
Abstract
Brontispa longissima is a highly destructive pest that affects coconut and ornamental palm plants. It is widely distributed across Southeast and East Asia and the Pacific region, causing production losses of up to 50–70%. While control methods and ecological phenomena have been the primary focus of research, there is a significant lack of studies on the molecular mechanisms underlying these ecological phenomena. The absence of a reference genome has also hindered the development of new molecular-targeted control technologies. In this study, we conducted a karyotype analysis of B. longissima and assembled the first high-quality chromosome-level genome. The assembled genome is 582.24 Mb in size, with a scaffold N50 size of 63.81 Mb, consisting of 10 chromosomes and a GC content of 33.71%. The BUSCO assessment indicated a completeness estimate of 98.1%. A total of 23,051 protein-coding genes were predicted. Our study provides a valuable genomic resource for understanding the mechanisms of adaptive evolution and facilitates the development of new molecular-targeted control methods for B. longissima.
Similar content being viewed by others


Background & Summary
Brontispa longissima Gestro, a destructive pest of coconut and ornamental palm plants, originates from Indonesia and New Guinea and has spread extensively across Southeast and East Asia and the Pacific region1. The potential for its range to expand further poses a significant risk, threatening coconut production, which is vital for many developing countries2,3. In invaded areas, B. longissima can rapidly reach high incidence rates, causing severe agricultural and economic damage, with production losses reaching as high as 50–70%4. The larvae and adults feed on the soft leaf tissues of coconut palms, resulting in brown leaves, reduced photosynthetic ability, stunted growth, and even death of the palms4. Given its destructive impact, effective management strategies are crucial to mitigate the threat posed by B. longissima.
Currently, the primary method for urgently controlling B. longissima in most countries is through the use of chemical insecticides. However, the effectiveness of pesticide sprays is limited as B. longissima spends most of its stages hidden within unopened buds of coconut trees. Furthermore, populations collected in Southeast Asia have demonstrated varying levels of resistance to certain insecticides, such as β-cypermethrin and avermectin5. Despite this, the specific molecular mechanisms underlying insecticide resistance in B. longissima remain unknown. Additionally, the feeding experience of B. longissima adults influences their subsequent host preferences, facilitating the beetle’s successful establishment in newly invaded habitats where the original host plant is scarce6. Furthermore, chemosensory gene families crucial for insect olfaction were identified based on antennal and abdominal transcriptomes of males and females using RNA-Seq7. However, RNA-Seq only provides limited information on the expression of chemosensory genes in specific tissues and time frames. The sequencing of the B. longissima genome will enable a more comprehensive identification of genes involved in key biological processes such as digestion, insecticide detoxification, and chemosensory perception. This comprehensive genomic dataset will also facilitate the development of targeted pest control methods, including RNA interference (RNAi) and gene editing techniques.
In this study, we utilized PacBio long-read sequencing and Hi-C sequencing technologies to construct the first high-quality chromosome-level reference genome of B. longissima. The final genome size was 582.24 Mb, organized into 10 chromosomes with N50 sizes of 63.81 Mb. Within this genome, we predicted a total of 23,051 protein-coding genes. This high-quality genome serves as a crucial genetic resource for investigating the molecular mechanisms underlying ecological phenomena in B. longissima, such as insecticide resistance and host selection.
Methods
Insect rare and sample collection
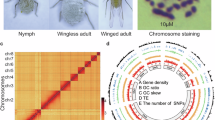
The adult B. longissima (Fig. 1A) specimens were collected from a coconut plantation (Fig. 1B) in Haikou, Hainan Province, in 2003. These insects were reared in the laboratory under controlled conditions: 26 ± 1 °C temperature, 14:10 (L:D) photoperiod, and 80 ± 5% relative humidity. To improve the accuracy and continuity of genome assembly, an inbred B. longissima laboratory population was obtained through sibling mating. The surface-sterilized male adults from this inbred laboratory population were used for Illumina, PacBio, and High-throughput chromosome conformation capture (Hi-C) sequencing, with sample sizes of 10, 10, and 15, respectively. Additionally, eggs, larvae at the 1st, 4th, and 5th instar stages, pupae, and male adults were collected from the laboratory-reared population for transcriptome sequencing. The experiment required 80 eggs, 50 1st instar larvae, 15 individuals each of 4th and 5th instar larvae and pupae, and 10 adults at different stages.

