
Abstract
Flow shop scheduling has garnered significant attention from researchers over the past ten years, establishing itself as a prominent area of study within the field of scheduling. Nevertheless, there exists a paucity of research dedicated to addressing Non-Permutation Flow Shop Scheduling Problems. In this study, a Hybrid Evolution Strategies (HES) is suggested by combining the exploitation ability of Nawaz, Enscore, and Ham (NEH) Heuristic, the exploration ability of Improved Evolution Strategies (IES), and a Local Search Technique to minimize the makespan of NPFSSP. The primary solution is produced through the NEH Heuristic, serving as a foundational solution for the IES. The IES is applied in two stages, in the first stage it improves the permutation sequence found from the NEH heuristic. In the second stage of the IES, the permutation sequence on the first 40% of machines is fixed as found in the first stage. The sequence on the last 60% of machines is altered only so that the makespan is minimized and a good non-permutation sequence is found. Recombination and mutation are the main genetic operators in IES. For recombination in IES, 16 offspring are generated randomly from a single parent. The Quad swap mutation operator is employed in the IES to optimize the utilization of the solution space while minimizing computational time. To prevent trapping in local minima, a Local Search Technique is integrated into the IES algorithm, which guides solutions to less explored areas. Computational analyses indicate that HES exhibits superior performance regarding solution quality, computational efficiency, and robustness.
Similar content being viewed by others
Introduction
In today’s competitive business environment, precise scheduling is the best tool for survival, success, and growth. Scheduling is the optimal allocation of resources. In a manufacturing environment, when all machines have the same processing sequence and a job has to be processed once on each machine it is termed as flow shop. Although flow shop has many applications i.e. manufacturing industry, process industry, automobile industry, pharmaceutical industry, glass industry, and steel industry, few practical techniques are proposed for its practical implementation. Flow Shop Scheduling Problems (FSSP) with more than two machines are NP-hard problems1. In the context of Flow Shop Scheduling Problems (FSSP), a job consists of “m” operations, each executed on a distinct machine. The sequence of jobs on each machine is optimized to achieve the desired objective function. The major types of FSSP are Permutation Flow Shop Scheduling Problems (PFSSP), Non-Permutation Flow Shop Scheduling Problems (NPFSSP), No-Wait Flow Shop Scheduling Problems (NWFSSP), Blocking Flow Shop Scheduling Problems (BFSSP), Hybrid Flow Shop Scheduling Problems, among others.
In the context of PFSSP, every machine follows an identical processing sequence, allowing any job to be executed on any of the available machines. Conversely, in NPFSSP, while all machines maintain the same processing sequence, the order of jobs assigned to each machine varies. Researchers in the last decade have mostly focused on PFSSP, however, in common industrial systems, we have NPFSSP. Ample research is carried out on PFSSP, while research on the optimization of NPFSSP is very little and is still underdeveloped in the literature. The quality of results for NPFSSP is not very good as small instances are solved while the solution for large instances is still unsolved. The reason is not practical applications of the problems but rather simple permutation schedules of PFSSP. NPFSSP finds extensive applications within computer-integrated manufacturing, the chemical sector, and flexible manufacturing systems; nonetheless, there exists a limited number of solution methodologies for its practical implementation.
Research work on NPFSSP is limited as compared to the largely solved PFSSP, where the main reason is the hardness of NPFSSP. In PFSSP, an optimal solution is searched from (n! ) feasible solutions, where “n” is the number of jobs. In NPFSSP the optimal solution is searched from (n! )m feasible solutions, where “m” is the number of machines. Hence, the search space for NPFSSP is much larger as compared to PFSSP. The solution obtained from NPFSSP should be equal to or better than the solution found using PFSSP. However, with the rise of powerful computers, interest in solving NFPSSP has increased and is currently a favored research area in flow shop scheduling literature. The set of solutions for the PFSSP constitutes a subset of the solutions for the NPFSSP2. The term “completion time” denotes the finishing time of the final job on the last machine, which is also referred to as makespan; this metric is the primary objective examined in the optimization of PFSSP3.
The most common objective for NFPSSP is the minimization of makespan2. Other objectives frequently studied in NPFSSP are: minimizing weighted mean tardiness4, minimizing total tardiness5, minimizing weighted mean completion time4, and total flow time6, among others. In this paper, a HES algorithm is proposed for the minimization of makespan for NPFSSP and is tested on Demirkol, et al.7 benchmark problems. The initial solution is produced through the NEH heuristic, followed by the application of an IES algorithm to enhance the solution further. To avoid the risk of becoming ensnared in a local minimum and to investigate superior solution regions, a Local search technique is integrated into the IES algorithm. To save computational time and explore more solution space, the Quad swap mutation operator is used in IES. To avoid cyclic repetition of the same chromosome, a frequency table is used and each chromosome can be mutated a maximum of 50 times.
In “Literature Review” Section 2, a comprehensive literature review is presented, offering an analysis of the NEH heuristic and the ES algorithm. “Problem Statement” Section succinctly outlines the problem statement along with its associated constraints, whereas “Methodology” Section provides a detailed discussion of the methodology employed. “Computational Results” Section focuses on the presentation of computational results. Lastly, "Conclusion and Recommendations" Section concludes with a discussion of findings and recommendations.
Literature review
Garey, et al.8 studied the complexities of FSSP and classified them as NP-complete problems for more than two machines. Hence solving them through exact methods is infeasible as they take ample computational time. Solution techniques for FSSP can be categorized as exact and heuristic methods. Exact methods can solve small-sized problems however they are not adequate to solve medium and large-size problems, moreover, they require ample computational time. Hence heuristic approaches are suitable to solve complex problems. The heuristic approach can be further categorized as Constructive heuristics and Meta-heuristics9. Constructive heuristics10,11) are good at finding feasible solutions however for large-size problems it is inferior to the optimal solution. In addition, the constructive heuristic cannot be applied to general cases as they are problem-specific. Meta-heuristics find a near-optimal solution with significant experimental time and are recommended for combinatorial optimization problems. Hence, researchers have used various Meta-heuristics i.e. Genetic Algorithm (GA), Tabu Search (TS), Evolution Strategies (ES), Simulated Annealing (SA), Evolutionary Programming (EP), Ant Colony Optimization (ACO), and Swarm Intelligence, among others, to solve complex problems.
Rossit, et al.2 carried out a comprehensive survey of various techniques used to solve NPFSSP with various objective functions. He analyzed 72 papers on NPFSSP with a period spread from 1988 to 2016. He showed that more than 65% of papers on NPFSSP were written after 2007, which shows that it is one of the focused researched topics in flow shop problems right now. He also summarized various techniques used to solve NPFSSP and showed that the percentage contribution of Exact, Constructive heuristics, and Meta-heuristics in solving NPFSSP are 22%, 28%, and 44% respectively. Hence, it is clear that Meta-heuristics are mostly used to solve NPFSSP as they provide better results, and can solve all size problems. The author showed that schedules for NPFSSP yield a better solution than PFSSP as the former includes all the solutions of PFSSP; however, more computational time is required to solve NPFSSP. Recent studies in Meta Heuristics indicate that there are occasions when the algorithm becomes ensnared in local minima, making it exceedingly challenging for the algorithm to escape from these local minima. Recently ample research has been performed on Hybrid Meta-heuristics in which different methods are combined to take advantage of each method. The optimal Hybrid Meta-heuristic will integrate the exploration and exploitation capabilities of diverse methodologies to yield the most effective outcomes.
The most prevalent objective function employed in addressing the FSSP is the minimization of makespan. Most of the researchers use makespan as a single objective function2. Janiak12 was the first researcher to minimize the makespan of NPFSSP; his algorithm was based on the Branch and Bound (B&B) Method and Disjunctive Graph Theory. A detailed performance evaluation of FSSP was carried out by Liao, et al.13 for Permutation vs. Non-Permutation schedules. The initial solution was found using three heuristics and was improved using the TS algorithm. Based on completion time-based criteria, the Permutation Schedules (PS) can be improved using Non-Permutation Schedules (NPS), however, the percentage improvement is rather small. While using the Tardiness and Weighted tardiness criteria, the percentage improvement is more specifically for more than 30 jobs. The experimental findings indicated that NPS outperformed PS in terms of performance. Haq, et al.14 proposed a Scatter Search (SS) approach for NPFSSP and tested its technique on Demirkol benchmark problems. The algorithm had a unifying principle that avoids repetition of the solution by using the adaptive memory principle.
