
Abstract
In the field of intelligent transportation, accurate vehicle detection, tracking, and re-identification are essential tasks that enable real-time monitoring, congestion management, and safety improvements. To address these needs in high-traffic highway environments, this study proposes a multi stage traffic flow model combining deep learning and metric learning. The model leverages the Segment Anything Model for vehicle detection, utilizing language-prompting to automate segmentation, thereby reducing manual adjustments and improving adaptability across complex traffic scenarios. For vehicle tracking, the model employs the StrongSORT algorithm, integrated with mask-based tracking to enhance recognition coherence and maintain resilience against occlusions, especially in congested conditions. Additionally, the PP-OCR module accurately extracts timestamps to support interval speed measurement across multiple viewpoints, using vehicle re-identification results for precise multi-camera tracking. Experimental results demonstrate that the proposed model significantly outperforms state-of-the-art methods, achieving higher mean average precision and tracking accuracy in both high-density and challenging traffic conditions, highlighting its robustness and suitability for intelligent transportation systems.
Similar content being viewed by others

Introduction
With economic development and increased intercity transportation, highway traffic volumes have continued to rise, making high-volume conditions commonplace. Many highways are now operating near maximum capacity, and frequent congestion poses significant challenges to traffic management1. Currently, most highway management systems still rely heavily on human expertise, while traditional sensor-based solutions are costly and insufficient for handling high traffic volumes, real-time variability, and the complexity of dynamic traffic environments2.
However, recent advancements in deep learning models within computer vision have enabled intelligent traffic prediction systems to be developed. Leveraging these models for vehicle detection, tracking, and re-identification facilitates accurate speed monitoring and comprehensive vehicle management. Applying these technologies can significantly enhance the efficiency of highway management, while also providing a robust basis for traffic flow optimization and congestion forecasting.
Vehicle detection plays a crucial role in autonomous driving, aiming to accurately identify and locate vehicles in each video frame by providing the maximum bounding box for each detected vehicle3. With the rapid advancement of convolutional neural networks, significant progress has been made in vehicle detection technology. For instance, the YOLO4 algorithm, which utilizes a regression-based approach, has streamlined traditional multi-stage object detection pipelines, effectively reducing computational load. However, performance often degrades under challenging conditions such as lighting changes and low resolution. Therefore, developing a robust and generalizable model for real-world vehicle detection remains essential.
Vehicle tracking is integral to intelligent transportation systems, enabling the unique identification, positioning, and trajectory tracking of vehicles across consecutive video frames within the same viewpoint5. Common tracking algorithms include region-based, dynamic contour-based, feature-based, and model-based approaches6,7,8,9. Despite their utility, these methods can suffer from tracking loss in real-world scenarios where vehicles move rapidly or undergo significant scale variations. Enhancing model stability and accuracy is thus paramount for effective vehicle tracking.
Vehicle re-identification technology enables the recognition of the same vehicle across different camera perspectives, making it indispensable for applications like interval speed measurement10. Current methods primarily fall into feature and metric learning-based approaches, such as license plate-based metric learning11. These approaches aim to extract distinctive vehicle features for effective matching across instances, though there remains room for performance improvement.
Traditional approaches primarily rely on end-to-end models, such as Mask R-CNN12 and YOLOv813. however, these models often face limitations in generalization and robustness, making them less adaptable to real-world, complex scenarios. To address these challenges, the Meta AI team introduced the Segment Anything Model (SAM)14, a versatile image segmentation model designed for rapid, efficient, and automated segmentation across a wide range of images without requiring task-specific fine-tuning. Pre-trained on large-scale image datasets, SAM exhibits strong generalization capabilities, handling both simple and complex segmentation tasks with ease. Leveraging advanced Vision Transformer (ViT)15 technology, SAM demonstrates remarkable transferability, unlocking significant potential for detection and segmentation tasks.
This study harnesses SAM’s advantages to develop a vehicle detection, tracking, and re-identification model tailored for highway scenarios, supporting vehicle counting and speed measurement. First, SAM is utilized to construct a high-precision vehicle detection model. Next, a multi-object tracking algorithm is proposed to enable vehicle tracking and trajectory extraction in highway environments. Additionally, a vehicle re-identification method is implemented to match vehicles across multiple viewpoints, enabling accurate interval speed measurements. Experimental results indicate that our method achieves a \(4.5\%\) higher average accuracy in vehicle counting compared to state-of-the-art methods, while also yielding significant performance gains in short-range and interval speed measurements. Our primary contributions include:
-
Introducing SAM into the vehicle detection task, using the CLIP text encoder to provide segmentation prompts, achieving high-precision detection and segmentation.
-
Developing a tracking algorithm based on combined vehicle masks and bounding boxes for vehicle tracking and trajectory extraction.
-
Proposing a metric learning-based vehicle re-identification algorithm to meet re-identification requirements across different viewpoints.
-
Enhancing the PP-OCR algorithm for video timestamp extraction, which combined with trajectory and re-identification results, enables short-range and multi-view interval speed measurements.
Method
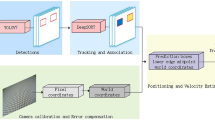
In this study, we propose a highway traffic flow analysis model that integrates modules for vehicle detection, tracking, and re-identification, enabling vehicle counting and interval speed measurement tasks. As illustrated in Fig. 1, the model comprises four primary modules: a general model-based vehicle detection algorithm, a multi-object tracking algorithm that combines masks and bounding boxes, a metric learning-based vehicle re-identification algorithm, and an interval speed measurement method utilizing timestamp and trajectory data. Each module is detailed below.

Workflow of Highway Traffic Flow Analysis Model. The model includes modules for vehicle detection, tracking, and re-identification to accomplish vehicle counting and interval speed measurement tasks. During the detection phase, SAM with a CLIP-based text encoder provides segmentation prompts for high-precision vehicle detection. In the tracking phase, vehicle masks and bounding boxes are combined with StrongSORT for trajectory extraction. For re-identification, a metric learning-based algorithm identifies vehicles across different viewpoints, utilizing both PP-OCR-extracted license plate information and SAM-extracted vehicle features.
Vehicle detection algorithm based on SAM
In this study, SAM is utilized for vehicle detection, where textual prompts guide automated segmentation. Users can enter simple commands, such as “identify vehicles” or “select vehicles in the right lane,” enabling the model to generate corresponding segmentation outputs automatically. The prompt encoder within SAM embeds these textual prompts into a feature space aligned with image features, ensuring accurate vehicle recognition. The workflow of SAM-based vehicle detection, from image and prompt encoding to mask generation, is illustrated in Fig. 2. Since SAM has been extensively pre-trained on large-scale natural image datasets, it inherently supports zero-shot generalization. Its combination of image and textual prompts allows for flexible segmentation in complex traffic environments, particularly in structured highway scenarios where vehicle categories are well-defined. Given its robust segmentation capability, we directly employ the pre-trained SAM model without additional fine-tuning. The vehicle detection results generated by SAM are shown in Fig. 3.

