
Abstract
Understanding the effects of artificial structures in marine landscapes is required for ecosystem-based management. Global demand for oil and gas and accelerated commitments to renewable energy development has led to the proliferation of marine artificial structures. Investigating the cumulative effects of these structures on marine ecosystems requires data on the benthic community over large geographical and long-time scales. It is imperative to share the data collected by many stakeholders in an integrated information system to benefit science, industry and policy. BISAR is the first data product containing harmonised and quality-checked international data on benthos from artificial structures in the North Sea. BISAR was compiled from environmental impact assessment studies and scientific projects (3864 samples, 890 taxa). Data derive from 34 artificial structures and surrounding soft sediments (years: 2003 to 2019). Structures include offshore wind turbines, oil and gas platforms and a research platform. Data from a geogenic reef, allow comparison of natural and artificial reef communities. We aim to host future BISAR data dynamically in the CRITTERBASE web portal.
Similar content being viewed by others

Background & Summary
Worldwide reduction of carbon emissions is needed to help reduce the effects of climate change. Twenty-seven member states of the European Union have committed to reduce emissions by 55% of 1990 levels by 20301. To achieve this, an unprecedented installation of offshore marine renewable energy devices (wind, wave, tidal, solar) and cable networks is required2. To date, offshore wind energy is the largest marine renewable energy provider, currently producing globally 35 GW with an increase to 70 GW expected by 20253 and a potential increase worldwide to 1000 GW expected by 20504. Europe has the majority of offshore wind farms (OWFs) with a capacity of 28 GW5, which corresponds to 5,795 grid-connected wind turbines across 123 OWFs and 12 countries5.
Marine biodiversity and their associated ecosystems are increasingly being affected by anthropogenic pressures, such as the growing number of artificial structures6,7, eutrophication, fisheries and climate change8,9,10. The introduction of man-made structures can potentially have both positive and negative effects on marine ecosystems11,12,13,14. Soft-bottom communities are altered close to artificial structures15,16,17, while a significant amount of marine growth colonises the artificial hard structures18,19.
To assess the effects of man-made structures on the benthic community, most environmental impact assessment data collection studies have been conducted over small spatial and temporal scales20 such as single turbines or single OWFs and associated infrastructure15,21,22. Some countries have coordinated programmes to standardise data collection methods on soft sediments (e.g., Germany23, Belgium24, the Baltic Sea25), and there are existing methods to study macrofauna on natural hard substrates such as rocky bottoms26. However, there are no internationally agreed methods, metrics or databases for the data collection, which is critical for understanding the effects of artificial structures on marine ecosystems. Data are disparate owing to differences in data diversity, regarding (i) sampling devices and methods, (ii) sample analysis (e.g., variables, taxonomic resolution), (iii) data storage and management, as well as (iv) continuously changing taxonomy. This results in a lack of consistent data with regards to offshore artificial structures and benthos. Thus, investigation of large-scale benthic effects requires merging data from different sources, which is challenging (time consuming, costly, difficult) or even not possible19. Taken together, the available data are underutilised.
A few attempts have been made to collect and analyse biodiversity data from different substrates (wind turbines, oil and gas platforms, surrounding soft sediments and rocky reefs) in a single region19,27,28. Ecosystem-based management requires a deep understanding of the effects of artificial structures over large spatial and temporal scales that exceed budgets, timeframes and jurisdictional borders. Data sharing through the creation of an integrated database can provide multiple benefits for science, industry, and policy. It could be used for large-scale research studies examining the aforementioned effects and facilitate ecosystem-based management. Furthermore, the creation of a centralised dataset could enable answering scientific questions regarding stepping stone effects beyond the scale of individual OWFs, platforms or countries29,30. Industry could exploit this dataset for environment-friendly planning, predicting effects of new activities at offshore locations. Finally, sharing such data is crucial in developing fact-based scientific advice for decommissioning decisions for various stakeholders.
This paper presents the first data collection ‘Biodiversity Information of benthic Species at ARtificial structures’ (BISAR). BISAR contains data on benthic macrofauna collected in environmental impact studies, scientific projects and species inventories conducted at 17 artificial offshore structures in the North Sea between 2003 and 2019. The structures include OWFs, oil and gas platforms, a research platform and a geogenic reef to compare natural and artificial reef communities. BISAR includes data from soft and hard substrate studies (34 artificial structures), allowing comparisons of changes in both habitat types. This data collection currently contains data from a total of 3864 samples with 890 taxa. BISAR is the first data product containing harmonised and quality-checked international data on benthos from substrates influenced by artificial structures in the North Sea. Various stakeholders (e.g., industry, public authorities, research) will profit from the BISAR data collection as the greatest challenge in an era of blue growth is to get access to data from various sources31.
