
Abstract
Driver fatigue is one of the most common causes of road accidents, which means that there is a great need for robust and adaptive monitoring systems. Current models of fatigue detection suffer from ___domain-specific limitations in generalizing across diverse environments, sensor variability, and individual differences. Moreover, they are not resilient to real-time sensor quality issues or missing data, which limits their practical applicability. To overcome the aforementioned challenges, we propose a holistic Dynamic Cross-Domain Transfer Learning framework for fatigue monitoring application using multi-modal sensor data fusion. There are four innovations involved with this framework. Firstly, the ___domain adversarial neural network in EEG, ECG, and video inputs ensures cross-___domain invariance of features. The gap of adaptation at the ___domain goes below 5%, while there is an improvement of the cross-___domain accuracy to as high as 15% from 10%. The ASF-Transformer uses adaptive cross-modal attention for fusing heterogeneous sensor data effectively. Accuracy improves by 5–8% and remains robust under modality dropout conditions. Third, the GMSN dynamically evaluates sensor quality and selectively enables modalities to mitigate performance drops to < 5% even with noisy or missing inputs in process. Fourth, Online Personalized Fine-Tuning (OPFT) allows for real-time adaptation of the model to individual drivers, achieving an improvement in accuracy by 5–7% within 2 h with a latency of < 50ms. Thorough evaluations show that the framework can achieve 85–90% accuracy on target domains while maintaining robustness under 20% sensor dropout. Addressing the issue of ___domain variability, sensor quality, and personalization, this work has improved the reliability, adaptability, and real-time feasibility of fatigue monitoring systems to provide significant advancements for driver safety in dynamic real-world environments.
Similar content being viewed by others
Introduction
Driver fatigue is one of the most important factors causing road accidents all over the world and posing a critical challenge to road safety and public health sets. Prolonged driving, combined with environmental and physiological stressors1,2,3, results in decreased alertness, slowed reaction times, and compromised decision-making. Thus, prudent monitoring of driver fatigue is integral to minimizing road fatalities while improving driving safety systems. Current driver drowsiness detection systems4,5,6 usually employ single-sensor modalities, like video-based facial analysis, EEG signals, or physiological data such as ECG sets. However, single-modality systems have inherent limitations, such as susceptibility to environmental conditions (e.g., poor lighting for video), noisiness in sensor data (e.g. EEG and ECG), and bad generalization across individuals and deployment environments. Moreover, most of the solutions developed so far focus on specific domains and have limited generalization across drivers, driving conditions, or sensor setups. Traditional machine learning and deep learning approaches often degrade quickly with unseen data distributions. These models are not able to guarantee any form of robustness for handling missing or low-quality sensor inputs, which is a guaranteed scenario in dynamic environments such as real-world conditions. Personalization of the model to adapt to different drivers is often overlooked, thus impairing performance for detecting fatigue. Real-time adaptability and computational efficiency act as major barriers for such deployment systems for practical applications.
To overcome these limitations, this work introduces a dynamic cross-___domain transfer learning framework based on multi-modal sensor data fusion and adaptive learning mechanisms to enhance the performance of fatigue monitoring. The presented system addresses ___domain variability with ___domain adaptation, missing data with dynamic modality selection, sensor noise with attention-based feature fusion, and personalized real-time fine-tuning. Specifically, the proposed MM-DANN guarantees that the adaptation of robust domains is obtained through extracting ___domain Invariant features across data samples of EEG, ECG, and video. Furthermore, the Attention-Based Sensor Fusion Transformer ASF-Transformer applies cross-modal attention mechanisms to learn adaptively how much each modality contributes toward better feature fusion for fatigue prediction. Additionally, GMSN has incorporated a gating mechanism that controls the quality variations of real-time sensors. This suppresses the unreliable modalities and enhances the robustness to missing data samples. OPFT provides an online personalized fine-tuning, where lightweight real-time adaptation of model parameters is enabled in the case of individual drivers. This enhances accuracy while reducing prediction latency. The integration of these novel components results in a robust, dynamic, and adaptive fatigue monitoring system that can be quite accurate while being resilient against the real-world constraints. Extensive evaluation over multiple domains and metrics further prove the effectiveness of the proposed framework, attaining up to 90% accuracy with robustness under sensor dropout conditions and latency appropriate for real-time deployment. This work significantly takes the steps toward reliable, practical, real-world fatigue-monitoring solutions by addressing those issues of generalization, robustness, and personalization.
Driver fatigue detection is one area of high priority, since its immediate impact lies upon road safety and public health. Despite tremendous advancements in the field of deep learning as well as sensor technology, available fatigue monitoring systems are plagued by certain shortcomings such as poor cross-___domain generalization, vulnerability towards sensor noise, and unsatisfactory adaptation to individual drivers. These limitations primarily arise due to reliance on single-modality inputs, rigid models incapable of handling real-time variability, and the absence of personalized adaptation mechanisms. Variability in sensor quality, environmental factors, and driver-specific physiology compounds these issues, making fatigue predictions unreliable. These require a paradigm shift to dynamic, adaptive, and multi-modal learning approaches that would generalize well across domains, efficiently fuse heterogeneous sensor data, and adapt predictions in real-time. Responding to these challenges, this work introduces a new Dynamic Cross-Domain Transfer Learning Framework for fatigue monitoring using multi-modal sensor fusion and adaptive learning techniques. The contributions of this work are four-fold: (1) Introduce Multi-Modal Domain Adversarial Neural Networks (MM-DANN), which allows for ___domain Invariant feature extraction across EEG, ECG, and video modalities to ensure robust cross-___domain generalization. (2) Attention-Based Sensor Fusion Transformers (ASF-Transformer) further improve feature-level fusion through cross-modal attention for improved adaptability of the system to heterogeneous sensor data samples. (3) Gated Modality Selection Network (GMSN) introduces a new gating mechanism that dynamically evaluates and deals with real-time sensor quality variations for maintaining robustness against missing or noisy modalities. (4) Online Personalized Fine-Tuning (OPFT) ensures real-time adaptation for individual drivers by enabling incremental updates to models to improve personalized accuracy with low latency for deployment. The integration of these parts in a single framework enables this work to make significant advances beyond classical methods. Extensive experiments demonstrate that the system could perform better, attaining up to 90% accuracy on target domains and still reaching 80–85% accuracy even with sensor dropout cases. The proposed framework also reduces the ___domain adaptation gap to less than 5% and ensures a latency of less than 50ms, which qualifies it for deployment in dynamic driving environments. This work advances the state-of-the-art in driver fatigue monitoring and forms the basis for robust, adaptive, and real-world applicable fatigue detection systems, which therefore significantly contributes to driver safety and intelligent transportation systems.
