
Abstract
Knowledge distillation improves student model performance. However, using a larger teacher model does not necessarily result in better distillation gains due to significant architecture and output gaps with smaller student networks. To address this issue, we reconsider teacher outputs and find that categories with strong teacher confidence benefit distillation more, while those with weaker certainty contribute less. Thus, we propose Logits Uncertainty Distillation (LUD) to bridge this gap. We introduce category uncertainty weighting to consider the uncertainty in the teacher model’s predictions. A confidence threshold, based on the teacher’s predictions, helps construct a mask that discounts uncertain classes during distillation. Furthermore, we incorporate two Spearman correlation loss functions to align the logits of the teacher and student models. These loss functions measure the discrepancy between the models’ outputs at the category and sample levels. We also introduce adaptive dynamic temperature factors to optimize the distillation process. By combining these techniques, we enhance knowledge distillation results and facilitate effective knowledge transfer between teacher and student models, even when architectural differences exist. Extensive experiments on multiple datasets demonstrate the effectiveness of our method.
Similar content being viewed by others

Introduction
The development of large deep models in computer vision continues to be significant in recent years. However, it is increasingly apparent that these models often encounter issues such as redundancy and high computational resource requirements. To tackle these challenges, various model compression methods have emerged, aiming to enhance the efficiency and compactness of deep models1,2. Among these compression techniques, knowledge distillation has emerged as a highly effective approach3. Knowledge distillation involves transferring knowledge from a large, cumbersome model (referred to as the teacher model) to a smaller, more streamlined model (known as the student model). This approach enables the student model to achieve a balance between efficiency and accuracy, making it suitable for deployment on resource-constrained devices or in scenarios that require real-time processing.
Concurrently, knowledge distillation presents a distinctive set of challenges in comparison to other compression techniques, particularly when working with large teacher models. The discrepancies in architectural design and predictive confidence between the teacher and student models, which we term “distillation gaps”, have the potential to significantly impede effective knowledge transfer. These challenges are of critical importance, as they directly impact the quality of knowledge transfer and the resulting performance of the student model. In contrast to other compression techniques, which are solely concerned with reducing the size of the model, knowledge distillation must strike a balance between compression and the preservation of the teacher’s knowledge. The process of knowledge distillation presents a distinctive set of challenges when working with large teacher models. These challenges are primarily attributable to discrepancies in architectural design and discrepancies in predictive confidence between the teacher and student models. The architectural differences between the teacher and student models may give rise to discrepancies in the level of comprehension of the intricacies of the teacher’s knowledge on the part of the student model, particularly if the teacher model is deeper or more complex. Such discrepancies may result in information loss or distortion during the distillation process, which could impede the accurate replication of the teacher’s performance. Furthermore, discrepancies in predictive confidence between the teacher and student models represent an additional challenge. The larger and more complex teacher model often exhibits a higher degree of confidence in assigning probabilities to different outcomes, whereas the student model may encounter difficulties in attaining a similar level of confidence. This discrepancy constrains the student model’s comprehension of the teacher’s reasoning and impedes the process of knowledge distillation. In order to address these challenges, various normalization techniques have been proposed with the aim of aligning the predictive confidence of the teacher and student models. However, applying these techniques to large models can be problematic. The complexity and size of the teacher model make achieving accurate normalization difficult, resulting in suboptimal knowledge transfer and limited improvements in student model performance. Given these limitations, there is a clear need for innovative approaches that can effectively bridge the distillation gaps and facilitate knowledge transfer, even in the presence of architectural differences and disparities in predictive confidence.
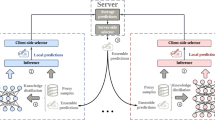
To address this problem, we propose a novel approach called Logits Uncertainty Distillation (LUD), as shown in Fig. 1. In this approach, we introduce the concept of category uncertainty weighting, which allows us to account for the inherent uncertainty in the teacher model’s predictions. This represents a novel approach in comparison to existing methods. By quantifying the confidence of the teacher model’s predictions and calculating a confidence threshold, a mask is constructed which discounts uncertain classes during the distillation process. This allows the student model to focus on more reliable and confident predictions, thereby enhancing its learning performance. Furthermore, two Spearman correlation-based loss functions, namely category distillation loss (CDL) and sample distillation loss (SDL), are integrated to align the logits of the teacher and student models. These loss functions quantify the discrepancy between the models’ outputs at both the category and sample levels. By considering the correlations between the logits, it is possible to ensure that the student model accurately captures the essential information from the teacher model. Our Spearman correlation-based loss functions (CDL and SDL) represent a distinctive approach to aligning teacher-student logits at both the category and sample levels. To further optimise the distillation process, we introduce adaptive dynamic temperature factors, which also represent an innovation in optimising knowledge transfer. The temperature matrix is calculated based on the Spearman correlation between the teacher and student logits, and the similarity values are mapped to a predefined temperature range. This enables an adaptive adjustment of the temperature during distillation, which in turn facilitates more effective knowledge transfer between the models.