SAM-based Vehicle Detection Workflow. The input consists of highway surveillance images and text-based prompts. The SAM model extracts image features, encodes textual prompts, fuses image and text embeddings, and generates precise vehicle masks using the SAM decoder.
Image encoder
The image encoder’s primary role is to extract global features from the input image. ViT is employed as the feature extractor in SAM, enabling the capture of global contextual information and complex spatial relationships. ViT partitions the input image into non-overlapping patches, which are linearly transformed, and a global feature representation is generated through multiple self-attention layers. Specifically, this process can be described as follows:
Let the image frame from a video be I with dimensions H\(\times\)W. It is divided into n patches, each of size P\(\times\)P. After applying a linear transformation to each patch, the initial feature representation is obtained:
These features are then processed through multiple self-attention layers, allowing global contextual information to be integrated, resulting in the deep feature representation f(I) of the image:
where S represents the spatial dimensions of the feature map, and D is the feature dimension. The choice of ViT as the feature extractor is an integral part of SAM’s architecture. Unlike CNN-based models that rely on local receptive fields, ViT leverages self-attention mechanisms to capture long-range dependencies, making it more effective for pixel-wise segmentation in complex environments. Since SAM is specifically designed to operate with ViT, we adhere to its default configuration.
Prompt encoder
SAM supports various types of prompts (e.g., text, points, or bounding boxes) to direct segmentation tasks. This study employs language prompts, allowing users to define segmentation areas in their natural language. The prompt encoder converts these inputs into embedding vectors aligned with the image features, facilitating subsequent fusion. For a textual prompt \(T_{lang}\), the prompt encoder converts the language instructions into an embedding vector \(g(T_{lang})\) using a text embedding model from CLIP16:
The prompt encoder ensures that the embedding and image feature \({R}^{H' \times W' \times D}\) share the same dimension D, allowing alignment and fusion. In this study, we use fixed textual prompts: “Car,” “Track,” and “Vehicle,” which comprehensively cover the primary categories relevant to vehicle detection. These prompts were chosen to align with common vehicle-related semantic categories in SAM’s pre-training dataset. Empirical validation confirmed that they consistently trigger accurate segmentation across different traffic conditions, eliminating the need for dynamic prompt adjustments.
Fusion of image and prompt features
For prompt-based segmentation, the image and prompt features are fused in SAM to produce joint features \(h(I,T)\). This fusion process is essential, as it combines global image context with prompt-specific information to ensure precise focus on vehicle regions during mask generation. The fusion process is represented as:
where \(\oplus\) denotes element-wise addition. The joint feature \(h(I,T) \in R^{H' \times W' \times D}\) then serves as input for the subsequent mask generation.
Mask decoder
The mask decoder utilizes the joint features to generate a high-resolution vehicle segmentation mask, predicting the pixel regions occupied by vehicles in the scene. Based on the fused image and prompt features, a segmentation mask M with dimensions H\(\times\)W is produced, where M is a binary mask (0 indicating background, 1 indicating vehicle regions). The mask generation process can be described as:
where the decoder output M corresponds to the segmented vehicle regions, outlining the contours of detected vehicles in the video frame.
Post-processing and final detection output
Once the segmentation masks are obtained, additional post-processing steps are applied to refine the detection results. The detected vehicle masks are converted into bounding boxes, which are used to extract individual vehicle instances. The final detection outputs consist of vehicle bounding boxes, segmentation masks, and classification labels. These outputs are passed to the tracking module for further analysis.
SAM’s segmentation capability inherently addresses common challenges such as occlusions, lighting variations, and small vehicles. Our dataset includes diverse conditions, covering different lighting environments and vehicle densities. Empirical results demonstrate that SAM maintains robust segmentation performance across these scenarios, supporting its suitability for real-world traffic monitoring.
Language prompts and vehicle recognition
A distinctive feature of SAM is its ability to perform vehicle recognition based on user-provided language prompts. In this study, we employ fixed textual prompts: “Car,” “Track,” and “Vehicle,” which are used to guide the model’s focus on vehicles in monitoring videos. These prompts were selected because they effectively align with SAM’s pre-trained dataset and have been verified to produce stable segmentation results without requiring additional prompt tuning.
For example, users can specify prompts such as “identify all vehicles” or “select vehicles in the right lane,” enabling the model to generate corresponding segmentation outputs. The prompt encoder embeds the language prompt \(T_{lang}\) into the model, aligning it with image features to generate the segmentation mask. Since SAM has been extensively pre-trained on diverse image datasets, it possesses strong generalization capabilities, allowing it to adapt to various vehicle scenes, including scenarios with partial occlusions and different viewpoints. Instead of dynamically adjusting prompts based on scene variations, we rely on SAM’s robust segmentation ability to handle diverse traffic conditions effectively.

Vehicle recognition results using the SAM model based on language prompts. The model guided by the prompt “identify all vehicles” successfully generates individual detection masks for multiple vehicles, including cars and trucks.
Vehicle tracking algorithm based on StrongSORT
Once vehicle detection is completed, the StrongSORT17 algorithm is employed for vehicle tracking. This algorithm is an extension of DeepSORT18, incorporating three core modules: an Exponential Moving Average (EMA) feature update strategy, a Noise Scale Adaptive (NSA) Kalman Filter, and an enhanced appearance feature embedding. Notably, StrongSORT introduces the Enhanced Camera Compensation (ECC) strategy to address scenes with changing viewpoints, such as autonomous driving scenarios. This is achieved by quantifying the performance of transformation distortions through image registration, thereby mitigating the deformation of detection results caused by shifts in viewpoint positions. However, as this study focuses on fixed-camera settings, the ECC strategy is not utilized. These modules collectively optimize real-time tracking performance and accuracy. Each module is detailed in the following subsections.
EMA feature update strategy
To enhance robustness against noise in detection, an EMA feature update strategy is adopted in place of DeepSORT’s original feature buffer mechanism. This strategy suppresses detection noise by utilizing feature variations between frames. Unlike the YOLOX-X19 detector and BoT appearance extractor in StrongSORT, this study uses SAM’s ViT to extract features and update the appearance state of the trajectory, effectively improving tracking robustness. The appearance state of the i-th trajectory at time t is represented as:
where \(f_{detected}\) detected is the appearance feature vector of the detected object extracted by SAM, and \(\alpha \in \{0,1\}\) represents a parameter for the EMA.
