
Abstract
Recently, intelligent analysis of lung nodules with the assistant of computer aided diagnosis (CAD) techniques can improve the accuracy rate of lung cancer diagnosis. However, existing CAD systems and pulmonary datasets mainly focus on Computed Tomography (CT) images from one single period, while ignoring the cross spatio-temporal features associated with the progression of nodules contained in imaging data from various captured periods of lung cancer. If the evolution patterns of nodules across various periods in the patients’ CT sequences can be explored, it will play a crucial role in guiding the precise screening identification of lung cancer. Therefore, a cross spatio-temporal lung nodule dataset with pathological information for nodule identification and diagnosis is constructed, which contains 317 CT sequences and 2,295 annotated nodules from 109 patients. This comprehensive database is intended to drive research in the field of CAD towards more practical and robust methods, and also contribute to the further exploration of precision medicine related field. To ensure patient confidentiality, we have removed sensitive information from the dataset.
Similar content being viewed by others

Background & Summary
Effective lung cancer screening and diagnosis has emerged as the critical factor in prolonging patient survival. Among the spectrum of fatal diseases, pulmonary diseases constitute a significant portion1,2,3. Within this category, lung cancer stands out as the most prominent, and its incidence and mortality rates are growing the fastest. This renders it one of the formidable malignancies, posing a severe threat to the population’s health and well-being4,5. Early diagnosis and prompt treatment of lung cancer patients have been shown to substantially enhance their survival rate6,7,8. Since pulmonary nodules as the initial clinical manifestation of lung cancer, the accurate diagnosis and thorough screening of pulmonary nodules assume pivotal roles in the overall therapy of lung cancer9,10,11. Medical imaging techniques encompassing modalities such as X-ray12, CT13,14, Positron Emission Tomography (PET), and so on, take on a critical function in the screening process for lung cancer. Among these techniques, CT scanning is regarded as a routine and indispensable tool in clinical practice, capable of non-invasively capturing the intricate heterogeneity of lung tumours. Consequently, it has emerged as the primary modality for lung cancer detection in contemporary healthcare settings.
The conventional diagnostic approach primarily involves clinicians manually examining CT images slice by slice and relying on their clinical expertise to make a diagnosis. However, this approach has several limitations15. Firstly, radiologists review hundreds of lung CT scans daily, which is a time-consuming and labour-intensive task. Secondly, diagnostic decisions made by clinicians can be highly subjective and may be influenced by their individual levels of expertise and clinical experience. Moreover, the heterogeneity of malignant lung nodules is not solely manifested in the size and morphological characteristics of the lesions, but also in subtle variations in local pixel values within CT images. These trivial nuances are often challenging for the human eye to discern accurately. As a result, accurately determining the malignancy degree of nodules poses a formidable challenge for physicians16.
The implementation of CAD systems in the context of lung nodule diagnosis effectively addresses the aforementioned challenges17,18. The traditional methods include those based on morphological features, voxel-based clustering, and threshold-based techniques19, which are highly reliant on manual hand-crafted feature representation and extraction. In recent years, the advent of deep learning-based algorithms applied to medical images16,20, and has led researchers to progressively propose 2D convolutional neural networks21,22,23 and 3D convolutional neural networks24,25,26,27,28 for the purpose of diagnosing lung nodules. These advancements in lung cancer CAD systems have resulted in breakthroughs and remarkable developments, yielding more accurate results than those traditional methodologies.
