
Abstract
The digitization of operation and maintenance in the intelligent power grid equipment relies on a diverse array of information for smart decision-making. In the ___domain of intelligent decision generation, proficiency is contingent upon extensive learning from copious amounts of text. This necessitates not only robust processing capabilities but also a high level of specialization. In addressing situations where authorization is lacking, pre-trained language models (PLMs) have already provided ideas when confronted with specialized domains or tasks. In consideration of the complexity of textual content in the field of the power grid, which encompasses a multitude of specialized knowledge and involves an abundance of proprietary terminology, we have undertaken an exploration of pre-trained model specialization using the power grid ___domain as an example, specifically for the task of generating maintenance strategies. A two-stage fine-tuning approach (P2FT) is employed, utilizing a large-scale pre-training model specifically designed for natural language processing. The efficacy and practical value of this method were evaluated through multiple metrics, juxtaposed with other advanced approaches involving low-parameter or parameter-free fine-tuning methods. Through a meticulous analysis and validation of experimental outcomes, we have corroborated the feasibility and practical application value of employing this approach for pre-trained model specialization. Additionally, it has furnished valuable guidance for text generation within both the Chinese language ___domain and the power grid ___domain.
Similar content being viewed by others
Introduction
Presently, decision generation is progressively evolving into the crux of intelligent decision-making. In the ___domain of intelligent power grids, the essence of intelligent decision-making lies in the text generation tasks associated with the adaptation, maintenance, and inspection of power grid equipment. It proves to be a formidable challenge to infuse such specialized knowledge into language models. While existing research achievements have acquired the ability to generate coherent text by grasping general language patterns, their aptitude for text generation may be limited when confronted with specialized domains or tasks.
As an important topic in language modeling, the research of text generation has received extensive attention in the literature. Bengio1 introduced the Neural Network Language Model (NNLM). With the rise of deep learning, the introduction of generative adversarial networks (GANs)2 revolutionized text generation. Researchers proposed various improved GAN models, including LeakGAN3. Additionally, Texygen4, an open-___domain benchmark platform, incorporated multiple text generation models, such as SeqGAN5 and MaliGAN6. Thomas Mikolov et al.7 introduced the word vector representation model. Subsequently, the attention mechanism8, pioneered by Google, found wide application in natural language generation, along with various deep learning methods based on Transformer. Google BERT9 is a well-known self-encoding pre-training language model utilizing the Transformer architecture to extract features. Contextually-aware word representations, as established through pre-training, have proven highly efficacious as versatile semantic attributes. They have significantly elevated the standard of performance across a spectrum of Natural Language Processing (NLP) tasks. This investigation has served as a wellspring of inspiration for a substantial body of subsequent research, propounding the “pre-training and fine-tuning” learning paradigm. In this framework, there is a recurring need for the meticulous fine-tuning of PLMs to suit the unique demands of various downstream tasks. Other notable language models include autoregressive models like ELMo10, GPT11,12, and XLNet13. GPT utilizes the Transformer architecture for feature extraction, capturing longer-range information efficiently.
For attribute or content control in text generation, Keskar et al.14 introduced the CTRL language model, enabling the automatic generation of texts across various types and domains through trainable conditional control codes. Chan et al.15 proposed the concept of text-guided text generation and self-supervised learning of the GPT2 base model. They constructed three self-supervised learning strategies and loss calculation methods for GPT2, enabling the model to self-learn control without relying on a large labeled corpus.
We referenced the Plug and Play Language Models (PPLM) proposed by Dathathri et al16 and implemented the P2FT for the purpose of constructing a ___domain-specific pretrained model. Here, we illustrate this with the generation of maintenance strategy in the context of the power grid ___domain. We selected this example because maintenance strategy in the power grid ___domain encompasses a wealth of specialized vocabulary, such as different power transmission equipment and diagnostic methodologies. This necessitates the model to possess a considerable reservoir of ___domain-specific knowledge. Additionally, the textual style in this ___domain significantly deviates from that of general ___domain text, rendering it highly representative. We aim to achieve the automatic generation of high-quality fault maintenance strategies in the power grid ___domain, utilizing the ROUGE17 and other evaluation indexes commonly used in text generation tasks for automatic quality evaluation of generated samples.
During the evaluation of text generation quality, the model’s text generation after first-stage fine-tuning is noticeably superior to that of the base model, supported by experimental results and human observation. Furthermore, by incorporating bag-of-words model of the PPLM for guidance, a number of indicators have improved significantly, for example, the F1-score of ROUGE-1, ROUGE-2, and ROUGE-L can be enhanced by approximately 0.7%, 0.6%, and 0.3% respectively.