Methods
BISAR contains data on a total of 3,864 samples taken at 1,453 stations with 68,433 records of 890 taxa of benthic macrofauna, from 34 artificial structures and surrounding soft bottom collected during 105 cruises between 2003 and 2019 (Table 1).
Data compilation
The data were compiled from various sources, such as different international research institutes, universities, and industry. Hence, the format between different datasets varied and the number of metadata was highly variable. To harmonise the data, one data template was created and used by all data providers (Fig. 1, MSExcel-table) containing main tables and metadata information (lookup tables) (see section ‘data records’). The main tables contain metadata on the cruise, station, and individual samples (e.g., scrape samples on turbines) which were compiled for the first time in a harmonised style for the BISAR data collection. Biota data and environmental data (e.g., substrate of samples) were also compiled. Look-up tables collect additional information, e.g., sampling gear and life stages of biota. A glossary of the BISAR data collection provides detailed information about the data columns, as well as units of column data and a brief description.

Workflow of the data compilation, quality check, storage and publication of the BISAR data collection.
Each dataset was individually transferred to the BISAR data collection by copying data columns from the original datasheets in the corresponding columns of the multi-sheet format. The compilation of the data was done between the data contributors and experienced data curators in an iterative process until the datasets were combined in the BISAR data collection (Fig. 1).
Notes on benthic sampling
Benthos samples were collected within the different projects which included seven OWFs, nine oil and gas platform foundations, one research platform and one geogenic reef (Fig. 2) in the North Sea. Different methods were applied to collect samples from the hard substrates on and around the artificial structures. Specifics for each artificial structure or platform are described in the following sections.

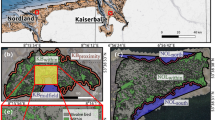
Map of sampling locations of the BISAR data collection. Alpha ventus and Prinses Amalia areas are displayed with zoom areas due to the large number of samples.
FINO 1 research platform, Germany
The research platform FINO 1 is similar in size and shape to today’s jacket foundations of offshore wind turbines32. Sampling of the artificial hard substrate took place between April 2005 and October 2007 at nine different water depths between 1 and 28 m. At each depth, one to two samples were taken at random positions on vertical surfaces. Samples measuring 20 × 20 cm were scraped and captured in a mesh bag (mesh size: 0.5 mm) by scientific divers. Aboard all samples were preserved in 4% borax-buffered formalin. In the laboratory, specimens were pre-sorted, stored in 75% ethanol and then identified. Colonial species were counted as present, while individual species were counted and wet weighed. Wet masses were corrected by a factor of 1.2 to account for changes due to storage in ethanol (following Zintzen et al.33,34).
Alpha ventus, Sandbank and DanTysk offshore wind farms, Germany
At alpha ventus, both epifauna communities on the structures and seabed communities (wind farm area and reference area) were sampled. Sandbank and DanTysk were sampled for the fauna colonising the artificial hard substrate. All three datasets were collected according to the standard investigation concept for OWFs in the German part of the North Sea (latest version: StUK 423,35).
Data from alpha ventus were collected in autumn 2009 and spring and autumn in the years 2010–2012. Sandbank was sampled in August 2019 and DanTysk in September 2018 and August 2019. Four turbines were investigated in alpha ventus (i.e., 2 jacket structures, 2 tripods), two turbines in Sandbank and DanTysk (all monopiles). Scrape samples with a surface area of 0.04 m² were collected by scientific divers at three or four different depths (alpha ventus at 1, 5, 10 and 15 m, Sandbank and DanTysk at 1, 5, 10 m), each with three replicates. Organisms were collected in mesh bags with a mesh size of 0.5 mm and conserved in 4% borax-buffered formalin. In the laboratory, taxa were identified, and individuals were counted and wet weighed.
Data from the project StUKplus Benthos also included seabed communities from alpha ventus only (in autumn 2008–2011)36. Samples were taken with Van Veen grabs (surface area 0.1 m²). The dataset served as a complementary investigation to the alpha ventus StUK monitoring, specifically to capture data relating to potential processes occurring at different distances from single wind turbines of the wind farm. Samples were collected at four sites, i.e., at two wind turbines inside the OWF alpha ventus and in two reference areas outside the OWF, with one transect in the main water current direction and one perpendicular to each other. Along each transect, seven stations, each 100 m apart (within OWF) and four sampling stations, each 200 m apart (within reference areas) were sampled. At each station, three replicate Van Veen grabs were sampled. Organisms were sieved over a 1 mm mesh and conserved in 4% borax-buffered formalin. Taxa were identified and individuals were counted and weighed (wet mass) afterwards in the laboratory.
