
Abstract
Larger cohorts improve the power of tumor gene expression analysis, but the signal is muddied if datasets are processed using different methods or have inaccurate metadata. Here we present five compendia containing consistently processed gene expression data derived from 16,446 diverse RNA sequencing datasets. To create the compendia, we obtained access to RNA sequence data from repositories containing public data as well as clinical partners with access to non-published data. We then assessed the quality, quantified gene expression, harmonized clinical metadata, and released the expression values and metadata without access restrictions. These datasets have been used for diverse projects ranging from identifying similarities between tumor types to assessing how well cell lines recapitulate tumors. They have also been used for n-of-1 analysis to identify genes with unusual expression patterns in a single sample and to infer molecular diagnosis. The comparison to new data is enabled by our dockerized, freely available pipeline. The compendia have been cited in at least 20 publications.
Similar content being viewed by others


Background & Summary
Gene expression profiling is a powerful tool in cancer research. It is used clinically to distinguish tumor subtypes1,2 and to identify potential drug targets3,4,5,6,7. For some cancers, it influences clinical decision making, and can predict survival time and likelihood of recurrence1,8,9,10,11,12. However, genomic data privacy concerns, computational requirements, technical challenges, and the personnel time involved make assembling large cohorts of tumor data difficult13. For rare cancers, such as pediatric cancers, data aggregations from multiple sources are necessary to achieve progress, because the diseases are individually rare and a small cohort of datasets rarely has enough power for sophisticated statistical analysis. We established the Treehouse Childhood Cancer Initiative in 2015 in part to create large compendia of harmonized cancer RNA-sequencing datasets, focused on pediatric cancers, to enable state-of-the-art genomic studies in pediatric oncology.
Our first compendium was compiled in 2016. It included seven pediatric tumor types and 10,368 datasets, where a dataset is data generated from one sample. It was based on our UCSC Genomics Institute colleagues’ uniform processing of RNA-Seq datasets14 from NCI’s The Cancer Genome Atlas (TCGA)15 and the corresponding NCI pediatric study Therapeutically Applicable Research To Generate Effective Treatments (TARGET)16,17,18,19,20.
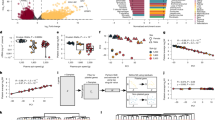
Since then, we have worked to increase the number of pediatric cancer datasets in our compendia. Currently, we have five compendia, including those dedicated to PDX, cell and tumor data, divided by transcript selection method. The compendia now include 16,446 datasets, 5,687 of which are from pediatric, adolescent and young adult individuals (pedaya, Fig. 1). The pediatric datasets span 128 cancer classifications as defined by International Classification of Diseases for Oncology, 3rd Edition, ICD-O-321; 31 classifications are represented by 20 or more datasets. The compendia contain datasets from large sequencing projects such as St. Jude, CBTN/Kids First DRC, and ICGA as well as many smaller single-study projects (Table 1).

Distribution of ages in compendia. The three most common diseases in pediatric, adolescent and young adult (pedaya, age <= 30) datasets in each compendium are specified by color. Datasets without associated ages (n = 974) are excluded from this plot.
To achieve this increased representation of pediatric diseases and types of data in the compendia, we identified candidate datasets by surveying scientific literature and data repositories for studies of gene expression in tumors, PDX and cell lines (Fig. 2). To consider data for inclusion in a compendium, we must know (1) the biological source type, such as tumor, PDX, or cell lines; (2) the method for transcript selection; (3) whether it is paired-end, (4) the kind of cancer, and (highly preferably) (5) the age or pediatric status of the person the cancer was found in. We assessed whether the data is comparable with existing compendia, e.g. does it share a transcript enrichment method and biological source type with an existing compendium? All compendia contain only paired-end data. Access to the sequence data for most of the datasets was controlled and required a multi-step application process. In our applications, we requested permission to redistribute the gene expression values we obtain through processing the sequence data. If we were granted access under these terms, we downloaded the metadata provided by the repository and searched literature for additional metadata. We also obtained datasets from collaborators that had not deposited the data into public repositories, and contributed data from 12 samples we sequenced ourselves. In all of our access requests, we asked to make de-identified aggregate gene expression measurements available to the public on our website.

Steps for assembling a gene expression data compendium derived from RNA sequencing.