To summarize, we make the following significant contributions:
We endeavor to delve into the ___domain-specific construction of pre-trained models. We have introduced the P2FT, utilizing it to achieve intelligent decision generation in the field of smart grids with efficiency and high quality. Utilizing the P2FT, we have achieved the injection of ___domain-specific expertise into the pre-trained model. This enables the execution of ___domain-specific downstream tasks. We exemplify our approach by considering the task of generating maintenance strategies in the power grid ___domain. This approach achieves excellent controllability in generating content while requiring only a small amount of computational resources.
We have incorporated a comprehensive dataset comprising information from thousands of case reports, documents of power grid standards, and other documents in the field of power grids. This has effectively addressed the scarcity of high-quality data in the ___domain. This dataset covers various fault types and power grid equipment, providing valuable resources for further research in this ___domain.
Through comprehensive experimentation and result analysis, we validate the feasibility and practical value of fine-tuning large-scale Chinese pre-training models for pre-trained model specialization in the power grid ___domain. The research demonstrates practical application value and offers valuable guidance for future developments in Chinese text generation.
Material and methods
Dataset
Data collection
Due to the deficiency in datasets within the power grid ___domain, it became imperative to independently create a ___domain dataset of substantial scale. The dataset we constructed emanates from the power grid operational data of an electric power company, encompassing thousands of case reports, nearly four thousand documents of power grid standards, and operational procedure files. These documents are available in both PDF and Word formats, containing detailed descriptions of fault cases and maintenance decision records for various power grid equipment. The aim is to utilize this dataset as a reference for actual equipment maintenance tasks during daily operations and maintenance processes, while also exploring its potential in generating automated maintenance policies.
Data preprocessing
The original corpus contains an abundance of redundant information. Our task is to meticulously filter and extract text content pertinent to the adaptation, maintenance, and inspection of power grid equipment. Subsequently, we organize and store the extracted text content in a predefined format, facilitating the construction of a high-quality ___domain dataset. In practice, some documents in the power grid ___domain are manually written and often contain unstructured text, including elements such as tables, images, text, and equipment numbers. Therefore, it is necessary to identify and extract the relevant and useful information contained within these documents.
The objective of information extraction is to analyze and process the unstructured fault case texts in the power grid ___domain. It involves extracting valuable information based on text attributes and categories. When extracting information from the power grid case reports, we abstract the information into a standardized attribute template. These attributes can be categorized into three types: numeric attributes, phrase attributes, and sentence attributes. Depending on the characteristics of each attribute type, corresponding information extraction schemes are formulated to achieve the structuring of text information.
We focus on extracting sentence-based attributes from the fault case database in the power grid ___domain, specifically the fault descriptions and corresponding maintenance strategies written in Chinese sentences. We created a dataset comprising over 770 manually labeled sentences with different attributes for training purposes. Word2Vec algorithm is then used to vectorize the sentences, followed by classification and recognition using the R-CNN neural network. Through cross-validation, the classification accuracy is achieved at 78%. The trained classifier can then be used to identify sentences within the power grid case reports and extract the attributes based on the sentence form.
Furthermore, 1078 case reports in the power grid ___domain are utilized as the original dataset for the P2FT. In the first stage, the training set and validation set are obtained by dividing the long paragraphs from 899 case reports. This results in 13,790 training set samples and 3,448 validation set samples. In the second stage, 279 case reports are used as test set samples for the two-stage fine-tuning process. The following Table 1 shows an example of a raw grid fault report and a sample after information extraction. The content displayed in the table is the result of translating the original Chinese information extraction into English text.
Data analysis
Due to the intricate nature of deficiency scenarios in the power grid ___domain, involving a myriad of devices, it is imperative to build a dataset with abundant information. Our constructed ___domain dataset is grounded in real operational business data, encompassing a diverse array of scenarios and various devices. We ensure that the data scale for each category is sufficiently substantial. We focus on case reports that encompass eight types of equipment failures in the power grid ___domain. These equipment failures include transmission line, transformer, switchgear, mutual inductor, switch cabinet, lightning arrester, cable and other equipment. The power grid case reports consist of text describing the faults encountered, while the maintenance strategies are related to addressing these faults.
On average, the power grid case report text has a length of 1,542 Chinese characters, providing detailed information about the equipment failures and their context. The maintenance strategy text, on the other hand, has an average length of 197 Chinese characters, which outlines the recommended approaches to resolve the identified issues. The categories and quantities of case reports we utilized are showed in Table 2.
