
Abstract
In recent years, deep learning techniques have shown impressive performance in the field of identification of diseases of crops using digital images. In this work, a deep learning approach for identification of in-field diseased images of maize crop has been proposed. The images were captured from experimental fields of ICAR-IIMR, Ludhiana, India, targeted to three important diseases viz. Maydis Leaf Blight, Turcicum Leaf Blight and Banded Leaf and Sheath Blight in a non-destructive manner with varied backgrounds using digital cameras and smartphones. In order to solve the problem of class imbalance, artificial images were generated by rotation enhancement and brightness enhancement methods. In this study, three different architectures based on the framework of ‘Inception-v3’ network were trained with the collected diseased images of maize using baseline training approach. The best-performed model achieved an overall classification accuracy of 95.99% with average recall of 95.96% on the separate test dataset. Furthermore, we compared the performance of the best-performing model with some pre-trained state-of-the-art models and presented the comparative results in this manuscript. The results reported that best-performing model performed quite better than the pre-trained models. This demonstrates the applicability of baseline training approach of the proposed model for better feature extraction and learning. Overall performance analysis suggested that the best-performed model is efficient in recognizing diseases of maize from in-field images even with varied backgrounds.
Similar content being viewed by others

Introduction
After rice and wheat, maize (Zea mays L.) (Poaceae) is the most essential cereal crop grown in diverse environmental conditions across the globe1. In 2020, the global yield of maize was around 1.15 billion MT with a productivity of 5.82 t/ha2. Among the 170 maize growing countries, India stands in the fourth position in terms of maize acreage while seventh in production terms, contributing nearly 4.6% and 2.4% of the global acreage and production respectively3. In India, maize is grown in an area of approx. 9.02 mha with a production of 27.71 mt and productivity of 3.1 t/ha2. It is widely valued for its extensive use as a staple food for human beings and quality feed-fodder for animals. In addition to that maize crop also serves as the primary raw material for many industrial products. Despite a high grain yield potential, the considerable obstacle to the higher yield of the maize crop is its vulnerability to several diseases. In maize, around 65 diseases have been reported from different regions in India4. With respect to production loss due to the diseases, 11 out of 65 diseases are of national importance in the Indian scenario5. Among these Maydis Leaf Blight (MLB)/ Southern Corn Leaf Blight (SCLB), Turcicum Leaf Blight (TLB)/ Northern Corn Leaf Blight (NCLB) and Banded Leaf and Sheath Blight (BLSB) diseases are prevalent in most of the maize growing regions of India. The MLB disease is mostly favoured by the warm and humid climatic regions of India which can cause the yield loss of around 40–70% of the total production6,7,8. The TLB disease has the capability of damaging 25–90% of total crop yield in severe conditions8. The BLSB disease generally causes 0–60% production loss in maize in natural conditions4. However, the extent of yield loss may reach 100% under severely affected conditions9. In order to manage a specific disease of a crop, it’s very important to identify the factor correctly and then apply management tactics accordingly. Therefore, correctly identifying the disease symptoms of the crops in in-field conditions is an important step for managing the disease spread. Traditionally, ___domain experts/plant pathologists/farmers used to diagnose any diseases by manually visualizing the symptoms of the disease in the crops with the naked eye. However, this approach isn’t feasible to a larger extent due to the constraints like time, cost, physical accessibility and resource availability. Many times, unavailability of ___domain experts, may hamper the accurate treatment of the diseases in the early stage. Therefore, a precise, quick and cost-effective approach for the diagnosis of diseases in crops is a challenge for the scientific community10. In the present scenario, automation of disease detection using deep learning nearly outperforms the traditional disease detection methodology and provides nearly expert-level performance in critical times. Therefore, a digital image-based automatic disease identification approach in maize crop would be a practical and viable solution to reach the stakeholders like maize farmers and extension personnel of the country.
Early investigations using semantic approach11, rule-based and ontology-based approach12,13, content-based image retrieval14, ___domain-specific expert systems15, etc. were performed for identification of diseases and pests in several crops. These approaches have shown impactful outcomes for the agriculture sector across the globe. In the last few years, the deep learning concepts of artificial intelligence and computer vision have emerged as a potential solution for many aspects of agricultural problems16. The deep learning techniques, particularly the convolution neural networks (CNN) have established a trend of automatic disease identification approachs in crops using digital images17. For the last few years, deep learning techniques are being used to identify diseases of major crops such as Rice18,19,20, Wheat21,22,23,24, Tomato25,26,27,28, Apple29,30,31, Cucumber32,33, Cassava34, Pearl Millet35 etc. Mohanty et al.36 developed deep CNN models for automatically identifying the disease from leaf images using an open-source dataset named PlantVillage37. The PlantVillage dataset contains 54,306 digital images of 26 diseases from 14 different crop species captured in lab conditions. Barbedo38 used the pre-trained CNN frameworks to identify in-field images of several diseases affecting 12 different crops. Ferentinos39 worked on developing deep learning models for identifying 56 diseases of different crops from 87,848 images of leaves captured both in a laboratory (PlantVillage dataset) and in the field. Chen et al.40 used transfer learning approach for identification of different diseases of Rice and Maize. They used pre-trained VGGNet network for classifying the images of plant diseases. Nanehkaran et al.41 proposed a novel segmentation-based approach for classification of diseases of 3 different crops. In both works, authors had used images of plant diseases collected from agricultural fields.
