
Abstract
The coronavirus disease 2019 (COVID-19) interventions in interrupting transmission have paid heavy losses politically and economically. The Chinese government has replaced scaling up testing with monitoring focus groups and randomly supervising sampling, encouraging scientific research on the COVID-19 transmission curve to be confirmed by constructing epidemiological models, which include statistical models, computer simulations, mathematical illustrations of the pathogen and its effects, and several other methodologies. Although predicting and forecasting the propagation of COVID-19 are valuable, they nevertheless present an enormous challenge. This paper emphasis on pandemic simulation models by introduced respiratory-specific transmission to extend and complement the classical Susceptible-Exposed-(Asymptomatic)-Infected-Recovered SE(A)IR model to assess the significance of the COVID-19 transmission control features to provide an explanation of the rationale for the government policy. A novel epidemiological model is developed using mean-field theory. Utilizing the SE(A)IR extended framework, which is a suitable method for describing the progression of epidemics over actual or genuine landscapes, we have developed a novel model named SEIAPUFR. This model effectively detects the connections between various stages of infection. Subsequently, we formulated eight ordinary differential equations that precisely depict the population’s temporal development inside each segment. Furthermore, we calibrated the transmission and clearance rates by considering the impact of various control strategies on the epidemiological dynamics, which we used to project the future course of COVID-19. Based on these parameter values, our emphasis was on determining the criteria for stabilizing the disease-free equilibrium (DEF). We also developed model parameters that are appropriate for COVID-19 outbreaks, taking into account varied population sizes. Ultimately, we conducted simulations and predictions for other prominent cities in China, such as Wuhan, Shanghai, Guangzhou, and Shenzhen, that have recently been affected by the COVID-19 outbreak. By integrating different control measures, respiratory-specific modeling, and disease supervision sampling into an expanded SEI (A) R epidemic model, we found that supervision sampling can improve early warning of viral activity levels and superspreading events, and explained the significance of containments in controlling COVID-19 transmission and the rationality of policy by the influence of different containment measures on the transmission rate. These results indicate that the control measures during the pandemic interrupted the transmission chain mainly by inhibiting respiratory transmission, and the proportion of supervision sampling should be proportional to the transmission rate, especially only aimed at preventing a resurgence of SARS-CoV-2 transmission in low-prevalence areas. Furthermore, The incidence hazard of Males and Females was 1.39(1.23–1.58), and 1.43(1.26–1.63), respectively. Our investigation found that the ratio of peak sampling is directly related to the transmission rate, and both decrease when control measures are implemented. Consequently, the control measures during the pandemic interrupted the transmission chain mainly by inhibiting respiratory transmission. Reasonable and effective interventions during the early stage can flatten the transmission curve, which will slow the momentum of the outbreak to reduce medical pressure.
Similar content being viewed by others
Introduction
In the absence of global containment, the current COVID-19 pandemic still calls for modeling tools to assess disease features in order to avoid greater social, economic and political disruption1,2. A common goal is to capture viral spread patterns and predictably adopt available policies to interrupt transmission before the peak of infection, which may be a long-term strategy for future responses to COVID-193. Until SARS-CoV-2 testing is restarted on a wide scale, a possible strategy would be to reflect epidemiologic trends in the overall population in real time via multistage sampling, as noted in our previous studies4. However, modeling efforts for multistage sampling would be difficult since the rates of transmission and clearance would change in response to control measures such as masks, quarantines, and vaccines, which is one of the common shortcomings of the classic SEI(A)R model5. To address these issues, disease-specific parameter drivers need to be modified and tested with different control measures imposed on the disease to see how pandemic transmission patterns change6,7.
The other aspect is that traditional epidemiologic models rarely capture well the spread differences between respiratory-specific and nonrespiratory infectious diseases8. For example, the classical SE(A)IR models were used for epidemiological prediction and control of the West Nile virus pandemic in North America in the 1990s9 and the SARS pandemic in Asia in 200310, but were unable to directly distinguish the spreading characteristics of these two infectious diseases in the modeling logics. Based on these concerns, we introduced respiratory-specific transmission to extend and complement the classical SE(A)IR model to assess the influence of different control measures on COVID-19 transmission.
A new epidemiological model is constructed based on mean-field theory11,12. First, based on the SE(A)IR extended framework, a natural framework to describe epidemic dynamics unfolding over real or realistic landscapes, we built a new model called SEIAPUFR that identifies the relationships among different phases of infection. Then we established eight ordinary differential equations that describe the population’s evolution through time in each compartment. Second, we adjusted the rates of transmission and clearance based on the influence of different control measures on the epidemiologic process which we used to extrapolate the future trajectory of COVID-19. On the basis of these parameter settings, we focused on the stabilization conditions of disease-free equilibrium (DEF)2, and derived model parameters suitable for COVID-19 outbreaks according to different population sizes. Finally, we conduct simulations and forecasts for several first-tier cities in China that recently attacked COVID-19, including Wuhan, Shanghai, Guangzhou, and Shenzhen.