Methods
In pursuit of the objective to achieve intelligent decision-making for the adaptation, maintenance, and inspection of power grid equipment, we took into consideration the rapid iteration and updating of data and knowledge in the power grid ___domain. This poses a demand for a high update speed for decision models. Therefore, methods with lower training time, hardware costs, and a requirement for fewer ___domain data are more suitable for intelligent decision scenarios in the power grid ___domain. The P2FT we propose involves two stages of fine-tuning using the GPT model. In the first stage, a large dataset comprising high-quality case reports in the power grid ___domain is used to fine-tune the GPT model, enabling adaptation to both the Chinese language and the power grid ___domain. This stage focuses on refining the model’s understanding of the specific ___domain.
In the second stage, secondary fine-tuning is conducted using the PPLM. This stage builds upon the intermediate fine-tuned model and utilizes a bag-of-words model constructed from the text data containing the maintenance strategy after information extraction. The PPLM enables coarse-grained control of the generated text during the text generation process. This allows for the automatic generation of maintenance strategy text specific to the power grid ___domain.
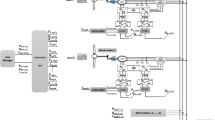
By employing the P2FT, the GPT model is trained to generate maintenance strategy text that is tailored to the power grid ___domain, incorporating both the language nuances and the specific requirements of the field. The method framework is as showed in Fig. 1.

Method framework.
Fine-tuning of Chinese text in power grid ___domain
The initial pre-training of the GPT model has already been completed using a large corpus of text, consisting of 8 million web pages. This pre-training equips the model with a strong language understanding capability. However, since the training data predominantly consists of English text, its effectiveness in Chinese and the power grid ___domain is limited. To address this, fine-tuning is performed using a rich dataset specific to the power grid ___domain.
In this study, the gpt2-medium model provided by the huggingface open-source library is used as the initial pre-trained model. Fine-tuning a pre-trained language model for a specific task typically requires labeled data for supervision. The final output sequence from the last block is treated as the prediction label. For instance, in a text classification task, the predicted class label y is determined by mapping the output sequence \(h_l^m\) to each category using a fully connected layer followed by a softmax layer. The calculation formula is as shown in equation 1.
In this study, the case reports in the power grid ___domain consist of both fault description and maintenance strategy text. Therefore, the task of generating maintenance strategies can be regarded as a case report generation task for model fine-tuning. This means that the data label “y” is contained within the input text data. To ensure an ample amount of training data, we employ the same self-supervised training method as the language model pre-training in the first-stage fine-tuning. This enables the model to adapt to Chinese text in the power grid ___domain.
The general idea behind one-way language model pre-training is to predict the subsequent text given a prompt content with a sequence length of “k”. We use the fault description text in the power grid ___domain as the prompt content to predict the corresponding maintenance strategy text. Let “T” represent the fault description text.
PPLM
Without clear control conditions or themes, the generated texts of The first-stage fine-tuning model may not be specifically associated with the input fault description and the corresponding maintenance strategies, limiting their usefulness to maintenance personnel. To address this issue, a second-stage fine-tuning is performed to further enhance the text generation process.
The second-stage fine-tuning approach does not involve any parameter or network structure changes to the original pre-trained language model. We begin by creating the bag-of-words model by selecting the first 500 Chinese characters based on the Chinese character frequency of identified Chinese characters specific to the power grid ___domain. A loss value is calculated and returned by the bag-of-words model to modify the historical information used in the forward propagation of the GPT language model. The new historical information is then utilized for re-sampling to obtain the token, and the number of re-sampling iterations is controlled to gradually approach the target text. This process allows for coarse-grained control of the text using minimal computing resources.
The overall text generation based on the topic of power grid ___domain maintenance strategy can be expressed as shown in equation 3. Here, p(x) represents a Chinese text generation model that is adaptable to the power grid ___domain and capable of generating natural language text, while \(p({a \mid x})\) denotes the process in which we utilize the bag-of-words model to determine whether the generated text exhibits the characteristics of power grid ___domain maintenance strategy text.
The PPLM method leverages the characteristic of GPT to perform predictive generation based on past historical information, denoted as H. At each time step t, the GPT model retains the K and V matrices that were used to generate the previous token as part of the historical information. This historical information is utilized to assist in the generation of the current time step.
As mentioned earlier, according to the network structure of GPT, the calculation of the K and V matrices takes into account all the preceding information, including the input text and the text that has been predicted/generated thus far. The historical information from each time step is preserved and carried forward to the subsequent time step (t+1) for generation.
The calculation formula for updating the historical information matrix and the forward propagation process of the updated model is as shown in equations 5 and 6.
