
Abstract
Remaining useful life (RUL) prediction is a crucial aspect of the prognostics health management of lithium-ion batteries (LIBs). Owing to the influence of resampling technology, particle degradation is often observed in the particle filter-based RUL prediction of LIBs, resulting in a low prediction accuracy and large uncertainty. In this paper, a novel particle flow filter with the grey model method (GM-PFF) is proposed to forecast the RUL and state of health of batteries. First, the least squares method is employed to obtain the initial values for double exponential empirical model parameters. Subsequently, the grey model is used to predict the current cycle capacity of LIBs as an observation value for the particle flow filter, solving the inaccurate estimation problem of the state of particle flow filter observation values, and the particle flow filter method is employed to update model parameters. Finally, a test dataset is divided into early, middle, and late stages to predict the RUL of LIBs and obtain the probability distributions. On the CALCE and NASA PCoE LIB dataset, GM-PFF reduces RMSE by 1% compared to PFF, exhibiting a higher prediction accuracy and effectively addressing the particle degradation problem.
Similar content being viewed by others

Introduction
Owing to their large capacity and long lifespan, lithium-ion batteries (LIBs) are commonly used in wearable devices, household appliances, medical equipment, aerospace applications, energy storage, and other fields1,2. With the continuing expansion of global industries, LIBs, as efficient and reliable energy storage devices, are increasingly used in various industries, such as new energy vehicles, large energy storage arrays, and transmission systems3. Concurrently, with the increasing demand for clean energy, LIBs have also received increasing attention in areas such as energy storage and smart grids. Undoubtedly, with the continuous development of technology, the performance of LIBs will be further improved, and their application fields will continue to expand.
With the increasing use of LIBs, their capacity decline and loss have become inevitable concerns. Solid electrolyte interface (SEI) film growth, electrode material dissolution, and metallic Li deposition primarily occur during LIBs cycles4,5. Under normal circumstances, the chemical properties of the internal electrodes and electrolytic materials of LIBs deteriorate with the increase in usage, resulting in increased internal side reactions and diminished battery capacity. The decline of LIB capacity can be used as an indicator to evaluate the remaining useful life (RUL) of an LIB6. The RUL of LIBs refers to the number of charging and discharging cycles that batteries experience when their available capacity decays to the end of life (EoL) capacity. Generally, when the available capacity of a battery decays to 70% or 80% of its rated capacity, it is considered to have reached its EoL7. If the health status of an LIB is not monitored, it can adversely affect the production and life. For example, the aging of LIBs has led to catastrophic accidents, such as fires and explosions in electric vehicles. Therefore, understanding and monitoring the state of health of LIBs and accurately predicting the RUL of LIBs under different conditions ensures the safe and reliable operation of the system while maximizing the use of the remaining value of the battery8.
To predict the RUL of lithium-ion batteries, scholars strive to identify the patterns of capacity degradation. However, the capacity fading of LIBs is nonlinear, making it challenging to establish an accurate mathematical model. Two approaches exist to predict the RUL of LIBs: model-driven and data-driven approaches9. The model-driven method establishes a mathematical model to predict the RUL of LIBs; however, it requires a thorough analysis of the internal degradation mechanisms of LIBs. The methods of optimizing model parameters, such as using the Kalman filter (KF) or particle filter (PF), can improve the prediction accuracy. Nevertheless, owing to the complexity and various influences of the degradation phenomena of LIBs, the accuracy of predictions using these methods may be limited. The data-driven method starts by collecting the historical capacity decline data of LIBs. Subsequently, the method uses machine learning techniques, such as support vector regression (SVR)10, neural networks (NNs)11, and Gaussian process regression (GPR)12, to mine hidden data and establishes the mathematical relationship between known and unknown data, thereby predicting the RUL of LIBs. Owing to the extensive data required for training machine learning methods, acquiring a significant amount of data in real-world applications to train precise models is challenging.