NSA Kalman filter
The NSA Kalman Filter is a core tracking algorithm in StrongSORT, improving tracking accuracy by adaptively calculating noise covariance. Compared to traditional Kalman filters, the NSA Kalman Filter better adapts to noisy and low-quality detections. The adaptive calculation of the noise covariance \(R_{k}\) as follows:
Hungarian algorithm
In each frame, to accurately match detected bounding boxes with existing trajectories, the Hungarian algorithm is employed by StrongSORT to minimize tracking errors (such as distance or feature errors). This algorithm finds the optimal matching between detections and trajectories by minimizing elements in a cost matrix. Each element in the cost matrix represents the matching cost between a current detection box and an existing target. In this study, Euclidean distance combined with motion information is used to evaluate the similarity in ___location and motion state, ensuring effective target matching. The element \(C_{i,j}\) in the cost matrix \(C\) is represented as:
where \(d(z_i,X_j)\) appearance represents the distance between the appearance features of detection \(i\) and trajectory \(j\) which contains the sum of the distance measures of appearance information and motion information.
Tracking method based on combined vehicle mask and bounding box
To further improve tracking accuracy, vehicle masks and bounding boxes detected by SAM are combined for matching, and confidence scores are computed for each vehicle ID to determine the final tracking result, ensuring high-precision vehicle recognition and tracking in multi-target tracking tasks.
Time extraction algorithm based on PP-OCR
This study uses the PaddlePaddle-based PP-OCR20 to perform time extraction on surveillance videos to achieve interval speed measurement. PP-OCR is an open-source OCR solution that is lightweight, efficient, easy to deploy, can quickly identify text in images, and is suitable for text detection and recognition in various complex scenarios. The specific methods are detailed as follows:
Data processing
This section addresses the challenges posed by variations in text color and background in image data, focusing on effectively extracting time information from surveillance video frames. The time display often consists of both black and white digits on diverse backgrounds. The process begins with cropping the region of interest using fixed coordinates, as illustrated in Fig. 4(a) and Fig. 5(a). For frames with black text on a light background, the cropped region is converted to grayscale (Fig. 4(b)), simplifying color complexity and improving text visibility. Contrast Limited Adaptive Histogram Equalization (CLAHE) is then applied to enhance finer text features, as shown in Fig. 4(c). Brightness and contrast adjustments further highlight the digits, ensuring they stand out prominently against the background (Fig. 4(d)). For frames with white text on a darker or varying background, an initial color inversion is applied (Fig. 5(b)), converting white text to black. Subsequently, the cropped region undergoes CLAHE application (Fig. 5(c)) and brightness adjustments (Fig. 5(d)). Global thresholding is performed after color inversion to create a binary image that distinctly separates the text from the background (Fig. 4(e) and Fig. 5(e)). Finally, contour retention techniques preserve the sharpness and integrity of the digits, resulting in a high-contrast image optimized for OCR processing (Fig. 4(f) and Fig. 5(f)).

Workflow for extracting time information from frames where digits are displayed as black text on a lighter background: (a) Cropping to the time region; (b) Grayscale conversion; (c) Application of CLAHE; (d) Brightness and contrast adjustment; (e) Global thresholding; (f) Retention of contours.

Workflow for extracting time information from frames where digits appear as both black and white text on varying backgrounds: (a) Cropping to the time region; (b) Color inversion for white text; (c) Application of CLAHE for black text; (d) Global thresholding applied after color inversion for white text; (e) Retention of contours for white text; (f) Retention of contours after color inversion for white text.
Text detection
The Differentiable Binarization (DB) algorithm in PP-OCR is used to detect text regions in the image. Suppose the detected text region is represented by a bounding box \(B\), with each box defined by coordinates \((B = x_1,y_1,x_2,y_2)\), where \((x_1,y_1)\) is the coordinate of the upper left corner of the box, and \((x_2,y_2)\) is the coordinate of the lower right corner of the box. The DB algorithm for text detection can be expressed as:
where \(I_{pre}\) represents the preprocessed image.
Time character recognition
The recognition of time characters is performed by the Convolutional Recurrent Neural Network (CRNN) model in PP-OCR, which uses Connectionist Temporal Classification (C-TC) loss to handle variable-length time sequences. This approach efficiently extracts time information from the video, providing precise time markers for subsequent interval speed measurements. The feature map extracted by CRNN is denoted as \(F_{CRNN}\), represented as:
The CTC loss is used to handle variable-length sequences, and the output character sequence \(S\) is given by:
where \(S\) represents the recognized character sequence, such as the time \(``12:34:56''\).
Vehicle re-identification algorithm based on metric learning
In this study, we propose a vehicle re-identification method that integrates both vehicle appearance features and license plate information using a metric learning approach. Unlike traditional vehicle Re-ID methods that rely solely on appearance-based features, our approach explicitly incorporates license plate information to enhance vehicle distinctiveness, particularly in structured highway environments where vehicle types and colors may be similar. This method effectively addresses visual variations caused by changes in viewing angle, lighting conditions, and partial occlusions. The re-identification framework follows a structured pipeline, as illustrated in Fig. 6, ensuring robust vehicle matching across multiple viewpoints.

Framework of the vehicle re-identification algorithm based on metric learning. The model extracts both image features and license plate features using SAM and PP-OCR, respectively. These features are then fused and evaluated for similarity during training and inference, ensuring accurate vehicle matching.
First, vehicle images from different viewpoints are processed through the SAM-based feature extractor, which captures discriminative vehicle appearance features. Unlike existing approaches that use standard CNN-based feature extractors, SAM provides segmentation-based feature representations, which improve robustness in complex traffic conditions. Simultaneously, the license plate is identified in the video using the detector described in Section 2.1 and extracted via the PP-OCR algorithm detailed in Section 2.3. The text on the license plate is then transformed into a numerical feature representation by embedding each character into a vector space, forming the license plate feature. Assuming the license plate string is \(P\) with a length of \(L\), and each character’s embedding vector is \(e_i \in R^{d_p}\), the embedded license plate feature \(V_p\) is computed as:
where \(L\) is the number of characters in the license plate, and \(d_p\) is the embedding dimension for each character.
In parallel, the visual features \(V_c\) of the vehicle are extracted using SAM’s encoder. To enhance identification accuracy, these visual features are fused with the license plate feature \(V_p\), creating a comprehensive feature representation:
where \(d_c\) is the dimension of the visual feature and \(d_p\) is the dimension of the license plate feature. This fusion enables the model to leverage both appearance-based and textual information for re-identification.
To effectively optimize the network, the loss function consists of two primary components: \(L_{vision}\) for the vehicle’s appearance feature \(V_c\) and \(L_{plate}\) for the license plate feature \(V_p\). A weighted combination of these losses ensures balanced learning:
where \(\lambda _v\) and \(\lambda _p\) are hyperparameters controlling the contributions of the visual and license plate features.
During inference, the similarity between the query vehicle and vehicles in the database is calculated based on the fused feature representation:
where \(V_{cp}^i\) represents the combined feature of the \(i\)-th vehicle in the reference database. The vehicle with the highest similarity score (smallest distance) is selected as the re-identification result.
This method ensures accurate vehicle re-identification by integrating both visual and textual information, significantly improving robustness in real-world highway surveillance applications. Unlike traditional CNN-based methods that rely primarily on appearance features, our approach leverages segmentation-based feature extraction, which enhances adaptability in challenging conditions such as occlusions and varying illumination. The approach effectively handles cases where visual similarity alone may lead to ambiguities, such as identical vehicle models with different license plates.
