
Abstract
As the road traffic situation becomes complex, the task of traffic management takes on an increasingly heavy load. The air-to-ground traffic administration network of drones has become an important tool to promote the high quality of traffic police work in many places. Drones can be used instead of a large number of human beings to perform daily tasks, as: traffic offense detection, daily crowd detection, etc. Drones are aerial operations and shoot small targets. So the detection accuracy of drones is less. To address the problem of low accuracy of Unmanned Aerial Vehicles (UAVs) in detecting small targets, we designed a more suitable algorithm for UAV detection and called GBS-YOLOv5. It was an improvement on the original YOLOv5 model. Firstly, in the default model, there was a problem of serious loss of small target information and insufficient utilization of shallow feature information as the depth of the feature extraction network deepened. We designed the efficient spatio-temporal interaction module to replace the residual network structure in the original network. The role of this module was to increase the network depth for feature extraction. Then, we added the spatial pyramid convolution module on top of YOLOv5. Its function was to mine small target information and act as a detection head for small size targets. Finally, to better preserve the detailed information of small targets in the shallow features, we proposed the shallow bottleneck. And the introduction of recursive gated convolution in the feature fusion section enabled better interaction of higher-order spatial semantic information. The GBS-YOLOv5 algorithm conducted experiments showing that the value of [email protected] was 35.3\(\%\) and the [email protected]:0.95 was 20.0\(\%\). Compared to the default YOLOv5 algorithm was boosted by 4.0\(\%\) and 3.5\(\%\), respectively.
Similar content being viewed by others

Introduction
Since the 20th century, object detection has become an important research result in the field of computer vision. It has been widely developed and applied in the fields of intelligent transportation, pedestrian detection and driverless driving1,2,3,4. As the accuracy of image classification improves, object detection algorithms based on convolutional neural networks5,6 have gradually become an current research hotspot.
UAV technology7 has become an important application area for drones with the in-depth study of relevant theory and practice. With the creation of high-precision sensors and the development of related technologies, the performance of UAVs is constantly being improved. It is also widely used in pedestrian detection, daily patrols and vehicle detection8. Drones are often equipped with high-definition cameras for image acquisition, with the advantages of easy operation, flexible flight, good stability, low cost, etc. In recent years, with the development of computer vision technology, the application of UAV intelligent transportation based on computer vision detection technology has received more and more attention from domestic and foreign research scholars.
For urban traffic management, both population and vehicle detection is an important detection object. Dense crowds and mixed traffic with non-motorized vehicles are the main factors causing traffic congestion and gridlock9. In addition, each city has a limited number of traffic police officers, and when there are traffic jams or situations requiring police patrols in many areas of the city, a large number of police officers need to be mobilized to maintain social order. This is not only labor demanding, but also less work efficient. The utilization of drones for daily crowd detection in priority places as well as vehicle detection10 on key roads not only brings efficiency improvements to the daily work of traffic police, but also offers a higher level of security.
Most current object detection algorithms are generally aimed at normal sized objects. And these algorithms perform well on most open source datasets11, such as the Pascal VOC dataset (VOC)12, Common Objects In Context dataset (COCO)13, and the ImageNet dataset14. The COCO dataset, common to the target detection field, contains more than 330,000 images and 80 categories15. It is also classified into large-size target16 (objects with area larger than 96 \(\times\) 96), medium-size target16 (objects with area between 32 \(\times\) 32 and 96 \(\times\) 96), and small-size target16 (objects with area smaller than 32 \(\times\) 32). The datasets such as COCO and VOC include medium and large size targets occupying most of them. The performance of target detection models in datasets such as COCO cannot meet the requirements of small target detection. In regard to the above problems, small target dataset17 applications for UAV photography were born, such as VisDrone 201918, UAV 12319, etc. Compared to the default algorithm, our proposed GBS-YOLOv5 algorithm encountered the following challenges for experiments on the VisDrone dataset20:
-
There are many targets. Hundreds of targets to be detected in each image, and many targets overlap21;
-
Target deformation. Different from the conventional21 dataset, the shooting angle of the UAV causes the target deformation;
-
The size of the target is too small21, because it was taken by a drone in the air, far away from the target. The small size of the target in the picture makes normal model training ineffective;
-
The background and scene are complex. The dataset contains two kinds of scenes, day and night. The UAV has a large perspective21, and the UAV22 takes pictures of more complex backgrounds.