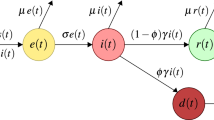
In the SEIAPUFR model, a graphical scheme represents the relationships among different phases of infection: S, susceptible (uninfected); E, exposed (those who have been polluted but are not yet infectious due to the incubation period); I, infected (asymptomatic or paucisymptomatic infected, undiscovered); A, diagnosed (asymptomatic infected, identified); P, respiratory specific model (symptomatic infected, detected); U, non-respiratory specific model; F, supervised sampling in the infected population (detected); R, healed (removed).
Methods
Modeling instructions
Here, we consider a large-scale metapopulation model describing a set of cities with baseline population Ni connected by human mobility; the whole population is subdivided into the COVID-19-relevant eight epidemiological compartments, which are: susceptible populations (Si, uninfected), exposed populations (Ei, contaminated but uninfected due to incubation period), infected populations (Ii, symptomatic or mildly symptomatic infection), asymptomatic population (Ai, asymptomatic infection), respiratory-specific model (Pi, respiratory-transmitted infection, e.g., droplets, aerosols), non-respiratory-specific population (Ui, non-respiratory-transmitted, e.g., contact, diet), supervised sampling of infected populations (Fi, detected), and recovered individuals (Ri) for each city i (show in Fig. 1).
All of the parameters evaluated are positive integers indicated by Greek letters. The interconnections between different phases of infection are illustrated in Fig. 1. The following are the parameters:
Parameter η is the inflow rate (including birth and immigration). For each period i, the transmission rate βi(the risk of disease transmission in a single encounter multiplied by the average number of contacts per person) occurs when a susceptible subject comes into touch with an exposed, infected, asymptomatic, respiratory-specific model or non-respiratory specific. We assume that susceptible people get vaccinated at a constant rate per capita Cj(0 ≤ Cj < 1, j ∈ {0, 1, 2, 3, 4}) (i.e., vaccine coverage rate). The vaccination effectiveness is λ(0 ≤ λ ≤ 1). When λ = 0, the vaccination has no effect. In contrast, when λ = 1, the vaccine is completely effective. g is the number of loci that were associated with SARS-CoV-2 infection and disease severity. \(\:\tau\:\) is the probability that those loci affect the general susceptibility population. These parameters can be changed since they impact various things, including government epidemic prevention efforts, quarantine, and immunization. The danger of infection from threatening people treated in adequate ICUs is low.
α and σ capture the incubation rate of detection relative to asymptomatic and symptomatic cases, respectively. These parameters reflect the level of attention on the disease and the number of tests performed over the population: they can be increased by enforcing a massive contact tracing. Moreover, these parameters are also the rate at which the exposed and asymptomatic population becomes infected. µ is the probability of infection for a susceptible population, which is the Wells-Riley mathematical equation developed by13) to express the transmission potential of infection as a function of the fraction of inhaled air that has been previously exhaled by someone in the building (i.e., rebreathed fraction) using CO2 concentration as a marker for exhaled-breath exposure. An infected person’s quantum generation rate is q(quanta/h). The breathing rate per individual is p(m3/h). The entire exposure time is t(h). V is the volume of the ventilated space (m3), and Q is the exterior air supply rate (m3/h). Based on the total CO2 level in the indoor air contributed from human origin and outdoor air supply, and person-to-person transmission of infectious diseases through recirculation air in the ventilation airspace, the outdoor air supply rate (Q) can be expressed as functions of the fraction of indoor that is exhaled breath (f ), people in the ventilation airspace (n), and breathing rate per person (p), as Q = np/f.
ρ is the probability rate at which the exposed become infected among the whole population. N∗ is the estimated number of SARS-CoV-2 infections correcting for imperfect test accuracy14). ϑg the parameters for the growth rate in the model, k is the maximum values of the model attained as t goes to infinity, N+ is the sum of the number of confirmed cases (tested positive), Sensitivity(Sen) < 1, or Specificity (Spec) < 1. These parameters are test-dependent but may be partially increased by improving the test efficacy and acquiring immunity against the virus.
The rate of infected subjects being removed is denoted by γi; it may differ significantly if an appropriate treatment for the disease is known and adopted for diagnosed patients, such as the perfect test and the vaccine efficacy at each specific period i, but otherwise, they are likely comparable. This value can be raised due to better therapies and viral immunity.
Description of modeling approaches
We consider the probability rate of becoming susceptible again, after having recovered from the infection, in the model because of the vaccine efficacy and imperfect correction of the test among the entire population, which appears not to be negligible since the epidemic can be transmitted without symptoms and posed a crucial problem for knowing the real infectious time frame and potential exposures15). According to several studies, asymptomatic and presymptomatic COVID-19 infections are equally transmissible in the early days of the illness16). Although some data suggest that SARS-CoV-2 has resurfaced17), the presence of viral RNA in respiratory samples might indicate persistence rather than return. More extensive studies have found that 30–70% of persons who test positive have little or no symptoms18) and that asymptomatic and pre-symptomatic people can transmit the pandemic19). The literature is still looking at the subacute and long-term effects of COVID-19, which can affect multiple organ systems20). Early evidence suggests that SARS-CoV-2 infection causes long-term effects, including tiredness, dyspnea, chest discomfort, cognitive problems, arthralgia, and declining quality of life21). These consequences might be caused by cellular damage, an inflammatory cytokine-producing innate immune response, or a pro-coagulant state caused by SARS-CoV-2 infection22). Previous coronavirus infections, such as the SARS epidemic in 2003 and the Middle East respiratory sickness (MERS) outbreak in 2012, have left survivors with a similar set of symptoms, raising concerns about COVID-19’s clinically significant consequences23).
SARS-CoV-2 has been found in asymptomatic people24), suggesting that subclinical active infection is a major factor in this epidemic. COVID-19 is often diagnosed by a reverse transcription polymerase chain reaction (RT-PCR) viral RNA test, which appears to be sensitive to the assay technique as well as the time of specimen collection, transit, and storage24). As a result, many infected persons probably remained undiscovered because they were subclinical or asymptomatic. We were particularly interested in predicting the effect of the respiratory-specific model, as well as supervision sampling, where temporary immunity is still likely in place, and the possibility of reinfection would have a significant impact on the total number of susceptible individuals, resulting in significant differences in the evolution of the pandemic curves we examined. We incorporate the effect of engineering control measures like increased air exchange and air filtration rates with personal masking, as well as public health interventions like vaccination, isolation, social distancing mandates, transmission dampening through the use of face masks, and contact tracing, on containing the spread of COVID-19 indoor and outdoor airborne infections to back up this claim. We utilize these findings to learn about epidemic progression and thereby model the initial wave of transmission using a deterministic SEIR compartmental framework25,26,27). This process-based knowledge of how non-pharmaceutical interventions (NPIs) alter epidemiological processes is utilized to predict COVID-19’s future trajectory and how various existing NPIs may affect it. Furthermore, when the potential of reinfection is given, the numerical simulation results of the model with varied population sizes show that the development is not similar. The main difference is that the restored population diminishes with time. As a result, while we cannot rule out the possibility that adaptive immunity to SARS-CoV-2 may not give long-term protection, we can safely assume that the risk of reinfection is not insignificant within the scope of our model.
Our approach distinguishes between non-diagnosed people who spread the illness more because they are not isolated and diagnosed people who spread the disease considerably less because they are correctly isolated and follow tight procedures, whether in the hospital or at home. Our model also takes into consideration the differential between the respiratory and non-respiratory populations, as well as the supervisory sampling on a single day throughout the epidemic. SARS-CoV-2 transmission from person to person in the home has been documented in China28,29). Although infection of COVID-19-positive persons’ household members is feasible, the disease incidence is difficult to determine now. Separating sick persons in designated quarantine centers is the only method to eliminate this risk30). Furthermore, our model considers vaccination efficiency and the total dosage received by the population throughout the pandemic.
Our model does not account for a possible latency between exposure to the virus and onset of infectiousness because there is mounting evidence that an infected individual can transmit the virus at an early, preclinical stage of the disease, based on epidemiological investigation of COVID-19 clusters31,32). Furthermore, recent studies have found that the median serial interval values for COVID-19 are near or less than the median incubation time33), indicating that the illness can be transmitted before symptoms appear. As a result, we did not think it was essential to introduce more stages: even if they are asymptomatic, those who have been exposed to the virus can still transmit it; thus, they fall in between the infected and diagnosed phases.
Finally, the SEIAPUFR model is a mean-field model that captures the average influence of occurrences affecting the whole population. Social mixing tendencies are averaged throughout the population and integrated into our parameters. Our model, on the other hand, is fully adaptable and suitable for incorporating features such as a distinction between respiratory and non-respiratory population groups and the importance of adjusting COVID-19 infection estimates for testing practices and diagnostic accuracy during periods of low testing rates. Another potential future development is to extend the model to predict the concurrent evolution of other diseases that, due to the epidemic emergency, may be overestimated, underestimated, or not treated appropriately because the healthcare system is overburdened, resulting in an increased number of ’collateral’ deaths not directly linked to the virus.
Analysis of the mathematical model
The SEIAPUFR model (1) is an eight-differential- equation bilinear system. The system is positive: if all state variables start with non-negative values at 0, they will take non-negative values for t ≥ 0.
When the total population size N (t) varies, it is frequently required to evaluate the proportions of people in eight epidemiological classes.
It is easy to check that s, e, i, a, p, u, f, and r fulfill the following set of differential equations:
The system is compartmental and exhibits the masse conservation property: \(\:\dot{s}+\dot{e}+\dot{i}+\dot{a}+\dot{p}+\dot{u}+\dot{f}+\dot{r}=0\), they are implying that the total population remains constant. Because the variables represent population fractions, they are restricted to \(\:s+e+i+a+p+u+f\:+r\:=\:1\), where 1 represents the whole population.
The variables r are absent from the first seven equations of (2). First, we will look at the simplified system.
and calculate r using \(\:r=1-s-e-i-a-p-u-f\) or \(\:\dot{r}={\gamma\:}_{i}(i+a+p+u)\). The equation’s feasible region (3) is
which can be shown to be positivity invariant (i.e., given non-negative beginning values in Ω, have non-negative components and stay in Ω for t ≥ 0) and universally attractive in \(\:{\mathcal{R}}_{+}^{7}\)with respect to (3). As a result, we concentrate on the dynamics of (3) in Ω. ∂Ω and Ω◦, respectively, represent the boundary and inside of Ω.
The basic reproduction number and DFE (Disease-Free Equilibrium)
The basic reproduction number
The basic reproduction number, as an indicator of disease transmission within a community, is crucial for understanding and managing a continuing pandemic. It is defined as the mean number of infections produced by one contaminated person during their contagious stage in a completely healthy community. Employing the next generation matrix methodology for our framework (1), the basic reproduction number may be determined by analyzing the generation matrices F and V, which represent the Jacobian matrices related to the emergence of new viruses and the net transition rate from the respective areas, accordingly
The basic reproduction number is given by the spectral radius of the product matrix \(\:F{V}^{-1}\).
DFE (Disease-Free Equilibrium)
There are two particular concerns when addressing a disease’s eradication in a population of varied sizes. The more challenging method of eradicating the pandemic (COVID-19) requires that the overall number of infected people be \(\:E\left(t\right)+I\left(t\right)+A\left(t\right)+P\left(t\right)+U\left(t\right)+F\left(t\right) \to 0\), whereas the weaker method requires that the proportion sum be \(\:e\left(t\right)+i\left(t\right)+a\left(t\right)+p\left(t\right)+p\left(t\right)+f\left(t\right) \to 0\) (confer34 for more details). We are motivated to look for conditions that will allow the DFE to exist and be stable for\(\:\:\:{G}_{0}(\frac{\eta\:}{{\sum\:}_{j=1}^{4}{C}_{j}\lambda\:+g\tau\:sN},0,\text{0,0},\text{0,0},{f}_{0})\) and inherent equilibrium point \(\:{G}^{*}({s}^{*},{e}^{*},{i}^{*},{a}^{*},{p}^{*},{u}^{*},{f}^{*})\). Clearly, the DFE of (3) is \(\:{G}_{0}(\frac{\eta\:}{{\sum\:}_{j=1}^{4}{C}_{j}\lambda\:s-g\tau\:sN},\text{0,0},\text{0,0},0,{f}_{0})\in\:{\Omega\:}\) which exists for all positive parameters. At each point \(\:G(s,\:e,\:i,\:a,\:p,\:u,\:f)\) the Jacobian matrix of (3) takes the form:
Where \(\:\xi\:=\frac{{\vartheta\:}_{g}{N}^{\text{*}}}{f}\left(\vartheta\:g{N}^{\text{*}}\text{l}\text{o}\text{g}\left(\frac{k}{f}\right)+\rho\:e-{\gamma\:}_{i}f\right)+{\gamma\:}_{i}\).
We derive the characteristic equation of J(G) at G = G0 to examine the stability of DFE:
The stability of G0 is equal to all (5) eigenvalues having a negative real portion, which is guaranteed by
The epidemiological threshold parameter R0 is used here. As a result, if R0 < 1, the DFE is locally asymptotically stable.
It finds that although \(\:{\widehat{R}}_{0}\)< 1 ensures \(\:{R}_{0}\) < 1, the opposite is not true.
Theorem 1
If < 1, of (3) is globally asymptotically stable in Ω; if R0 > 1, it is unstable. Except for those starting on the invariant s- and f-axes, which approach G0 along these axes, the solution of (3) starting sufficiently near G0 in Ω moves farther away from G0.
Proof of Theorem 1. We define an appropriate Lyapunov function \(\:{L}_{func}=\sigma\:\alpha\:e+\sigma\:i+\mu\:a+\sigma\:\left(1-\alpha\:\right)p+\rho\:u+\left(1-\mu\:\right){f}^{2}\), to verify the global stability of G0. When \(\:{L}_{func}\)is differentiated along (3), \(\:{L}_{\text{func}}^{{\prime\:}}\:\)is obtained by formulas below
When R0 ≤ 1, the greatest value of (8) in Ω is attained at the extremal points: M1(0, 0, 0, 0, 0, 0, 0); M2(1, 0, 0, 0, 0, 0, 0); M3(0, 1, 0, 0, 0, 0, 0); M4(0, 0, 1, 0, 0, 0, 0); M5(0, 0, 0, 1, 0, 0, 0); M6(0, 0, 0, 0, 1, 0, 0); M7(0, 0, 0, 0, 0, 1, 0); M8(0, 0, 0, 0, 0, 0, 1). (8) becomes an equality \(\:{L}_{\text{func}}^{{\prime\:}}=0\) ), if s = 0, e = 0, i = 0, a = 0, p = 0, u = 0, f = 0 or \(\:{\widehat{R}}_{0}=1\). The singleton {G0} is the greatest invariant set in \(\:\left\{\right(s,e,i,a,p,u,f)\in\:{\Omega\:}|{L}_{func}^{{\prime\:}}=0\}\). The DFE {G0} is globally asymptotically stable when \(\:{\widehat{R}}_{0}\) ≤ 1, according to LaSalle’s Invariance Principal35), Chap. 2,Theorem, 6.4.
when \(\:e=i=a=u=f=0,{L}_{\text{secfunc\:}}^{{\prime\:}}>0\) for \(\:s\), which is sufficiently close to \(\:\frac{\eta\:}{{\sum\:}_{j=1}^{4}\:{C}_{j}\lambda\:+g\tau\:sN}\). Except for those on the invariant s- and f-axes, solutions staring sufficiently near to G0 depart a neighborhood of G0 when (3) reduces to \(\:\stackrel{\prime }{s}=\eta\:-{\sum\:}_{j=1}^{4}\:{C}_{j}\lambda\:s-g\tau\:sN\) and therefore \(\:s\left(t\right)\to\:\eta\:-{\sum\:}_{j=1}^{4}\:{C}_{j}\lambda\:-g\tau\:sN\) as \(\:t\to\:{\infty\:}\).
It should be noted that eigenvalue analysis of J(G) may also verify the unstable nature of DFE G0 when R0 > 1. The threshold parameters R0 and \(\:{\widehat{R}}_{0}\) determine whether the infected fraction (e(t), i(t), a(t), p(t), u(t), f (t)) vanishes locally or globally in time. Reducing R0 to values less than unity can effectively ”eradicate” the epidemic (COVID-19). When \(\:{\widehat{R}}_{0}\) is changed to a value less than or equal to unity, the pandemic can be ”eradicated” even if it is enormous. R0 and \(\:{\widehat{R}}_{0}\) may be understood epidemiologically as disease transmission via contacts becoming stronger as both susceptible inflow and exposed ones grow. Both R0 and \(\:{\widehat{R}}_{0}\) are discovered to be decreasing functions of λ. If \(\:\lambda\:<\frac{\eta\:}{1+\eta\:}\) R0 rises with Cj and falls with Cj if implying that the high vaccination rate combined with low vaccine efficacy will likely make the pandemic ”persistent.” As the immunization rate λ rises, \(\:{\widehat{R}}_{0}\)decreases.
Epidemic outbreak function based on our model
Given the multitude of variables influencing the values of \(\:\beta\:\) and \(\:\gamma\:\), such as government actions for epidemic prevention, quarantine protocols, and vaccination efforts, it is not justifiable to treat \(\:\beta\:\) and \(\:\gamma\:\) as fixed constants. Furthermore, an alternative widely-used approach involves using a function to estimate the values of \(\:\beta\:\) and \(\:\gamma\:\), individually. This technique ensures the continuity of the values of \(\:\beta\:\) and \(\:\gamma\:\), resulting in frequent variations. Hence, this work integrates these two concepts, supposing that the values of \(\:\beta\:\) and \(\:\gamma\:\) remain constant inside a certain time frame, and are updated upon entering the subsequent period.
In a pandemic, the change rate of infected populations can indicate whether the disease is breaking out or fading. E, I, A, P, U, and F reflect the number of infections in the SEIAPUFR model(1). Those in E are still in incubation, but those in I, A, P, U, and F have already been infected. When the sum of E, I, A, P, U, and F change rates is more than 0, we can conclude that the disease is still spreading, that is
Which implies
By the SEIAPUFR model (1), we have
It follows that
\(\:\text{S}\text{u}\text{p}\text{p}\text{o}\text{s}\text{e}\:\text{t}\text{h}\text{a}\text{t}\:\text{t}\text{h}\text{e}\:\text{e}\text{x}\text{p}\text{r}\text{e}\text{s}\text{s}\text{i}\text{o}\text{n}\)\(\:{\gamma\:}_{i}\left[-\frac{(1+\rho\:)}{{\gamma\:}_{i}}E\left(t\right)+I\left(t\right)+A\left(t\right)+P\left(t\right)+U\left(t\right)+F\left(t\right)-\frac{{\vartheta\:}_{g}{N}^{\text{*}}}{{\gamma\:}_{i}}\text{l}\text{o}\text{g}\left(\frac{k}{F\left(t\right)}\right)\right]>0\)
then we have,
The virus is disappearing when the rate of change of \(\:E\left(t\right)+I\left(t\right)+A\left(t\right)+P\left(t\right)+U\left(t\right)+F\left(t\right)<0\). Using the above method, we have that
We know that the virus is under control and can coexist with people for a long time when the rate of change of \(\:E\left(t\right)+I\left(t\right)+A\left(t\right)+P\left(t\right)+U\left(t\right)+F\left(t\right)=0\).
As a result, we have
According to the mathematical study above, the formula of the outbreak factor created by the SEIAPUFR model at time t in each period i is defined by
We define \(\:\:{B}_{i}=\stackrel{-}{\left(B\right(t){)}_{i}}\)as the average value of the outbreak factor for the period i.
The spatial dissemination of COVID-19 throughout several urban areas
Given a collection of n interconnected communities, where the population of S,…,R are denoted as Sk,…,Rk correspondingly, we could lead to the following Eq.
\(\:{\beta\:}_{ik}\) represents the rate at which individuals in community k get infected. This expression should encompass both local community contacts and those linked with mobility, as stated by
Where, the parameters \(\:{\theta\:}_{j}^{Y}\left(Y\in\:\left\{i,a,p,u,f\right\}\right)\) represent the probability at which illness is transmitted from the five contagious groups, and these rates are reliant on the community, \(\:{D}_{0,lj}^{Y}\left(Y\in\:\left\{s,e,i,a,p,u,f,r\right\}\right)\) represents the likelihood ( \(\:\sum\:_{j=1}^{n}{D}_{0,lj}^{Y}=1\) for all k’s and Y’s) of individuals in epidemiology area Y, from community k, coming into interaction with individuals in community j, either as residents or while traveling from community l (note that j, k, and l might be the same). It should be noted that transmission has been presumed to vary depending on the frequency. On the other hand, the transmission rates \(\:{\theta\:}_{j}^{Y}\left(Y\in\:\left\{i,a,p,u,f\right\}\right)\:\)and monitoring parameters are considered to be potentially different for each community, which accounts for variations in disease transmission across different areas before containment measures were put in place(\(\:{\theta\:}_{j}^{Y})\).
The fundamental reproductive number of the spatial mode
In close proximity to the DFE, the condition is characterized by a baseline population size (Nk) in community k, where all people are vulnerable to the illness. Additionally, all other epidemiological compartments are empty (\(\:{e}_{k}={i}_{k}={a}_{k}={p}_{k}={u}_{k}={r}_{k}=0,\:and\:{f}_{k}={f}_{0}\:for\:all\:k{\prime\:}s\)), the simplified systems \(\:\dot{y}={J}_{0}y\) describes the dynamics of model (Eq. 18), where where \(\:y={\left[{{s}_{k},e}_{k},{i}_{k},{a}_{k},{p}_{k},{u}_{k},{f}_{k},{r}_{k}\right]}^{T}\)(where \(\:k=1,\cdots\:,n\)) and \(\:{J}_{0}\) is the spatial Jacobian matrix.
The identity matrix, denoted as I, and the null matrix, denoted as 0, both have a dimension of n. The matrices \(\:{\psi\:}_{0}^{Y}\left(Y\in\:\left\{i,a,p,u,f\right\}\right)\) are provided by
here N is a diagonal matrix consisting of the population sizes Nk as its non-zero entries. The matrices \(\:{D}_{0}^{Y}=\left[{D}_{0,lj}^{Y}\right]\left(Y\in\:\left\{s,i,a,p,u,f\right\}\right)\) reflect the contact terms that are regionally specifically and sub-stochastic, taking into account restrictions measures. The matrices \(\:\:\:{\theta\:}^{Y}\left(Y\in\:\left\{i,a,p,u,f\right\}\right)\) are diagonal matrices that include the contact rates as their non-zero members \(\:{\theta\:}_{j}^{Y}\), and \(\:{{\Gamma\:}}_{0}\) is a diagonal matrix consisting of the components of vector \(\:vN{D}_{0}^{s}\) as its non-zero entries, assuming that \(\:v\) is a row vector of size n and is unitary.
Due to its block-triangular form, it is evident that \(\:{J}_{0}\) has a single eigenvalue that is strictly negative, namely\(\:-(-\eta\:+\sum\:_{j=1}^{4}{C}_{j}\lambda\:+g\tau\:N)\), with a multiplicity of n. Hence, the stability characteristics of the DFE of model (Eq. 18), which ascertain the possibility of sustained disease transmission in the presence of controls, are connected to the eigenvalues of a lower-dimensional spatial Jacobian connected to the infection subsystem, i.e., The subset of state factors that are directly associated with the transmission of the illness in this particular situation \(\:\left\{{e}_{1},\cdots\:,{e}_{n},{i}_{1},\cdots\:,{i}_{n},{a}_{1},\cdots\:,{a}_{n},{p}_{1},\cdots\:,{p}_{n},{u}_{1},\cdots\:,{u}_{n},{f}_{1},\cdots\:,{f}_{n}\right\}\). It is important to know that the introduction of fading immunity does not alter the spectrum characteristics of the Jacobian matrix when assessed at the DFE. The Jacobian \(\:{J}_{0}^{{\prime\:}}\:\)is expressed as follows
The asymptotic stability qualities of the DFE may be evaluated using a NGM technique. The spectral radius of the NGM offers the projection of the control reproduction number, \(\:{R}_{0}\), which represents the average number of secondary infections caused by one contaminated people in a fully susceptible population with disease-containment measures in place. If the \(\:{R}_{0}\:\)is greater than 1, it indicates that the disease has the ability to establish itself in the community over time, resulting in endemic propagation. To calculate the value of \(\:{R}_{0}\) for the model described by Eq. (18), it is possible to break down the Jacobian of the infection subsystem into a matrix that represents spatial transmission.
and a transition matrix
It should be noted that \(\:{J}_{0}={V}_{0}+{W}_{0}\). The spatial NGM, which encompasses a vast ___domain \(\:{Q}_{0}^{L}\) and incorporates variables beyond the states-at-infection (namely, the exposed individuals \(\:{e}_{i}\)), may be expressed as follows:
Due to the distinctive block-triangular configuration of \(\:{Q}_{0}^{L}\), the spatial NGM with a limited ___domain (\(\:{Q}_{0}\), considering just \(\:{e}_{i}\))) may be represented as \(\:{Q}_{0}^{1}\). The control reproduction number may be determined by calculating the spectral radius of the NGM (with either a big or small ___domain) i.e.,
here, \(\:{M}_{0}^{i},\:\:{M}_{0}^{a},\:{M}_{0}^{p},\:\:{M}_{0}^{u},\:\:{M}_{0}^{f}\), represent five matrices that describe the specific contributions of different factors (infected, diagnosed, respiration specific, non-respiration specific, and supervised sampling) to the next generation of infections in a neighborhood of the DFE when disease containment measures are in place.
Fit of the model for the SARS-CoV-2 outbreak
Based on the varying population sizes, we deduce the model parameters. The estimated parameter values are based on various population sizes for the number of currently infected individuals with different SOI (asymptomatic or paucisymptomatic, quarantined at home, roughly corresponding to variables I(t) and A(t) in our model; symptomatic and respiratory specific, roughly corresponding to variable P (t) in our model; symptomatic and non-respiratory specific, roughly corresponding to variable U (t) in our model, the number of supervised sampling in infected and vaccinated population in the specific period, roughly corresponding to variable F (t) in our model), and the number of diagnosed individuals with non-imperfect test accuracy who recovered (approximately corresponding to the quantity \(\:{\int\:}_{0}^{t}{\gamma\:}_{i}\left(I\left(\psi\:\right)+A\left(\psi\:\right)+P\left(\psi\:\right)+U\left(\psi\:\right)\right)d\psi\:\) that can be computed based on our model). We fit the model to the number of presently infected cases, respiratory cases, and supervision sampling.
We use a best-fit technique to determine the settings that minimize the sum of the squares of the errors locally. The model has a massive number of state variables and a large number of unknown parameters whose numerical calculation is a difficult task; it is probable that an unlimited number of distinct parameter sets might be produced that all match the data equally well. On the other hand, our parameters are control tuning knobs whose settings should accurately recreate the data. The model parameters were fitted using repeated local minimization of the sum of the squares of the errors, based on a priori epidemiological and clinical knowledge of relative parameter magnitude (as stated above) and beginning from a random initial guess. The parameters were updated during the simulation based on the sequential steps taken by policymakers, each of increasing strength.
Results
Parameter estimation methods
The parameter estimation (PE) methodology is a beneficial and newly popular method for determining the nearest parameter values to the actual data while producing the curve that best matches the real data. The PE approach calculates the most realistic parameter values for the established mathematical model. The numerical values of the parameters in the majority of the studies in the literature are the estimated parameter values utilized in the preceding articles36,37,38,39,40,41,42). This strategy improves the utility of our research by calculating model-specific parameter values. The PE methodology is a highly effective way to find the best appropriate curve for the actual data while delivering parameter values as near to the true values as possible.