Karyotype analysis of the B. longissima. (A) Photo of B. longissima. (B) Photos of coconut palm (Cocos nucifera L.) damage caused by B. longissima. (C,D) karyotype analysis of B. longissima male chromosome number.
Genome sequencing and assembly
Genomic DNA was extracted from male adults within one day of emergence using the QIAamp DNA Mini Kit (Qiagen, Hilden, Germany) for Illumina, PacBio, and Hi-C sequencing. The purity and integrity of the DNA were verified with a NanoDrop 2000C spectrophotometer (Thermo Fisher Scientific, Wilmington, DE, USA) and 1.5% agarose gel electrophoresis. Approximately 0.5 μg of genomic DNA was used to create a PCR-free Illumina genomic library with the TruSeq Nano DNA HT Sample Preparation Kit (Illumina), targeting a 350-bp insert size. The library was sequenced in a 2 × 150-bp format on the Illumina NovaSeq 6000 platform, generating 39.06 Gb of raw data, achieving a sequence coverage of 67.08× (Table 1). The quality control of the raw Illumina reads was performed using fastp v0.20.18. Clean reads were then used to construct a 17-mer frequency distribution map with Jellyfish v2.3.19. The genome size of B. longissima was further estimated to be 553 Mb (Supplementary Figure 1) using GCE v1.0.210.
For PacBio sequencing, 5 μg of genomic DNA was used to generate ~20-kb insert libraries. These libraries were sequenced on the PacBio Sequel (Pacific Biosciences) platform. A total of 154.76 Gb of clean data was generated, providing a sequence coverage of 265.8× (Table 1). The PacBio clean reads were then subjected to de novo assembly using Canu v1.911 following parameters were used for de novo assembly: correctedErrorRate = 0.035 utgOvlErrorRate = 0.065 trimReadsCoverage = 2 trimReadsOverlap = 500. The parameter correctedErrorRate = 0.035 sets the maximum allowed error rate for corrected reads, ensuring high accuracy of the reads used in the assembly process. The parameter utgOvlErrorRate = 0.065 specifies the maximum error rate allowed for overlaps between unitigs, which helps in correctly assembling contiguous sequences. The trimReadsCoverage = 2 parameter ensures that only reads with at least two times coverage are used, removing low-coverage reads that might introduce errors. Finally, trimReadsOverlap = 500 sets the minimum overlap length required between reads, ensuring that only significant overlaps are considered during assembly. These settings help to improve the accuracy and continuity of the assembled genome. To further generate non-redundant genome sequences, haplotigs and contig overlaps in the initial assemblies were removed using purge_dups v1.2.612. The genome assembly was further refined for errors using both PacBio and Illumina reads with NextPolish v1.2.413 with default parameters.
Hi-C scafolding
Firstly, we conducted cytogenetic analysis using testicular material from sexually mature male coconut leaf beetles. The analysis revealed that the male diploid complement of coconut leaf beetles consists of 18 autosomes along with X and Y sex chromosomes (Fig. 1C,D). To achieve the contig to chromosome-level assembly, the Hi-C technique was used to identify contacts between different regions of chromatin filaments. Male adults within 1 day of emergence were selected for Hi-C library construction. The Hi-C library was constructed following the standard library preparation protocol, where nuclear DNA was cross-linked in situ, extracted, and then digested with the restriction enzyme DpnII. The Hi-C libraries were sequenced on the Illumina NovaSeq 6000 platform with 2 × 150-bp reads. Low-quality reads and adapters from the Hi-C library were filtered using fastp v0.20.18. Under the default parameters, a total of 73.48 Gb of clean data was generated (Table 1) and then mapped to the assembled contigs using Chromap v0.2.514 with the parameter: “--remove-pcr-duplicates”. YaHS v1.2a.115 was applied to perform clustering, ordering, and orientation based on the agglomerative hierarchical clustering algorithm. The chromosome interaction matrix was further manually adjusted using JuicerBox v1.11.0816. Finally, the genome had a total size of 582.24 Mb and an N50 size of 63.81 Mb (Table 2). The genome contained 10 chromosomes (Fig. 2A), which included 98.01% of the assembled contigs (Table 2).