Extensive experiments demonstrate our method outperforms traditional distillation on datasets like CIFAR-100 and ImageNet. The results demonstrate that the entropy weighting facilitates the more effective extraction of reliable knowledge from the teacher. Furthermore, adaptive tuning facilitates enhanced compatibility between heterogeneous model outputs. The combination of these contributions achieves state-of-the-art performance, thereby validating our approach as an effective technique for mitigating output mismatches in cross-architecture model pairs.
In summary, the key contributions of the proposed approach are:
-
1.
We introduce category uncertainty weighting to account for uncertainty in the teacher model’s predictions. This allows us to focus on more reliable and confident predictions during distillation, addressing the challenge of transferring knowledge from complex teacher models to simpler student models.
-
2.
We incorporate two Spearman correlation-based loss functions (CDL and SDL) to align the logits of teacher and student models at both category and sample levels. This novel approach ensures a more comprehensive transfer of knowledge.
-
3.
We introduce adaptive dynamic temperature factors, which optimize the distillation process by adjusting the temperature based on the similarity between teacher and student logits. These innovations collectively address the gaps in handling model uncertainty, aligning logits across different architectures, and adapting the distillation process dynamically.
-
4.
Extensive experiments demonstrate the proposed approach outperforms traditional distillation methods on datasets like CIFAR-100 and ImageNet. Our experimental results demonstrate that LUD outperforms existing methods, particularly when dealing with large architectural gaps between teacher and student models.
The following section presents the experimental results obtained with our LUD method. Subsequently, we present the existing literature on knowledge distillation, with a particular focus on the novel contributions of our own proposal. Furthermore, we analyse the limitations of our method and describe its real-world application scenario. In conclusion, we provide a comprehensive explanation of our methodology and present our findings.

Overall framework of Logits Uncertainty Distillation. We use category uncertainty weighting to address uncertainty in the teacher model’s predictions. A confidence threshold, based on the teacher’s predictions, is used to create a mask that discounts uncertain classes during distillation. Additionally, two Spearman correlation loss functions are used to align the logits of the teacher and student models by measuring the discrepancy between their outputs at the category and sample levels. The arrows show the flow of data through the system, including the generation of sample and category logits, indicating the roles of different components.
Results
Experimental results on CIFAR-100
Implementation
The CIFAR-100 dataset is a widely used benchmark dataset in the field of computer vision. These images are divided into 100 different classes, with each class containing 600 images. In our experiments, we investigated various teacher-student models with the same or different architecture styles, following the settings proposed in the CRD4 method. The training process for these models spanned 480 epochs. We employed a mini-batch size of 64 and utilized the standard stochastic gradient descent (SGD) optimizer with a weight decay of 0.0005. The learning rate was adjusted using a multi-step schedule, initially set to 0.05. By following these standardized training settings, we ensured consistency and enabled fair comparisons between different teacher-student models and LUD methods. These settings include the choice of optimization algorithm, weight decay, learning rate schedule, and training duration, allowing for reliable evaluations and performance comparisons in our experiments.
Comparison results under similar teacher-student pairs
By analyzing Table 1, our method is compared with other techniques in detail. Comparing our method with the other techniques: (1) LUD consistently achieves higher accuracy than KD3, FitNets5, AT6, SP7, CC8, VID9, RKD10, PKT11, AB12, FT13, NST14, and CRD4 methods across various teacher-student model combinations. (2) LUD performs comparably or better than SRRL15 methods when applicable. (3) LUD does not have data available for comparison with DIST16 method. These accuracy gains demonstrate the effectiveness of the LUD method in transferring knowledge from the teacher model to the student model. By incorporating learnable unit-distribution layers and distribution matching techniques, the LUD method enables the student model to capture the distributional information present in the teacher model. This fine-grained information contributes to the improved performance and higher accuracy gains.
Comparison results under different teacher-student pairs
Table 1 compares the performance of the LUD method compared to other knowledge distillation methods. We include standard deviations for each accuracy measurement, providing a measure of the variability in our results. For the teacher-student model combination of ResNet32x4 and ShuffleNetV1: (1) LUD achieves an accuracy of 78.68, which is the highest among all the methods. (2) Other knowledge distillation methods like FitNet, AT, SP, CC, VID, RKD, PKT, AB, FT, NST, and CRD achieve lower accuracies ranging from 71.14 to 75.11. In the context of knowledge distillation and model compression, even small improvements in accuracy can be considerable, especially when dealing with state-of-the-art models. The accuracy gain of 3.57% (from 75.11% to 78.68%) achieved by our LUD method over the best-performing existing method (CRD) is indeed practically significant. This improvement translates to a relative error reduction of over 14%, which is substantial in the field of machine learning. In practical applications, for example in image classification for medical diagnosis or autonomous driving, such an improvement could result in more accurate predictions and potentially life-saving decisions. Moreover, our method consistently outperforms alternative techniques when applied to a range of teacher-student model combinations, thereby demonstrating its robustness and practical applicability. These comparisons demonstrate the efficacy of the method in transferring knowledge from the teacher model to the student model, resulting in enhanced performance. It is important to note that the comparison is specific to this particular teacher-student model combination, and that the results may vary for different combinations. Nevertheless, based on the available data, these enhanced accuracy levels have practical implications and the potential to influence outcomes in real-world scenarios. The results demonstrate the competitiveness and potential of LUD as a knowledge distillation method.