At present, the majority of lung nodule detection and classification researches rely on the LIDC/IDRI dataset29 or its extended subsets30. These datasets are annotated by four experienced chest radiologists. However, the labels lack verification from pathological reports, resulting in a degree of uncertainty regarding their accuracy. Recently, several new datasets have been proposed. The PN9 dataset includes nine categories based on combinations of nodule size and density31. Later, the LIDP dataset features annotations derived from pathology reports, providing more accurate labels32. Additionally, most existing CAD systems only address the detection of pulmonary nodules or the benign/malignant classification of these nodules, lacking more advanced functionalities. This limitation may be directly linked to the types of public datasets currently available. To address this issue, a new lung nodule dataset with histopathology-based cancer type annotation has been constructed. This dataset offers precise cancer type annotations, small challenging nodule detection, and a rich variety of cancer classifications, enabling more advanced functionalities for deep learning models33. However, these existing datasets share a common limitation - covering only clinical imaging data at a single time point, thus overlooking the crucial properties, trends, and patterns associated with the gradual and dynamic evolution of tumors cross spatio-temporal periods.
The morphology of nodules continuously evolves and transforms over time. Notably, patients often visit different healthcare facilities and undergo multiple CT scans at various stages of their illness. However, challenges in the interoperability and seamless exchange of medical information hinder the effective sharing of data between hospitals over different periods. In clinical practice, data from various times and sources is crucial for comprehensive assessment, yet physicians face difficulties in accessing and monitoring CT scan information across different time periods. This isolation of information can compromise the consistency of diagnostic analysis and treatment plans, potentially impacting patient care. To address this critical bottleneck, using CAD systems to dynamically observe cross-temporal sequence data of patients and identify and analyze patterns based on disease progression can significantly enhance the accuracy of lung nodule detection and diagnosis. This approach provides physicians with dynamic insights into disease development. Therefore, there is an urgent need for a dataset that incorporates diverse temporal and spatial dimensions.
In this study, we introduce a novel cross spatio-temporal lung nodule dataset based on pathological information, which effectively integrates rich multimodal information within the spatio-temporal dimension. The constructed dataset comprises 317 CT scans from 109 patients, including 1,569 malignant nodules and 726 benign nodules. Moreover, the dataset includes 201 cross spatio-temporal CT scans of different times. During the processing of the dataset, we accurately locate and annotate the nodules in the CT scans according to the pathological information. This critical step ensures the precise tracking and quantitative analysis of nodules, thereby furnishing reliable clinical data (e.g., Ground truth with labeled detail) for disease research and medical imaging analysis. To the best of our knowledge, this dataset is the pioneering pulmonary nodule dataset that embraces the concept of cross spatio-temporal integration with various periods, and provides a fresh dynamic perspective and opportunity for future medical imaging investigations.
A comparison of our dataset with existing publicly available datasets is presented in Table 1. This table compares these diverse datasets in three key aspects: labeling methods, categories, and whether they include multiple time series for the identical patient. As illustrated in the Table 1, our dataset contains finer categorization and more accurate pathology-based labels. An obvious advantage of our dataset is the inclusion of multiple time series for the same patient, enabling a more comprehensive analysis of tumor progression across different times.
Methods
In order to more effectively address the clinical need for mining richer information related to lung disease, discovering potential imaging features, and predicting the evolutionary tendency of the disease, we partner with The Second Hospital of Shandong University to construct a pathology-driven cross spatio-temporal lung CT dataset drawn from actual clinical cases. This dataset is correct annotated based on pathology information. The data samples involved in this study have been reviewed and supported by the research ethics committee of the Second Hospital of Shandong university (approval number: KYLL-2023LW089). Since the Dataset is collected retrospectively and these data undergo irreversible desensitization, there is no sensitive data such as personal information, privacy, and biological samples of the subjects involved in the data. Meanwhile, this study complies with the ethical principles of the Helsinki Declaration and does not pose any risk or harm to the subjects, so the Ethics Committee has exempted the researchers from the requirement to provide informed consent from the patients and has allowed the public release of this dataset. The following section will provide a detailed overview of the dataset, covering aspects such as the collection principles, data collection and annotation, dataset structure, dataset properties and so on.
Collection principles
To ensure the accuracy of the collected subjects and to eliminate interference from irrelevant factors, we implement the following principles in our case selection process:
Inclusion criteria
In accordance with pathology-driven criterion, only pulmonary nodules with a definitive pathological diagnosis are included. These nodules must be uniquely identifiable in the corresponding CT images based on the provided descriptions of nodule ___location and size in the diagnosis. This strict criterion ensures that each target nodule aligns precisely with its pathological diagnosis.