As early as in 2008, Saha and Goebel13 proposed the Bayeux Adams Theorem, a battery utilization computer application, to diagnose and predict the uncertainty of battery health and establish the RUL of LIBs, which pioneered the prediction and development of particle filter in the RUL of LIBs. LIBs have a higher energy density and longer lifespan than conventional batteries, making them the power source of choice for many modern electronic devices. The PF is an approximate Bayesian filter algorithm based on Monte Carlo sampling. It is suitable for nonlinear and non-Gaussian systems. The main idea of the PF is to extract random state particles from the posterior distribution to represent the distribution. The likelihood of extraction increases with the particle weight. However, after many iterations, only a few samples among a large number of particle samples have a higher weight, while low-weight samples still occupy computing resources, which is known as the particle depletion phenomenon14. Qiang Miao et al. introduced the unscented PF (UPF) into the prediction of battery RUL. The algorithm combines the PF and unscented KF (UKF) to improve the prediction accuracy of the PF algorithm15. Qiu et al. proposed using the improved cuckoo search algorithm to iteratively optimize particles and force them to move toward the maximum likelihood region, thus relieving the particle degeneracy phenomenon during filtering and improving the prediction accuracy16. Shuai Wang et al. proposed a prediction method based on the interacting multi-model PF, which can be used to determine the uncertain distribution of RUL17.
Daum et al. proposed a particle flow filter (PFF) called the Daum–Huang filter (DHF) to solve particle degradation; the filter gives each particle the same weight, without resampling, and does not rely on suggested density functions. Introducing the concept of homotopy theory, the particles flow from the prior probability distribution to the posterior probability distribution18. Generally, the PFF is approximately two orders of magnitude more accurate than the extended KF (EKF) or UKF in dealing with nonlinear problems. To achieve the same accuracy as that of the standard PFF, the PFF requires a reduction in number of particles by three orders of magnitude19. The flow strategy plays a key role in the PFF method. Different flow strategies result in different forms of particle flow. The information of particles can be fully utilized by designing a suitable flow strategy, improving the accuracy of prediction. In previous studies, various flow strategies, such as the IPF filter, NZDDH filter, and exacted DHF (EDHF), have been proposed20,21,22,23,24,25,26. Choi et al. proved that the performances of the IPF and EDH filters are better than those of well-known algorithms (bootstrap PF, auxiliary PF, EKF, and UKF) under linear, nonlinear, Gaussian, non-Gaussian, and different state space dimensions and particle numbers27. Mori et al. proposed an adaptive step-size PFF to deal with the rigid flow caused by solving differential equations, enabling a smoother particle flow from the prior distribution to the posterior distribution28. Different particle flow strategies can be selected and adjusted based on the characteristics of specific problems to obtain the best prediction effect.
Considering the excellent performance of the PFF in nonlinear dynamic systems, this study aims to apply the EDHF to estimate the parameters of the double-exponential model of lithium-ion battery capacity decay. The main contributions of this study are as follows:
-
(1)
The PFF is used for predicting the RUL of LIBs. Experiments are carried out on CALCE data sets, evaluation indicators use the root mean square error, absolute error and precision index. The results show that the method can greatly improve the accuracy and probability density distributions of LIB RUL prediction.
-
(2)
Combining the grey model with the PFF leverages the advantage of the grey model in providing relatively reliable predictions even in scenarios with limited sample data. Particle flow filtering, similar to traditional particle filtering, heavily relies on the observation equation for prediction accuracy. The predictive outcomes of the grey model are introduced into the PFF as observation states, and the particle weights are updated. The integration enables to better capture dynamic changes in the system, enhancing the accuracy of future state predictions.
The remainder of this manuscript is organized as follows. Section “Methodology” introduces the principles of the grey model and PFF. Section 3 introduces the experiment. The experimental results are presented and discussed in Sect. 4. Finally, Sect. 5 provides the summary of the study and the future scope of work.
Methodology
Grey model
The grey model was first proposed by Deng in 198229. It lies between the white model and black model and represents a system with partially known internal information and partially unknown information30. The grey model has unique advantages in predicting the data quality under extremely small sample sizes, with relatively good prediction effectiveness. The most typical one is GM (1,1); the process of establishing GM (1,1) is as follows31.
