
Abstract
Increasing the efficiency of current forage breeding programs through adoption of new technologies, such as genomic selection (GS) and phenomics (Ph), is challenging without proof of concept demonstrating cost effective genetic gain (∆G). This paper uses decision support software DeltaGen (tactical tool) and QU-GENE (strategic tool), to model and assess relative efficiency of five breeding methods. The effect on ∆G and cost ($) of integrating GS and Ph into an among half-sib (HS) family phenotypic selection breeding strategy was investigated. Deterministic and stochastic modelling were conducted using mock data sets of 200 and 1000 perennial ryegrass HS families using year-by-season-by-___location dry matter (DM) yield data and in silico generated data, respectively. Results demonstrated short (deterministic)- and long-term (stochastic) impacts of breeding strategy and integration of key technologies, GS and Ph, on ∆G. These technologies offer substantial improvements in the rate of ∆G, and in some cases improved cost-efficiency. Applying 1% within HS family GS, predicted a 6.35 and 8.10% ∆G per cycle for DM yield from the 200 HS and 1000 HS, respectively. The application of GS in both among and within HS selection provided a significant boost to total annual ∆G, even at low GS accuracy rA of 0.12. Despite some reduction in ∆G, using Ph to assess seasonal DM yield clearly demonstrated its impact by reducing cost per percentage ∆G relative to standard DM cuts. Open-source software tools, DeltaGen and QuLinePlus/QU-GENE, offer ways to model the impact of breeding methodology and technology integration under a range of breeding scenarios.
Similar content being viewed by others

Introduction
Designing the best structure for a breeding program, within the resources available, are important decisions to be made at the onset of cultivar development1,2. In forage breeding, there are a range of well proven and commonly used methods based on half-sib and full-sib family recurrent selection3,4, which have often been adapted to suit specific breeding objectives. Today, genomic selection and marker-aided breeding approaches5,6,7 together with high throughput, non-destructive phenotyping platforms8,9,10,11 provide new opportunities for plant breeders to improve the efficiency and accuracy of conventional plant breeding strategies.
The cost and time required for phenotypic assessment limits the efficiency of screening traits in crops and forages. This is particularly the case for evaluating yield or stress related traits such as DM yield, increased tolerance to abiotic stress, or water use efficiency12. Breeding focused on improving growth is often constrained by destructive methods of biomass measurement across multiple genotypes evaluated in field trials13. The application of powerful sensors and digital tools can help in accurate trait quantification14. In the past five years adoption of these phenomics based technologies and tools in crops and forages has increased markedly8,11,14,15,16,17.
Questions associated with optimisation of breeding strategies are complex, compounded by cost and uncertainty of changing a system, even if the existing system may be delivering less genetic gain, be less nimble or address fewer traits than desired. Decision support software enables simulation of breeding strategy efficacy in response to factors including selection among and within genetic families, different combinations of year, season, site and replicate with associated costs per selection cycle. Such software help breeders design and implement more efficient and effective breeding programs based on predicted genetic gain. To date this has been focused on simulation for inbred species18,19,20, leaving a gap in obligate outcrossing species such as forage grasses. Recent efforts to address this gap have led to the development of two decision support software packages for plant breeding: the tactical tool DeltaGen21 based on deterministic modelling; and the strategic tool QuLinePlus22 a component of QU-GENE18 based on stochastic modelling. QuLinePlus is a breeding module, specifically designed to simulate full and half sibling breeding programs for outcrossing species and QU-GENE is considered as an engine which generates the simulation inputs. Concurrently, new phenomic tools for electronic automation, acceleration and standardisation of data collection for key traits such as DM yield have been developed8, and are being deployed in field breeding programs23. Genomic prediction models have recently been developed and assessed for complex traits, including DM yield24 and nutritive value25 in perennial ryegrass (Lolium perenne). Understanding the implications of these new technologies on genetic gain over time is pivotal to ensuring their use is optimized.
The availability of Ph and GS tools for forage plant breeding, and of decision support simulation tailored for outbred species, gives rise to the opportunity to examine the relative costs and impact of options for integrating these tools into breeding systems. This paper aims to investigate, using modelling and simulation, the relative efficiency of five half sib (HS) breeding methods based on predicted genetic gain and associated costs to improve DM yield of perennial ryegrass. Simulation was conducted applying tactical deterministic and strategic stochastic decision support modelling software (i.e. DeltaGen and QU-GENE) based on a “mock data” set of 1000 HS families, created by combining DM yield data from two sets of field trials. A key objective of this paper is also to demonstrate the potential application of the combination of DeltaGen/QU-GENE, to expand the scope of tools available to breeders in decision support for breeding program design.
The five HS family breeding methods simulated were: (a) standard phenotypic among half-sib family selection (Ap), (b) among half-sib family selection based on phenomics (APh), (c) standard phenotypic among half-sib family selection and within family genomic selection (ApWgs), (d) among half-sib family selection based on phenomics and within family genomic selection (APhWgs), (e) both among and within half-sib family selection based on genomic selection (AgsWgs).
Material and methods
Deterministic modelling for estimating genetic gain using HS family breeding strategies
The genetic gain simulation analyses were conducted using the open source software DeltaGen21 (available via https://deltagen.agresearch.co.nz/app/deltagen) for single selection cycles. The constructed mock data matrices of 200 HS and 1000 HS families used to generate starting points for the simulation of breeding methods, were compiled using perennial ryegrass DM yield and growth score measurements generated from two sources of multi-year-season-___location trials. The term starting points referred to in this paper, are a common set of HS family means, estimates of additive genetic/interaction variance components and narrow sense heritabilities, applied in the different breeding equations used for deterministic modelling and simulation of the five breeding methods using DeltaGen.
Construction of the 1000 and 200 HS family “mock data” matrices of perennial ryegrass
Prediction of differences in genetic gain ∆G among breeding strategies is based on the application of quantitative genetic models3,4. These genetic analyses require estimates of population parameters; phenotypic variance (\({\sigma }_{P}^{2}\)), additive genetic variance (\({\sigma }_{A}^{2}\)), different components of genotype-by-environment (GE) interaction such as HS family interactions with; year, season and ___location, depending on breeding objectives, and narrow sense heritability (\({h}_{n}^{2}\)). In our investigation using deterministic simulation, a key criterion for modelling the impact of GS and Ph technologies on the relative efficiency of HS family breeding methods, was to use mock data sets constructed from actual HS family multi ___location- year-season field trials rather than using in silico generated data. These mock data matrices enabled “realistic” estimates of genetic parameters to be generated. It is important to note that these estimates were only used as starting points to conduct simulation of the breeding methods using DeltaGen. Two mock DM yield data matrices, of 1000 HS and 200 HS families, were created by combining data generated from multi-___location, year and season, HS family evaluation studies reported by Faville et al.24 and Arojju et al.26.
The 1000 HS family DM yield mock data set was based on field trials conducted across 2 locations over 2 years and 3 seasons per year. The mock data set was constructed so that each ___location had a 20 row-by-50 column design with 3 replicates. The herbage DM yield data matrix consisting of 200 HS families was constructed from a random sample of 200 families taken from the 1000 HS family matrix. The year (\(n\)=2), season (\(n\)=3) and ___location (\(n\)=2) data associated with each of the 200 randomly sampled HS families, were combined into a 3 replicate, row and column (10 rows- by-20 columns) by ___location, season and year design matrix. A detailed description of construction of the two mock data sets is provided in supplementary material 1 in File S1, and the distribution of the 200 and 1000 HS family DM yield data are presented in Figure S1.
It is important to note that a key assumption used for quantitative genetic analysis and modelling of the mock data, was that both the 200 HS and 1000 HS families were generated from parents randomly sampled from the same random mating population, cross pollinated under isolation. The coefficient of inbreeding (\(F\)) was assumed to be zero \((F=0)\) and therefore the among HS family (\({\sigma }_{f}^{2}\)) variation provided an estimate of ¼ \({\sigma }_{A}^{2}\) (additive genetic variation)27.
Data analysis
The two HS family mock data matrices (provided as supplementary material 2) were analysed using Eqs. 1 and 2 below, to derive estimates of additive genetic variation, associated genotype-by-environment (GE) interaction and narrow sense heritability on a family mean basis. A linear mixed model (Eq. 1) using the Residual Maximum Likelihood (REML)28,29,30 procedure in DeltaGen21 was used to estimate genetic parameters to be used for modelling based on breeding equations.