Exclusion criteria
Cases with pathological diagnoses unrelated to pulmonary nodules are excluded. This step effectively eliminates any interference from other non-nodule lesions in our dataset.
Pre-treatment imaging
All CT scans are performed before any relevant treatments are administered. This inclusion criterion ensures that the image characteristics of the nodules are not influenced by prior treatments.
Quality control
We meticulously review and discard CT images with missing layers or incorrect layering to guarantee the integrity and continuity of the lung nodule image dataset.
Data collection and annotation
Our data collection and annotation efforts are conducted at The Second Hospital of Shandong University. The data collection process encompasses four key stages, as illustrated in Fig. 1:

The workflow for generating the dataset. Firstly, the Electronic Medical Record System (EMRS) is used to identify cases diagnosed with pulmonary occupying lesions within the past six years. Subsequently, these cases are filtered using the Pathology Information System (P.I.S), retaining only those with available pathology information. Finally, one or multi-time CT sequences of the patient are exported from the Picture Archiving and Communication System (PACS). After data extraction, the dataset is categorized into two distinct categories: classification and detection. Under the guidance of expert physicians, annotators extract the coordinate information of the nodules from the CT sequences, based on the corresponding pathological information, and records it in the CSV file. In addition, post-segmentation lung data is also provided.
Case collection
We amassed cases from the EMRS spanning from January 2016 to January 2023, specifically selecting those cases with diagnoses referencing nodular lung lesions and accompanying surgery records.
Pathological diagnosis recording
On the basis of the organized case records, we retrieve and document the pathological diagnosis corresponding to the lung nodules in the P.I.S.
Patient imaging data retrieval
In the PACS system, we search for the CT scan times of the patients, view the patients’ multiple diagnostic imaging reports and CT images, and subsequently employ the provided image descriptions in the diagnostic imaging reports along with the corresponding pathological diagnostic results to precisely locate the target pulmonary nodule.
Data export and archive preparation
Following the identification of the target pulmonary nodules, we proceed to export the corresponding DICOM file sequences. To facilitate subsequent labelling operations and ensure data preservation, we create archive disks containing the imaging data.
Under the guidance of expert physicians, we perform the labelling of nodule ___location and contour within the exported CT sequences. Then physicians verify the lesion locations by referencing the imaging manifestations and the pathological information contained in the dataset. Afterwards, they instruct the annotators to complete the labelling task within the slices containing the lung nodules. This rigorous process is crucial in guaranteeing the precision and reliability of the annotations, forming a robust foundation for subsequent data analysis. In total, we label 2,295 nodules across 317 CT scans in this dataset.
Dataset structure
Temporal dimension CT series
We collect CT scans from patients at various time points, denoted as T1, T2, …, Tm, where m represents the CT scans captured at the m moments for each patient. Unlike single-point-in-time slice studies, longitudinal studies yield dynamic data tend to unearth richer information about the disease variation. Figure 2 shows an example of CT images taken at different times for an identical patient.

An example of the CT sequences of different temporal dimension.
Spatial dimension CT series
In the spatial dimension, we annotate the CT scan sequences (referred to as P1, P2, …, Pk,…, Pn) containing pulmonary nodules. Within these sequences, we identify and designate specific slices where the nodules are most prominently visible as keyframes, represented by Pk. Figure 3 provides an example of the CT sequences for a patient in line of the spatial dimension.

An example of the CT sequences in terms of spatial dimension.
Cross spatio-temporal dimension CT series
Our dataset encompasses both longitudinal inspection data spanning multiple time moments and spatially oriented horizontal data. This comprehensive dataset enables researchers to concurrently observe nodule changes from the temporal and spatial perspective simultaneously, facilitating the training of accurate lung nodule diagnosis models and providing a rich, multi-dimensional perspective for in-depth exploration of disease progression. A holistic overview of the dataset is presented in Fig. 4.