Horns Rev I offshore wind farm, Denmark
In the Horns Rev I wind farm in Denmark, two sampling surveys of epifauna organisms per year were conducted on the monopile foundations and scour protection layer, during three years i.e., March and September of 2003, 2004 and 200537,38. Scrape samples of 0.04 m2 were collected by scientific divers in the direction of the principal water current on both the upstream (SSW) and the downstream sides (NNE). Samples were taken at depths of 0, 2, 4, 6 and 8 m depth at the monopiles and from rocks in the scour protection layer at depths between 6 and 10 m. Two replicates per depth and three per rock were collected in bags with a mesh size of 1 mm. All samples were preserved in ethanol until further processing in the laboratory, where the samples were sorted under a stereomicroscope. All organisms were identified, counted and their ethanol wet mass was determined.
Prinses Amalia wind farm, the Netherlands
In the Prinses Amalia wind farm (PAWP), the fauna both on the structures and in the seabed were studied. In total, four turbine foundations were selected, both at edges and at the centre of the wind farm. Monitoring of the epifauna on the monopile foundations and scour protection layer was conducted three and a half (October 2011) and six (July 2013) years after construction27,39,40. Scrape samples taken by scientific divers were collected at five different depths: splash zone, 2, 5, 10 and 17 m depth from both sides of the turbine (SSW and NNE) with a single sample per depth-side combination. The sampled surface area was 28 × 20 cm (0.056 m2) and scraped fauna were collected in a sampling net (mesh size: 0.25 mm). The scour protection layer was sampled by collecting small rocks.
Soft-sediment fauna was collected within the wind farm in March 2012 and April 201339,40 with 1 sample per station, from the wind farm and reference areas south-west and north-east of the wind farm. Soft sediment fauna was sampled using a box corer grabbing an area of 0.078 m2. The samples were sieved on board on a sieving table with mesh size of 1 mm.
All samples and rocks were fixed with a borax buffered 5% formaldehyde solution. In the laboratory, all organisms were identified, counted and their biomass (both wet and ash-free dry mass) was measured. Colonial species were noted as present per sample, while their biomass was not determined.
Borkum Reef grounds, oil and gas platforms Neptune Energy & Petrogas GBS, the Netherlands
The Borkum Reef Grounds is an area with geogenic reefs at the border between the Netherlands and Germany. Neptune and Petrogas are oil and gas platforms in the Netherlands. The fauna of the geogenic reefs and large hard substrates from platforms were sampled by scientific divers by scraping, using an airlift sampler with nets of mesh size 0.5 mm27,28,41. Sample size was 0.05 m2. On the scour protection layer around the Neptune platforms, individual rocks or gravel were collected from an area of 0.05 m2. Around the Petrogas Gravity Based structure (GBS), large rocks were sampled by scraping fauna from within a 0.05 m2 frame and collecting it in an airlift sampler with nets of mesh size 0.5 mm. On board, samples were rinsed from the nets and conserved on ethanol 99% or borax buffered formaldehyde 6%. Rocks with epifauna were conserved whole without sieving. In the laboratory, all taxa were identified, counted and weighed (all wet, some also ash free dry mass). Colonial species surface area covered was estimated to the nearest cm2, but the species were not weighed.
Belwind and C-Power offshore wind farms, Belgium
The long-term monitoring of Belgian offshore wind farms started in 200842 and is still ongoing. The monitoring data presented here refer to monopile foundations from the Belwind OWF (since 2010), and jacket and gravity-based foundations from the C-Power park (since 2008). During the first two years, the sampling occurred seasonally (spring, summer, autumn) and across various depths of the selected foundations. Later, the samples were collected once a year in summer or autumn, at approximately 15 m depth and from the scour protection layers. In Belwind, four monopile foundations were sampled throughout the monitoring period, but not simultaneously. In C-Power, the gravity-based turbine D5 was sampled throughout the entire duration of the monitoring, except in 2016 when samples were taken from D6. The jacket foundation from C-Power was sampled only once (one year after installation). The sample size of the scrape samples taken by scientific divers was 0.0625 m2 and scraped material was collected in a plastic zip lock bag. Scour protection layer stones were collected manually by divers and were brought to the surface in plastic sample bags. All samples were preserved in buffered 4% formalin. In the laboratory, the samples were sieved using a 1 mm mesh size sieve and organisms were sorted and identified. Individual species were counted while for colonial species only presence was scored.
Due to the different purposes of the projects from which the data originate, and the various construction periods of the artificial structures, there is variation in the number of samples and the timing of sampling and water and sediment depths at which the samples were taken. The total number of samples per ___location varied from 11 (Borkum Reef) to 1,984 (alpha ventus; Fig. 3). Sampled water depths varied between 0 and 37 m, and some structures were sampled throughout the water column (e.g., FINO 1, Neptune, Horns Rev), while at some locations only the top half of the water column was sampled (e.g., alpha ventus; DanTysk, Sandbank; Fig. 4).