Experimental results on ImageNet
Implementation
The performance of the LUD approach was evaluated on the ImageNet dataset using the ResNet-18 and MobileNet models as baseline models. The training settings followed the standard practices for most distillation methods, with a total of 100 training epochs. The learning rate schedule utilized a multi-step approach, starting at 0.1 and decaying by a factor of 0.1 at the 30th, 60th, and 90th epochs.
Comparison results
The comparison results of LUD on the ImageNet dataset are presented in Table 2. Notably, LUD achieved significant improvements over the baseline models. For the ResNet-18 model, LUD attained a gain of 2.27% to the student model in Top-1 accuracy, while for the MobileNet model, it achieved a gain of 2.81%. Comparing LUD with other knowledge distillation (KD) methods, it outperformed them by substantial margins. When compared to traditional KD methods, LUD exhibited an accuracy improvement of 1.36% to 2.26%. Additionally, when compared to the MGD method for the MobileNet model, LUD demonstrated superiority with margins ranging from 1.01% to 1.56% in Top-5 and Top-1. These results provide strong evidence for the effectiveness and superiority of LUD, particularly when applied to large-scale datasets like ImageNet. In summary, the experiments conducted on the ImageNet dataset using the ResNet-18 and MobileNet models, along with the comparison against other KD methods, highlight the significant performance gains achieved by LUD. These findings validate the effectiveness of the proposed method and its potential to enhance model performance on challenging and large-scale datasets.
Ablation studies for our LUD
The hyperparameters \(T_{\text {min}}\) and \(T_{\text {max}}\) in the LUD (Logits Uncertainty Distillation) technique determine the temperature range used during the distillation process. These hyperparameters control the softness or hardness of the predicted probabilities from the teacher model. In the LUD method, the logits (pre-softmax outputs) of both the teacher and student models are transformed using a temperature scaling factor. This temperature scaling allows for the adjustment of the model’s confidence in its predictions. Higher temperatures result in softer probability distributions with greater entropy, while lower temperatures produce sharper distributions with less uncertainty. The performance of LUD can be sensitive to the choice of temperature range (Tmin and Tmax). Optimal settings may vary across different tasks and model architectures, potentially requiring additional tuning. To determine the optimal hyperparameter settings, we conducted experiments using different values of \(T_{\text {min}}\) and \(T_{\text {max}}\) and evaluated their performance on a validation set or through other metrics. From the results presented in Fig. 2, it can be observed that the combination of \(T_{\text {min}} = 2\) and \(T_{\text {max}} = 6\) yielded the best performance in terms of accuracy or other desired evaluation metrics. These optimal hyperparameter settings indicate that a temperature range between 2 and 6 is effective for transferring knowledge from the teacher model to the student model. The choice of these values might be based on the specific characteristics of the dataset, the complexity of the task, or previous empirical observations.

Ablation studies for our LUD on Cifar-100. LOW-T and HIGH-T mean \(T_{\text {min}}\) and \(T_{\text {max}}\).

t-SNE visualizations of feature embeddings from CIFAR100, comparing the KD-distilled student model (left) with the LUD-distilled student model (right).
T-SNE visualizations
In Fig. 3, the t-SNE visualizations of feature embeddings on CIFAR100 reveal notable differences. The student model’s class clusters, while reflecting the teacher’s in relative positioning, are more spread out. This spread indicates the effectiveness of LUD in reducing task-irrelevant instance-instance relationships from the teacher model, resulting in a more distinct and task-focused feature space for the student model. On the other hand, the student model exhibits more dispersed clusters, highlighting the role of LUD in enhancing task-specific discriminative capabilities when using a large-scale foundation model as the teacher.
Following a comprehensive description of the experimental findings, we will present an overview of the existing literature on knowledge distillation and uncertainty analysis. We will then examine the distinctive advantages and potential limitations of LUD in comparison to other related works, and discuss its potential applications.
