
Abstract
Hypertension combined with hyperhomocysteinemia significantly raises the risk of ischemic stroke. Our study aimed to develop and validate a biomarker-based prediction model for ischemic stroke in Hyperhomocysteinemia-type (H-type) hypertension patients. We retrospectively included 3,305 patients in the development cohort, and externally validated in 103 patients from another cohort. Logistic regression, least absolute shrinkage and selection operator regression, and best subset selection analysis were used to assess the contribution of variables to ischemic stroke, and models were derived using four machine learning algorithms. Area Under Curve (AUC), calibration plot and decision-curve analysis respectively evaluated the discrimination and calibration of four models, then external validation and visualization of the best-performing model. There were 1,415 and 42 patients with ischemic stroke in the development and validation cohorts. The final model included 8 predictors: age, antihypertensive therapy, biomarkers (serum magnesium, serum potassium, proteinuria and hypersensitive C-reactive protein), and comorbidities (atrial fibrillation and hyperlipidemia). The optimal model, named A2BC ischemic stroke model, showed good discrimination and calibration ability for ischemic stroke with AUC of 0.91 and 0.87 in the internal and external validation cohorts. The A2BC ischemic stroke model had satisfactory predictive performances to assist clinicians in accurately identifying the risk of ischemic stroke for patients with H-type hypertension.
Similar content being viewed by others

Introduction
Due to its high incidence, recurrence, mortality, and disability rates, stroke continues to be the second leading cause of death worldwide, according to the Global Burden of Disease Study (GBD) 20191. Intravenous thrombolysis and endovascular thrombectomy are the main treatments for ischemic stroke at the moment2. A limited therapeutic window presents a significant challenge for nations with insufficient or unbalanced medical resources3. Therefore, the best way to lessen the burden of stroke is early prevention.
More than half of ischemic stroke patients are diagnosed with hypertension, making it one of the most significant modifiable risk factors for stroke4. Additionally, there is a causal relationship between homocysteine (Hcy) concentration and stroke5. The prevalence of hyperhomocysteinemia (HHcy) is about 3 / 4 of the hypertension population in China. H-type hypertension is defined as hypertension combined with elevated Hcy level6. Surprisingly, vascular damage is worsened by a synergistic effect between Hcy and hypertension7. The above suggests that H-type hypertension patients should be focused on monitoring the risk of ischemic stroke.
The Framingham stroke risk profile (FSP) and CHA2DS2-VASc score are widely used to assess the risk of stroke in general population and and nonvalvular atrial fibrillation (AF) patients8,9. However, there are few validated tools available for assessing the risk of ischemic stroke in patients with H-type hypertension. Clinicians typically manage high-risk population in the cardiovascular field using a combination of demographics characteristics and medical history, along with some laboratory indicators. By employing this strategy, our study aims to screen out high-risk groups for ischemic stroke, develop and validate a high-performance prediction model for ischemic stroke in patients with H-type hypertension, and facilitate further risk stratification management by clinicians for patients.
Results
Baseline characteristics
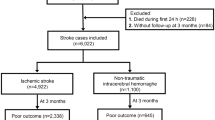
According to the inclusion and exclusion criteria, among the 11,631 patients diagnosed with H-type hypertension at Beijing Anzhen Hospital from January 2022 and December 2023, 4,632 suffered an ischemic stroke. A total of 3,305 had medical records in same hospital between January 2018 and December 2021, and 2,340 were assigned to the training set and 965 to the testing set (Supplementary Fig. 1). Another 103 H-type hypertension patients, including 61 patients without ischemic stroke and 42 patients with ischemic stroke, were enrolled as an external validation cohort from the China-Japan Friendship Hospital (Supplementary Fig. 2). Detailed information about the characteristics of patients in the total cohort, training, and internal validation sets are shown in Table 1 and Supplementary Table 1, respectively. As shown in Table 1, patients with ischemic stroke were older with higher SBP and had a higher proportion of smokers and a history of cardiovascular disease (all P < 0.05) as compared to non-stroke patients.