For a set of historical data,
The first-order accumulated generation order (1-AGO) of the historical array sequence is expressed as
The whitening differential equation is given by
where \(\alpha\) denotes the development grayscale, and \(\beta\) denotes the internal generation control grayscale; they conform to
The restored data and predicted values are as follows:
Particle flow filter
In the dynamic nonlinear system model, let \({{\text{X}}_k}\)represent the state vector of the target at time k and\({{\text{Z}}_k}\)denote the measurement value. Accordingly, the state equation and measurement equation are
where \({g_k}\) represents the state transition function, and \({\mu _k}\) denotes the process noise. Moreover, \({{\text{h}}_k}\) represents the observation function, and \({\nu _k}\) denotes the measurement noise.
Solving the Bayesian filter usually entails two steps:
(1) Prediction: Bayes’ theorem is used to infer the next state of the system based on the dynamic model and prior information of the system. The prediction step relies on the current state estimation and the system model, advancing and forecasting the state using the state transition equation:
(2) Update: Considering the observed data, an estimate of the state of the system is updated by comparing the observed data with the predicted estimate. The update step is based on Bayes’ theorem, using the observed data to correct the uncertainty of the forecast estimates.
where \(p({X_k}\left| {{X_{k - 1}})} \right.\) represents the state transition density function, and\(p({Z_k}\left| {{X_k})} \right.\) represents the likelihood function. The estimate of the system state can be continuously and iteratively updated by alternating the prediction and updating steps, enabling efficient inference and prediction of the system state32. While estimating the system state, the Bayesian filter method also provides quantification of the estimation uncertainty, making the inference of the system state more reliable and accurate.
The PFF introduces the homotopy principle in the topology to move particles from prior distribution to posterior distribution33. According to the Bayesian rule, the posterior probability density function (PDF) is calculated as
where \(p({Z_k}\left| {{Z_{k - 1}})} \right.=\int {p({X_k}\left| {{Z_{1:k - 1}})} \right.p({Z_k}\left| {{X_k})} \right.} d{X_k}\) is the normalization coefficient. The PF is a nonlinear filter algorithm based on the Monte Carlo method, which approximates the posterior probability distribution of a system through a series of randomly generated particles. The larger the particle weight, the closer it is to the real state. During the resampling process, particles with significant weights are more likely to be resampled, resulting in a loss of particle diversity.
The PFF assigns the same weight \(\omega _{k}^{j}\) to \({N_p}\) particles:
For convenience, let \(m\left( {{X_k}} \right)\) and \(n\left( {{X_k}} \right)\)represent the likelihood function \({\text{p(}}{{\text{Z}}_k}\left| {{X_k})} \right.\) and the prior probability density, respectively. The logarithmic homotopy function \(\log p({X_k},\lambda )\) can be defined as
where \(\lambda\) signifies a pseudo-discrete time, ranging from 0 to 1. The normalization coefficient is \(K\left( \lambda \right)=\int {g\left( {{X_k}} \right)} h{\left( {{X_k}} \right)^\lambda }dX\). When \(\lambda\) = 0, the particle flow is in the prior distribution state; while \(\lambda\) changes from 0 to 1, the particles move gradually, until \(\lambda\) = 1, at which point the particles move to the appropriate posterior distribution area. It is assumed that the particle flow obeys the Ito stochastic differential equation34:
where\(f\left( {X,\lambda } \right)\) represents the flow vector, and \(\sigma \left( {X,\lambda } \right)\) is the diffusion coefficient. Based on different assumptions, different solutions to Eq. (12) exist, and the precise PFF is a well-known solution method35,36. The EDH assumes that both the prior distribution and the likelihood distribution obey Gaussian distribution, and the precise PF can be expressed as
where
Here, R denotes the measurement noise variance matrix, P represents the prior covariance matrix, and H can be obtained through the first-order linearization of the measurement function. The state update of the jth particle is
Experimental design
Lithium-ion battery dataset
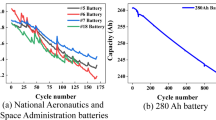
The lithium-ion batteries data used in this paper come from the Center for Advanced Life Cycle Engineering (CALCE) at the University of Maryland, College Park and National Aeronautics and Space Administration Prognostics Center of Excellence (NASA PCoE). LIBs operated under three conditions of charging, discharging, and EIS impedance at room temperature (24 °C). The termination life threshold of the battery is set at 70% of the rated capacity, which is 1.4Ah. The CALCE LIBs started constant current discharge from 4.2 V until the voltage droped to 2.5 V. They had a similar number of cycles to the previous three groups of batteries. The EoL of the batteries is 0.7Ah. The capacity degradation trends of two LIBs datasets are depicted in Fig. 1.