Discussion
Discussions on related works
Model compression methods17,18,19,20,21,22,23 include knowledge distillation24,25,26,27,28 and model searching techniques29,30,31,32,33,34,35. Knowledge distillation36,37,38,39,40 involves significant effort across multiple stages of research. Firstly, appropriate teacher and student models need to be selected based on the task and compression goals, necessitating a review of recent architectures and an understanding of their properties. Once selected, the models must be implemented either from scratch or adapted from available codebases. Knowledge Distillation (KD) has seen the development of various approaches and techniques for training a student model using the knowledge from a high-capacity teacher model. Early works, such as3,41, utilized soft logit outputs from teachers to provide additional supervision during training, focusing on transferring the knowledge encoded in the teacher’s output probabilities. Subsequent advancements introduced feature distillation methods5,6,13, aiming to align the intermediate feature representations of the student and teacher models. These approaches focused on matching the feature maps despite differences in dimensions, such as width, height, and channels, to ensure that the student model captures similar high-level representations as the teacher model. Relation distillation methods4,10 explored the structural information present in the teachers’ logits or features, treating knowledge as an instance graph with feature embeddings as nodes. Methods like DarkRank42, RKD10, and CCKD43 employed various strategies to generate edge weights, often based on similarity metrics. Contrastive learning techniques were utilized by approaches like CRD4 and CRCD44 to align representations. SSKD45 and CSKD46 incorporated self-supervised learning and category-level information, respectively, into the distillation process. LKD47 and GLD48 focused on local features and relationships, highlighting the diversity in distillation strategies. In contrast to existing methods, our approach concentrates on distilling knowledge from the foundation models and harnessing their potential. We aim to leverage the core concepts and principles of the teacher model to effectively guide the student model’s learning process. By focusing on the fundamental knowledge encoded in the teacher model, we seek to distill the most valuable insights and transfer them to the student model. Our approach recognizes the importance of building upon the foundation models and extracting the essence of their knowledge for optimal distillation results. Uncertainty learning tackles challenging problems at the intersection of machine learning and probability theory. Two main categories of uncertainty exist: data uncertainty and model uncertainty. Data uncertainty arises from uneven data distribution, measurement errors, and inaccurate labeling. Model uncertainty results from inaccuracies in model structure, parameters, and the training procedure. To address uncertainty issues, researchers conduct various related studies, including ensemble learning, Bayesian methods, and test-time data augmentation methods49. Ensemble methods combine multiple models to enhance uncertainty estimation, capturing complex patterns and reducing the impact of individual model errors. Deep Ensembles provide cutting-edge uncertainty estimation without the need for Bayesian methods, but they are computationally intensive. Lakshminarayanan et al.50 proposed a simple alternative to Bayesian NNs that requires minimal hyperparameter tuning while yielding high-quality predictive uncertainty estimates. Valdenegro-Toro et al.51 suggested deep sub-ensembles as an alternative to deep ensembles, ensembling only the layers near the output rather than the entire model. Bayesian methods use a statistical framework to model uncertainty. Numerous innovative uncertainty-aware methods have been developed, including new model architectures, loss functions, and training procedures for capturing uncertainty52. Handling uncertainty is crucial for building precise and trustworthy machine learning systems. Kuleshov et al.53 proposed a simple approach to calibrate the regression algorithm. Liu et al.54 introduced a Bayesian Deep learning method to investigate the impact of inflow uncertainty on reservoir operation rules, considering both model parameter uncertainty and inflow uncertainty. Many high-performing deep learning models currently in use are non-Bayesian and do not offer uncertainty estimates. Upadhyay et al.55 addressed these issues with BayesCap, which involves learning a Bayesian identity mapping for the frozen model to provide uncertainty estimation. Dropout can be seen as a Bayesian approximation, with the dropout rate reflecting the model’s uncertainty56. Dropout offers a practical and cost-effective method for Active Learning by using dropout at test time as Monte Carlo sampling to model pixel-wise uncertainty and analyze image information, thereby enhancing training performance. Test-time data augmentation involves applying various techniques to generate diverse versions of input data during model prediction. Molchanov et al.57 introduced greedy policy search (GPS), a simple but effective method for learning a policy of test-time augmentation. Kim et al.58 conducted research on test-time augmentation at the instance level to select suitable transformations, along with an additional module designed for predicting the loss. The objective of our research is to address the issue of distillation gaps that emerge when utilising large teacher models, with a particular emphasis on the discrepancy in predictive confidence between teacher and student models. It is observed that while larger teacher models frequently demonstrate elevated confidence in their predictions, student models encounter difficulties in attaining a comparable level of certainty. This discrepancy impedes effective knowledge transfer. It has been observed that existing techniques for aligning teacher-student confidence, when applied to very large models, become problematic. The increased complexity makes accurate normalisation difficult, resulting in suboptimal knowledge transfer. Our method directly addresses this issue by introducing category uncertainty weighting and adaptive temperature factors. These novel components enable more effective extraction of reliable knowledge from large teachers and enhance compatibility between heterogeneous model outputs.