Unfortunately, datasets were excluded at each step of the process due to incomplete, inaccurate or missing metadata, underlining the need for simpler access methods and careful consideration of usability before releasing data13. For example, crucial information like transcript enrichment method and disease were not always available in SRA. For one SRA study, we reviewed 4 publications to obtain transcript enrichment method and disease, and yet disease remained undetermined in 7 (nearly 10%) of the datasets. In other SRA records, age and sex were not available on SRA, in the publication, or by communication with the authors. In direct communications, we have received incorrect information about the transcript enrichment method, which was then corrected when we observed high abundance of non-polyadenylated histone transcripts in a nominally polyA-selected dataset. Even when accurate, well-structured metadata is available in a repository, access can be challenging. An EGA dataset had associated articles referring to both RNA-Seq and whole genome sequencing (WGS) data. Only after applying for access to the controlled access dataset were we able to determine that the data was WGS.
If the datasets were sufficiently annotated and appropriate for our compendia, we next added the metadata to our secure REDCap database. If we had permission, we downloaded the FASTQ or BAM sequence data files and processed the sequence data with our dockerized pipeline, generating quality metrics and gene expression quantification values. When we did not have permission to download the raw sequence data, we had two options to generate fully comparable output data. Three institutional partners used option A: deploying our dockerized pipeline to process the sequence data in their own ecosystem and sharing the output with us for incorporation into our compendia. With one institutional partner we used option B: implementing our dockerized pipeline on the institution’s cloud-based platform, processing the data ourselves, and downloading the output. Both of these avenues eliminate the need for raw data transfer and represent important options for harmonizing genomic data, given regulatory and technical restrictions.
Compendia were assembled from comparable gene-level expression data and paired with clinical metadata such as disease type, sex, and age. Data were considered comparable if the same input RNA selection method was used and biological sample types were deemed similar by our analysts. Sequence data generated from poly-A selected RNA and ribo-depleted RNA are in separate compendia, as are data from different sample types such as tumors, in vitro cell cultures, and patient-derived xenograft (PDX) models. The compendia files were then shared with the public via GEO and other sources (see Usage Notes section).
Methods
Data identification
Adult, pediatric, adolescent, and young adult RNA-Seq data and clinical metadata are identified in repositories including Database of Genotypes and Phenotypes (dbGAP/SRA), European Genome-phenome Archive (EGA), Sequence Read Archive (SRA), St. Jude Cloud, and Kids First Data Resource Center, as well as through direct collaborations. Metadata are analyzed to determine whether the data are comparable, and permissions for access are sought.
Metadata processing
The diseases are harmonized, and age and source are compiled and recorded in a REDCap database22. ICD-O-3 harmonized disease values are determined by Treehouse researchers when they are not provided.
RNA extraction, library preparation and sequencing
Twelve QC pass datasets were sequenced internally. TH46_2416_S01 data was generated from a flash frozen tissue sample as previously described4; the RNA had a RIN score of 5.7. For the 5 datasets with IDs TH44_4659_S02-TH44_4659_S06, RNA was extracted from Formalin-Fixed Paraffin-Embedded (FFPE) tumor tissue samples using the truXTRAC FFPE total NA (tNA) Ultra Kit - Column (Covaris) and the ME220 Ultrasonicator System for Adaptive Focused Acoustics (Covaris). For the 6 datasets with IDs TH46_2416_S02, TH46_5187_S01, TH46_5187_S02, TH46_5188_S01, TH46_5188_S02, and TH46_5189_S01, RNA was obtained from flash frozen tissue homogenized in DNA/RNA Shield using ZR BashingBead Lysis Tubes (Zymo) and extracted using Quick DNA/RNA miniprep Kit (Zymo). For all 11, RNA quantity was measured using the Qubit™ High Sensitivity RNA Assay (Thermo Fisher Scientific) and the RNA quality was measured using the Tapestation High Sentisitivity RNA assay (Agilent). The RNA libraries were constructed using the Stranded Total RNA Prep, Ligation with Ribo-Zero Plus Kit (Illumina). Ribosomal RNA was enzymatically depleted from 50–100 ng of total input RNA with a DV200 score of 55% or higher. Reverse transcription was used to convert RNA into cDNA followed by A-tailing, adapter ligation and amplification. The RNA libraries were sequenced using the NextSeq. 1000 System (Illumina). The 200 cycle kit (Illumina) was used to generate 100 bp paired-end sequencing reads and 70–95 million reads per sample. PhiX Control v3 was used as a sequencing run quality control and spiked in at 5%.
Sequence data processing
Gene expression in each sample is uniformly quantified using the dockerized TOIL RNA-Seq pipeline versions from 3.2 to 3.4.114; all of these versions produce bitwise identical RSEM gene expression outputs. The pipeline uses RSEM Version 1.2.2523 for quantification after aligning reads with STAR v 2.3.2a24 using indices generated from the human reference genome GRCh38 and the human gene models GENCODE 23 as described at https://github.com/UCSC-Treehouse/pipelines. Stranded and non-strand-specific data is processed identically. Quality is assessed with the MEND pipeline https://github.com/UCSC-Treehouse/mend_qc25.