In the maize crop, a few but significant works have been done for automatic identification of several diseases42,43,44,45,46,47,48,49. The authors44,45,46 have worked on developing deep learning models for identifying diseases of maize crop. They worked on the publicly available maize data from the PlantVillage repository. Authors43,47 used the image dataset from the PlantVillage repository for building disease classification models. However, they augmented images from other sources such as Global AI challenge, internet sources, etc. with the maize data of plant village repo. As the images of the Plant Village repository were captured under controlled environmental conditions and in a destructive manner, it limits the applicability of these approaches in real in-field conditions. DeChant et al.42 have developed a computational pipeline of CNNs for identifying Northern Corn Leaf Blight (NCLB/TLB) disease of maize crop. Here, they collected images of TLB disease of maize crop from the experimental field in non-destructive manner. Their approach reported promising results for identifying NCLB/TLB disease of maize. Whereas Haque et al.48 have used a deep CNN model i.e. ‘GoogleNet’ for identifying Maydis Leaf Blight disease from healthy leaves. However, a limitation of these works is that in both studies only one disease of maize has been addressed. Chen et al.49 proposed a lightweight network for recognition of eight maize diseases. They incorporated attention module with the DenseNet architecture to propose the novel model. They collected a total of 466 images of diseases of maize from agricultural fields of Fujian Province, China.
In this work, we investigated the state-of-the-art CNN framework ‘Inception-v3’ network for classifying the three diseases of maize crop along with healthy leaves. We applied different architectural layers on top of the ‘Inception-V3’ model and applied baseline training approach. With this approach, we achieved significant results for classification of diseases of maize crop. We also performed comparative analysis of the proposed approach with the pre-trained benchmark CNN models and comparatively better results.
Major contributions of this study are as follows: first, we have created an image database containing diseased (three diseases) and healthy images of maize crop. These images were collected from the standing crops in several experimental fields in a non-destructive manner. This image database was used in this study to train, validate and test the developed CNN models. Second, we employed a state-of-the-art CNN model ‘Inception-v3’ model with three architectural layers on the top and trained the models from scratch with our collected dataset. The models showed significant performance for classifying the images of maize crop even with varied complex backgrounds.
Maize disease dataset and classification approach
Dataset
In this experiment, a total of 5939 digital images of maize crop were captured in a non-destructive manner. The image dataset consists of three diseases classes and one healthy class. A summary of collected images of maize crop has been shown in Table 1. The images of maize crop were collected from experimental fields of All India Coordinated Research Project (AICRP) on Maize centres of ICAR-Indian Institute of Maize Research (ICAR-IIMR), Ludhiana, India (as described in Table S1). In this study, we mainly considered three major diseases of maize crop namely Maydis Leaf Blight (MLB), Turcicum Leaf Blight (TLB) and Banded Leaf and Sheath Blight (BLSB). Therefore, the experimental fields were chosen based on hotspot locations of MLB, TLB and BLSB diseases in three maize growing zones viz. North Hill Zone (NHZ), North West Plain Zone (NWPZ) and North East Plain Zone (NEPZ). In these hot spot locations, pathology trials for screening the maize diseases are already going on under the AICRP on Maize project of ICAR-IIMR. These trails are constituted under artificially epiphytotic conditions in the various hot spot locations across the country where the region-specific susceptible/tolerant cultivars of maize are artificially inoculated with pathogen inoculum. Details of the experimental trials, diseases-wise hot spot locations and inoculation techniques followed are provided in50.
We collected the images of maize crop from these experimental trails during 15–60 DAS (Days after sowing) for healthy images and 25–60 DPI (days post-inoculation) for the diseased ones during both Kharif and Rabi seasons (as described in Table S1). The images of disease symptoms were associated with a mixture of susceptible and tolerant cultivars of maize crop. The variations in the symptom expressions of the diseased images were minor between the susceptible and tolerant genotypes. The images were captured manually using several image-capturing devices such as Nikon D3500 Camera having 18–55 mm Lens and CMOS Sensor with 24.2 MP; Xiaomi Redmi Y2 smartphone with 12 MP camera and ASUS Zenfone Max Pro M1 smartphone with 13 MP camera. Sample images of each diseased class have been shown in Fig. 1. While capturing the images from the maize field, the following protocols were maintained:
-
1.
Keeping a distance of 25–40 cm between the camera lens and the plant part/leaf
-
2.
Targeting only one affected plant part/leaf per image
-
3.
Focusing the camera lens into the disease affected portion of the plant part/leaf
-
4.
Capturing the top-view/front-view images of the diseased plant parts/leaves

Sample images of dataset (A) Healthy, (B) Maydis Leaf Blight, (C) Turcicum Leaf Blight and (D) Banded Leaf and Sheath Blight of Maize Crop.
The symptoms of the three diseases are as follows:
MLB is one of the serious fungal diseases caused by the fungus Cochliobolus heterostrophus (also known as Helminthosporium maydis). Primarily, regions with warm (20–32 °C) and humid climate favours the disease incidence. It has its effect right from the seedling stage to the harvest stage. The symptoms of this disease can be identified by the presence of small, yellowish/brown, round or oval spots on the lower or upper surface of leaves. As the disease grows, these spots enlarge, become elliptical and the center becomes straw coloured with a reddish-brown margin 51.