The end of life of batteries B05, B06, and B18 are 125, 109, and 112 cycles, respectively, while the EoL of batteries A1, A2, and A3 are 218, 197, and 144 cycles, respectively. Among these batteries, B06 has the shortest end of life, only 109 cycles. In order to further explore the laws of battery performance degradation and achieve early prediction of battery remaining useful life, this experiment set different life stages for more detailed observation and analysis, with 70 cycles set as the early stage, 80 cycles set as the mid stage, and 90 cycles set as the late stage.

Capacity degradation curve of lithium-ion batteries (LIBs).
Particle flow filter framework with grey model
The battery capacity calculation formula is as follows:
During the cycle use of LIBs, the capacity gradually decreases. The overall trend is initially fast and then slow. Once the capacity drops to a certain critical value, the battery can no longer be used. Currently, the recognized threshold is 70% of the rated capacity of the battery. According to the existing physical knowledge, the mapping relationship between the capacity of LIBs and the charge–discharge cycle is established, that is, the capacity decline model of LIBs:
where a, b, c, and d are model parameters, and k is the number of charge and discharge cycles of the lithium battery. This model is also called a double-exponential empirical decay model.
The state transition equation and measurement equation of the LIB system are as follows:
\({{\text{X}}_k}=\left[ {{a_k},{b_k},{c_k},{d_k}} \right],\)
In order to obtain accurate parameter estimation for the battery experience degradation model, the Matlab curve fitting toolbox was first used to fit six sets of experimental data from two datasets, obtaining the parameters a, b, c, and d of empirical formula (19) (see Table 1). Then take the mean parameter value of each dataset as the initial parameter for the least squares method.
The probability density function (PDF) describes the probability distribution of a battery reaching the failure threshold. The PDF of predicted RUL can be further calculated by
The framework of the proposed GM-PFF is depicted in Fig. 2.
The specific implementation processes for battery RUL prediction are as follows:
Step 1: Initialize the number of particles \({N_p}\) is 100, measurement noise \({\omega _a}\sim N\left( {0,1e - 6} \right)\), \({\omega _b}\sim N\left( {0,1e - 6} \right)\), \({\omega _c}\sim N\left( {0,1e - 6} \right)\), \({\omega _d}\sim N\left( {0,1e - 6} \right)\) and observation noise \({\nu _k}\sim N\left( {0,1e - 3} \right)\); fit the parameters of the degradation model for the first k cycles of the battery capacity using the least squares method; set the starting time ST = k+1; obtain the actual capacity \({{\text{Q}}_i}\;(i=k+1,\;k+2, \ldots ,\;m)\) as training data; and set the gray model sliding window t.
Step 2: Obtain the particle distribution, use the grey model to predict the battery capacity of the k + 1 cycle as an observation value for the PFF, find the Jacobian matrix H, and obtain A and b introduced in Sect. 1. Particles flow to a posterior distribution, update particle distribution.
Step 3: Set the prediction phase after the m + 1th cycle; if cycle i < m, repeat Step 1.2 and set the capacity failure threshold as FT.
Step 4: Use degradation models to predict battery capacity Q. In comparing Q and FT, if Q > FT, let m = m + 1 and repeat the prediction until Q < FT.