Compendia assembly
The metadata database is surveyed to identify datasets relevant to each compendium. The RNA-Seq data must contain at least 10 million mapped exonic, non-duplicate (MEND) reads. Samples are de-duplicated as follows: only one of any set of technical replicates are included (or technical replicates are combined); nominally unrelated samples that have extremely high correlation are investigated as potential duplicates; and samples from the same tumor that might have different biology (e.g. different loci from the same tumor) are retained.
Gene expression outputs from RSEM and tab delimited metadata are processed by the compendium generation script, with arguments to select the desired unit of expression. We also generate a file containing the assignment of colors to diseases to maintain consistency in visualizations across releases and visualization tools.
Compendia names reflect sample type (tumor, cell lines, PDX) and input RNA type (i.e. poly-A RNA, ribo-depleted RNA). The version of the compendium is named with the year and month of publication (for compendia generated in 2021 or later) or sequentially (for compendia generated before 2021).
Compendia distribution
The compendia are published on the NCBI Gene Expression Omnibus (GEO; https://www.ncbi.nlm.nih.gov/gds) and as described in the Usage Notes section.
Data Records
The compendia are available in the NIH’s gene expression omnibus (GEO) repository with the accession numbers in Table 2. Each compendium consists of a metadata table, and two gene expression tables. Gene expression tables contain one row per gene and one column per RNA-Seq result (one dataset). The expression values are in units of log2(TPM + 1) and expected counts. The corresponding metadata table contains one row per dataset identifier and one column for each type of metadata. In Tables 3, 4 below, we summarize the values found in the metadata tables for each compendia.
Tumor and PDX compendia
For tumor and PDX compendia, whether containing polyA-selected data or ribo-depleted datasets, every record has an associated disease annotation (Table 3). Most also have age at diagnosis, sex, the study the data originate from and additional dataset identifiers from the source. All values except age are encoded as strings.
Cell line compendia
Metadata for cell lines differ from tumors (Table 4). Because most (896/932) of our current cell line compendium comes from CCLE, we’ve included the information needed to match CCLE metadata to sequencing data. They include the parent cell line, CCLE identifiers, and corresponding TCGA cohort where relevant. All values except age are encoded as strings.
Technical Validation
Each dataset added to our compendia is subject to rigorous technical validation. We define the technical quality of the dataset on three levels: (1) the quality of the sample preparation and sequencing; (2) accurate metadata; and (3) the impact of batch effects.
First, we address sample and sequencing quality issues. Sample volume, tissue storage and library preparation can lead to low quality RNA-Seq data, and we rarely have access to the quality metrics that would inform us about the details of each step26,27. Instead we infer the quality from the sequencing data. Specifically, we count the number of MEND reads, and use a threshold (10 million MEND reads) that infers a reasonable degree of quality at each step25. Here and subsequently, all references to read counts refer to the number of pairs of reads. Our MEND count threshold is based on the observation that (1) the median number of MEND reads present in a survey of more than 2000 RNA-Seq datasets was 50% of total reads and (2) the average of two major recommendations for sequencing depth (10 million reads from ’t Hoen et al.28 and 30 million reads from ENCODE Project Consortium29) is 20 million reads. Since there are 10 million MEND reads in a typical RNA-Seq dataset of 20 million reads, we set a threshold of at least 10 million MEND reads to accept a dataset into a compendium. We do not consider 10 million MEND reads a recommended depth but a minimum depth at which the dataset is informative.
Secondly, we address metadata accuracy issues by a combination of careful up-front curation and diligent follow-up of anomalies13. When publications and repositories report different metadata for the same samples, our curation team reaches out to originators to resolve the contradiction. Consistently inaccurate metadata, on the other hand, can be difficult to detect. The most common inaccuracy is incorrect reporting of the library preparation method. We review each compendium using the TumorMap visualization tool, which arranges datasets according to similarity of expression values30. On TumorMap, we have seen datasets from one study remain separate from datasets we would expect to be similar based on diagnosis. We reach out to the data originators, explain our observations, and ask them to reconfirm their metadata. In this way, some datasets were ultimately determined to have been generated via a ribosomal RNA depletion library preparation in spite of the initial report that they were generated via polyA selection.