Time evolution for each population in Shenzhen in the SEIAPUFR model for N = 17,560,000. Each generation chooses all the sites randomly and according to their state.
Numerical simulation of SEIAPUFR model of COVID-19 in each city
The product of the number of infected and susceptible persons determines the pace of the rise in the number of infections. Understanding the SEIAPUFR model system reveals the alarming rise in infection rates worldwide. As a result of sick persons moving throughout the world, the number of infected people has increased, resulting in a rise in the vulnerable population43). This creates a positive feedback loop, causing the number of actively infected patients to increase rapidly. As a result, during a surge period, the number of vulnerable persons increases, as does the number of infected individuals.
Numerical simulation results of the SEIAPUFR model of COVID-19 in Shenzhen
The proportion of the population at each stage at any given time is determined as follows: N = 17,560,000, N∗ = 1384, E(0) = 1, A(0) = 1, P (0) = 0, U (0) = 1, I(0) = 1384, F (0) = 1, R(0) = 1369, S = N − I − R − E − A − F − U, C0 = 0, C1 = 0.95, C2 = 0.95, C3 = 0.95, η = 0.001, λ = 0.96, σ = 0.4, α = 0.6, ε = 1- µ, β = 0.25, γ = 0.3, µ = 0.8, ρ = 0.9, and k = 469,917,τ = 0.7,g = 23, which were reported by44).
We tested the model mentioned above with N = 17,560,000 and found the following time evolution for each population of the SEIAPUFR model (Fig. 2). Each population’s size is determined by the density of infected persons every day. When we look at the time evolution in Fig. 2, we can see that the differential equation models have a similar form as in45). The susceptible population decreases as the recovery population grows over time until the disease spread stops and a stationary value is reached. The exposed, infected, asymptomatic, respiratory-specific model, non-respiratory specific model, and guided sampling in infected populations grow until they reach a maximum value, then fall until they reach a null value at reducing epidemics. In this approach, our model may be used to replicate the SEIR model’s behavior. To better understand the policy resolution of these fundamental framework cases, we run various tests with different values of N.
The above settings were used to replicate the model and produce the graphs shown in Fig. 3(A-H). A comparison of the curves produced by the SEIAPUFR model is shown. The current number of infected (including all phases), recovered, and diagnostic cases are all accurately replicated. The difference between the two curves can be explained as follows:
The model takes into account infections of various severity levels (for example, P (t) is the number of respiratory diseases that must be considered when examining the pandemic’s flatten curve, and F (t) is the number of surveillance samples that must be considered when estimating the number of infectious individuals on a given day). In contrast, Fig. 2 depicts the epidemic progression predicted by the model for the COVID-19 outbreak, after day 34. In the presence of perfect test accuracy, countermeasures, and vaccine effectiveness (such as lockdowns, social distancing, hygiene recommendations, and the use of face masks), we have β ∈ {0.14, 0.2, 0.25, 0.5} and γ = 0.3, and the model predicts an evolution that leads to 220, 000; 500, 000; 700, 000; 1, 500, 000; of the individuals having been exposed by the virus, and 200, 000; 389,000; 500, 000; 810, 000 of the individuals having Asymptomatic, 600,000; 1, 200, 000; 1, 600,000; 2, 700, 000 of the population having respiratory specific because of the indoor and outdoor airborne infections,150,000; 310,000; 420,000; 680,000 of the population having non-respiratory specific, 600,000; 1,400,000; 1,800,000; 3,100,000 of the population having supervision sampling across a 120-day horizon (Fig. 3A-H) for β ∈ {0.14, 0.2, 0.25, 0.5}.