Step 5: Obtain the RUL of LIBs using RUL = m-ST-k and calculate the remaining lifespan predicted for each particle as a PDF.

GM-PFF framework for RUL prediction.
Evaluation index
Root mean square error (RMSE): The error between actual battery capacity and predicted battery capacity
Absolute error (AE): The absolute value of the difference between the actual remaining life of the battery and predicted remaining life.
Precision index (PI): The relative width of the probability density interval. And \(\sup (RUL)\) and \(\inf (RUL)\) represent the upper and lower bounds of the probability density interval, respectively.
Results and discussion
Owing to the nonlinear and stochastic characteristics of LIB capacity degradation trajectories, the grey model demonstrates superiority in handling small-sample nonlinear systems. It can be utilized to provide rough estimates of the LIB capacity.
Considering battery A1 as an example, the training data include those of 70, 80, and 90 cycles, and the capacity prediction results of the grey model are depicted in Fig. 3. Evidently, the GM (1,1) prediction trajectory approximates a straight line, making it suitable for predicting the degradation trend of the LIB capacity. However, its performance in predicting random terms is relatively weak.

Fitting Results of GM (1,1) for battery A1.
The prediction results of GM (1,1) for three battery groups are presented in Table 2. \(\alpha\) and \(\beta\) are parameter estimates of the grey model. To validate the accuracy of grey predictions, we introduce the posterior difference ratio c; a smaller c indicates a higher prediction accuracy. Generally, c values below 0.35, 0.5, and 0.65 signify high model accuracy, qualified accuracy, and basically qualified accuracy, respectively. Conversely, a c value that exceeds 0.65 indicates inadequate model accuracy. For battery A1, all c values are below 0.5, indicating a relatively high model accuracy and closeness of GM (1,1) predictions to the actual values. However, for battery A2, we observe that the later-stage c value is below 0.65, indicating basically qualified accuracy, while the early-stage c value exceeds 0.65, suggesting insufficient accuracy of GM (1,1) during that period. Overall, the c values for battery A2 fall between 0.5 and 0.65, indicating a moderate level of model accuracy.
This implies that GM (1,1) is feasible for predicting LIB capacity, particularly for battery A1, for which the model performs robustly. However, it is crucial to note that GM (1,1) is sensitive to historical data, particularly when considering degradation trends, where the influence of random terms is significant, potentially resulting in relatively poor model prediction effectiveness.
From Figs. 4, 5, 6 and 7, it is evident that the GM-PFF predictions closely align with the actual capacity degradation trends. The predicted endpoints of battery life closely match the actual endpoints, and the PI primarily concentrates around the predicted endpoints. The width of CALCE spans 2–3 cycles, while NASA PCoE’s width is 5–7 cycles. This suggests a concentrated particle distribution, indicating the accuracy of the proposed model in predicting the lifespan of LIBs.
Furthermore, we established three key prediction stages in the graph, corresponding to different developmental phases of battery life. Initially, 70 cycles serve as the early prediction stage, aiming to capture the initial performance degradation trends of the battery. Subsequently, 80 cycles represent the mid-term prediction stage with the aim of delving deeper into understanding the mid-term patterns of battery performance degradation. Finally, 90 cycles signify the late-stage prediction, aiming to accurately capture the characteristics of batteries that approach failure.
The black markers in the graph depict the actual evolution of LIB capacity, while the red markers represent the corresponding predictions of the remaining capacity using the GM-PFF model. This clear comparison demonstrates the accurate prediction of the battery capacity degradation trend by GM-PFF. The red solid line indicates the battery failure threshold at the 0.7 Ah capacity level of CALCE and 1.4 Ah capacity level of NASA PCoE. The blue solid line represents the PI that predicts the distribution of possible battery lifespans.
The graph analysis clarifies that the predictions of the GM-PFF model for the capacity degradation trend of LIBs closely match the actual situation. The predicted endpoints of battery life align closely with the actual endpoints, and the concentration of the PI around the predicted endpoints, with a width of 2–3 or 5–7 cycles, indicates a focused particle distribution. This means that the proposed model provides a relatively accurate estimate of the RUL of LIB, and reduces the range of uncertainty, providing greater support for decision-making.