TLB disease is generally caused by the ascomycete fungus, Setosphaeria turcica. The symptoms of this disease start as small elliptical spots on the lower leaves which turn greenish spindle-shaped and bigger with time. The mature symptoms are characterized by 3–15 cm long cigar-shaped lesions that are gray to tan color8. This disease is mainly prevalent in the hilly regions of the country where the mild temperature and high humidity favours the disease development.
The BLSB is a very serious fungal disease of maize caused by Rhizoctonia solani f.sp. sasakii., which can wipe out the entire crop yield under severe conditions1. The disease generally prefers warm and humid weather conditions. The symptoms of this disease develop as straw-colored necrotic lesions alternating with dark brown on basal leaf sheaths and appear probably after 40–45 days after sowing9. Later these lesions enlarge and form dark brown sclerotia on diseased sheaths, husk and cobs. In severe cases, these cobs are completely damaged and dried out9.
Data preparation
Pre-processing of images is an important task in the disease detection model pipeline as the images may differ in size, contain noises, have uneven illuminations, etc.52. As the images of maize crop were captured with different image-capturing devices (such as smartphones, digital cameras etc.), there exists variability in the images in terms of resolutions (width and height) and format. One of the fundamental aspects of deep learning networks is that the images should be homogeneous53. Therefore, the raw images required proper pre-processing before being applied to any of the deep learning models52. In this experiment, at first, all the images were resized to \(256 \times 256\) pixels (resolution) by a python script using ‘PIL’ (Python Imaging Library) library and used for model training thereafter. All the images were saved in .jpg format in respective folders in storage disks. Next, images were read from the storage disks and converted to numpy arrays using the ‘NumPy’ library for standardization purposes. The numpy arrays provide an efficient way for reading and processing the images during model training. These numpy arrays of size \(256 \times 256\) were used as input to the proposed model for feature extraction and classification.
In this experiment, it could be noted that the number of images in MLB class was far more than the other three classes. This imbalance in the number of images in the classes would have a pessimistic influence on the performance of the deep learning models. Therefore, to avoid this situation, artificial images were generated for the classes containing less number of images than MLB class. The ‘Augmentor’ library, available in python was used for this augmentation process. The artificial images were generated by transforming the original images in such a way that labels of the images were preserved during transformation54. The aim of this image augmentation process was to increase the variability as well the volume of the dataset. In this experiment, several image transformation techniques were used such as rotation (90, 270 degrees), flipping, distortion, skewing etc. A detailed summary of the augmented images has been provided in Table 2. We have also applied brightness enhancement techniques in our dataset to resolve the effect of uneven brightness in the disease symptoms and discussed in the results section.
Classification approach
In present scenario, deep convolutional neural networks (CNNs) are at the core in the field of computer vision and pattern recognition55. The CNNs have the capability to learn the distinguishable features of the images/objects automatically from pixel arrangements in the images, unlike the traditional machine learning approaches where classifiers are trained with hand-engineered features of images34.
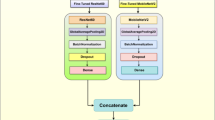
In this experiment, we used a well-known state-of-the-art CNN model ‘Inception-v3’ for classifying the in-field images of maize crop. The ‘Inception-v3’ network is 42-layers deep with concatenated convolutions and pooling layers and 2.5 times costlier than ‘GoogleNet’ in terms of computational cost. The ‘Inception-v3’ network achieved the top-5 error rate of 3.58% and the top-1 error rate of 17.2% during the evaluation with the ‘ImageNet’ dataset55. We employed three different architectures on top of the ‘Inception-v3’ model viz. flatten layer with fully connected layer (Inception-V3_flatten-fc), global average pooling layer (Inception-v3_GAP) and global average pooling layer with fully connected layer (Inception-V3_GAP-fc). The network diagrams of the proposed three models have been shown in Fig. 2. In last couple of years, past studies have shown the effectiveness of Inception network (pre-trained/ base line trained) in recognizing the diseased images of crops26,27,34,36,38,43,48. It has also been observed that, ‘inception’ module of Inception network integrated with other benchmark deep CNN models obtained significant results for disease identification problems30,31,40. Keeping in mind the image recognition performance on disease classification in the previous studies, we chose inception-v3 as the base network for this experiment.

Architecture of the proposed models: (A) Inception-v3_flatten-fc, (B) Inception-v3_GAP and (C) Inception-v3_GAP-fc.
We evaluated and compared the performances of these models on the collected in-field image dataset of maize crop. We applied the baseline training approach where the all the layers of the models were trained with our maize dataset. We didn’t use any pre-trained weights for the models, rather weights were randomly initialised during training time. The models were trained for 200 epochs with a batch size of 64 for both training and validation datasets. We have provided an ablation study in the result section for choice of the epochs and batch size for the training phase. The adam optimizer with the default value of the hyperparameters such as learning rate of 0.001, beta_1 of 0.9 and beta_2 of 0.999 was used. During the training, categorical cross entropy function was used as the loss function.
We also trained few pre-trained state-of-the-art deep learning models such as VGG-16, VGG-19, Inception-v3, ResNet-50-v2, ResNet-101-v2, ResNet-152-v2 and InceptionResNet-v2 with our maize dataset. We employed transfer learning on these pre-trained models by using pre-trained ‘ImageNet’ weights that are available with Keras. We compared the performances of the pre-trained models with the approach proposed in this manuscript to showcase the impact of using baseline approach in a state-of-art of the deep CNN model.