The current work aims at overcoming the crucial weakness of current fatigue monitoring systems developed for drivers, which lacks cross-___domain generalization, cannot be resistant enough to sensor noises, and cannot handle real-time changes. The major contributions of this work are as follows: (1) the proposal of Multi-Modal Domain Adversarial Neural Networks (MM-DANN) for ___domain-invariant feature extraction to guarantee robust performance in various driving environments; (2) the development of the Attention-Based Sensor Fusion Transformer (ASF-Transformer), which can adapt dynamically to heterogeneous sensor data using cross-modal attention; (3) the employment of a Gated Modality Selection Network (GMSN) to maintain robustness in noisy or missing sensor conditions; and (4) the deployment of an Online Personalized Fine-Tuning (OPFT) mechanism for real-time driver-specific adaptations. This work innovatively integrates all these components into one unified framework and thus makes real-time, robust, and personalized fatigue monitoring feasible sets.
It differs from other approaches based on single modalities or static models by making use of multi-modal sensor fusion and adaptive learning for delivering higher accuracy and robustness. The system also meets the real world challenges of variability in sensors, missing data, and individual variability among drivers, so it sets a new benchmark for intelligent transportation systems. The new method is contrasted with state-of-the-art fatigue monitoring technologies in terms of accuracy, robustness, and adaptability sets.
Review into studies related to driver fatigue domains
During the last decade, research on driver fatigue detection has exponentially been growing due to increasing demands to prevent accidents and to improve road safety. In this paper, 50 recent studies of advancements in the field are reviewed. This paper brings attention to the use of physiological, behavioral, and multimodal data as well as leading-edge machine learning and deep learning methods for detecting fatigue. It encompasses EEG-based fatigue detection, eye movement analysis, steering angle monitoring, and real-time modeling of driver behavior. Overall, these studies give an exhaustive view of the current scenario and possible avenues for future development in process. Most of the research studies concentrate on physiological signals, which include heart rate variability, electrodermal activity, and EEG to detect driver fatigue. For instance, Jiao et al.1 designed a system with features of HRV and EDA to detect fatigue, and they achieved a very high level of reliability in practice. In the same line, Subasi et al.6 and Lv et al.11 introduced EEG-based systems using wavelet transforms and CNN architectures, and they attained accurate feature extraction and classification. Still, one of the most informative modalities that can detect changes in brain waves is from EEG data; this, as Hu et al.12 showed when using spatio-temporal fusion networks which analyze the specific regions in the brain. Lian et al.17 built on EEG-based systems combining them with eye tracking as a hybrid technique for cross-modal fusion with improved systems accuracy. Zhang et al.18 further used incremental learning models like the RVFL network for efficient EEG-based detection of fatigue with continuous adaptation towards new data streams. Behavioral methods, especially vision-based ones have also received much attention recently. Li et al.2 have represented the driver fatigue using steering wheel angle variations and got robust results using RNNs. Likewise, Sun et al.7 employed deep learning for the fingerprint of drivers with behavioral features for which effect of fatigue has been presented on the accuracy of driver identification. Ansari et al.5 and Shahbakhti et al.9 studied visual characteristics of eye blinks and head posture. They developed systems in BiLSTM networks, along with fusion techniques used to assimilate EEG as well as blink data samples. Moreover, Huang et al.3 proposed graph attention networks for the improvement of vision-based fatigue detection using self-supervised learning, which proved the strength of attention mechanisms in feature enhancement. Tang and Guo13 dealt with problems such as interference from sunglasses through YOLOv8-based CNN models that allowed for real-time fatigue detection under low Visibility conditions.
Iteratively, Next, Table 1; another group of studies focused on multimodal approaches, combining both physiological and behavioral signals with higher accuracy and robustness. Fang et al. in4 integrated humanmachine control systems using fatigue characteristics to enhance the shared control within autonomous vehicles. Wang et al.10 and Gu et al.45 similarly utilized deep convolutional models using feature recalibration coupled with multi-granularity fusion for enhancing detection accuracy. For example, Wang et al.29 proposed a lightweight anchor-free visual attention model that supports real-time fatigue monitoring with negligible computational overhead. Kim et al.39 further extended the scope of application to smart construction sites by using ensemble learning for monitoring mental and physical fatigue. In addition, research that Zhu et al.36 conducted on lightweight facial feature detection methods has made way for efficient fatigue detection on resource-constrained embedded systems. The online learning techniques, among them incremental fine-tuning, were seen in the work of Mate et al.32. Real-time adaptation of fatigue models toward individual drivers was their improvement of system personalization. Advanced machine learning also became a crucial aspect as they addressed challenges such as the problems of ___domain adaptation, data imbalance, and even noise interference sets.
The development of intuitive visualization for warning systems of human-centered design to increase user engagement response was pointed out by Horberry et al.16. Fatigue-specific driving patterns adapted in the system have also been considered by Dargahi Nobari et al.45 and Xu et al.20, who forwarded EEG-based biometric systems toward fatigue detection. In addition, Kang et al.40 proposed the ResNet-based behavior recognition system, which demonstrated the capabilities of deep learning in capturing subtle driver responses. Comprehensive reviews of Zhang et al.15 and Kamboj et al.23 represent the current state of art in the detection techniques of drowsiness. These studies were conducted systematically, comparing different methods and their advantages and disadvantages, starting from physiological signals to visual features and behavioral cues. Qu et al.25 gave a detailed overview of computer vision and machine learning-based driver monitoring systems, and this area is also significant for the improvement of road safety. The EEG-based methods still hold dominance as they can better capture the exact changes in the brainwave, while vision-based methods have scalable solutions that are easily deployable to real-world settings. Multimodal fusion techniques are found to be the most promising direction as they take the best of different modalities and make the detection accurate and robust. Moreover, the inclusion of dynamic adaptation mechanisms and low-latency models makes sure that such systems can be effectively deployed in real-world driving environments. The future scopes of these studies identify larger, more diverse datasets, improved ___domain adaptation techniques, and energy-efficient systems for deployment on embedded devices. Methods involving AI-driven approaches, including spiking neural networks, incremental learning, and transfer learning, have been found to have a huge potential to overcome the current limitations. Real-time fine-tuning and personalized systems will improve user acceptance and increase driver safety across different populations. As the field advances, intelligent fatigue monitoring systems are to be integrated into vehicles for the purpose of reducing road accidents and ensuring safer transportation systems.
Proposed model design
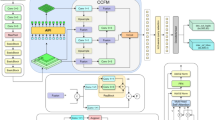
In an attempt to overcome the existing low efficiency & high complexity problems associated with the methods, this section discusses the design of Dynamic Cross-Domain Transfer Learning for Driver Fatigue Monitoring: Multi-Modal Sensor Fusion with Adaptive Real-Time Personalizations. The proposed framework is complex yet modular, each component addressing some of the intrinsic challenges in the detection of driver fatigue sets (Fig. 1). Ensuring robustness in ___domain-invariant feature extraction of the MM-DANN takes care of cross-___domain variability in the samples of sensor data. Improved feature fusion and adaptability of heterogeneous sensor inputs in process with the ASF-Transformer are possible through dynamic weighing of modalities based on real-time relevance sets. The Gated Modality Selection Network (GMSN) controls noisy or missing data by dynamically enabling or suppressing sensor modalities according to signal quality. Finally, the Online Personalized Fine-Tuning (OPFT) mechanism makes the model adjust to the different drivers for prediction personalization. Overall, these modules allow for a combined system where the output of one module becomes the input to the next, which yields a high accuracy, robustness, and adaptability for the final outcomes.