Prediction results for capacity degradation trend of battery A1.

Prediction results for capacity degradation trend of battery A2.

Prediction results for capacity degradation trend of battery A3.

Prediction results for capacity degradation trend of battery B06.
A comparison of predictions between the GM-PFF and PFF on two datasets is presented in Tables 3 and 4. Both methods maintain consistency in the number of particles (100) as well as the experimental environment and parameter settings. From the perspective of RMSE, GM-PFF exhibits lower error values in all battery predictions. Taking the early stage of battery A1 as an example, the RMSE value of GM-PFF reached 0.0569, while the RMSE value of PFF was 0.0827, reducing the error of GM-PFF by about 31%. GM-PFF reduces RMSE error by more than 3% on the CALCE dataset and by more than 6% on the NASA PCoE dataset. This data clearly indicates that GM-PFF has a significant advantage in prediction accuracy. In terms of AE, taking the later stage of battery B06 as an example, the AE value of GM-PFF is only 3, far lower than PFF’s 14, and the error has been reduced by about 79%. GM-PFF has reduced AE prediction errors in both datasets, demonstrating its higher accuracy and stability in predicting the remaining battery life. The PI value of GM-PFF is also relatively small, which means that the uncertainty of its prediction results is lower. We noticed that the errors in predicting B06 and B18 in GM-PFF at the beginning of the 90th cycle were relatively large. This is due to the capacity recovery phenomenon of the battery at the 90th cycle, which caused a deviation between the observed values and the predicted values, affecting the estimated model parameters and increasing the error. Due to the trend of the exponential empirical model, it may cause errors in predicting trends on some batteries. As the predicted data increases, the prediction error of GM-PFF decreases on CALCE batteries. GM-PFF is more reliable in predicting battery capacity degradation and can provide more accurate guidance for battery management and maintenance.
In summary, the GM-PFF demonstrates a remarkable predictive performance in handling the nonlinear and complex nature of LIB capacity degradation. The results of this study indicate that the GM-PFF is highly applicable for addressing battery capacity degradation problems characterized by randomness and complexity.
Conclusion
Accurate RUL prediction is at the core of LIBs Prognostics and Health Management (PHM). Particle filter is one of the primary model-driven methods for RUL prediction. However, the particle degeneracy is an inevitable issue, which will lead to a decrease in the prediction accuracy. This study introduced the grey model and PFF to predict the remaining useful life of LIBs. Evaluations were conducted using three performance metrics, RMSE, AE, and PI, to assess the PFF results at different stages (early, middle, and late periods). Probability density distribution ranges were used to express the uncertainty of prediction outcomes. Experimental results on two commonly used datasets indicate that, compared to the traditional PF, the proposed GM-PFF mitigates the risk of particle degeneration, narrows the uncertainty range of prediction results, and exhibits lower errors in predicting the RUL of LIBs. However, the accuracy of particle flow filter predictions is excessively dependent on the initial values of model parameters. Future research will involve introducing different particle flow strategies to predict the RUL of LIBs as well as analyzing and comparing the performance of various PFF types, with the aim of enhancing the accuracy and robustness of PFF predictions.
Data availability
The data can be accessed at https://calce.umd.edu/battery-data.
References
Jiang, H. et al. Multiple health indicators assisting data-driven prediction of the later service life for lithium-ion batteries. J. Power Sources 542, 1818. https://doi.org/10.1016/j.jpowsour.2022.231818 (2022).
Li, X., Yuan, C. & Wang, Z. State of health estimation for Li-ion battery via partial incremental capacity analysis based on support vector regression. Energy 203, 117852. https://doi.org/10.1016/j.energy.2020.117852 (2020).
Hu, X., Xu, L., Lin, X. & Pecht, M. Battery lifetime prognostics. Joule 4, 310–346. https://doi.org/10.1016/j.joule.2019.11.018 (2020).