Predictor selections
There were 16 variables with P < 0.05 by univariate logistic regression (Supplementary Table 2). After stepwise regression, 13 variables were ultimately retained, namely, age, antihypertensive therapy, hyperlipidemia, atrial fibrillation (AF), diabetes mellitus (DM), BMI, SBP, DBP, hs-CRP, K, Mg, Hcy and proteinuria. In best subset selection regression, when the model included eight variables, the BIC of the model reached its minimum. These eight variables were age, antihypertensive therapy, hyperlipidemia, AF, hs-CRP, K, Mg, and proteinuria, respectively (Fig. 1A and B). In LASSO regression, 17 variables were selected with a lambda that is within 1 standard error (SE), namely age, gender, antihypertensive therapy, antiplatelet therapy, hyperlipidemia, AF, DM, coronary artery disease (CAD), BMI, SBP, DBP, hs-CRP, K, Mg, Hcy, proteinuria and carotid artery stenosis (Fig. 1C and D). Eventually, eight variables were included to develop models: age, antihypertensive therapy, hyperlipidemia, AF, hs-CRP, K, Mg, and proteinuria (Fig. 2).

Best subset selection regression and LASSO regression for the selection of variables. (A) Variation of BCI with the change of model size. (B) Features included when BIC reaches its minimum value. (C) Coeffificient of each variable in LASSO regression with the change of log lambda. First vertical dotted line: l value (lambda min) when binomial deviance was minimum. Second vertical dotted line: lambda min + 1se (lambda 1se). (D) Variation of binomial deviance with the change of log lambda in LASSO regression. First vertical dotted line: l value (lambda min) when binomial deviance was minimum. Second vertical dotted line: lambda min + 1se (lambda 1se).

The common variables were confirmed by all three feature selection methods: stepwise regression, LASSO regression, and best subset selection regression.
Model development and validation
Eight variables were entered into a multivariable logistic regression model, linear kernel SVM model, random forest model, and XGBoost model, respectively. Four models yielded the AUC of 0.905 (95% CI: 0.887–0.924), 0.896 (95% CI: 0.876–0.915), 0.893 (95% CI: 0.872–0.914), 0.909 (95% CI: 0.890–0.927) for the risk of ischemic stroke (Fig. 3; Table 2). The difference of AUC between logistic regression model and XGBoost model was not significant (DeLong test, P = 0.406). Based on the maximal Youden’s index, the threshold of four models were 55%, 46%, 37%, and 43% in order. The XGBoost model had the highest sensitivity, 0.825, with a specificity of 0.860.

Discrimination of the four models. Receiver operating characteristic (ROC) curves of the four models with AUC and 95% CI.
Calibration plots were used to assess the calibration of models. As shown in Fig. 4, four models had a good calibration. Among them, the predicted odds of the outcome of the logistic regression model and XGBoost model were close to the actual probability (Fig. 4A and D). Four models resulted in a high net benefit, especially the logistic regression model and XGBoost model (Fig. 5). Conclusively, the logistic regression model and XGBoost model exhibited excellent discrimination and calibration performance. Considering the visualization and scalability of the prediction model, we ultimately chose the logical regression model as the optimal model. The weight coefficients of eight variables in the logistic regression model was shown in Supplementary Fig. 3. Serum magnesium, serum potassium, AF, and hyperlipidemia have a higher weight in the optimal model.

Calibration of the four models. (A) Logistic model. (B) SVM model. (C) random forest model. (D) XGBoost model.

Decision-curve analysis of the four models. Decision curves of the four models showing the net benefit of using each model according to different threshold probabilities in the internal validation cohort.
In the external cohort, the logistic regression model achieved an AUC of 0.872 (95% CI: 0.805–0.939) showing good discrimination capacity (Supplementary Fig. 4 and Supplementary Table 3). The logistic regression model also was well-calibrated and had a high net benefit in the external cohort (Supplementary Figs. 5 and 6).