Implementation
We implemented all the models using Keras56, a high-level API for the TensorFlow engine57 in the python programming language. All the experiments were conducted on the NVIDIA DGX GPU servers equipped with high-speed Tesla V100 GPUs. The details of the hardware and software configuration have been given in Table 3.
Results and discussion
Performance metrics
We divided the whole dataset into three partitions- training, validation and testing sets for conducting a fair performance evaluation. First, we divided the whole dataset into two parts with the ratio of 85:15 where 85% of the data were used for training and validation purpose and remaining 15% was kept separate for testing/evaluating the models after training. Next, we split the 85% data into two parts with different combinations for training-validation tasks. The summary of different training-validation configurations of the dataset is provided in Table 4. Here, we partitioned the original and the augmented data separately and combined thereafter to ensured that each partition must contain images from original dataset as well as the augmented ones. All the data splitting was done by a python script. After training and validation, the models were tested with the separate 15% testing dataset in all the experiments. It may be noted that the data used for testing all the models contains images from the original as well as augmented dataset. Then, we constructed confusion matrices to get disease-wise classification performance of the models. The confusion matrix gives the following variables:
-
True positive (TP): # items predicted positive and it is true
-
True Negative (TN): # items predicted negative and it is true
-
False Positive (FP): # items predicted positive and it is false
-
False Negative (FN): # items predicted negative and it is false
Next, the performance metrics such as precision, recall, accuracy and f1-score were also computed from the values of true positive (TP), false positive (FP), true negative (TN), and false negative (FN) for further evaluating models in this study58:
-
\(Prescion = \frac{TP}{{TP + FP}}\), measures the % of predicted as positives are actually positive
-
\(Recall = \frac{TP}{{TP + FN}}\), measures the % of actual positive are predicted as positive
-
\(Accuracy = \frac{TP + TN}{{TP + FP + TN + FN}}\), measure the overall performance of the model
-
\(F_{1} Score = 2*\frac{Precision*Recall}{{Precision + Recall}}\), measures the robustness of the model
Performance analysis of proposed models
Comparative analysis of the models in different data configurations
The overall testing accuracies for classifying the images into correct diseased-classes for different training-validation data configurations have been provided in Fig. 3 (please see Table S2 in the supplementary file for more details). The reported accuracies ranged from 90.84% (for Inception-v3_flatten-fc in 50–35 data configuration) to 95.71% (for Inception-v3_GAP in 70–15 data configuration). It can be observed from Fig. 3 that classification accuracies of all the models showed an increasing trend as the training data were increased accordingly. The models achieved maximum accuracies when 70% of whole dataset was used for training purpose. From Fig. 3, it can be seen that Inception-v3_GAP model reported the higher testing accuracies consistently than the other two models (Inception-v3_flatten-fc and Inception-v3_GAP_fc) in all the data configurations. The results implied that deep learning models worked well on the images even with complex backgrounds (such as soil, straw, human body parts, other plants parts and so on) and showed reasonably better results than random guessing. These results also support the fact that deep learning models require huge number of training samples to learn and capture the inherent features from the data under study.

Overall testing accuracies of the proposed models on different training-validation data configurations.
Comparative analysis of the models in 70–15 data configuration
The confusion matrices for the models trained on the 70–15 data configurations have been portrayed in Fig. 4. The diagonal elements of the matrix represent the proportion of predictions of the trained models that matched correctly with the class levels of test data and off-diagonals represent the incorrect predictions. The confusion matrices indicate that models were good at predicting the images of Healthy and BLSB class of maize dataset, while the models weren’t quite promising for the MLB and TLB classes. After 200 epochs of training, the Inception-v3_GAP model achieved the overall testing accuracy of 95.71% which was approx. 0.3% higher than other two models as shown in Table 5. The testing loss of the Inception-v3_GAP model was 0.1861 that was lowest of all. Therefore, it is evident that Inception-v3_GAP showed comparatively better performance for predicting the diseases of maize crop than the other two models. The class-wise prediction accuracies of Inception-v3_GAP model were reported as 99% for Healthy, 91% for MLB, 95% for TLB and 98% for BLSB. Here, the reason for low accuracy in MLB class might be the similarity of initial symptoms with the TLB diseases, in turn, the model wasn’t able to distinguish the features in such images and made false predictions. We also calculated the average precision, average recall and average f1-score for the models as shown in Fig. 5. It can be noted from Fig. 5 that Inception-v3_GAP model achieved highest values for these metrics such as 95.66% for average precision, 95.68% for average recall and 95.66% for average f1-score. Hence, these results supports the efficiency of the Inception-v3_GAP for correct predictions of the targeted diseases of maize crop.

Confusion matrices of the proposed models on the 70–15 data configuration (A) Inception-v3_flatten-fc (B) Inception-v3_GAP and (C) Inception-v3_GAP-fc.

Average precision, recall and f1-score of the proposed models on 70–15 data configuration.