Metadata errors have also been detected during clinical analysis using our Comparative Analysis of RNA Expression (CARE) pipeline7. For example, in one dataset reported to be generated via polyA selection, many non-polyadenylated genes were identified as exceptionally highly expressed relative to the compendium of polyA-selected tumor datasets. However, data had actually been generated via a ribosomal RNA depletion library preparation, and thus the apparent high relative expression was an artifact of the inclusion of non-polyadenylated transcripts. Datasets determined to be in the wrong compendium are removed.
Anomalies can be due to inaccurate metadata, or they can indicate complex biological phenomena. CARE reported that a sample from a teratoma patient was most similar to glioma or glioblastoma. We discussed the finding with the clinician, and a histological review identified glial features. The patient was subsequently diagnosed with gliomatosis peritonei, which has a more favorable prognosis than teratomas without mature glial tissue6.
The third aspect of our technical validation concerns batch effects. Because our data come from different sources (often corresponding to institutions), we assume some batch effects are present. Unfortunately, using a batch effect removal tool like ComBat removes biological signals as well as batch effects31. Instead, when adding datasets, we visualize their correlations to datasets from other sources using TumorMap. For example, we consider the likelihood of batch effects low if the new datasets are dispersed among those from other sources. Figure 3 shows a TumorMap grouping of more than 30 synovial sarcoma datasets that come from four sources. The interspersed placement indicates that the similarity of the datasets is greater than batch effects that might divide them. If, on the other hand, data for a given cancer from one source are consistently placed separately from data from the same cancer from other sources, we revisit the metadata as described above to confirm the datasets are assigned to the correct compendium. If the metadata appears correct, we leave the data in the compendium because the distinct placement may be due to biological phenomena. We encourage users to review correlations across institutions to assess the possible role of batch effects in their analyses.

TumorMap visualization of datasets in the PolyA Tumor compendium version 11. (a) All 12,747 datasets; each point represents one dataset. Position is based on similarity of gene expression. Colors indicate the diagnosis of the donor. The circled group are mostly synovial sarcomas. (b) Synovial sarcoma and related datasets (red are synovial sarcoma; gray are other diseases). (c) Study sources of the synovial sarcoma datasets: SRP126664 (brown), phs000178 (light blue), phs000673.v2.p1 (green), data from two unrelated collaborators that was unpublished at the time of the compendium release (blue).
Usage Notes
Internally, we use our compendia to identify potential druggable targets for individual pediatric cancer patients. Our Comparative Analysis of RNA Expression (CARE) identifies transcripts in a patient’s tumor that have exceptionally high expression relative to all tumors in a particular compendium (pan-cancer analysis) or relative to similar tumors (pan-disease analysis)7. We have analyzed RNA-Seq tumor data from 164 patients and identified clinically relevant genomic information for 1293,4,6,7,25. For at least 8 of the patients, this information was applied, and six of them benefited3,4,6,7.
We and others have used the compendia for a variety of purposes (Table 5). In 2024, our compendia averaged 80 downloads per month.
Our website (https://treehousegenomics.soe.ucsc.edu/public-data) hosts an overview of all compendia, with links to sources for (1) downloading the data GEO (https://www.ncbi.nlm.nih.gov/gds) and Xena (https://xena.treehouse.gi.ucsc.edu)32 and (2) visualizing data without downloading it: the Tumor Map (https://Tumormap.ucsc.edu/?p=Treehouse/TumorCompendium_v11_PolyA), Xena (https://xena.treehouse.gi.ucsc.edu)30 and the UCSC cell browser (https://cells.ucsc.edu/?ds=treehouse)33.
As large aggregations of consistently processed data, gene expression compendia are resource-intensive to assemble. They require ongoing attention to resolve inconsistencies, perform rigorous quality control and incorporate newly available data. However, these efforts have proven worthwhile, yielding contributions to clinical and translational cancer research. Through assembling these data and making them easily accessible, we aim to reduce barriers to entry into the field of pediatric oncology, increase the ability of researchers to make accurate and meaningful contributions, and ultimately advance the wellbeing of children with cancer.
Code availability
Compendia can be generated from a collection of single-dataset expression files using the build_compendium_matrix.py script available on GitHub at https://github.com/UCSC-Treehouse/compendium-expression-matrix and archived at https://doi.org/10.5281/zenodo.15213775.
References
Tomida, S. et al. Gene expression-based, individualized outcome prediction for surgically treated lung cancer patients. Oncogene 23, 5360–5370 (2004).
Xu, X. et al. Differential gene expression profiling of gastric intraepithelial neoplasia and early-stage adenocarcinoma. World J. Gastroenterol. WJG 20, 17883–17893 (2014).