Model visualization
The eight variables: age (A), antihypertensive therapy (A), biomarkers (B) (serum magnesium, serum potassium, proteinuria, and hypersensitive C-reactive protein), comorbidities (C) (atrial fibrillation and hyperlipidemia) were fitted a logistic regression model to predict the risk of ischemic stroke in H-type hypertension patients was termed the A2BC ischemic stroke model and presented as a nomogram (Fig. 6). The variables were listed separately, and the cumulative score is matched to a risk score.

Nomogram of the optimal model. The probability of ischemic stroke in patients with H-type hypertension. The clinical indicators were placed on each variable axis, and the vertical line was drawn from that value to the top points scale for calculating the score for each predictor. The total scores from each variable value represent the possibility of ischemic stroke in patients with H-type hypertension.
Discussion
Based on two independent retrospective cohorts with a large sample size, our study developed and internally and externally validated a model to predict the risk of ischemic stroke. This model included 8 variables: age (A), antihypertensive therapy (A), biomarkers (B) (serum magnesium, serum potassium, proteinuria, and hypersensitive C-reactive protein), comorbidities (C) (atrial fibrillation and hyperlipidemia), which termed the A2BC ischemic stroke model. The A2BC ischemic stroke model showed great discrimination and calibration for the risk of ischemic stroke, with similar findings when externally validated.
At present, the most effective treatment of acute ischemic stroke (AIS) is reperfusion therapy in therapeutic time window, including intravenous thrombolysis (IVT) and endovascular therapy (EVT), but about 3/4 patients present over 4.5 h after stroke onset or with an unknown time of onset10. Besides, there are numerous contraindications associated with IVT that must be carefully considered11. The rates of IVT and EVT were 5.64% and 1.45% between 2019 and 2020 in China12. Recurrent ischemic stroke is another challenge even with improved secondary prevention, recurrence rates of ischemic stroke seem unchanged over time13. Because of above all, primary prevention of high-risk population may be another effective way to improve the burden of ischemic stroke. However, there is an unmet need for accurate and validated models for estimating risk of ischemic stroke.
Some guidelines propose FSP as a reliable tool for 10-year stroke risk estimates14. Despite its widespread application, the validity of the FSP has not been sufficiently studied in populations with different age range or ethnicity. A prospective study showed that FSP overestimates the risk of stroke in Chinese15. In the same way, both the CV risk calculator and Stroke Riskometer need to be validated and adapted in the Chinese population16,17. Also, although most risk factors have an independent effect on ischemic stroke, interactions may exist between these factors when considering predicting overall risk. A combined analysis of hypertension and Hcy showed they act additively to increase the risk of stroke22. Therefore, it is necessary to establish a prediction model for ischemic stroke specific to the H-type hypertension subset. One of the purposes of risk assessment is to guide an appropriate primary prevention program. Additional folic acid significantly reduces the risk of first stroke in hypertension patients, compared with antihypertensive therapy alone18.
Serum magnesium, an inorganic ion, is given the most weight in our model, and serum potassium is also significant. Magnesium and potassium are crucial trace elements for organisms, as we all know. Magnesium helps to prevent ischemic stroke. Through various mechanisms, it lowers blood pressure more effectively than potassium19. Inflammation, endothelial dysfunction, and platelet dysfunction have all been linked to low magnesium levels20. Stroke risk was 2.5 times higher for diuretic users with low serum potassium than for those with high serum potassium21. When compared to adults receiving antihypertensive therapy, hypokalemia is independently associated with an increased risk of ischemic stroke and is unrelated to diuretics.
Dyslipidemia is an independent risk factor for stroke22. The risk of an ischemic stroke can be decreased by lowering atherogenic lipoproteins23,24. New lipid-lowering medications have made it possible to lower LDL-C to extremely low levels, but doing so will raise the risk of hemorrhagic stroke25. A significant risk factor for stroke is AF. Hypertrophic hypertensive cardiac disease complicated by AF is the most frequent cardiac source of emboli in cardioembolic stroke26.A thrombus from the left atrial (LA) cavity, particularly the left atrial appendage (LAA), is primarily responsible for ischemic stroke associated with AF27. Plasma Hcy levels were found to be associated with LA/LAA thrombus and could be used to predict the risk of LA/LAA thrombus in non-valvular AF patients with low CHA2DS2-VASc scores28.