For NPFSSP, Ying and Lin15 suggested a Multi Heuristic Desirability Ant Colony System. With makespan as the objective, the algorithm was tested on Demirkol instances. Lin and Ying9 proposed a Hybrid approach for NPFSSP to minimize makespan using SA and TS algorithms. The author found new upper bounds for 40 instances of Demirkol. A Hybrid Novel Quantum Differential Evolution Algorithm (QDEA) was suggested by Zheng and Yamashiro16 for NPFSSP, the Hybrid algorithm combined Local search, Differential operations, and Q-bit search. Ying17 proposed an Iterated greedy (IG) algorithm for NPFSSP and validated his results on Demirkol benchmark problems. Rossi and Lanzetta18 suggested a Native Non-Permutation algorithm using the ACO algorithm for NPFSSP. To build a native solution he used a digraph approach and validated his technique on Demirkol benchmark problems. Ziaee and Karimi19 developed a Mixed Integer Programming (MIP) model to minimize the Total Tardiness (TT) of NPFSSP. Preemption-dependent processing times and job due dates are used to minimize the TT. The algorithm underwent evaluation using instances that were generated at random.
For non-availability intervals in NPFSSP, a Hybrid Incremental Genetic algorithm (HIGA) was proposed by Cui, et al.20. The author investigated two types of intervals, in which the former intervals are fixed and known in advance while later intervals are flexible and cannot exceed a threshold time. For large-size problems, the Hybrid algorithm combines an incremental GA algorithm, a population diversity supervision scheme, and a local refinement scheme. With makespan as the objective, Ye, et al.21 solved NPFSSP having time lag constraints. The preliminary solution was developed through the application of a PFSSP heuristic, followed by the utilization of an IG algorithm to pinpoint high-quality non-permutation schedules. Benavides and Ritt22 suggested two heuristics for NPFSSP minimizing their makespan, the two heuristics used were Constructive and an Iterated Local Search (ILS) heuristic. By utilizing a few local inversions in both the heuristics, permutation structure is observed in optimal non-permutation schedules. Using unavailability constraints, Assia, et al.23 Minimized Total Energy Consumption (TEC) of NPFSSP, investigated two unavailability constraints using Mixed Binary Integer Programming (MBIP) model.
Benavides and Ritt24 employed Taillard’s acceleration technique to develop three heuristics for NPFSSP. IG algorithm combined the three heuristics i.e. a Constructive heuristic, a Non-Permutation Insertion Local Search, and a Reduced Neighborhood Best Improvement Local Search to minimize makespan. In the context of retail order picking within the NPFSSP framework, characterized by absent operations, transportation delays, and restricted capacity limitations, Souiden, et al.25 introduced a mathematical model aimed at reducing the overall time taken by all machines involved. With time couplings and makespan objectives, Idzikowski, et al.26 used three methods i.e. B&B method, TS, and GA algorithm to solve them and tested the results on Taillard (Taillard27) problems. With makespan as the objective function and stochastic processing times, Rossit, et al.28 introduced a Novel Approach for the combinatorial analysis of FSSP with two job cases. The goal was to determine the dominance properties between PFSSP and NPFSSP. Brum, et al.29 reduced the overall completion time (∑C) in the NPFSSP by proposing a framework for the development of IG algorithms and implementing an automatic algorithm configuration to achieve more efficient outcomes. A high-quality permutation schedule is first created, which is subsequently transformed into a non-permutation schedule by altering the sequence of jobs on select machines. The outcomes were verified using benchmark problems from Taillard and VRF (Vallada, et al.30).
Over the years researchers have mostly focused on GA for scheduling problems as they are powerful and can solve complex problems which are difficult to be solved using conventional techniques. GA has been successfully used in industrial engineering, operations research, management science, system engineering, etc. However, GA requires ample computational time, and sometimes it gets trapped in local minima31. To overcome these difficulties, the ES algorithm is used in this research. ES is a stochastic search heuristic and is a specialization of Evolutionary algorithms used for solving various optimization problems. ES mimics adaptive procedures in biological evolution. ES is mostly applied to continuous black-box optimization problems. The main operators of the ES are initialization, recombination, mutation, evaluation, and selection. In the initialization phase, an individual solution is generated and its fitness is evaluated. The evolutionary loop begins after the initialization phase and continues through recombination, mutation, evaluation, and selection until the termination requirements are met. Mutation and recombination are the main operators in ES to create offspring and have equal importance in the performance of the algorithm. Based on the objective function value, the selection operator selects individuals who are transferred to the next iteration.
The basic types of ES are Two membered-ES and Multi membered-ES. In a Two-membered, one offspring is generated from a parent. In multi-membered-ES, more than one offspring is generated from a single parent. One unique characteristic of ES that distinguishes it apart from GA, which has a constant mutation rate, is the mutation operator’s self-adaptation. The mutation operator signifies the magnitude and direction of changes in the origin of the new position of the individuals in the search space. ES is commonly represented as (µ + λ)-ES, where µ represents the number of parents and λ represents the number of offspring. For recombination operators, different values of λ can be used i.e. 4, 8, 9, and 16 (Paris, et al.32). It is advised to choose λ = 4 for the minimal search of solution space with the least amount of computational time and λ = 16 for the highest search of solution space at the expense of computational time. Although ES is commonly applied to a continuous optimization problem, however by modifying the recombination and mutation operator was successfully applied to the discrete optimization problem by Cai and Thierauf [65]. For continuous optimization problems, there should be minor variations in all the components of a parent [40]. Small variations in parents reflect small mutations, which mimic natural biological evolution. In discrete optimization problems, constituents of a parent take their value from a discrete set, so a random variation arises from one discreet value to another nearby discrete value. Normally there is a large difference between two adjacent values, hence varying all components of a parent will result in a high mutation in the objective function. For better results, Cai and Thierauf [65] advised altering a few components in a parent. For more detail, on ES the readers should refer to [66], [67].
To date application of ES in the scheduling field is very limited, although it has been successfully applied to various optimization problems i.e. Image Filtering32, Capacitated Vehicle Routing Problem33, Structural Shape Optimization34, Designing Of Metal Forming Die Surfaces35, Feedforward And Recurrent Networks36, Multiprocessor Scheduling37, Mobile Manipulator Path Planning38, Multigrid Problems39, Wireless Sensor Networks40, Automatic Berthing41 and Electricity Load Forecasting Problems42,43). For Hybrid Flexible Flow Shop Problems, de Siqueira, et al.44 Proposed an algorithm based on the ES algorithm. The initial solution was generated using the NEH heuristic and IG algorithm. A Hybrid GA algorithm was proposed by Zhang, et al.45 by combining ES, Local search, and Population Diversity Supervision Scheme for Periodical Maintenance (PM) of FSSP. Khurshid, et al.46 proposed a Hybrid ES algorithm for Robust PFSSP, in which he utilized the global search abilities of ES and combined it with TS to exploit its Local search abilities. For the recombination operator, λ = 9 is used and for the mutation operator, double quad swap mutation is used. Two Fast Evolutionary algorithms based on ES were proposed by Khurshid, et al.47 to minimize the makespan of PFSSP. Results of the proposed algorithm were also validated in a real-life case of battery manufacturing, and the results show that by using ES the company can significantly increase its production. Khurshid, et al.48 combined an Improved ES algorithm with SA to minimize the makespan of PFSSP and the results were validated on Taillard benchmark problems. ES was also utilized to solve BFSSP with makespan as the objective function49 In another research on makespan minimization in the NWFSSP, Khurshid, et al.50 combined the Iterated Greedy (IG) algorithm with the ES algorithm. IG algorithm is famous for its simplicity in solving FSSP and the hybridization with ES leads to a robust algorithm that efficiently solved benchmark Taillard and Carlier problems. Recently ES was extended to Job Shop Scheduling Problems by Khurshid and Maqsood51 with minimization of makespan as the objective function. Together with SA, the ES creates the initial solution at random, enhancing the hybrid algorithm’s local search capabilities and preventing it from becoming stuck in local minima. Table 1, compares ES with other techniques in the literature used to solve NPFSSP.
Problem Statement
In NPFSSP, n-jobs are processed on m-machines. A job represents an individual task or work unit that must be processed across multiple machines in a specific order to complete. The processing sequence refers to the specific order in which each job will visit the machines to complete its required operations. Each job is processed by m operations with an order 1,…,m. The ith operation of a job is processed by the ith machine. The sequence of operation for machines can be different. Preemption is prohibited, and a job once loaded on a machine will be processed uninterrupted for the entire processing time. Processing times on the machine (including setup times) are known in advance and the number of jobs is known. All machines are thoroughly available and the number of machines is known. At time zero, any job can be started first. The storage capacity of buffers is unlimited.
Pij is the processing time of job j on machine i. The processing of the job is completed once it finishes visiting all the machines. Let Cij be the completion time of job j on machine i. The total completion time also termed makespan can be calculated as follows:
Examine the following variables along with a large positive constant M.