By updating the historical information matrix with the influence of control attributes and incorporating it into the GPT model’s forward propagation, the text generation process can be guided and influenced by specific topics or attributes with the adjustable strength parameter \(\alpha\).
Experiments
Experimental configuration
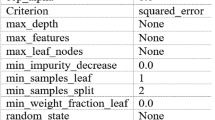
The hardware device used for training the model and text generation in the two-stage fine-tuning process in the experiment is the NVIDIA GeForce RTX 3090. To set up the Python environment, we need to install Anaconda 3. The total amount of model parameters is 317M, the batch size is 8, and the total number of epochs is 30. The gpt2-medium model training parameters are as shown in Table 3.
In the second-stage fine-tuning under the PPLM, the word prediction during the generation process is performed using the top-k method. Here, k is set to 10. This means that the top ten Chinese characters with the highest probability values are considered as candidate words for selection during the generation process. The specific parameters are set as shown in Table 4.
Experimental results
Contrast experiment
During the experiment, we opted for more advanced approaches to fine-tune pre-trained language models with fewer or zero parameters.
Table 5 presents a comparative analysis of the P2FT with other advanced methods for low-parameter or parameter-free fine-tuning of pre-trained language models. We employ the widely-used Llama-Index framework to integrate external ___domain knowledge into the pre-trained language model Baichuan2, reducing the cost of internal knowledge updates. This method effectively minimizes the cost of injecting knowledge into the original pre-trained language model, although it still necessitates the construction of an external knowledge source as the basis for text generation. In this experimental process, we extracted 1.7K knowledge-oriented records from a substantial corpus of operating procedures in the power grid ___domain. Each record encompasses multidimensional data, including equipment types, component categories, decision criteria, diagnostic analysis, and maintenance decisions. This external information source is utilized for maintenance strategy generation and ROUGE and other evaluation metrics.
Furthermore, we utilized the Baichuan2-7B model as the baseline model, achieving ___domain adaptation through a combined approach of instruction tuning and Lora fine-tuning. The fine-tuning process involved a dataset of 4.4K instructions sourced from numerous historical case reports and standard documents in the power grid ___domain. The fine-tuned model was then used for maintenance strategy generation experiments, followed by metric evaluations. The results from Table 5 indicate that the P2FT exhibits certain advantages over the other two advanced methods in all evaluation metrics. Particularly noteworthy is the superiority of the P2FT in the ROUGE-L metric, suggesting that its generated text maintains a higher degree of fluency and readability compared to fine-tuned pre-trained language models. This underscores the effectiveness of the PPLM in preserving the original language understanding and organizational capabilities of the baseline language model to a significant extent.
We also calculated BERTSCORE, TER, and other metrics, which are presented in Table 5. BERTSCORE, by extracting features through BERT and calculating the inner product, provides a maximum similarity score. Experimental results show that compared to other methods, the P2FT improves precision, recall, and F1 scores in BERTSCORE, indicating that the P2FT’s generated results align more closely with the reference texts and exhibit superior ___domain-specific vocabulary usage and decision-making capabilities. We also employed perplexity to evaluate the fluency of the generated Chinese text. The P2FT demonstrates lower perplexity, indicating strong language modeling ability and producing text that closely resembles natural language with enhanced readability. Additionally, we used the TER metric to further assess the reliability of the generated results across various methods, evaluating their performance from the perspective of error rates. The P2FT achieved a lower TER value, proving its semantic alignment with the reference texts and more accurate generation strategies.
As depicted in Table 6, a comparison with current advanced low-parameter or parameter-free fine-tuning schemes for pre-trained language models reveals that these methods impose high demands on the construction of external ___domain knowledge. This challenge hampers the adaptability of pre-trained language models to low-resource domains. P2FT’s strength lies in its ability to forego secondary full-parameter fine-tuning of the original language model. Additionally, it requires minimal external information, limited to guiding words in the word bag, almost eliminating the need for extensive dataset construction tailored to the ___domain. This capability significantly reduces the consumption of human and hardware resources.
Parameter size and data volume are key factors in evaluating large models. Statistics show that since 2018, the scale of datasets used in training large language models has been steadily increasing. The GPT-1 dataset in 2018 was approximately 4.6GB, while GPT-3 in 2020 reached 753GB, and by 2021, the Gopher model’s dataset had grown to 10,550GB. In summary, parameter size and data volume have become crucial factors in improving model performance. However, in specific domains, data is often scarce and task-related datasets are limited. The P2FT aims to efficiently accomplish specialized ___domain tasks with lower data costs and smaller parameter sizes, providing both experimental and theoretical foundations, as well as valuable references for constructing pre-trained language models in specific fields, such as text generation tasks in the Chinese language and the power grid industry. We used ROUGE-N and BERTSCORE to verify the professionalism of the generated results from the perspectives of sentence structure and semantics, proving that this method has practical applications for maintenance decision-making in real-world power grid scenarios. It can provide valuable suggestions to maintenance personnel. Additionally, we applied the TER metric to further confirm the method’s effectiveness and ___domain expertise. ROUGE-L and perplexity were used to validate the fluency and readability of the model’s output after adapting from an English base model to Chinese, demonstrating that it also holds practical value in Chinese-language tasks and can provide a theoretical foundation and reference for related future tasks.