Interval speed measurement method based on trajectory and timestamp
By tracking and re-identification algorithms to obtain vehicle trajectories and matching results, combined with the timestamp extracted by PP-OCR, we can further calculate the average short-distance speed of the vehicle. First, in a single-view setting, the travel distance is estimated based on the trajectory distance, and the actual distance is converted using the lane detection model proposed by Feng et al.21. In addition, for the multi-view re-identification matching task, this study calculates the interval average speed based on the appearance time of the vehicle in different views and the known distances between these views.
However, in real-world scenarios, surveillance videos often suffer from non-uniform frame rates due to adaptive encoding, network transmission variations, or post-processing frame extraction. Traditional methods that directly rely on raw OCR timestamps may lead to significant errors when the FPS is inconsistent. To address this, we introduce a hybrid time estimation method that first estimates the actual FPS of the video based on high-confidence OCR timestamps and then applies this FPS to correct all timestamps, ensuring robust and accurate speed measurement.
Perspective transformation for viewpoint correction
To ensure accurate speed measurement, we apply a perspective transformation to correct distortions introduced by the camera’s viewing angle. Without such a correction, vehicles moving at an angle relative to the camera may have inaccurate trajectory distance estimates, leading to incorrect speed calculations.
We employ a homography matrix \(H\) to transform the image coordinates of the vehicle into a real-world coordinate system, aligning the measurements with the ground plane. The transformation is defined as:
where \({X}_{\text {image}} = (x, y, 1)^\top\) represents the vehicle position in the image coordinate system, \({X}_{real} = (X, Y, 1)^\top\) represents the transformed real-world position and \(H\) is the homography matrix, computed using at least four known reference points from the scene.
The homography transformation corrects the image’s perspective distortion by aligning the camera’s view with a bird’s-eye perspective, making the vehicle’s motion appear as if viewed from directly above. This process ensures that trajectory distances are computed accurately, unaffected by perspective effects.
Estimating actual FPS from high-confidence OCR results
Given a set of timestamps \({T} = \{T_1, T_2, \dots , T_n\}\) extracted by OCR and their corresponding confidence scores \({C} = \{C_1, C_2, \dots , C_n\}\), we first filter out unreliable OCR results with confidence below a threshold \(\tau\). The confidence threshold \(\tau\) is predefined, for example, \(\tau = 0.9\). The remaining high-confidence timestamps \({T}_{high}\) and their associated frame indices \({F}_{high}\) are then used to compute the estimated frame rate (\(FPS_{est}\)) as:
where \(F_i\) and \(T_i\) are the frame index and timestamp of the i-th high-confidence OCR result, and m is the total number of high-confidence timestamps. This FPS estimation adapts to non-uniform frame spacing caused by variable FPS recording, ensuring a more reliable measure of the video’s true frame rate.
Refining all timestamps using estimated FPS
Once the estimated FPS is obtained, it is applied to refine all timestamps, including high-confidence ones, ensuring that the time interval between frames is consistent with the actual video frame rate. The corrected timestamp for any frame \(F_t\) is computed as:
where \(T_{start}\) is the earliest high-confidence timestamp, and \(F_{start}\) is its corresponding frame index. For frames with low-confidence OCR results (\(C_t < \tau\)), instead of using their raw OCR timestamps, their corrected timestamps are interpolated using:
where \(F_{prev}\) is the nearest preceding frame with a high-confidence timestamp. This approach ensures that frames with unreliable OCR recognition are assigned reasonable timestamps that align with the true frame rate of the video.
Final speed calculation
After applying perspective transformation and timestamp correction, the interval speed V for a vehicle traveling a known distance D is computed as:
where \(T_{start}^{corrected}\) and \(T_{end}^{corrected}\) are the refined timestamps of the vehicle’s first and last appearances. By incorporating both perspective correction and FPS estimation, all timestamps and trajectory distances reflect real-world conditions, significantly improving speed measurement accuracy.
Advantages and robustness against non-uniform FPS
Unlike conventional methods that assume a fixed FPS, the proposed approach dynamically estimates FPS based on OCR-detected timestamps, making it well-suited for handling variable FPS videos where frame intervals are inconsistent due to encoding settings. This method is particularly useful in frame-skipping scenarios, such as those caused by video compression or adaptive streaming, as well as in irregularly sampled videos where frames are unevenly extracted post-recording. By adapting to non-uniform FPS and refining all timestamps, this method significantly improves the accuracy of time-based vehicle speed estimation, ensuring robustness in real-world intelligent transportation applications. Furthermore, by recalibrating even high-confidence OCR timestamps with the estimated FPS, this approach minimizes the cumulative error introduced by minor OCR inaccuracies, leading to a more stable and accurate speed measurement.
Experiments
Dataset description
In this experiment, we utilized four datasets: the University at Albany Detection and Tracking (UA-DETRAC)22 dataset, a private dataset, the BrnoCompSpeed dataset, and the VeRi-776 vehicle re-identification benchmark23.
The UA-DETRAC dataset comprises 100 sequences totaling 138,252 image frames and was primarily used for pre-training on vehicle detection, trajectory tracking, and re-identification tasks. It provides diverse urban traffic scenes with various weather conditions and illumination changes, making it a robust benchmark for model pre-training. In this work, the first 60 sequences were used as training data, and the remaining 40 sequences were used for testing. This split ensures a balanced evaluation of detection and tracking performance under different conditions.
The private dataset consists of traffic surveillance videos collected from four consecutive monitoring points along a highway. Data was recorded between March and June 2023, covering traffic conditions from 11:00 AM to 6:30 PM. The recordings were captured using high-resolution fixed-position surveillance cameras (1920\(\times\)1080) operating at 60 FPS, ensuring fine-grained temporal resolution for precise vehicle tracking and speed estimation. To manage the high frame rate, we adopted a sampling strategy, retaining only one out of every ten frames, resulting in a dataset containing 163,165 frames (see Table. 1). The dataset includes a variety of vehicle types, with approximately 65% small passenger cars, 25% trucks, and 10% buses.
All video frames in the private dataset were manually annotated using the LabelMe tool24. To ensure annotation accuracy, each frame was independently labeled by two annotators, who manually assigned bounding boxes to detected vehicles following standardized labeling guidelines. A third expert reviewer cross-validated the annotations, resolving discrepancies and refining bounding box placements when necessary. To further enhance annotation reliability, an Intersection over Union (IoU) threshold-based consistency check was performed to identify significant positional deviations between annotators, and a random sample comprising 10% of the annotated frames was reviewed for quality control. Additionally, cross-camera tracking validation was conducted to ensure the consistency of re-identification labels across different viewpoints. Any detected inconsistencies were flagged for correction to maintain the accuracy of vehicle tracking information. To facilitate speed estimation, timestamps were extracted, and ground-truth speed values were computed based on calibrated distances between monitoring points. Data from monitoring points 1 and 2 were used for training, while data from points 3 and 4 were allocated for testing. The dataset can be accessed upon request and approval from the corresponding author.