A global overview of the dataset structure.
Dataset properties
Pathological type
Since the CT data in this dataset originate from patients who have undergone surgery or medical treatment, there are more malignant cases than benign cases. To address this imbalance while considering clinical relevance, we apply a like-for-like aggregation approach to classify the dataset into six distinct pathology types. These types include invasive adenocarcinoma (A), minimally invasive adenocarcinoma (B), adenocarcinoma in situ (C), other malignant subtypes (D), cases involving inflammation (E), and benign subtypes (F), as illustrated in Fig. 5(a).

Statistics of dataset categories and nodule sizes. (a) The types and percentages of pathology in the dataset; (b) The types and percentages of nodule size; (c) The correlation between nodule size and pathological type.
From the graph, it is evident that there are more malignant nodules than benign nodules, with 1,569 malignant nodules (68.37%) and 726 benign nodules (31.63%).
Nodule size
Pulmonary nodules are categorized based on size into four distinct groups: 0–10 mm, 11–20 mm, 21–30 mm, and >30 mm. Among these categories, nodules sized between 11–20 mm are the most prevalent, comprising 42.79% of all nodules. Nodules sized 21–30 mm and >30 mm each account for approximately 27.67% and 26.49%, respectively, as shown in Fig. 5(b).
Figure 5(c) illustrates the correlation between nodule size and pathological type. It is notable that invasive adenocarcinomas are predominant among nodules sized between 21 and 30 mm. Additionally, inflammation is observed in nodules sized between 11 and 20 mm.
Nodule ___location
Figure 6(a) illustrates the distribution of nodule locations. It shows that the superior lobe of right lung has the highest number of nodules, followed by the inferior lobe of left lung.

Statistics on Nodule Location and Nodule Count. (a) Nodule ___location; (b) Number of nodules per sequence.
Nodule count
We quantify the number of nodules in each sequence, as shown in Fig. 6(b). The sequences with 1–5 nodules are the most numerous, totaling 168, followed by sequences with 6–10 nodules, 81 in total.
Patient demographics
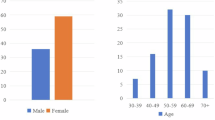
We compile the demographic information of the patients. The gender distribution, as depicted in Fig. 7(a), indicates that there are more female patients than male patients.

Patient demographics. (a) Gender distribution of patients; (b) Age distribution of sequences.
Since our dataset includes multiple CT sequences for the same patient over different times, the patient’s age may vary across sequences. Therefore, we record the age corresponding to each CT sequence, as illustrated in Fig. 7(b). The data shows that the majority of patients fall within the age ranges of 51–60 and 61–70.
Thickness
We concurrently collect CT sequences with slice thicknesses of 1.25 mm and 5 mm to address diverse requirements in actual clinical diagnosis and treatment. Some patients have both 1.25 mm and 5 mm CT scans. There are 164 CT series with a slice thickness of 1.25 mm and 153 series with a slice thickness of 5 mm.
Data preprocessing
Initially, Gaussian filtering is applied to each image slice to achieve two objectives: image smoothing for noise reduction and enhancement of color contrast between the lungs and surrounding tissues. Subsequently, a clustering technique is employed to determine thresholds that effectively distinguish lung regions from non-lung regions within the medical images. The ultimate aim of this preprocessing step is to isolate and highlight the lung region, so that the structure or region of interest can be more easily identified in successive segmentation and analysis steps. The processed lung region is then systematically stored in a designated folder, labeled as “lung_mask”. This is included in the “1.25 mm_3D_detection_mhd_2.zip” dataset within the “Data Records” section for 1.25mm slice thickness detection34.