Assembly and quality evaluation of the chromosome genome of B. longissima. (A) Circos plot of distribution of genomic elements in B. longissima. (B) Comparison of BUSCO completeness of the genome among 14 coleoptera species, as a percentage of 1367 insect genes from insecta_odb10. (C) Comparison of contig contiguity among 8 Coleoptera species, including Rhagonycha fulva, H. axyridis, B. longissima, Leptinotarsa decemlineata, C. septempunctata, P. serraticornis, Dendroctonus valens, Tribolium castaneum. N (x)% graphs show contig sizes (y-axis), in which x percent of the assembly consists of contigs of at least that size.
Following Hi-C scaffolding, the genome integrity of B. longissima was assessed using Benchmarking Universal Single-Copy Orthologs (BUSCO v5.4.3)17. The assessment showed that the B. longissima chromosome-level assembly achieved the following BUSCO scores: C: 98.1% [S: 97.8%, D: 0.3%], F: 0.4%, M: 1.5%, n: 1367. These results confirm that the B. longissima genome assembly is both complete and accurate. Furthermore, B. longissima demonstrates relatively greater completeness compared to other Coleoptera insects (Fig. 2B). Remarkably, the assembly continuity of B. longissima surpasses that of other high-quality Coleoptera genome assemblies (Fig. 2C).
Repetitive elements and non-coding RNA annotations
The tandem repeats were firstly annotated using the software GMATA v2.318 and Tandem Repeats Finder (TRF) v4.0919 with default parameters. The simple sequence repeats (SSRs) and all tandem repeat elements across the entire genome were identified using GMATA and TRF, respectively. The transposable elements (TEs) sequences, including SINEs, Penelope, LINEs, LTR elements, DNA transposons, and Rolling-circles were annotated using de novo approaches. We first created a de novo repeat library using RepeatModeler v2.0.420 based on the assembly sequences with default parameters. Transposable element (TE) sequences were then identified through homology searches against this library using RepeatMasker v4.1.521. As a result, 288.54 Mb of repetitive element sequences were identified, representing 49.55% of the genome assembly (Table 3).
To obtain non-coding RNAs (ncRNAs) in the B. longissima genome, two strategies were employed: database searches and model predictions. Transfer RNAs (tRNAs) were identified using tRNAscan-SE v2.0.922 with eukaryote-specific parameters, while microRNAs (miRNAs), ribosomal RNAs (rRNAs), small nuclear RNAs (snRNAs), and small nucleolar RNAs (snoRNAs) were detected by searching the Rfam database v14.1023 with Infernal cmscan v1.1.4. Additionally, rRNAs and their subunits were predicted using Barrnap v0.9 with the parameter --kingdom euk. This comprehensive approach identified 459 tRNAs, 83 rRNAs, 68 miRNAs, and 84 other ncRNAs (Table 4).