The linear mixed model used for analysis across locations, seasons and years:
\({Y}_{ijklmno}\) is the value of an attribute measured from HS family \(i\) in column \(o\) and row \(n\) of replicate \(m\) at ___location \(j\) in season \(k\) of year \(l\), and \(i=\) 1,…, \({n}_{f}\); \(j=\) 1,…,nl, \(k=1\),…,\({n}_{s}\); \(l=1\),…, \({n}_{y}\); \(m=\) 1,…, \({n}_{b}\); \(n=1\),…, \({n}_{r}\); \(o=1\),…,\({n}_{c}\); where f, \(l\), \(s\), \(y\), \(b\), \(r\) and \(c\), are families, locations, seasons, years, replicates, rows and columns, respectively; \(M\) is the overall mean; \({f}_{i}\) is the random effect of family \(i\), \(N(0, {\sigma }_{f}^{2});\) \({l}_{j}\) is the fixed effect of ___location \(j\); \({\left(fl\right)}_{ij}\) is the effect of the interaction between family \(i\) and ___location \(j\), \(N(0,{\sigma }_{fl}^{2})\); \({s}_{k}\) is the fixed effect of season \(k\); \({\left(fs\right)}_{ik}\) is the effect of the interaction between family \(i\) and season \(k\), \(N(0,{\sigma }_{fs}^{2})\); \({y}_{l}\) is the fixed effect of year \(l\);\({\left(fy\right)}_{il}\) is the effect of the interaction between family \(i\) and year \(l\), \(N(0,{\sigma }_{fy}^{2})\); \({b}_{jklm}\) is the random effect of replicate \(m\) within ___location \(j\), within season \(k\), within year \(l\), \(N(0,{\sigma }_{b}^{2})\); \({r}_{jklmn}\) is the random effect of row \(n\) in replicate \(m\) within ___location \(j\), within season \(k\), within year \(l\), \(N(0,{\sigma }_{r}^{2})\); \({c}_{jklmno}\) is the random effect of column \(o\) in row \(n\) in replicate \(m\) within ___location \(j\), within season \(k\), within year \(l\), \(N(0,{\sigma }_{c}^{2})\); \({\varepsilon }_{ijklmno}\) is the residual effect for family \(i\) in row \(n\) and column \(o\) in replicate \(m\) in ___location \(j\) in season \(k\), during year \(l\), \(N(0,{\sigma }_{\varepsilon }^{2})\).
The estimates of variance components generated from Eq. 1, were used to generate an estimate of narrow sense heritability, \({h}_{n}^{2}\), for herbage DM yield on a family mean basis using Eq. 2.
where \(n\), number of and f, l, s, y and r, are families, locations, seasons, years and replicates, respectively.
DeltaGen generated estimates of narrow sense heritability (\({h}_{n}^{2}\)) on a HS family mean basis across locations, seasons and years31.
Breeding methods and associated prediction equations
The five breeding methods assessed in this study were:
-
(a)
Standard phenotypic among HS family selection (Ap): Elite HS families are selected based on phenotypic performance within or across environments. Equal numbers of remnant seed from each selected HS family are randomly sampled. The selected individuals become the parents of the next generation. The prediction equation for genetic gain4,
$$\Delta G={k}_{f}c\frac{\frac{1}{4}{\sigma }_{A}^{2}}{{\sigma }_{PF}}$$(3)where, \({k}_{f}\), is among family selection intensity; \(c\), parental control factor; \({\sigma }_{A}^{2}\), additive genetic variance;\({\sigma }_{PF}\), the phenotypic standard deviation among families. For HS family selection c = 0.5 as selection is on female gametes only27.
-
(b)
Among HS family selection using LiDAR (light detection and ranging) based phenomics (APh): as per (a), elite HS families are selected but based on phenotypic data collected using a LiDAR based phenomic tool8. The precision of genetic gain estimated using breeding Eq. (3) will depend on the accuracy of the phenomics method applied.
-
(c)
Standard phenotypic among HS family selection and within HS family genomic selection (ApWgs): This breeding method consists of the steps: (i) select elite HS families, using a predetermined selection pressure, based on standard phenotypic measurements as per (a); (ii) equal numbers of remnant seed from each selected HS family are randomly sampled, seedlings established and individually genotyped, individual genomic-estimated breeding values (GEBV’s) determined using genomic prediction, and the best seedlings within each family based on their GEBV’s are selected on a predetermined selection pressure; (iii) the selected individuals become the parents of the next generation. The genomic prediction model used in step (ii) is itself derived using standard phenotypic measurements from the HS field trial and DNA marker data from the maternal parents of the HS families24,32,33. The equation for predicting genetic gain,
$${\mathrm{A}}_{p}{\mathrm{W}}_{gsY}={k}_{f}{c}_{f}\frac{\frac{1}{4}{\sigma }_{AY}^{2}}{{\sigma }_{PF}}+{k}_{w}{c}_{w}{h}_{X}{r}_{A-XY}\frac{\surd 3}{2}{\sigma }_{AY}$$(4)where, \({\mathrm{A}}_{p}{\mathrm{W}}_{gsY}\) is the predicted ∆G for trait Y using a combination of standard phenotypic among HS family selection and within HS family genomic selection; \({\sigma }_{AY}^{2}\), additive genetic variance for primary trait Y; \({\sigma }_{AY}\), standard deviation of additive genetic variance for primary trait \(Y\); \(\sqrt{\frac{3}{4}}=\frac{\sqrt{3}}{2}\); \({\sigma }_{PF}\), among HS family phenotypic standard deviation; \({k}_{f}\) and \({k}_{w}\), among and within family selection intensity, respectively; \({c}_{f}\) (= 0.5) and \({c}_{W}\) (= 0.5) among and within family parental controls, respectively; \({h}_{X}\) , square root of heritability for secondary trait \(X\); \({r}_{A-XY}\), genomic prediction accuracy – Pearson’s correlation between Phenotypic Estimated Breeding Values – BLUP’s \(Y\) and GEBV’s \(X\). In GS, the assumption is \({h}_{X}\) =134,35. Please note that the subscript \(gsY\) in Eqs. 4 and 5 is for genomic selection (\(gs\)) for trait \(Y\). This is based on correlated response where, trait \(Y\) (the true breeding value of an individual) is indirectly selected based on selection for trait \(X\) (the GEBV of that individual).
-
(d)
Among HS family selection using LiDAR based phenomics (Ph) and within family genomic selection (APhWgs): as per (c) except that elite HS families are selected based on data collected using a LiDAR based Ph tool.
-
(e)
Both among and within HS family selection based on genomic selection (AgsWgs): This breeding method is implemented in cycle 2 using the HS families generated using the ApWgs method (c). In this scenario, following application of ApWgs, a second cycle of selection is completed using only genomic prediction. To achieve among family selection based on GEBV’s, a predetermined number of seeds is randomly sampled from each HS family and the seedlings genotyped. The marker information is used in the already-established genomic prediction model to generate GEBV estimates and a mean GEBV for each family is determined. Based on the required selection pressure, HS families are selected on their GEBV means. Within-family selection of the chosen HS families, using a predefined selection pressure, is applied to family members based on their individual GEBV estimates, as per (c). The selected individuals form the parents of the next generation. The equation used for predicting genetic gain21,
$${\mathrm{A}}_{gsY}{\mathrm{W}}_{gsY}={k}_{f}{c}_{f}{h}_{X}{r}_{A-XY}\frac{1}{2}{\sigma }_{AY}+{k}_{w}{c}_{w}{h}_{X}{r}_{A-XY}\frac{\surd 3}{2}{\sigma }_{AY}$$(5)where the terms in the above equation have been defined in equation 4.
Genomic selection
For the purposes of this exercise, the cost of conducting GS was defined as the cost per GEBV. The costing was based on a non-commercial research laboratory, the Forage Genetics GBS facility at AgResearch, and includes consumables and time. All steps from extracting DNA through genotyping-by-sequencing (GBS) to generate a GEBV are addressed in supplementary material 1, Table S1: DNA isolation, GBS library development, GBS library sequencing, bioinformatic processing and genotype calling from raw GBS data, and genomic prediction (GEBV determination). Seedling grow-out and tissue sampling were not included as it is expected tissue samples for DNA isolation would be provided. The GBS process, including data filtering steps, is largely as described by Faville, et al.24 except that it is conducted at a 384-plex scale (376 samples plus four blanks and four positive controls per library) instead of 96-plex (94 samples plus one blank and one positive control).