Next, we analysed computational cost of these models in terms of training time per epoch and number of trainable parameters as showed in Fig. 6. It is evident from Fig. 6A that Inception-v3_GAP has the lowest number of trainable parameters, while Inception-v3_flatten-fc has the highest number of trainable parameters. And Fig. 6B indicates that both Inception-v3_GAP and Inception-v3_GAP-fc models took almost similar training time per epoch, whereas Inception-v3_flatten-fc took maximum time for training. This indicates that Inception-v3_GAP is superior than the other two models in terms the computational complexity.

Computational behavior of the proposed models on 70–15 data configuration (A) Number of trainable parameters and (B) Training time per epoch.
Comparative analysis of Inception-v3_GAP with pre-trained models
We presented comparative results between the pre-trained models and Inception-v3_GAP model in Fig. 7 (see Table S3 in the supplementary file for more details). The pre-trained models were trained on the 70–15 data configuration and tested on the 15% testing data of the maize dataset. It is apparent from Fig. 7A that among pre-trained models, VGG 19 achieved highest accuracy of 91.18% however, Inception-v3 achieved 72.8% and InceptionResnet-v2 achieved the least (56.05%). The results show that highest performing VGG 19 is 4.53% behind the Inception-v3_GAP in classification accuracy. From Fig. 7B,C,D, it is clear that performance of Inception-v3_GAP model was way better than pretrained models in terms of average precision, recall and f1-score. The highest performing pretrained model i.e. VGG 19 reported the average precision, recall and f1-score of 91.12%, 91.09% and 91.09%, respectively, whereas the Inception-v3_GAP reported these metrics as 95.66%, 95.68% and 95.66%. These results indicate that it is possible to achieve better classification performances in baseline training of deep learning models than the transfer learning on pre-trained ones. It suggests that baseline learning approaches can be remarkable in extracting low-level as well as high-level features from the image dataset under study.

Comparative analysis of classification performance of Inception-v3_GAP model with pre-trained models on 70–15 data configurations: (A) Classification Accuracy (B) Average Precision (C) Average Recall and (D) Average f1-score.
We also observed the computational behaviour of pre-trained models while training on the maize data. The number of trainable parameters and training time per epoch are presented in Fig. 8. It can be noted from Fig. 8A that VGG 16 has lowest number of trainable parameters and Resnet-152-v2 had highest number of trainable parameters. Whereas Inception-v3_GAP has approx. 48% more parameters than VGG 16 which almost similar to that of pre-trained Inception-v3. In Fig. 8B we observed an interesting fact that Inception-v3_GAP took 31 s per epoch, whereas Inception-v3 took only 11 s per epoch during training. Therefore, from computational point view, Inception-v3_GAP is slightly costlier than the pre-trained models. The main reason for this high computational cost in Inception-v3_GAP may be the baseline training i.e. training each and every layer of the model for feature extraction. This can be considered as a limitation of this approach. Despite this computational bottleneck, Inception-v3_GAP has greater advantage of higher classification accuracy in disease symptoms identification than the pretrained ones.

Comparison of computational behavior of Inception-v3_GAP model with pre-trained models on 70–15 data configuration: (A) Number of trainable parameters and (B) training time per epoch.
Performance analysis of Inception-v3_GAP model under enhanced brightness
We conducted experiments on enhancing the brightness levels of the images of maize crop. As we know that in field condition, images of diseases may suffer from uneven illumination. This will affect the perception of disease symptoms within the images and ultimately affect the model’s performance while identifying the brighter images. Therefore, we applied gamma correction technique in our whole dataset to enhance the brightness levels. The gamma correction is a power-law image transformation technique59. We applied the gamma \(\left( \gamma \right)\) operation at four levels [1.25, 1.5, 1.75 and 2.0] on the dataset and augmented with original dataset as shown in Fig. 9. Next, we trained the proposed Inception-v3_GAP model on this brightness enhanced dataset and presented the experimental results in Table 6. As observed in Table 6, the testing accuracy achieved by the model was 95.99% on this data with the loss of 0.1787. We can see that model’s classification performance slightly improved when data was augmented with brightness-enhanced images. This result indicates the effectiveness of the proposed model in identifying the diseased images even in the enhanced brightness condition. Hence, it can be concluded that the Inception-v3_GAP model is quite capable of capturing the features of the disease symptoms in both normal light as well as enhanced brightness condition.

Brightness enhancement of sample images using four gamma (γ) values.
Based on the overall performance analysis, it is observed that Inception-v3_GAP model was better than other two models for classifying the maize diseases. This model has shown quite significant results with respect to both prediction accuracy as well as computational complexity. The GAP layer in the ‘inception-v3' model has enhanced the feature extraction and learning capability of the model. The reason behind this fact is that the global average pooling layer enforces a close relationship between the feature maps and the class levels of the problem under study. It eases out the interpretation of the class labels from the feature maps becomes feasible and lowers testing loss during the predictions. Another advantage of GAP layer is that it doesn’t add any extra parameters to the model during training, hence there is very less chance of overfitting at this layer. Therefore, it ultimately lowers the model’s trainable parameters and yet gives better prediction results. On the other hand, the fc layer adds a no. of trainable parameters, which increases the risk of overfitting in the models during training. Hence, the classification performance of the models with fc layer was lower than the GAP model. Therefore, based on the empirical analysis, it can be concluded that the proposed Inception-v3_GAP significantly identifies the images of diseases of maize crop.