Newton, Y. et al. Comparative RNA-Sequencing analysis benefits a pediatric patient with relapsed cancer. JCO Precis. Oncol. 1–16 https://doi.org/10.1200/PO.17.00198 (2018).
Reed, M. R. et al. A Functional Precision Medicine Pipeline Combines Comparative Transcriptomics and Tumor Organoid Modeling to Identify Bespoke Treatment Strategies for Glioblastoma. Cells 10, 3400 (2021).
Roy, R., Winteringham, L. N., Lassmann, T. & Forrest, A. R. R. Expression Levels of Therapeutic Targets as Indicators of Sensitivity to Targeted Therapeutics. Mol. Cancer Ther. 18, 2480–2489 (2019).
Sanders, L. M. et al. Comparative RNA-seq analysis aids in diagnosis of a rare pediatric tumor. Mol. Case Stud. 5, a004317 (2019).
Vaske, O. M. et al. Comparative Tumor RNA Sequencing Analysis for Difficult-to-Treat Pediatric and Young Adult Patients With Cancer. JAMA Netw. Open 2 (2019).
Beer, D. G. et al. Gene-expression profiles predict survival of patients with lung adenocarcinoma. Nat. Med. 8, 816–824 (2002).
Larsen, J. E. et al. Expression profiling defines a recurrence signature in lung squamous cell carcinoma. Carcinogenesis 28, 760–766 (2007).
Petrosyan, F., Daw, H., Haddad, A., Spiro, T. & Sood, R. Gene Expression Profiling for Early-stage NSCLC. Am. J. Clin. Oncol. 38, 103–107 (2015).
Zhu, C.-Q. et al. Prognostic and Predictive Gene Signature for Adjuvant Chemotherapy in Resected Non–Small-Cell Lung Cancer. J. Clin. Oncol. 28, 4417–4424 (2010).
Kratz, J. R. et al. A practical molecular assay to predict survival in resected non-squamous, non-small-cell lung cancer: development and international validation studies. Lancet 379, 823–832 (2012).
Learned, K. et al. Barriers to accessing public cancer genomic data. Sci. Data 6, 98 (2019).
Vivian, J. et al. Toil enables reproducible, open source, big biomedical data analyses. Nat. Biotechnol. 35, 314–316 (2017).
Hoadley, K. A. et al. Cell-of-Origin Patterns Dominate the Molecular Classification of 10,000 Tumors from 33 Types of Cancer. Cell 173, 291–304.e6 (2018).
Liu, Y. et al. The genomic landscape of pediatric and young adult T-lineage acute lymphoblastic leukemia. Nat. Genet. 49, 1211–1218 (2017).
Chun, H.-J. E. et al. Genome-Wide Profiles of Extra-cranial Malignant Rhabdoid Tumors Reveal Heterogeneity and Dysregulated Developmental Pathways. Cancer Cell 29, 394–406 (2016).
Pugh, T. J. et al. The genetic landscape of high-risk neuroblastoma. Nat. Genet. 45, 279–284 (2013).
Gadd, S. et al. A Children’s Oncology Group and TARGET initiative exploring the genetic landscape of Wilms tumor. Nat. Genet. 49, 1487–1494 (2017).
Farrar, J. E. et al. Genomic Profiling of Pediatric Acute Myeloid Leukemia Reveals a Changing Mutational Landscape from Disease Diagnosis to Relapse. Cancer Res. 76, 2197–2205 (2016).
WHO (World Health Organization). International Classification of Diseases for Oncology. (2000).
Harris, P. A. et al. Research Electronic Data Capture (REDCap) - A metadata-driven methodology and workflow process for providing translational research informatics support. J. Biomed. Inform. 42, 377–381 (2009).
Li, B. & Dewey, C. N. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics 12, 323 (2011).
Dobin, A. et al. STAR: ultrafast universal RNA-seq aligner. Bioinformatics 29, 15–21 (2013).
Beale, H. C. et al. The case for using mapped exonic non-duplicate reads when reporting RNA-sequencing depth: examples from pediatric cancer datasets. GigaScience 10 (2021).
Gallego Romero, I., Pai, A. A., Tung, J. & Gilad, Y. RNA-seq: impact of RNA degradation on transcript quantification. BMC Biol. 12, 42 (2014).
Sarantopoulou, D. et al. Comparative evaluation of RNA-Seq library preparation methods for strand-specificity and low input. Sci. Rep. 9, 13477 (2019).