Data Records
We have publicly released the data in the Zenodo repository without any password protection34,35. Since our data is large and Zenodo has an upload capacity limitation, we split the dataset and store it in two different websites (Database Part A34 and Database Part B35). To facilitate downloads, we have partitioned large-sized files into multiple zip archives. In case the main link doesn’t work, we also provide an alternate link36. The uploaded dataset files are organized according to different slice thicknesses (1.25 mm and 5 mm), which are described as follows.
For the layer thickness of 1.25 mm, we provide two different types of datasets for classification and detection. The detailed description of the file format is given below:
1.25 mm slice thickness classification dataset
The classification dataset, comprising BMP-format images, is compressed into a single archive named “class_dataset.zip” and uploaded to Database Part A34. Within this archive, the dataset is divided into two segments: the training set and the testing set, in a 5:1 ratio. These segments are stored in the “train” and “validate” folders, respectively. Each folder contains six subfolders categorized as labels 1, 2, 3, 4, 5 and 6, which correspond to invasive adenocarcinoma, minimally invasive adenocarcinoma, adenocarcinoma in situ, other malignant subtypes, inflammation, and other benign subtypes, respectively. Additionally, the “READ_ME.txt” file provides detailed information, including the number of samples in the training and testing sets for each category.
1.25 mm slice thickness detection dataset
For the 1.25 mm slice thickness, we develop a dataset for lung nodule detection and evaluation, encompassing both three-dimensional (3D) and two-dimensional (2D) data formats.
-
1)
3D Data: We offer two formats: MHD and BMP.
The MHD dataset includes four compressed files, uploaded to Database Part A34. Specifically: “1.25 mm_3D_detection_mhd_0.zip” and “1.25mm_3D_detection_mhd_1.zip” contain the original MHD-format images of the patients. “1.25mm_3D_detection_mhd_2.zip” includes MHD-format images that have undergone lung segmentation named “lung_mask”. “5mm_3D_detection_mhd_3.zip” contains the “annotations.csv” file, which holds information on the actual nodule positions and diameters. These data points are referenced within a global coordinate system, serving as a reliable benchmark for assessing the performance of the testing data.
The detection dataset in BMP format contains augmented data through flipping and rotation, and is stored in Dataset Part B35. We compress the images into three distinct sub-archives for easy upload, each labeled as “1.25mm_3D_detection_bmp i (i = 0–10).zip”. Researchers should extract and consolidate these files for use. In addition, both the labels and training and test set information are placed in “1.25mm_3D_detection_bmp11.zip”. This archive contains the files “image_annotation_augment_diameter.csv”, “train_anno.csv”, “val_anno.csv”, “train.txt”, and “val.txt”. The “image_annotation_augment_diameter.csv” file provides detailed information regarding the real nodule positions and diameters based on the voxel coordinate system. This data is divided into training and testing sets in a 5:1 ratio, saved as “train_anno.csv” and “val_anno.csv” files, respectively. The case numbers for the training and testing sets are listed in “train.txt” and “val.txt”.
-
2)
2D Data: We provide the “1.25mm_2D_detection.zip” folder in Database Part A34. The “JPEGImages” folder contains the dataset images, the “Annotations” folder includes the XML format annotations, and the “labels” folder holds the bounding box center coordinates along with the width and height. “VOC_CT.xlsx” lists the image filenames and their corresponding nodule coordinates (xmin, ymin, xmax, ymax). To facilitate model training and performance evaluation, we partition the dataset into training and testing sets using a 4:1 ratio. The image names of these sets are recorded in the “train.txt” and “val.txt” files located in the “ImageSets/Main” directory, while the image paths are documented in the “train.txt” and “val.txt” files within the “images” folder. Furthermore, the “train.txt” and “val.txt” files inside the “1.25mm_2D_detection.zip” include the image paths and corresponding nodule coordinates.
5mm slice thickness detection dataset
We provide a detection dataset availablely in MHD format within Database Part A34. This dataset is divided into four compressed files. The first three files, “5mm_3D_detection_mhd i (i = 0–2).zip” contain data in MHD format. The final file, “5mm_3D_detection_mhd3.zip” includes detailed information on the actual nodule locations and diameters for each case in the global coordinate system.