Numerous studies have demonstrated that hypertension can cause cerebrovascular diseases through a variety of mechanisms, including adapting automatic regulation of cerebral blood flow (CBF) to hypertension29, endothelial dysfunction, reduction of nitric oxide (NO)30, elevated levels of angiotensin II (Ang II) leading to cerebral artery hypertrophy and inward remodeling31. Fortunately, the negative effects of hypertension can be offset by a variety of antihypertensive medications. Using long-lasting dihydropyridine-Ca2+ channel blocker attributes to the normalization of autoregulation of CBF32. Similarly, other types of antihypertensive drugs also have this effect33. Additionally, combining antihypertensive medications in suboptimal doses can establish tolerance and effectively treat the remodeling of cerebral arteries brought on by hypertension34.
Proteinuria, the other factor in our model, is a common sign of renal damage and has a particularly strong association with stroke35,36. Researchers have proposed the term “cerebro-renal interaction” because kidney disease and cerebrovascular disease are closely related37. The above can be explained by the idea that increased urinary protein excretion rate may be connected to significant vascular damage38. According to epidemiological studies, people over 65 account for the majority of stroke cases, and the risk rises with age39,40. Variety in circulation factors in the systemic environment, cellular senescence, and hypertension during human aging can all increase the risk of stroke41.
The A2BC ischemic stroke model consists of 8 general variables, which are simple to collect in clinical practice, there is no need to take into account specialized examination equipment and technical personnel, allowing community hospitals to conduct rapid screening and significantly saving medical resources. Our study had some limitations as well. First, the differences between various ischemic stroke subtypes have not been considered. Hypertension is the primary cardiovascular risk factor for cerebral infarction only for lacunar strokes and atherothrombotic infarctions, that is, ischemic stroke associated with small and large artery disease42. Building upon the findings of this study, future research could confirm these results in the different ischemic stroke subtypes, particularly lacunar infarcts with hypertension and diabetes as the main risk factors43. Second, certain H-type hypertension-specific risk factors for ischemic stroke, like MTHFR polymorphism, have not been studied. However, not many community hospitals in China offer MTHFR polymorphism detection services. Third, since our research was a retrospective study and the prediction model created by the machine learning algorithm was just a reflection of mathematical logic, there was no causal relationship. Therefore, even though we have demonstrated the model’s good performance on an external validation cohort, more clinical data and prospective queues were required to improve the model’s performance in specific clinical application scenarios. Fourth, we excluded secondary hypertension in patients with H-type hypertension, as the causes of secondary hypertension are diverse, and the predictive factors are complex. Therefore, our model cannot be used for secondary hypertension patients with elevated Hcy levels. Finally, the clinical efficacy of Hcy reduction therapy in primary and secondary ischemic stroke prevention is still controversial. Identifying individuals who respond effectively to Hcy reduction treatment and implementing precision therapy—including optimized dosage, duration, combination with other drugs, and consideration of genotype—are crucial for reducing stroke risk in high-risk populations. Achieving these goals relies on an accurate and reliable risk prediction model.
Materials and methods
Study population
This retrospective cohort study consecutively included inpatients diagnosed with H-type hypertension, whether or not they suffered first ischemic stroke, at Beijing Anzhen Hospital, Capital Medical University from January 2022 to December 2023. Patients with secondary hypertension or a history of ischemic stroke would be excluded. These patients would also be excluded if they lack data in Beijing Anzhen Hospital from January 2018 to December 2021. Meanwhile, we extracted an external validation cohort from the China-Japan Friendship Hospital between January 2023 and June 2023.