Analysis experiment
During the experiment, we compared the generated texts from the fine-tuned model with the original, untuned model using fault description texts as input to generate maintenance strategy texts. The test data consisted of pairs of fault description texts and corresponding maintenance strategy texts was utilized as input and label texts for the text generation task calculate the average metrics.
The evaluation results are presented in Table 7, showing the comparison of three evaluation indexes before and after fine-tuning. All indexes have improved after fine-tuning.
For the ROUGE-1 index, the recall rate has increased from 2.046% to 40.943% after fine-tuning. This improvement is attributed to the fact that the original GPT model is more suitable for English text generation, and fine-tuning with professional Chinese text enhances its ability to generate Chinese text.
The ROUGE-2 index, which measures the smoothness and accuracy of the generated text using 2-gram units, has also shown improvement, with the recall rate increasing from 0.052% to 12.145%. This improvement indicates the effectiveness of fine-tuning with a large number of Chinese case texts in the power grid ___domain. For Chinese text, a certain meaning needs to be composed of multiple Chinese characters, and the 2-gram unit used to calculate the index involves the use of many professional Chinese vocabularies, so compared with ROUGE-1, the index can measure the smoothness of the generated text and the accuracy of the use of short vocabularies.
Similarly, the recall rate of the ROUGE-L index, which focuses on the main content of the generated text using the longest common subsequence (LCS), has increased from 2.289% to 21.653%. This improvement suggests that the fine-tuning process is necessary for text generation tasks in the power grid ___domain, as it enables the model to generate text that includes the selection of maintenance strategies and the application of professional technology, providing direct reference for maintenance personnel.
Indeed, the text generated by the original GPT model can often be unreadable and contain a significant number of non-Chinese characters. However, after fine-tuning with Chinese texts in the power grid ___domain, the generated text shows improved readability and fluency. This improvement is evident both from a human perspective and through the evaluation of ROUGE-2 and ROUGE-L indicators, indicating the effectiveness of fine-tuning the pre-trained model with ___domain-specific Chinese texts.
Regarding the ROUGE-L indicator, the higher recall rate compared to the precision rate can be attributed to the longer length setting of the generated text compared to the reference text. The objective of automatic policy text generation is not to provide complete and refined operation steps, but rather to offer reference decisions based on historical cases. Therefore, generating longer text to provide potential strategies from multiple perspectives is more practical and aligns with the goal of the task.
Regarding the BERTSCORE metric, compared to the original GPT model, the precision of the fine-tuned GPT model improved significantly from 66.6% to 93.0%, recall from 81.1% to 92.4%, and the F1 score from 72.6% to 92.7%. These substantial improvements demonstrate the model’s enhanced understanding and generation capabilities for maintenance decision-making tasks in the power grid ___domain. From the experimental results, we also observed that the TER metric decreased from 3.243 to 1.571, indicating a significant reduction in redundant content unrelated to maintenance decisions. This reflects a more precise understanding of task requirements and a clearer focus in the generated content. Additionally, whether through manual inspection or comparison of the perplexity metric before and after fine-tuning, we noted a marked improvement in the fluency of the generated Chinese text. This suggests that the first stage of fine-tuning significantly enhanced the model’s ability to comprehend and respond in Chinese, facilitating its progress in ___domain-specific tasks.
Overall, the first-stage fine-tuning using Chinese case texts in the power grid ___domain has achieved significant improvements in multiple indexes, indicating the effectiveness of the fine-tuning process in generating high-quality policy text for maintenance strategies in the power grid ___domain.
In the subsequent experiment, we employed the fine-tuned gpt2-medium model, which was previously fine-tuned in the first stage, for the automatic generation of maintenance strategy texts in the power grid ___domain. During the generation process, we incorporated the PPLM for second-stage fine-tuning. The test data used in this experiment was the same as mentioned earlier. After calculating multiple metrics for the newly generated maintenance strategy texts, we compared the results with the previous metric values. This evaluation allowed us to assess the effectiveness of the PPLM in guiding the generation process based on key characters.