Number of samples taken per ___location and year.

Substrate sampled per ___location and depth. To illustrate variations in the number of samples and variations in substrates at locations at the same depth, a small amount of random noise (jitter) was added to the positioning of the points in the x and y direction. To illustrate variations in the number of samples and variations in substrates at locations at the same depth, a small amount of random noise (jitter) was added to the positioning of the points in the x and y direction.
BISAR is a valuable dataset to investigate the colonising epifauna on different artificial structures and the benthos surrounding the structures. Descriptions and details about the study designs, including reference sites for the different artificial structures, are given in Table 1 (see column DOI (Related papers)). The currently unpublished BISAR collection has already been used in scientific studies e.g., to estimate the effects of decommissioning of offshore wind farms on benthos43; to investigate long-term cumulative impacts of offshore wind farms on biodiversity44; and some of the data have been applied to compare biodiversity on platforms, wind farms and rocky reefs27 and in the analysis of generalised benthic changes after wind-farm construction19. These published studies highlight the potential application of the BISAR data collection.
Data Records
The BISAR data collection is available at figshare45 as part of this publication. The data collection is composed of 11 tables as multi-sheet format (*.xlsx format) and contains primary data and meta-data structured in main tables and lookup tables for further information (Fig. 1). The first table contains a detailed glossary with information on all tables, headers, and units of the data. The following tables and contents are included in the file in separate tabs:
Main tables:
-
Cruise - Data on sampling cruises, including vessel names, dates and region visited.
-
Station - Station coding for stations visited in cruises, dates, coordinates and local depth.
-
Sample - Samples collected at each station, with data on gear type used, sampled area and coordinates and depths of each sample. Here, information on artificial structures, data on the platform type, foundation type, construction material and sample type were included.
-
Biota - Information on the species observed in the samples, with species name, data on the AphiaID as used in WoRMS42 (World Register of Marine Species), number of individuals (i.e., counts of individuals) and presence/absence data, weights (wet, dry or ash free dry mass in g) and fraction of sub sample.
-
Sediment - Sediment characterisation data on samples, with grain sizes, sample weights and loss of mass on ignition.
Lookup tables:
-
Dataset - Information on the datasets and projects that were included in BISAR, including a DOI and short project description.
-
Gear - All gear types used to collect the samples included in BISAR.
-
Taxon - All unique taxa included in BISAR, with WoRMS export data.
-
Person - Names, affiliation and contact information of the scientists leading the projects on which BISAR is based.
-
Lifestage - Different ontogenetic life stages of the species included in the biota sheet, e.g., remarks on whether a species is juvenile, larval, etc.
-
CRS - Coordinate Reference System on which the positions of each station and sample are based.
Summary information for each ___location included in BISAR is provided in Table 1. All datasets are published, some as a supplement to a publication (secondary source), others as data publications (i.e., DOI data publication) (see Table 1).
Technical Validation
This section describes the procedure on how the single datasets from various sources were quality checked and harmonised to combine all data in the BISAR data collection. One of the greatest challenges during the BISAR data compilation was dealing with multiple methods and sampling devices, and the fact that the basic entity of record, i.e., the taxonomy of a species, is subject to change. Taxonomic records of species can change over time as taxa are re-described and given synonyms.
Harmonisation of different datasets requires knowledge of the data. Thus, the compilation, harmonisation and quality control were carried out in an iterative process between data providers and curators (see iterative process, Fig. 1). This process was carried out in several rounds until the datasets could finally be included in the BISAR data collection.
During this iterative ingest, we applied several levels of quality checks. There are two different data scenarios in the compiled dataset: biotic data are provided either as numbers (i.e., counts) or as presence/absence data. Wet mass is only optionally provided and is not available for all datasets. The counts refer to different sampling surface areas from e.g., scrape samples or Van Veen grabs. The applied quality routines compare the given “sampled surface area” with the area of the sampling gear to ensure that count data are set in relation to an area for future standardisation. In addition, we checked the uniqueness of the following quadruple per sample (i.e., per smallest entity of the data collection): (i) AphiaID, i.e., a taxon-specific ID provided by WoRMS46, (ii) life stage (e.g., juvenile), (iii) sieve mesh size, and (iv) taxonomic specification (e.g., cf., indet.). The same AphiaID may be named more than once in the same sample only if it differs in its combination with the three other attributes. Finally, the taxonomy of taxa was controlled by several steps within the data compilation process: (a) taxonomy was synchronised by queries to WoRMS with the respective AphiaID, (b) missing taxa information was added (e.g. taxonomic tree and relatedness of species) and (c) a comprehensive taxa list across the respective datasets was added to the BISAR data collection. This ensures a harmonised taxonomy for all datasets. All these quality component activities lead to repeated compilation of datasets until final inclusion in the BISAR data collection.