The mathematical model to calculate the makespan of NPFSSP is as follows.
s.t
Equations 2, and 3 ensure that one job is processed on one machine only. Equation 4 ensures that a job is finished on a machine before it is loaded on the next machine. Equation 5 defines the domains of the variables.
Methodology
NEH Heuristic
In FSSP for the minimization of makespan, the NEH heuristic10 is regarded as the best constructive heuristic of all times. Ruiz and Maroto52 compared various heuristics available for PFSSP and has shown that the NEH heuristic achieves best results for makespan objective function. The superiority of the NEH heuristic over other heuristics was also investigated by Kalczynski and Kamburowski53. To obtain further information and practical uses of the NEH heuristic, the readers should consult the papers of Kalczynski and Kamburowski54, Dong, et al.55, and Kalczynski and Kamburowski56. The NEH heuristic works in three steps. It initially sequences the job by the sum of completion times in descending order on all the machines. In the second step, two jobs with the maximum value of work content are selected first and their makespan is calculated. In step three, the remaining jobs are then placed at possible positions so that the makespan is minimized. Job 3 ≤ i ≤ n can be inserted into the partial sequence in i different positions. Using Taillard acceleration, the NEH algorithm’s computational time was lowered from O(n3 m) to O(n2 m)11. Combining the NEH heuristic with other Meta-Heuristics yields the best results as claimed by numerous researchers. Stützle57 combined the NEH heuristic with the ILS algorithm, Tabu search was combined with NEH heuristic by Grabowski and Wodecki58, the NEH heuristic was combined with two GA by Ruiz, et al.59, Ruiz and Stützle60 combined Iterated Greedy algorithm with NEH heuristic, Whale optimization algorithm combined NEH heuristic by Abdel-Basset, et al.61, and Aqil62,63 combined NEH heuristic with population based meta-heuristics i.e. IG algorithm, Migratory Bird Optimization, Artificial Bee Colony algorithm, and ILS algorithm.
The main strength of the NEH heuristic is the initial arrangement of jobs and jobs insertion phase, while its weakness is the large number of ties during step 3. The tie-breaking mechanism of Fernandez-Viagas and Framinan64 which is based on minimum idle time has shown very good performance as it does not increase the O(n2 m) complexity of the NEH heuristic. Figure 1 displays the pseudocode for the NEH heuristic. Over the past 20 years, various Meta-heuristics58,65,58,66,67) have been used to solve PFSSP with the minimization of makespan as the objective function. In most of these Meta-heuristics, the initial sequence was found using the NEH heuristic. Local search methods i.e. GA, SA, ACO, and TS, among others, were used to improve the sequence, and these local search methods found very good results when combined with the NEH heuristic53. Hence, the NEH heuristic is also used to generate the initial sequence in this paper. The proposed HES works in two phases, in the initial phase solution for the NPFSSP is found using the NEH heuristic (a permutation schedule is generated). The outcomes of the NEH heuristic are optimized in the second phase using the IES method. The IES algorithm work in two steps, for first 1000 iterations the permutation schedule found from NEH is further improved while in the next 4000 iterations, a non-permutation schedule is improved using the IES algorithm. Therefore, the IES Algorithm uses the NEH Heuristic solution as a seed.

Pseudo Code for NEH Heuristic.
Evolution strategies (ES)
Darwinian Theory of Evolution i.e. Stronger tends to survive while weaker tend to die is the basis for Evolutionary algorithms. The subclass of Evolutionary Algorithms is Evolutionary Programming, ES, GA, and Genetic Programming. Conferring to Darwin’s theory, the principles of variation and selection are the fundamental principles in the development of species. All variants of Evolutionary algorithms have the same essence: offspring are generated from a parent population and then the best offspring are selected to generate a new parent for the next iteration. ES was developed by Rechenberg68 in 1970 and is a stochastic optimization algorithm. They were further improved by Schwefel69. The first application of ES was to design optimal shapes for the win shape and nozzle using physical experiments. High-performing structures with astonishing shapes were discovered due to the evolutionary design of ES. Originating from hill climbing strategies, ES was applied to other complex problems such as black optimization problems by using high-performance computers. The introduction of mutation distribution of adaptive step sizes contributed to the success of ES. Although some stochastic search algorithms utilized step-size adaptation, a flexible adaptation scheme in mutation distribution was focused on by researchers to improve its performance. This feature of ES distinguishes it from a GA where a constant mutation rate is used. For the adaptation of mutation parameters, three mainstream variants were developed. First, control a single step size by using the 1/5th success rule. Second, mutation self-adaptation which mimics natural evolution, and third, efficient de-randomized self-adaptation scheme. Attempts to find an effective de-randomized adaptation scheme let Hansen, et al.70 discover covariance matrix adaptation-ES, which is highly suitable for global optimization problems.
Population-based-ES also known as multi-membered-ES was developed in parallel and performed as collective Hill-climbing termed by Schwefel71. Multi-membered-ES is more suitable for noisy and global optimization problems, as they exploit the affirmative effects of recombination operators. Population-based-ES can be run in parallel and can be extended to advance ES for solving multi-modal and multi-objective optimization tasks. Presently, ES is mostly used to solve Simulation-based optimization. As ES does not require derivatives, hence it is also applicable to solve the optimization of non-smooth functions. Main variants of ES are used for continuous optimization problems, unlike GA which is suited for binary search spaces. Modern-ES are as efficient as other derivative-free optimization algorithms and are successfully applied to a large number of system optimization and engineering problems72. In ES, the whole population is simultaneously processed, unlike other algorithms where few solutions are processed from the population. The primary operators for ES are, recombination and mutation to produce offspring. ES is self-adaptable, meaning it can vary some parameters during a run. Initially, Hartmann73 used ES for numerical applications, and later Schwefel69 used it to solve discrete and binary parameter optimization problems. The key features of ES are as follows.
-
They are recommended for real value optimization problems.
-
The main source of genetic variation is a mutation, unlike GA where the crossover is the main genetic operator.
-
Crossover is not used and offspring are randomly generated from a parent by recombination.
-
A deterministic procedure is used for selection.
-
The mutation rate is varied during iterations to achieve faster results as mutation operators are parameterized.
ES is defined by the notion (µ + λ)-ES, where µ represents the number of parents and λ represents the number of offspring. ES can be classified into two types, Two membered-ES, and Multi membered-ES. The Two membered-ES is also represented as (1 + 1)-ES which is simply a mutation scheme and the population consists of a single parent. Initial experiments were accomplished using one parent and one offspring and mutation was carried out by withdrawing two numbers from a normal distribution. The parent was replaced by its offspring if it was better. With the invention of computers and the introduction of the population concept by Rechenberg, the Two membered (1 + 1)-ES was replaced with a Multi membered-ES. Additionally, the concept of recombination operators is incorporated in the Multi-membered-ES. Now, a parent produces λ offspring in one repetition. The Multimembered-ES consists of two basic stages. Step one uses both recombination and mutation to create offspring. However, a method for choosing survivors is used in the second stage. Recombination operators can be classified into intermediate and discrete operators. In the former category, parental variable values are selected from parents at random. While in the later category, the offspring gets the average value of its parents. Both mating selection and the need that the parent involved to be distinct are absent. For continuous variables, 100% mutation and 100% recombination are carried out. If the parents take part in the selection process it is termed as (µ + λ)-ES otherwise it is termed as (µ, λ)-ES where parents die out of the selection phase and only offspring take part in the selection process. Because only the finest parents are kept and the rest are forgotten, the selection process is referred to as truncation selection. It is advised for recombination operators to use different values of λ. Paris, et al.32 Used λ = 4, 8, and 16 in their research on image processing.
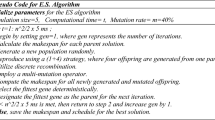
To locate a better nearby solution and avoid local minima, the ES method should be paired with any local search technique as it occasionally becomes caught in one. In the proposed research, the exploitation ability of the NEH heuristic is combined with the exploration ability of IES for optimum results with minimum computational time. To find better solutions and escape local minima, the IES algorithm is equipped with a Local Search Technique. Rossit, et al.2 showed that the possible solution of PFSSP is a subset of NPFSSP. Therefore, to find a good non-permutation schedule, first, start with a better permutation schedule and then modify it to find a good non-permutation schedule. So in this research, first a permutation schedule is generated using the NEH heuristic. The permutation schedule acts as a parent solution for the IES algorithm, which further improves the permutation schedule for the next 1000 iterations. Then a non-permutation schedule is generated and improved using the IES algorithm in the next 4000 iterations. Figure 2 shows the Pseudo code of HES, which shows the generation scheme of the Permutation and Non-permutation schedule using the NEH heuristic and IES algorithm respectively. In step 10, for finding a non-permutation sequence, the permutation sequence found is fixed on the first 40% machines and is not changed for the next 4000 iterations, i.e. The sequence for the first 40% machines is the same as found from the previous 1000 iterations. For the last 60% of machines, the non-permutation sequence is obtained by applying the IES algorithm and the sequence is varied so that the makespan is minimized. Therefore, in the second stage of the IES algorithm, a non-permutation sequence is obtained by altering the sequence of the last 60% of machines only. As shown in Fig. 1, for the first two machines permutation sequence is fixed, while in the last two machines, the sequence is varied so that the makespan is minimal as compared to the makespan found using the permutation sequence.