Limitations on our works
Our method, while demonstrating promising results, faces several challenges that warrant further investigation. A key concern is the method’s strong dependence on the quality and performance of the teacher model. Given that LUD aims to transfer knowledge from the teacher to the student, any inherent biases or inaccuracies present in the teacher model risk being propagated to the student during the distillation process. This underscores the importance of selecting and training high-quality teacher models to ensure optimal knowledge transfer. Additionally, the performance of LUD exhibits sensitivity to hyperparameter selection, particularly the temperature range defined by Tmin and Tmax. The process of identifying optimal values for these parameters can be time-consuming and computationally intensive, potentially requiring extensive tuning to achieve the best results. Furthermore, while our experiments have shown favorable outcomes for certain model pairs, the generalizability of LUD across a broader spectrum of architectural designs and domains remains an open question. LUD may have limitations in scenarios with extremely small student models or when dealing with very noisy datasets. And the effectiveness of LUD relies on the quality and confidence of the teacher model’s predictions. If the teacher model is poorly calibrated or has low confidence across many classes, the benefits of uncertainty weighting may be limited. To fully assess the method’s robustness and versatility, it is crucial to conduct more comprehensive evaluations encompassing a wider array of network architectures and application domains beyond those explored in the current study. We believe that acknowledging these limitations provides a more balanced view of our method and can guide future research directions.
Discussions on practical application of science and engineering
Knowledge distillation enables deploying efficient models on resource-constrained devices and in real-time processing scenarios. This is particularly relevant for applications like mobile vision, edge computing, and IoT systems where model size and latency are critical. Our approach enables deep neural networks to be of better and better interest for edge devices, which is of practical value for many scientific and engineering fields that require deep neural networks. Some key areas include:
Mobile and edge computing: LUD can compress large models for deployment on resource-constrained devices, enabling advanced AI capabilities on smartphones or IoT devices.
Medical imaging: In applications like X-ray analysis, LUD can distill complex models into smaller ones suitable for real-time diagnosis in clinical settings.
Autonomous vehicles: LUD can help compress large perception models for real-time object detection and decision-making within the limited computational resources of a vehicle.
Robotics: LUD can enable the deployment of sophisticated control policies on robots with limited onboard computing power.
The aforementioned examples demonstrate the efficacy of knowledge distillation in bridging the gap between large, high-performance models and the practical constraints associated with their deployment across a range of engineering and scientific disciplines. Furthermore, our approach, LUD, has the potential to facilitate a variety of application scenarios.
Methods: logits uncertainty distillation
Reviewing logits knowledge distillation
Logits knowledge distillation aims to transfer the class-based predictions of a teacher model to a student network. Given a classification dataset with inputs \(\{x_i\}_{i=1}^{N}\) and one-hot labels \(\{y_i\}_{i=1}^{N}\), a teacher model T produces logits (pre-softmax activations) \(\{z_i^T\}_{i=1}^{N}\), which represent the unnormalized class probabilities.
Instead of directly minimizing the traditional cross-entropy loss \(-\log p(y_i|x_i)\), the student model S learns to match its own logits \(\{z_i^S\}_{i=1}^{N}\) to the softened teacher probabilities. The teacher probabilities are computed as:
where \(\tau\) is a temperature hyperparameter controlling the softness. The objective function is:
Adding this loss during training encourages the student to not only fit the training targets but also emulate traits of the teacher’s generalized knowledge beyond the training labels. Logits distillation has been widely used due to its simplicity and effectiveness.
Uncertainty in knowledge distillation
Neural networks do not provide confidence estimates and may suffer from overconfidence or under-confidence issues. The informativeness of each training sample is different. We use uncertainty to measure the informativeness of each sample. Confidence-based is a common method to quantify uncertainty. And it is measured as follows:
In knowledge distillation, the confidence of a teacher model’s predictions provides valuable information about category uncertainty. For a classification task with C classes, the teacher’s normalized softmax output for sample x can be represented as:
Where \(z_c^T(x)\) is the unnormalized logit for class c, and \(\tau\) is the temperature. The confidence of each prediction can be simply quantified by the maximum value in the predicted results of the teacher model:
This uncertainty provides important information for distillation - predictions with low confidence, i.e. high uncertainty, may not be reliably learned by the student. Therefore, category uncertainty can be accounted for to improve distillation by discounting uncertain classes based on confidence weighting. This allows the teacher to guide the student more selectively towards confident predictions.