Fitted and predicted epidemic evolution. (A–H), Population dynamics of susceptible; exposed; infected; asymptomatic, respiratory specific model; non-respiratory specific model; supervised sampling in infected individuals, and healed class of the considered model using various values of β and γ.

Epidemic evolution predicted by the model for the COVID-19 outbreak, when N = 17,560,000. (A) The relationship between respiratory population and exposed population during the evolution control of the pandemic; (B,C) Shown an outbreak component, in periods two and three; (D) Time development of the density of the infected population for various values of the parameters β and γ.

Time evolution for each population in Shanghai in the SEIAPUFR model for N = 24,870,895. Each generation chooses all the sites randomly and according to their state.
and γ = 0.3, respectively. For β = 0.5, the peak of concurrently exposed, infected, asymptomatic, respiratory specific, non-respiratory specific, and supervision sampling individuals occurs around 18 days and amounts to 53.99% of the population; however, the peak of concurrently exposed, infected, asymptomatic, respiratory specific, non-respiratory specific, and supervision sampling individuals for β = 0.14 occurs later, around 62 days, and amounts to 10.93% of the population.
The difference between sub-populations of exposed individuals and respiratory-specific individuals evolves, as shown in Fig. 4A, and it’s interesting to note that respiratory-specific sub-populations increased with exposed sub-populations at different time and then started to decrease around (750000; 1600000), it means that many steps, such as the use of face masks, social distance, the deployment of an effective vaccine, different degrees of testing, and the building of herd immunity, are being taken from this point forward to flatten the transmission curve.

Fitted and predicted epidemic evolution. (A–H) Population dynamics of susceptible; exposed; infected; asymptomatic, respiratory specific model; non-respiratory specific model; supervised sampling in infected individuals and healed class of the considered model using various values of β, and γ, N = 24,870,895.

Epidemic evolution predicted by the model for the COVID-19 outbreak, when N = 24,870,895. (A) The relationship between the respiratory population and exposed population during the evolution control of the pandemic; (B,C) Shown an outbreak component in periods four and six; (D) Time development of the density of the infected population for various values of the parameters β and γ.
If respiratory sub-populations are managed early on, the transmission may be lowered over time. As a result of our model predictions, we can conclude that the respiratory-specific sub-population has a potential effect on flattening the curve during pandemic transmission, which would prevent the health care system from becoming overwhelmed because the peak number of beds occupied at any given time would be lower under a flatter curve, would slow the momentum of the outbreak, reducing the overshoot of cases after the outbreak peak, and would allow time to develop clinical care methods and capability, as well as to analyze treatments with the flawless test accuracy and improve vaccine efficacy46,47).

Time evolution for each population in Wuhan in the SEIAPUFR model for N = 12,326,518. Each generation chooses all the sites randomly and according to their state.
The numerical simulation of the outbreak factor in periods 2 and 3 is shown in Fig. 4B, C. Before the initial peak (41, 50 days) and after about 61 days, respiratory-specific control, countermeasure, and perfect test accuracy regulations can delay the development of the pandemic. In both cases(periods two and three), the higher epidemic values are focused around t = 60 days. Based on this observation, we may assume that with less control (t < 70), the infected curve has a larger peak and, after that, the spread cases for t = 80, showing that the density of infected people is higher, but the infection ends sooner, even when control measures are loosened. Furthermore, if no reasonable control measures are implemented, an exponential pandemic peak will inevitably occur over time. Based on the varied values of β and γ, we plot some curves of the number of infectious individuals during the pandemic transmission (Fig. 4D). When we apply a higher control (β < 0.03), we notice an expansion of the dark blue zone in Fig. 4D, which is between a blue region and a dark portion. This scenario exhibits various peaks separated by a portion of lower I value, describing a wave of infections45). Furthermore, the color scale in Fig. 4D reflects the amount of I.

Fitted and predicted epidemic evolution. (A–H) Population dynamics of sus- ceptible; exposed; infected; asymptomatic, respiratory specific model; non-respiratory specific model; supervised sampling in infected individuals and healed class of the considered model using various values of β, and γ, N = 12,326,518.

Epidemic evolution predicted by the model for the COVID-19 outbreak, when N = 12,326,518. (A) The relationship between the respiratory population and exposed population during the evolution control of the pandemic; (B,C) Shown an outbreak component in periods two and five; (D) Time development of the density of the infected population for various values of the parameters β and γ.
The colored zones represent combinations of β and γ for which the pandemic continues indefinitely. Meanwhile, we have scenarios like epidemic extinction in the yellow zone, despite the relaxation of control efforts and reinfection. Greater values of I correspond to higher values of β. As we can see, even at a greater γ = 0.14, the value of infection is I = 0.0. As the value of β rises, the value of disease I fall for all γ values.

Time evolution for each population in Guangzhou in the SEIAPUFR model for N = 18,676,605. In each generation, all the sites are chosen randomly and according to their state.
The black region, for lower values of β and higher values of γ, can be explained by the fact that, with control measures (lower values of γ), a greater number of people are infected at the start of the spread, but when the people become susceptible again, there are no more infected people to perpetuate the disease spread in the exposed compartment. From the above finding, we can deduce that the reduction arises solely once the amount of susceptibles diminishes, which was solely due to the stringent measures implemented by the Chinese government in Shenzhen. China implemented quarantine measures for possible patients, regulated individuals’ mobility, and limited overseas travel. Social separation was extensively observed, and the majority of individuals wearing face masks. The actual infection rates have declined more significantly than anticipated by the SIR model. The result shown in Figs. 3, and 4 indicate that the Chinese government has effectively mitigated the effects of COVID-19’s propagation in Shenzhen.
Numerical simulation results of the SEIAPUFR model of COVID-19 in Shanghai
The proportion of the population at each stage at any given time is determined as follows: N = 24,870,895, N ∗ = 59,342, E(0) = 1, A(0) = 5396, P (0) = 0, U (0) = 1, I(0) = 59,342, F (0) = 1, R(0) = 45,873, S = N − I − R − E − A − F − U, C0 = 0, C1 = 0.96, C2 = 0.96, C3 = 0.95, η = 0.001, λ = 0.97, σ = 0.4, α = 0.6, ε = 1- µ, β = 0.691, γ = 0.2, µ = 0.6, ρ = 0.8, and k = 469,917,τ = 0.7,g = 23, which were reported by44).

Fitted and predicted epidemic evolution. (A–H), Population dynamics of susceptible; exposed; infected; asymptomatic, respiratory specific model; non-respiratory specific model; supervised sampling in infected individuals and healed class of the considered model using various values of β, and γ, N = 18,676,605.