Additional data quality checks during the iterative compilation process of BISAR data collection were conducted using the CRITTERBASE Collector App (Fig. 1)47,48. CRITTERBASE is a biodiversity information system hosted by the Alfred Wegener Institute that can handle sample-based and organism related marine data. For a full description of data quality control, see the publication44 and https://critterbase.awi.de/#qc. Our data quality check showed the high-quality harmonisation of international data required an interdisciplinary team of biologists, data and computer scientists as harmonised metadata and high-quality plausibility checks on the reliability of raw data. Therefore, it is recommended that technical and biological expertise is considered across these types of exercises.
Usage Notes
Single data sets may be downloaded from published sources listed in Table 1. The complete BISAR data compilation is published as part of this publication45 (Fig. 1). Further, BISAR data compilation will be available via the CRITTERBASE web portal https://critterbase.awi.de/bisar. Therefore, the entire data collection or excerpts could be downloaded (Table 1). New data additions from ongoing monitoring and new locations will be available by the same web portal in the future.
BISAR includes quality-checked raw and original benthic data from various sources and artificial structure types. Please note that taxa of the BISAR collection were checked for synonyms and actual taxon names via WoRMS during the quality checks. However, biotic data contain the original name (from laboratory analysis), while the valid taxon names (via WoRMS) are provided in the species reference table of BISAR. In addition, the data originate from different laboratories and taxonomists with different degrees of taxonomic precision. For example, the anemone Metridium senile may be reported with different names, i.e., ‘Metridium senile’, ‘Metridium’, ‘Anthozoa’, in the BISAR data collection. As with all benthic raw data, taxonomy must be further harmonised for the user’s purposes, e.g., by combining taxon entries to higher taxonomic levels, as computable analysis corresponds to several taxa. Thus, working with the BISAR data collection needs some level of benthic, taxonomic knowledge.
Counts of individuals and presence/absence data are given in different columns in the BISAR data collection, and may need to be combined for further analysis. The count data refer to different “sampled surface areas” of the different sampling gears (i.e., grab, scrape samples with different sampling areas). The “sampled surface areas” are provided for all samples in BISAR. Thus, users must consider sample size and “sampled surface areas” to standardise count data (e.g., individuals per m2) for the user’s purposes.
The BISAR data compilation summarises the raw data from different projects as our intention was to provide as much details and data from the different studies as possible. Thus, the data are not homogenised, i.e., different sieve mesh sizes and sampling gears. Instead, we provide all necessary information to homogenise the data by the users themselves. We therefore suggest that users working with this data compilation familiarise themselves with the detailed information in the metadata, look-up tables, and glossary of data, which, when combined with benthic knowledge, will help them handle the data properly.
Code availability
The source code for the Collector App for CRITTERBASE - the software for data quality checking and storage - is available as a free download under the open-source BSD 3 licence (https://doi.org/10.5281/zenodo.5724020)48. The software libraries and versions used are referenced in the README.MD file.
References
European Commission. A European Green Deal; Striving to be the first climate neutral continent. A European Green Deal | European Commission europa.eu (2022).
Rusu, E. Marine renewable energy: an important direction in taking the green road towards a low carbon future. Energies 15, 5480, https://doi.org/10.3390/EN15155480 (2022).
GWEC,Global wind report 2021. Global Wind Energy Council, Brussels, Belgium.79 pp. https://gwec.net/wp-content/uploads/2021/03/GWEC-Global-Wind-Report-2021.pdf last visited: 21.11.2022 (2021).
IRENA. Future of wind: Deployment, investment, technology, grid integration and socio-economic aspects (A Global Energy Transformation paper), International Renewable Energy Agency, Abu Dhabi. https://www.irena.org/-/media/Files/IRENA/Agency/Publication/2019/Oct/IRENA_Future_of_wind_2019.pdf (2019).
Wind Europe. Offshore wind energy, Oceans of opportunity. https://windeurope.org/policy/topics/offshore-wind-energy/ last visited: 09.12.2022 (2021).
Duarte, C. M. et al. Is global ocean sprawl a cause of jellyfish blooms? Front. Ecol. Environ. 11(2), 91–97 (2013).
Bugnot, A. B. et al. Current and projected global extent of marine infrastructure. Nat. Sustain. 4, 33–51, https://doi.org/10.1038/s41893-020-00595-1 (2020). 7.
Heery, E. C. et al. Identifying the consequences of ocean sprawl for sedimentary habitats. J. Exp. Mar. Biol. Ecol. 492, 31–48, https://doi.org/10.1016/j.jembe.2017.01.020 (2017).