Adaptive uncertainty distillation
Our methodology employs a range of techniques with the objective of optimising the knowledge distillation process. Our approach, Logits Uncertainty Distillation (LUD), introduces several key innovations that address critical gaps in existing knowledge distillation methods. First, we introduce category uncertainty weighting to account for uncertainty in the teacher model’s predictions. This allows us to focus on more reliable and confident predictions during distillation, addressing the challenge of transferring knowledge from complex teacher models to simpler student models. Second, we incorporate two Spearman correlation-based loss functions (CDL and SDL) to align the logits of teacher and student models at both category and sample levels. This novel approach ensures a more comprehensive transfer of knowledge. And then, we introduce adaptive dynamic temperature factors, which optimize the distillation process by adjusting the temperature based on the similarity between teacher and student logits. These innovations collectively address the gaps in handling model uncertainty, aligning logits across different architectures, and adapting the distillation process dynamically. Subsequently, the overall loss is determined. Figure 1 shows the overall framework of Logits Uncertainty Distillation. By incorporating category uncertainty weighting and Spearman correlation-based loss functions, our approach effectively transfers knowledge from the teacher model to the student model, enabling the student model to achieve comparable performance while having a smaller model size.
The detailed calculation method is as follows: Firstly, the concept of category uncertainty weighting is introduced as a means of addressing the distillation gap caused by differences in teacher and student architectures. In particular, the initial step is to obtain a set of data and calculate the confidence vector using the teacher model. Subsequently, a threshold is determined by taking the median of the confidence vector, and a mask is constructed accordingly. For each data point in the dataset, if the confidence value is greater than the threshold, the corresponding element in the mask is set to 1; otherwise, it is set to 0. This mask is then incorporated into the calculation of the loss function using the following formula:
Where \(mask_i\) represents the mask value for the i-th data, and \(Conf_i\) denotes the confidence predicted by the teacher model for the i-th data. The function \(med\{\cdot \}\) denotes the computation of the median value.
Additionally, to align the dimensionality of the logits, we incorporate the distinct Spearman correlation-based loss functions in addition to the cross-entropy loss between the student model’s output and the ground truth. These loss functions measure the discrepancy between the logits of the teacher and student models.
Spearman correlation coefficient Distillation Loss (\(D_{scc}\)): We calculate the distillation distance function based on the Spearman correlation coefficient (SCC) between node embeddings. The computation is done using Eq. (7):
Here, \(\textrm{R}({\textbf{x}}_i)\) and \(\textrm{R}({\textbf{y}}_i)\) are the ranks of \({\textbf{x}}_i\) and \({\textbf{y}}_i\), and \(\mathrm{{\overline{R}}}({\textbf{x}})\) and \(\mathrm{{\overline{R}}}({\textbf{y}})\) are the average ranks. This method robustly measures correlations, capturing intra-batch relationships and connections between sample nodes and class centers.
Category Distillation Loss (\({\mathscr {L}}_{\text {CDL}}\)): Based on category consistency, this loss is computed as:
Here, \({\mathscr {L}}_{\text {CDL}}\) represents the category distillation loss, \(D_{scc}\) denotes the Spearman correlation, and \(p^S(x)\) and \(p^T(x)\) are the softmax outputs of the student and teacher models, respectively.
Sample Distillation Loss (\({\mathscr {L}}_{\text {SDL}}\)): This loss relies on batch consistency and can be calculated as:
Here, \({\mathscr {L}}_{\text {SDL}}\) denotes the sample distillation loss, \(D_{scc}\) represents the Spearman correlation, and \(p^S(x)\) and \(p^T(x)\) denote the softmax outputs of the student and teacher models, respectively.
To prevent the negative impact of uncertain teacher model predictions on the student model’s performance, we apply the aforementioned mask when the teacher model exhibits low confidence in its predictions. This sets the category consistency-based and sample distillation loss functions to zero in such cases.
The adaptive dynamic temperature factors are used in the methodology. The temperature matrix is computed based on the Spearman correlation between teacher and student logits. This correlation is mapped to a predefined temperature range (\(T_{\min }\) to \(T_{\max }\)) using a non-linear function. And this mapping is calculated as below formula:
where \(\rho _{ij}\) is the Spearman correlation for class i and sample j. This dynamic adjustment of temperature during distillation enables more effective knowledge transfer, particularly when there are architectural differences between teacher and student models.
The overall loss function of our knowledge distillation approach is given by:
Where \({\mathscr {L}}_{\text {CE}}\) is the cross-entropy loss between the student model’s output and the ground truth, \({\mathscr {L}}_{\text {LUD}}\) is the logits uncertainty distillation loss, \({\mathscr {L}}_{\text {CDL}}\) is the category distillation loss, \({\mathscr {L}}_{\text {SDL}}\) is the sample distillation loss, and \(\lambda _{\text {CDL}}\), and \(\lambda _{\text {SDL}}\) are hyperparameters that control the relative importance of each loss term.
In the methods section, we provide a detailed account of the procedures to be followed in order to implement uncertainty-based knowledge distillation. The following section presents a summary of the contributions made by this paper.