Patients with hypertension were diagnosed according to the International Society of Hypertension recommendations44. Systolic blood pressure (SBP) in the office or clinic was ≥ 140 mmHg and/or diastolic blood pressure (DBP) was ≥ 90 mmHg following repeated examinations were considered as hypertension. In addition, the guideline also suggested that blood pressure < 140 / 90 mmHg in patients with a history of hypertension and currently using antihypertensive drugs were still diagnosed as hypertension. Patients with essential hypertension were identified when secondary hypertension was excluded. Hypertension patients, together with serum Hcy concentrations ≥ 10 µmol/L, were identified as H-type hypertension45. Ischemic stroke was confirmed via computed tomography (CT) or brain magnetic resonance imaging (MRI) combined with clinical symptoms and signs. Our study was conducted according to the Declaration of Helsinki and was approved by the hospital’s ethical review board (Beijing Anzhen Hospital, Capital Medical University, Beijing, China). The need to obtain informed consent was waived by the ethical review board of Beijing Anzhen Hospital, Capital Medical University.
Data collection
According to literature research, 23 candidate variables associated with stroke were enrolled in the study. Clinical characteristics including age, gender, smoking, drinking, SBP, DBP, body mass index (BMI), medical history and history of drug and results of carotid ultrasonography were collected from the hospital information system (HIS). Hypersensitive C-reactive protein (hs-CRP), serum potassium (K), serum sodium (NA), serum magnesium (Mg), total bilirubin (TBil), and direct bilirubin (DBiL) were detected by the automatic biochemical analyzer (Roche Cobas C702). Proteinuria was analyzed by the automatic urine analyzer (Mindray UA-5800). All laboratory tests were the first test results during the hospitalization and were collected from the laboratory information system (LIS).
Model development, validation, and statistical analysis
Our study was reported according to TRIPOD (Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis) statement (TRIPOD checklist). All statistical analyses were conducted with R software for macOS (Version 4.2.1, https://www.r-project.org/). Continuous variables were described with mean ± standard deviation (SD) or with median (25th − 75th quartile) for skewed data, compared using the Mann-Whitney test. Categorical variables were described with frequency and percentages and compared using χ2 tests. Variables with missing values > 20% were excluded. Multiple imputations were applied to variables missing < 2 0% using the R package mice, and one imputation result was finally used. Hcy was transformed into a categorical variable with 2 knots placed at 15 µmol/L and 30 µmol/L, the rest of the variables remained unchanged.
Patients from Beijing Anzhen Hospital, Capital Medical University were randomly divided into a training set and a testing set in a ratio of 70–30%. The Logistic regression, LASSO regression and best subset selection analysis were applied to filter features in the training cohort, respectively. In logistic regression, univariate regression was first performed for all variables, then statistically significant variables (P < 0.05) were selected for a bidirectional stepwise multivariate logistic regression analysis. In LASSO regression, the beta coefficients of variables that are not strongly associated with the outcome are decreased to zero, which removed these variables from the model. We applied 10-fold validation to obtain the suitable lambda (i.e., lambda.1se) and select the variables with non-zero coefficients. In best subset selection regression, variables in the regression with the minimum Bayesian information criterion (BIC) were selected. The models were fitted with the common features confirmed by three methods.
Prediction models were derived using four machine learning algorithms, including logistic regression, linear kernel support vector machine (SVM), random forest, and eXtreme gradient boosting (XGBoost). The AUC, calibration plot, and DCA were used to assess the discrimination and calibration performance of models. All P values are two-sided, with results < 0.05 considered significant.
Data availability
Some or all data sets generated and/or analyzed during the present study are not publicly available but are available from the corresponding author upon reasonable request.
References
Collaborators, G. B. D. S. Global, regional, and national burden of stroke and its risk factors, 1990–2019: A systematic analysis for the global burden of Disease Study 2019. Lancet Neurol. 20, 795–820. https://doi.org/10.1016/S1474-4422(21)00252-0 (2021).
Campbell, B. C. V. et al. Ischaemic stroke. Nat. Rev. Dis. Primers 5, 70. https://doi.org/10.1038/s41572-019-0118-8 (2019).