Pseudo Code for HES algorithm.
Improved evolution strategies (IES)
To enhance the performance of (1 + 1)-ES, and to ensure simultaneous intactness of exploitation and exploration ability of the ES algorithm, the following improvements are suggested.
-
To explore the solution space as much as possible in the shortest amount of time, utilize the quad-swap mutation operator.
-
For recombination, λ = 16 is used, hence a parent solution generates sixteen offspring at random.
-
For selection, (µ + λ) is used in this paper, hence both the offspring and parent are involved in the selection process. If the makespan of a parent solution is superior to that of the generated offspring, the parent solution may persist through multiple iterations, unless it is replaced by a more optimal offspring.
-
To guide the search to unexplored areas and increase exploration, a frequency table is used. In the frequency table, a record of the mutated chromosome is maintained and a chromosome can be mutated a maximum of 50 times.
-
To escape local minima, a Local Search Technique is utilized.
-
IES is applied for the optimization of Demirkol Benchmark problems for the very first time.
Figure 3 shows the Pseudo Code for Improved ES algorithm.

Pseudo Code for IES algorithm.
Initialization
The a individuals build a parent population from µ parent am, where m = 1,…, µ and λ offsprings ãl where l = 1,…, λ. The parent and offspring population at iteration g are symbolized as \(\:{{\beta\:}_{\mu\:}}^{k}\) and \(\:{{\beta\:}_{\lambda\:}}^{k}\) where
Selection
Based on the fitness values, the selection is used to find solutions before performing recombination. While fitness refers to the minimization of makespan during the exploration of solution space. Through a deterministic procedure, selection operators of type (+,) generate a parent population \(\:{\beta\:}_{\mu\:}\) for the next iteration g + 1. According to fitness value F(y), the best individuals from a set of γ individuals (a1,…,aγ) are selected.
\(\:\left({a}_{1;\varvec{\upgamma\:},\:}{a}_{2;\varvec{\upgamma\:},\:\:}{\dots\:,a}_{\mu\:;\varvec{\upgamma\:},\:\:}\right)=selection\:({a}_{1},\dots\:,{a}_{\gamma\:})\) where γ ≥ µ (4)
Recombination
In recombination, offspring are denoted as λ is generated from the parent which is denoted as µ. The main categories of recombination operators are intermediate and discrete recombination. In the former recombination, the properties of all the individuals are taken into account and the offspring takes their average properties. While in the latter recombination, individual parent properties are transferred to their offspring. In this paper λ = 16 is used, where sixteen offspring are produced from one parent at random. The recombination operator selects the parent (\(\:\epsilon\:\)) which takes part in the generation of offspring.
\(\:\epsilon\:=\left({a}_{1},\dots\:,{a}_{m},\dots\:,{a}_{\mu\:}\right)\) and m = 1,…, µ (5)
The recombination operator itself provides little benefit, however, when it is combined with the mutation operator it provides useful results. Recombination guarantees that the offspring are similar to their parents.
Quad swap mutation operator
Mutation serves as the primary mechanism for generating genetic diversity within the ES algorithm. It introduces minor alterations at each iteration. A key advantage of the ES algorithm lies in its ability to adaptively modify the mutation operator. Given that the mutation operator is contingent upon the specific problem being addressed, the precise configuration of this operator significantly influences the overall efficacy of the ES. Notably, swap mutation is particularly effective for combinatorial optimization challenges. To maximize the exploration of the solution space efficiently, a Quad swap mutation operator is employed, which involves selecting four chromosomes and exchanging their positions, as illustrated in Fig. 4. The mutation rate is fixed during the iteration. The history of the mutated chromosomes is also maintained and each chromosome can be mutated a maximum of 50 times each, this guides the search of the algorithm to new promising areas. The new offspring (\(\:{{\beta\:}_{\lambda\:}}^{k})\) are generated by randomly interchanging positions of parent population (\(\:{{\:\beta\:}_{\mu\:}}^{k}\)) at each iteration (k).

Quad swap mutation operator.
Frequency table
To avoid repetition of the same offspring, again and again, a frequency table is used. The frequency table stores the swapping moves of the mutated offspring. Maximum mutations for each chromosome are set at 50. Hence less mutated offspring are given priority in mutation, so the search is guided to less explored areas. The frequency table minimizes computational time and also increases the exploration ability of the IES algorithm.
Selection (survivor)
Based on fitness, the selection is used to deterministically choose the best µ-parents after creating λ-offsprings. The two selection operators available in ES are (µ + λ) and (µ, λ). In the former operator, the selection process involves both parents and the offspring, the best solution is termed as a parent for the next iteration. In the latter operator, parental individuals are eliminated from the selection process, allowing only their offspring to participate. The most optimal solution among the offspring is designated as the parent for the subsequent iteration. The (µ, λ) strategy is suggested for optimizing real-valued parameters. For combinatorial optimization (µ + λ) is recommended75 and is used in the paper.
Local search
To guide the solution search to more promising areas and to avoid the local minima, a local search technique is incorporated in the IES algorithm. The insertion Local search technique of the IG algorithm of Ruiz and Stützle60 is used to generate new sequences and operate as follows. A job from a sequence is removed and inserted into another position. The process is repeated in each iteration to find a new solution that has a better makespan value. The history of the removed job is maintained so that repetition of the same move can be avoided and the search can be guided to less explored areas. Ruiz and Stützle60 showed that small modifications in the local search provide better solutions while large modifications cause a strong disruption. The pseudocode for the local search technique is shown in Fig. 5.

Local search procedure.
Termination
Various termination criteria may be employed, such as computational time, upper bound values, lack of improvement in solutions over a designated number of iterations, and the total number of iterations, among others. In this study, the chosen termination criterion is the number of iterations, which is set at 5,000. Figure 6 illustrates the mechanics of the proposed Hybrid Evolution Strategy algorithm.

Mechanics of Hybrid Evolution Strategies.
Parameter optimization
The population size, selection operator, reproduction operator, mutation type, mutation rate, and termination criteria are the six main factors that make up the ES algorithm. Typically, the population size, determined by the reproduction operator, remains constant. As the population size increases, so does the computational time required for each iteration. For flow shop problems swap mutation operators perform better as compared to other mutation operators74. There are various types of swap mutation operators i.e. single swap mutation operators, double swap mutation operators, quad swap mutation operators, and k-swap mutation operators. For parameter optimization, the best-performing mutation operator is selected from single swap mutation operators, double swap mutation operators, and quad swap mutation operators as the k-swap mutation operator takes ample computational time. The mutation rate during the iteration is fixed. Different types of reproduction operators can be selected i.e. λ = 4, 5, 8, 9, and 16 32. Various termination iterations, such as 3000, 3500, 4000, 4500, and 5000, can be employed. As a result, we need to figure out the ES algorithm’s three total parameters. The calibration of algorithm parameters is done using the Multifactor Analysis of Variance Design of Experiments76. The algorithm’s stopping criterion is 50xnxm milliseconds, where n and m are the number of jobs and machines, respectively. The algorithm is tested on eight instances i.e. DMU_20_15_10, DMU_20_20_10, DMU_30_15_9, DMU_30_20_10, DMU_40_15_10, DMU_40_20_9, DMU_50_15_8, DMU_50_20_8, and five iterations are performed for each instance to perform the parameter configuration.
The following factors are the focus of the computational experiment during the calibration phase: (I) the five levels of the reproduction operator (λ): 4, 5, 8, 9, and 16. (II) Mutation type at three levels: single swap mutation operators, double swap mutation operators, and quad swap mutation operators. (III) Five levels for termination criteria are used i.e. 3000, 3500, 4000, 4500, and 5000, resulting in 5 × 3 × 8 × 5 = 600 Average Relative Percentage Difference (ARPD) values.
In Table 2 results of a Multi-factor ANOVA are shown, the ARPD is the response variable, and it can be computed using Eq. (6).
C* is the makespan of the ES algorithm, while C is the best makespan value for any instance.