Firth, L. B. et al. in Oceanography and Marine Biology: an annual review. Vol 54, 1st edn (Eds. Hughes, R. N., Hughes, D. J., Smith, I. P. & Dale A.C.) Ch. Ocean sprawl: challenges and opportunities for biodiversity management in a changing world. 10.1201/9781315368597 (CRC Press, 2016).
Reusch, T. B. H. et al. The Baltic Sea as a time machine for the future coastal ocean. Sci. Adv. 4, eaar8195, https://doi.org/10.1126/sciadv.aar8195 (2018).
Inger, R. et al. Marine renewable energy: potential benefits to biodiversity. J. Appl. Ecol. 46, 1145–1153, https://doi.org/10.1111/j.1365-2664.2009.01697.x (2009).
Witt, M. J. et al. Assessing wave energy effects on biodiversity: the wave hub experience. Philos. Trans. Royal Soc. A. 370, 502–529, https://doi.org/10.1098/rsta.2011.0265 (2009).
Birchenough, S. N. R. & Degraer, S. Science in support of ecologically sound decommissioning strategies for offshore man-made structures: taking stock of current knowledge and considering future challenges. ICES J. Mar.Sci. 77(3), 1075–1078, https://doi.org/10.1093/ICESJMS/FSAA039 (2020).
Galparsoro, I. et al. Reviewing the ecological impacts of offshore wind farms. npj Ocean Sustainability 1, 1, https://doi.org/10.1038/s44183-022-00003-5 (2022).
Coates, D. A., Deschutter, Y., Vincx, M. & Vanaverbeke, J. Enrichment and shifts in macrobenthic assemblages in an offshore wind farm area in the Belgian part of the North Sea. Mar. Environ. Res. 95, 1–12, https://doi.org/10.1016/J.MARENVRES.2013.12.008 (2014).
Lefaible, N., Colson, L., Braeckman, U. & Moens, T. in Environmental Impacts of Offshore Wind Farms in the Belgian Part of the North Sea: Marking a Decade of Monitoring, Research and Innovation (Eds Degraer, S., Brabant, R., Rumes, B. & Vigin, L.) Ch. 5Royal Belgian Institute of Natural Sciences, OD Natural Environment, Marine Ecology and Management, Brussels, Belgium47–64 (2019).
Brzana, R., Janas, U. & Tykarska, M. B. Effects of a 70-year old artificial offshore structure on oxygen concentration and macrobenthos in the Gulf of Gdańsk (Baltic Sea). Estuar. Coast. Shelf. Sci. 235, 106563, https://doi.org/10.1016/j.ecss.2019.106563 (2020).
Degraer, S. et al. Offshore wind farm artificial reefs affect ecosystem structure and functioning: A synthesis. Oceanography 33(4), 48–57, https://doi.org/10.5670/oceanog.2020.405 (2020).
Coolen, J. W. P. et al. Generalized changes of benthic communities after construction of wind farms in the southern North Sea. J. Env. Manage. 315, 115173, https://doi.org/10.1016/j.jenvman.2022.115173 (2022).
Wilding, T. A. et al. Turning off the DRIP (‘data-rich, information-poor’) – rationalising monitoring with a focus on marine renewable energy developments and the benthos. Renew. Sust. Energ. Rev. 74, 848–859, https://doi.org/10.1016/j.rser.2017.03.013 (2017).
Sheehan, E. V. et al. Development of epibenthic assemblages on artificial habitat associated with marine renewable infrastructure. ICES J. Mar. Sci. 77(3), 1178–1189, https://doi.org/10.1093/icesjms/fsy151 (2018).
Bicknell, A. W. J., Sheehan, E. V., Godley, B. J., Doherty, P. D. & Witt, M. J. Assessing the impact of introduced infrastructure at sea with cameras: a case study for spatial scale, time and statistical power. Mar. Environ. Res. 147, 126–137, https://doi.org/10.1016/j.marenvres.2019.04.007 (2019).
BSH. Standard - Investigation of the impacts of offshore wind turbines on the marine environment (StUK4). Hamburg und Rostock, Federal Maritime and Hydrographic Agency (BSH), 86 (2014).
Degraer, S., Brabant, R., Rumes, B. & Vigin, L. Environmental Impacts Of Offshore Wind Farms In The Belgian Part Of The North Sea: Attraction, Avoidance And Habitat Use At Various Spatial Scales. Memoirs on the Marine Environment. Brussels: Royal Belgian Institute of Natural Sciences, OD Natural Environment, Marine Ecology and Management, 104pp (2021).