Barthels, D. & Das, H. Current advances in ischemic stroke research and therapies. Biochim. Biophys. Acta Mol. Basis Dis. 1866, 165260. https://doi.org/10.1016/j.bbadis.2018.09.012 (2020).
Caprio, F. Z. & Sorond, F. A. Cerebrovascular disease: Primary and secondary Stroke Prevention. Med. Clin. North. Am. 103, 295–308. https://doi.org/10.1016/j.mcna.2018.10.001 (2019).
Casas, J. P., Bautista, L. E., Smeeth, L., Sharma, P. & Hingorani, A. D. Homocysteine and stroke: Evidence on a causal link from mendelian randomisation. Lancet 365, 224–232. https://doi.org/10.1016/S0140-6736(05)17742-3 (2005).
Zhou, F., Hou, D., Wang, Y. & Yu, D. Evaluation of H-type hypertension prevalence and its influence on the risk of increased carotid intima-media thickness among a high-risk stroke population in Hainan Province, China. Med. (Baltim). 99, e21953. https://doi.org/10.1097/MD.0000000000021953 (2020).
Liu, Z. et al. Hyperhomocysteinemia exaggerates adventitial inflammation and angiotensin II-induced abdominal aortic aneurysm in mice. Circ. Res. 111, 1261–1273. https://doi.org/10.1161/CIRCRESAHA.112.270520 (2012).
Wolf, P. A., D’Agostino, R. B., Belanger, A. J. & Kannel, W. B. Probability of stroke: A risk profile from the Framingham Study. Stroke 22, 312–318. https://doi.org/10.1161/01.str.22.3.312 (1991).
Gage, B. F. et al. Selecting patients with atrial fibrillation for anticoagulation: Stroke risk stratification in patients taking aspirin. Circulation 110, 2287–2292. https://doi.org/10.1161/01.CIR.0000145172.55640.93 (2004).
Tong, D. et al. Times from symptom onset to hospital arrival in the get with the guidelines–Stroke Program 2002 to 2009: Temporal trends and implications. Stroke 43, 1912–1917. https://doi.org/10.1161/STROKEAHA.111.644963 (2012).
Hurford, R., Sekhar, A., Hughes, T. A. T. & Muir, K. W. Diagnosis and management of acute ischaemic stroke. Pract. Neurol. 20, 304–316. https://doi.org/10.1136/practneurol-2020-002557 (2020).
Ye, Q. et al. Rates of intravenous thrombolysis and endovascular therapy for acute ischaemic stroke in China between 2019 and 2020. Lancet Reg. Health West. Pac. 21, 100406. https://doi.org/10.1016/j.lanwpc.2022.100406 (2022).
Kolmos, M., Christoffersen, L. & Kruuse, C. Recurrent ischemic stroke - A systematic review and Meta-analysis. J. Stroke Cerebrovasc. Dis. 30, 105935. https://doi.org/10.1016/j.jstrokecerebrovasdis.2021.105935 (2021).
Goldstein, L. B. et al. Guidelines for the primary prevention of stroke: A guideline for healthcare professionals from the American Heart Association/American Stroke Association. Stroke 42, 517–584. https://doi.org/10.1161/STR.0b013e3181fcb238 (2011).
Huang, J. Y., Cao, Y. F. & JP, G. Modified Framingham Stroke Profile in the prediction of the risk of stroke among Chinese. Chin. J. Cerebrovasc. Dis. 10, 228–232 (2013).
Li, J. et al. H-type hypertension and risk of stroke in Chinese adults: A prospective, nested case-control study. J. Transl. Int. Med. 3, 171–178. https://doi.org/10.1515/jtim-2015-0027 (2015).
Goff, D. C. et al. Jr. ACC/AHA guideline on the assessment of cardiovascular risk: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. J. Am. Coll. Cardiol. 63, 2935–2959, (2013). https://doi.org/10.1016/j.jacc.2013.11.005 (2014).