Table 8 shows multiple indexes comparison results of the generated text under the PPLM and the first-stage fine-tuning gpt2-medium generated text, so as to verify the feasibility of the bag-of-words model in the ___domain of power grid text generation.
The experimental results indicate that the PPLM improves the recall, accuracy, and F1 value of the ROUGE-1, ROUGE-2, and ROUGE-L metrics. The recall rate of the ROUGE-1 metric increased from 40.943% to 41.161%. Similarly, the recall rate of the ROUGE-2 metric rose from 12.145% to 13.008%, while the recall rate of the ROUGE-L metric increased from 21.653% to 22.329%. The improvement is particularly significant for ROUGE-2 and ROUGE-L, as these metrics focus on the expression form and coherence of the generated text. By constructing a word bag based on special vocabulary in the power grid ___domain and using it to guide the language style and wording of the generated text, the quality of the generated maintenance decision text in the power grid ___domain is enhanced.
The use of single Chinese characters, even after splitting, can effectively guide the language style and wording of the text. In addition, the reason why some indicators are not improved much compared with the fine-tuning in the first stage may be that the case text we use for fine-tuning itself contains the content of maintenance strategy, so the use of professional vocabulary is not much different from that of maintenance strategy text as a whole. If it is in other professional fields or a large number of texts used for fine-tuning are far from the target text, there will be more significant guidance effect. Here, PPLM uses bag-of-words model to control text generation. The experiment shows that if the characters with lower word frequency rank are used as bag-of-words, the index even drops, which is enough to prove its guiding effect.
Moreover, the bag-of-words model not only guides the content of the generated strategy but also influences the language style. For instance, excluding date-related characters from the word bag can lead to generated text that adheres to the natural language specifications of maintenance strategies and avoids the inclusion of irrelevant or outdated information.
Regarding the BERTSCORE metric, experimental results show that the PPLM effectively improves precision, recall, and F1 scores by 0.7%, 1.9%, and 1.3%, respectively. The TER metric further decreased from 1.571 to 1.569, and perplexity dropped by 3.231. These improvements indicate that the PPLM can enhance model performance without increasing parameter size or training costs. The content generated for ___domain-specific tasks shows improvements in both technical accuracy and Chinese readability.
Overall, the use of the PPLM and the incorporation of a ___domain-specific bag-of-words model show promise in improving the quality, language style, and relevance of the generated text in the power grid ___domain.
In the subsequent experiments, we additionally performed word segmentation on the generated maintenance strategy texts after each fine-tuning stage, considering the characteristics of Chinese texts. We then recalculated the average ROUGE metric based on the segmented results. This evaluation method is more suitable for assessing Chinese ___domain texts. By utilizing the ROUGE-1 metric, we were able to better validate the readability and reference value of the generated texts, thereby further confirming the practical value of this approach in generating texts within the Chinese ___domain. Additionally, we conducted an analysis of the variations observed in each metric.
Table 9 presents some examples of using the P2FT to generate maintenance strategies based on fault descriptions. A comparison with the results generated by a first-stage model demonstrates that it aligns more closely with the maintenance strategies outlined in the original case report. The text displayed in the table represents the English translation of the original Chinese-generated results.
Table 10 shows the comparison results of the ROUGE index calculated by the two-stage fine-tuning gpt2-medium and other models after Chinese jieba word segmentation.
The improvement brought about by the second-stage fine-tuning approach on the original model remains quite evident, particularly in the recall rate of the ROUGE-1 metric, which increased from an initial value of 6.202% to 26.702% through the fine-tuning process. Considering the Chinese language’s characteristics, where a vocabulary often consists of multiple Chinese characters, Chinese vocabulary segmentation is beneficial for better similarity comparison and coherence analysis of text. Chinese vocabulary segmentation breaks down the text into individual Chinese vocabularies, which allows for more accurate matching and analysis of the overall meaning of the text. However, it should be noted that the condition for similarity matching becomes stricter when using n-gram units composed of Chinese characters in the ROUGE index calculation. This stricter condition may result in a decrease in the index values compared to the text without vocabulary segmentation. Nonetheless, the experimental results still show an overall improvement trend in the three ROUGE metrics, especially after the first-stage fine-tuning, confirming the effectiveness of the approach.
It is important to highlight that the ROUGE-1 index of the text after Chinese vocabulary segmentation using tools like jieba may differ from the ROUGE-2 index obtained from the unsegmented text. After vocabulary segmentation, the text may contain vocabularies of various lengths, including both short vocabularies (length 2) and long professional vocabularies specific to the power grid ___domain. Additionally, many meaningless vocabularies that were counted as 2-gram units in the unsegmented text are omitted. Therefore, the examination of the text’s logic becomes more meticulous, and the higher recall of the ROUGE-1 index in the experimental results (reaching 26.702%) can better highlight the high text quality of the generated grid maintenance strategy.