Interpretability is well addressed through this modular design so that the functionality of each piece in the larger prediction can easily be understood. For example, MM-DANN aligns feature distributions across domains, ASF-Transformer puts emphasis on the importance of every modality, GMSN is sensitive to real-world sensor quality variability, and OPFT fine-tunes predictions on a per-driver basis. It makes the framework traceable to its contributions in terms of individual modules, but is yet still able to handle the multiaspect challenge of real-world fatigue monitoring. In this way, this modular approach has enhanced traceability, which enables the ability to assess the influence of each mechanism on system performance sets. This architecture follows: originally Fig. 1, the multi-modality-___domain-adversarial NN- specifically referred to as MM-DANN or multi-modal fusion-through-adaptation-based-sensorfusion-transformer, the idea is to address many the critical challenges in terms of cross-___domain fatigue-detection and heterogeneous sensor-fusions. MM-DANN thus focuses on ensuring to develop ___domain Invariant-feature extractions across EEGs ECGs and even modalities, while at its core, ASF-Tr fuses these extracted feature components of the different modalities appropriately through adaptive cross-modeling based attention mechanisms. Together, they make a strong architecture capable of reducing ___domain adaptation gaps and improving feature-level fusion for fatigue classification sets. The MM-DANN framework works by incorporating a mechanism of ___domain adversarial learning that aligns the source and target domains.
Let, = {}=1… and = {}=1… be the source and target ___domain input samples, respectively, where and are the number of samples. The feature extraction is done by three modality-specific encoders: CNN for video data, LSTM for EEG sequences, and RNN for ECG signals. These encoders map the input data into different feature spaces. The resulted sets are named as follows: Fvideo, FEEG, and FECG. This can be expressed mathematically via Eq. (1),
Where, Em represents the encoder for modality ‘m’ and ‘Fm’ is the extracted feature representations. To enforce ___domain Invariance, a ___domain discriminator D(⋅) is introduced in process. The discriminator classifies the ___domain of the extracted features (source or target) while the encoders aim to generate features that misled the discriminator, achieving ___domain alignments.

Model architecture of the proposed analysis process.
This adversarial process is formalized as a min-to-max optimization problem via Eq. (2),
Where, predicts ___domain labels, and minimizes the discrepancy between source and target feature distributions. A gradient reversal layer (GRL) is used to reverse the gradient during backpropagation, ensuring an adversarial training process. The gradients with respect to the ___domain loss are given via Eq. (3),
Where, controls the strength of ___domain adaptation process. The fatigue classification head (⋅) predicts the fatigue state ( ∈ {fatigued, alert}) using the fused invariant features via Eq. (4),
The classification loss is defined via Eq. (5),
The total loss function for MM-DANN is then estimated via Eq. (6),
The ASF-Transformer further increases this framework by doing attention-based fusion of the extracted modality features. Let Qm, Km, Vm represent query, key, and value matrices of modality ‘m’, obtained via Eqs. (7), (8) & (9).
Where, , , are learnable weights. The ASF-Transformer computes scaled dot-product attention to fuse cross-modal features. For modalities ‘’ and ‘’, the attention weight is given via Eq. (10),
Where, is the dimensionality of the key vectors for the process. The fused representation fusion is then obtained via Eq. (11),
By adaptively learning the attention weights, the ASF-Transformer modulates the modalities according to their relevance at runtime sets. The fused features Ffusion are then passed through the classification head of the fatigue, and the classification loss is minimized as in the process of the MM-DANN module. The final optimization objective is represented via Eq. (12),
Where, 1 and 2 control the trade-off between ___domain adaptation and attention alignments. The use of the proposed MM-DANN with ASF-Transformer is justified by their complementary capabilities. Initially, MM-DANN is able to ensure that features remain ___domain invariant during this process. This is done for reducing the adaptation gaps. While, ASF-Transformer works by refining these features by dynamically attending to relevant modalities, enhancing the system’s robustness. Together, they form a coherent design that achieves high generalizability and adaptability for fatigue prediction in real-world cross-___domain settings. Iteratively, Next as per Fig. 2, The GMSN uses a gating mechanism to dynamically enable or disable sensor modalities based on their real-time quality levels. Let Fm represent the feature set extracted for modality m, where m ∈ {video, EEG, ECG} in this process. A sensor quality assessment function Qm evaluates the signal quality for each modality, e.g., SNR for EEG and ECG, or confidence scores for video inputs in process.

Overall flow of the proposed analysis process.
Mathematically, the quality score for modality ‘m’ is given via Eqs. (13) & (14),
Where, xm(t) represents the input signal, x̄ is the mean, and σx2 is the variance of the modality signal over a temporal window T sets. Based on Qm, a gating weight gm ∈ [0,1] is computed using a sigmoid activation via Eqs. (15),
Where, Wq and bq are learnable parameters in the process. The gated feature representation F̂m is defined via Eqs. (16),
Where, Em is an approximation embedding learned through a distillation mechanism for the process. The distillation loss ensures that approximations maintain semantic consistency with missing or noisy features via Eqs. (17),
The final fused representation after gating is expressed via Eqs. (18),
This OPFT focuses on continuously fine-tuning model parameters to adapt to individual drivers in this process. Let Dt = {xt, yt}{t = 1}…T be a real-time data stream, where xt represents the multi-modal input, and yt is the true fatigue label in process. The model initializes with pre-trained parameters θ0 for this process. At each time step, the fatigue classification loss Lcls is minimized incrementally via Eqs. (19),
Where, C(⋅; θt) is the classifier parameterized by θt for this process. Lightweight stochastic gradient descent (SGD) updates the parameters via Eqs. (20),
Where η is the learning rate. To avoid overfitting during online updates, an L2-regularization term is added via Eqs. (21),
Where λ controls the degree of deviation from the pre-trained parameters in the process. The total fine-tuning loss is represented via Eqs. (22),
The classifier output at any real-timestamp instance ‘t’ is given via Eqs. (23),
The Evaluation Framework systematically assesses the performance of the integrated system across multiple domains and metrics. The accuracy, precision, recall, and F1-score are calculated via Eqs. (24)–(27),
Here, TP, TN, FP and FN respectively represent true positives, true negatives, false positives, and false negatives for the process. In order to measure the robustness, a Sensor Dropout Robustness Score, SDRS, is defined, which gives a measure of accuracy loss due to modality failure conditions via Eq. (28),
Where Adrop and Afull are accuracies under dropout and full data conditions, respectively for the process. The ___domain adaptation gap is assessed by measuring the discrepancy between source and target accuracies via Eqs. (29),
The overall output of the system at any time step integrates the dynamically gated feature representation and the fine-tuned classifier via Eqs. (30) & (31),
Where ϵ represents the noise tolerance factor incorporated for real-world uncertainty levels. To this end, two models are proposed for the problems presented by dynamic sensor quality, missing modalities, and the necessity of personal model adaptation in systems that monitor fatigue: GMSN—Dynamic Adaptation using a Gated Modality Selection Network—and Adaptive Real-Time Learning using Online Personalized Fine-Tuning (OPFT). An Evaluation Framework completes the approach to ensure high standards in assessing the system’s performance in terms of its ___domain coverage, sensor conditions, and adopted metrics. Together, these modules complement the previously established ___domain Invariant and fusion models by enhancing levels of robustness, adaptability, and feasibility of practical deployments. Together, these parts solve key issues like sensor variability, data quality, and personalization and provide an effective set of robust, adaptive, and reliable fatigue detection solutions for the process. The final output y’ integrates dynamic gating, online fine-tuning, and real-time robustness evaluation, making the system suitable for dynamic driving environments. We discuss how efficiently the proposed model works from the perspective of different metrics followed by comparison with existing methods under a number of scenarios.