Huo, Y. et al. Efficacy of folic acid therapy in primary prevention of stroke among adults with hypertension in China: The CSPPT randomized clinical trial. JAMA 313, 1325–1335. https://doi.org/10.1001/jama.2015.2274 (2015).
Houston, M. The role of magnesium in hypertension and cardiovascular disease. J. Clin. Hypertens. (Greenwich). 13, 843–847. https://doi.org/10.1111/j.1751-7176.2011.00538.x (2011).
Kupetsky-Rincon, E. A. & Uitto, J. Magnesium: Novel applications in cardiovascular disease–a review of the literature. Ann. Nutr. Metab. 61, 102–110. https://doi.org/10.1159/000339380 (2012).
Green, D. M. et al. Serum potassium level and dietary potassium intake as risk factors for stroke. Neurology 59, 314–320. https://doi.org/10.1212/wnl.59.3.314 (2002).
Alloubani, A., Nimer, R. & Samara, R. Relationship between hyperlipidemia, cardiovascular disease and stroke: A systematic review. Curr. Cardiol. Rev. 17, e051121189015. https://doi.org/10.2174/1573403X16999201210200342 (2021).
Jukema, J. W. et al. Effect of Alirocumab on Stroke in ODYSSEY OUTCOMES. Circulation 140, 2054–2062. https://doi.org/10.1161/CIRCULATIONAHA.119.043826 (2019).
Giugliano, R. P. et al. Stroke Prevention with the PCSK9 (Proprotein Convertase Subtilisin-Kexin type 9) inhibitor Evolocumab added to statin in high-risk patients with stable atherosclerosis. Stroke 51, 1546–1554. https://doi.org/10.1161/STROKEAHA.119.027759 (2020).
Ma, C. et al. Low-density lipoprotein cholesterol and risk of intracerebral hemorrhage: A prospective study. Neurology 93, e445–e457. https://doi.org/10.1212/WNL.0000000000007853 (2019).
Pujadas Capmany, R., Arboix, A. & Casanas-Munoz, R. Anguera-Ferrando, N. Specific cardiac disorders in 402 consecutive patients with ischaemic cardioembolic stroke. Int. J. Cardiol. 95, 129–134. https://doi.org/10.1016/j.ijcard.2003.02.007 (2004).
Yao, Y., Shang, M. S., Dong, J. Z. & Ma, C. S. Homocysteine in non-valvular atrial fibrillation: Role and clinical implications. Clin. Chim. Acta 475, 85–90. https://doi.org/10.1016/j.cca.2017.10.012 (2017).
Yao, Y. et al. Elevated homocysteine increases the risk of left atrial/left atrial appendage thrombus in non-valvular atrial fibrillation with low CHA2DS2-VASc score. Europace 20, 1093–1098. https://doi.org/10.1093/europace/eux189 (2018).
Pieniazek, W. & Dimitrow, P. P. [Autoregulation of cerebral circulation: Adaptation to hypertension and re-adaptation in response to antihypertensive treatment]. Przegl Lek. 63, 688–690 (2006).
Cipolla, M. J., Liebeskind, D. S. & Chan, S. L. The importance of comorbidities in ischemic stroke: Impact of hypertension on the cerebral circulation. J. Cereb. Blood Flow. Metab. 38, 2129–2149. https://doi.org/10.1177/0271678X18800589 (2018).
Umesalma, S., Houwen, F. K., Baumbach, G. L. & Chan, S. L. Roles of caveolin-1 in angiotensin II-induced hypertrophy and inward remodeling of cerebral pial arterioles. Hypertension 67, 623–629. https://doi.org/10.1161/HYPERTENSIONAHA.115.06565 (2016).
Ikeda, J., Yao, K. & Matsubara, M. Effects of benidipine, a long-lasting dihydropyridine-Ca2 + channel blocker, on cerebral blood flow autoregulation in spontaneously hypertensive rats. Biol. Pharm. Bull. 29, 2222–2225. https://doi.org/10.1248/bpb.29.2222 (2006).