Comparative analysis with previous works on maize disease identification
Here, we presented a comparative analysis between our proposed approach and the approaches proposed in literatures40,44,46,49 for identification of diseases in maize crop in Table 7. From this comparison, it is quite evident that our proposed model is quite good at identifying the images of three diseases of maize crop even with complex backgrounds.
Ablation studies
In order to select the optimum batch size and epochs during the model training time, we conducted some experiments on different batch sizes and epochs. We presented the experimental results of Inception-v3_GAP model trained with four batch sizes of 8, 16, 32 and 64 images in Fig. 10. It can be observed from Fig. 10A,B that the training time per epoch decreases, while the testing accuracy increases as the batch sizes were increased. The optimum results were obtained with 64 batch size during the model training. In Fig. 11 testing accuracies were measured at different epochs of model training. It was noticed that the testing accuracy gradually increases with epochs till it reaches 200. After 200 epochs, the model starts overfitting with the dataset, so the epochs were chosen for 200 iterations.

Effect of batch sizes in the model performance (A) batch size vs training time per epoch and (B) batch size vs testing accuracy of the model.

Effect of epochs in the testing accuracies.
Conclusions
In this study, deep convolutional neural network-based approach has been proposed to automatically identify digital images of diseases along with healthy leaves of maize crop. A total of 5939 in-field images of maize crop were collected from the experimental fields located in three maize growing zones. This dataset consists of images of three diseases such as Maydis leaf blight (MLB), Turcicum leaf blight (TLB) and Banded leaf and sheath blight (BLSB) along with healthy ones. Images were collected using different devices such as handheld camera, smartphones to incorporate diversification in the images. In order to avoid the adverse effect of class imbalances in original dataset, some classes were augmented with artificial images generated using rotation enhancement and brightness enhancement methods.
Using the basic structural framework of state-of-the-art ‘Inception-v3’network, three network architectures were modeled on the maize dataset. We applied baseline learning in these architectures where all the computational layers were trained with our maize dataset. The experimental results state that Inception-v3_GAP achieved highest accuracy of 95.99% in separate test dataset. The Inception-v3_GAP model was efficient in learning the relevant features from the disease symptoms and in predicting correct class levels in the unseen data. This study proposes that deep learning techniques can provide quite promising results in identifying the disease symptoms of crops. Additionally, this experiment also suggests that in-field images of diseases symptoms of crops with varied background effects can be efficiently modeled by the deep learning techniques without applying any traditional image pre-processing techniques.
Furthermore, to showcase the effectiveness of our proposed approach, we conducted a detailed comparative analysis of a few pre-trained state-of-the-art networks. We used transfer learning approach for the pre-trained models. Comparative results show that Inception-v3_GAP model involves higher computational cost in terms of training time and number of parameters than pre-trained models. However, besides high computational cost, Inception-v3_GAP model performed quite better at correctly classifying the disease symptoms based on learned features from the data under study. It can be said that baseline training of deep CNN models is also capable of learning low level as well high levels features from the input images and further providing remarkable classification results on the dataset under study.
Moreover, we have validated the model’s disease classification results with the ___domain experts of maize crop. We are in process of conducting validation of the models in the farmer’s field. In future, the proposed model will be integrated with a mobile application for providing a real-time disease identification tool. This will facilitate a means of automated diagnosis of the disease symptoms to maize growers without any engagement of ___domain experts or extension workers. Therefore, timely management of diseases and reduction in overall production loss in maize crop will be ensured.
Data availability
The datasets used and analysed during the current study are available from the corresponding author on reasonable request.
References
Kaur, H. et al. Leaf stripping: An alternative strategy to manage banded leaf and sheath blight of maize. Indian Phytopathol. https://doi.org/10.1007/s42360-020-00208-z (2020).
FAOSTAT 2021, Statistical Database of the Food and Agriculture of the United Nations. FAO http://www.fao.org (2021).
Food and Agribusiness Strategic Advisory & Research Team (FASAR) & Vij, J. BOOSTING GROWTH OF INDIA’S MAIZE ECOSYSTEM - KEY IMPERATIVES. http://ficci.in/spdocument/23479/FICCI-YESBANKMaizeReport_2021.pdf (2021).
Rai, D. & Singh, S. K. Is banded leaf and sheath blight a potential threat to maize cultivation in Bihar?. Int. J. Curr. Microbiol. Appl. Sci. https://doi.org/10.20546/ijcmas.2018.711.080 (2018).
ICAR-IIMR 2020. Annual Maize Progress Report Kharif 2020. (2020).
Ali, F. et al. Heritability estimates for yield and related traits based on testcross progeny performance of resistant maize inbred lines. J. Food Agric. Environ. 9, 438 (2011).
Nwanosike, M. R. O., Mabagala, R. B. & Kusolwa, P. M. Effect of Northern leaf blight (Exserohilum turcicum) severity on yield of maize (Zea mays L.) in Morogoro, Tanzania. Int. J. Sci. Res. 4, 466–475 (2015).
Hooda, K. S. et al. Turcicum leaf blight—sustainable management of a re-emerging maize disease. J. Plant Dis. Prot. https://doi.org/10.1007/s41348-016-0054-8 (2017).
Hooda, K. S. et al. Banded leaf and sheath blight of maize: Historical perspectives, current status and future directions. Proc. Natl. Acad. Sci. India Sect. B Biol. Sci. https://doi.org/10.1007/s40011-015-0688-5 (2017).