Phenomics, sampling and field trial operational costs
The Ph referred to in this paper is a LiDAR based mobile platform for non‑invasive vegetative biomass and growth rate estimation in perennial ryegrass. The accuracy of 0.90 was determined from LiDAR based volumetric estimates compared against fresh weight and dry weight data across different ages of plants, seasons, stages of regrowth, sites, and row plot (two 2 m rows 15 cm apart) configurations23. The costs (New Zealand $) per sample; based on perennial ryegrass herbage DM derived via harvest and via Ph were $7.50 and $0.87, respectively. These sampling costs were obtained from multi-year, season and ___location field trials, based on row plots, which generated the original data used to build the 1000 HS family data matrix. The cost information is provided in supplementary material 1, Table S2.
Stochastic modelling of multiple selection cycles using HS family breeding strategies
Stochastic modelling of the three breeding strategies Ap, ApWgs and AgsWgs were conducted using QuLinePlus22, available via https://sites.google.com/view/qu-gene, with modifications to the software to implement GS. The objective of this modelling was to generate trends of response to selection over multiple breeding cycles, based on populations of similar size used in deterministic modelling.
The breeding strategies; Ap, ApWgs and AgsWgs were simulated across ten selection cycles using QuLinePlus software. The three strategies were compared for percentage of genetic gain per year (%ΔG), cumulative genetic gain (ΣΔG), allele fixation rate, genetic variance and prediction accuracy across multiple selection cycles. Each generated value is an average 250 iterations.
Generation of the initial training population for simulation in QuLinePlus
Two sets of training populations consisting of 196 and 980 HS families, hereafter referred to as Sim200 and Sim1000, were simulated. Beginning with experimentally derived information on phenomic and associated genomic data from a commercial breeding population consisting of 98 plants, QuLinePlus software was used to generate 98 HS families. These HS families were used to simulate their performance for DM yield for three years across three locations. From each of the evaluated families two random individuals were drawn to generate a training population of 196 plants (Sim200) and ten random individuals were drawn to generate a second training population of 980 plants (Sim1000). It is important to note that the 200 and 1000 HS families used in deterministic modelling were related, the former a random sample from the latter.
Defining the genetic model and trait architecture
A recombination map with seven linkage groups was constructed based on a genetic map36 using the genomic markers from the initial population (98 individuals). In total, 1807 segregating markers were assigned to the seven linkage groups, out of which 474 were QTLs with an additive gene model. The allelic effect of each QTL was estimated based on genome-wide association analysis for DM yield implemented using GAPIT37.
Narrow sense heritabilities on a family mean basis, estimated from mixed model analysis in DeltaGen using data for mean DM yield of the simulated 200 HS and 1000 HS families, were converted to single plant-based heritabilities (considering 30 plants per plot).
Genomic prediction
A genomic prediction model was generated using marker and phenotypic data from the training populations, Sim200 and Sim1000. The GEBVs for each individual plant were estimated using a standard BLUP procedure using the R package rrBLUP38. The heritability estimate of GEBVs was considered as 0.95, rather than 1.00, to account for genotyping error.
Breeding strategies
The breeding strategies Ap, ApWgs and AgsWgs were simulated in QuLinePlus using the modelling options available for each method.
-
(a)
Among half-sib family phenotypic selection (Ap): Using Sim200 and Sim1000 training populations, the Ap strategy was performed by randomly intermating all individuals to generate 196 and 980 HS families. These HS families were evaluated for DM yield in two environments for two years using three replicates and 30 plants per plot. From these trials, among family selection pressures of 20% and 2% were applied to select the best families. To restore the initial number of parents in the training population (196 and 980) for the next selection cycle, random samples of 5 (2.77%) and 50 (27.77%) individuals from the best 20% and 2% HS families were taken and used as parents to generate progeny for the next selection cycle. Each selection cycle was completed in three years (years 1 and 2—field evaluation and selection, and year 3—random mating of selected parents and half-sib family generation).
-
(b)
Among half-sib family phenotypic selection and within family genomic selection (ApWgs): In this breeding strategy, HS families were phenotypically evaluated as described in (a) and among family selection pressures of 20% and 2% were applied based on phenotype. However, within family selection was based on GEBVs estimated using the rrBLUP genomic prediction model. The GEBVs were ranked and the top 5 (2.77% within family selection pressure) or 50 (27.77% within family selection pressure) individuals from the best 20% and 2% families, respectively, were selected as parents for the next cycle. Each selection cycle was completed in three years (years one and two—field evaluation and selection, and year three—random mating of selected parents and half-sib family generation).
-
(c)
Among and within half-sib family selection based on genomic selection (AgsWgs): The AgsWgs strategy was similar to ApWgs, with the only difference at the stage of among family selection, which was based on GEBVs rather than phenotypic measurements. Among and within family selection pressures were the same as the ApWgs strategy, with 20% and 2% among family selection pressure and 2.77% and 27.77% within family selection pressure. It is important to note that this breeding strategy was conducted in one year.
Simulation output
Percentage genetic gain (%∆G) for all three breeding strategies was based on BLUP mean differences between selection cycles. The percentage genetic gain per year was calculated by dividing total predicted %∆G by the number of years per cycle. Cumulative genetic gain (Σ∆G) was calculated as the BLUP mean in each cycle relative to that in cycle zero. Allele fixation rate was computed within the QuLinePlus software to determine the percentage of fixed alleles in each cycle for the trait under selection. Genomic prediction accuracy was computed as the Pearson correlation coefficient between the true breeding value and their GEBVs. Percentage change of genetic variance across selection cycles was computed relative to cycle zero, considered as 100%.
Results
Deterministic modelling
Variance component analysis indicated significant (P < 0.05) additive genetic variation (\({\sigma }_{A}^{2}\)) for herbage dry matter (DM) yield among the HS families within each of the two mock data matrices, consisting of 200 and 1000 entries (Table 1). There were significant (P < 0.05) family-by-season (\({\sigma }_{AS}^{2}\)) and family-by-___location (\({\sigma }_{AL}^{2}\)) interactions estimated from the 200 HS matrix but family-by-year (\({\sigma }_{AY}^{2}\)) was not significant (P > 0.05) in this dataset. The estimates of family-by-season (\({\sigma }_{AS}^{2}\)), family-by-___location (\({\sigma }_{AL}^{2}\)) and family-by-year (\({\sigma }_{AY}^{2}\)) interactions were all significant (P < 0.05) for the 1000 HS family DM yield matrix. HS family narrow sense heritability (\({h}_{n}^{2}\)) estimates for DM yield, based on family mean performance across years, seasons and locations, were moderate for both data matrices, the 1000 HS family derived estimate being higher (Table 1). The estimates were within the range reported for perennial ryegrass24,39,40. The estimated genetic parameters, from REML analysis, presented in Table 1 were used as starting points in the different breeding equations to predict genetic gain.
Predicted genetic gain based on the 200 HS family mock data matrix
Applying the among HS family phenotypic selection method (Ap), at a selection pressure of 20%, to the seasonal DM yield data, predicted a 1.43% increase in DM yield above the population mean of 200 HS families (Table 2). Using phenomics with an accuracy of 0.90 for estimating DM yield generated from APh, a 1.29% increase in DM yield was predicted. The cost per %ΔGc using Ap was higher than that when APh was applied. However, using APh reduced the cost per %ΔGc by 25%. The final number of selected parents decreased from 40 at 20% selection pressure to 4 individuals at 2% selection pressure (Table 2).