Technical Validation
Classification experiments
To appraise the efficacy of our designed pulmonary nodule classification dataset, we conduct comprehensive assessments utilizing eight distinct and typical image classification networks, namely ResNet37, ConvNext38, ResNext39, Res2Net40, SE-ResNet41, CABNet42, InceptionV443, and EfficientNet44. These networks exhibit diverse architectures and excellent performance characteristics, enabling a thorough examination of the dataset’s suitability for pulmonary nodule classification tasks. We carry out both training and testing phases for these networks using identical datasets and configurations to ensure the fairness and comparability of our experiments. Each dataset is divided into training and testing sets in a 5:1 ratio. During the experiment, each network undergoes training for a total of 150 epochs.
For the quantitative assessment of classification performance, we employ two key metrics, namely Extreme Accuracy (ACC) and Quadratic Weighted Kappa (QWK), for objective evaluation. These metrics are selected to provide a thorough assessment of our classification results. The outcomes of these experiments are presented in Table 2.
As evident from the table, our dataset yields reliable results across various categorical networks. This consistency underscores the dataset’s label and feature accuracy, as well as its robustness. The multi-model applicability indicates that the dataset encompasses diverse data samples and has been adequately considered in terms of data quality and diversity. While all eight typical networks achieve accuracy and QWK scores exceeding 0.5, it is remarkably that none of their metrics attain exceptionally high values. This observation accentuates the challenges and research potential inherent in our dataset.
To assess the quality of category detection for the eight individual networks, we present the confusion matrices in Fig. 8. Significantly, the values along the main diagonal of each confusion matrix are relatively higher, signifying that the network classification results generally aligned with our annotations. This alignment highlights the effectiveness of our dataset for classification tasks. Given that different networks exhibit varying sensitivities to distinct data classes, this further verifies the dataset’s complexity and diversity.

Detection experiments
In order to validate the effectiveness of the lung nodule detection dataset, we test five different object detection networks, consisting of Faster R-CNN45, Yolov346, MobileNet47, SSD48, and RetinaNet49. Remarkably, each network is trained over 50 epochs using the same dataset and train configuration. To estimate the model’s performance, we employ object detection evaluation metrics typically used for the COCO dataset, including Average Precision (AP), AP50, AP75, APS, APM, and APL46. These metrics are widely recognized for assessing the accuracy of detection box localization by the model. Detailed test results are presented in Table 3.
Specifically, APS, APM, and APL gauge the detection performance of target objects at diverse sizes. Given that our dataset contains over twice as many malignant nodules as benign nodules, the substantial number of malignant nodules enhances the model’s sensitivity in detecting malignancies. Consequently, the APL metrics for the results obtained with the five popular networks are higher.
Code availability
To make this dataset easily available to users, we have released a resource located in a GitHub repository. The repository includes Python sample code that demonstrates how to use the data, helping users understand and apply this dataset effectively. You can find the resource in the following GitHub repository: https://github.com/Heroandzhang/CSTL_DATASET.
References
Leiter, A., Veluswamy, R. R. & Wisnivesky, J. P. The global burden of lung cancer: current status and future trends. Nat. Rev. Clin. Oncol. 20, 624–639 (2023).
Weiss, J. et al. Deep learning to estimate lung disease mortality from chest radiographs. Nat. Commun. 14, 2797 (2023).
Fu, Y. et al. Gender disparities in lung cancer incidence in the united states during 2001–2019. Sci. Reports. 13, 12581 (2023).
Siegel, R. L., Miller, K. D., Wagle, N. S. & Jemal, A. Cancer statistics. Ca. Cancer J. Clin. 73, 17–48 (2023).
Badr, H. S. et al. Unified real-time environmental-epidemiological data for multiscale modeling of the covid-19 pandemic. Sci. Data. 10, 367 (2023).
Rudin, C. M., Brambilla, E., Faivre-Finn, C. & Sage, J. Small-cell lung cancer. Nat. Rev. Dis. Primers. 7, 3 (2021).