Epidemic evolution predicted by the model for the COVID-19 outbreak, when N = 18,676,605. (A) The relationship between respiratory population and exposed population during the evolution control of the pandemic; (B,C) Shown an outbreak component, in periods five and seven; (D) Time development of the density of the infected population for various values of the parameters β and γ.
From the above parameters, analyzing the time evolution presented in Fig. 5, we observe the similar results when N = 24,870,895. The susceptible population decreases as the recovery population increases over time until a stationary value achieved when the disease spread ends. The exposed, the infected, the asymptomatic, the respiratory specific model, non-respiratory specific model, and supervised sampling in infected populations increase until a maximum value and then they decrease and assume a null value in the end of the epidemics. Conversely, Fig. 5 shows the epidemic evolution that would have been predicted by the model for the COVID-19 outbreak, after 25 days.
The Fig. 6A-H shows that, with use of face marks, social-distancing countermeasures, vaccine effectiveness, and perfect test accuracy after days 5, 10, 15, 20 having a mild effect, β ∈ {0.31, 0.44, 0.56, 0.69} and γ = 0.2. Hence, the peak is delayed for each compartment and reduced in amplitude, because of vaccine effectiveness and perfect test accuracy. Over a 120-day horizon, as shown in Fig. 6C, the model predicts an evolution that leads to a peak in the number of concurrently infected individuals around days 15, 17, 19, 21, amounting to 6.07%, 6.47%, 6.79%, 7.07% of the population for β ∈ {0.31, 0.44, 0.56, 0.69} and γ = 0.2, respectively. Eventually, 15.68%, 16.88%, 18.09%, 19.29% of the population have respiratory specific with the virus because of the contagion and 10.45%, 10.85%, 11.25%, 12.06% of the population have respiratory specific for β ∈ {0.31, 0.44, 0.56, 0.69} and γ = 0.2, respectively (Fig. 6F). The fractions of patients in supervision sampling, are shown in Fig. 6G, and reach their peak on days 5, 10, 15, 20, amounting to 17.29%, 18.5%, 19.7%, 20.9% of the population for β ∈ {0.31, 0.44, 0.56, 0.69} and γ = 0.2. The adopted use of face marks, social-distancing countermeasures, vaccine effectiveness, and perfect test accuracy, although mild, have some impact and help gain more time to strengthen and supply the health care system, but is still insufficient.
The Fig. 7A shows how the different between sub-populations of exposed individuals and respiratory specific individuals evolve over time, and it is interesting to notice that the respiratory specific sub-populations increased with exposed sub-populations at a different time and started to decrease around a point (2800000; 3000000),it implies that several measures are being made from this point on to flatten the transmission curve, such as the use of face masks, social distance, the deployment of an effective vaccine, varying degrees of testing, and the establishment of herd immunity. In particular, if the respiratory sub-populations are early controlled the transmission could be reduced over the time. The Fig. 7B, C shows the numerical simulation of outbreak factor in periods 4 and 6. In periods 4 and 6, the respiratory specific control, countermeasure, and perfect test accuracy rules can slow the spread of pandemic before the first peak(39 day), and latter around 54, 59, 81 days. In both cases(periods 4 and 6), the highest values of the epidemic are concentrated around t = 38 days. Based on this observation, we may assume that with less control (t < 40), the infected curve has a larger peak and, after it, the spread cases for t = 50, 59, 81, showing that the density of infected people is higher but the infection ends sooner, even when control measures are loosened. Furthermore, if no roughly control measures are put in place, we will constantly observe an exponential pandemic peak over time. The Fig. 7D show the number of infectious individuals during the transmission of the pandemic based on the different values of β, and γ. When apply a lower control (β = 0.2), we notice an enlargement of the blue zone in Fig. 7D. This scenario exhibits various peaks separated by a portion of lower I values, which describes a scenario of a wave of infections45). Furthermore, the color scale in Fig. 7D reflects the amount of I. The colored zones represent combinations of β and γ for which the pandemic continues indefinitely.
Nevertheless, in the orange zone, we are seeing events connected to the extinction of the epidemic, despite the relaxation of control efforts and reinfection. Greater values of I correspond to higher values of β. As the value of β rises, the value of infection I falls for all γ values. The black region, for lower values of β and higher values of γ, can be explained by the fact that a greater number of people are infected at the start of the spread, but when the people become susceptible again, there aren’t enough infected people to keep the disease spreading in the exposed compartment. The steps implemented were effective, as evidenced by the decrease in the actual amount of cases aligning with the model projections. Therefore, the actions currently implemented are essential to control the outbreak and may not be relaxed. Instead, they ought to be increasingly stringent. The effectiveness of the mandated vaccine may be diminished by extensive testing and contact tracing, which would significantly aid in the swift end of this pandemic.
Numerical simulation results of the SEIAPUFR model of COVID-19 in Wuhan
The proportion of the population at each stage at any given time is determined as follows: N = 12,326,518, N ∗ = 50,423, E(0) = 1, A(0) = 0, P (0) = 1, U (0) = 0, I(0) = 50,423, F (0) = 1, R(0) = 46,551, S = N − I − R − E − A − F − U, C0 = 0, C1 = 0.96, C2 = 0.96, C3 = 0.95, η = 0.001, λ = 0.97, σ = 0.4, α = 0.6, ε = 1- µ, β = 0.2, γ = 1/7, µ = 0.6, ρ = 0.8, and k = 469,917,τ = 0.7,g = 23, which were reported by44).
From the above parameters, analyzing the time evolution presented in Fig. 8, we observe the similar results when N = 12,326,518. The susceptible population decreases as the recovery population increases over time until a stationary value achieved when the disease spread ends. The exposed, the infected, the asymptomatic, the respiratory specific model, non-respiratory specific model, and supervised sampling in infected populations increase until a maximum value and then they decrease and assume a null value in the end of the epidemics. Conversely, Fig. 8 shows the epidemic evolution that would have been predicted by the model for the COVID-19 outbreak, after 41 days. If there is a minor increase in the future population of vulnerable population no significant effects will ensue. Nonetheless, a significant epidemic of the virus can yield devastating consequences.
The Fig. 9A-H shows that, with stronger use of face masks with vaccine and perfect test accuracy, able to yield β ∈ {0.1, 0.13, 0.17, 0.2} and γ = 0.08, the peak is delayed, because the increase in the number of new infected is reduced so much that it soon becomes a decrease. Over a 120-day horizon, as shown in Fig. 9C, the model predicts an evolution of the situation that leads to a peak in the number of concurrently infected individuals around day 75, 60, 50, 40, amounting to 20.28%, 18.65%, 17.84%, 16.22% of the population for β ∈ {0.1, 0.13, 0.17, 0.2} and γ = 0.08, respectively. Eventually, 52.73%, 47.05%, 45.43%, 44.62% of the population have respiratory specific with the virus and 34.07%, 31.64%, 30.83%, 29.21% of the population have non respiratory specific for β ∈ {0.1, 0.13, 0.17, 0.2} and γ = 0.08 because of the non control of respiratory specific individuals. The fraction of patients in need of supervision sampling, as shown in Fig. 9G, reach their peaks on day 75, 60, 50, 40, amounting to 58.41%, 55.17%, 52.73%, 51.92% of the population.
The Fig. 10A shows how the different between sub-populations of exposed individuals and respiratory specific individuals evolve over time, and it is interesting to notice that the respiratory specific sub-populations increased with exposed sub-populations at a different time and started to decrease around a point (1100, 000; 2100, 000), it suggests that numerous efforts are being taken to flatten the transmission curve from this point on, such as the use of face masks, social distance, the deployment of an effective vaccine, various degrees of testing, and the development of herd immunity. In particular, if the respiratory sub- populations are early controlled the transmission could be reduced over the time. The Fig. 10B, C shows the numerical simulation of outbreak factor in periods 2 and 5. In periods 2 and 5, the respiratory specific control, countermeasure, and perfect test accuracy rules can slow the spread of pandemic before the first peak(78 day), and latter around 98 days. In both cases(periods 2 and 5), the higher outbreak values are clustered around t = 78, 98 days. Based on this observation, we may conclude that with less control (70 < t < 100), the infected curve has a bigger peak and, after it, the spread cases for t = 78, 98, showing that the density of infected people is higher but the infection ends sooner, even when control measures are loosened. Furthermore, we will always witness an exponential epidemic peak over time if no reasonable control measures are put in place. The Fig. 10D show the number of infectious individuals during the transmission of the pandemic based on the different values of β, and γ. When a greater control is given, we witness an expansion of the dark blue zone (γ > 0.1) in Fig. 10D, which is between a blue region and a dark section. Following the color scale, this scenario exhibits various peaks separated by a portion of lower I values, which indicates a scenario of a wave of infections45). Furthermore, in Fig. 10D, the color scale represents the amount of I. The colored zones represent combinations of β and γ for which the pandemic does not terminate over time. Moreover, in the orange zone, we are seeing scenarios connected to the extinction of the epidemic, despite the relaxation of control efforts and the reinfection. Greater values of I are present for higher levels of β. As we can see, even at larger γ > 0.1 values, the value of infection I = 0.0. As the value of β grows, the value of infection I falls for all values of γ. The black region, for lower values of β and higher values of γ, can be explained by the fact that, with lower control measures (lower values of γ), a greater number of individuals are infected at the start of the spread, and then, when the individuals become susceptible again, there will be no more infected individuals to perpetuate the disease spread in the exposed compartment.

The COVID-19 data was gathered from the population of Wuhan, Shanghai, Guangzhou, and Shenzhen between July 31 and August 30, 2021, and then compared to the goodness of fit curve produced by the suggested model.
Numerical simulation results of the SEIAPUFR model of COVID-19 in Guangzhou
The proportion of the population at each stage at any given time is determined as follows: N = 18,676,605, N ∗ = 894, E(0) = 1, A(0) = 4, P (0) = 1, U (0) = 0, I(0) = 894, F (0) = 1, R(0) = 732, S = N − I − R − E − A − F − U, C0 = 0, C1 = 0.96, C2 = 0.96, C3 = 0.95, η = 0.001, λ = 0.97, σ = 0.4, α = 0.6, ε = 1- µ, β = 0.35, γ = 1/7, µ = 0.6, ρ = 0.8, and k = 469,917,τ = 0.7,g = 23, which were reported by44).
From the above parameters, analyzing the time evolution presented in Fig. 11, we observe the similar results when N = 18,676,605. The susceptible population decreases as the recovery population increases over time until a stationary value achieved when the disease spread ends. The exposed, the infected, the asymptomatic, the respiratory specific model, non-respiratory specific model, and supervised sampling in infected populations increase until a maximum value and then they decrease and assume a null value in the end of the epidemics. Conversely, Fig. 11 shows the epidemic evolution that would have been predicted by the model for the COVID-19 outbreak, after 21 days. This suggests that social separation protocols and handling of cases, along with its severe socioeconomic repercussions, might have to persist for an extended duration.
The Fig. 12A-H shows that, with even stronger use of face masks with vaccine efficacy and perfect test accuracy, β ∈ {0.35, 0.44, 0.54, 0.63} and γ = 0.0071. Over a 120-day horizon, as shown in Fig. 12C, the model predicts an evolution of the situation that leads to a peak in the number of concurrently infected individuals around days 30, 26, 22, 19, amounting to 13.38%, 12.85%, 12.31%, 11.78% of the population for β ∈ {0.35, 0.44, 0.54, 0.63} and γ = 0.0071, respectively. Eventually, 29.44%, 28.91%, 28.37%, 27.84%of the population have respiratory specific with the virus and 20.88%, 20.34%, 19.81%, 19.28% of the population have non respiratory specific with the virus. The fraction of patients in need of supervision sampling, as shown in Fig. 12G, reach their peaks on days 30, 26, 22, 19, amounting to 40.15%, 39.62%, 39.08%, 37.48% of the population, result of an expanded testing initiative that detected a greater number of moderately symptomatic infected populations.