The results of predicted ∆G presented in Tables 3 and 4 were generated from two cycles of HS family selection for increasing herbage DM yield. Cycle 1 (C1) (Table 3) was based on the ApWgs method in which the same among and within family selection pressures of 20%/10% (among/within family), 10%/5%, 5%/1% and 2%/1%, were applied at each level of accuracy rA (0.26, 0.36, 0.46). Cycle 1 consisted of 3 years. Cycle 2 (C2) (Table 4) used genomic selection for both the among and within family selection (AgsWgs) applying selection pressures of 20%/10% and 10%/5%. Cycle 2, a single year, was based on 100 HS families each taken from the 2000 HS and 500 HS families generated in C1 at selection pressures of 20%/10% and 10%/5%, respectively. In addition to rA values of 0.26, 0.36 and 0.46, an additional level of accuracy, rA of 0.12, was applied in C2 to model a scenario of declining accuracy due to decay of genetic relationships (Table 4).
In C1 (Table 3), the predicted %ΔG per cycle rose as rA was increased. In this cycle, the combination of increasing among HS family phenotypic selection pressure (2%) and within family genomic selection pressure (1%), at high rA (0.46), resulted in the highest ΔG of 6.35%, based on data from the Ap seasonal herbage DM yield sampling method. The cost per percentage gain was a low $27,397 compared to the high $111,819 at among and within HS family selection pressures of 20% and 10%, respectively, at rA of 0.26. However, while the low selection pressures and rA resulted in the selection of 400 parents, the high selection pressure and rA lead to identifying only 4 parents (Table 3). As expected, the predicted ΔG per cycle, under the APh strategy phenomics assessments of seasonal herbage DM in C1, was slightly lower than Ap, but there was a substantial increase in cost efficiency per % genetic gain (Table 3).
Cycle 2 (Table 4) was based on genomic selection among and within (AgsWgs) 100 HS families generated from selected parents from C1 at 20%/10% and 10%/5% selection pressure and at rA values of 0.26, 0.36 and 0.46. In C2, ΔG was estimated relative to the new mean of HS progeny generated from C1, within each combination of % selection pressure and rA. The predicted ΔG per cycle ranged from 2.05% at rA 0.26 to 3.59% at rA 0.46, at among and within family selection pressures of 20%/10%. Applying higher selection pressures (10%/5%) at rA values of 0.26 and 0.46, increased the range of predicted ΔG per cycle to 2.44% and 4.27%, respectively. Predicted ΔG combined across selection C1 and C2 resulted in totals ranging from 4.93% to 7.58% at rA 0.26 and 0.46, respectively, at among and within selection pressures of 20%/10% (Table 4). At the same rA values of 0.26 and 0.46 at among and within HS family selection pressures of 10%/5%, the predicted ΔG combined across cycles C1 and C2 were 5.93% and 9.06%, respectively. Comparing the costs per percentage predicted ΔG, combined across cycles C1 and C2, the total of $148,418 at rA 0.26 and 20%/10% among and within family selection pressures was over double the cost, $71,711 at rA 0.46 at 10%/5% selection pressures. The number of elite parents selected on GEBV’s at the end of C2 were 200 and 50 based on the among and within family selection pressures of 20%/10% and 10%/5%, respectively (Table 4). These results assumed that the rA values, 0.26, 0.36 and 0.46, did not change from C1 to C2. The effect of possible genomic accuracy decay on ΔG in C2 was assessed using a rA of 0.12. This resulted in diminished ΔG and increased costs ($) per % ΔG. However, even at the reduced rA of 0.12, the additional predicted ΔG in the single year of C2 provided an increase in total gain across cycles C1 and C2.
Predicted genetic gain based on the 1000 HS family mock data matrix
The trend of response to selection for DM yield based on the 1000 HS families was the same as that observed from the 200 HS family simulations. Using DM cut phenotypic data (Ap) the predicted ΔGc ranged from 1.90 at 20% among HS family phenotypic selection pressure to 3.62% at 1% selection pressure (Table 5). The large population of HS families resulted in higher numbers of parental half-sibs being selected, compared to the 200 HS family dataset. This ranged from 200 parental HS families at 20% selection pressure to 10 families at 1%. The application of phenomics based DM assessment (APh) clearly indicated its impact on reducing costs ($) per %ΔGc by 58%.
Analyses involving 1000 HS families (Tables 6 and 7) generated results analogous to those from the 200 HS families (Tables 3 and 4). The application of the ApWgs breeding strategy to the 1000 HS families in C1 resulted in predicted ΔGc ranging from 3.69% to 8.10% at among/within selection pressures of 20%/10% and 2%/1% at rA values of 0.26 and 0.46, respectively. While the predicted ΔGc from applying APhWgs at similar combinations of selection pressures and rA values was lower, there was a considerable reduction in cost ($) per %ΔG that ranged from 10 to 40%. The number of selected parental HS families in C1 at the among and within family selection pressure combinations of 5%/1% and 2%/1%, resulted in selection of less than 100 HS families, 50 and 20, respectively (Table 6).
Genomic among and within family selection was conducted in C2, in a single year, on 100 HS families from C1 generated at 20%/10% and 10%/5% selection pressure at rA values of 0.26, 0.36 0.46. Trends in ΔGc mirrored those observed with the 200 HS family dataset, but the level of gain was consistently higher. The AgsWgs applied resulted in predicted ΔGc ranging from 2.53% at rA 0.26 to 4.41% at rA 0.46 at among and within family selection pressures of 20%/10% (Table 7). At selection pressures of 10%/5% and rA values of 0.26 and 0.46, predicted ΔGc cycle increased to 3.00% and 5.23%, respectively. Combining %ΔG across C1 and C2 resulted in total ΔG ranging from 6.22% to 9.48% at rA 0.26 and 0.46, respectively, at selection pressures of 20%/10%. At the same rA values of 0.26 and 0.46 and selection pressures of 10%/5%, the predicted %ΔG combined across selection C1 and C2 was 7.49% and 11.33%, respectively. The total combined costs per %ΔG across cycles 1 and 2, were $273,392 at rA equal to 0.26 at 20%/10% among and within family selection pressures was over twice the cost, $113,901 at rA 0.46 at 10%/5% selection pressures. The elite parents selected on GEBV’s at the end of cycle 2 were 200 individuals and 50 individuals based on the selection pressures of 20%/10% and 10%/5%, respectively (Table 7). As in the 200 HS family analysis, the effect of a possible scenario of rA decay on ΔG in C2 was assessed using a rA of 0.12, (Table 7). The outcomes were similar to those observed in the 200 HS analysis.
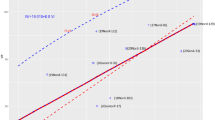
Predicted annual %ΔG for seasonal DM yield resulting from deterministic modelling of the three breeding strategies; Ap, ApWgs and AgsWgs, based on data from the 200 and 1000 HS families clearly indicate the lower response to selection resulting from the among HS family phenotypic selection (Ap) breeding strategy (Fig. 1A,B). There was an increase in annual %ΔG when GS was combined with the Ap breeding method. The predicted annual %ΔG improved with increasing selection pressure and rA. The breeding strategy AgsWgs resulted in the highest predicted annual %ΔG at all among and within family selection pressures and rA. It is also clear that when rA decreased to 0.12 in C2 there was a reduction in predicted annual %ΔG, as would be expected. However, even at a rA value of 0.12 in C2, the predicted annual %ΔG was higher than that predicted for HS in C1 at all selection pressures (Fig. 1A,B).

Predicted annual percentage genetic gain (%∆G) for seasonal DM yield resulting from modelling the breeding strategies; among HS family phenotypic selection (Ap), among HS family phenotypic selection and within family genomic selection (ApWgs), among and within HS family genomic selection (AgsWgs), applied to the: (A) 200 HS families and (B) 1000 HS families, of perennial ryegrass. Ap was only conducted for one cycle. In cycle 2, only genomic selection (GS) was conducted at accuracies (rA) of 0.12, 0.26, 0.36 and 0.46. *rA of 0.12 was only applied to simulations using among HS family selection pressures of 20% and 10% and within HS family selection pressures of 10% and 5%, respectively. The predicted annual %∆G for each combination of selection pressures is indicated by the height of bars, values in brackets indicate rA levels. Since cycle 1 consisted of 3 years, annual genetic gain, %∆G = %∆GC/3. Cycle 2 was 1 year.