Furthermore, the experimental results indicate that while the ROUGE-1 and ROUGE-2 metrics show a consistent improvement, the ROUGE-L metric does not exhibit significant enhancement. This can be attributed to the fine-tuning process of the PPLM, which performs token-level resampling using Chinese single character rather than Chinese vocabularies. As a result, it may alter the expression or character order of some common vocabularies, causing numerical impact on the ROUGE-L metric. However, such changes often do not significantly affect the meaning of the text or its readability for maintenance personnel.
Discussion
Methods and results discussion
In this study, we have introduced the P2FT for pre-trained language models. By leveraging a substantial amount of case reports in the power grid ___domain, we have successfully achieved the automatic generation of maintenance strategy texts in both the Chinese and power grid domains using a large-scale language model. Throughout the experimental process, we observed that although pre-trained language models are trained on vast amounts of text data, their understanding of specialized domains remains limited, resulting in a scarcity of valuable information they can provide. Consequently, it is crucial to acquire a substantial amount of high-quality text data for ___domain adaptation training.
Furthermore, we discovered that employing the PPLM for parameter-free fine-tuning can enhance evaluation metrics while significantly reducing time costs. The generated maintenance strategies targeting defect descriptions were deemed highly valuable from both a human reading perspective and an evaluation standpoint. This indicates that low-cost fine-tuning of pre-trained language models for the power grid ___domain is feasible and efficient.
The second-stage fine-tuning, conducted using gpt2-medium, involved training and generating text simultaneously, omitting substantial model training time. In recent years, several studies have explored methods for low-parameter or parameter-free fine-tuning of pre-trained language models. For instance, Hu et al.18 proposed the LORA fine-tuning method, Zhang et al.19 introduced the LLaMA-Adapter fine-tuning method based on the LLaMA model, and Wei et al.20 presented the Instruction Tuning method. We opted for more advanced approaches to fine-tune pre-trained language models with fewer or zero parameters. In the experimental process, we compared them with the P2FT, highlighting the advantages of the P2FT.
Moreover, our task of generating power grid ___domain maintenance strategies poses a greater challenge compared to other text generation tasks. It involves a significant amount of specialized ___domain knowledge and technical expertise, without a fixed writing structure, and encompasses both the Chinese and power grid domains. Through our research, we have found that there is a greater abundance of publicly available text datasets in the medical ___domain on the internet, which cover a wide range of professional knowledge. In contrast, there is a scarcity of text data specifically related to the power grid ___domain, with most available data consisting of indicator-based information and limited coverage of fault repair plans. To achieve the organized development and healthy growth of a smart grid, it is imperative to utilize high-quality data more efficiently and establish diverse and secure channels for its dissemination.
Theoretical and practical implications
Practical Significance. The model established, trained, and experimented upon in this research holds practical significance in providing assistance to maintenance personnel in future power grid fault equipment maintenance and repair work. Additionally, it can contribute to the development of a more comprehensive knowledge system by leveraging subsequent data generated from power grid related work, thereby enhancing its application value. For instance, when encountering power grid equipment failures similar to those documented in historical case reports, the model developed in this research can be utilized to automatically generate strategies, thereby guiding the implementation of maintenance work to a certain extent.
Theoretical Significance. The comprehensive conclusions drawn from the experiments conducted in this research hold theoretical significance by providing methodological references for text generation tasks involving large-scale pre-trained language model fine-tuning in other domains.
Conclusions
The P2FT proposed by us involves the establishment of a dataset pertaining to maintenance of faults in the power grid ___domain. This database serves as the foundation for fine-tuning a large-scale pre-training model in two stages. Then we construct a ___domain-specific model that can achieve automatic generation of power grid equipment fault maintenance strategies. The generated texts are then analyzed, summarized, and evaluated using multiple indicators. Experimental results verify the effectiveness of our approach. We aim to furnish a theoretical foundation and valuable references for the ___domain-specific construction of pre-trained language models, as well as for text generation tasks within the Chinese language ___domain and the power grid industry. However, our approach currently focuses on statistically analyzing specialized textual characteristics in the power grid ___domain, guiding text generation. Future research will explore more efficient ways to fine-tune pre-trained language models under various control conditions, improving training while saving time and resources.
Data availability
If any researcher requires data support for this article, please contact the corresponding author of this article via email to obtain our dataset.