Some samples of the VisDrone 2019 dataset are shown in Fig. 1.

Datasets examples in (a) busy street block, (b) crossroads, and (c) the suburbs.
The improved algorithm was mainly based on the default CSP-Darknet53 (Cross Stage Partial Darknet53)23. Introduced efficient spatio-temporal interaction (ESI) module, and the C3 (Cross Stage Partial Bottleneck with 3 convolutions) module24 was replaced in Backbone24 with ESI module. The shallow bottleneck (SB) module was used to retain more shallow semantic information25, thus solved the problem of large loss of small target information26. We added a fourth detector head to the original network for the output of minimal targets. The spatial pyramid convolution (SPC) module was used to extract the shallow feature information as the fourth detection head. Finally, we introduced PAN (Path Aggregation Network) feature fusion27 into recursive gated convolution28 in the Neck part of YOLOv529. This could better realize the semantic information interaction of high-order spatial features30. Through experiments, the test results based on the VisDrone dataset showed that GBS-YOLOv5 was 4.0\(\%\) and 3.5\(\%\) higher than the original YOLOv5 algorithm under the conditions of IoU of 0.5 and 0.95, respectively.
To sum up, our main contributions are as follows:
-
An efficient spatio-temporal interaction module was proposed. It could better preserve spatial feature information, deepen the depth of feature extraction31 network, and mine more abundant feature information32 of the target;
-
The shallow bottleneck module was added to the Backbone structure to enrich the shallow feature layer information;
-
Added SPC detection head. Used the pyramidal convolution module as a feature extraction33 module for small targets;
-
Recursive gated convolution was combined to the Neck part34 of feature fusion to realize the semantic information interaction of high-value spatial features.
Realted work
With the rapid development of artificial intelligence technology35 since the 20th century. Target detection algorithm based on depth learning36 has become the mainstream target detection algorithm with its advantages of simple structure and higher accuracy. There are mainly two research directions: one-stage37 network model and two-stage38 network model.
The two-stage model divides the target detection problem into two stages: extracting candidate regions39, classifying candidate regions and position correction39. Object detection is realized through these two stages.In 1998, Yann Le Cun et al. first proposed the application of convolutional neural network to digital recognition40. In 2012, Alex Krizhevsky and others proposed the AlexNet algorithm and won the championship in the ImageNet 2012 Challenge41 Since then, target detection based on deep learning has entered a stage of rapid development. In 2015, Girshick R realized the shared convolution operation based on the R-CNN (Regions with CNN features)42 algorithm and proposed Fast R-CNN43. Later, Faster R-CNN44 was proposed. He Kaiming put forward Mask R-CNN45 in 2017, realizing the task of segmentation46.
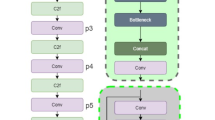
Due to the two-stage is based on the classification of the target detection algorithm, the detection speed is slow47, and still can not meet most of the requirements of real-time places. Therefore, one stage target detection algorithm is proposed to solve the real-time problem48 of detection. Among those, the one stage detection algorithms mainly include mainstream algorithms such as YOLO (You only look once)49, SSD (Single Shot MultiBox Detector)50 and RetinaNet51. In 2016, Redmon J et al. proposed the YOLO algorithm52. Unlike the two stages, the algorithm uses the target detection framework as a regression problem52. Subsequently, YOLOv253, YOLOv354, YOLOv455, YOLOv556 and YOLOv757 of YOLO series were put forward successively. This series of algorithms are easier to be embedded in mobile devices because of their small amount of computation and fast computing speed. In 2022, F-CenterNet was proposed, which was a UAV target detection algorithm based on a single-stage detection framework. The algorithm used embedded reinforcement learning to adaptively optimize the network structure and loss function. In 2020, Scaled-YOLOv5 was proposed, a lightweight UAV target detection algorithm that used technologies such as multi-resolution training, data augmentation, and adaptive convolution to achieve fast inference while maintaining high accuracy. DroneNet was an integrated framework for UAV target detection and tracking problems, including classic models such as Faster R-CNN, YOLOv2 and had achieved good results by training ensemble models. Our improved algorithm and experimental work are based on YOLOv5 algorithm. The default YOLOv5 network structure is shown in Fig. 2. As can be seen, YOLOv5 is divided into Backbone, Neck and Head sections in total.