’t Hoen, P. A. C. et al. Reproducibility of high-throughput mRNA and small RNA sequencing across laboratories. Nat. Biotechnol. 31, 1015–1022 (2013).
ENCODE Project Consortium. Encode Standards, Guidelines and Best Practices for RNA-Seq. (2011).
Newton, Y. et al. TumorMap: Exploring the Molecular Similarities of Cancer Samples in an Interactive Portal. Cancer Res. 77, e111–e114 (2017).
Lee, A. J., Park, Y., Doing, G., Hogan, D. A. & Greene, C. S. Correcting for experiment-specific variability in expression compendia can remove underlying signals. GigaScience 9, giaa117 (2020).
Goldman, M. J. et al. Visualizing and interpreting cancer genomics data via the Xena platform. Nat. Biotechnol. 38, 675–678 (2020).
Speir, M. L. et al. UCSC Cell Browser: visualize your single-cell data. Bioinformatics https://doi.org/10.1093/bioinformatics/btab503 (2021).
Stewart, E. et al. Orthotopic patient-derived xenografts of paediatric solid tumours. Nature 549, 96–100 (2017).
Newman, S. et al. Genomes for Kids: The Scope of Pathogenic Mutations in Pediatric Cancer Revealed by Comprehensive DNA and RNA Sequencing. Cancer Discov. 11, 3008–3027 (2021).
Schwartz, J. R. et al. The acquisition of molecular drivers in pediatric therapy-related myeloid neoplasms. Nat. Commun. 12, 985 (2021).
Umeda, M. et al. Integrated Genomic Analysis Identifies UBTF Tandem Duplications as a Recurrent Lesion in Pediatric Acute Myeloid Leukemia. Blood Cancer Discov. 3, 194–207 (2022).
Barretina, J. et al. The Cancer Cell Line Encyclopedia enables predictive modelling of anticancer drug sensitivity. Nature 483, 603–607 (2012).
Lilly, J. V. et al. The children’s brain tumor network (CBTN) - Accelerating research in pediatric central nervous system tumors through collaboration and open science. Neoplasia 35, 100846 (2023).
Shapiro, J. A. et al. OpenPBTA: The Open Pediatric Brain Tumor Atlas. Cell Genomics 3, 100340 (2023).
Northcott, P. A. et al. Subgroup-specific structural variation across 1,000 medulloblastoma genomes. Nature 488, 49–56 (2012).
Jones, D. T. W. et al. Recurrent somatic alterations of FGFR1 and NTRK2 in pilocytic astrocytoma. Nat. Genet. 45, 927–932 (2013).
Jones, D. T. W. et al. Dissecting the genomic complexity underlying medulloblastoma. Nature 488, 100–105 (2012).
Bender, S. et al. Recurrent MET fusion genes represent a drug target in pediatric glioblastoma. Nat. Med. 22, 1314–1320 (2016).
Honeyman, J. N. et al. Detection of a Recurrent DNAJB1-PRKACA Chimeric Transcript in Fibrolamellar Hepatocellular Carcinoma. Science 343, 1010–1014 (2014).
Simon, E. P. et al. Transcriptomic characterization of fibrolamellar hepatocellular carcinoma. Proc. Natl. Acad. Sci. 112, E5916–E5925 (2015).
Darcy, D. G. et al. The genomic landscape of fibrolamellar hepatocellular carcinoma: whole genome sequencing of ten patients. Oncotarget 6, 755–770 (2015).
Grasso, C. S. et al. Functionally defined therapeutic targets in diffuse intrinsic pontine glioma. Nat. Med. 21, 555–559 (2015).
Perry, J. A. et al. Complementary genomic approaches highlight the PI3K/mTOR pathway as a common vulnerability in osteosarcoma. Proc. Natl. Acad. Sci. 111, E5564–E5573 (2014).
Kohsaka, S. et al. A recurrent neomorphic mutation in MYOD1 defines a clinically aggressive subset of embryonal rhabdomyosarcoma associated with PI3K-AKT pathway mutations. Nat. Genet. 46, 595–600 (2014).
Shern, J. F. et al. Comprehensive Genomic Analysis of Rhabdomyosarcoma Reveals a Landscape of Alterations Affecting a Common Genetic Axis in Fusion-Positive and Fusion-Negative Tumors. Cancer Discov. 4, 216–231 (2014).
Brohl, A. S. et al. The Genomic Landscape of the Ewing Sarcoma Family of Tumors Reveals Recurrent STAG2 Mutation. PLOS Genet. 10, e1004475 (2014).
Robinson, D. R. et al. Activating ESR1 mutations in hormone-resistant metastatic breast cancer. Nat. Genet. 45, 1446–1451 (2013).