Protein-coding gene prediction and function annotation
To annotate protein-coding genes (PCGs) in the genome, we utilized a comprehensive approach combining ab initio prediction, homology-based prediction, and transcriptome-based evidence. Ab initio predictions were performed using Augustus v3.2.324 with default parameters. For homology-based prediction, we aligned and homology annotation the genome sequence against non-overlapping protein sequences from closely related seven species, including Drosophila melanogaster, T. castaneum, Coccinella septempunctata, Harmonia axyridis, Octodonta nipae, Propylea japonica, and Pyrochroa serraticornis, using Miniprot v0.1225 with default parameters. Transcriptome-based predictions were divided into two approaches: RNA-Seq prediction and Iso-Seq prediction. For RNA-Seq prediction, RNA-seq data were mapped to the genome using HISAT2 v2.1.026 and gene models were predicted with Cufflinks v2.2.127 with default parameters. For Iso-Seq prediction, we mapped the Iso-Seq data using GMAP v2023-12-0128 and Minimap2 v2.2829 with default parameters, followed by gene prediction with PASA v2.5.330. The RNA-Seq samples were collected from the egg, 1st, 4th, and 5th instars, pupa, and male adults, generating 111.85 Gb of data (Table 1). The Iso-Seq samples were mixed samples including all developmental stages, generating 68.27 Gb of data (Table 1). Finally, we integrated the gene prediction results from these methods using EVidenceModeler v1.1.131 with default parameters to generate unified consensus gene models. This analysis predicted a total of 23,051 genes in B. longissima, with the total length of coding sequences (CDSs) reaching 35.75 Mb, representing 6.14% of the genome (Table 1). The predicted protein gene sequences assessed for BUSCO completeness were 95.4% (n: 1367), including 94.4% single-copy, 1.0% duplicated, 2.9% fragmented and 1.7% missing BUSCOs.
To perform functional annotation of the protein-coding genes, we employed multiple approaches. First, the predicted genes were aligned against the NR and UniProtKB databases using Diamond v0.9.30.13132 with a threshold of 1e-5, resulting in 21,142 genes (91.71%) showing hits in the NR database and 11,952 genes (51.85%) in the UniProtKB database (Table 5). Additionally, to annotate Gene Ontology (GO) terms, KEGG and Reactome pathways, and identify protein domains, we used HMMER v3.1b233 for the Pfam database, KofamKOALA v1.3.034 for KEGG, and eggNOG-mapper v2.1.53235 for eggNOG. This resulted in 14,752 genes (63.99%) matching the Pfam database and 20,205 genes (87.63%) matching the eggNOG database. Furthermore, 11,755 genes (50.99%) were annotated with GO terms and 13,373 genes (58.01%) with KEGG Orthology (KO) terms. In total, 21,368 of the 23,051 predicted genes (92.69%) were annotated by at least one public database, demonstrating substantial functional annotation coverage (Table 5).
Data Records
All data were associated with the BioProject PRJNA1085852. The reference genome of B. longissima was deposited in GenBank (JBBPDZ000000000.136). Raw data from Pacbio (SRR2827742437), Hi-C (SRR2827742338) and Illumina (SRR2827742539) genome sequencing and RNA-seq (SRR28277416-SRR2827742240,41,42,43,44,45,46) were deposited in the NCBI SRA database with the accession number SRP49423347. The annotation of the B. longissima genome have been deposited at figshare2634425248.
Technical Validation
Genome assembly quality assessment
To assess the quality of the genome, the Illumina genomic reads, Pacbio genomic reads and RNA-Seq reads were mapped to B. longissima genome using the BWA v0.7.17-r118849, Minimap2 v2.22-r110129, and HISAT2 v2.1.026, respectively. The results showed that 98.04% of the Illumina genomic reads mapped back to the assembly, achieving a genome coverage rate of 98.20% (Table 6). Additionally, 94.42% of Pacbio genomic reads were mapped back to the assembly, with a genome coverage rate of 99.79%. More than 86.79% of all RNA-Seq reads were also successfully recovered in the genome, indicating that most reads were successfully assembled (Table 6). The completeness of the B. longissima genome assembly was further evaluated using BUSCO (v5.3.2), which revealed that 98.1% of Insecta dataset core genes (odb_10, released on 2024-01-08) from OrthoDB (http://www.orthodb.org) were identified in the genome assembly (Table 2). The predicted protein gene sequences assessed for BUSCO completeness were 95.4% (n: 1367), including 94.4% single-copy, 1.0% duplicated, 2.9% fragmented and 1.7% missing BUSCOs. A total of 23,051 genes were predicted, and the predicted protein gene sequences showed a BUSCO completeness of 95.4%. Together, these assessments strongly suggest that the assembled B. longissima genome was complete and high quality.