Stochastic modelling
Genetic gain
The percentage annual genetic gain (%ΔG) for DM yield in Sim200 and Sim1000 training populations were different for each breeding strategy (Fig. 2). The trends in genetic gain between two training populations (Sim200 and Sim1000) were similar, however, the variation in genetic gain across multiple iterations was higher in Sim200 compared to the Sim1000 training population. Among different breeding strategies, the highest annual genetic gain (%ΔG) was achieved for AgsWSgs, followed by ApWgs and Ap strategies under both 20% and 2% selection pressures. The differences in %ΔG between the breeding strategies were less evident after the second selection cycle (Fig. 2). When comparing among family selection pressures, the highest genetic gain for all three strategies was observed under 2% selection pressure compared to 20% selection pressure. While the variability in genetic gain across multiple iterations was consistently higher under 2% selection pressure compared to that at 20%, this was more evident for the AgsWgs strategy. The highest ΣΔG in each selection cycle was achieved in ApWgs strategy, followed by Ap and AgsWgs (Supplementary material 1, Figure S2).

The percentage genetic gain (%ΔG) per year for DM yield in Sim200 and Sim1000 training populations estimated across 10 selection cycles using three breeding strategies (Ap, ApWgs and AgsWgs). Selection pressures of 20% and 2% were imposed to select the best HS families. Within each family, for the ApWgs and AgsWgs strategies the top 5 or 50 individuals were selected and for the Ap strategy 5 or 50 individuals were randomly selected to restore the initial number of parents for the next selection cycle. In each selection cycle %ΔG was based on 250 iterations.
Fixation rate of favourable alleles
The influence of selection pressure and training population size on allele fixation rates were observed, with the latter being more pronounced (Fig. 3). The fixation rate was highest in the Sim200 training population under 2% selection pressure and the lowest rate was observed in Sim1000 under 20% selection pressure. In both the training populations, under 20% among family selection pressure, the fixation rate steadily increased across the selection cycles. However, under 2% selection pressure the alleles were fixed more rapidly from selection cycle 3 for all three breeding strategies. Among three breeding strategies, the allele fixation rate followed similar patterns and the differences in fixation rate were more noticeable in the later selection cycles (Fig. 3).

Percentage of favourable alleles fixed in the Sim200 and Sim1000 training populations at each selection cycle, under three breeding strategies (Ap, ApWgs and AgsWgs). A selection pressure of 20% and 2% was imposed to select the best HS families. Within each family, for the ApWgs and AgsWgs strategies the top 5 or 50 individuals were selected and for Ap strategy 5 or 50 individuals were randomly selected to restore the initial number of parents for next selection cycle. In each selection cycle percentage of favourable alleles were based on 250 iterations.
Genetic variance and prediction accuracy
The percentage of genetic variance present within the Sim200 and Sim1000 training population decayed rapidly from cycle 0 to cycle 1 for all three breeding strategies. The patterns were similar under the two different selection pressures (Fig. 4). In Sim200 training population, among three breeding strategies, the lowest genetic variance was observed for AgsWgs followed by ApWgs and Ap, similar trends were observed in Sim1000 training population. The prediction accuracy at cycle 0 was 0.3 in Sim200 and 0.25 in Sim1000 and was reduced to 0.12 (60% decrease in prediction accuracy) and 0.07 (72% decrease in prediction accuracy) in selection cycle 1 (Fig. 5). There was no difference in the prediction accuracies between the two different selection pressures. The accuracy steadily decreased from cycle 2 and at the end of cycle 10 was a low 0.03 in Sim200 and 0.002 in Sim1000 training populations (Fig. 5).

The percentage of genetic variance at each selection cycles estimated in Sim200 and Sim1000 training populations using three breeding strategies (Ap, ApWgs and AgsWgs). A selection pressure of 20% and 2% was imposed to select best half-sib families and within each family, for the ApWgs and AgsWgs strategies top 5 and 50 individuals were selected and for Ap strategy random 5 and 50 individuals were selected to restore the initial number of parents for next selection cycle. In each selection cycle percentage genetic variance was based on 250 iterations.

Average prediction accuracy estimated as the Pearson correlation co-efficient between true breeding value (TBV) and genomic estimated breeding value (GEBV) in the Sim200 and Sim1000 training populations. In each selection cycle prediction accuracy was based on 250 iterations.
Discussion
Deterministic modelling
Choosing and optimizing an appropriate breeding strategy to suit a specific cultivar development goal, will require the comparison of different breeding methods based on predicted genetic gains3. While a key criterion for determining the success of a breeding method is genetic gain, cost is also a major factor. Especially in commercial breeding programs, where cost efficiency of a breeding strategy, and access to commercial opportunities, will often determine its adoption.
With increasing pressure on plant breeders to develop new productive cultivars with adaptation to changing environments and meeting consumer demands, new selection and phenotyping technologies must be implemented to enhance genetic advance41. However, incorporation of these technologies into conventional field breeding programs are often challenged as being expensive to implement. Application of quantitative genetic deterministic21 and stochastic modelling22 can be used to evaluate the relative efficiency, genetic gain and associated cost, of conventional breeding strategies in combination with the integration of new selection technologies.
As mentioned in the introduction, HS and FS family breeding strategies are commonly used in forage grass cultivar development programs. In this paper, we present results from deterministic modelling using DeltaGen and stochastic modelling via QU-GENE/QuLinePlus, to predict ∆G and calculate cost per predicted %∆G for DM herbage yield of perennial ryegrass. Deterministic analysis was conducted using a common set of starting points based on estimates of quantitative genetic parameters, from analysis of the 200 HS and 1000 HS family mock data matrices generated using actual field trial DM yield (kg ha-1). We also evaluated the effect of using phenomics (Ph) on the cost per cycle of selection. The narrow sense heritability values 0.31 and 0.36, estimated for herbage DM yield for the 200 HS and 1000 HS families, respectively, were within the range previously reported24,42,43. For mean herbage DM yield across years, seasons and locations, and based on a three year selection cycle, the predicted annual %∆G per selection cycle from the Ap strategy varied from 0.48 to 0.83 (200 HS families) and 0.63 to 1.21 (1000 HS families), depending on selection pressure. These increases are in the general range reported by Humphreys44 0.38%, Easton, et al.45 0.4% to 0.5%, Wilkins and Humphreys46 0.5% to 0.6%, Woodfield47 0.25% to 0.73% and Harmer, et al.48 0.76%. However, at high selection pressures applying Ap in large HS populations, such as the 1000 family dataset, annual increases of 1.21% can be achieved. With every percentage increase in ∆G, cost efficiency improved. Although the predicted %∆G using data from Ph based DM assessments (at an accuracy of 0.90), was lower than predictions using DM yield from herbage cuts, there was a considerable decrease in the cost per %∆G. This was especially evident when comparing DM measurement costs between the ApWgs and APhWgs breeding methods based on herbage cuts and LiDAR phenomic assessments, from the 1000 HS families. There was a considerable reduction in cost ($) per %ΔG that ranged from 10 to 40%.
Annual increases in %∆G of over 2% per year will be required in crops such as maize (Zea mays), rice (Oryza sativa), wheat (Triticum aestivum), and soybean (Glycine max L.), to meet future global food demands49. For perennial ryegrass and other out crossing forage species, achieving a 2% annual gain in DM yield using Ap methods, which exploit only a quarter of the total available additive genetic variation27, is an unrealistic objective. Accessing the ¾ additive variation within HS families will make a significant contribution to increasing annual %∆G4,50. Low genetic gains in forage breeding programs are due, in part, to an inability to satisfactorily exploit within family genetic variation50,51. Historically, application of within family selection in forage grasses could only be based on measurements conducted on random samples of individual, spaced plants, representing the selected HS families. Casler50 presented a range of examples in forage grass breeding for and against using spaced plants. Hayward and Vivero52 and Lazenby and Rogers53 indicated poor genetic correlation between individual spaced plant vigour and sward DM yield. Applying GS based on prediction models constructed using multi-year-season-___location phenotypic data from sown rows or plots makes within family selection for DM yield and other sward traits feasible. The benefits to ∆G of using GS typically focus on the promise of reducing generation interval. However, in addition, the application of genomic prediction to generate GEBV’s for large numbers of random individuals sampled from elite HS families, offers a means to also improve ∆G by increasing the efficiency of within family selection for sward DM yield. Deterministic simulation of the ApWgs breeding strategy using DeltaGen, based on the 200 HS and 1000 HS families, clearly indicated the advantage of applying GS for within family selection. For both HS populations, increasing within family selection pressure, from 10 to 1% or increasing rA from 0.26 to 0.46 increased %∆G per cycle. For both the 200 HS and 1000 HS family populations, at 1% within family GS, %∆G per cycle for DM yield was 6.35 and 8.10, respectively. Based on the three-year selection cycle assumed in this study, these increases equate to annual %∆G of 2.11 and 2.70, comfortably above the 2% ∆G per annum target. As expected, with increasing genetic gain the cost %∆G decreased.