The default YOLOv5 network structure.
The Backbone section is mainly composed of the downsampling module (CBS), the residual module (C3) and the SPPF (Spatial Pyramid Pooling-Fast)58. One of these is the CBS module59 which is a standard convolution module. It is made up of the convolution operation, the batch norm normalisation process and the SiLU activation function60. The C3 module is the main module for learning on residual features. Its structure is divided into two branches. One of the branches uses multiple Bottleneck stacks and three standard convolutional layers. The other one only goes through a basic convolution module. Finally, the two branches are subjected to the concat operation. When the picture is sent into the YOLOv5 detection frame. First, the Backbone convolution module is used to perform the down sampling operation of the feature map. Then, learn the residual characteristics through the residual network and deepen the depth of the network. Next, repeat the above operations and finally pass through the SPPF (Spatial Pyramid Pooling Fast) module. Finally, the feature information is transferred to the Neck part for feature fusion.
The Neck section is made up of FPN29 (Feature Pyramid Networks, FPN) and PAN29 (Path Aggregation Network, PAN) structures. Where the FPN is a top-down feature fusion from the bottom of the Backbone network to build a high-level semantic feature map. PAN structure carries out feature fusion from bottom to top to make up for strengthened positioning information.
The Head section is made up of predictor 1, predictor 2 and predictor 3. The images undergo feature extraction, feature fusion to eventually form three sizes of detection heads, which are used to output three different sizes of targets: large, medium and small.
In the field of target detection, the performance of target detection algorithms requires certain evaluation criteria to measure how well the algorithm performs. The mAP (mean Average Precision) is a very important measure. In addition, common metrics used to measure target detection algorithms are accuracy27, precision27, recall27, IoU27, etc.
IoU: Positioning accuracy can be determined by the window overlap between the detection window and the marked object, i.e. Intersection-Over-Union (IoU). Let the marker window be A and the detection window be B. The IoU is calculated as in Eq. (1).
The numerator represents the area of the overlap between windows A and B, and the denominator represents the sum of the areas of windows A and B. Obviously, the value of IoU is between [0, 1], while the closer the IoU is to 1, the more the two windows overlap and the better the positioning accuracy, and vice versa.
P: represents the precision49 rate. It is the ratio of the actual number of positive samples in the predicted sample to the number of all positive samples. The larger the value the better, 1 being ideal. Calculated as in Eq. (2).
R: represents the recall49 rate. This is the ratio of the actual number of positive samples in the predicted sample to the number of samples predicted. Generally speaking, the higher the recall rate, the lower the accuracy rate tends to be. Calculated as in Eq. (3).
Map: Mean Average Precision49. It averages the accuracy values for multiple validation sets of individuals. As a measure of detection accuracy in object detection. There are two metrics in total. At IoU of 0.5, this is expressed as [email protected]. At IoUs of 0.5–0.95, the average mAP on a step size of 0.05 is expressed as [email protected]:0.95.
Improved methods
The YOLO series was a deep learning-based target detection framework that achieved efficient target detection by detecting all objects in a single forward propagation. YOLOv7 and YOLOv5 were different versions of YOLO, with YOLOv7 being the newer version. In terms of computational efficiency and accuracy, YOLOv7 improved relative to YOLOv5. However, YOLOv5 was much faster than YOLOv7 in terms of training and inference and had a lower memory footprint. This made YOLOv5 more advantageous in UAV detection application scenarios. Therefore, it remained our choice to improve YOLOv5 version. The network structure of our proposed GBS-YOLOv5 algorithm was shown in Fig. 3. Firstly, at the input of the network, we used a shallow bottleneck to downsample the picture while increasing the number of channels of the feature map. By this it would be possible to retain as much detailed information about the target as possible. Next, our proposed efficient spatiotemporal interaction module was used as the residual feature learning module for Backbone. It could better combine deep semantic information with shallow semantic information. In the Neck section, we added a spatial pyramidal convolution module to the 160 \(\times\) 160 layers as the detection head for very small targets. Finally, recursive gated convolution was introduced into the PAN structure to enhance spatial localization information.

The network of GBS-YOLOv5.