Bayliss, J. et al. Lowered H3K27me3 and DNA hypomethylation define poorly prognostic pediatric posterior fossa ependymomas. Sci. Transl. Med. 8, 366ra161 (2016).
McBride, M. J. et al. The SS18-SSX Fusion Oncoprotein Hijacks BAF Complex Targeting and Function to Drive Synovial Sarcoma. Cancer Cell 33, 1128–1141.e7 (2018).
Kotani, Y. et al. Therapeutic Potential of Bromodomain and Extra-Terminal Domain Inhibitors for Synovial Sarcoma Cells. Cancers 16, 1125 (2024).
Chang, M. T. et al. Identifying recurrent mutations in cancer reveals widespread lineage diversity and mutational specificity. Nat. Biotechnol. 34, 155–163 (2016).
Brohl, A. S. et al. Immuno-transcriptomic profiling of extracranial pediatric solid malignancies. Cell Rep. 37, 110047 (2021).
Sun, Z. et al. Integrative analysis of synovial sarcoma transcriptome reveals different types of transcriptomic changes. Front. Genet. 13, 925564 (2022).
Lesluyes, T. et al. Genomic and transcriptomic comparison of post-radiation versus sporadic sarcomas. Mod. Pathol. Off. J. U. S. Can. Acad. Pathol. Inc 32, 1786–1794 (2019).
Winters, J. L. et al. Development and Verification of an RNA Sequencing (RNA-Seq) Assay for the Detection of Gene Fusions in Tumors. J. Mol. Diagn. JMD 20, 495–511 (2018).
Bharathy, N. et al. Preclinical testing of the glycogen synthase kinase-3β inhibitor tideglusib for rhabdomyosarcoma. Oncotarget 8, 62976–62983 (2017).
Scott, M. C. et al. Comparative Transcriptome Analysis Quantifies Immune Cell Transcript Levels, Metastatic Progression, and Survival in Osteosarcoma. Cancer Res. 78, 326–337 (2018).
Wang, X.-T. et al. Malignant melanotic Xp11 neoplasms exhibit a clinicopathologic spectrum and gene expression profiling akin to alveolar soft part sarcoma: a proposal for reclassification. J. Pathol. 251, 365–377 (2020).
Andersson, A. K. et al. The landscape of somatic mutations in infant MLL -rearranged acute lymphoblastic leukemias. Nat. Genet. 47, 330–337 (2015).
Jäger, N. et al. Hypermutation of the Inactive X Chromosome Is a Frequent Event in Cancer. Cell 155, 567–581 (2013).
Pinto, E. M. et al. Genomic landscape of paediatric adrenocortical tumours. Nat. Commun. 6, 6302 (2015).
Qaddoumi, I. et al. Genetic alterations in uncommon low-grade neuroepithelial tumors: BRAF, FGFR1, and MYB mutations occur at high frequency and align with morphology. Acta Neuropathol. (Berl.) 131, 833–845 (2016).
Behjati, S. et al. Recurrent mutation of IGF signalling genes and distinct patterns of genomic rearrangement in osteosarcoma. Nat. Commun. 8, 15936 (2017).
Sturm, D. et al. New Brain Tumor Entities Emerge from Molecular Classification of CNS-PNETs. Cell 164, 1060–1072 (2016).
Northcott, P. A. et al. The whole-genome landscape of medulloblastoma subtypes. Nature 547, 311–317 (2017).
Beale, H. et al. Treehouse compendium of polyA selected RNA-Seq gene expression data from 13,359 tumors. Gene Expr. Omn. https://identifiers.org/geo/GSE294351 (2025).
Beale, H. et al. Treehouse compendium of ribosomal-depletion RNA-Seq gene expression data from 2079 tumors. Gene Expr. Omn. https://identifiers.org/geo/GSE294353 (2025).
Beale, H. et al. Treehouse compendium of polyA selected RNA-Seq gene expression data from 932 cell lines. Gene Expr. Omn. https://identifiers.org/geo/GSE294350 (2025).
Beale, H. et al. Treehouse compendium of polyA selected RNA-Seq gene expression data from 33 PDX. Gene Expr. Omn. https://identifiers.org/geo/GSE294349 (2025).
Beale, H. et al. Treehouse compendium of ribosomal-depletion RNA-Seq gene expression data from 43 PDX. Gene Expr. Omn. https://identifiers.org/geo/GSE294352 (2025).
Comitani, F. et al. Diagnostic classification of childhood cancer using multiscale transcriptomics. Nat. Med. 29, 656–666 (2023).