Donatelli, M. et al. Modelling the impacts of pests and diseases on agricultural systems. Agric. Syst. https://doi.org/10.1016/j.agsy.2017.01.019 (2017).
Marwaha, S., Bedi, P., Yadav, R. & Malik, N. Diseases and pests identification in crops-a semantic web approach. in Proceedings of the 4th Indian International Conference on Artificial Intelligence (eds. Prasad, B., Lingras, P. & Ram, A.) 1057–1076 (IICAI, 2009).
Marwaha, S. & Agridaksh, A. Tool for developing online expert system. In Agro-Informatics and Precision Agriculture 2021 (ed. Reddy, P. K.) 17–23 (Allied Publishers Pvt. Ltd., New Delhi, 2012).
Yadav, V. K. et al. Maize AGRIdaksh: A farmer friendly device. Indian Res. J. Extens. Educ. 12, 13–17 (2012).
Marwaha, S., Chand, S. & Saha, A. Disease diagnosis in crops using content based image retrieval. in International Conference on Intelligent Systems Design and Applications, ISDA (2012). https://doi.org/10.1109/ISDA.2012.6416627.
Arora, A., Saha, L. K., Marwaha, S., Jain, R. & Jha, A. K. Online system for integrated pest management on tomato in Agridaksh. in 2015 International Conference on Computing for Sustainable Global Development, INDIACom 2015 (2015).
Kamilaris, A. & Prenafeta-Boldú, F. X. Deep learning in agriculture: A survey. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2018.02.016 (2018).
Too, E. C., Yujian, L., Njuki, S. & Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2018.03.032 (2019).
Lu, Y., Yi, S., Zeng, N., Liu, Y. & Zhang, Y. Identification of rice diseases using deep convolutional neural networks. Neurocomputing https://doi.org/10.1016/j.neucom.2017.06.023 (2017).
Rahman, C. R. et al. Identification and recognition of rice diseases and pests using convolutional neural networks. Biosys. Eng. https://doi.org/10.1016/j.biosystemseng.2020.03.020 (2020).
Chen, J., Zhang, D., Nanehkaran, Y. A. & Li, D. Detection of rice plant diseases based on deep transfer learning. J. Sci. Food Agric. 100, 3246–3256 (2020).
Lu, J., Hu, J., Zhao, G., Mei, F. & Zhang, C. An in-field automatic wheat disease diagnosis system. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2017.09.012 (2017).
Johannes, A. et al. Automatic plant disease diagnosis using mobile capture devices, applied on a wheat use case. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2017.04.013 (2017).
Zhang, X. et al. A deep learning-based approach for automated yellow rust disease detection from high-resolution hyperspectral UAV images. Remote Sens. https://doi.org/10.3390/rs11131554 (2019).
Picon, A. et al. Deep convolutional neural networks for mobile capture device-based crop disease classification in the wild. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2018.04.002 (2019).
Fuentes, A. F., Yoon, S., Lee, J. & Park, D. S. High-performance deep neural network-based tomato plant diseases and pests diagnosis system with refinement filter bank. Front. Plant Sci. https://doi.org/10.3389/fpls.2018.01162 (2018).
Brahimi, M., Boukhalfa, K. & Moussaoui, A. Deep learning for tomato diseases: Classification and symptoms visualization. Appl. Artif. Intell. https://doi.org/10.1080/08839514.2017.1315516 (2017).
Zhang, K., Wu, Q., Liu, A. & Meng, X. Can deep learning identify tomato leaf disease?. Adv. Multimedia https://doi.org/10.1155/2018/6710865 (2018).
Durmus, H., Gunes, E. O. & Kirci, M. Disease detection on the leaves of the tomato plants by using deep learning. in 2017 6th International Conference on Agro-Geoinformatics, Agro-Geoinformatics 2017 (2017). https://doi.org/10.1109/Agro-Geoinformatics.2017.8047016
Wang, G., Sun, Y. & Wang, J. Automatic image-based plant disease severity estimation using deep learning. Comput. Intell. Neurosci. https://doi.org/10.1155/2017/2917536 (2017).
Liu, B., Zhang, Y., He, D. J. & Li, Y. Identification of apple leaf diseases based on deep convolutional neural networks. Symmetry https://doi.org/10.3390/sym10010011 (2018).
Jiang, P., Chen, Y., Liu, B., He, D. & Liang, C. Real-time detection of apple leaf diseases using deep learning approach based on improved convolutional neural networks. IEEE Access https://doi.org/10.1109/ACCESS.2019.2914929 (2019).
Ma, J. et al. A recognition method for cucumber diseases using leaf symptom images based on deep convolutional neural network. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2018.08.048 (2018).
Zhang, S., Wu, X., You, Z. & Zhang, L. Leaf image based cucumber disease recognition using sparse representation classification. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2017.01.014 (2017).
Ramcharan, A. et al. Deep learning for image-based cassava disease detection. Front. Plant Sci. https://doi.org/10.3389/fpls.2017.01852 (2017).
Kundu, N. et al. Iot and interpretable machine learning based framework for disease prediction in pearl millet. Sensors https://doi.org/10.3390/s21165386 (2021).
Mohanty, S. P., Hughes, D. P. & Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. https://doi.org/10.3389/fpls.2016.01419 (2016).
Hughes, D. P. & Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics (2016).