Spatial pyramid convolution module
In the default Neck section (shown in Fig. 4a), a combination of FPN+PAN ideas was used. The feature maps were fused with feature information extracted from Backbone’s C3, C4 and SPPF layers, respectively. Firstly fusion of high level features with the underlying features through the FPN network. It aimed to simultaneously exploit the high resolution of the underlying features and the rich semantic information of the high-level features to improve the detection of small objects. The different levels of feature information were then fused by the PAN structure. The purpose was to retain a more overly shallow ___location feature to further improve network performance. The final results after three inspection heads as pre-detection were 80 \(\times\) 80, 40 \(\times\) 40 and 20 \(\times\) 20. We proposed the spatial pyramidal convolution module as the detection head for very small targets in the default Neck section (see Fig. 4b). It contained a 3 \(\times\) 3 convolution, SPPF module, SPPF\(\_\)1 module and C3 module. The SPPF\(\_\)1 contained a 1 \(\times\) 1 convolution and three parallel standard convolutions (with convolution kernel sizes of 3 \(\times\) 3, 5 \(\times\) 5 and 7 \(\times\) 7). The Spatial Pyramid Convolution module took the output of Backbone’s P2 layer as input to the module.
Initially after SPPF block and SPPF\(\_\)1 block, the number of channels of the feature map was changed. In the next stage, the feature map was stitched together by the Concat operation. An output of the spatial pyramidal convolution module was used as a 160 \(\times\) 160 detection head. Finally, we embed a recursive gated convolution on top of the default Neck.

The spatial pyramid convolution module (a) default YOLOv5 structure, (b) b-1: GBS-YOLOv5 structure, b-2: SPC network and b-3: SPPF\(\_\)1 structure.
Efficient space-time interaction module
The default C3 module consisted mainly of 1 \(\times\) 1 convolution and N \(\times\) bottleneck modules. This module was the main module for learning about residual features. Its structure was divided into two branches (as shown in Fig. 5a). The left branch used an N \(\times\) Bottleneck stack and 3 standard convolutional layers. The right-hand branch undergoed only one basic convolution module. Finally, the two branches were subjected to a concat operation. Despite its effectiveness in increasing the depth of the network, the C3 module was still inadequate in extracting feature information for small targets. This led us to propose the Efficient Spatio-Temporal Interaction module. The module was used to deepen the feature extraction network while at the same time extracting feature information about the target. The structure was divided into two main left and right branches (shown in Fig. 5b). First, the left branch consisted of N recursive gated convolution and 1 \(\times\) 1 convolution layers. Its function was to achieve input adaptation and higher order spatial interaction through recursive gated convolution. Immediately afterwards, the feature map was fed into the 1 \(\times\) 1 convolution module to change the feature dimension. Immediately afterwards, the feature map was fed into the 1 \(\times\) 1 convolution module to change the feature dimension. The right-hand branch was a stack of standard convolutions and serves to extract a larger range of features and deeper features. Finally, the output of the two branches was subjected to a Concat operation.
In this case, the recursive gated convolution is implemented as follows.Supposed that \(x\in {{R}^{HW\times C}}\) is the input feature. The projection features \({{p}_{0}}\) and \(\left\{ {{q}_{k}} \right\} ,k\in \left[ 0,n-1 \right]\) are obtained by means of a linear projection function \(\phi\). Its effect is to slice and dice the input features according to the number of channels, as shown in Eq. (4).
The sliced features are fed sequentially into the gated convolution for recursive operations as in Eq. (5), where \(k=0,1,\ldots ,n-1\).
Equation (2) scales the output features of each operation by \({1}/{\alpha }\;\). In the process of spatial interaction it is necessary to ensure that both are of the same dimension. Therefore, \({{g}_{k}}\) is the dimensional mapping function during the operation. Finally, the output y is obtained by recursive gated convolution, as in Eq. (6).

Efficient space-time interaction module (a) C3 block, (b) ESI block.
Shallow bottleneck
In the default YOLOv5 model, a 640 \(\times\) 640 size image with 3 channels was given 2\(\times\) downsampling through a 6 \(\times\) 6 size convolution kernel with a step size of two. Convolution kernels with a length and width of 6 were not friendly to the retention of small target information. After 2\(\times\) downsamplings, a great deal of detailed information about small targets was lost. Therefore, in our proposed GBS-YOLOv5 model, a large convolutional kernel was transformed into 1 \(\times\) 1 and 3 \(\times\) 3 convolutional kernels. The feature map was subsequently 2\(\times\) downsampled after a 3 \(\times\) 3, step 2 convolution kernel. The specific structure was shown in Fig. 6, where the default model was shown in the Fig. 6a and the improved model was shown in the Fig. 6b.