Harper, S. L. Antihypertensive drug therapy prevents cerebral microvascular abnormalities in hypertensive rats. Circ. Res. 60, 229–237. https://doi.org/10.1161/01.res.60.2.229 (1987).
Dupuis, F. et al. Effects of suboptimal doses of the AT1 receptor blocker, telmisartan, with the angiotensin-converting enzyme inhibitor, ramipril, on cerebral arterioles in spontaneously hypertensive rat. J. Hypertens. 28, 1566–1573. https://doi.org/10.1097/hjh.0b013e328339f1f3 (2010).
Ninomiya, T. et al. Proteinuria and stroke: A meta-analysis of cohort studies. Am. J. Kidney Dis. 53, 417–425. https://doi.org/10.1053/j.ajkd.2008.08.032 (2009).
Kelly, D. M. & Rothwell, P. M. Proteinuria as an independent predictor of stroke: Systematic review and meta-analysis. Int. J. Stroke 15, 29–38. https://doi.org/10.1177/1747493019895206 (2020).
Hsieh, C. Y. & Sung, S. F. From kidney protection to stroke prevention: The potential role of Sodium glucose Cotransporter-2 inhibitors. Int. J. Mol. Sci. 24 https://doi.org/10.3390/ijms24010351 (2022).
Koga, M. Cerebrorenal interaction and stroke outcome. J. Atheroscler. Thromb. 25, 566–567. https://doi.org/10.5551/jat.ED091 (2018).
Benjamin, E. J. et al. Heart Disease and Stroke Statistics-2017 update: A Report from the American Heart Association. Circulation 135, e146–e603. https://doi.org/10.1161/CIR.0000000000000485 (2017).
Feigin, V. L., Lawes, C. M., Bennett, D. A. & Anderson, C. S. Stroke epidemiology: A review of population-based studies of incidence, prevalence, and case-fatality in the late 20th century. Lancet Neurol. 2, 43–53. https://doi.org/10.1016/s1474-4422(03)00266-7 (2003).
Wang, X. et al. Exosomes and Exosomal microRNAs in Age-associated stroke. Curr. Vasc. Pharmacol. 19, 587–600. https://doi.org/10.2174/1570161119666210208202621 (2021).
Arboix, A., Roig, H., Rossich, R., Martinez, E. M. & Garcia-Eroles, L. Differences between hypertensive and non-hypertensive ischemic stroke. Eur. J. Neurol. 11, 687–692. https://doi.org/10.1111/j.1468-1331.2004.00910.x (2004).
Arboix, A. et al. Clinical predictors of lacunar syndrome not due to lacunar infarction. BMC Neurol. 10 https://doi.org/10.1186/1471-2377-10-31 (2010).
Unger, T. et al. International Society of Hypertension Global Hypertension Practice Guidelines. Hypertension 75, 1334–1357, (2020). https://doi.org/10.1161/HYPERTENSIONAHA.120.15026 (2020).
Tan, Y. et al. Impact of H-Type hypertension on Intraplaque Neovascularization assessed by contrast-enhanced Ultrasound. J. Atheroscler Thromb. 29, 492–501. https://doi.org/10.5551/jat.61275 (2022).
Acknowledgements
This work was supported by the National Key Research and Development Program (2022YFC2009600) (2022YFC2009602).
Author information
Authors and Affiliations
Contributions
Study concept and design: Hui Yuan, Ke Chen. Data collection: Ke Chen, Jianxun He, Lan Fu, Xiaohua Song, Ning Cao. Data analysis and interpretation: Ke Chen, Jianxun He, Lan Fu, Xiaohua Song, Ning Cao. Drafting of the manuscript: Ke Chen, Hui Yuan. Critical revision of the manuscript: all authors. Final approval: all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, K., He, J., Fu, L. et al. Prediction of ischemic stroke in patients with H-type hypertension based on biomarker. Sci Rep 15, 1221 (2025). https://doi.org/10.1038/s41598-024-83662-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-83662-3