ANOVA involves finding the ideal factor concentrations to either maximize or decrease the response variable. Selecting the elements (independent variables) and their respective levels is the first step in designing an experiment77. After that, the design should let the elements be changed methodically to see how they affect the response variable (dependent variable). The following are the basic steps in an ANOVA: (1) Determine the average response for every factor level. (2) Determine the response’s overall mean. (3) Divide the overall variation into parts that can be attributed to every element and how they interact. (4) To calculate the F-statistic for each individual factor and their interactions, divide the mean square of each factor by the mean square of the error. Subsequently, to assess significance, compute the p-value corresponding to each F-statistic. A factor is considered significant if its p-value falls below the predetermined significance threshold, such as 0.05.
The results in Table 3 show the P-value for the reproduction operator is 0.000, hence it is statistically significant as its P-value is less than 0.05. The reproduction operator significantly influences the response variable. In contrast, the P-value associated with mutation type is 0.927, indicating that mutation type does not have a meaningful impact on the response variable. Similarly P-value for termination criteria is 0.680, hence it also has no substantial effect on the response variable and it fails to reject the Null hypothesis. Figures 7, 8 and 9 present the means along with a 95% confidence interval for mutation type, reproduction type, and termination criteria. A statistically significant difference between two means is indicated when the ARPD values for those means do not overlap.

Box plot for mutation types.

Box plot for reproduction types.

Boxplot for termination criteria.
Statistically, the value of reproduction operator 5 is better than 4, 8 is better than 5, 9 is better than 8, and 16 is better than 9, as shown in Fig. 8. However, out of all the reproduction operators, value 16 is the best. From Fig. 7 on mutation rates, we can see that a double swap is better than a single swap and a quad swap is better than a double swap. Therefore, we select the quad-swap mutation operator. Regarding the termination criteria, Fig. 9 shows that the ARPD value at 5000 iterations is the lowest when compared to values at 3000, 3500, 4000, 4500, and 5000 iterations. As a result, we set the reproduction operator to 16 and the mutation rate to quad-swap mutation, along with a 5,000 iteration count.
Computational results
Test problems
To assess the effectiveness of the HES algorithm, they are tested on benchmark problems of Demirkol, et al.7. Demirkol instances are hard instances and are used in experimental results by numerous researchers. The Demirkol benchmark problems can be downloaded using URL78. A total of 600 problems are proposed by Demirkol, et al.7 for shop scheduling problems. 120 instances are for minimization of makespan (Cmax) while 480 instances are for minimization of maximum Lateness (Lmax). 40 instances are used for the minimization of Cmax for NPFSSP. For these instances, machine ranges are 15 & 20, while job ranges are 20, 30, 40 & 50. Hence, the total number of combinations is eight, and the number of operations ranges from 300 to 1000. For all these eight combinations, a total of ten instances are generated.
Results and discussion
The performance of any algorithm is dependent on the exact tuning of its genetic operators. NEH heuristic is utilized to generate the initial solution, which is then refined using the global search ability of the ES algorithm. To guide the ES to less explored areas and to escape local minima, Hybridization is performed by incorporating a frequency table and Local Search Technique. HES is coded in MATLAB 2013 and runs on a Core™ i5 with a 2.4 GHz processor with 8 GB RAM. To validate the results of the HES, it has been run 30 times for each instance of Demirkol benchmark problems. The computational time and makespan of each instance tested on the HES algorithm are shown in Table 2. The solution of the HES is compared with the Shifting bottleneck heuristic of Demirkol, et al.7 (DMU). Ying and Lin15 proposed a Multi-heuristic Desirability Ant Colony algorithm (MHD-ACS) and improved the upper bound for 32 out of 40 problems of Demirkol. The MHD-ACS algorithm was coded in Visual C + + and run on a Pentium 4 (1.5 GHz) Processor. Each instance was run five times and the termination criteria were 5000 iterations. Rossi and Lanzetta18 suggested a Native Non-Permutation Ant Colony Optimization (NNP-ACS) algorithm to solve the NPFSSP of DMU. The NNP-ACS algorithm runs with a Pentium 4 (3 GHz) processor and 2 GB RAM. Each instance was run ten times and the termination criteria were 3000 iterations. Ying17 proposed an IG algorithm for NPFSSP and validated his results on Demirkol benchmark problems. The IG algorithm was coded in Visual C# and ran a Pentium 4 (2.4 GHz) processor. Cui, et al.20 suggested a Hybrid GA (HIGA) for NPFSSP with unavailability constraints. The HIGA algorithm was coded in C# and ran an Intel Core i3 3.3 GHz and 4 GB RAM.
To fairly compare HES with the other algorithms i.e. DMU, MHD-ACS, NNP-ACS, IG, HIGA all these algorithms were coded in MATLAB 2013 and run on the same processor, i.e. Core™ i5 with a 2.4 GHz processor with 8 GB RAM. Termination criteria for all these algorithms were also set at 5000 iterations. Makespan values and computational time taken by DMU, MHD-ACS, NNP-ACS, IG, and HIGA for Demirkol problems are shown in Table 3. From Table 3 it is evident that the computational time taken by HES for all the 40 Demirkol problems is also lower than the computational time taken by DMU. Thus, in terms of processing time and solution quality, HES has surpassed DMU. HES also outperforms MHD-ACS for all 40 instances in terms of makespan values and computational time. HES found New 40 UB for all Demirkol problems and performed better than NNP-ACS for all 40 problems. However, the computational time taken by NNP-ACS is much higher than the computational time of HES. For the instance, DMU_20_15_3, the computational time of ES is 15.88 s, while for NNP-ACS it is 45.71, which is almost 3 times more than HES. For the instance, DMU_30_15_3, the computational time of HES is 17.31 s while for NNP-ACS it is 178.78 which is almost ten times the computational time of HES. For the instance, DMU_50_20_2, the computational time of HES is 28.58 s while for NNP-ACS it is 719.18, which is almost twenty-five the computational time of HES. Hence, it is conceived that HES performs better than NNP-ACS in terms of computational time and makespan values. HES performs better than IG for all 20 jobs problems although the computational time taken by IG is less. However, looking at the solution quality the computational time difference is very small and can be ignored. For 30 jobs with 15 and 20 machines, HES performs better than IG. For 40 jobs with 15 and 20 machines, IG performs better than HES and the computational time taken by IG is almost twice the computational time of HES. For 50 jobs and 15 machines case, the performance of IG surpasses that of HES. Conversely, in a situation involving 50 jobs and 20 machines, HES demonstrates superior performance compared to IG. Furthermore, the computational time required by IG exceeds twice that of HES across all instances involving 50 jobs.
HES finds a better solution as compared to HIGA for problems with 50 jobs and 15 machines. For 20 jobs and 20 machines cases, HES finds a better solution, and the computational time taken by HES is almost the half of computational time of HIGA. In the case of having 30 jobs and 15 machines, HIGA performs better than HES but at the expense of computational time, as the computational time taken by HIGA is thrice the computational time of HES. In the case of having 30 jobs and 20 machines, HES performs better than HIGA and the computational time of HES is minimum. In the case of 30 jobs and 15 machines, HIGA performs better than HES but at the expense of computational time, as the computational time taken by HIGA is thrice the computational time of HES. Similar is the case for 30 jobs and 20 machine instances where HIGA performs better than HES. HES outperformed HIGA for all 40 job instances but the computational time taken by HIGA is almost five times as compared to the computational time of HES. For 50 jobs and 15 machines cases, HIGA finds better solutions while in the case of having 50 jobs and 20 machines, HES performs better than HIGA. In terms of the overall comparison of HES with techniques, HES outperforms DMU, MHD-ACS, and NNP-ACS algorithms. The performance of HES is at par with the performance of IG and HIGA, however, the computational time of IG and HIGA is much more as compared to the computational time of HES.
The suggested HES is suitable for both small and large-scale problems, demonstrating significantly reduced computational time in comparison to other algorithms documented in the literature for NPFSSP. Therefore, it is crucial to implement the proposed method in practical scenarios to assess its efficacy and leverage the minimal computational time that HES offers in determining optimal processing sequences.