Arnal Barbedo, J. G. Plant disease identification from individual lesions and spots using deep learning. Biosys. Eng. https://doi.org/10.1016/j.biosystemseng.2019.02.002 (2019).
Ferentinos, K. P. Deep learning models for plant disease detection and diagnosis. Comput. Electron. Agric. https://doi.org/10.1016/j.compag.2018.01.009 (2018).
Chen, J., Chen, J., Zhang, D., Sun, Y. & Nanehkaran, Y. A. Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agric. 173, 105393 (2020).
Nanehkaran, Y. A., Zhang, D., Chen, J., Tian, Y. & Al-Nabhan, N. Recognition of plant leaf diseases based on computer vision. J. Ambient. Intell. Humaniz. Comput. https://doi.org/10.1007/s12652-020-02505-x (2020).
DeChant, C. et al. Automated identification of northern leaf blight-infected maize plants from field imagery using deep learning. Phytopathology https://doi.org/10.1094/PHYTO-11-16-0417-R (2017).
Zhang, X., Qiao, Y., Meng, F., Fan, C. & Zhang, M. Identification of maize leaf diseases using improved deep convolutional neural networks. IEEE Access https://doi.org/10.1109/ACCESS.2018.2844405 (2018).
Sibiya, M. & Sumbwanyambe, M. A computational procedure for the recognition and classification of maize leaf diseases out of healthy leaves using convolutional neural networks. AgriEngineering https://doi.org/10.3390/agriengineering1010009 (2019).
Ahila Priyadharshini, R., Arivazhagan, S., Arun, M. & Mirnalini, A. Maize leaf disease classification using deep convolutional neural networks. Neural Comput. Appl. https://doi.org/10.1007/s00521-019-04228-3 (2019).
Marwaha, S. et al. Maize disease classification using deep CNN model. in Proceeding of 8th International Conference on Agricultural Statistics (2019).
Lv, M. et al. Maize leaf disease identification based on feature enhancement and DMS-robust alexnet. IEEE Access https://doi.org/10.1109/ACCESS.2020.2982443 (2020).
Haque, M. A. et al. Image-based identification of maydis leaf blight disease of maize (Zea mays) using deep learning. Indian J. Agric. Sci. 91, 1362–1367 (2021).
Chen, J., Wang, W., Zhang, D., Zeb, A. & Nanehkaran, Y. A. Attention embedded lightweight network for maize disease recognition. Plant. Pathol. 70, 630–642 (2021).
Kumar, B. et al. Standard Operating Practices for All India Coordinate Research Project on Maize. IIMR Technical Bulletin 2021/2 (2021).
Singh, R., Srivastava, R. P. & Lekha, R. Nothern corn leaf blight- an important disease of maize : An extension fact sheet. Indian Res. J. Extens. Educ. 12, 324–327 (2012).
Dhaka, V. S. et al. A survey of deep convolutional neural networks applied for prediction of plant leaf diseases. Sensors https://doi.org/10.3390/s21144749 (2021).
Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning Vol. 1(2) (MIT Press, 2016).
Bloice, M. D., Roth, P. M. & Holzinger, A. Biomedical image augmentation using Augmentor. Bioinformatics https://doi.org/10.1093/bioinformatics/btz259 (2019).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recogn. https://doi.org/10.1109/CVPR.2016.308 (2016).
Chollet, F. Keras. Journal of Chemical Information and Modeling (2013).
Abadi, M. et al. TensorFlow: Large-scale machine learning on heterogeneous distributed systems. (2016).
Misra, T. et al. SpikeSegNet-a deep learning approach utilizing encoder-decoder network with hourglass for spike segmentation and counting in wheat plant from visual imaging. Plant Methods https://doi.org/10.1186/s13007-020-00582-9 (2020).
Bertalmío, M. Brightness perception and encoding curves. in Vision Models for High Dynamic Range and Wide Colour Gamut Imaging 95–129 (Academic Press, 2020). https://doi.org/10.1016/B978-0-12-813894-6.00010-7.
Acknowledgements
We would like to thank ICAR-IIMR for their support and facilities for data collection and processing.
Funding
This study has been jointly funded by the National Agriculture Science Funds (NASF), ICAR and National Agricultural Higher Education Project (NAHEP), ICAR.
Author information
Authors and Affiliations
Contributions
M.H., S.M., C.D., A.A., K.S.H., M.K., S.I. and B.L. conceived the study. M.H. conducted the experiments and implemented the models described. M.H., C.K. and S.N. analysed the results and wrote the manuscript. K.S.H., P.S., S.A. and M.P. collected, curated and processed the image data. P.K. and R.A. provided the computational resources and facilities for data collection and conducting the experiments.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Haque, M.A., Marwaha, S., Deb, C.K. et al. Deep learning-based approach for identification of diseases of maize crop. Sci Rep 12, 6334 (2022). https://doi.org/10.1038/s41598-022-10140-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-10140-z
This article is cited by
-
Foliar symptom-based disease detection in black pepper using convolutional neural network
Phytopathology Research (2025)
-
Detection of cotton crops diseases using customized deep learning model
Scientific Reports (2025)
-
SPDGrNet: A Lightweight and Efficient Image Classification Network for Zea mays Diseases
Journal of Crop Health (2025)
-
Deep SqueezeNet learning model for diagnosis and prediction of maize leaf diseases
Journal of Big Data (2024)