As alluded to above, in addition to enabling within family selection, a key advantage in using GS is reducing the length of a selection cycle and the cost %∆G54,55. This was further demonstrated in our deterministic simulation by applying a wholly GS second selection cycle, AgsWgs, to the HS families generated following C1 in both the 200 HS and 1000 HS family scenarios. The fact that AgsWgs enabled selection of another generation of elite parental seedlings based on GEBV’s in the space of one year, following C1 (3 years), resulted in high annual %∆G in cycle 2. Annual %∆G resulting from AgsWgs was higher than both the Ap and ApWgs breeding strategies at all selection pressures and rA’s. This additional year based on AgsWgs following the 3 years of the field-based strategy (C1) increased total %∆G.
It is important to note that the deterministic simulation results discussed assumed that the rA values 0.26, 0.36 and 0.46 in C1 continued to hold in C2. There is always the probability of the correlation between GEBV’s and phenotype derived BLUP’s or true breeding values, decreasing due to decay in rA, due principally to declining genetic relatedness between training and selection populations56, following polycrossing of C1 selected parents. The use of a rA of 0.12 was introduced into simulation in C2 to investigate this scenario. Simulation results indicated that even at the rA value of 0.12 in C2, the predicted annual %ΔG using AgsWgs, was higher than that predicted for Ap in C1 at all selection pressures.
Stochastic modelling
While genetic gain is a key determinant of the merit of a breeding strategy, information on fixation rate of favourable alleles and the rate of decay of genetic variance and rA are vital, especially when designing long-term recurrent selection breeding programs. For example, knowing at what stage in the recurrent selection process to recalibrate the prediction model when using GS is essential. Application of strategic decision support software tools such as QU-GENE, provide a platform for plant breeders to assess the progress, over multiple selection cycles, for ∆G and associated genetic parameters such as; additive genetic variance, fixation rates and rA. In crop species, several studies have explored stochastic modelling to understand long-term trends of implementing GS in breeding programs19,57,58,59,60. In forages, Lin, et al.55 and Esfandyari, et al.61 used stochastic modelling to assess the impact of GS in commercial and FS breeding programs.
In the current study, stochastic modelling using QU-GENE/QuLinePlus provided graphical trends for; ∆G, allele fixation rate, genetic variance and rA, over 10 cycles of selection in response to three breeding strategies; Ap, ApWgs and AgsWgs, when applied to either 200 HS or 1000 HS families of perennial ryegrass. In our simulations, the greatest %∆G observed for GS (ApWgs and AgsWgs) breeding strategies compared to Ap across two different selection pressures and populations sizes (Fig. 2). These results are due to precise selection of genotypes, for DM yield, within a family when implementing GS, compared to random selection of individuals from within selected families when using the Ap strategy. This further supports the findings of Esfandyari, et al.61 who in the context of full sib (FS) family breeding strategies, reported that accurate selection of single plants, based on GS, establishes a strong genetic correlation in terms of performance between single plants and plots, leading to increased ∆G.
The GS breeding strategies applied in C1 outperformed the Ap strategy in terms of predicted %∆G. However, in later cycles, these differences were less pronounced, due to a decline in rA in the selection cycles post C1. These trends observed in our simulations were similar for both the Sim200 and Sim1000 HS families, mainly due to similar size and number of additive genetic effects used in the recombination map for simulating the breeding strategies. Generally, with larger training populations, rA increases6,62 or remains constant relative to smaller populations58. However, in our simulations there was a difference in rA following each selection cycle. In the Sim1000 HS families the observed rA values were relatively lower compared to the Sim200 HS family simulations. While the rA disparity between the populations is unclear, it should be noted that, Sim200 and Sim1000 were two independently simulated populations evaluated under different GE simulation systems, as described in “Material and Methods”. Populations evaluated under different GE systems, irrespective of the size of training population, produce different rA63,64. In forages, rA is a result of genetic linkage and linkage disequilibrium (LD)24,65,66. As selection cycles progress the genetic linkage between the training and selection population declines, resulting in poor rA as observed in our simulations (Fig. 5). To maintain higher rA across multiple selection cycles, training populations need to be updated with new elite material or by including the families from previous selection cycles58,61. The implication of this strategy in HS breeding systems is yet to be investigated and would be considered in future studies.
Genetic variance within breeding populations provides the foundation for cultivar development67. In our simulations, there was a rapid decline in the percentage of genetic variance from selection C0 to C1, particularly for the ApWgs and AgsWgs methods and in the later selection cycles there was a steady decline in all three breeding strategies (Fig. 4). The rapid decline from C0 to C1 in the GS strategies is the result of utilizing both among (1/4 σ2A) and within (3/4 σ2A) HS family additive genetic variation, and this was reflected in the %∆G (Fig. 2). In addition, the polygenic architecture of the DM yield trait may be an underlying factor. Muleta, et al.58 reported similar trends, notably a rapid early decline in genetic variance, for a polygenic trait through their simulation of genomic assisted recurrent selection in sorghum (Sorghum bicolor). Cycles of continuous recurrent selection increase the frequency of favourable alleles and at the same time increase the probability of fixation of deleterious alleles. Selection pressure and population size have big impact on the allele fixation rates (Fig. 3). Our simulations demonstrated that smaller populations and high selection pressure will lead to higher allelic fixation rates earlier in the selection cycles. Allelic fixation rate is the direct measure of inbreeding in a population27,68,69. With decreasing population size and higher selection pressures the potential for inbreeding depression increases55,68,69. In cross pollinating species such as perennial ryegrass, which consists of heterozygous and heterogenous populations, inbreeding depression effects can be severe70. Our results re-emphasize the importance of larger training populations for GS implementation in order to maintain optimum levels of inbreeding rates and the genetic variance in a recurrent selection program.
In addition to having information such as heritability of key traits, the possibility of predicting the rate of decrease of their genetic variances and associated allele fixation rates, over multiple selection cycles, as shown in our study for HS families, also simulation studies by Esfandyari, et al.61 for FS families and Lin, et al.55 in a commercial breeding program, will enhance decisions on choice of breeding pool to achieve specific cultivar development goals, by deploying cost effective breeding strategies.
Conclusion
Optimizing breeding program inputs for rate and cost-efficiency of genetic gain can be informed by simulation. Using mock data matrices constructed from empirically derived data, we demonstrated short- and long-term impacts of breeding strategy and integration of key technologies including genomic selection and phenomics on rate of predicted genetic gain for dry matter yield, a key economic trait, in perennial ryegrass. Our findings indicate these technologies offer substantial improvements in the rate of gain, and in some cases improved cost-efficiency per unit gain. The value of GS in exploiting within family additive genetic variation to increase genetic gain was demonstrated using both deterministic and stochastic simulation.
The application of GS in both among and within HS family selection in C2, provided a significant boost to total annual genetic gain across both cycles (C1 = 3 years and C2 = 1 year), even at low GS accuracy rA of 0.12. Despite some reduction in genetic gain, using phenomics (LiDAR based mobile platform) to assess seasonal DM yield clearly demonstrated its impact by reducing cost per percentage gain relative to standard DM cuts.
The open-source software tools, DeltaGen and QU-GENE, offer ways to query and model the impact of breeding methodology and technology integration under a range of breeding scenarios and inputs in out crossing species including pasture species. This software expands the scope of tools available to breeders in decision support for breeding program design. The analyses reported in this paper can also be extended to major crop species using the genetic modelling capability for self-pollinating species, developed in both DeltaGen and QU-GENE.
Data availability
The datasets generated in this study are included as supplementary information files.
Code availability
Software links to perform the deterministic and stochastic modelling were provided within this article.
References
Moll, R. H. & Stuber, C. W. In Advances in Agronomy Vol. 26 (ed. Brady, N. C.) 277–313 (Academic Press, 1974).