Hu, X., Feng, F., Liu, K., Zhang, L., Xie, J. & Liu, B. State estimation for advanced battery management: Key challenges and future trends. Renew. Sustain. Energy Rev. 114, 13 (2019).
Park, S. W., Lee, H. & Won, Y. S. A novel aging parameter method for online estimation of lithium-ion battery states of charge and health. J. Energy Storage 48, 3987. https://doi.org/10.1016/j.est.2022.103987 (2022).
Wang, J. et al. State of health trajectory prediction based on multi-output gaussian process regression for lithium-ion battery. Batteries 8, 134. https://doi.org/10.3390/batteries8100134 (2022).
Severson, K. A. et al. Data-driven prediction of battery cycle life before capacity degradation. Nat. Energy. 4, 383–391. https://doi.org/10.1038/s41560-019-0356-8 (2019).
Rauf, H., Khalid, M. & Arshad, N. Machine learning in state of health and remaining useful life estimation: theoretical and technological development in battery degradation modelling. Renew. Sustain. Energy Rev. 156, 111903. https://doi.org/10.1016/j.rser.2021.111903 (2022).
Jiao, R., Peng, K. & Dong, J. Remaining useful life prediction of lithium-ion batteries based on conditional variational autoencoders-particle filter. IEEE Trans. Instrum. Meas. 69, 8831–8843. https://doi.org/10.1109/TIM.2020.2996004 (2020).
Li, X., Yuan, C. & Wang, Z. State of health estimation for Li-ion battery via partial incremental capacity analysis based on support vector regression. Energy 203, 117852. https://doi.org/10.1016/j.energy.2020.117852 (2020).
Liu, Y. et al. A novel remaining useful life prediction method for lithium-ion battery based on long short-term memory network optimized by improved sparrow search algorithm. J. Energy Storage 61, 106645. https://doi.org/10.1016/j.est.2023.106645 (2023).
Liu, K., Li, Y., Hu, X., Lucu, M. & Widanage, W. D. Gaussian process regression with automatic relevance determination kernel for calendar aging prediction of lithium-ion batteries. IEEE Trans. Ind. Inf. 16, 3767–3777. https://doi.org/10.1109/TII.2019.2941747 (2020).
Saha, B. & Goebel, K. Uncertainty management for diagnostics and prognostics of batteries using bayesian techniques. IEEE Publ. https://doi.org/10.1109/AERO.2008.4526631 (2008).
Mo, Y. W. & Xiao, D. Y. Evolutionary particle filter and its application. Control Theory Technol. 22(2), 269–272. https://doi.org/10.7641/j.issn.1000-8152.2005.2.019 (2005).
Miao, Q., Xie, L., Cui, H., Liang, W. & Pecht, M. Remaining useful life prediction of lithium-ion battery with unscented particle filter technique. Microelectron. Reliab. 53, 805–810. https://doi.org/10.1016/j.microrel.2012.12.004 (2013).
Qiu, X., Wu, W. & Wang, S. Remaining useful life prediction of lithium-ion battery based on improved cuckoo search particle filter and a novel state of charge estimation method. J. Power Sources 450, 227700. https://doi.org/10.1016/j.jpowsour.2020.227700 (2020).
Wang, S., Han, W., Chen, L., Zhang, X. & Pecht, M. Experimental verification of lithium-ion battery prognostics based on an interacting multiple model particle filter. Trans. Inst. Meas. Control 2020, 01423312. https://doi.org/10.1177/0142331220961576 (2020).
Daum, F. & Huang, J. Nonlinear filters with log-homotopy. Proc. SPIE Int. Soc. Opt. Eng. 7698, 5920–5923 (2007).
Daum, F. & Huang, J. Particle degeneracy: Root cause and solution. Proc. SPIE Int. Soc. Opt. Eng. 8050, 7167. https://doi.org/10.1117/12.877167 (2011).