Figure 10 provides a comparison of HES with DMU, MHD-ACS, NNP-ACS, IG, and HIGA algorithms in terms of makespan values. From Fig. 10, it ca. be seen that HES performs better than DMU, NNP-ACS, and MHD-ACS. HES finds a better solution as compared to IG and HIGA for 20 and 30 jobs instances, however, for 30 and 40 jobs, IG and HIGA find better makespan values as compared to HES. In the case of 50 jobs and 15 machines, both IG and HIGA find better makespan values. For 50 jobs and 20 machine cases, HES finds better makespan values as compared to IG and HIGA. Another important aspect of the performance of any algorithm is its improvement in objective function value, which increases the number of iterations. In Fig. 11, the graph is shown for the instance DMU_50_20_2, in which the x-axis shows the number of iterations while the y-axis shows the makespan value at the respective number of iterations. At 500 iterations, the makespan is 8648, and at 1000 iterations, it reduces to 8389. Makespan values at 2000, 3000, 4000, and 5000 iterations are 8281, 8137, 8076, and 7996. Hence, there is a continuous improvement in makespan values with the number of iterations. Therefore, it is evident that the HES algorithm avoids local minima and finds better schedules in its neighborhood with an increase in the number of iterations.

Makespan Comparison of HES with benchmark problems.

Evolution of the best solution.
The performance of any algorithm is calculated using the % GAP from the lower bound, hence for the Demirkol benchmark instances %GAP can be calculated for all the instances using Eq. (7)
\(\:where\:\)\(\:{LB}_{d}\:is\:the\:lower\:bound\:found\:by\:Demirkol\:\)\(\:{\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:C}_{\:best}\:is\:the\:best\:makespan\:found\:from\:any\:algorithm\).
In Table 4, the %GAP for all 40 problems of DMU is calculated using HES, DMU, MHD-ACS, NNP-ACS, IG, and HIGA Algorithms. For instance, DMU_20_15_3, the %GAP for DMU and HES is 32.29% and 14.04%, which is almost half the %GAP of DMU. %GAP for the instance DMU_30_15_3, for DMU and HES, is 30% and 12.21% respectively, so for this instance, the %GAP for HES is less than half the value of DMU. So it shows that HES gives very good results for small instances of problems. Now comparing results of large instances, the %GAP for the instance DMU_50_20_2, for DMU and HES is 18.66% and 10.67% respectively. So even for large instances, HES is giving better results as compared to the results of DMU. Similarly, the %GAP of HES for all 40 instances is less than the %GAP of DMU, which shows the better performance of the HES algorithm for the 40 instances. %GAP calculated by MHD-ACS is better than the %GAP calculated by DMU for all 40 instances, however, it is inferior to the %GAP of HES. %GAP of NNP-ACS is better than both DMU and MHD-ACS, however, it is also inferior to the %GAP values of HES. Therefore, it is proved that the performance of HES is better than DMU, MHD-ACS, and NNP-ACS in terms of %GAP values. %GAP values of HES are at par with the HIGA however IG provides better values, especially for instances where jobs are 40 and 50 and the machines range from 15 to 20.
The overall average %GAP for DMU, MHD-ACS, NNP-ACS, IG, HIGA, and HES is 25%, 21.18%, 24.27%, 13.35% 4.53%, and 14.53% respectively. So in terms of overall performance HES is better than DMU, MHD-ACS, NNP-ACS, and at par with HIGA however, IG performs better than HES in terms of average %GAP values.
In Fig. 12, the %GAP for DMU, MHD-ACS, NNP-ACS, IG, HIGA, and HES is shown in graphical form. The smaller the %GAP the better the performance of the algorithm, hence from Fig. 12, it is clear that for all the 40 DMU problems, the %GAP of HES is minimum, as compared to the %GAP, found by DMU, MHD-ACS & NNP-ACS. This proves the better performance of HES than DMU, MHD-ACS, and NNP-ACS. The performance of HES is at par with the performance of IG and HIGA.

%GAP Comparison of HES with other benchmark problems from LB.
Wilcoxon signed rank test
A non-parametric statistical test called the Wilcoxon signed-rank test is used to assess the effectiveness of two algorithms. Finding out if the paired performance measurements of two algorithms differ statistically significantly across various datasets or experimental settings is its main goal. To assess how well the HES algorithm performs in comparison to the DMU, MHD-ACS, NNP-ACS, IG, and HIGA algorithms, It is essential to assess the statistical differences in the performance of algorithms by employing the Wilcoxon signed rank test. Should the asymptotic significance value fall below the predetermined significance level of 0.05, it indicates a statistically significant difference between A and B. Table 5 displays the results of the Wilcoxon test for the algorithms HES, DMU, MHD-ACS, NNP-ACS, IG, and HIGA. The values of the Alternative Hypothesis and Null Hypothesis for HES versus DMU, MHD-ACS, NNP-ACS, IG, and HIGA, calculated against the Wilcoxon signed test, are shown in Table 6. The Cmax and PI values of HES differ considerably from the DMU method since the P-value for HES vs. DMU is less than 0.05.
Additionally, the Cmax and PI values of HES differ considerably from those of the MHD-ACS algorithm since the P-value for HES vs. MHD-ACS is less than 0.05. The Cmax and PI values of HES differ considerably from those of the MHD-ACS and HIGA algorithms, and similarly, the P-values for HES vs. NNP-ACS and HES vs. HIGA are less than 0.05. Nonetheless, the HES vs. IG P-value is more than 0.05, indicating that the Cmax and PI values for the two methods do not differ significantly. Therefore, the statistical results of HES are better than DMU, MHD-ACS, NNP-ACS, and HIGA algorithms but inferior to the IG algorithm.
Friedman test
A non-parametric statistical test called the Friedman test is used to compare different algorithms on various datasets. Finding out whether there are any appreciable variations in the algorithms’ performance is its main goal. Using a Friedman test, the HES algorithm’s performance is contrasted with the DMU, MHD-ACS, NNP-ACS, IG, and HIGA algorithms’ performances. A statistical technique for assessing how well suggested algorithms perform in comparison to other algorithms is the Friedman test. Table 6 displays the average rating of all algorithms in comparison to five algorithms. ARPD data are used to compare each algorithm. The IG algorithm, with a mean rank of 1.88, outperforms all other algorithms considered. Following closely, the HES-SA algorithm holds the second position with a mean rank of 2.13. Additionally, the performance of the HIGA algorithm is comparable to that of the HES algorithm. Other algorithms i.e. NNP-ACS, MHD-ACS, and DMU have mean ranks of 4.24, 5.06, and 5.58 respectively and their performance is inferior as compared to the HES algorithm.
Conclusion and recommendations
Since the objective of this research is the minimization of makespan for NPFSSP, hence schedules are generated for NPFSSP using a HES algorithm. Researchers have dedicated significant attention to Hybrid Meta-heuristics over the years, aiming to integrate the most effective characteristics of various methodologies. In this context, the HES algorithm merges the exploitation capabilities of the NEH heuristic with the exploratory aspects of the IES algorithm. Additionally, to avoid being trapped in local minima, a Local Search Method is integrated into the IES algorithm. The initial solution was generated using the NEH heuristic, which acts as a seed for IES. The mutation rate for the Quad swap is utilized, and adjustments to this rate are made to identify the optimal outcomes while minimizing computational time. To guide the search to promising areas, a frequency table is used, which stores the history of mutated chromosomes and each chromosome can be mutated a maximum of 50 times. The frequency table limits the cyclic repetition of the same mutation chromosomes and then guides the search to less explored areas of the solution space. The algorithm underwent testing on 40 instances of the Demirkol Benchmark problems related to the NPFSSP. The findings indicate that the HES algorithm outperformed other solution methods documented in the literature, demonstrating superior performance in terms of computational time, solution quality, and robustness.
Further recommendations are as follows: First, the algorithm should be applied to real-life problems to minimize their total completion time. Second, the objective of this research was makespan, however, it can be extended to other performance criteria i.e. tardiness, total flow time, maximum lateness, total tardiness, etc. Third, HES can be applied to other manufacturing environments. Fourth, the proposed research did not account for sequence-dependent setup times; however, it is recommended that such factors be incorporated in future studies. Fifth, develop an algorithm to solve NPFSSP with more than three objectives. Sixth, in this paper, the processing times are deterministic; the proposed technique should be extended to problems with stochastic processing times. Finally, schedules are generated for Demirkol problems, however, schedules must be generated for VRF (Vallada, et al.30) instances, to validate the performance of HES on harder benchmark problems.
Data availability
Data is available upon request from the corresponding author.
References
Garey, M. R. & Johnson, D. S. Computers and intractability: a guide to the theory of npcompleteness (series of books in the mathematical sciences). ed. Computers Intractability, 340 (1979).
Rossit, D. A., Tohmé, F. & Frutos, M. The non-permutation flow-shop scheduling problem: A literature review. Omega 77, 143–153. https://doi.org/10.1016/j.omega.2017.05.010 (2018).
Ye, H., Li, W. & Miao, E. An effective heuristic for no-wait flow shop production to minimize makespan. J. Manuf. Syst. 40, 2–7. https://doi.org/10.1016/j.jmsy.2016.05.001 (2016).