Howlader, N. et al. The effect of advances in lung-cancer treatment on population mortality. N. Engl. J. Med. 383, 640–649 (2020).
Prior, F. et al. The public cancer radiology imaging collections of the cancer imaging archive. Sci. Data. 4, 170124 (2017).
Venkadesh, K. V. et al. Prior ct improves deep learning for malignancy risk estimation of screening-detected pulmonary nodules. Radiology. 308, e223308 (2023).
Mazzone, P. J. & Lam, L. Evaluating the patient with a pulmonary nodule: a review. JAMA. 327, 264–273 (2022).
Kim, R. Y. et al. Artificial intelligence tool for assessment of indeterminate pulmonary nodules detected with ct. Radiology. 304, 683–691 (2022).
Reis, E. P. et al. Brax, brazilian labeled chest x-ray dataset. Sci. Data. 9, 487 (2022).
Wang, S., Ouyang, X., Liu, T., Wang, Q. & Shen, D. Follow my eye: Using gaze to supervise computer-aided diagnosis. IEEE Trans. Med. Imaging. 41, 1688–1698 (2022).
Li, H., Zeng, N., Wu, P. & Clawson, K. Cov-net: A computer-aided diagnosis method for recognizing covid-19 from chest x-ray images via machine vision. Expert Syst. Appl. 207, 118029 (2022).
Chen, C. L. et al. An annotation-free whole-slide training approach to pathological classification of lung cancer types using deep learning. Nat. Commun. 12, 1193 (2021).
Paez, R. et al. Longitudinal lung cancer prediction convolutional neural network model improves the classification of indeterminate pulmonary nodules. Sci. Rep. 13, 6157 (2023).
Liang, M. et al. Low-dose ct screening for lung cancer: computer-aided detection of missed lung cancers. Radiology. 281, 279–288 (2016).
Papanastasiou, G. et al. Focus on machine learning models in medical imaging. Phys. Med. Biol. 68, 010301 (2023).
de Carvalho Filho, A. O. et al. Automatic detection of solitary lung nodules using quality threshold clustering, genetic algorithm and diversity index. Artif. Intell. Med. 60, 165–177 (2014).
Shin, H. C., Orton, M. R., Collins, D. J., Doran, S. J. & Leach, M. O. Stacked autoencoders for unsupervised feature learning and multiple organ detection in a pilot study using 4d patient data. IEEE Trans. Pattern Anal. Mach. Intell. 35, 1930–1943 (2012).
Wang, Q. et al. Higher-order transfer learning for pulmonary nodule attribute prediction in chest ct images. BIBM. 741–745 (2019).
Cheng, J. Z. et al. Computer-aided diagnosis with deep learning architecture: applications to breast lesions in us images and pulmonary nodules in ct scans. Sci. Rep. 6, 24454 (2016).
Xie, Y., Zhang, J., Xia, Y., Fulham, M. & Zhang, Y. Fusing texture, shape and deep model-learned information at decision level for automated classification of lung nodules on chest ct. Inf. Fusion. 42, 102–110 (2018).
Liao, F., Liang, M., Li, Z., Hu, X. & Song, S. Evaluate the malignancy of pulmonary nodules using the 3-d deep leaky noisy-or network. IEEE Trans. Neural Netw. Learn. Syst. 30, 3484–3495 (2019).
Zhou, Z. et al. Models genesis: Generic autodidactic models for 3d medical image analysis. Proc. Int. Conf. Med. Image Comput. Comput. -Assisted Intervention. 384–393 (2019).
Zhu, W., Liu, C., Fan, W. & Xie, X. Deeplung: deep 3d dual path nets for automated pulmonary nodule detection and classification. WACV. 673–681 (2018).
Li, Y. & Fan, Y. Deepseed: 3d squeeze-and-excitation encoder-decoder convolutional neural networks for pulmonary nodule detection. Proc. IEEE Int. Symp. Biomed. Imaging. 1866–1869 (2020).