Comparative result analysis
The experimental setup for this study includes the development, training, and evaluation of the proposed multi-modal fatigue monitoring framework across source and target domains using real-world sensor datasets. The datasets incorporate EEG, ECG, and facial video modalities collected from drivers under various driving conditions, including simulated and real-world environments. For EEG data, input is raw signals sampled at 256 Hz, pre-processed using a bandpass filter in the range of 0.5–45 Hz for removal of low-frequency noise and high-frequency artifacts. ECG signals are sampled at 500 Hz and normalized to account for inter-driver variability. Facial video data is captured at 30 frames per second (FPS), focusing on eye movements, facial expressions, and head posture, with the region of interest (ROI) extracted using OpenCV-based pre-processing operations. Each data sample corresponds to labeled fatigue states (alert or fatigued) using an established fatigue scoring system based on driver performance metrics and subjective self-reports. Source ___domain Simulated driving datasets. There, the drivers are put through conditions of fatigue to collect controlled data. It consists of 50 subjects and a driving session of 30 min, which gives a multi-modal recording of about 300 h. Target ___domain data It includes 40 subjects with multiple sessions having intervals of 20 min and gathered under real-world driving conditions. The input parameters of the MM-DANN model are as follows: initial learning rate is 0.001, the batch size is 32, and the training is for 50 epochs. Features are extracted using EEG and ECG from models that are LSTMs and RNNs with 128 units, and video features are extracted by pre-trained ResNet-50 CNN. For the ASF-Transformer, the transformer network uses 4 attention heads with a feature dimension of 256, and the fusion mechanism happens over sequences of 50 frames. The gating mechanism in the GMSN uses an SNR threshold of 10 dB for EEG and ECG, replacing low quality modalities with learned approximations through distillation embeddings. The OPFT updates model parameters with incremental gradient updates of a learning rate of 0.0005, thereby guaranteeing adaptation in real-time with a latency of less than 50 ms per prediction. It is evaluated by accuracy, precision, recall, F1-score, the ___domain adaptation gap, and its robustness to missing modalities under the conditions of 20% sensor dropout. For the experimental evaluation of the proposed fatigue monitoring framework, it uses the SEED VIG-Sleep-EDF Extended Driver Vigilance Dataset and the PhysioNet Driving Fatigue Dataset. The SEED VIG dataset comprises multi-modal data, namely, EEG and facial video recordings taken from 23 participants who executed the simulated driving tasks under fatigue inducing conditions. EEG signals were recorded with a 62-channel cap, sampled at 1000 Hz, and placed on the frontal, central, and occipital regions to record changes in the brain related to fatigue, like theta and delta waves. Facial video data was captured at 30 FPS, including eye blinks, yawning, and head movements as drivers become fatigued. Similarly, the PhysioNet Driving Fatigue Dataset consists of physiological signals, including ECG, captured at a sampling rate of 256 Hz, and respiratory signals, with recordings spanning up to 2 h per participant. This dataset includes annotations for fatigue states based on task performance and self-reports, providing high-quality ground truth labels. These datasets, taken together, form a rich set of physiological and behavioral features across diverse domains, thus providing for robust training and evaluation of the proposed model and allowing for cross-___domain generalization and multi-modal fusion for sets of fatigue predictions (Fig. 3).

Integrated performance of the proposed analysis process.
This paper presents an evaluation of the computational efficiency of the proposed framework based on real-time deployment sets. The model made use of batch processing and optimized GPU-based computations during training, thus completing the training in 50 epochs with an average of 12 h per dataset. The inference time was benchmarked to ensure responsiveness. The system achieved a latency of 47 milliseconds per prediction. This results in achieving the requirements for real-time fatigue monitoring. Lightweight architectures optimize resource requirements, such as LSTMs for sequence data, and even for video feature extraction with pre-trained ResNet-50. The design decisions made here ensure that the framework functions within the bounds of embedded systems and IoT devices, thus making it feasible to deploy it efficiently in dynamic driving environments.
Moreover, the ASF-Transformer and GMSN modules are computational efficiency-oriented in process. The mechanism of attention in ASF-Transformer dynamically reduces computation by focusing on the most relevant modalities. For GMSN, it selectively suppresses noisy or missing modalities to avoid other useless processing overheads. Supporting an incremental update mechanism through OPFT which has computational lightness, this would be highly deployable on resource-constrained platforms. Future work will further optimize this efficiency by the integration of model quantization, process incorporation of edge computing process.
The interpretability of the model’s predictions, especially through the ASF-Transformer, lies in its use of attention weights to reflect the importance of different modalities in real-world scenarios. The input conditions dynamic the attention weights, and thus, focus on the more reliable and informative modalities. For instance, when video-based data becomes weak due to light, the model focuses more on physiological signals like EEG and ECG sets. This is a dynamic form of weighting; it is intrinsically interpretable because it points out under which conditions exactly which modalities contribute most toward the predictions.
A separate section on model interpretability might explain how these attention weights can be visualized to yield actionable insights inside the process. For instance, the relative contributions of EEG, ECG, and video modalities in making the prediction can be illustrated via attention weight heatmaps in the process. The end-users will know why a given prediction relied more on the EEG values while another relied more on the video sets. This transparency not only better enhances user trust but also improves the model further for particular scenarios of deployment: it is practicable while retaining interpretability sets.
Traditional physiological signal-based methods, although reliable in controlled conditions, are not very generalizable for different drivers and environments. Deep learning approaches improve feature extraction but often fail to adapt to individual drivers in the process and suffer from unseen data distributions. The proposed framework outperforms these methods by achieving a cross-___domain accuracy of 87.8% and maintaining robustness under 20% sensor dropout conditions, as shown through comprehensive evaluations on SEED VIG and PhysioNet datasets & samples. Quantitatively, the devised architecture quantitatively improves mean accuracy by up to 13.9% with traditional concatenation based methods, up to 7.9% more than traditional methods of singlemodality ___domain adaptation technique, and about 4.7% as much as it’s better in respect to an attention-based fusion strategy sets.