Code availability
If any researcher requires code support for this article, please contact the corresponding author of this article via email to obtain our code.
Materials availability
If any researcher requires materials support for this article, please contact the corresponding author of this article via email to obtain our materials.
References
Bengio, Y. et al. A neural probabilistic language model. J. Mach. Learn. Res. 3, 1137–1155 (2003).
Goodfellow, I. J., Pouget-Abadie, J. & Mirza, M., et al. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 2672–2680 (MIT Press, Cambridge, MA, USA, 2014).
Guo, J., Lu, S. & Cai, H., et al. Long text generation via adversarial training with leaked information. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence 5141–5148 (AAAI Press, Palo Alto, California, USA, 2018).
Zhu, Y. et al. Texygen: A benchmarking platform for text generation models. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval 1097–1100 (Association for Computing Machinery, New York, NY, USA, 2018).
Yu, L., Zhang, W. & Wang, J., et al. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence 2852–2858 (AAAI Press, Palo Alto, California, USA, 2017).
Che, T., Li, Y. & Zhang, R., et al. Maximum-likelihood augmented discrete generative adversarial networks. arxiv:1702.07983 (2017).
Mikolov, T., Chen, K. & Corrado, G., et al. Efficient estimation of word representations in vector space. arxiv:1301.3781 (2013).
Vaswani, A., Shazeer, N. & Parmar, N., et al. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems 6000–6010 (Curran Associates Inc., Red Hook, NY, USA, 2017).
Devlin, J., Chang, M. W. & Lee, K., et al. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Volume 1 (Long and Short Papers) 4171–4186 (Association for Computational Linguistics, Minneapolis, Minnesota, 2019).
Peters, M. E., Neumann, M. & Iyyer. M., et al. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) 2227–2237 (Association for Computational Linguistics, New Orleans, Louisiana, 2018).
Radford, A., Narasimhan, K. & Salimans, T., et al. Improving language understanding by generative pre-training (2018).
Brown, T. B., Mann, B. & Ryder, N., et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems 1877–1901 (Curran Associates Inc., Red Hook, NY, USA, 2020).
Yang, Z., Dai, Z. & Yang, Y., et al. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd International Conference on Neural Information Processing Systems 5753–5763 (Curran Associates Inc., Red Hook, NY, USA, 2019).
Keskar, N. S., McCann, B. & Varshney, L. R., et al. Ctrl: A conditional transformer language model for controllable generation. arxiv:1909.05858 (2019).
Chan, A. et al. Cocon: A self-supervised approach for controlled text generation. In 9th International Conference on Learning Representations, ICLR 2021 1–22 (OpenReview.net, Virtual Event, 2021).
Dathathri, S. et al. Plug and play language models: A simple approach to controlled text generation. In 8th International Conference on Learning Representations, ICLR 2020 1–34 (OpenReview.net, Addis Ababa, Ethiopia, 2020).
Lin, C. Y. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out 74–81 (Association for Computational Linguistics, Barcelona, Spain, 2004).
Hu, E. J., Shen, Y. & Wallis, P., et al. Lora: Low-rank adaptation of large language models. arxiv:2106.09685 (2021).
Zhang, R., Han, J. & Zhou, A., et al. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arxiv:2303.16199 (2023).
Wei, J. et al. Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022 1–46 (OpenReview.net, Virtual Event, 2022).
Funding
This work was supported by the State Grid Shandong Electric Power Company Science and Technology Project “Research and Application of Multi-scenario Equipment Operation Inspection Intelligent Decision Technology Based on Knowledge Reasoning”.(Grant number 520626220107)
Author information
Authors and Affiliations
Contributions
Conceptualization: Y.Y., C.L., B.Z., W.Z., F.Z., Z.L.; Data curation: Y.Y., C.L., B.Z., W.Z., F.Z., Z.L.; Formal analysis: Y.Y., B.Z.; Funding acquisition: Y.Y., C.L., W.Z., F.Z., Z.L.; Investigation: Y.Y., B.Z.; Methodology: Y.Y., B.Z.; Project administration: Y.Y., C.L., W.Z., F.Z., Z.L.; Resources: Y.Y., C.L., W.Z., F.Z., Z.L.; Software: B.Z.; Supervision: Y.Y., C.L., W.Z., F.Z., Z.L.; Validation: B.Z.; Visualization: B.Z.; Writing-original draft: B.Z.; Writing-review and editing: B.Z..
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yang, Y., Li, C., Zhu, B. et al. Enhancing ___domain-specific text generation for power grid maintenance with P2FT. Sci Rep 14, 26771 (2024). https://doi.org/10.1038/s41598-024-78078-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-78078-y