Zhou, H. Y., Lu, C., Chen, C., Yang, S. & Yu, Y. A unified visual information preservation framework for self-supervised pre-training in medical image analysis. IEEE Trans. Pattern Anal. Mach. Intell. 45, 8020–8035 (2023).
Armato, S. G. et al. The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Med. Phys. 2, 915–931 (2011).
Setio, A. A. A. et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Med. Image Anal. 42, 1–13 (2017).
Mei, J., Cheng, M. M., Xu, G., Wan, L. R. & Zhang, H. Sanet: A slice-aware network for pulmonary nodule detection. IEEE Trans. Pattern Anal. Mach. Intell. 44, 4374–4387 (2021).
Shao, Y. et al. Lidp: A lung image dataset with pathological information for lung cancer screening. Proc. Int. Conf. Med. Image Comput. Comput. - Assisted Intervention. 13433, 770–779 (2022).
Jian, M., Chen, H., Zhang, Z. et al. A Lung Nodule Dataset with Histopathology-based Cancer Type Annotation. SciData 11, 824 https://doi.org/10.1038/s41597-024-03658-6 (2024).
Jian, M. & Zhang, H. Cross spatio-temporal pathology-based lung nodule dataset. Zenodo https://doi.org/10.5281/zenodo.12582356 (2023).
Jian, M. & Zhang, H. Cross spatio-temporal pathology-based lung nodule dataset. Zenodo https://doi.org/10.5281/zenodo.12576633 (2023).
Jian, M. & Zhang, H. Cross spatio-temporal lung nodule dataset. Kaggle https://doi.org/10.34740/kaggle/dsv/8812289 (2024).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 770–778 (2016).
Liu, Z. et al. A convnet for the 2020s. IEEE Conf. Comput. Vis. Pattern Recognit. 11976–11986 (2022).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. IEEE Conf. Comput. Vis. Pattern Recognit. 1492–1500 (2017).
Gao, S. H. et al. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 43, 652–662 (2019).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. IEEE Conf. Comput. Vis. Pattern Recognit. 7132–7141 (2018).
He, A., Li, T., Li, N., Wang, K. & Fu, H. Cabnet: Category attention block for imbalanced diabetic retinopathy grading. IEEE Trans. Med. Imag. 40, 143–153 (2020).
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. AAAI Conf. Artif. Intell. 31 (2017).
Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. Int. Conf. Mach. Learn. 6105–6114 (2019).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 28 (2015).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. Preprint at https://arxiv.org/abs/1804.02767 (2018).
Howard, A. G. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. Preprint at https://arxiv.org/abs/1704.04861 (2017).
Liu, W. et al. Ssd: Single shot multibox detector. Eur. Conf. Comput. Vis. 21–37 (2016).
Lin, T. Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. IEEE Int. Conf. Comput. Vis. 2980–2988 (2017).
Acknowledgements
This work was supported by National Natural Science Foundation of China (NSFC) (61976123, 61601427); Taishan Young Scholars Program of Shandong Province; and Key Development Program for Basic Research of Shandong Province (ZR2020ZD44).
Author information
Authors and Affiliations
Contributions
Muwei Jian: Writing - Conceptualization; Methodology; Writing - Review & Editing; Supervision; Haoran Zhan: Formal analysis; Data Curation; Writing - Original Draft; Writing -Conceptualization; Mingju Shao: Methodology; Formal analysis; Resources; Hongyu Chen: Validation; Conceptualization; Visualization; Huihui Huang: Visualization; Data Curation; Yanjie Zhong: Visualization; Data Curation; Changlei Zhang: Resources; Bin Wang: Resources; Penghui Gao: Resources.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jian, M., Zhang, H., Shao, M. et al. A Cross Spatio-Temporal Pathology-based Lung Nodule Dataset. Sci Data 11, 1007 (2024). https://doi.org/10.1038/s41597-024-03851-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03851-7