(A,B) The prevalence and incidence hazard of respiratory infectious in China form Global Burden of Disease(GBD) database in 2021 for Males and Females.
The Fig. 13A shows how the different between sub-populations of exposed individuals and respiratory specific individuals evolve over time, and it is interesting to notice that the respiratory specific sub-populations increased with exposed sub-populations at a different time and started to decrease around a point (1, 780, 000; 2, 800, 000), this suggests that, from this point on, various efforts are being taken to flatten the transmission curve, such as the use of face masks, social distance, the deployment of an effective vaccine, various degrees of testing, and the development of herd immunity. In particular, if the respiratory sub- populations are early controlled the transmission could be reduced over the time. The Fig. 13B, C shows the numerical simulation of outbreak factor in periods 5 and 7. In periods 5 and 7, the respiratory specific control, countermeasure, and perfect test accuracy rules can slow the spread of pandemic before the first peak(10 day), and latter around 115 days. In both cases(periods 5 and 7), the greater values of the epidemic are localized around t = 10, 115 days. Based on this observation, we may assume that with less control (t < 20), the infected curve has a larger peak and, after it, the spread cases for t = 10, 115, suggesting that the density of infected individuals is higher but the infection ends sooner, even when control measures are loosened. Moreover, if no reasonable control measures are put in place, an exponential viral peak will continuously occur over time.
The Fig. 13D show the number of infectious individuals during the transmission of the pandemic based on the different values of β, and γ. When a higher control is applied( β < 0.06), we see an extension of the black region, in Fig. 13D. Following the color scale, this scenario represents some peaks separated by a section of lowers values of I, which characterizes a scenario of a wave of infections45). Furthermore, in Fig. 13D, the color scale indicates the magnitude of I. The colored regions display combinations of β and γ for which the epidemic does not end over time. Meanwhile, for the yellow region, we observe situations related to the extinction of the epidemic, even with the relaxation of control measures and the reinfection. The higher values of I are present for higher values of β. As we see, even for a higher value of γ = 0.08, the value of infection I = 0.0. As the value of β increases, the value of infection I decreases for all values of γ. The black region, for lower values of β and higher values of γ can be explained by the fact that, with lower control measures (lower values of γ), a higher number of individuals are infected in the beginning of the spread, then, when the individuals become susceptible again, there are not more infected individuals to perpetuate the disease spread in the exposed compartment.
These scenarios, despite being surpassed, are critical in demonstrating that increased use of face masks in conjunction with vaccine efficacy and perfect test accuracy were an appropriate policy, given that the epidemic could still have had tragic outcomes in the absence of respiratory specific and supervision sampling individuals. They also propose that mandating stricter usage of face masks with vaccination effectiveness and flawless test accuracy as early as feasible, for nations still in the midst of an outbreak, leads to tremendous gains over a delayed intervention.
In epidemic transmission models, it is essential for the basic reproduction number, R0, to be smaller than one for effective pandemic control. Nonetheless, this criterion may not consistently enough for the backward bifurcation phenomenon, wherein a stable endemic equilibrium coexists with a stable disease-free equilibrium for R0 < 1. This phenomena has substantial public health implications, since it renders the standard criterion of the fundamental reproduction number being less than one necessary, yet insufficient for disease eradication. The accompanying bifurcation graph and the duration sequence corresponding to the force of infection G = βI/N are illustrated in the supplementary material Figure using the parameters N = 17,560,000, E(0) = 1, A(0) = 1, P (0) = 0, U (0) = 1, I(0) = 1384, F (0) = 1, R(0) = 1369, S = N − I − R − E − A − F − U, β = 0.25, γ = 0.3 for Shenzhen, N = 24,870,895, E(0) = 1, A(0) = 5396, P (0) = 0, U (0) = 1, I(0) = 59,342, F (0) = 1, R(0) = 45,873, S = N − I − R − E − A − F − U,β = 0.31, γ = 0.8 for Shanghai, N = 12,326,518, E(0) = 1, A(0) = 0, P (0) = 1, U (0) = 0, I(0) = 50,423, F (0) = 1, R(0) = 46,551, S = N − I − R − E − A − F − U,β = 0.03, γ = 1/7 for Wuhan, and Guangzhou N = 18,676,605, E(0) = 1, A(0) = 4, P (0) = 1, U (0) = 0, I(0) = 894, F (0) = 1, R(0) = 732, S = N − I − R − E − A − F − U, β = 0.1, γ = 1/7, displaying the disease-free equilibrium (DFE) and two endemic equilibria, where the greatest infectious equilibrium is stable and the smallest endemic equilibrium is unstable. The findings shown in this figure indicate that the local asymptotic stability of DEF and EE is contingent upon the starting sizes of the subpopulations, meaning that stable DEF coexists with stable EE. This work suggests that the standard epidemiological criterion of ensuring the fundamental reproduction number (R) of our model is less than one is not anymore sufficient, however it remains required, for successfully monitoring the propagation of an epidemic in a region.
Model fitting
To fit the system (1), we used real data on the cumulative number of COVID-19 cases in Wuhan, Shanghai, Guangzhou, and Shenzhen, including those who were infected, and eliminated. The data was obtained from http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml. Specifically, we selected data that was reported over a 30-day period of the pandemic, spanning from july 31 and August 30, 2021. To get the numbers for η = 6.477e + 3, we utilized the current life expectancy in China (77.3 years). And assume that, N ∗ = 894, E(0) = 1, A(0) = 4, P (0) = 1, U (0) = 0, I(0) = 26, F (0) = 1, R(0) = 1, S = N − I − R − E − A − F − U, C0 = 0, C1 = 0.96, C2 = 0.96, C3 = 0.95, λ = 0.97, σ = 1/5.148), α = 0.599548), ε = 1- µ, β = 0.35(fitted), γ = 1/739), µ = 0.6(fitted), ρ = 0.2169(fitted), and k = 469,917,τ = 0.8,g = 23, which were reported by44).
By using a least squares methodology, we successfully fit the model to the data and determine the parameters. Figure 14 displays empirical data on the number of infected patients, along with the fitting of a model to the number of infected symptomatic cases. It is evident from this illustration that the model accurately represents the data on the quantity of symptomatic instances of infection. All persons who are infected with COVID-19, whether they show symptoms or not, as well as those who are suspected of having the virus, are being admitted to hospitals in Wuhan, Shanghai, Guangzhou, and Shenzhen. Moreover, from Fig. 15, we observed that the prevalence of Males and Females was 0.019(0.017–0.022), and 0.019(0.017–0.021), why the incidence hazard of Males and Females was 1.39(1.23–1.58), and 1.43(1.26–1.63), respectively. The incidence hazard for respiratory infectious of Females was higher than incidence hazard for respiratory infectious of Males. Authorities can diminish the total amount of susceptible persons by suitable measures, and when accompanied by the isolation of infected people, this will lower the highest rate of transmissions. Upon completion, this effectively reduces the duration of the virus’s effects on population. Consequently, the second assertion lacks scientific foundation and is erroneous. It is crucial to diminish the highest level of disease, as this will minimize the time of necessary harsh measures(develop efficient vaccine ), contrary to the assertions made by the press and authorities that it would prolong the duration.
Model performance
The COVID-19 predictive validity of the models reported here was tested utilizing different population sizes. Our SEIAPUFR model has consistently delivered some of the most accurate projections when compared to other models49). For a clear evaluation of our model performance, we have added additional sets of model and supervision samples. Moreover, the difference between our model and the traditional one is that our system can help clinicians to get the result of the nucleic acid testing based on the supervised sampling in a few minutes, while the traditional method uses the whole population for the nucleic acid testing on respiratory samples, which needs more time, and energies. We stress that these are projections of possible futures that are susceptible to a variety of model assumptions and data variability. Conducting an inadequate number of testing underestimates the probability of transmission and hinders the development of an effective vaccine; our mathematical framework can forecast the long-term consequences of misdiagnosis.
Discussion and conclusion
SARS-CoV-2 has been difficult to control since the start of the pandemic, and the spread of multiple variants has only exacerbated this challenge, and many mathematics models have been developed to predict the transmission of COVID-1950,51,52. It has been used that control programs are developed to interrupt the chains of transmission within communities by scaling up testing, contact tracing, and isolation since the early days, but heavy losses have also been paid, both politically and economically53,54,55. Since SARS-CoV-2 can spread from people who are pre-symptomatic, symptomatic, or essentially asymptomatic, diagnosis and isolation based on symptoms alone will not be enough to stop the virus from spreading56,57. This group of persons is likely to become populationwide covert transmitters. The estimations of SARS-CoV-2 transmissibility, which mainly rely on observed counts of cumulative infections, might be influenced by restricted and biased testing58. These tests are time-consuming and cannot be performed on all of the population, and substantial false negative rates have also been reported59. As a result, using effective targeted control strategies to detect infected individuals might be one way to flatten transmission curves and enable the resumption of social activities and economic recovery. In this study, we combined a vaccine method, a perfect test accuracy, a respiratory specific model, and disease supervision sampling into a single host population for disease control to mirror those findings from studies of historical pandemic. The parameter estimation methodology was well used for determining the nearest parameter values to the actual data while producing the curve that best matches the real data60. The novel SEIAPUFR model also replicated accurately and extended the classic SEI(A)R propagation model, while simulating the significance of supervision sampling in control of respiratory communicable disease at different stages. These findings indicate that reasonable control measures can lower the transmission rate β to slow spread of SARS-CoV-2, resulting in a reduction in the number of people exposed and infected. If reasonable and effective interventions are adopted to suppress respiratory transmission during the early stage of the pandemic, it can flatten the transmission curve-that is, to extend the period over which cases occurred, which will slow the momentum of the outbreak to reduce medical pressure. In contrast, loosened containment can accelerate the spread, so that an exponential pandemic peak will inevitably occur over time. The number of infected people increases with an increasing β, so as the required proportion of supervision sampling. Whereas the removal rate γ tends to correlate with different levels of medical care and disease severity in the area, including non-life-threatening cases (asymptomatic and paucisymptomatic; minor and moderate infection) and potentially life-threatening cases (major and extreme infection) that require intensive care units (ICUs). Classic SEI(A)R model can be used to forecast or simulate future transmission scenarios under various assumptions about parameters governing transmission, disease, and immunity, while long-term simulation cannot be done with constant parameters61. This is due to the fact that the transmission rate β and the removed rate γ must be modified over time based on the adoption of control measures62. The original versions of the controversial model from the Institute for Health Metrics and Evaluation (IHME) fell into this category. The disease-specific parameters driving model can be modified to test how the pandemic may change under various assumptions about the disease and implementation of control measures. In our study, we assume that the β value will be different in different scenarios based on the implementation of control measures (such as lockdown, social distancing, hygiene advice and use of masks) and vaccine effectiveness. The model predicts an evolution that is concurrently the peaks of population (including exposed, asymptomatic, respiratory specific, non-respiratory specific, supervision sampling) occur earlier, faster, and higher as the β value increases. Such excessively rapid peaks can easily overburden the healthcare system and compress the time to improve clinical care strategies and capacity. This phenomenon may explain why the Chinese government was so aggressive in taking control measures early in the pandemic63. Absolutely, these containment measures are very useful, mainly in that the exposure sub-populations increase with the respiratory-specific sub-populations early in the pandemic, and then start to decrease after a certain inflection point. It means that control measures during the pandemic have interrupted the chain of transmission-mainly by reducing respiratory spread, reflected in sharply reduced exposures owing to fewer respiratory-specific populations, which is forward to flatten the transmission curve. Hence, we firmly believe it is logical to distinguish between respiratory and non-respiratory transmission based on the disease characteristics of COVID-19, just like other modified SEI(A)R models such as SEIRS, SVEIR and SEPIAR to more accurately describe transmission for different modeling purposes. Identification of people in the community who are infected is an integral element of outbreak management. Some countries monitor COVID-19 fluctuations with surveys of virus prevalence in the wider population, but these have mostly been one-off activities due to high costs. Therefore, real-time supervision sampling survey based on population samples is a crucial component of effective targeted control strategies. Whether in targeted capture of real-time viral spread, or horizontal and longitudinal designs for prevalence and relapse tracking, this supervision sampling has significant advantages as SARS-CoV-2 persists. The Real-time Assessment of Community Transmission-1 (REACT-1) study64, a representative community-wide sampling survey that is tracking prevalence of SARS-CoV-2 across England through repeated random population-based sampling. Other studies such as Zambia’s cluster sample survey for estimated numbers of SARS-CoV-2 infections65, and the Office for National Statistics (ONS) Coronavirus Infection Survey66, through repeated cross-sectional household surveys with additional serial sampling and longitudinal follow-up, presented the spread trends of COVID-19 in England. The concepts of supervision sampling are well used in these studies to track virus and estimate prevalence. However, these surveys are also unilateral and imperfect to a certain extent. On the one hand, most sample surveys are tended to maximize randomness and representativeness to objectively reflect the pandemic characteristics. In fact, there are still many circumstances where we need targeted routine asymptomatic testing for high-risk groups and areas to prevent outbreaks in at-risk settings. On the other hand, as the survey progresses, the sampling proportions should be different among communities due to adoption of control measures. Even the targeted proportions should also be different due to differences in transmission capacity, according to the contemporaneous numbers of asymptomatic, respiratory symptoms, and non-respiratory symptoms. This program is designed to reflect the objective regulation of the pandemic from multiple levels by combining multiple groups of people in the same period. We adjust the proportion of supervision sampling based on the number of susceptible and exposed individuals, as well as differences in transmission rate. It is not difficult for us to find that the tendency in propagation curve of supervision sampling is close to respiratory specific model. This may be explained that respiratory infection is the main way of COVID-19 spread, which hence determines the number of exposed people to a certain extent. While the proportion of peak sampling is proportional to the β value, and both decrease with