
Abstract
Sorghum cultivation plays a pivotal role in addressing food insecurity in South Sudan, but persistent conflict continues to impose challenges in the agriculture sector therefore understanding the impact of conflict on sorghum yield prediction is important for country food security. This research integrates various sources of data including sorghum yield from small scale farmers during four agricultural seasons (2018–2021), climate, remotely sensed data, and conflict occurrence probability to predict sorghum yield in South Sudan. We use five Machine Learning (ML) techniques, including Random Forest (RF), Decision Tree (DT), Extreme Gradient Boosting (XGboost), Support Vector Machine (SVM) and Artificial Neural Network (ANN) to predict 2021 end-of-season sorghum yield in conflict affected Upper Nile and Western Bahr El Gazal states. We computed correlations and the analysis revealed high variability in term of yield in the 2 states with an average sorghum yield of 366.03 kg/ha (SD = 292.29 kg/ha) and a strong positive correlation (0.75, p < 0.001) between cultivated land size and sorghum yield. During the training phase DT, RF, XGboost and ANN models showed high accuracy, with each having an R2 > 70%. DT and XGboost both had an accuracy close to 80% and less prediction error. Predicting 2021 sorghum yield, XGboost, DT and RF models yielded best combination of metrics with good accuracy. Our results reveal that adding conflict occurrence probability data to the models, while complex, had minimal impact on yield predictions. Further analysis revealed cultivated land size was the most significant predictor for all the models. This paper demonstrates that despite ongoing conflict, reasonably good end-of-season sorghum yield prediction with relevant food security planning implications could be done with ML, but challenges remain in generalizing these results due to limited crop data and regional variability in South Sudan.
Similar content being viewed by others

Introduction
In South Sudan, the cultivation of sorghum plays a pivotal role in addressing food insecurity. But increasing population and conflict have imposed challenges in the agriculture sector in terms of productivity and food security. The accurate estimation of sorghum production in South Sudan emerges as a critical imperative1, Sorghum being an important staple crop in this country and the region. With challenges related to instability and decades of insecurity and field access, remote sensing and modeling represents an opportunity to turn data into insights that will enable humanitarian actors and decision-makers to make strategic plans to meet people needs and ensure people’s food security.
Humanitarian actors, government, and farmers in South Sudan will benefit from accurate yield estimates to make strategic decisions that impact both economic outcomes, food security and effective humanitarian aid. In this country, the impact of conflicts on agricultural productivity cannot be understated. The interplay between conflict probability and crop yield adds a layer of intricacy to decision-making processes2, which calls for a comprehensive approach that takes into account both the immediate challenges and ensures long-term sustainability. In this context of extensive farming systems with low inputs low outputs, climate factors emerge as crucial determinants of sorghum yield at small-scale farmers. South Sudan’s climatic conditions, characterized by high temperature variations, high variations in rainfall patterns, soil moisture, evapotranspiration exert direct influences on crop growth and development. Understanding and quantifying the influence of these climatic variables are essential for unraveling the intricate relationship between weather patterns and sorghum production. The use of traditional approaches for crop yield estimations is a time-consuming process and very risky to be conducted within volatile and unpredictable circumstances due to chronic instability and security that hinder the execution of large-scale surveys, particularly in South Sudan. In this country, existing approaches for crop yield estimation mostly rely on small scale production surveys. The need for sorghum yield prediction especially when conventional large-scale surveys cannot be conducted due to conflict and lack of access, existing limited data is of great importance3,4.
In the era of digital agriculture5, characterized by smart farming tools and technologies, the integration of advanced methodologies becomes a transformative avenue for addressing these challenges6,7. Artificial intelligence, big data analytics, cloud computing, machine learning (ML)8, and sensor technologies collectively provide a comprehensive platform for massive data collection, storage, and analysis9. Unfortunately, these technologies are far from reaching full penetration in terms of capacity building in South Sudan. ML involves the development and examination of algorithms capable of learning from data. These algorithms function by constructing models from input data and utilizing them for making predictions or decisions, rather than relying solely on explicitly programmed instructions. With minimal human intervention, ML provides enhanced decision-making support10,11. In this research work the ML algorithms used are Artificial Neural Networks (ANN), Support Vector Machines (SVM), Random Forest (RF), Extreme Gradient Boost (XGBoost), and Decision trees (DT), to predict sorghum yield in conflict setting. These ML models stand out for their ability to navigate the complexities of both linear and non-linear agricultural data12, making them invaluable for sorghum yield predictions in the South Sudanese context11,13.
However, the efficacy of ML predictions is contingent upon the quality of the input data, model representation, and the specific target variable, in this case, sorghum yield. In this study, an incremental technique is employed, commencing with soil data and progressively incorporating weather data, conflict probability, and other remotely sensed vegetation proxies factors. The aim is to assess the impact on sorghum yield predictions across five popular ML algorithms, providing a nuanced understanding of the interplay between conflict, climate, and sorghum production in South Sudan.