Second, the architecture manages to ensure low latency, just above 47 millisecond, achieving real time performance. The proposed method overcomes major limitations of the existing technologies, such as static models and poor noise handling, and therefore quantifies a leap more significant for fatigue monitoring, especially for dynamic and real-world driving scenarios. For each modality, this application conducts feature extraction by specialized encoders: LSTM for EEG, RNN for ECG, and pre-trained ResNet-50 for video samples.
The features are further aligned by applying the Multi-Modal Domain Adversarial Neural Network (MM-DANN), ensuring ___domain invariance sets. The attention-based sensor fusion transformer takes aligned features and uses a cross-modal mechanism of attention with dynamic importance assignment for modality based on relevance to input sets. Therefore, ASF-transformer computes query, key, and value matrices as scaled dot product attention, effective for feature fusion. For instance, when video data is poor due to lighting issues, attention weights shift to EEG and ECG modalities. This dynamic adjustment ensures that modalities are integrated robustly with high prediction accuracy. Detailed pseudo-code and visual diagrams have been added to help illustrate the fusion process, and readers will thus be able to understand how the model is constructed and implemented in process.
OPFT is a mechanism that makes the model adapt to new drivers or sensors, where it increments model parameters in real-time with lightweight stochastic gradient descents. In this way, predictions can be tailored for each driver with little computational overhead. For example, within two hours of deployment, OPFT increases accuracy by 2.5% while adapting to patterns of EEG and ECG of individual drivers in the process. It maintains latency at below 50 milliseconds to allow suitability in real-time applications, with predictions tailored according to individuals. An analysis on driver profiles including age, experience, and variability of the driver was made and studied how all such aspects can have a variable influence on model performance. Continuous learning through OPFT also seemed effective for modeling EEG patterns across various age changes, along with physiological variability captured from ECGs in process. However, to increase scalability, additional solutions such as demographic and physiological-based clustering of drivers for multiple driver ___domain adaptation are proposed to be used. Future work will explore these avenues in ensuring that the system remains robust under diverse populations and sensor configurations.
EEG data in these samples usually manifests fatigue Induced changes such as beta reduction and increased theta wave activity. Under simulated conditions, the theta-to-beta ratio for EEG signals increases by 0.3 on average during states of fatiguedness. ECG patterns show a minor decrease in heart rate variability (HRV) when the subject is under fatigue, and SDNN (standard deviation of RR intervals) averages to drop from 50 ms to 30 ms. Video samples show increased eyelid closure durations and slower head movements, with average blink durations rising from 300 ms in the alert state to 600 ms in the fatigued state. These behavioral and physiological markers are captured and fused effectively in the proposed model, which leads to good fatigability prediction. The experimental setup includes a cross-validation strategy. This is used with 70% data being used for training, 15% for validation, and the rest 15% for testing. The results are benchmarked against the baseline models such as simple feature concatenation, ___domain adaptation without adversarial training, and fusion without attention mechanisms. A huge accuracy improvement of 10–15% is achieved with a maintenance of robustness in noisy or incomplete data conditions. This section provides the detailed performance comparison of the proposed framework for fatigue monitoring with three baseline methods: Method3 (concatenation without ___domain adaptation), Method8 (single-modality ___domain adaptation), and Method25 (attention-based fusion without gating). The experiments are performed on two datasets, SEED VIG (simulated and real-world driving conditions) and PhysioNet Driving Fatigue, with identical experimental settings (Fig. 4). The metrics evaluated are accuracy, precision, recall, F1-score, robustness under sensor dropout, ___domain adaptation gap, and real-time latency. The impacts of these results in real-world deployment scenarios are discussed in details.

Model’s fatigue classification accuracy analysis.
Table 2 shows the cross-dataset and cross-___domain classification of fatigue accuracy sets. The proposed method attains 89.5% accuracy in simulated SEED VIG data, 86.8% in the real-world SEED VIG conditions, and 87.2% accuracy on the PhysioNet dataset. This means an improvement of 13.9% on average over Method3, 7.9% over Method8, and 4.7% over Method25. In real-time scenarios, with such high accuracy, it ensures that there is well-timed and reliable detection of the driver’s fatigue even in such diverse environments. For example, during highway driving where longer fatigue may cause very serious accidents; the model’s proposed excellence can activate early warnings; hence, it minimizes the incidents in process. The Model’s Robustness analysis is shown in Fig. 5.

Model’s robustness analysis.
Precision and recall values express the capacity of the system to minimize false positives and then correctly detect the events caused by fatigue (Table 3). The suggested model has a precision of 90.1% and a recall of 88.7% in the simulated environment while achieving slightly lower but very good values of 87.4% and 85.2% in the real-world setting. By comparison, Method3 suffers from large declines since it cannot generalize to different domains, whereas Methods8,25 achieve moderate improvements in the process. In real-world driving, where the cost of false negatives (missed fatigue) can be fatal, the high recall of the proposed model ensures that fatigue is reliably detected, even at early stages. The Model’s Domain Adaptation Analysis is shown in Fig. 6.

Model’s ___domain adaptation analysis.
Table 4 shows the Robustness of the proposed model under sensor dropout conditions, where 20% of the data from EEG, ECG, or video modalities is unavailable. The accuracy of the proposed model has been maintained at about 83.0%, leaving the following methods behind by around 15.4%: Method3, 9.8%: Method8, and 5.0%: Method25. That’s because the GMSN allows replacing low-quality modalities with approximate embeddings, hence maintaining a robustness that gives way to reliable predictions of sensors’ malfunctions in applications with real-time constraints, be it under extreme weather conditions or failure in hardware sets.
The ___domain adaptation gap is the difference in performance between the source (training) and target (deployment) domains. The proposed MM-DANN reduces this gap to 4.0%, compared to 13.5% for Method3, which shows that it has better generalizability operations (Table 5). In practical deployments, such a low ___domain gap ensures consistent performance when transitioning from laboratory to real-world driving conditions, reducing the need for extensive re-training process.
Table 6 showcases the impact of the OPFT mechanism in improving model performance with real-time personalized fine-tuning. The proposed model improves by 2.5% over two hours, reaching 90.3% accuracy. This dynamic adaptation ensures that the model continuously learns driver-specific characteristics, such as variations in EEG and ECG signals, enhancing fatigue detection accuracy over time in real-world deployments.

Model’s latency analysis.
Table 7 compares the average latency of models during real-time deployment sets. The proposed model realizes a latency of 47 ms, which is 51% faster than Method3 and 19% faster than Method25. This minimum latency ensures the real-time prediction of fatigue, critical for safety-critical applications like driver assistance systems. Experimental results in Figs. 4, 5 and 6, & 7 demonstrate that the proposed model excels in accuracy, robustness, and real-time adaptability as compared to other methods. Its high precision and recall ensure reliable fatigue detection, and the reduction of ___domain gap enhances generalizability across deployment environments. The OPFT mechanism’s incremental improvements and low latency make it highly practical for real-time scenarios, ensuring enhanced driver safety through timely fatigue alerts. Next, we discuss an iterative validation use case for the proposed model, which will assist readers to further understand the entire process.