Daum, F., Huang, J., Krichman, M. & Kohen, T. Seventeen dubious methods to approximate the gradient for nonlinear filters with particle flow, Signal & Data Processing of Small Targets (International Society for Optics and Photonics, 2009). https://doi.org/10.1117/12.823519
Daum, F. & Huang, J. Particle flow for nonlinear filters, Bayesian decisions and transport. International Conference on Information Fusion (IEEE Publications, 2013).
Daum, F. & Huang, J. Particle flow with non-zero diffusion for nonlinear filters. SPIE Symposium on Signal Processing, SPIE Proceedings, Baltimore Maryland. https://doi.org/10.1117/12.2009363 (2013).
Daum, F. & Huang, J. Seven dubious methods to mitigate stiffness in particle flow with nonzero diffusion for nonlinear filters, Bayesian decisions and transport. SPIE Symposium on Signal and Data Processing of Small Targets, Baltimore, Maryland (2014).
Daum, F. & Huang, J. How to avoid normalization of particle flow for nonlinear filters, Bayesian decisions, and transport. SPIE Symposium on Signal and Data Processing of Small Targets (2014).
Daum, F., Huang, J. & Noushin, A. Coulomb’s law particle flow for nonlinear filters. Proc. SPIE. 7698, 5920–5923. https://doi.org/10.1117/12.887514 (2012).
Daum, F. & Huang, J. Small curvature particle flow for nonlinear filter. Proc. SPIE Int. Soc. Opt. Eng. 8393, 7 (2011).
Choi, S., Willett, P., Daum, F. & Huang, J. Discussion and application of the homotopy filter. Proc. SPIE Int. Soc. Opt. Eng. https://doi.org/10.1117/12.886385 (2011).
Mori, S., Daum, F. & Douglas, J. Adaptive step size approach to homotopy-based particle filter Bayesian update. International Conference on Information Fusion (IEEE, 2016).
Ju-Long, D. Control problems of grey systems. Syst. Control Lett. 1, 288–294. https://doi.org/10.1016/S0167-6911(82)80025-X (2020).
Chen, L. et al. Remaining useful life prediction of battery using a novel indicator and framework with fractional grey model and unscented particle filter. IEEE Trans. Power Electron. 35, 5850–5859. https://doi.org/10.1109/TPEL.2019.2952620 (2024).
Xu, Z., Xie, N. & Li, K. Remaining useful life prediction for lithium-ion batteries with an improved grey particle filter model. J. Energy Storage. 78, 110081. https://doi.org/10.1016/j.est.2023.110081 (1982).
Hong, S., Qin, C., Lai, X., Meng, Z. & Dai, H. State-of-health estimation and remaining useful life prediction for lithium-ion batteries based on an improved particle filter algorithm. J. Energy Storage https://doi.org/10.1016/j.est.2023.107179 (2023).
Whitehead, G. W. Elements of Homotopy Theory (Springer Science and Business Media, 2012).
Hall, A. J. & Wake, G. C. Functional differential equations determining steady size distributions for populations of cells growing exponentially. J. Aust Math. Soc. Ser. B Appl. Math. 31, 434–453. https://doi.org/10.1017/S0334270000006779 (1990).
Daum, F. & Huang, J. Exact particle flow for nonlinear filters. IEEE International Conference on Acoustics (IEEE Publications, 2011).
Daum, F., Huang, J. & Noushin, A. New theory and numerical results for Gromov’s method for stochastic particle flow filters. https://doi.org/10.23919/ICIF.2018.8455287 (2018).
Acknowledgements
This work is partially supported by the Natural Science Foundation Project of Fujian Province (2023J01297). Thanks for the realistic LIB degradation data from the Center for Advanced Life Cycle Engineering (CALCE) of Maryland University.
Author information
Authors and Affiliations
Contributions
Wang Shuai and Li yiting wrote the main manuscript text and Zhou Shoubinand Chen Lifei prepared all figures and Michael Pecht is responsible for language. All authors reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shuai, W., Yiting, L., Shoubin, Z. et al. Remaining useful life prediction of lithium-ion batteries using a novel particle flow filter framework with grey model. Sci Rep 15, 3311 (2025). https://doi.org/10.1038/s41598-025-86511-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-86511-z