Conclusion
In conclusion, our LUD addresses the challenge of output gaps between teacher and student models in knowledge distillation. By examining the teacher’s outputs, we identify that categories with high confidence contribute more to effective distillation, while uncertain categories have a less impact. To bridge this gap, we introduce output entropy weighting, which emphasizes high-confidence categories while reducing the negative influence of uncertain ones. Additionally, we align the full-dimensional logits using Spearman correlation loss and adaptively adjust the temperature coefficient during training. These techniques enhance the compatibility between teacher and student outputs, improving the overall knowledge transfer process. Experimental results on various benchmarks demonstrate that the proposed approach outperforms traditional distillation methods. The entropy weighting enables the extraction of reliable knowledge from the teacher, while adaptive temperature tuning further enhances compatibility. These contributions collectively establish uncertainty distillation as an effective technique for mitigating output mismatches in heterogeneous model pairs. The achieved state-of-the-art results validate the effectiveness of this approach, showcasing its potential for improving knowledge distillation performance.
Data availability
The datasets used and analyzed during the current study are available in the CIFAR (http://www.cs.toronto.edu/ kriz/cifar-100-python.tar.gz) and ImageNet public repository (https://image-net.org/download-images.php). The code implementation of our method will be made available on GitHub [https://anonymous.4open.science/r/lud-B36B/] upon publication of this paper. The raw experimental data, including training logs, evaluation metrics, and intermediate model checkpoints, are available from the corresponding author on reasonable request.
References
Li, H., Kadav, A., Durdanovic, I., Samet, H. & Graf, H. P. Pruning filters for efficient convnets. In ICLR (2017).
Hu, J. et al. Squeeze-and-excitation networks. In CVPR, 7132–7141 (2018).
Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. Preprint at http://arxiv.org/abs/1503.02531 (2015).
Tian, Y., Krishnan, D. & Isola, P. Contrastive representation distillation. In ICLR (2020).
Romero, A. et al. Fitnets: Hints for thin deep nets. In ICLR (2015).
Zagoruyko, S. & Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In ICLR (2017).
Tung, F. & Mori, G. Similarity-preserving knowledge distillation. In ICCV (2019).
Peng, B. et al. Correlation congruence for knowledge distillation. In ICCV (2019).
Ahn, S., Hu, S. X., Damianou, A., Lawrence, N. D. & Dai, Z. Variational information distillation for knowledge transfer. In CVPR (2019).
Park, W., Lu, Y., Cho, M. & Kim, D. Relational knowledge distillation. In CVPR (2019).
Passalis, N. & Tefas, A. Learning deep representations with probabilistic knowledge transfer. In ECCV (2018).
Heo, B. et al. A comprehensive overhaul of feature distillation. In ICCV, 1921–1930 (2019).
Yim, J., Joo, D. & Bae, J. & Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In CVPR (2017).
Huang, Z. & Wang, N. Like what you like: Knowledge distill via neuron selectivity transfer. Preprint at http://arxiv.org/abs/1707.01219 (2017).
Yang, J. et al. Knowledge Distillation Via Softmax Regression Representation Learning. In ICLR (2021).
Huang, T., You, S., Wang, F., Qian, C. & Xu, C. Knowledge distillation from a stronger teacher. Preprint at http://arxiv.org/abs/2205.10536 (2022).
Wei, Z. et al. Convformer: Closing the gap between cnn and vision transformers. Preprint at http://arxiv.org/abs/2209.07738 (2022).
Qin, J., Wu, J., Xiao, X., Li, L. & Wang, X. Activation modulation and recalibration scheme for weakly supervised semantic segmentation. In AAAI (2022).
Wei, Z. et al. Tvt: Training-free vision transformer search on tiny datasets. Preprint at http://arxiv.org/abs/2311.14337 (2023).
Dong, P. et al. Rd-nas: Enhancing one-shot supernet ranking ability via ranking distillation from zero-cost proxies. Preprint at http://arxiv.org/abs/2301.09850 (2023).
Dong, P. et al. Progressive meta-pooling learning for lightweight image classification model. In ICASSP (2023).
Dong, P. et al. Emq: Evolving training-free proxies for automated mixed precision quantization. In ICCV (2023).
Li, L. & Li, A. A2-aug: Adaptive automated data augmentation. In ICCV (2023).
Li, L., Jin, Z. Shadow knowledge distillation: Bridging offline and online knowledge transfer. In NeuIPS (2022).
Li, L., Dong, P., Li, A. & Wei, Z., & Yang, Y. Evolving knowledge distiller for any teacher-student pairs. In NeuIPS, Kd-zero (2024).
Li, L. Self-regulated feature learning via teacher-free feature distillation. In ECCV (2022).
Li, L. et al. Explicit connection distillation. In ICLR (2020).
Dong, P. & Li, L. & Wei, Z. Student architecture search for distillation without training. In CVPR, Diswot (2023).
Hu, Y., Wang, X., Li, L. & Gu, Q. Improving one-shot nas with shrinking-and-expanding supernet. Pattern Recognit. (2021).
