephropathy and diabetic retinopathy. Chin. J. Kidney Dis. Investig. (Electr. Ed.) 8(2), 85–90 (2019).
Naruse, K. et al. Aldose reductase in hibition prevents glucose-induced apoptosis in cultured bovine retinal microvascular pericytes. Exp. Eye Res. 71(3), 309–315 (2000).
Ejaz, S. et al. Importance of pericytesand mechanisms of pericyte loss during diabetes retinopathy. Diabetes Obes. Metab. 10(1), 53–56 (2008).
Fengjun, Z. et al. Recent advances in pathological mechanisms of diabetic retinopathy. Recent Adv. Ophthalmol. 36(6), 584–587 (2016).
King, P., Peacock, I. & Donnelly, R. The UK prospective diabetes study (UKPDS): Clinical and therapeutic implications for type 2diabetes. Br. J. Clin. Pharmacol. 48(5), 643–648 (1999).
Ting, D. S., Cheung, G. C. & Wong, T. Y. Diabetic retinopathy: Global prevalence, major risk factors, screening practices and public health challenges: A review. Clin. Exp. Ophthalmol. 44(4), 260–277 (2016).
Bo, S. et al. C-peptide and the risk for incident complications and mortality in type 2 diabetic patients: A retrospective cohort study after a 14-year follow-up. Eur. J. Endocrinol. 167(2), 173–180 (2012).
Lee, Y. J. et al. Essential role of transglutaminase 2 in vascular endothelial growth factor-induced vascular leakage in the retina of diabetic mice. Diabetes 65(8), 2414–2428 (2016).
Wang, Y. et al. Association of C-peptide with diabetic vascular complications in type 2 diabetes. Diabetes Metab. 46(1), 33–40 (2020).
Hao, L. et al. Risk factors for diabetic retinopathy in patients with diabetes mellitus. Nurs. Pract. Res. 5(9), 1337–1440 (2021).
Zhang, F. F. Risk factors of retinopathy in type 2 diabetes mellitus. Electr. J. Clin. Med. Lit. 6(42), 25–28 (2019).
Funding
The authors received basic scientific research funds from Heilongjiang Provincial Department of Education (Funds project number: 2022-KYYWF-0725).
Author information
Authors and Affiliations
Contributions
WXY: overall design of the study. SP: experimental validation. ZGX: statistical work towards experimental data. LJH: collection of data. ZYF: data analysis. The study was designed and supervised by LY and XHN. LJQ carried out study quality assessment. The corresponding author CRJ is responsible for ensuring that the descriptions are accurate. All authors contributed significantly and were involved in editing, reviewing, and approving the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent for publication
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, X., Shen, P., Zhao, G. et al. An enhanced machine learning algorithm for type 2 diabetes prognosis with a detailed examination of Key correlates. Sci Rep 14, 26355 (2024). https://doi.org/10.1038/s41598-024-75898-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-75898-w