Helcom. Manual for Marine Monitoring in the COMBINE Programme of HELCOM. Annex C-8 Soft bottom macrozoobenthos. 277-287 (2017).
Rees, H. Biological monitoring: General guidelines for quality assurance. ICES Techniques in Marine Environmental Sciences 32, 1–52, https://doi.org/10.25607/OBP-280 (2004).
Coolen, J. W. P. et al. Benthic biodiversity on old platforms, young wind farms and rocky reefs. ICES J. Mar.Sci. 77(3), 1250–1265, https://doi.org/10.1093/icesjms/fsy092 (2020a).
Coolen, J. W. P. et al. Ecological implications of removing a concrete gas platform in the North Sea. J. Sea Res. 166, 101968, https://doi.org/10.1016/j.seares.2020.101968 (2020b).
Coolen, J. W. P. et al. Marine stepping-stones: Water flow drives Mytilus edulis population connectivity between offshore energy installations. Mol. Ecol. 29(4), 686–703, https://doi.org/10.1111/mec.15364 (2020c).
McLean, D. L. et al. Influence of offshore oil and gas structures on seascape ecological connectivity. Glob. Change Biol. 28, 3515–3536, https://doi.org/10.1111/gcb.16134 (2022).
Murray, F. et al. Data challenges and opportunities for environmental management of North Sea oil and gas decommissioning in an era of blue growth. Mar. Policy. 97, 130–138, https://doi.org/10.1016/j.marpol.2018.05.021 (2018).
Krone, R., Gutow, L., Joschko, T. & Schröder, A. Epifauna dynamics at an offshore foundation – implications of future wind power farming in the North Sea. Mar. Environ. Res. 85, 1–12, https://doi.org/10.1016/j.marenvres.2012.12.004 (2013).
Zintzen, V., Norro, A., Massin, C. & Mallefet, J. Spatial variability of epifaunal communities from artificial habitat: shipwrecks in the southern bight of the North Sea. Estuar. Coast. Shelf Sci. 76, 327–344, https://doi.org/10.1016/j.ecss.2007.07.012 (2008a).
Zintzen, V., Norro, A., Massin, C. & Mallefet, J. Temporal variation of Tubularia indivisa (Cnidaria, Tubulariidae) and associated epizoites on artificial habitat communities in the North Sea. Mar. Biol. 153, 405–420, https://doi.org/10.1007/s00227-007-0819-5 (2008b).
BSH. Standard - Investigation of the impacts of offshore wind turbines on the marine environment (StUK3). Hamburg und Rostock, Federal Maritime and Hydrographic Agency (BSH), 58 (2007).
Teschke, K., Gusky, M., & Gutow, L. Data on benthic species assemblages and seafloor sediment characteristics in an offshore windfarm in the southeastern North Sea. Data in Brief 46,108790, https://doi.org/10.1016/j.dib.2022.108790 (2023).
Leonhard, S. B., & Pedersen, J. Hard bottom substrate monitoring Horns Rev offshore wind farm. Annual status report, 2004. 79 pp (2005).
Leonhard, S. B., & Frederiksen, R. Hard Bottom Substrate Monitoring Horns Rev Offshore Wind Farm 2005. Data Report No. 2. Bio/Consult as. 126 pp (2006).
Vanagt, T., Van de Moortel, L., & Faasse, M. A. Development of hard substrate fauna in the Princess Amalia Wind Farm. eCOAST report 2011036. Oostende, Belgium (2013).
Vanagt, T., & Faasse, M. Development of hard substratum fauna in the Princess Amalia Wind Farm. Monitoring six years after construction. eCOAST report 2013009. Oostende, Belgium (2014).
Coolen, J. W. P. et al. Reefs, sand and reef-like sand: a comparison of the benthic biodiversity of habitats in the Dutch Borkum Reef Grounds. J. Sea Res. 103(1), 84–92, https://doi.org/10.1016/j.seares.2015.06.010 (2015).
Kerckhof, F., Rumes, B., Norro, A., Jacques, T. G. & Degraer, S. in Offshore wind farms in the Belgian part of the North Sea: Early environmental impact assessment and spatio-temporal variability. (Eds. Degraer, S., Brabant, R. & Rumes, B.) Royal Belgian Institute of Natural Sciences, Management Unit of the North Sea Mathematical Models. Marine ecosystem management unit. pp. 53-68 (2010).
Spielmann, V., Dannheim, J., Brey, T. & Coolen, J. W. P. Decommissioning of offshore wind farms and its impact on benthic ecology. J. Environ. Manage. 347, 119022, https://doi.org/10.1016/j.jenvman.2023.119022 (2023).
Li, C. et al. Offshore wind energy and marine biodiversity in the North Sea: life cycle impact assessment for benthic communities. Environ. Sci. Technol. 57, 6455–6464, https://doi.org/10.1021/acs.est.2c07797 (2023).