Dong, P. et al. Prior-guided one-shot neural architecture search. Preprint at http://arxiv.org/abs/2206.13329 (2022).
Lu, L. et al. Uniads: Universal architecture-distiller search for distillation gap. In AAAI (2024).
Zimian Wei, Z. et al. Auto-prox: Training-free vision transformer architecture search via automatic proxy discovery. In AAAI (2024).
Zhu, C., Li, L. & Wu, Y. & Sun, Z. Real-time semantic segmentation architecture search without training. In AAAI, Saswot (2024).
Dong, P. et al. Parzc: Parametric zero-cost proxies for efficient nas. Preprint at http://arxiv.org/abs/2402.02105 (2024).
Chen, K. et al. Gp-nas-ensemble: a model for the nas performance prediction. In CVPRW (2022).
Xiaolong, L., Lujun, L. & Chao, L. & Yao, A. Knowledge distillation via n-to-one representation matching. In ICLR, Norm (2023).
Li, L., Shiuan-Ni, L., Yang, Y. & Jin, Z. Boosting online feature transfer via separable feature fusion. In IJCNN (2022).
Li, L., Shiuan-Ni, L., Yang, Y. & Jin, Z. Teacher-free distillation via regularizing intermediate representation. In IJCNN (2022).
Shao, S. et al. Catch-up distillation: You only need to train once for accelerating sampling. Preprint at http://arxiv.org/abs/2305.10769 (2023).
Li, L., Dong, P., Wei, Z. & Yang, Y. Automated knowledge distillation via monte carlo tree search. In ICCV (2023).
Bucila, C., Caruana, R. & Niculescu-Mizil, A. Model compression. In KDD (2006).
Chen, Y. et al. Darkrank: Accelerating deep metric learning via cross sample similarities transfer. In AAAI, vol. 32 (2018).
Peng, B. et al. Correlation congruence for knowledge distillation. In Int. Conf. Comput. Vis. (2019).
Zhu, J. et al. Complementary relation contrastive distillation. In CVPR, 9260–9269 (2021).
Xu, G. et al. Knowledge distillation meets self-supervision. In ECCV, 588–604 (Springer, 2020).
Chen, Z. et al. Improving knowledge distillation via category structure. In ECCV, 205–219 (Springer, 2020).
Li, X. et al. Local correlation consistency for knowledge distillation. In ECCV, 18–33 (Springer, 2020).
Kim, Y. et al. Distilling global and local logits with densely connected relations. In ICCV, 6290–6300 (2021).
Bai, Q. et al. Glead: Improving gans with a generator-leading task. In IEEE Conf. Comput. Vis. Pattern Recog. (2023).
Lakshminarayanan, B., Pritzel, A. & Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. In NIPS (2017).
Valdenegro-Toro, M. Deep sub-ensembles for fast uncertainty estimation in image classification. In Bayesian Deep Learning Workshop at Neural Information Processing Systems 2019 (2019).
Gustafsson, F. K., Danelljan, M. & Schön, T. B. Evaluating scalable Bayesian deep learning methods for robust computer vision. abs/1906.01620 (2019).
Kuleshov, V., Fenner, N. & Ermon, S. Accurate uncertainties for deep learning using calibrated regression. In International Conference on Machine Learning, 2796–2804 (PMLR, 2018).
Liu, Y. et al. Deriving reservoir operation rule based on Bayesian deep learning method considering multiple uncertainties. J. Hydrol. 579, 124207 (2019).
Upadhyay, U., Karthik, S., Chen, Y., Mancini, M. & Akata, Z. Bayescap: Bayesian identity cap for calibrated uncertainty in frozen neural networks. In ECCV (2022).
Gomez, A. N. et al. Learning sparse networks using targeted dropout. Preprint at http://arxiv.org/abs/1905.13678 (2019).
Molchanov, D., Lyzhov, A., Molchanova, Y., Ashukha, A. & Vetrov, D. Greedy policy search: A simple baseline for learnable test-time augmentation. Preprint at http://arxiv.org/abs/2002.09103, 2 (2020).
Kim, I., Kim, Y. & Kim, S. Learning loss for test-time augmentation. Adv. Neural. Inf. Process. Syst. 33, 4163–4174 (2020).
Acknowledgements
This work is supported by the National Key R&D Program of China (2022YFC3302100).
Author information
Authors and Affiliations
Contributions
Z.G. and P.Z. conceived the experiment(s), Z.G. drafted the manuscript, Z.G. and D.W. conducted the experiment(s), Z.G. and Q.H. analysed the results. P.Z. advised on model designs/experiments. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Guo, Z., Wang, D., He, Q. et al. Leveraging logit uncertainty for better knowledge distillation. Sci Rep 14, 31249 (2024). https://doi.org/10.1038/s41598-024-82647-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-82647-6