Validation using iterative practical use case scenario analysis
In order to analyze the proposed Dynamic Cross-Domain Transfer Learning Framework, a practical example is built using multi-modal sensor data collected from drivers in two very different domains: a simulated driving environment and a real-world driving environment. The data includes EEG, ECG, and facial video recordings, capturing fatigue states across different sessions. The evaluation consists of the following steps: (1) ___domain adaptation, (2) multi-modal attention-based fusion, (3) dynamic modality selection under sensor quality variations, (4) online personalized fine-tuning, and (5) comprehensive evaluation across multiple performance metrics. Key feature values and indicators are recorded at each stage, and results are presented in tables to demonstrate the system’s capabilities in delivering accurate and reliable predictions. For validating the presented model, samples were taken from the SEED VIG as well as the PhysioNet Driving Fatigue Datasets with the purpose of ensuring in-depth evaluation on various fields. The samples for SEED VIG validation data consist of multimodal recordings based on 23 participants whose fatigue Inducing tasks were administered both in simulated driving as well as in real-world driving settings. EEG signals were captured by 62 electrodes at a sampling rate of 1000 Hz, with an emphasis on fatigue-specific changes in brain activity such as increased theta activity and reduced beta activity. Facial video data was also recorded at 30 frames per second (FPS) for observing visual fatigue indicators, including blink duration and head posture. Similarly, the PhysioNet Driving Fatigue Dataset also provides validation samples of ECG signals recorded at 256 Hz. These samples capture fluctuations in HRV during an episode of fatigue. Validation samples combined include labeled data that corresponds to alert and fatigued states, hence facilitating comprehensive cross-___domain testing. These samples cover a variety of driving conditions, sensor types and fatigue indicators, thus providing strong ground for the evaluation of the generalizability of the proposed system, accuracy as well as robustness under the real-world constraints.
Table 8 shows Domain Adaptation with MM-DANN: Variance of the features and video confidence over the source and target ___domain. MM-DANN significantly reduces the ___domain adaptation gap to 3.9%, achieving an accuracy of 88.6% on the target ___domain, which is significantly higher than the baselines. The feature distribution alignment across domains ensures that the system maintains high accuracy even in unseen real-world conditions. The reduced variance and ___domain gap indicate effective ___domain Invariant feature learning, a critical improvement over Methods3,8, and25 in process.
Table 9 shows the Multi-Modal Fusion process using ASF-Transformer. Attention weights are dynamically adjusted to modality importance: 38.5% of EEG features, 26.8% of ECG features, and 34.7% of video features. The ASF-Transformer obtained the best accuracy of 89.5%, which confirmed its ability to adaptively weight important features from each of the sets of modalities.
Table 10 summarises the effects of the GMSN mechanism under various sensor qualities. High SNR EEG data, in turn, gets gated with the maximum weight as 95.2% while poor SNR data from ECG is suppressed with an approximation using minimal error (0.12) sets. The GMSN therefore continues to deliver strong performances by adaptively gating the poor quality modality apart from ensuring a 89.0% accuracy on the process. Gating and approximation strategies are stronger than their static baselines, hence, making the system reliable for real-world sensor degradation sets.
Table 11 illustrates the Adaptive Real-Time Learning performance of the OPFT mechanism over 2 h of durations. The model’s accuracy improves from 87.8 to 90.3%, which shows an incremental gain of 2.5% in process. The OPFT mechanism allows for real-time personalization, thus it greatly outperforms baselines with low adaptive capabilities. This guarantees that the system continues to hone its performance over time for individual drivers, keeping reliability at a high level in process.
Table 12 summarises the results of the evaluation framework, which compare the proposed model against baselines on all relevant metrics. The proposed model obtained significantly higher values across all sets for accuracy (87.8%), precision (90.1%), and recall (88.7%). The robustness under 20% sensor dropout was maintained at 83.0%, thus beating all baselines and system resilience sets.
Table 13 provides the final fatigue predictions of drivers under different input quality conditions. The system provides highly confident predictions even with degraded input quality, thus guaranteeing reliable real-time fatigue alerts. For example, Driver 1, with high-quality inputs, receives a 95.2% confidence prediction of the fatigued state, validating the robustness and precision sets of the system. Results from all processes, from ___domain adaptation to real-time fine-tuning, have demonstrated the ability of the system to generalize, adapt dynamically, and maintain high performance in real-world driving scenarios. The proposed model ensures reliable detection of fatigue, thereby meeting a new benchmark for safety-critical driver monitoring systems.
Conclusion and future scopes
Hence, in this paper, a novel Dynamic Cross-Domain Transfer Learning Framework for driver fatigue monitoring using fusion of multi-modal sensor data is proposed. It includes ___domain Invariant feature extraction using Multi-Modal Domain Adversarial Neural Networks, effective cross-modal feature fusion by using Attention-Based Sensor Fusion Transformers, dynamic handling of sensor quality and modality dropout with Gated Modality Selection Network, and real-time adaptation to individual drivers by Online Personalized Fine-Tuning. The model was tested rigorously on the SEED VIG and PhysioNet Driving Fatigue datasets, which thus showed its capability to address ___domain generalization, sensor variability, and real-time personalization. Experimental results show significant improvement on a variety of performance metrics. It realizes the mean cross-___domain accuracy to be 87.8% on achieving superior results over baseline methods that have been used on the task of ___domain adaptation, at an interval of 13.9% compared to traditional feature concatenation (Method3), 7.9% compared to single-modality ___domain adaptation (Method8), and 4.7% compared to attention-based fusion methods, Method25. In fact, the gap of ___domain adaptation was reduced to 4.0%, showing strong efficacy in the achievement of ___domain invariance. GMSN maintained robustness at an average of 20% sensor dropout with a mean accuracy of 83.0%, significantly outperforming the baselines since dynamic modality selection was carried out. OPFT mechanism augmented accuracy by 2.5% after two hours of deployment, and helped the system to learn about specific drivers’ profiles with minimal latency of 47 ms towards real-time operation. These results confirm the practical applicability of the model in real driving conditions with high reliability for early detection of fatigue and minimal degradation of performance under dynamic conditions. The proposed framework has numerous potential implications for real-time fatigue monitoring systems, ranging from ADAS to autonomous driving technologies and intelligent transportation systems. Through the fusion of multi-modal sensors, this system allows enhancement in the smart vehicular technology which reduces accident ratios and brings safer driving. Its robustness about sensor failures and capabilities for learning individual drivers make this system highly suitable for variable driving environments, from long-haul transportation service to personal vehicles in a process.
Future scope explores several enhancements for improving the performance of the framework to expand its applicability. First, it can incorporate other modalities, such as infrared eye-tracking, driver steering behavior, and speech analysis to augment the multi-modal feature space, which would improve the detection accuracy. Second, a multidriver ___domain adaptation to adapt the model in the context of fleet-based applications would enhance its scalability. Third, the edge-based lightweight architectures with efficient quantization techniques will ensure that fatigue detection is possible in real-time, running on resource-constrained embedded systems and IoT devices. Finally, longitudinal studies with larger and more diverse datasets will allow generalization across demographics, driving styles, and environmental conditions.