In summary, this research endeavors to contribute valuable insights into optimizing the prediction accuracy of sorghum yield in South Sudan. By addressing the multi-faceted challenges posed by conflict, climate factors, and the intricate dynamics of crop production, the study aspires to equip agricultural stakeholders, humanitarian actors, and government with the tools they need to make informed decisions, ensuring people’s food needs are met in the country. We adopted five ML algorithms for predicting sorghum yield, including DT, RF, XGboost, SVM and ANN14,15. Our primary goals included: (1) establishing a framework for predicting sorghum yield; (2) identifying the most effective ML algorithms for sorghum yield prediction; and (3) investigating the variations in sorghum yield prediction along with the relative significance of variables16,17.
The objective of this research is to suggest an integrated approach for predicting sorghum crop yield at the scale of small-holder farmers, considering the uncertainty in complex and diverse farming systems impacted by persistent conflict. The proposed method involves utilizing remotely sensed data, identifying optimal crop-specific yield estimators from a couple of vegetation status proxies over time, and incorporating a stochastic combination of these outcomes along with their associated uncertainties in a context of protracted conflict.
Materials and methods
Study area
Upper Nile State
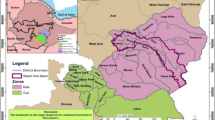
Upper Nile is one of the states (Fig. 1) in South Sudan and is positioned at coordinates 09°46′N 32°44′E, with its headquarter located in Malakal. The state comprises 13 counties and is home to an estimated population of 790,147 inhabitants, as per the South Sudan National Bureau of Statistics(NBS) population estimation survey 2021 (https://nbs.gov.ss/publication-categories/population-censuses). Spanning an area of 77,823.42 square kilometers, the region is primarily engaged in the cultivation of sorghum, wheat, millet, and sesame. These crops are grown through either rain-fed or irrigated methods. The cultivation period in this state goes from April to November, encompassing land preparation in April/May, planting in July or early August, and harvesting by November at the latest. The climate there is characterized by a unimodal rainfall season, with annual rainfall ranging from 500 mm to 650 mm with the peaks in July and August. It’s worth noting that due to security concerns, access to many parts of Upper Nile state is problematic.
Western Bahr El Ghazal State
Western Bahr El Ghazal located at 07°53′N 25°52′E is another state with Wau as its capital city (Fig. 1). It has an area of 91,079 km squared with an estimated population of 562,555 persons (NBS, 2021). The majority of this state is situated along the northern section of the Ironstone plateau, featuring red laterite soils with occasional alluvial deposits in the low-lying areas.
The region typically receives ample rainfall, providing support for more than 180 growing days conducive to cereal production. In general, crop planting is completed by mid-May when the soil moisture is good enough after 2–3 good rains to initiate the germination. Sorghum usually matures after 5 months and harvest happens in late November beginning of December. There is a general dependence on carryover seeds. Western Bahr El Gazal and Upper Nile states are two of the 14 states that form the Republic of South Sudan. In these two states, diversified crops are cultivated but Sorghum (Sorghum bicolor) is the predominant crop.

Map of South Sudan showing Upper Nile and Western Bahr El Ghazal States and the study sites.
Data sources
Remote sensing data
We collected three types of vegetation index data (VI), the normalized difference vegetation index (NDVI), the Enhanced Vegetation Index (EVI) and the Leaf Area Index (LAI) from MODIS product (Fig. 2). Extensive literature have demonstrated vegetation indexes can monitor the dynamic change of vegetation18. Currently, many studies have shown that NDVI and EVI have a good correlation with crop yield16,19 and the combination of NDVI and EVI can provide more crop information, which can efficiently be used for crop yield prediction20. In this study, we used six years (2015–2020) of remote sensing data.

Distribution of NDVI, EVI and Precipitation across Barh El GAzal and Upper Nile in South Sudan. (a) NDVI distribution Bahr El Gazal (c) EVI distribution Bahr ElGazal.
Climate and soil data
Climate variables are important drivers for crop production21,22. Extreme temperatures and droughts show adverse impacts on crops in the context of global climate change23,24. We used temperature and precipitation data from MODIS (https://lpdaac.usgs.gov/products/mod11a1v061/) product to predict sorghum yield in a context where local meteorological services are non-operational. Soil moisture (SM) data were obtained from SMAP Enhanced L3 Radiometer (https://nsidc.org/data/spl3smpe/versions/4).
Sorghum yield data
Field surveys were conducted during 4 years and self-declared post-harvest sorghum yield data (2018–2021) were collected in 15 villages of 2 states including 8 villages in Upper Nile and 7 in Western Bahr El Ghazal states. A total of 2,100 small-scale farmers were randomly selected and interviewed through a network of surveyors from within local communities. Information related to land size, yield, farmers perception of the impact of the conflict on the cultivated land size was collected. Conflict affected areas selected for interview have been mapped in 1. The average and standard deviation (SD) of the collected yield data were calculated and data were excluded and considered as outliers if they were not in the range of attainable yield plus or minus 2.5SD under South Sudan rain fed extensive low-input-low-output farming system.