Milligan, S. B., Gravois, K. A., Bischoff, K. P. & Martin, F. A. Crop effects on broad-sense heritabilities and genetic variances of sugarcane yield components. Crop Sci. https://doi.org/10.2135/cropsci1990.0011183X003000020020x (1990).
Fehr, W. R. Principles of Cultivar Development: Crop Species (Macmillan Publishing Company, 1987).
Casler, M. D. & Brummer, E. C. Theoretical expected genetic gains for among-and-within-family selection methods in perennial forage crops. Crop Sci. 48, 890–902. https://doi.org/10.2135/cropsci2007.09.0499 (2008).
Collard, B. C., Jahufer, M., Brouwer, J. & Pang, E. An introduction to markers, quantitative trait loci (QTL) mapping and marker-assisted selection for crop improvement: the basic concepts. Euphytica 142, 169–196 (2005).
Jannink, J.-L., Lorenz, A. J. & Iwata, H. Genomic selection in plant breeding: From theory to practice. Brief. Funct. Genom. 9, 166–177. https://doi.org/10.1093/bfgp/elq001 (2010).
Meuwissen, T. H. E., Hayes, B. J. & Goddard, M. E. Prediction of total genetic value using genome-wide dense marker maps. Genetics 157, 1819–1829 (2001).
Ghamkhar, K. et al. Real-time, non-destructive and in-field foliage yield and growth rate measurement in perennial ryegrass (Lolium perenne L.). Plant Methods 15, 72 (2019).
Shorten, P. R., Leath, S. R., Schmidt, J. & Ghamkhar, K. Predicting the quality of ryegrass using hyperspectral imaging. Plant Methods 15, 63. https://doi.org/10.1186/s13007-019-0448-2 (2019).
Gebremedhin, A. et al. Development and validation of a phenotyping computational workflow to predict the biomass yield of a large perennial ryegrass breeding field trial. Front. Plant Sci. 11, 689 (2020).
Miao, C. et al. Semantic segmentation of sorghum using hyperspectral data identifies genetic associations. Plant Phenom. 2020, 4216373. https://doi.org/10.34133/2020/4216373 (2020).
Araus, J. L. & Cairns, J. E. Field high-throughput phenotyping: the new crop breeding frontier. Trends Plant Sci. 19, 52–61 (2014).
Montes, J. M., Technow, F., Dhillon, B. S., Mauch, F. & Melchinger, A. E. High-throughput non-destructive biomass determination during early plant development in maize under field conditions. Field Crop Res. 121, 268–273. https://doi.org/10.1016/j.fcr.2010.12.017 (2011).
Roitsch, T. et al. Review: New sensors and data-driven approaches—A path to next generation phenomics. Plant Sci. 282, 2–10. https://doi.org/10.1016/j.plantsci.2019.01.011 (2019).
Perez-Sanz, F., Navarro, P. J. & Egea-Cortines, M. Plant phenomics: an overview of image acquisition technologies and image data analysis algorithms. GigaScience https://doi.org/10.1093/gigascience/gix092 (2017).
Tardieu, F., Cabrera-Bosquet, L., Pridmore, T. & Bennett, M. Plant phenomics, from sensors to knowledge. Curr. Biol. 27, R770–R783. https://doi.org/10.1016/j.cub.2017.05.055 (2017).
Zhao, C. et al. Crop phenomics: Current status and perspectives. Front. Plant Sci. https://doi.org/10.3389/fpls.2019.00714 (2019).
Podlich, D. W. & Cooper, M. QU-GENE: A simulation platform for quantitative analysis of genetic models. Bioinformatics 14, 632–653. https://doi.org/10.1093/bioinformatics/14.7.632 (1998).
Iwata, H. & Jannink, J. L. Accuracy of genomic selection prediction in barley breeding programs: A simulation study based on the real single nucleotide polymorphism data of barley breeding lines. Crop Sci. 51, 1915–1927 (2011).
Yabe, S., Iwata, H. & Jannink, J.-L. A simple package to script and simulate breeding schemes: The breeding scheme language. Crop Sci. 57, 1347–1354. https://doi.org/10.2135/cropsci2016.06.0538 (2017).
Jahufer, M. & Luo, D. DeltaGen: A comprehensive decision support tool for plant breeders. Crop Sci. 58, 1118–1131 (2018).
Hoyos-Villegas, V. et al. QuLinePlus: Extending plant breeding strategy and genetic model simulation to cross-pollinated populations—case studies in forage breeding. Heredity 122, 684–695. https://doi.org/10.1038/s41437-018-0156-0 (2019).
George, R., Barrett, B. & Ghamkhar, K. Evaluation of LiDAR scanning for measurement of yield in perennial ryegrass. J. N. Zeal. Grassl. 81, 55–60 (2019).
Faville, M. J. et al. Predictive ability of genomic selection models in a multi-population perennial ryegrass training set using genotyping-by-sequencing. Theor. Appl. Genet. 131, 703–720 (2018).
Arojju, S. K., Cao, M., Jahufer, M. Z., Barrett, B. A. & Faville, M. J. Genomic predictive ability for foliar nutritive traits in perennial ryegrass. G3 Genes Genomes Genet. 10, 695–708 (2020).
Arojju, S. K. et al. Multi-trait genomic prediction improves predictive ability for dry matter yield and water-soluble carbohydrates in perennial ryegrass. Front. Plant Sci. https://doi.org/10.3389/fpls.2020.01197 (2020).
Falconer, D. S., Mackay, T. F. & Frankham, R. Introduction to quantitative genetics (4th edn). Trends Genet. 12, 280 (1996).
Harville, D. A. Maximum likelihood approaches to variance component estimation and to related problems. J. Am. Stat. Assoc. 72, 320–338 (1977).
Patterson, H. D. & Thompson, N. R. Recovery of inter-block information when block sizes are unequal. Biometrika 58, 545–554. https://doi.org/10.1093/biomet/58.3.545 (1971).
Patterson, H. D. & Thompson, R. Maximum likelihood estimation of components of variance. In Proceedings of the 8th International Biometrical Conference. 197–207 (1975).
Nyquist, W. E. & Baker, R. Estimation of heritability and prediction of selection response in plant populations. Crit. Rev. Plant Sci. 10, 235–322 (1991).
Annicchiarico, P. et al. Accuracy of genomic selection for alfalfa biomass yield in different reference populations. BMC Genom. 16, 1020 (2015).
Grinberg, N. F. et al. Implementation of genomic prediction in Lolium perenne (L.) breeding populations. Front. Plant Sci. 7, 133 (2016).
Dekkers, J. Marker-assisted selection for commercial crossbred performance. J. Anim. Sci. 85, 2104–2114 (2007).
Dekkers, J. Prediction of response to marker-assisted and genomic selection using selection index theory. J. Anim. Breed. Genet. 124, 331–341 (2007).
Byrne, S. L. et al. A synteny-based draft genome sequence of the forage grass Lolium perenne. Plant J. 84, 816–826 (2015).
Lipka, A. E. et al. GAPIT: genome association and prediction integrated tool. Bioinformatics 28, 2397–2399. https://doi.org/10.1093/bioinformatics/bts444 (2012).
Endelman, J. B. Ridge regression and other kernels for genomic selection with R package rrBLUP. Plant Genome 4, 250–255 (2011).
Jafari, A., Connolly, V. & Walsh, E. Genetic analysis of yield and quality in full-sib families of perennial ryegrass (Lolium perenne L.) under two cutting managements. Irish J. Agric. Food Res. 2, 275–292 (2003).
Oconnor, J. R., Jahufer, M. Z. Z. & Lyons, T. Examining perennial ryegrass (Lolium perenne L.) persistence through comparative genetic analyses of two cultivars after nine years in the field. Euphytica 216, 36. https://doi.org/10.1007/s10681-020-2568-1 (2020).
Cobb, J. N. et al. Enhancing the rate of genetic gain in public-sector plant breeding programs: Lessons from the breeder’s equation. Theor. Appl. Genet. 132, 627–645 (2019).
Rhodes, I. The relationship between productivity and some components of canopy structure in ryegrass (Lolium spp.): III. Spaced plant characters, their heritabilities and relationship to sward yield. J. Agric. Sci. 80, 171–176. https://doi.org/10.1017/S002185960005718X (1973).