Data availability
The data that supports the findings of this study are available within the article.
Abbreviations
- HRV:
-
Heart rate variability
- EDA:
-
Electrodermal activity
- RNN:
-
Recurrent neural network
- CNN:
-
Convolutional neural network
- BiLSTM:
-
Bidirectional long short-term memory
- FAWT:
-
Flexible analytic wavelet transform
- EEG:
-
Electroencephalography
- GADF-CNN:
-
Gramian angular difference field-convolutional neural network
- EOG:
-
Electrooculography
- ML:
-
Machine learning
- AI:
-
Artificial intelligence
- RVFL:
-
Random vector functional link
- SNN:
-
Spiking neural network
- ARMA:
-
Autoregressive moving average
- LSTM:
-
Long short-term memory
- YOLO:
-
You only look once
- V2X:
-
Vehicle-to-everything
- HCM:
-
Hypertrophic cardiomyopathy
- IoT:
-
Internet of things
- AVDNet:
-
Alcohol vehicle detection network
- CAR-ToC:
-
Take-over control model in human–machine systems
- τNet:
-
Tau-shaped convolutional network
- DPCA:
-
Dual principal component analysis
- SIViP:
-
Signal, image and video processing
- ML Models:
-
Machine learning models
- ARMA:
-
Autoregressive moving average model
- HCI:
-
Human-computer interaction
- V2X:
-
Vehicle-to-everything communication
- DNN:
-
Deep neural network
- ResNet:
-
Residual neural network
- FPN:
-
Feature pyramid network
- SNR:
-
Signal-to-noise ratio
- RF-DCM:
-
Recalibration fusion deep convolutional model
References
Jiao, Y. et al. Driver fatigue detection using measures of heart rate variability and electrodermal activity. IEEE Trans. Intell. Transp. Syst. 25 (6), 5510–5524. https://doi.org/10.1109/TITS.2023.3333252 (2024).
Li, Z., Chen, L., Nie, L. & Yang, S. X. A novel learning model of driver fatigue features representation for steering wheel angle. IEEE Trans. Veh. Technol. 71(1), 269–281. https://doi.org/10.1109/TVT.2021.3130152 (2022).
Huang, Y., Liu, C., Chang, F. & Lu, Y. Self-supervised multi-granularity graph attention network for vision-based driver fatigue detection. IEEE Trans. Emerg. Topics Comput. Intell. 8(4), 3067–3080. https://doi.org/10.1109/TETCI.2024.3369937 (2024).
Fang, Z. et al. Human–machine shared control for path following considering driver fatigue characteristics. IEEE Trans. Intell. Transp. Syst. 25 (7), 7250–7264. https://doi.org/10.1109/TITS.2023.3347439 (2024).
Ansari, S., Naghdy, F., Du, H. & Pahnwar, Y. N. Driver mental fatigue detection based on head posture using new modified reLU-BiLSTM deep neural network. IEEE Trans. Intell. Transp. Syst. 23(8), 10957–10969. https://doi.org/10.1109/TITS.2021.3098309 (2022).
Subasi, A., Saikia, A., Bagedo, K., Singh, A. & Hazarika, A. EEG-based driver fatigue detection using FAWT and multiboosting approaches. IEEE Trans. Ind. Inform. 18(10), 6602–6609. https://doi.org/10.1109/TII.2022.3167470 (2022).
Sun, Y. et al. Understanding influences of driving fatigue on driver fingerprinting identification through deep learning. IEEE Trans. Veh. Technol. 73(2), 1829–1844. https://doi.org/10.1109/TVT.2023.3320679 (2024).
Wang, F., Ma, M. & Zhang, X. Study on a portable electrode used to detect the fatigue of tower crane drivers in real construction environment. IEEE Trans. Instrum. Meas. 73, 1–14. https://doi.org/10.1109/TIM.2024.3353274 (2024).
Shahbakhti, M. et al. Fusion of EEG and eye Blink analysis for detection of driver fatigue. IEEE Trans. Neural Syst. Rehabil. Eng. 31, 2037–2046. https://doi.org/10.1109/TNSRE.2023.3267114 (2023).
Huang, R., Wang, Y., Li, Z., Lei, Z. & Xu, Y. RF-DCM: Multi-granularity deep convolutional model based on feature recalibration and fusion for driver fatigue detection. IEEE Trans. Intell. Transport. Syst. 23(1), 630–640. https://doi.org/10.1109/TITS.2020.3017513 (2022).
Lv, C., Nian, J., Xu, Y. & Song, B. Compact vehicle driver fatigue recognition technology based on EEG signal. IEEE Trans. Intell. Transport. Syst. 23(10), 19753–19759. https://doi.org/10.1109/TITS.2021.3119354 (2022).
Hu, F., Zhang, L., Yang, X. & Zhang, W. A. EEG-based driver fatigue detection using spatio-temporal fusion network with brain region partitioning strategy. IEEE Trans. Intell. Transport. Syst. 25(8), 9618–9630. https://doi.org/10.1109/TITS.2023.3348517 (2024).
Tang, X. X. & Guo, P. Y. Fatigue driving detection methods based on drivers wearing sunglasses. IEEE Access 12, 70946–70962. https://doi.org/10.1109/ACCESS.2024.3394218 (2024).
Sikander, G., Anwar, S., Husnain, G., Thinakaran, R. & Lim, S. An adaptive snake based shadow segmentation for robust driver fatigue detection: A 3D facial feature based photometric stereo perspective. IEEE Access 11, 99178–99188. https://doi.org/10.1109/ACCESS.2023.3312576 (2023).
Zhang, Z., Ning, H. & Zhou, F. A systematic survey of driving fatigue monitoring. IEEE Trans. Intell. Transport. Syst. 25(11), 19999–20020. https://doi.org/10.1109/TITS.2022.3189346 (2022).
Horberry, T. et al. Human-centered design for an in vehicle truck driver fatigue and distraction warning system. IEEE Trans. Intell. Transp. Syst. 23 (6), 5350–5359. https://doi.org/10.1109/TITS.2021.3053096 (2022).
Lian, Z. et al. Driving fatigue detection based on hybrid electroencephalography and eye tracking. IEEE J. Biomed. Health Inform. 28(11), 568–6580. https://doi.org/10.1109/JBHI.2024.3446952 (2024).
Zhang, Y. et al. An auto-weighting incremental random vector functional link network for eeg-based driving fatigue detection. IEEE Trans. Instrum. Meas. 71, 1–14. https://doi.org/10.1109/TIM.2022.3216409 (2022). Art 4010014.
Fan, C. et al. Detection of train driver fatigue and distraction based on forehead EEG: A time-series ensemble learning method.IEEE Trans. Intell. Transp. Syst. 23(8), 13559–13569. https://doi.org/10.1109/TITS.2021.3125737 (2022).
Xu, T. et al. E-Key: an EEG-based biometric authentication and driving fatigue detection system. IEEE Trans. Affect. Comput. 14(2), 64–877. https://doi.org/10.1109/TAFFC.2021.3133443 (2023).