Conflict data
Conflict data used in this study were downloaded from Uppsala University conflict database https://ucdp.uu.se. Uppsala is the world leading provider of data on armed conflict and organized violence. Uppsala data provide information on state- based violence, non-state violence and one-sided violence. This conflict data relies on several variables that capture the conflict history and intensity of a country. The dataset provided for download is named according to the variable that is forecasted (for example, variable armedconf3 contains data about three months ahead forecast of armed conflict). This conflict dataset contains variables such as: country isocode, year, month, text-model: the forecast probability of the text model that internal political violence(armed conflict/anyviolence) breaks out within the next 3 or 12 months, best- model(the forecast probability of the best model), period 2010 to 2021. This conflict data was confronted against ACLED data (Armed Conflict Location and Event Data - www.acleddata.com). ACLED is an NGO specialized in disaggregated conflict and violence data collection, analysis and crisis mapping. In addition, farmers’ perception of conflict and its impact on their cultivated land and sorghum production data were collected.
Ethical considerations
During field data collection, farmers who accepted to be interviewed in the frame of this research were provided with clear explanation of the objective of the study and confirmed their consent.
This study was approved by the School of Mathematics/University of Nairobi and in accordance with the submitted research protocol. Participating farmers were randomly chosen, and their consent confirmed. For anonymity and for protection purpose, names of farmers were not collected. Each questionnaire received a simple code before data were encoded in an Excel file and hard copies destroyed.
The enumerators were trained on the use of the questionnaire and importance of free participation for research purpose.
Machine learning methods for estimating sorghum yield
Decision trees (DT)
A DT model possesses a structure resembling a tree, and it predicts probable outcomes25,26, it is an effective tool for solving classification and regression problems and have been used widely in remote sensing application in agriculture. It uses a non-parametric algorithm and able to deal with large and complex datasets27,28.
Formally, a DT can be thought of as a mapping from some \(\:k\) regions of the input ___domain \(\:\:\:\:\{{R}_{1},{R}_{2},\dots\:,{R}_{k}\}\) to \(\:k\) corresponding predictions \(\:\{{w}_{1},{w}_{2},\dots\:,{w}_{k}\}\). These regions are required to partition the input ___domain, meaning that there is no intersection between any of two regions, and the union of the regions recovers the entire input ___domain. The prediction for any point in a certain region \(\:{R}_{j}\) is the same, namely \(\:{w}_{j}\)29.
This prediction \(\:f\left(x\right)\) can be expressed as follow:
Random Forest (RF)
RF which is also known for classification and regression, is a non-parametric supervised learning ensemble method25,30. It accomplishes these tasks by constructing predictive models using multiple learning algorithms. To ensure the forests are uncorrelated, the algorithm employs randomization in creating each tree. These trees, in turn, contribute to the forest’s predictive capabilities, enhancing the accuracy of decision-making31. To foster uncorrelated forests, the algorithm utilizes randomization in the construction of each tree. Subsequently, these trees employ the predictive powers of the forest to make accurate decisions32,33,34,35.
To predict sorghum yield, RF aggregates predictions across individual trees trained on independent subsets of the data34,35.
Given \(\:B\) trees and an input \(\:x\), the prediction \(\:\widehat{y}\) is given by:
where \(\:{f}_{b}\left(x\right)\) is the prediction from the \(\:b\)-th tree.
Extreme gradient boosting (XGboost)
XGboost is a powerful gradient-boosting algorithm known for its efficiency and high performance. It builds a series of weak learners sequentially and corrects errors made by previous models. It involves these major steps: (a) sequential training where a weak learner is trained on the dataset, (b) the computation of the residual between the predicted and true values, and (c) an iterative process where a new weak learner is fit to the residuals and repeat until a predefine number of trees is reached. The prediction from the ensemble is the sum of predictions from all individual trees, weighted by a learning rate36:
where \(\:\:\:\:\:F\left(x\right)\): the final ensemble prediction for an input \(\:x\), aggregating predictions from multiple models, \(\:\:\:\:\:\sum\:_{i=1}^{N}\eta\::\:t\)he summation symbol, indicating that predictions from each model \(\:{f}_{i}\left(x\right)\) are combined across \(\:N\) models, \(\:\:\:\:{f}_{i}\left(x\right)\): the prediction from the \(\:i\)-th model in the ensemble, \(\:\:\:\:\eta\:\): a weighing factor, determining the influence of each model \(\:{f}_{i}\left(x\right)\) on the overall prediction \(\:\:\:F\left(x\right)\).
Support vector machines (SVM)
SVM is a powerful supervised non-parametric algorithm for both classification and regression tasks. SVM offers various distinctive badges in handling complex multidimensional data using hyperplane. During SVM regression, the inputs is mapped to a high-dimensional feature space using a kernel function, and then a linear regression model is constructed in the new feature space to balance between minimizing errors and overfitting. In this research we used Gaussian Kernel function37,38.