Tavakkoli-Moghaddam, R., Rahimi-Vahed, A. & Mirzaei, A. H. A hybrid multi-objective immune algorithm for a flow shop scheduling problem with bi-objectives: Weighted mean completion time and weighted mean tardiness. Inf. Sci. 177, 5072–5090. https://doi.org/10.1016/j.ins.2007.06.001 (2007).
Liu, G., Song, S. & Wu, C. Some heuristics for no-wait flowshops with total tardiness criterion. Comput. Oper. Res. 40, 521–525. https://doi.org/10.1016/j.cor.2012.07.019 (2013).
Vahedi-Nouri, B., Fattahi, P., Tavakkoli-Moghaddam, R. & Ramezanian, R. A general flow shop scheduling problem with consideration of position-based learning effect and multiple availability constraints. Int. J. Adv. Manuf. Technol. 73, 601–611. https://doi.org/10.1007/s00170-014-5841-4 (2014).
Demirkol, E., Mehta, S. & Uzsoy, R. Benchmarks for shop scheduling problems. Eur. J. Oper. Res. 109, 137–141. https://doi.org/10.1016/S0377-2217(97)00019-2 (1998).
Garey, M. R., Johnson, D. S. & Sethi, R. The complexity of flowshop and jobshop scheduling. Math. Oper. Res. 1, 117–129. https://doi.org/10.1287/moor.1.2.117 (1976).
Lin, S. W. & Ying, K. C. Applying a hybrid simulated annealing and tabu search approach to non-permutation flowshop scheduling problems. Int. J. Prod. Res. 47, 1411–1424. https://doi.org/10.1080/00207540701484939 (2009).
Nawaz, M., Enscore, E. E. & Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 11, 91–95. https://doi.org/10.1016/0305-0483(83)90088-9 (1983).
Taillard, E. Some efficient heuristic methods for the flow shop sequencing problem. Eur. J. Oper. Res. 47, 65–74. https://doi.org/10.1016/0377-2217(90)90090-X (1990).
Janiak, A. General flow-shop scheduling with resource constraints. Int. J. Prod. Res. 26, 1089–1103. https://doi.org/10.1080/00207548808947920 (1988).
Liao, C., Liao, L. & Tseng, C. A performance evaluation of permutation vs. non-permutation schedules in a flowshop. Int. J. Prod. Res. 44, 4297–4309. https://doi.org/10.1080/00207540600595892 (2006).
Haq, A. N., Saravanan, M., Vivekraj, A. & Prasad, T. A scatter search approach for general flowshop scheduling problem. Int. J. Adv. Manuf. Technol. 31, 731–736. https://doi.org/10.1007/s00170-005-0244-1 (2007).
Ying, K. C. & Lin, S. W. Multi-heuristic desirability ant colony system heuristic for non-permutation flowshop scheduling problems. Int. J. Adv. Manuf. Technol. 33, 793–802. https://doi.org/10.1007/s00170-006-0492-8 (2007).
Zheng, T. & Yamashiro, M. in 7th International Conference on Electrical Engineering Computing Science and Automatic Control. 357–362 (IEEE). (2010).
Ying, K. C. Solving non-permutation flowshop scheduling problems by an effective iterated greedy heuristic. Int. J. Adv. Manuf. Technol. 38, 348 (2008).
Rossi, A. & Lanzetta, M. Featuring native metaheuristics for non-permutation flowshop scheduling. J. Intell. Manuf. https://doi.org/10.1007/s10845-012-0724-8 (2012).
Ziaee, M. & Karimi, H. Non-permutation flow shop scheduling problem with preemption-dependent processing time. Cogent Eng. 3 https://doi.org/10.1080/23311916.2016.1243982 (2016).
Cui, W. W., Lu, Z., Zhou, B., Li, C. & Han, X. A hybrid genetic algorithm for non-permutation flow shop scheduling problems with unavailability constraints. Int. J. Comput. Integr. Manuf. 29, 944–961. https://doi.org/10.1080/0951192X.2015.1130247 (2016).
Ye, S., Zhao, N., Li, K. & Lei, C. Efficient heuristic for solving non-permutation flow-shop scheduling problems with maximal and minimal time lags. Comput. Ind. Eng. 113, 160–184. https://doi.org/10.1016/j.cie.2017.08.024 (2017).
Benavides, A. J. & Ritt, M. Two simple and effective heuristics for minimizing the makespan in non-permutation flow shops. Comput. Oper. Res. 66, 160–169. https://doi.org/10.1016/j.cor.2015.08.001 (2016).
Assia, S., Ikram, E. A., Abdellah, E. B. & Ahmed, E. B. in 2019 5th International Conference on Optimization and Applications (ICOA). 1–5.
Benavides, A. J. & Ritt, M. Fast heuristics for minimizing the makespan in non-permutation flow shops. Comput. Oper. Res. 100, 230–243. https://doi.org/10.1016/j.cor.2018.07.017 (2018).
Souiden, S., Cerqueus, A., Delorme, X. & Rascle, J. L. Retail order picking scheduling with missing operations and limited buffer. IFAC-PapersOnLine 53, 10767–10772 (2020).
Idzikowski, R., Rudy, J. & Gnatowski, A. Solving non-permutation flow shop scheduling problem with time couplings. Appl. Sci. 11, 4425 (2021).
Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 64, 278–285. https://doi.org/10.1016/0377-2217(93)90182-M (1993).
Rossit, D. A., Vásquez, Ó. C., Tohmé, F., Frutos, M. & Safe, M. D. A combinatorial analysis of the permutation and non-permutation flow shop scheduling problems. Eur. J. Oper. Res. 289, 841–854 (2021).
Brum, A., Ruiz, R. & Ritt, M. Automatic generation of iterated greedy algorithms for the non-permutation flow shop scheduling problem with total completion time minimization. Comput. Ind. Eng. 163, 107843 (2022).
Vallada, E., Ruiz, R. & Framinan, J. M. New hard benchmark for flowshop scheduling problems minimising makespan. Eur. J. Oper. Res. 240, 666–677. https://doi.org/10.1016/j.ejor.2014.07.033 (2015).
Tseng, L. Y. & Lin, Y. T. A genetic local search algorithm for minimizing total flowtime in the permutation flowshop scheduling problem. Int. J. Prod. Econ. 127, 121–128. https://doi.org/10.1016/j.ijpe.2010.05.003 (2010).
Paris, P. C. D., Pedrino, E. C. & Nicoletti, M. Automatic learning of image filters using cartesian genetic programming. Integr. Computer-Aided Eng. 22, 135–151. https://doi.org/10.3233/ICA-150482 (2015).
Mester, D. & Bräysy, O. Active-guided evolution strategies for large-scale capacitated vehicle routing problems. Comput. Oper. Res. 34, 2964–2975. https://doi.org/10.1016/j.cor.2005.11.006 (2007).
Papadrakakis, M., Tsompanakis, Y. & LAGAROS, N. D. Structural shape optimization using evolution strategies. Eng. Optim. 31, 515–540. https://doi.org/10.1080/03052159908941385 (1999).
Schenk, O. & Hillmann, M. Optimal design of metal forming die surfaces with evolution strategies. Comput. Struct. 82, 1695–1705. https://doi.org/10.1016/j.compstruc.2004.03.055 (2004).
Mahsal Khan, M., Masood Ahmad, A., Muhammad Khan, G. & Miller, J. F. Fast learning neural networks using cartesian genetic programming. Neurocomputing 121, 274–289. https://doi.org/10.1016/j.neucom.2013.04.005 (2013).
Greenwood, G. W., Gupta, A. & McSweeney, K. in Proceedings of the First IEEE Conference on Evolutionary Computation. IEEE World Congress on Computational Intelligence. 345–349 (IEEE).
Watanabe, K., Izumi, K., Kunitake, Y. & Kiguchi, K. Path planning for an Omnidirectional Mobile Manipulator by Evolutionary Strategy. Nihon Kikai Gakkai Ronbunshu C Hen/Transactions Japan Soc. Mech. Eng. Part. C. 67, 2897–2904. https://doi.org/10.1299/kikaic.67.2897 (2001).
Shir, O. M. in Proceedings of the 2016 on Genetic and Evolutionary Computation Conference Companion. 33–34.
Srivastava, G. & Singh, A. Boosting an evolution strategy with a preprocessing step: application to group scheduling problem in directional sensor networks. Appl. Intell. 48, 4760–4774. https://doi.org/10.1007/s10489-018-1252-9 (2018).
Maki, A., Sakamoto, N., Akimoto, Y., Nishikawa, H. & Umeda, N. Application of optimal control theory based on the evolution strategy (CMA-ES) to automatic berthing. J. Mar. Sci. Technol. 25, 221–233. https://doi.org/10.1007/s00773-019-00642-3 (2020).