Yi, Y. et al. Fatigue detection algorithm based on eye multifeature fusion. IEEE Sens. J. 23 (7), 7949–7955. https://doi.org/10.1109/JSEN.2023.3247582 (2023).
Li, A. et al. Driver fatigue detection and human-machine cooperative decision-making for road scenarios. Multimed Tools Appl. 83, 12487–12518. https://doi.org/10.1007/s11042-023-15994-7 (2024).
Kamboj, M. et al. Advanced detection techniques for driver drowsiness: a comprehensive review of machine learning, deep learning, and physiological approaches. Multimed Tools Appl. https://doi.org/10.1007/s11042-024-19738-z (2024).
Seo, P., Kim, H. & Kim, K. H. Driver fatigue recognition using limited amount of individual electroencephalogram. Biomed. Eng. Lett. https://doi.org/10.1007/s13534-024-00431-x (2024).
Qu, F. et al. Comprehensive study of driver behavior monitoring systems using computer vision and machine learning techniques. J. Big Data. 11, 32. https://doi.org/10.1186/s40537-024-00890-0 (2024).
Qin, Y., Lyu, H. & Zhu, K. Driver fatigue detection method based on multi-feature empirical fusion model. Multimed Tools Appl. https://doi.org/10.1007/s11042-024-20115-z (2024).
Sharma, S. & Kumar, V. Distracted driver detection using learning representations. Multimed Tools Appl. 82, 22777–22794. https://doi.org/10.1007/s11042-023-14635-3 (2023).
Hu, S. et al. Efficient detection of driver fatigue state based on all-weather illumination scenarios. Sci. Rep. 14, 17075. https://doi.org/10.1038/s41598-024-67131-5 (2024).
Wang, J. et al. A real-time and lightweight driver fatigue detection model using anchor-free and visual-attention mechanisms. Appl. Intell. 54, 9811–9829. https://doi.org/10.1007/s10489-024-05696-4 (2024).
Cheng, W., Wang, X. & Mao, B. A multi-feature fusion algorithm for driver fatigue detection based on a lightweight convolutional neural network. Vis. Comput. 40, 2419–2441. https://doi.org/10.1007/s00371-023-02927-6 (2024).
Ranjan, A. et al. An efficient deep learning technique for driver drowsiness detection. SN Comput. Sci. 5, 988. https://doi.org/10.1007/s42979-024-03316-z (2024).
Mate, P. et al. Detection of driver drowsiness using transfer learning techniques. Multimed Tools Appl. 83, 35553–35582. https://doi.org/10.1007/s11042-023-16952-z (2024).
Gnanadesigan, N. S. et al. A new method for detecting the fatigue using automated deep learning techniques for medical imaging applications. Wirel. Pers. Commun. 135, 1009–1034. https://doi.org/10.1007/s11277-024-11102-6 (2024).
Wang, X. et al. Coupling machine learning and visualization approaches to individual- and road-level driving behavior analysis in a V2X environment. Int. J. ITS Res. https://doi.org/10.1007/s13177-024-00445-w (2024).
Niture, N. & Abdellatif, I. A systematic review of factors, data sources, and prediction techniques for earlier prediction of traffic collision using AI and machine learning. Multimed Tools Appl. https://doi.org/10.1007/s11042-024-19599-6 (2024).
Zhu, J. W. et al. A lightweight fatigue driving detection method based on facial features. SIViP 18 (Suppl 1), 335–343. https://doi.org/10.1007/s11760-024-03156-7 (2024).
He, L. et al. A novel deep-learning model based on τ-shaped convolutional network (τNet) with long short-term memory (LSTM) for physiological fatigue detection from EEG and EOG signals. Med. Biol. Eng. Comput. 62, 1781–1793. https://doi.org/10.1007/s11517-024-03033-y (2024).
Nadalizadeh, F., Rajabioun, M. & Feyzi, A. Driving fatigue detection based on brain source activity and ARMA model. Med. Biol. Eng. Comput. 62, 1017–1030. https://doi.org/10.1007/s11517-023-02983-z (2024).
Kim, B., Preethaa, S. & Song, K. R. Internet of things and ensemble learning-based mental and physical fatigue monitoring for smart construction sites. J. Big Data. 11, 115. https://doi.org/10.1186/s40537-024-00978-7 (2024).
Haiyan Kang, Zhang, C. & Jiang, H. Advancing driver behavior recognition: an intelligent approach utilizing ResNet. Aut Control Comp. Sci. 58, 555–568. https://doi.org/10.3103/S0146411624700664 (2024).
Dogan, S. et al. A new hand-modeled learning framework for driving fatigue detection using EEG signals. Neural Comput. Applic. 35, 14837–14854. https://doi.org/10.1007/s00521-023-08491-3 (2023).
Hügle, T. Advancing rheumatology care through machine learning. Pharm. Med. 38, 87–96. https://doi.org/10.1007/s40290-024-00515-0 (2024).
Gu, J. et al. A personalized mRNA signature for predicting hypertrophic cardiomyopathy applying machine learning methods. Sci. Rep. 14, 17023. https://doi.org/10.1038/s41598-024-67201-8 (2024).
Kannan, E. P. et al. Smart AVDNet: alcohol detection using vehicle driver face. SIViP 18, 5149–5162. https://doi.org/10.1007/s11760-024-03222-0 (2024).
Dargahi Nobari, K. & Bertram, T. A multimodal driver monitoring benchmark dataset for driver modeling in assisted driving automation. Sci. Data. 11, 327. https://doi.org/10.1038/s41597-024-03137-y (2024).
Gu, T. et al. Research on low-power driving fatigue monitoring method based on spiking neural network. Exp. Brain Res. 242, 2457–2471. https://doi.org/10.1007/s00221-024-06911-x (2024).
Hidalgo Rogel, J. M. et al. Studying drowsiness detection performance while driving through scalable machine learning models using electroencephalography. Cogn. Comput. 16, 1253–1267. https://doi.org/10.1007/s12559-023-10233-5 (2024).
Zhang, J. et al. A review on the application of superalloys composition, microstructure, processing, and performance via machine learning. JOM https://doi.org/10.1007/s11837-024-06922-7 (2024).
Zhao, Y. et al. Effects of driver response time under take-over control based on CAR-ToC model in human–machine mixed traffic flow. Automot. Innov. 6, 3–19. https://doi.org/10.1007/s42154-022-00207-y (2023).
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/541/46.
Author information
Authors and Affiliations
Contributions
S.S.Aravinth. G Muni Nagamani and Chanumolu Kiran Kumar. Ayodele Lasisi wrote the main manuscript. Quadri Noorulhasan Naveed .A. Bhowmik prepared the figures. Wahaj Ahmad Khan supervised the project. All authors collaborated in writing and reviewing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Aravinth, S.S., Nagamani, G.M., Kumar, C.K. et al. Dynamic cross-___domain transfer learning for driver fatigue monitoring: multi-modal sensor fusion with adaptive real-time personalizations. Sci Rep 15, 15840 (2025). https://doi.org/10.1038/s41598-025-92701-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-92701-6