To further validate the generalizability of our proposed method, we evaluated its performance on the BrnoCompSpeed dataset25, a publicly available dataset consisting of 18 high-resolution traffic videos recorded across six different sessions. Each session includes three fixed camera views, capturing a variety of traffic scenarios such as urban intersections and highway segments. The dataset contains 20,685 vehicles with precisely measured ground-truth speeds, obtained using optical gate sensors and LiDAR-based tracking, and further verified against GPS-based reference data, making BrnoCompSpeed an ideal benchmark for assessing speed estimation accuracy. For evaluation, we used all 18 videos from Part A of the dataset, which are designated for inference only. All speed estimates produced by our method were compared against the reference values provided in the official annotations. In this work, BrnoCompSpeed was specifically used for evaluating the performance of our interval speed estimation module, as it provides reliable and accurate vehicle speed labels. However, since the dataset does not include frame-level bounding box annotations required for supervised vehicle detection, it is not suitable for evaluating the detection component of our system.
Additionally, to assess the effectiveness of our re-identification module, we included the VeRi-776 dataset23, a widely used benchmark for vehicle Re-ID tasks. Unlike video datasets, VeRi-776 is composed entirely of images captured from 20 surveillance cameras at different locations in an urban environment. The dataset includes 37,778 training images spanning 576 vehicle identities and 11,579 testing images involving 200 vehicle identities. Each vehicle appears in multiple viewpoints and scenes, accompanied by metadata such as vehicle color, type, camera ID, and timestamps. This dataset was exclusively used for inference to evaluate Re-ID performance and benchmark against existing state-of-the-art approaches.
Implementation details
The vehicle detection model was implemented using the ViT-H text encoder of CLIP and ViT-H feature extractor within the SAM framework. Since SAM has been pre-trained on large-scale natural image datasets, it possesses strong zero-shot generalization capabilities. Therefore, we directly adopt the pre-trained SAM model without fine-tuning, as its segmentation performance is well-suited for vehicle detection in traffic surveillance. To guide the segmentation process, we employ fixed textual prompts: “Car,” “Track,” and “Vehicle,” which were selected based on their alignment with SAM’s pre-training dataset and their effectiveness in producing stable segmentation results.
As SAM is inherently designed with ViT as its core feature encoder, we follow its default configuration without exploring alternative architectures such as CNN-based models. The tracking and re-identification models were pre-trained on the UA-DETRAC dataset and then fine-tuned on the private training dataset, with testing conducted on the private dataset. Both the StrongSORT and PP-OCR algorithms were configured with default settings. All experiments were conducted on a server equipped with Tesla V100 GPUs.
Evaluation metrics
We use the Mean Average Precision (mAP), F1 Score, and Mean Intersection over Union (mIoU) metrics to evaluate the performance of the vehicle detection model. mAP provides a measure of precision and recall across all classes, giving an overall indication of detection accuracy. F1 Score balances precision and recall, serving as a comprehensive performance metric. mIoU measures the overlap between predicted and ground truth regions, capturing the spatial accuracy of detections. The calculation formulas for these metrics are as follows:
where \(N\) represents the total number of classes, \(\text {AP}_i\) is the Average Precision for class \(i\), representing the area under the precision-recall curve for that class. \(\text {TP}_i\) denotes the true positives for class \(i\), \(\text {FP}_i\) denotes the false positives, and \(\text {FN}_i\) denotes the false negatives.
Additionally, we use the Mean Average Tracking Accuracy (MOTA), Identity Switches (IDs), and Identification F-score (IDF1) metrics to evaluate the tracking model’s performance. MOTA primarily reflects detection accuracy, while IDF1 emphasizes the consistency of ID matching. The calculation formulas for these metrics are as follows:
where \(\text {FN}_t\) represents the number of false negatives at time \(t\), \(\text {FP}_t\) represents the number of false positives, \(\text {IDSW}_t\) represents the number of identity switches, and \(\text {GT}_t\) represents the total number of ground truth objects. Additionally, \(\text {IDTP}\) denotes the true positives of ID matches, \(\text {IDFP}\) denotes the false positives, and \(\text {IDFN}\) denotes the false negatives.
In this task, Character Error Rate (CER) and Accuracy are used to assess the performance of the time information extraction model. CER measures character-level recognition errors by calculating the deviation between extracted and ground truth characters, with a lower CER indicating higher character extraction accuracy. Accuracy evaluates whether the entire extracted time string is correct, with a higher score reflecting better overall recognition performance. The calculation formulas for these metrics are as follows:
where \(\text {Ins}\) represents the number of insertion errors, \(\text {Del}\) represents the number of deletion errors, \(\text {Sub}\) represents the number of substitution errors, \(\text {Total}\) represents the total number of ground truth characters, and \(\text {Correct}\) represents the number of completely correct time strings extracted.
For speed estimation, we introduce Absolute Error (AE), Mean Absolute Error (MAE), and Root Mean Square Error (RMSE) as evaluation metrics to measure the accuracy of the predicted vehicle speeds. AE evaluates the absolute difference between predicted and actual speeds for individual vehicle samples, while MAE quantifies the average absolute difference across all samples. RMSE further penalizes larger errors, making it a more sensitive measure of prediction accuracy. The formulas are defined as follows:
where \(N\) is the total number of vehicles, \(V_{\text {pred},i}\) represents the predicted speed for vehicle \(i\), and \(V_{\text {actual},i}\) represents the actual speed of vehicle \(i\).
Vehicle detection results
To evaluate the performance of the proposed SAM-based vehicle detection method, we conducted extensive experiments on both a private highway surveillance dataset and the public UA-DETRAC dataset. Table. 2 summarizes the detection accuracy of our approach in comparison with several widely-used object detection frameworks. These include two-stage detectors such as Faster R-CNN26 and Mask R-CNN12, one-stage detectors like SSD27, YOLOv54, and YOLOv813, as well as the evolving baseline EB model28.
Our method achieves the highest detection accuracy on both datasets, reaching 88.2% mAP, 89.7% F1 Score, and 85.9% mIoU on the private dataset, and 79.5%, 84.0%, and 81.3%, respectively, on UA-DETRAC. These results outperform all baselines across every metric. Compared with the strongest baseline YOLOv8, the proposed method achieves improvements of +4.5% mAP and +5.5% mIoU on the private dataset, and +2.7% mAP and +3.4% mIoU on UA-DETRAC. These consistent gains across datasets demonstrate the superior generalization capability of the SAM-based architecture.
The primary performance gain stems from the use of SAM’s multimodal segmentation design, which integrates both visual features and language-guided prompts. By allowing text inputs such as “Car” and “Truck,” SAM enables more precise semantic masking than pure visual models, especially in scenes with diverse vehicle types, complex occlusions, and lighting variability.