The decision function for SVM can be expressed as39:
where \(\:f\left(x\right)\:\): the decision function that classifies the input \(\:x\), \(\:\text{sign}\): returns \(\:+1\) or \(\:-1\), determining the class of \(\:x\), X: The feature vector for a data point, b: the bias term, adjusting the hyperplane’s position.
Artificial neural networks (ANN)
ANN is a computational model which mimics the human nervous system. ANN is commonly applied to predict crop yield40. Similarly to the human cognitive processes, their abilities include forecasting and learning operations; learning is referred to as training41. Neural network has become a central concept in modern machine learning. A network of neurons can be constructed by linking multiple neurons together in the sense that the output of one neuron forms an input to another42,43. A simple model for such a network is the multilayer perceptron as introduced by44.
A neuron-like processing unit can be written as follow:
where the \(\:{x}_{j}\) are the inputs to the unit, the \(\:{w}_{j}\) are the weights, \(\:\:\:\:\:b\)is the bias, \(\:\:\:\:\varphi\:\)is the nonlinear activation function, and \(\:\:\:\:\alpha\:\)is the unit’s activation45.
In this research, the input layer consists of several neurons, including remotely sensed vegetation proxies, climate and soil moisture data, and conflict data.
Model evaluation
Assessment of prediction accuracy of the models on both training and testing sets were based on three common statistical metrics46: coefficient of determination R2, root mean square error RMSE, and the mean absolute error MAE.
R2 is a measure of the proportion of the variance in the dependent variable that is predictable from the independent variables. RMSE and MAE, on the other hand, quantify the average errors between predicted and actual values46. The average values of independent metrics across all models were also analyzed.
where \(\:{\:\:\:y}_{i}\)and \(\:{\widehat{y}}_{i}\) are the individual reported farmer yield and predicted yield for the study period, \(\:\:\:\:\stackrel{⃐}{y}\)is the mean yield value, \(\:\:\:\:n\)is the number of interviewed farmers.
where \(\:\:\:\:n\) is the number of observations, \(\:{\:\:\:\:y}_{i}\)is the actual value of the dependent variable for observation \(\:i\), and \(\:{\:\:\:\:\widehat{y}}_{i}\)is the predicted value of the dependent variable for observation \(\:i\).
where \(\:\:\:\:n\)is the number of observations, \(\:\:\:\:{y}_{i}\)is the actual value of the dependent variable for observation \(\:i\), and \(\:{\:\:\:\widehat{y}}_{i}\)is the predicted value of the dependent variable for observation \(\:i\).
Results
Descriptive statistics
In this section, we present a table and a figure, as shown in Fig. 4; Table 1, the variables under consideration are cultivated land size, sorghum yield, evapotranspiration, soil moisture, and precipitation, each of which plays a pivotal role in sorghum cropping.
A broad range of cultivated land and sorghum yield was observed in the two states as shown in Fig. 3. The maximum cultivated land size was 3 ha, indicating the presence of relatively larger land areas in the Upper Nile state. The mean cultivated land size in both states was approximately 0.633 ha, the standard deviation for land size was at 0.461 ha, suggesting a moderate degree of variability in cultivated land sizes across the two regions. While the sorghum yield averaged around 366.03 kg/ha with a maximum yield at 2’345 kg/ha (Fig. 4), showcasing the potential for high-yield outcomes. The standard deviation for sorghum yield was 292.29 kg/ha, indicating a considerable range of yield outcomes. Precipitation data reveals a maximum value of 10.706 mm reflecting the highest observed value, and an average of 2.517 mm. The precipitation standard deviation was of 2.463 mm reflecting the variability in regional precipitation patterns. Together, these descriptive statistics offer a comprehensive overview of the agricultural and environmental characteristics of the two states.

Sorghum yield against cultivated land in hectare.

Sorghum yield in Kg/ha across years.
Correlation
The correlation Table 2; Fig. 5, illuminate the intricate relationships among key parameters in the studied region, offering insights into the direction, strength, and statistical significance of these connections.
A strong positive correlation of 0.75 is observed between land size and sorghum yield, indicating a substantial and statistically significant association. The larger cultivated land areas tend to be the higher the sorghum yield is confirming the practice in low-input-low-output farming system. The correlation between sorghum yield and precipitation is moderate but lacks statistical significance (p = 0.103). Soil moisture and precipitation exhibit a weak positive correlation of 0.05, with a p-value of 0.297.

Correlation of variables.