Code availability
This study followed the protocols and manuals provided by the bioinformatics software developers for data processing and analysis, as described in the Methods section. No custom scripts were used.
References
Chen, Z. et al. Development of Single Nucleotide Polymorphism (SNP) Markers for Analysis of Population Structure and Invasion Pathway in the Coconut Leaf Beetle Brontispa longissima (Gestro) Using Restriction Site-Associated DNA (RAD) Genotyping in Southern China. Insects. 11, 230 (2020).
Lu, B. et al. Inter-country trade, genetic diversity and bio-ecological parameters upgrade pest risk maps for the coconut hispid Brontispa longissima. Pest Manag. Sci. 76, 1483–1491 (2020).
Zhang, X., Tang, B. & Hou, Y. A Rapid Diagnostic Technique to Discriminate between Two Pests of Palms, Brontispa longissima and Octodonta nipae (Coleoptera: Chrysomelidae), for Quarantine Applications. J. Econ. Entomol. 108, 95–99 (2015).
Voegele, J. Biological control of Brontispa longissima in Western Samoa: An ecological and economic evaluation. Agric. Ecosyst. Environ. 27, 315–329 (1989).
Lin, Y. Y., Jin, T., Jin, Q. A., Wen, H. B. & Peng, Z. Q. Differential susceptibilities of Brontispa longissima (Coleoptera: Hispidae) to insecticides in Southeast Asia. J. Econ. Entomol. 105, 988–93 (2012).
Takano, S., Takasu, K., Ichiki, R., Fushimi, T. & Nakamura, S. Induction of host‐plant preference in Brontispa longissima (Gestro) (Coleoptera: Chrysomelidae). J. Appl. Entomol. 135, 634–640 (2011).
Bin, S. Y. et al. Antennal and abdominal transcriptomes reveal chemosensory gene families in the coconut hispine beetle, Brontispa longissima. Sci. Rep. 7, 2809 (2017).
Chen, S., Zhou, Y., Chen, Y. & Gu, J. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics. 34, i884–i890 (2018).
Marçais, G. & Kingsford, C. A fast, lock-free approach for efficient parallel counting of occurrences of k-mers. Bioinformatics. 27(6), 764–770 (2011).
Liu, B. H. et al. Estimation of genomic characteristics by analyzing k-mer frequency in de novo genome projects. arXiv preprint arXiv:1308.2012 (2013).
Koren, S. et al. Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res. 27, 722–736 (2017).
Guan, D. et al. Identifying and removing haplotypic duplication in primary genome assemblies. Bioinformatics. 36, 2896–2898 (2020).
Hu, J., Fan, J., Sun, Z. & Liu, S. NextPolish: a fast and efficient genome polishing tool for long-read assembly. Bioinformatics. 36, 2253–2255 (2020).
Zhang, H. et al. Fast alignment and preprocessing of chromatin profiles with Chromap. Nat. Commun. 12, 6566 (2021).
Zhou, C., McCarthy, S. A. & Durbin, R. YaHS: yet another Hi-C scaffolding tool. Bioinformatics. 39, btac808 (2023).
Durand, N. C. et al. Juicebox Provides a Visualization System for Hi-C Contact Maps with Unlimited Zoom. Cell Syst. 3, 99–101 (2016).
Simao, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics. 31, 3210–3212 (2015).
Wang, X., Wang, L. & GMATA An Integrated Sofware Package for Genome-Scale SSR Mining, Marker Development and Viewing. Front. Plant Sci. 7, 1350 (2016).
Benson, G. Tandem repeats finder: a program to analyze DNA sequences. Nucleic Acids Res. 27, 573–580 (1999).
Flynn, J. M. et al. RepeatModeler2 for automated genomic discovery of transposable element families. Proc. Natl. Acad. Sci. USA 117, 9451–9457 (2020).