Song, J., Zhao, Q., Xu, Y. & Zhu, L. A signature of 29 immune-related genes pairs to predict prognosis in patients with neuroblastoma. Int. Immunopharmacol. 88, 106994 (2020).
Gupta, A., Taslim, C., Tullius, B. P. & Cripe, T. P. Therapeutic modulation of the CD47-SIRPα axis in the pediatric tumor microenvironment: working up an appetite. Cancer Drug Resist. 3, 550–562 (2020).
Mittal, K. et al. Targeting TRIP13 in favorable histology Wilms tumor with nuclear export inhibitors synergizes with doxorubicin. Commun. Biol. 7, 1–13 (2024).
Pan, M. et al. The Chemotherapeutic CX-5461 Primarily Targets TOP2B and Exhibits Selective Activity in High-Risk Neuroblastoma. 2021.02.25.432934 https://www.biorxiv.org/content/10.1101/2021.02.25.432934v1 (2021).
Zeng, B. et al. OCTAD: an open workspace for virtually screening therapeutics targeting precise cancer patient groups using gene expression features. Nat. Protoc. 16, 728–753 (2021).
Casillo, S. M. et al. An ERK5-PFKFB3 axis regulates glycolysis and represents a therapeutic vulnerability in pediatric diffuse midline glioma. Cell Rep. 43 (2024).
Zhao, G. et al. Reversal of cancer gene expression identifies repurposed drugs for diffuse intrinsic pontine glioma. Acta Neuropathol. Commun. 10, 150 (2022).
Wang, Y. et al. Meiotic protein SYCP2 confers resistance to DNA-damaging agents through R-loop-mediated DNA repair. Nat. Commun. 15, 1568 (2024).
Gupta, A. et al. Infantile fibrosarcoma–like tumor driven by novel RBPMS-MET fusion consolidated with cabozantinib. Cold Spring Harb. Mol. Case Stud. 6, a005645 (2020).
Savary, C. et al. Depicting the genetic architecture of pediatric cancers through an integrative gene network approach. Sci. Rep. 10, 1224 (2020).
Luck, C., Yu, K., Okimoto, R. A. & Sirota, M. Transcriptional Fidelity Enhances Cancer Cell Line Selection in Pediatric Cancers. 2021.10.01.462682 https://www.biorxiv.org/content/10.1101/2021.10.01.462682v1 (2021).
Sanders, L. M. et al. Machine learning multi-omics analysis reveals cancer driver dysregulation in pan-cancer cell lines compared to primary tumors. Commun. Biol. 5, 1367 (2022).
Warren, A. et al. Global computational alignment of tumor and cell line transcriptional profiles. Nat. Commun. 12, 22 (2021).
Zeng, W. Z. D., Glicksberg, B. S., Li, Y. & Chen, B. Selecting precise reference normal tissue samples for cancer research using a deep learning approach. BMC Med. Genomics 12, 21 (2019).
Acknowledgements
Funding for this work comes from NIH Centers of Excellence in Genomic Science award for Center for Live Cell Genomics. Emily Beazley Kures for Kids Fund St. Baldrick’s Consortium Grant. California Initiative to Advance Precision Medicine. Alex’s Lemonade Stand Foundation. The NextGen Award for Transformative Cancer Research from the American Association for Cancer Research. NIH National Cancer Institute award R50 CA274213. R01 5R01CA243555 (PI: Sweet-Cordero).
Author information
Authors and Affiliations
Contributions
K.L. coordinated efforts to access and collect data from public and private repositories. E.T.K. developed the compendium assembly pipeline and compiled compendia. K.L., E.T.K., A.G. Lyle and H.C.B. uniformly processed data. O.M.V. directed the project as principal investigator and secured funding. S.R.S., A.S.C., and D.H. directed the project and secured funding. L.M.S., K.L., A.G. Lyle, Y.A.V., A.G. Lee, L.C.S., S.G.L. and O.M.V. identified high priority datasets. L.M.S., K.L., A.G. Lyle, Y.A.V., and O.M.V. harmonized disease annotations. A.v.d.B., M.M., K.E.-M., M.J.K., and E.Y.H. generated sequencing data. H.C.B., A.C., A.G. Lyle, S.J. and R.A. wrote the manuscript. All authors reviewed and approved the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Beale, H.C., Learned, K., Kephart, E.T. et al. Consistently processed RNA sequencing data from 50 sources enriched for pediatric data. Sci Data 12, 1134 (2025). https://doi.org/10.1038/s41597-025-05376-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05376-z