Comparing training accuracy of sorghum yield on different models
In this study, five ML models were trained with the observed yields and variables of sorghum from 2018 to 2020. The evaluated results, based on the ten-fold cross-validation, were summarized according to different models and time windows in Fig. 6. Comprehensively, considering three evaluation indicators (R2, RMSE, and MAE), DT, RF, XGboost and ANN models showed high accuracy, with all having high R2 (> 0.7) indicating a significant relationship between the predicted and observed yield. DT and XGboost both had an accuracy close to 0.8. DT had the lowest RMSE (200.71 Kg/ha) while XGboost showed an RMSE of 252.75 Kg/ha. While having a good predictive accuracy (0.74) on the learning dataset, the ANN had the highest error with an RMSE (304.68 Kg/ha) compare to all the models. SVM performed slightly poor with an accuracy of 0.68 and an RMSE of 234.92 Kg/ha. Thus, XGboost, RF, and DT were more accurate for sorghum yield prediction than ANN and SVM. Moreover, we found that the training accuracy varied by time windows even with the same ML algorithm, especially for the RMSE and MAE. However, the time windows showed less impact on R2 values of XGboost, ANN, RF, and SVM. Finally, three algorithms (XGboost, RF, and DT) were selected to establish prediction models for sorghum yield.

Scores of five models of sorghum yield based on ten-fold cross-validation results in different time windows (The unit of RMSE and MAE is Kg/ha).
Sorghum yield predictions
Based on the trained models of DT, ANN, RF, SVM, and XGboost in Section “Comparing training accuracy of sorghum yield on different models”, sorghum yield in the 2 states in 2021 were predicted. The residuals of the prediction results of these models all passed the Kolmogorov-Smirnov test and obeyed normal distribution, which showed that these regression models were acceptable. The scatter diagrams of the predicted and observed yields during the training phase and on the test data for the different models are shown in Fig. 7. We found that the predicted and observed yields showed a good linear fit with R2 of about 0.5 for all the 5 models during the test phase. RF, DT and XGboost showed higher accuracy in predicting sorghum yield over 57%. Such results indicated that the three machine learning models can predict sorghum yield with quite good accuracy in following order XGboost > DT > RF. Furthermore, the prediction areas were overestimated for low yields observed with smaller deviations, while underestimated for high observed yields with relatively greater deviations.
After running the model on training and test datasets the Root Mean Square Error (RMSE) and R2 were obtained for the 5 ML models. The results revealed that, DT perform well with a low testing RMSE of 174.31 and a testing R2 of 0.573, indicating strong generalization with minimal overfitting. RF yielded similar results (RMSE = 176.27, R2 = 0.576), suggesting they capture complex patterns but provide no notable improvement over DT. XGBoost on the other hand, with the lowest testing RMSE of 171.68 and highest testing R2 of 0.586, is the most effective model, reflecting its strength in minimizing error and explaining variance in unseen data. In contrast, SVM showed weaker performance with a testing RMSE of 188.95 and the lowest R2 at 0.506, suggesting limitations in capturing the necessary non-linear patterns. ANN showed the highest testing RMSE (225.62) and a lower R2 of 0.525, indicating significant overfitting despite a complex architecture. Overall, XGBoost stands out as the most accurate model for sorghum yield prediction, balancing low error with high predictive power.

Comparison of actual yield and predicted yield on training data (DT, RF, XGB, SVM, ANN) and testing data (DT2, RF2, XGB2, SVM2, ANN2).
Impact of different models on prediction accuracy
As shown in Figs. 7 and 9, based on the RMSE and R2 metrics, XGboost emerged as the most effective model for predicting sorghum yield in 2021 agriculture season providing the best balance between prediction accuracy and explanatory power. DT and RF also showed moderate performance but were outperformed by XGboost Fig. 8. In contrast, SVM and ANN performed relatively poorly, indicating that they may require further optimization or may not be as suitable for this specific prediction task under scarcity of data.
Outperforming other models, XGboost model yielded the highest combination of best metrics with an RMSE of 171.68 kg/ha and an R2 of 58.6%. Renowned for efficiency, XGboost excels in capturing intricate relationships within the sorghum yield data, indicating its potential for accurate sorghum yield prediction. DT model had the second best competitive performance with a combination of RMSE of 174.31 kg/ha and R2 of 57.3% demonstrating effectiveness in sorghum yield predictions. RF exhibits a RMSE of 176.27 kg/ha and an R2 of 57.6%. These findings are consistent with those of47 on Maize in the Sahel region and are significant in predicting sorghum yield in South Sudan (Fig. 9).

Residuals distribution against predicted yields on the testing data.

Models sorghum yield prediction errors. RMSE and MAE values.
The variable importance of the DT, RF, and XGboost are displayed in Fig. 10. All of the models show that land size and land moisture were the most important variables in predicting sorghum yield in South Sudan. Conflict probability did not appear to be a major factor influencing sorghum yield prediction.

Top 10- variables importance for sorghum yield prediction.
The significance of a single factor cannot be evaluated in isolation from other factors (Fig. 10). From this research XGboost, DT and RF ML offer a mean to gauge the relative importance of variables in predicting sorghum yield using vegetation proxies, climatic and soil moisture parameters in a conflict affected context such as South Sudan. Results underscore the vital role of vegetation proxies such NDVI, EVI and climate data in sorghum yield prediction, aligned with prior research highlighting the significance of factors such as NDVI, precipitation, and temperature in sorghum yield prediction4,16,17,19,21,37,48,49.