Dannheim, J. et al. BISAR - Biodiversity Information of benthic Species at ARtificial structures. figshare https://doi.org/10.6084/m9.figshare.28533011 (2025).
WoRMS Editorial Board. World Register of Marine Species. https://www.marinespecies.org at VLIZ. Accessed 2022-11-11. https://doi.org/10.14284/170 (2022).
Teschke, K. et al. CRITTERBASE, a science-driven data warehouse for marine biota. Sci. Data 9(1), 483, https://doi.org/10.1038/s41597-022-01590-1 (2022).
Kloss, P. et al. The Collector’s App for CRITTERBASE, a science-driven data warehouse for marine biota (4.4.4). Zenodo https://doi.org/10.5281/zenodo.5724020 (2021).
Acknowledgements
This work has been discussed, facilitated, and executed by members of the International Council for the Exploration of the Sea (ICES) Working Group on Marine Benthal and Renewable Energy Developments (WGMBRED). This work is in recognition of the importance of good quality international data sets on offshore wind farms. Data of Sandbank, DanTysk were collected on behalf of Vattenfall in the framework of the mandatory monitoring of the German Standard Investigation of the Impacts of Offshore Wind Turbines on the Marine Environment (latest version: StUK 4, published by BSH 2014). Horns Ref data were kindly made available with permission of Vattenfall. Samples of alpha ventus were collected on behalf of the DOTI GmbH & Co. KG in the framework of the German mandatory monitoring (latest version: StUK 4, published by BSH 2014) and collected and quality controlled by the Federal Maritime and Hydrographic Agency (BSH) in cooperation with the Alfred Wegener Institute (AWI). The FINO 1 platform was sampled as part of the research project BeoFINO and BeoFINO II, funded by the German Federal Ministry for the Environment, Nature Conservation and Nuclear Safety (BMU, grant number 0329974 A). The StUKplus Benthos data in the alpha ventus wind farm was sampled as a part of the research project StUKplus (BSH, order number: 0327689 A/AWI3). The Belwind and C-Power data were collected as part of the Belgian offshore wind farm environmental monitoring program, WinMon.BE, coordinated by the Institute of Natural Sciences. Joop Coolen was funded by a contribution from the Dutch Offshore Wind Ecological Programme (WOZEP). Joop Coolen and Ninon Mavraki were funded by a Top Sector Energy Grant from the Ministry of Economic Affairs as part of the project ‘Scour protection design for biodiversity enhancement in North Sea Offshore Wind Farms’ (BENSO) and the Wageningen University Knowledge Base programme: KB36 Biodiversity in a Nature Inclusive Society (project number KB36-004-008) - that is supported by finance from the Dutch Ministry of Agriculture, Nature and Food Quality. Paul Kloss was funded by a contribution of the ANKER project (BSH, order number: FKZ 0325921) and the MARLIN II project (BSH, order number: 10047583). Silvana Birchenough was supported by Cefas Seedcorn and Ecostar (UKRI, INSITE North Sea programme https://insitenorthsea.org/).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
All authors contributed to the conceptual idea of the BISAR data collection arising from the discussions of the WGMBRED meetings. Jennifer Dannheim (J.D.), Paul Kloss (P.K.), Joop W.P. Coolen (J.C.) and Jan Vanaverbeke (J.V.) conceived the idea of the data collection BISAR and developed the project and publication. Data of BISAR were provided by J.D., J.C., Ninon Mavraki (N.M.), Mirta Zupan (M.Z.), Babeth van der Weide (B.W.), Oliver Bittner, Roland Krone, Marco Faasse and Katharina Teschke (K.T.). Quality management and collation of datasets were performed by P.K., J.D., N.M., M.Z., J.V. and Vanessa Spielmann (V.S.). J.D., J.C., N.M., M.Z., V.S., K.T., P.K., K.T., J.V., Emma Sheehan, Urszula Janas, Silvana N.R. Birchenough, Jolien Buyse (J.B.) and Steven Degraer (S.D.) wrote the manuscript. J.D., J.C. developed the figures with contributions from Zoe Hutchison (Z.H.), Paul Causon, Drew A. Carey and Michael Rasser. S.D., Z.H., Andrew B. Gill and Alexa Wrede performed the final revision of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dannheim, J., Kloss, P., Vanaverbeke, J. et al. Biodiversity Information of benthic Species at ARtificial structures – BISAR. Sci Data 12, 604 (2025). https://doi.org/10.1038/s41597-025-04920-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-04920-1
This article is cited by
-
Offshore wind farms modify coastal food web dynamics by enhancing suspension feeder pathways
Communications Earth & Environment (2025)