Fè, D., Pedersen, M. G., Jensen, C. S. & Jensen, J. Genetic and environmental variation in a commercial breeding program of perennial ryegrass. Crop Sci. 55, 631–640 (2015).
Humphreys, M. The contribution of conventional plant breeding to forage crop improvement. In Proceedings of the 18th International Grassland Congress’. Winnipeg and Saskatoon, Canada. 8–17. (1997)
Easton, S., Amyes, J., Cameron, N., Green, R., Norriss, M. & Stewart, A. Pasture plant breeding in New Zealand: where to from here?. In Proceedings of the conference-New Zealand Grassland Association, 173–180 (2002).
Wilkins, P. & Humphreys, M. Progress in breeding perennial forage grasses for temperate agriculture. J. Agric. Sci. 140, 129–150 (2003).
Woodfield, D. Genetic improvements in New Zealand forage cultivars. In Proceedings of the conference-New Zealand grassland association. 3–8. (1999)
Harmer, M., Stewart, A. & Woodfield, D. Genetic gain in perennial ryegrass forage yield in Australia and New Zealand. J. N. Zeal. Grassl. 78, 133–138 (2016).
Ray, D. K., Mueller, N. D., West, P. C. & Foley, J. A. Yield trends are insufficient to double global crop production by 2050. PLoS ONE 8, e66428. https://doi.org/10.1371/journal.pone.0066428 (2013).
Casler, M. Among-and-within-family selection in eight forage grass populations. Crop Sci. 48, 434–442 (2008).
Simeão Resende, R. M., Casler, M. D. & de Resende, M. D. V. Genomic selection in forage breeding: Accuracy and methods. Crop Sci. 54, 143–156. https://doi.org/10.2135/cropsci2013.05.0353 (2014).
Hayward, M. & Vivero, J. Selection for yield in Lolium perenne. II. Performance of spaced plant selections under competitive conditions. Euphytica 33, 787–800 (1984).
Lazenby, A. & Rogers, H. Selection criteria in grass breeding. II. Effect, on Lolium perenne, of differences in population density, variety and available moisture. J. Agric. Sci. 62, 285–298 (1964).
Lin, Z. et al. Genetic gain and inbreeding from genomic selection in a simulated commercial breeding program for perennial ryegrass. Plant Genome https://doi.org/10.3835/plantgenome2015.06.0046 (2016).
Lin, Z. et al. Optimizing resource allocation in a genomic breeding program for perennial ryegrass to balance genetic gain, cost, and inbreeding. Crop Sci. 57, 243–252. https://doi.org/10.2135/cropsci2016.07.0577 (2017).
Habier, D., Fernando, R. L. & Dekkers, J. C. M. The impact of genetic relationship information on genome-assisted breeding values. Genetics 177, 2389–2397. https://doi.org/10.1534/genetics.107.081190 (2007).
Daetwyler, H. D., Hayden, M. J., Spangenberg, G. C. & Hayes, B. J. Selection on optimal haploid value increases genetic gain and preserves more genetic diversity relative to genomic selection. Genetics 200, 1341–1348 (2015).
Muleta, K. T., Pressoir, G. & Morris, G. P. Optimizing genomic selection for a sorghum breeding program in Haiti: A simulation study. G3 Genes Genomes Genet. 9, 391–401. https://doi.org/10.1534/g3.118.200932 (2019).
Müller, D., Schopp, P. & Melchinger, A. E. Persistency of prediction accuracy and genetic gain in synthetic populations under recurrent genomic selection. G3 Genes Genomes Genet. 7, 801–811. https://doi.org/10.1534/g3.116.036582 (2017).
Denis, M. & Bouvet, J.-M. Efficiency of genomic selection with models including dominance effect in the context of Eucalyptus breeding. Tree Genet. Genomes 9, 37–51. https://doi.org/10.1007/s11295-012-0528-1 (2013).
Esfandyari, H., Fè, D., Tessema, B. B., Janss, L. L. & Jensen, J. Effects of different strategies for exploiting genomic selection in perennial ryegrass breeding programs. G3 Genes Genomes Genet. https://doi.org/10.1534/g3.120.401382 (2020).
Lorenz, A., Smith, K. & Jannink, J. L. Potential and optimization of genomic selection for Fusarium head blight resistance in six-row barley. Crop Sci. 52, 1609–1621 (2012).
Heslot, N., Akdemir, D., Sorrells, M. E. & Jannink, J.-L. Integrating environmental covariates and crop modeling into the genomic selection framework to predict genotype by environment interactions. Theor. Appl. Genet. 127, 463–480. https://doi.org/10.1007/s00122-013-2231-5 (2014).
Sun, J. et al. High-throughput phenotyping platforms enhance genomic selection for wheat grain yield across populations and cycles in early stage. Theor. Appl. Genet. 132, 1705–1720 (2019).
Fè, D. et al. Genomic dissection and prediction of heading date in perennial ryegrass. BMC Genom. 16, 921 (2015).
Byrne, S. L. et al. Using variable importance measures to identify a small set of SNPs to predict heading date in perennial ryegrass. Sci. Rep. 7, 1–10 (2017).
Bhandari, H., Nishant Bhanu, A., Srivastava, K., Singh, M. & Shreya, H. A. Assessment of genetic diversity in crop plants. An overview. Adv. Plants Agric. Res. 7, 00255 (2017).
Busch, J. Inbreeding depression in self-incompatible and self-compatible populations of Leavenworthia alabamica. Heredity 94, 159–165 (2005).
Leimu, R., Mutikainen, P., Koricheva, J. & Fischer, M. How general are positive relationships between plant population size, fitness and genetic variation?. J. Ecol. 94, 942–952. https://doi.org/10.1111/j.1365-2745.2006.01150.x (2006).
Bean, E. W. & Yok-Hwa, Chen. An analysis of the growth of inbred progeny of Lolium. J. Agric. Sci. 79, 147–153 (1972). https://doi.org/10.1017/S0021859600025478
Acknowledgements
The authors wish to acknowledge Dr Tony Conner, AgResearch, and Dr Ed Butler, Partnerships Manager, for their mentorship and support that ensured the success of Pastoral Genomics Plus. Authors like to acknowledge the valuable comments provided by Dr David Hume, AgResearch to improve the manuscript.
Funding
This work was funded by Pastoral Genomics Plus (PSTG1501), a joint venture co-funded by DairyNZ, Beef + Lamb New Zealand, Dairy Australia, AgResearch Ltd, New Zealand Agriseeds Ltd, Grasslands Innovation Ltd, DEEResearch, and the Ministry of Business, Innovation and Employment (New Zealand).
Author information
Authors and Affiliations
Contributions
M.Z.J., M.F., K.G., A.G. and B.B. conceived the study. M.Z.J. performed the deterministic modelling analysis and wrote the initial manuscript. S.K.A. performed the stochastic modelling analysis and S.K.A. and V.A. interpreted the results. M.Z.J., S.K.A., M.F., K.G., D.L., V.A., W.Y., M.S., I.D., A.G., C.E., W.C., A.S., R.G., V.H.V., K.B. and B.B. contributed to the interpretation of the results. M.Z.J., S.K.A., V.A.. and K.B. played a key role in finalizing the manuscript.
Corresponding author
Ethics declarations
Competing interests
Authors MZJ, SKA, MF, KG, DL, AG, BB are employed by AgResearch, a New Zealand Crown Research Institute. Authors CE and WC are employed by Barenbrug Agriseeds Ltd and authors AS and RG are employed by PGG Wrightson Seeds Ltd. Neither funders nor the industry partners were involved in the design of this study.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jahufer, M.Z.Z., Arojju, S.K., Faville, M.J. et al. Deterministic and stochastic modelling of impacts from genomic selection and phenomics on genetic gain for perennial ryegrass dry matter yield. Sci Rep 11, 13265 (2021). https://doi.org/10.1038/s41598-021-92537-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-92537-w
This article is cited by
-
The value of early root development traits in breeding programs for biomass yield in perennial ryegrass (Lolium perenne L.)
Theoretical and Applied Genetics (2025)
-
Genomic selection shows improved expected genetic gain over phenotypic selection of agronomic traits in allotetraploid white clover
Theoretical and Applied Genetics (2025)
-
Machine learning after a decade: is it still a missing keystone in genomic-based plant breeding?
Artificial Intelligence Review (2025)