Discussion
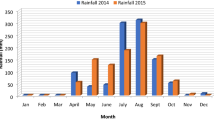
This study compares the accuracy of five popular ML models (RF, DT, XGboost, ANN and SVM) to define the influence of remotely sensed climate and vegetation indexes, cultivated land size and conflict data in sorghum yield prediction. The descriptive statistics revealed high positive correlation 0.75 (P < 0.001) between cultivated land size and sorghum yield which tends to increase with the size of cultivated land. In addition, yield data analysis reveals that there was a variation between the two states and within the different years for the period of this study. The variation between the year could be explained by several factors including differences between rainfall during the agricultural season. The rainfall data show favorable patterns in Western Bahr El Gazal than in Upper Nile state.
We found that cultivated land size is a pivotal variable and plays a substantial role in sorghum yield predictions in the context of South Sudan characterized by an extensive low-input-low-output sorghum farming system as shown in Fig. 3. This research also highlights the importance of soil moisture and inter-annual variability of rainfall in association with cultivated land size as key determinants of sorghum yield prediction as revealed by the variable importance in Fig. 10.
Several studies have compared predictive capabilities of ML models focusing on climate data and remote sensing vegetation proxies in Eastern Africa (50,51,52, during the training phase, we found that DT explained 79.9% of sorghum yield variation while XGBoost exhibited 78.2% and RF 75.8% accuracy. ANN and SVM models explained respectively 74.5% and 68.9% Fig. 7. These results are similar to50 on maize prediction using NDVI in Kenya.
On the other hand, the impact of conflict on agriculture have also been studied on different angles53,54,55,56, but this is the first time conflict data is incorporated to assess its influence on sorghum yield prediction in a context of chronic conflict with limited access and data scarcity. We find that conflict probability adds another layer of complexity to the predictive models but did not influence much the end-of-season sorghum yield prediction for 2021 agriculture season for all the models.
We concluded that the comparison between the five different ML algorithms used in this study would be useful to provide strong prediction of sorghum yield when limited crop data can be collected and combined with large, good quality, and freely available remotely sensed data about vegetation and climate information.
There are still limitations and uncertainties when it comes to the use of ML in yield prediction mainly in context of data scarcity one of which is related to lack of consistent data on different crop growth stages, as well as lack of extensive data on crop yield and which might increase uncertainty in the model performance. In addition, ML models were trained using data from specific locations and period of time and which can limit their generalization to other locations.
Conclusion
This study explored the potential for estimating sorghum yield using remotely sensed predictor variables and evaluated the performance of 5 ML models (DT, RF, XGboost, SVM and ANN). Knowing which variable affects the end-of-season sorghum yield is very important for decisions on agriculture farming practices and planning in particular in a context of chronic conflict and data scarcity. The results of Sorghum yield modeling showed that DT, XGboost and RF predicted end-of-season sorghum yield with higher accuracy on testing data compare to the other models. With respective prediction accuracy of R2 of 57%, 59%, 56.2% and lower RMSE (< 176 kg/ha) and MAE (< 105 kg/ha).
The results highlight that sorghum yield prediction accuracy was subject to variations based on factor such as cultivated land size, soil moisture and the specific algorithms employed. Additionally, regional disparities in South Sudan emerged as a significant determinant influencing sorghum yield prediction. This research confirms land size, soil moisture are key predictor variables of sorghum cropping in low-input-low-output farming system such as in South Sudan. These findings offer valuable insights for policymakers, agricultural practitioners, humanitarian actors striving to enhance food security in South Sudan.
Data availability
Datasets used and/or analyzed during the current study will be made available from the corresponding author on reasonable request. Remotely sensed data are freely available online. Precipitation data, daytime land temperature and Evapotranspiration data, NDVI, LAI all available online.
References
Dorosh, P. A., Rashid, S. & Asselt, J. Enhancing food security in South Sudan: The role of markets and regional trade. Agric. Econ. 47(6), 697–707 (2016).
Vesco, P., Kovacic, M., Mistry, M. & Croicu, M. Climate variability, crop and conflict: Exploring the impacts of spatial concentration in agricultural production. J. Peace Res. 58(1), 98–113 (2021).
Orr, A., Mwema, C., Gierend, A. & Nedumaran, S. Sorghum and millets in Eastern and Southern Africa: Facts, trends and outlook (ICRISAT, 2016).
Okeyo, S. O., Ndirangu, S. N., Isaboke, H. N. & Njeru, L. K. Determinants of sorghum productivity among small-scale farmers in Siaya County, Kenya. Afr. J. Agric. Res. 16(5), 722–731 (2020).
Klerkx, L., Jakku, E. & Labarthe, P. A review of social science on digital agriculture, smart farming and agriculture 4.0: New contributions and a future research agenda. NJAS Wagening. J. Life Sci. 90, 100315 (2019).