Tarailo-Graovac, M. & Chen, N. Using RepeatMasker to identify repetitive elements in genomic sequences. Curr. Protoc. Bioinformatics. 4, 4101–41014 (2009).
Lowe, T. M. & Eddy, S. R. tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. Nucleic. Acids. Res. 25, 955–64 (1997).
Kalvari, I. et al. Rfam 14: expanded coverage of metagenomic, viral and microRNA families. Nucleic Acids Res. 49, D192–D200 (2021).
Stanke, M. et al. AUGUSTUS: ab initio prediction of alternative transcripts. Nucleic. Acids. Res. 34, W435–9 (2006).
Li, H. Protein-to-genome alignment with miniprot. Bioinformatics. 39, btad014 (2023).
Kim, D., Paggi, J. M., Park, C., Bennett, C. & Salzberg, S. L. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat. Biotechnol. 37, 907–915 (2019).
Trapnell, C. et al. Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nat. Biotechnol. 28, 511–515 (2010).
Wu, T. D. & Watanabe, C. K. GMAP: a genomic mapping and alignment program for mRNA and EST sequences. Bioinformatics. 21, 1859–75 (2005).
Li, H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics. 34, 3094–3100 (2018).
Haas, B. J. et al. Improving the Arabidopsis genome annotation using maximal transcript alignment assemblies. Nucleic Acids Res. 31, 5654–66 (2003).
Haas, B. J. et al. Automated eukaryotic gene structure annotation using EVidenceModeler and the Program to Assemble Spliced Alignments. Genome Biol. 9, R7 (2008).
Buchfink, B., Reuter, K. & Drost, H. G. Sensitive protein alignments at tree-of-life scale using DIAMOND. Nat. Methods. 18, 366–368 (2021).
Eddy, S. R. Accelerated Profile HMM Searches. PLoS Comput. Biol. 7, e1002195 (2011).
Aramaki, T. et al. KofamKOALA: KEGG Ortholog assignment based on profile HMM and adaptive score threshold. Bioinformatics. 36, 2251–2252 (2020).
Cantalapiedra, C. P., Hernandez-Plaza, A., Letunic, I., Bork, P. & Huerta-Cepas, J. eggNOG-mapper v2: Functional Annotation, Orthology Assignments, and Domain Prediction at the Metagenomic Scale. Mol. Biol. Evol. 38, 5825–5829 (2021).
Li, Z. Y. Brontispa longissima isolate ZL-2024, whole genome shotgun sequencing project. GenBank https://identifiers.org/ncbi/insdc:JBBPDZ000000000.1 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277424 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277423 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277425 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277416 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277417 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277418 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277419 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277420 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277421 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRR28277422 (2024).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRP494233 (2024).
Li, Z. Y. Genome information files for Brontispa longissima. figshare. Dataset. https://doi.org/10.6084/m9.figshare.26344252.v1 (2024).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics. 25, 1754–60 (2009).
Acknowledgements
This work was supported by the National Key R&D Program of China (2021YFC2600400 & 2021YFC2600402); the Central Public-interest Scientific Institution Basal Research Fund for Chinese Academy of Tropical Agricultural Sciences (No. 1630042019029); the Hainan Province Science and Technology Special Fund (ZDKJ2021016); the Shenzhen Science and Technology Program (KQTD20180411143628272); and the agricultural science and technology innovation program.
Author information
Authors and Affiliations
Contributions
Z.G., Z.P. and F.W. conceived the study. C.T., T.J. and C.L. prepared the samples. Z.L. and Z.G. performed the experiments, analyzed the data, and wrote the manuscript. H.W. and X.Q. conducted the field investigation and took photos. Z.P., F.W., B.L. and W.Q. evaluated the results. G.M. provided funding support. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, Z., Ma, G., Tang, C. et al. A chromosome-level genome assembly of the Brontispa longissima. Sci Data 11, 1002 (2024). https://doi.org/10.1038/s41597-024-03846-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03846-4