Khan, G. M. & Arshad, R. Electricity Peak Load Forecasting using CGP based Neuro Evolutionary techniques. Int. J. Comput. Intell. Syst. 9, 376–395. https://doi.org/10.1080/18756891.2016.1161365 (2016).
Coelho, V. N. et al. A self-adaptive evolutionary fuzzy model for load forecasting problems on smart grid environment. Appl. Energy. 169, 567–584. https://doi.org/10.1016/j.apenergy.2016.02.045 (2016).
de Siqueira, E. C., Souza, M. J., de Souza, S. R., de França Filho, M. F. & Marcelino, C. G. in Evolutionary Computation (CEC), 2013 IEEE Congress on. 989–996 (IEEE).
Zhang, S. Y., Lu, Z. Q. & Cui, W. Flow shop scheduling optimization algorithm with periodical maintenance. Jisuanji Jicheng Zhizao Xitong/Computer Integr. Manuf. Syst. CIMS. 20, 1379–1387. https://doi.org/10.13196/j.cims.2014.06.zhangsiyuan.1379.9.2014061 (2014).
Khurshid, B., Maqsood, S., Omair, M., Nawaz, R. & Akhtar, R. Hybrid evolution strategy approach for robust permutation flowshop scheduling. Adv. Prod. Eng. Manage. 15, 204–216. https://doi.org/10.14743/apem2020.2.359 (2020).
Khurshid, B. et al. Fast evolutionary algorithm for Flow Shop Scheduling problems. IEEE Access. https://doi.org/10.1109/ACCESS.2021.3066446 (2021).
Khurshid, B. et al. An Improved Evolution Strategy hybridization with simulated annealing for permutation Flow Shop Scheduling problems. IEEE Access. 9, 94505–94522. https://doi.org/10.1109/ACCESS.2021.3093336 (2021).
Maqsood, S. & Khurshid, B. in 28th International Conference on Automation and Computing (ICAC). 1–6 (IEEE). (2023).
Khurshid, B., Maqsood, S., Khurshid, Y., Naeem, K. & Khalid, Q. S. A hybridization of evolution strategies with iterated greedy algorithm for no-wait flow shop scheduling problems. Sci. Rep. 14, 2376. https://doi.org/10.1038/s41598-023-47729-x (2024).
Khurshid, B. & Maqsood, S. A hybrid evolution strategies-simulated annealing algorithm for job shop scheduling problems. Eng. Appl. Artif. Intell. 133, 108016. https://doi.org/10.1016/j.engappai.2024.108016 (2024).
Ruiz, R. & Maroto, C. A comprehensive review and evaluation of permutation flowshop heuristics. Eur. J. Oper. Res. 165, 479–494. https://doi.org/10.1016/j.ejor.2004.04.017 (2005).
Kalczynski, P. J. & Kamburowski, J. On the NEH heuristic for minimizing the makespan in permutation flow shops. Omega 35, 53–60. https://doi.org/10.1016/j.omega.2005.03.003 (2007).
Kalczynski, P. & Kamburowski, J. On the NEH heuristic for minimizing the makespan in permutation flow shops☆. Omega 35, 53–60. https://doi.org/10.1016/j.omega.2005.03.003 (2007).
Dong, X., Huang, H. & Chen, P. An improved NEH-based heuristic for the permutation flowshop problem. Comput. Oper. Res. 35, 3962–3968. https://doi.org/10.1016/j.cor.2007.05.005 (2008).
Kalczynski, P. J. & Kamburowski, J. An improved NEH heuristic to minimize makespan in permutation flow shops. Comput. Oper. Res. 35, 3001–3008. https://doi.org/10.1016/j.cor.2007.01.020 (2008).
Stützle, T. Applying iterated local search to the permutation flow shop problem. (1998).
Grabowski, J. & Wodecki, M. A very fast tabu search algorithm for the permutation flow shop problem with makespan criterion. Comput. Oper. Res. 31, 1891–1909. https://doi.org/10.1016/S0305-0548(03)00145-X (2004).
Ruiz, R., Maroto, C. & Alcaraz, J. Two new robust genetic algorithms for the flowshop scheduling problem. Omega 34, 461–476. https://doi.org/10.1016/j.omega.2004.12.006 (2006).
Ruiz, R. & Stützle, T. A simple and effective iterated greedy algorithm for the permutation flowshop scheduling problem. Eur. J. Oper. Res. 177, 2033–2049. https://doi.org/10.1016/j.ejor.2005.12.009 (2007).
Abdel-Basset, M., Manogaran, G., El-Shahat, D. & Mirjalili, S. A hybrid whale optimization algorithm based on local search strategy for the permutation flow shop scheduling problem. Future Generation Comput. Syst. 85, 129–145. https://doi.org/10.1016/j.future.2018.03.020 (2018).
Aqil, S. J. A. & J. f., S. & Engineering. Effective Population-based Meta-heuristics with NEH and GRASP heuristics minimizing total weighted flow Time in No-Wait Flow Shop Scheduling Problem under sequence-dependent setup time constraint. 1–24 (2024).
Aqil, S. Effective Population-based Meta-heuristics with NEH and GRASP heuristics minimizing total weighted flow Time in No-Wait Flow Shop Scheduling Problem under sequence-dependent setup time constraint. Arab. J. Sci. Eng. 49, 12235–12258. https://doi.org/10.1007/s13369-023-08642-7 (2024).
Fernandez-Viagas, V. & Framinan, J. M. On insertion tie-breaking rules in heuristics for the permutation flowshop scheduling problem. Comput. Oper. Res. 45, 60–67 (2014).
Nowicki, E. & Smutnicki, C. A fast tabu search algorithm for the permutation flow-shop problem. Eur. J. Oper. Res. 91, 160–175. https://doi.org/10.1016/0377-2217(95)00037-2 (1996).
Ying, K. C. & Liao, C. J. An ant colony system for permutation flow-shop sequencing. Comput. Oper. Res. 31, 791–801. https://doi.org/10.1016/S0305-0548(03)00038-8 (2004).
Murata, T., Ishibuchi, H. & Tanaka, H. Genetic algorithms for flowshop scheduling problems. Comput. Ind. Eng. 30, 1061–1071. https://doi.org/10.1016/0360-8352(96)00053-8 (1996).
Rechenberg, I. Optimierung technischer Systeme nach Prinzipien der biologischen Evolution. (1970).
Schwefel, H. P. Evolutionsstrategie und Numerische Optimierung (Technische Universität, 1975).
Hansen, N., Ostermeier, A. & Gawelczyk, A. in ICGA 57–64 (Citeseer).
Schwefel, H. P. Collective phenomena in evolutionary systems. (1987).
Back, T., Emmerich, M. & Shir, O. Evolutionary algorithms for real world applications [application notes]. IEEE Comput. Intell. Mag. 3, 64–67. https://doi.org/10.1109/MCI.2007.913378 (2008).
Hartmann, D. Optimierung balkenartiger Zylinderschalen aus Stahlbeton mit elastischem und plastischem Werkstoffverhaltenna,. (1974).
Liu, Q., Ullah, S. & Zhang, C. An improved genetic algorithm for robust permutation flowshop scheduling. Int. J. Adv. Manuf. Technol. 56, 345–354. https://doi.org/10.1007/s00170-010-3149-6 (2011).
Barrachina, J. et al. Reducing emergency services arrival time by using vehicular communications and evolution strategies. Expert Syst. Appl. 41, 1206–1217. https://doi.org/10.1016/j.eswa.2013.08.004 (2014).
Montgomery, D. C. Design and Analysis of Experiments (Wiley, 2017).
Vannucci, M., Colla, V. J. J., o., I. & Systems, F. Fuzzy adaptation of crossover and mutation rates in genetic algorithms based on population performance. 28, 1805–1818 (2015).
Acknowledgements
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2022S1A5C2A04092540).
Author information
Authors and Affiliations
Contributions
B.K. conceived the study; B.K., S.M., M.S.H., M.O., and S.J.H. were the principal investigators; B.K., S.M., MS.H., M.O., and S.J.H directed the overall study design; B.K. and S.M. performed the experiments; B.K., S.M., M.S.H., M.O., and S.J.H. analyzed the data; S.M. performed the supervision; B.K. wrote the manuscript. All authors discussed and interpreted the results. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khurshid, B., Maqsood, S., Habib, M.S. et al. A hybrid evolution strategies algorithm for non-permutation flow shop scheduling problems. Sci Rep 15, 11856 (2025). https://doi.org/10.1038/s41598-025-88124-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-88124-y