Wolfert, S., Ge, L., Verdouw, C. & Bogaardt, M. J. Big data in smart farming–a review. Agric. Syst. 153, 69–80 (2017).
Balakrishnan, N. & Muthukumarasamy, G. Crop production-ensemble machine learning model for prediction. Int. J. Comput. Sci. Softw. Eng. 5(7), 148 (2016).
Ngo, V. M. & Kechadi, M. T. Crop knowledge discovery based on agricultural big data integration. In: Proceedings of the 4th International Conference on Machine Learning and Soft Computing, pp. 46–50 (2020).
Chergui, N., Kechadi, M. T. & McDonnell, M. The impact of data analytics in digital agriculture: a review. In 2020 International Multi-Conference On: Organization of Knowledge and Advanced Technologies (OCTA) 1–13 (IEEE, 2020).
Cedric, L. S. et al. Crops yield prediction based on machine learning models: Case of west African countries. Smart Agric. Technol. 2, 100049 (2022).
Stas, M., Van Orshoven, J., Dong, Q., Heremans, S. & Zhang, B. A com- parison of machine learning algorithms for regional wheat yield prediction using NDVI time series of spot-vgt. In 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics) 1–5 (IEEE, 2016).
Liakos, K. G., Busato, P., Moshou, D., Pearson, S. & Bochtis, D. Machine learning in agriculture: A review. Sensors 18(8), 2674 (2018).
Crane-Droesch, A. Machine learning methods for crop yield prediction and climate change impact assessment in agriculture. Environ. Res. Lett. 13, 114003 (2018).
Gandhi, N., Armstrong, L. J., Petkar, O. & Tripathy, A. K. Rice crop yield prediction in India using support vector machines. In 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE) 1–5 (IEEE, 2016).
Dang, C., Liu, Y., Yue, H., Qian, J. & Zhu, R. Autumn crop yield prediction using data-driven approaches: Support vector machines, random forest, and deep neural network methods. Can. J. Remote. Sens. 47(2), 162–181 (2021).
Mkhabela, M. S., Bullock, P., Raj, S., Wang, S. & Yang, Y. Crop yield forecasting on the Canadian prairies using modis NDVI data. Agric. For. Meteorol. 151(3), 385–393 (2011).
Bansal, Y., Lillis, D. & Kechadi, T. Winter wheat crop yield prediction on multiple heterogeneous datasets using machine learning. In 2022 International Conference on Computational Science and Computational Intelligence (CSCI) 206–212 (IEEE, 2022).
Motohka, T., Nasahara, K. N., Oguma, H. & Tsuchida, S. Applicability of green- red vegetation index for remote sensing of vegetation phenology. Remote Sens. 2(10), 2369–2387 (2010).
Huang, J., Wang, H., Dai, Q. & Han, D. Analysis of NDVI data for crop identification and yield estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 7(11), 4374–4384 (2014).
Benos, L. et al. Machine learning in agriculture: A comprehensive updated review. Sensors 21(11), 3758 (2021).
Feng, P. et al. Impacts of rainfall extremes on wheat yield in semi-arid cropping systems in eastern Australia. Clim. Change 147, 555–569 (2018).
Challinor, A. J. et al. A meta-analysis of crop yield under climate change and adaptation. Nat. Clim. Change 4(4), 287–291 (2014).
Webber, H. et al. Diverging importance of drought stress for maize and winter wheat in Europe. Nat. Commun. 9(1), 4249 (2018).
Ummenhofer, C. C. et al. How climate change affects extremes in maize and wheat yield in two cropping regions. J. Clim. 28(12), 4653–4687 (2015).
Dietterich, T. G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems 1–15 (Springer, 2000).
Song, Y. Y. & Ying, L. U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 27(2), 130 (2015).
Gavankar, S. S. & Sawarkar, S. D. Eager decision tree. In 2017 2nd International Conference for Convergence in Technology (I2CT) 837–840 (IEEE, 2017).
Burhan, H. A. Crop yield prediction by integrating meteorological and pesticides use data with machine learning methods: An application for major crops in Turkey. Ekonomi Politika ve Finans Araştırmaları Dergis 7, 1–18 (2022).
George, S. Cs229 lecture notes: Decision trees.
Bali, N. & Singla, A. Emerging trends in machine learning to predict crop yield and study its influential factors: A survey. Arch. Comput. Methods Eng. 29(1), 95–112 (2022).
Senagi, K., Jouandeau, N. & Kamoni, P. Using parallel random forest classifier in predicting land suitability for crop production. J. Agric. Inf. 8(3) (2017).
Han, Q., Gui, C., Xu, J. & Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 226, 734–742 (2019).
Zhang, H., Zimmerman, J., Nettleton, D. & Nordman, D. J. Random forest prediction intervals. The American Statistician Online ahead of print (2019).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Wright, M. N. & Ziegler, A. Ranger: a fast implementation of random forests for high dimensional data in c++ and r. arXiv Preprint https://doi.org/10.48550/arXiv.1508.04409 (2015).