the adoption of control measures. This means that sampling in low-prevalence areas should be appropriately reduced, where supervision sampling should be only aimed at preventing a resurgence of SARS-CoV-2 transmission. In a rapidly evolving epidemic, during which ongoing targeted surveillance is essential to guide public health response67. Regarding diagnostic tests for COVID-19, current conventional molecular techniques for detecting SARS-CoV-2 in respiratory samples utilize non-specific real-time polymerase chain reaction with reverse transcription strategies, targeting RNA-dependent RNA polymerase and E genes. The tests were labor-intensive and are unable to be administered to all vulnerable persons within the community; elevated rates of false negatives have been identified, and accredited institutions equipped with costly apparatus are required. There is an urgent need for quick tests exhibiting high sensitivity and specificity that may be readily implemented in real-world environments such as hospitals, schools, airports, and train stations. Certain laboratories are advancing towards the development of a 15-minute test for the simultaneous detection of SARS-CoV-2 immunoglobulins IgM and IgG in human blood. In contrast, surveillance sampling control of this respiratory infectious disease may have prospective value relative to routine surveillance, especially virus testing in the wider population. For one thing, this program could more accurately describe the natural laws of COVID-19, and data from supervision sampling or similar surveys could be used to target local public health or vaccination campaigns, which would facilitate policy response and timely implementation of public health interventions68. For another, the information from community-based surveillance can be used to calibrate and merge other data streams, not only symptomatic testing but also the use of mobility data and sewage-based sampling of viral RNA69. Additionally, regardless of low-prevalence or disease control, the targeted sampling can help to provide early warning of any upturn in infections. With the persistence of SARS-CoV-2, this targeted surveillance will hopefully become the main policy to contain respiratory infectious diseases in the future. Nonetheless, this junior mathematical model had several limitations. First, although the typical cities for the COVID-19 outbreak are the four districts selected for the simulation, the generalisability of the findings to all districts of China is unknown. Second, it is not clear whether such transmission simulations based on urban populations are applicable to rural areas due to large differences in population density and medical care. Third, the number of individuals selected for the model simulation stems from the national government work report, including the total population, the infected, the removed, vaccination coverage, etc. These values may deviate from the actual results to a certain extent, although we have tried our best to avoid. Finally, we did not take into account the effects of specific conditions, such as containment measures adjustment, variant emergence, increased social mixing, and population migration, which may be seriously addressed in our future.
In conclusion, we employ a least squares method to enhance our comprehension of contact-based virus transmission. The framework of independent variables as infected carriers in two dimensions is comprehensible and demonstrates potential for enhancing the comprehension of infectious illness epidemics. It is easier to access than different designs and can capture random interactions overlooked by traditional methods. The simulations demonstrate a reasonably good prediction of infection paths, including primary as well as secondary waves, for COVID-19 information collected from four nations with significantly varied characteristics.
Data availability
The datasets generated and/or analysed during the current study are available in the http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml, https://www.geodata.cn/sari2020/web/index.html, and VizHub - GBD Results (healthdata.org).
References
Andersen, K. G., Rambaut, A., Lipkin, W. I., Holmes, E. C. & Garry, R. F. The proximal origin of SARS-CoV-2. Nat. Med. 26, 450–452 (2020).
Mari, L. et al. The epidemicity index of recurrent SARS-CoV-2 infections. Nat. Commun. 12, 2752 (2021).
Peeling, R. W., Heymann, D. L., Teo, Y-Y. & Garcia, P. J. Diagnostics for COVID-19: moving from pandemic response to control. Lancet 399, 757–768 (2022).
Pan, X. et al. A digital mask-voiceprint system for postpandemic surveillance and tracing based on the STRONG strategy. J. Med. Internet Res. 25, e44795 (2023).
Kraemer, M. U. G. et al. Monitoring key epidemiological parameters of SARS-CoV-2 transmission. Nat. Med. 27, 1854–1855 (2021).
Jewell, N. P., Lewnard, J. A. & Jewell, B. L. Caution warranted: using the institute for health metrics and evaluation model for predicting the course of the COVID-19 pandemic. Ann. Intern. Med. 173, 226–227 (2020).
Holmdahl, I. & Buckee, C. Wrong but useful — what Covid-19 epidemiologic models can and cannot tell us. N. Engl. J. Med. 383, 303–305 (2020).
Chen, Y., Liu, F., Yu, Q. & Li, T. Review of fractional epidemic models. Appl. Math. Model. 97, 281–307 (2021).
Ferraguti, M., Dimas Martins, A. & Artzy-Randrup, Y. Quantifying the invasion risk of West Nile virus: insights from a multi-vector and multi-host SEIR model. One Health. 17, 100638 (2023).
Cori, A., Boëlle, P-Y., Thomas, G., Leung, G. M. & Valleron, A-J. Temporal variability and social heterogeneity in disease transmission: the case of SARS in Hong Kong. PLoS Comput. Biol. 5, e1000471 (2009).
Wang, W., Tang, M., Eugene Stanley, H. & Braunstein, L. A. Unification of theoretical approaches for epidemic spreading on complex networks. Rep. Prog Phys. 80, 036603 (2017).
Campillo-Funollet, E. et al. Predicting and forecasting the impact of local outbreaks of COVID-19: use of SEIR-D quantitative epidemiological modelling for healthcare demand and capacity. Int. J. Epidemiol. 50, 1103–11013 (2021).
Rudnick, S. N. & Milton, D. K. Risk of indoor airborne infection transmission estimated from carbon dioxide concentration. Indoor Air. 13, 237–245 (2003).
Rothman, K. J., Greenland, S. & Lash, T. L. Modern epidemiology: Third edition. (2008).
Rasmussen, A. L. & Popescu, S. V. SARS-CoV-2 transmission without symptoms. Science 371, 1206–1207 (2021).
Cevik, M. et al. SARS-CoV-2, SARS-CoV, and MERS-CoV viral load dynamics, duration of viral shedding, and infectiousness: a systematic review and meta-analysis. Lancet Microbe. 2, e13–22 (2021).
Spychalski, P., Błażyńska-Spychalska, A. & Kobiela, J. Estimating case fatality rates of COVID-19. Lancet Infect. Dis. 20, 774–775 (2020).
Qiu, H. et al. Clinical and epidemiological features of 36 children with coronavirus disease 2019 (COVID-19) in Zhejiang, China: an observational cohort study. Lancet Infect. Dis. 20, 689–696 (2020).
Zou, L. et al. SARS-CoV-2 viral load in upper respiratory specimens of infected patients. N Engl. J. Med. 382, 1177–1179 (2020).
Gupta, A. et al. Extrapulmonary manifestations of COVID-19. Nat. Med. 26, 1017–1032 (2020).
Carfì, A., Bernabei, R., Landi, F., Gemelli Against & COVID-19 Post-Acute Care Study Group. Persistent symptoms in patients after acute COVID-19. JAMA 324, 603–605 (2020).
Sungnak, W. et al. SARS-CoV-2 entry factors are highly expressed in nasal epithelial cells together with innate immune genes. Nat. Med. 26, 681–687 (2020).
Ahmed, H. et al. Long-term clinical outcomes in survivors of severe acute respiratory syndrome and Middle East respiratory syndrome coronavirus outbreaks after hospitalisation or ICU admission: a systematic review and meta-analysis. J. Rehabil Med. 52, jrm00063 (2020).
Lu, X. et al. SARS-CoV-2 infection in children. N Engl. J. Med. 382, 1663–1665 (2020).
Lin, Q. et al. A conceptual model for the coronavirus disease 2019 (COVID-19) outbreak in Wuhan, China with individual reaction and governmental action. Int. J. Infect. Dis. 93, 211–216 (2020).
Anastassopoulou, C., Russo, L., Tsakris, A. & Siettos, C. Data-based analysis, modelling and forecasting of the COVID-19 outbreak. PLoS One. 15, e0230405 (2020).
Wu, J. T. et al. Estimating clinical severity of COVID-19 from the transmission dynamics in Wuhan, China. Nat. Med. 26, 506–510 (2020).
Ji, L-N. et al. Clinical features of pediatric patients with COVID-19: a report of two family cluster cases. World J. Pediatr. 16, 267–270 (2020).
Qian, G. et al. COVID-19 transmission within a family cluster by presymptomatic carriers in China. Clin. Infect. Dis. 71, 861–862 (2020).
Fineberg, H. V. Ten weeks to crush the curve. N Engl. J. Med. 382, e37 (2020).
Pung, R. et al. Investigation of three clusters of COVID-19 in Singapore: implications for surveillance and response measures. Lancet 395, 1039–1046 (2020).
Rothe, C. et al. Transmission of 2019-nCoV infection from an asymptomatic contact in Germany. N Engl. J. Med. 382, 970–971 (2020).
Nishiura, H., Linton, N. M. & Akhmetzhanov, A. R. Serial interval of novel coronavirus (COVID-19) infections. Int. J. Infect. Dis. 93, 284–286 (2020).
Busenberg, S., Cooke, K. & Thieme, H. Demographic change and persistence of HIV/AIDS in a heterogeneous population. SIAM J. Appl. Math. 51, 1030–1052 (1991).
LaSalle, J. P. The Stability of Dynamical Systems. Third Printing (Soc. for Industrial and Applied Mathematics, 2002).
Capistrán, M. A., Moreles, M. A. & Lara, B. Parameter estimation of some epidemic models. The case of recurrent epidemics caused by respiratory syncytial virus. Bull. Math. Biol. 71, 1890–1901 (2009).
Godio, A., Pace, F. & Vergnano, A. SEIR modeling of the Italian epidemic of SARS-CoV-2 using computational Swarm Intelligence. IJERPH 17, 3535 (2020).
Pan, J. et al. Risk assessment and evaluation of China’s policy to prevent COVID-19 cases imported by plane. PLoS Negl. Trop. Dis. 14, e0008908 (2020).
Read, J. M., Bridgen, J. R. E., Cummings, D. A. T., Ho, A. & Jewell, C. P. Novel coronavirus 2019-nCoV (COVID-19): early estimation of epidemiological parameters and epidemic size estimates. Philos. Trans. R Soc. Lond. B Biol. Sci. 376(1829), 20200265 (2021).
Liu, Z. et al. Modeling the trend of coronavirus disease 2019 and restoration of operational capability of metropolitan medical service in China: a machine learning and mathematical model-based analysis. Glob Health Res. Policy. 5, 20 (2020).
Huo, X., Chen, J. & Ruan, S. Estimating asymptomatic, undetected and total cases for the COVID-19 outbreak in Wuhan: a mathematical modeling study. BMC Infect. Dis. 21, 476 (2021).
Wang, L. et al. Modelling and assessing the effects of medical resources on transmission of novel coronavirus (COVID-19) in Wuhan, China. MBE 17, 2936–2949 (2020).
Chinazzi, M. et al. The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak. Science 368, 395–400 (2020).
Asgari, S. & Pousaz, L. A. Human genetic variants identified that affect COVID susceptibility and severity. Nature 600, 390–391 (2021).
de Souza, S. L. T., Batista, A. M., Caldas, I. L., Iarosz, K. C. & Szezech, J. D. Dynamics of epidemics: impact of easing restrictions and control of infection spread. Chaos Solitons Fractals. 142, 110431 (2021).
Cobey, S. Modeling infectious disease dynamics. Science 368, 713–714 (2020).
Koelle, K., Martin, M. A., Antia, R., Lopman, B. & Dean, N. E. The changing epidemiology of SARS-CoV-2. Science 375, 1116–1121 (2022).
Castañeda, A. R. S. et al. Modified SEIR epidemic model including asymptomatic and hospitalized cases with correct demographic evolution. Appl. Math. Comput. 456, 128122 (2023).
Friedman, J. et al. Predictive performance of international COVID-19 mortality forecasting models. Nat. Commun. 12, 2609 (2021).
Thirthar, A. A., Abboubakar, H., Alaoui, A. L. & Nisar, K. S. Dynamical behavior of a fractional-order epidemic model for investigating two fear effect functions. Results Control Optim. 16, 100474 (2024).
Ding, X., Lu, J. & Chen, X. Lyapunov-based stability of time-triggered impulsive logical dynamic networks. Nonlinear Anal. Hybrid. Syst. 51, 101417 (2024).
Adnan Thirthar, A. Stability and bifurcation of an SIS epidemic model with saturated incidence rate and treatment function. Iran. J. Math. Sci. Inf. 15(2), 129–146 (2020).
Kickbusch, I. & Liu, A. Global health diplomacy—reconstructing power and governance. Lancet 399(10341), 2156–2166 (2022).
Pei, S., Yamana, T. K., Kandula, S., Galanti, M. & Shaman, J. Burden and characteristics of covid-19 in the United States during 2020. Nature 598(7880), 338–341 (2021).
Kucharski, A. J. et al. Effectiveness of isolation, testing, con- tact tracing, and physical distancing on reducing transmission of sars-cov-2 in different settings: a mathematical modelling study. Lancet. Infect. Dis. 20(10), 1151–1160 (2020).
Arons, M. M. et al. Presymptomatic sars-cov-2 infections and transmission in a skilled nursing facility. N. Engl. J. Med. 382(22), 2081–2090 (2020).
Moghadas, S. M. et al. The implications of silent transmission for the control of covid-19 outbreaks. Proc. Natl. Acad. Sci. 117(30), 17513–17515 (2020).
Barber, R. M. et al. Estimating global, regional, and national daily and cumulative infections with SARS-CoV-2 through Nov 14, 2021: a statistical analysis. Lancet 399(10344), 2351–2380 (2022).
Kucirka, L. M., Lauer, S. A., Laeyendecker, O., Boon, D. & Lessler, J. Variation in false- negative rate of reverse transcriptase polymerase chain reaction–based sars-cov-2 tests by time since exposure. Ann. Intern. Med. 173(4), 262–267 (2020).
Aguiar, M. et al. Mathematical models for dengue fever epidemiology: a 10-year systematic review. Phys. Life Rev. 40, 65–92 (2022).
Kraemer, M. U. et al. Monitoring key epidemiological parameters of sars-cov-2 transmission. Nat. Med. 27(11), 1854–1855 (2021).
Jewell, N. P., Lewnard, J. A. & Jewell, B. L. Caution warranted: using the Institute for Health Metrics and evaluation model for predicting the course of the COVID-19 pandemic. Ann. Intern. Med. 173(3), 226–227 (2020).
Maier, B. F. & Brockmann, D. Effective containment explains subexponential growth in recent confirmed COVID-19 cases in China. Science 368(6492), 742–746 (2020).
Elliott, J. et al. Predictive symptoms for COVID-19 in the community: REACT-1 study of over 1 million people. PLoS Med. 18(9), e1003777 (2021).
Mulenga, L. B. et al. Prevalence of SARS-CoV-2 in six districts in Zambia in July, 2020: a cross-sectional cluster sample survey. The Lancet Global Health. 9(6), e773-e781 (2021).
Pouwels, K. B. et al. Community prevalence of sars-cov-2 in England from April to November, 2020: results from the ons coronavirus infection survey. Lancet Public. Health. 6(1), e30–e38 (2021).
Chang, S. et al. Mobility network models of covid-19 explain inequities and inform reopening. Nature 589(7840), 82–87 (2021).
Peeling, R. W., Heymann, D. L., Teo, Y. Y. & Garcia, P. J. Diagnostics for COVID-19: moving from pandemic response to control. Lancet 399(10326), 757–768 (2022).
Vogels, C. B. et al. Analytical sensitivity and efficiency comparisons of sars-cov-2 rt–qpcr primer–probe sets. Nat. Microbiol. 5(10), 1299–1305 (2020).
Acknowledgements
This work was supported by Natural Science Foundation of Hunan Province, China under Grants 2022JJ30673. Degree & Postgraduate Education Reform Project of Central South University. [No.2022JGB008]. The Key Research and Development Program of Hunan Province [No.2019SK2022]. The Hunan Health and Family Planning Commission Project [No.20200063].Emergency Special Project of Central South University [No. 160260007], A visual active tracking precision epidemic prevention safety net for Anti-coronavirus with artificial intelligence support. Research Programme of Advanced Interdisciplinary Studies (Grant No. 2023QYJC028). Top Ten Research Programme Disruptive Technology of Hunan Province, China(Grant No. 2022GK3003), the Key Research and Development Program of Hunan Provincial Science and Technology Department, China(Grants 2023DK2003). The Xiang Science and Education Projects [2018]234 (201835), Research on the application of digital intelligent medicine in safe transportation. The National Natural Science Foundation of China (under Grants 61375063, 61271355, 11301549 and 11271378) and also funded by the Graduate Student Innovation Foundation of Central South University (2019zzts213).
Disclaimer
The concepts and information presented in this paper are based on research and are not commercially available.
Author information
Authors and Affiliations
Contributions
XP drafted the paper. AHH and HM completed the mathematical simulations and revised the manuscript. LX and XC proposed this hypothesis and revised the manuscript. YZ, CC, JW, and AMV provided perspectives on the model and revised the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hounye, A.H., Pan, X., Zhao, Y. et al. Significance of supervision sampling in control of communicable respiratory disease simulated by a new model during different stages of the disease. Sci Rep 15, 3787 (2025). https://doi.org/10.1038/s41598-025-86739-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-86739-9