To further evaluate the contribution of textual prompting in SAM, we conduct an ablation study under three configurations, as reported in Table 3: (1) visual-only model using only image features, (2) prompt-only model using only textual guidance, and (3) full model using both inputs.
The results indicate that the Full SAM configuration significantly outperforms the other two variants on both datasets, confirming that language prompts not only enhance semantic segmentation accuracy but also help disambiguate occluded or low-contrast vehicle regions. On the private dataset, Full SAM improves mAP by +5.7% over image-only, and by +8.6% over prompt-only. Similar trends are observed on UA-DETRAC. This validates that prompt-driven semantic control synergizes effectively with visual features in vehicle detection tasks.
Vehicle tracking results
We present a comparative analysis of our SAM + StrongSORT tracking framework against established methods on both the private highway surveillance dataset and the UA-DETRAC benchmark, with results summarized in Table. 4. On the private dataset, our method significantly outperformed existing tracking pipelines that are based on MHT29, DeepSORT18, and KIOU30. Our tracker achieved the highest MOTA of 68.3% and an IDF1 of 60.3%, along with the lowest IDSW value of 731 among all competitors. The substantial improvements can be attributed to the introduction of segmentation-level cues from SAM, which provide rich contour and mask-level features that are less susceptible to inter-object occlusions and motion blur. This feature-level precision enables StrongSORT to generate more stable appearance embeddings, thus reducing identity fragmentation and improving association across frames.
For the UA-DETRAC benchmark, we followed the established evaluation protocol and report results averaged over multiple weather and lighting conditions. Our method, denoted as SAM + StrongSORT, achieved a MOTA of 30.2%, an IDF1 of 56.8%, and an IDSW of 380. These results are notably better than all conventional trackers, including YOLOv8 + StrongSORT and EB + KIOU. The gain in IDF1 is particularly significant, suggesting that our method preserves trajectory consistency more effectively over long sequences and varying traffic density levels. Compared to the best performing trackers in the UA-DETRAC tracking leaderboard22, our results approach the level of state-of-the-art methods while being implemented with lightweight architecture and no specialized hand-crafted motion models. The relatively high IDF1 score underlines the strength of SAM-based semantic segmentation in delivering reliable identity features, which contributes to reduced identity switches, especially in congested scenes.
In both datasets, our method demonstrates consistent performance across evaluation metrics, confirming its robustness and adaptability under diverse real-world conditions. The integration of semantic mask features with identity-aware tracking mechanisms provides a promising direction for enhancing multi-object tracking performance in intelligent transportation systems. Future improvements could involve integrating additional appearance cues such as license plate recognition or vehicle attribute embeddings to further boost discriminative tracking capability in high-ambiguity environments.
Time detection results
We conducted a comparison with leading OCR algorithms, including the PP-OCR baseline model (see Table. 5). The results indicate that traditional models struggled to separate time information from the background in complex road images. In contrast, the proposed method effectively removed background noise and processed black and white characters separately to accurately extract time information. Fig. 7 presents a comparative analysis of various filtering methods applied to enhance the clarity of black text on grayscale images, showcasing the differences in each method’s effectiveness for isolating time information from the background. In this analysis, CLAHE (Fig. 7a) is used to increase contrast, while Gaussian Blur (Fig. 7b) provides a smoothing effect to reduce noise. A combination of Gaussian Blur and thresholding (Fig. 7c) aims to further sharpen the text. Bilateral filtering (Fig. 7d) focuses on edge preservation to maintain text clarity, morphological operations (Fig. 7e) highlight text structure, and adaptive thresholding (Fig. 7f) adjusts contrast based on local areas. This comparison illustrates the strengths and limitations of each technique for separating time information in complex backgrounds, validating our chosen method’s effectiveness through contrast.

Qualitative results of black text clarity enhancement on grayscale images using different filtering techniques. (a) Application of CLAHE for contrast enhancement; (b) Gaussian Blur for noise reduction; (c) Combined Gaussian Blur and thresholding for text sharpening; (d) Bilateral Filtering for edge preservation; (e) Morphological operations to reinforce text structure; (f) Adaptive Thresholding to adjust contrast locally.
Vehicle re-identification results
To comprehensively evaluate the effectiveness and generalizability of the proposed vehicle re-identification method, we conducted experiments on two datasets: a private highway surveillance dataset and the public benchmark VeRi-776. Table. 6 presents the results, comparing our model with representative state-of-the-art methods. Across both datasets, our method consistently achieves superior performance. On the private dataset, our full model achieves the highest mAP of 71.2% and Rank-1 accuracy of 83.9%, outperforming methods such as TransReID and MDFE-Net. Similarly, on the VeRi-776 benchmark, our model achieves 83.10% mAP and 97.85% Rank-1 accuracy, surpassing all listed competitors including TransReID (82.00%/97.10%) and MDFE-Net (80.33%/97.01%). These results validate the robustness of our segmentation-based multimodal feature fusion strategy under both controlled and challenging real-world conditions.
To further investigate the contribution of individual modalities in our framework, we conducted an ablation study under three different configurations: (1) using only vehicle appearance features (Visual-only); (2) using only license plate textual features (Plate-only); and (3) fusing both features (Full model). The results are reported in Table. 7.
The results confirm that both appearance and plate-based features contribute positively to overall performance, with the fusion model yielding the best results on both datasets. On the private dataset, the Full model outperforms the Visual-only configuration by 3.7% in mAP and 4.6% in Rank-1 accuracy. On VeRi-776, the performance gap is even more pronounced, highlighting the importance of combining spatial and semantic cues in scenarios with high visual ambiguity. The visual-only model performs competitively when visual features are clear, but struggles in the presence of similar vehicle types or color schemes. The plate-only configuration provides valuable identity information but is more sensitive to low resolution or occlusion. In contrast, our full model effectively leverages the strengths of both modalities, offering more stable and reliable re-identification across diverse conditions. These findings demonstrate the practical benefits of our multimodal design and reinforce its applicability for real-world intelligent transportation systems.
Short-range speed measurement in single-view
In this section, as illustrated in Fig. 8, pixel displacement distances were calculated from vehicle trajectories in single-view video data. Fig. 8(a) marks the starting point, and Fig. 8(b) represents the endpoint. Tires and lane lines were used as reference points to establish a scale for two-dimensional distance correction, facilitating the calculation of actual travel distances between the two points.
To ensure more accurate distance measurements, a perspective transformation was applied to correct any distortions due to the camera’s viewing angle. This transformation, using a homography matrix, aligned the video frame with a top-down perspective, ensuring that vehicle positions were accurately mapped to real-world coordinates. As a result, the vehicle trajectory was adjusted to account for perspective distortions, particularly when the vehicle moved at an angle relative to the camera. This perspective correction was crucial to ensure that the distance measurement was not affected by viewing angle discrepancies.