Ren, Y., Ling, F. & Wang, Y. Research on provincial-level soil moisture prediction based on extreme gradient boosting model. Agriculture 13(5), 927 (2023).
Han, J. et al. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 12(2), 236 (2020).
Cubillas, J. J., Ramos, M. I., Jurado, J. M. & Feito, F. R. A machine learning model for early prediction of crop yield, nested in a web application in the cloud: A case study in an olive grove in southern Spain. Agriculture 12(9), 1345 (2022).
Das, P., Jha, G. K., Lama, A. & Parsad, R. Crop yield prediction using hybrid machine learning approach: A case study of lentil (Lens culinaris Medik). Agriculture 13(3), 596 (2023).
Akbar, A., Kuanar, A., Patnaik, J., Mishra, A. & Nayak, S. Application of artificial neural network modeling for optimization and prediction of essential oil yield in turmeric (Curcuma longa L). Comput. Electron. Agric. 148, 160–178 (2018).
Yildirim, T., Moriasi, D. N., Starks, P. J. & Chakraborty, D. Using artificial neural network (ann) for short-range prediction of cotton yield in data-scarce regions. Agronomy 12(4), 828 (2022).
Alvarez, R. Predicting average regional yield and production of wheat in the Argentine pampas by an artificial neural network approach. Eur. J. Agron. 30(2), 70–77 (2009).
Li, A., Liang, S., Wang, A. & Qin, J. Estimating crop yield from multi-temporal satellite data using multivariate regression and neural network techniques. Photogramm. Eng. Remote Sens. 73(10), 1149–1157 (2007).
Hussain, M. M., Bari, S. H., Mahmud, I. & Siddiquee, M. I. H. Application of different artificial neural network for streamflow forecasting. In Advances in Streamflow Forecasting 149–170 (Elsevier, 2021).
Khaki, S., Pham, H. & Wang, L. Yieldnet: A Convolutional Neural Network for Simultaneous corn and Soybean Yield Prediction Based on Remote Sensing data 2020–2012 (bioRxiv, 2020).
Zhang, Y., Zhao, Z. & Zheng, J. Catboost: A new approach for estimating daily reference crop evapotranspiration in arid and semi-arid regions of northern China. J. Hydrol. 588, 125087 (2020).
Leroux, L. et al. Maize yield estimation in west africa from crop process-induced combinations of multi-___domain remote sensing indices. Eur. J. Agron. 108, 11–26 (2019).
Johnson, M. D., Hsieh, W. W., Cannon, A. J., Davidson, A. & Bédard, F. Crop yield forecasting on the Canadian prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 218, 74–84 (2016).
Saeed, U. et al. Forecasting wheat yield from weather data and modis ndvi using random forests for Punjab Province, Pakistan. Int. J. Remote Sens. 38(17), 4831–4854 (2017).
Lewis, J., Rowland, J. & Nadeau, A. Estimating maize production in Kenya using NDVI: Some statistical considerations. Int. J. Remote Sens. 19(13), 2609–2617 (1998).
Petersen, L. K. Real-time prediction of crop yields from modis relative vegetation health: A continent-wide analysis of Africa. Remote Sens. 10(11), 1726 (2018).
Mann, M. L., Warner, J. M. & Malik, A. S. Predicting high-magnitude, low- frequency crop losses using machine learning: An application to cereal crops in Ethiopia. Clim. Change 154(1), 211–227 (2019).
Sperling, L. The effects of the Rwandan war on crop production and varietal diversity: A comparison of two crops. War Crop Divers (1997).
Guhuray, F. & Ruiz, B. The effects of war on cropping systems: A study of two zones in Nicaragua. War Crop Divers 75 (1997).
Li, X. Y. et al. Civil war hinders crop production and threatens food security in Syria. Nat. Food 3(1), 38–46 (2022).
Eklund, L. et al. Societal drought vulnerability and the Syrian climate-conflict nexus are better explained by agriculture than meteorology. Commun. Earth Environ. 3(1), 85 (2022).
Acknowledgements
We would like to thank GIS colleagues and friends who contributed to download remotely sensed data and for the data treatment. The views expressed in this research paper are those of the authors and not the ICRC.
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
Conceptualization, Design, methodology, John K. and J.I.M., John N., Investigation, Field data collection, John K., Model development, validation, John K., J.I.M., John N. and V.M.,Writing original draft, John K., J.I.M., V.M., John N. All authors reviewed the manuscript.All authors have read and agreed to the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
Before interviews farmers were informed about the research and requested for their consent.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Karongo, J., Mwaniki, J.I., Ndiritu, J. et al. Sorghum yield prediction based on remote sensing and machine learning in conflict affected South Sudan. Sci Rep 15, 4469 (2025). https://doi.org/10.1038/s41598-025-89030-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-89030-z