Using these corrected displacements and the time interval, the method accurately determined the instantaneous vehicle speed. The results shown in Table. 8 confirm the precision of this approach, with minimal error between the actual and predicted speeds. The table also demonstrates the improvements achieved by incorporating perspective correction, where the AE is computed based on the predicted speeds after correction. Additionally, Table. 9 presents the MAE and RMSE values, further validating the reliability of our speed estimation method.

Workflow for Calculating Vehicle Displacement and Speed. (a) Identify the starting point; (b) Identify the endpoint, with pixel and real distances shown in the image.
Interval speed measurement in multi-view
Using vehicle re-identification results and timestamp extraction averages in multi-view scenarios, we calculate speed across multiple camera positions. With known distances between views, time difference information extracted by PP-OCR is directly applied to calculate interval speed. Results shown in Table. 10 indicate that the proposed method effectively calculates average vehicle speed over designated intervals. Additionally, Table. 11 presents the MAE and RMSE values, further validating the reliability of our speed estimation method.
Discussion and conclusion
In this study, we proposed a comprehensive highway traffic flow model that integrates deep learning techniques with metric learning strategies for robust vehicle detection, tracking, re-identification, and speed measurement. The experimental results on several datasets, including the private dataset, UA-DETRAC22, BrnoCompSpeed25, and VeRi-77623, confirm that our method surpasses existing state-of-the-art techniques in accuracy, robustness, and adaptability. Particularly, the proposed approach excels in vehicle detection and re-identification tasks, demonstrating superior performance across various evaluation metrics.
One of the key strengths of our model lies in its ability to dynamically integrate image features with textual inputs through SAM’s vision-language prompting mechanism. Unlike conventional detection algorithms that rely solely on visual features, our approach enhances segmentation accuracy by leveraging fixed textual prompts such as “Car,” “Track,” and “Vehicle.” These textual cues enable the model to more accurately localize and classify vehicles, especially in scenarios with occlusions, lighting variations, or vehicles with similar visual appearances. The ability to incorporate semantic guidance via text improves the model’s generalization ability, making it robust to different traffic conditions. SAM’s zero-shot generalization capability further enhances its practicality by allowing the model to perform well in fixed-camera surveillance settings without requiring extensive fine-tuning for each new dataset.
For vehicle tracking, we combined the StrongSORT multi-object tracking algorithm with SAM-derived mask-level segmentation cues. This fusion improved the stability of appearance feature embeddings, significantly reducing IDSW and preserving vehicle identities across frames, particularly in congested environments. The experimental results show that our tracking module outperforms traditional tracking methods, such as those based on MHT and DeepSORT, in both the private dataset and UA-DETRAC, with higher MOTA and IDF1 scores. This improvement can be attributed to the precise segmentation from SAM, which enables better tracking performance in complex traffic scenarios, especially those with high vehicle density or frequent occlusions. However, challenges remain, particularly in scenarios with extreme occlusions, low-light conditions, and the detection of small or distant vehicles. SAM’s segmentation capabilities help mitigate issues caused by moderate occlusions, but further work is needed to handle severe occlusions and dynamic traffic scenes. Future research could explore integrating complementary modalities, such as infrared imaging or near-infrared cameras, to enhance the robustness of the detection and tracking system under low-light or adverse weather conditions.
The vehicle re-identification module in our system integrates visual features with license plate information extracted via PP-OCR. This multimodal fusion strategy enables accurate identification across different camera views, which is particularly beneficial in real-world surveillance scenarios. The results from the VeRi-776 dataset23 demonstrate that our model outperforms several state-of-the-art re-identification methods, such as TransReID44 and MDFE-Net45, further validating the efficacy of combining spatial and semantic features for robust vehicle re-identification. By leveraging both appearance features and textual license plate data, our method achieves high mAP and Rank-1 accuracy, even in cases where vehicles have similar appearances across multiple viewpoints.
Moreover, the integration of PP-OCR for timestamp extraction and multi-camera synchronization improves the accuracy of vehicle speed estimation. The proposed interval speed measurement method, which uses trajectory data from both single- and multi-view setups, enables precise speed estimation, even in complex traffic environments. The temporal calibration approach, supported by homography-based geometric corrections, helps minimize errors in speed prediction, providing a reliable framework for real-time traffic monitoring and vehicle behavior analysis. The accuracy of this approach has been validated on both private and BrnoCompSpeed datasets25, confirming its effectiveness in diverse real-world deployments.
While the proposed system performs well under a range of conditions, there are still several limitations to address. SAM’s segmentation mechanism, although effective in handling moderate occlusions and visual ambiguities, faces challenges in extreme cases such as low-light environments or highly congested traffic scenes. To overcome these limitations, future work could explore integrating additional sensing modalities, such as thermal or near-infrared imaging, which would improve detection accuracy under poor visibility conditions. Moreover, enhancing small vehicle detection by employing higher resolution inputs or multi-scale feature fusion techniques could further improve the system’s robustness and adaptability.
Another area for improvement is the model’s reliance on fixed camera configurations. While the current system works well in controlled environments with fixed cameras, extending it to work with dynamic setups, such as mobile cameras on drones or vehicles, presents new challenges. These include compensating for camera motion and ensuring frame alignment across multiple viewpoints. Solutions like online calibration or simultaneous localization and mapping could be explored to make the model adaptable to more dynamic monitoring systems.
Furthermore, optimizing the system’s computational efficiency remains crucial, particularly for real-time deployment. SAM’s segmentation process and the PP-OCR-based timestamp extraction could benefit from further optimization techniques, such as model pruning or token sparsity in the ViT architecture. These approaches could reduce computational costs without sacrificing accuracy, making the system more suitable for large-scale, real-time applications in traffic monitoring.
Finally, addressing ___domain adaptation challenges is essential for the model’s deployment in diverse environments. Techniques like unsupervised ___domain adaptation, style augmentation, and contrastive self-supervised learning could improve the model’s performance across varying traffic scenes, weather conditions, and regions with different vehicle distributions. This would further enhance the system’s robustness and ensure its effectiveness in real-world deployments.
In conclusion, the proposed highway traffic flow analysis system offers a scalable, robust, and generalizable solution for automated vehicle monitoring. By leveraging deep learning techniques, multimodal feature fusion, and advanced tracking algorithms, the system demonstrates excellent performance across various traffic conditions and datasets. Its applications extend beyond vehicle detection and tracking to include intelligent transportation systems, traffic safety analysis, and smart city infrastructure. Future work will focus on refining the system’s capabilities, addressing its limitations, and exploring new avenues for improving detection, tracking, and re-identification accuracy in real-world environments.
Data availability
The datasets analyzed during the current study are not publicly available due to privacy concerns associated with real-world highway scenarios, including sensitive information about traffic, vehicles, and license plates, but are available from the corresponding author on reasonable request.
References
Ravish, R. & Swamy, S. R. Intelligent traffic management: A review of challenges, solutions, and future perspectives. Transp. Telecommun. J. 22, 163–182 (2021).
Tengilimoglu, O., Carsten, O. & Wadud, Z. Implications of automated vehicles for physical road environment: A comprehensive review. Transp. Res. Part E Logist. Transp. Rev.169, 102989 (2023).
Karangwa, J., Liu, J. & Zeng, Z. Vehicle detection for autonomous driving: A review of algorithms and datasets. IEEE Trans. Intell. Transp. Syst.https://doi.org/10.1109/TITS.2023.3292278 (2023).
Jocher, G. et al. ultralytics/yolov5: v3. 1-bug fixes and performance improvements. Zenodo (2020).
Fu, H., Guan, J., Jing, F., Wang, C. & Ma, H. A real-time multi-vehicle tracking framework in intelligent vehicular networks. China Commun. 18, 89–99 (2021).
Feng, Z. & Wang, H. Efficient object tracking algorithm based on lightweight siamese networks. Eng. Appl. Artif. Intell. 133, (2024).
Hu, W. et al. Active contour-based visual tracking by integrating colors, shapes, and motions. IEEE Transactions on Image Processing 22, 1778–1792 (2012).
Zhang, J., Zhang, M., Zhang, H., Cai, Z. & Zhu, L. Fqtrack: Object tracking method based on a feature-enhanced memory network and memory quality selection mechanism. Electronics 13, 3221 (2024).
Pinto, J. et al. Deep learning for model-based multiobject tracking. IEEE Transactions on Aerosp. Electron. Syst. 59, 7363–7379 (2023).
Huynh, S. V. A strong baseline for vehicle re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4147–4154 (2021).
Amiri, A., Kaya, A. & Keceli, A. S. A comprehensive survey on deep-learning-based vehicle re-identification: Models, data sets and challenges. arXiv preprint arXiv:2401.10643 (2024).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, 2961–2969 (2017).
Terven, J., Córdova-Esparza, D.-M. & Romero-González, J.-A. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and Yolo-NAS. Mach. Learn. Knowl. Extr.5, 1680–1716 (2023).
Kirillov, A. et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4015–4026 (2023).
Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Radford, A. et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763 (PMLR, 2021).
Du, Y. et al. Strongsort: Make deepsort great again. IEEE Trans. Multi.25, 8725–8737 (2023).
Wojke, N., Bewley, A. & Paulus, D. Simple online and realtime tracking with a deep association metric. In 2017 IEEE international conference on image processing (ICIP), 3645–3649 (IEEE, 2017).
Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
Li, C. et al. Pp-ocrv3: More attempts for the improvement of ultra lightweight ocr system. arXiv preprint arXiv:2206.03001 (2022).
Feng, Z. et al. Rethinking efficient lane detection via curve modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 17062–17070 (2022).
Wen, L. et al. Ua-detrac: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 193, (2020).
Liu, X., Liu, W., Mei, T. spsampsps Ma, H. A deep learning-based approach to progressive vehicle re-identification for urban surveillance. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, 869–884 (Springer, 2016).
Russell, B. C., Torralba, A., Murphy, K. P. & Freeman, W. T. Labelme: a database and web-based tool for image annotation. Int. journal computer vision 77, 157–173 (2008).
Sochor, J. et al. Brnocompspeed: Review of traffic camera calibration and comprehensive dataset for monocular speed measurement. arXiv preprint arXiv:1702.064413, 6 (2017).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence 39, 1137–1149 (2016).
Liu, W. et al. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, 21–37 (Springer, 2016).
Wang, L. et al. Evolving boxes for fast vehicle detection. In 2017 IEEE international conference on multimedia and Expo (ICME), 1135–1140 (IEEE, 2017).
Blackman, S. S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 19, 5–18 (2004).
Lyu, S. et al. Ua-detrac 2017: Report of avss2017 & iwt4s challenge on advanced traffic monitoring. In 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 1–7 (IEEE, 2017).
Smith, R. An overview of the tesseract ocr engine. In Ninth international conference on document analysis and recognition (ICDAR 2007), vol. 2, 629–633 (IEEE, 2007).
Zhou, X. et al. East: an efficient and accurate scene text detector. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 5551–5560 (2017).
Liao, M., Shi, B., Bai, X., Wang, X. & Liu, W. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the AAAI conference on artificial intelligence, vol. 31 (2017).
Deng, D., Liu, H., Li, X. & Cai, D. Pixellink: Detecting scene text via instance segmentation. In Proceedings of the AAAI conference on artificial intelligence, vol. 32 (2018).
Wang, W. et al. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9336–9345 (2019).
Du, Y. et al. Pp-ocrv2: Bag of tricks for ultra lightweight ocr system. arXiv preprint arXiv:2109.03144 (2021).
Tang, Y., Wu, D., Jin, Z., Zou, W. & Li, X. Multi-modal metric learning for vehicle re-identification in traffic surveillance environment. In 2017 IEEE International Conference on Image Processing (ICIP), 2254–2258 (IEEE, 2017).
Liu, X., Zhang, S., Huang, Q. & Gao, W. Ram: a region-aware deep model for vehicle re-identification. In 2018 IEEE international conference on multimedia and expo (ICME), 1–6 (IEEE, 2018).
Qian, J., Jiang, W., Luo, H. & Yu, H. Stripe-based and attribute-aware network: A two-branch deep model for vehicle re-identification. Measurement Science and Technology 31, 095401 (2020).
Jin, X., Lan, C., Zeng, W. & Chen, Z. Uncertainty-aware multi-shot knowledge distillation for image-based object re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence 34, 11165–11172 (2020).
Meng, D. et al. Parsing-based view-aware embedding network for vehicle re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7103–7112 (2020).
Sun, Z., Nie, X., Xi, X. & Yin, Y. Cfvmnet: A multi-branch network for vehicle re-identification based on common field of view. In Proceedings of the 28th ACM international conference on multimedia, 3523–3531 (2020).
Kuma, R., Weill, E., Aghdasi, F. & Sriram, P. Vehicle re-identification: an efficient baseline using triplet embedding. In 2019 International Joint Conference on Neural Networks (IJCNN), 1–9 (IEEE, 2019).
He, S. et al. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF international conference on computer vision, 15013–15022 (2021).
Bai, L. & Rong, L. Vehicle re-identification with multiple discriminative features based on non-local-attention block. Sci. Reports 14, 31386 (2024).
Acknowledgements
The author extends heartfelt gratitude to the Communication University of Shanxi for providing financial support, which was instrumental in conducting this research.
Author information
Authors and Affiliations
Contributions
R.L. conceptualized the study, designed the research framework, implemented and evaluated the proposed algorithms, prepared all figures and tables, wrote the manuscript, reviewed, revised, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, R. A multi stage deep learning approach for real-time vehicle detection, tracking, and speed measurement in intelligent transportation systems. Sci Rep 15, 22531 (2025). https://doi.org/10.1038/s41598-025-07343-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-07343-5