The default structure compared with the improved structure (a) default input, (b) shallow bottleneck input.
Experimental results
All Experiments Conducted on VisDrone 2019 Dataset. For the fairness of the ablation experiments, we also tested excellent algorithms such as GBS-YOLOv5 and YOLOv3 based on the VisDrone dataset. The experimental results indicated that our proposed GBS-YOLOv5 had a good performance in terms of detection accuracy.
Experimental setting
Experimental equipment
We used Windows 11 with a 12th Gen Intel(R) Core(TM) i5-12400 processor, 8 GB of RAM and an NVIDIA Geforce GTX3060 graphics card with 12 GB of Graphics memory.
Dataset
Drones being loaded with cameras were already being used rapidly in agriculture, transport, aerial photography and other areas. As a result, the requirements for drones to collect visual data had become more stringent. To be persuasive, we used the VisDrone open source dataset for our experiments. The VisDrone dataset was collected by the AISKYEYE team at the Machine Learning and Data Mining Laboratory of Tianjin University. The datasets analysed during the current study were available in the VISDRONE repository (https://github.com/VisDrone/VisDrone-Dataset). It consisted of 26,908 frames and 10,209 images. This was captured by a drone camera and covers a wide area. These included ___location (14 different cities from China separated by thousands of kilometres), environment (urban and rural), objects (pedestrians, vehicles, bicycles, etc.) and density (sparse and crowded scenes). In addition to this, the datasets were collected using different drone platforms18 (i.e. different models of drones) in different scenarios and under different weather and lighting conditions19. The dataset was predefined with 10 category (pedestrian, person, car, van, bus, truck, motor, bicycle, awning-tricycle, and tricycle) bounding boxes. For the experiments, we used 10,209 still images and divided the dataset into a training set, a validation set, and a test set according to the official predefined. The dataset contained small targets, with heavy target occlusion and a large number of detection targets. In this case, the label information of the VisDrone dataset and the number of categories were shown in Fig. 7.

Volume information for each category in the VisDrone 2019 dataset.
Experimental detailed information
During the experiment, the AISKYEYE team has divided the dataset into a training set (6471 images), a validation set (548 images) and a test set (1610 images). In the experiment, we used the training parameters to set the training weights without official weights, the number of training epochs to 150, the batch size as 16, and the input size of 640 \(\times\) 640. The training hyperparameters were set as follows. The initial learning rate was 0.01, where the stochastic gradient descent (SGD) method was 1E−2 and the stochastic optimiser Adam was 1E−3. The loss function in training was shown in equation 7. And to prevent overfitting phenomenon in training, we set the following hyperparameters for the characteristics of Visdrone dataset. Mosaic data enhancement was 1.0, scaling factor was 0.5, inversion factor was 0.1, mage HSV-value augmentation was 0.4, image HSV-saturation augmentation was 0.7, and image HSV-hue augmentation was 0.015, etc.
In this case, the Loss in training contained three main aspects of loss: rectangular box loss (\(L\text {os}{{\text {s}}_{box}}\)), confidence loss (\(L\text {os}{{\text {s}}_{obj}}\)), and classification loss (\(L\text {os}{{\text {s}}_{}}\)). Loss weights a, b, c were set to: 1.0, 0.05, 0.5, respectively. Before starting training, the YOLOv5 model first calculated the best recall of the anchored boxes for this dataset. When the best recall was greater than or equal to 0.98, used the model default anchor box. Conversely, if the optimal recall did not reach the specified threshold, the model recalculated the appropriate anchor frame using the kmeans clustering algorithm. Through extensive experimentation, we had finalised the four inspection head anchor frame sizes for the GBS-YOLOv5 model, as shown in Table 1.
The official YOLOv5s model contained a total of five sub-models: YOLOv5l, YOLOv5m, YOLOv5n, YOLOv5s, YOLOv5x. These five types of models were diferent only in the parameters of the width and depth of the network. Due to the consideration of real-time algorithm, we chose YOLOv5s as the experimental control group, with network depth and width parameters of 0.33 and 0.50, respectively. In the training process, the training batch was adjusted to 16 and the works to 10. Image enhancement techniques such as mosaic and rotation were used. Uses a default model preheat round of 3 epochs.
Experimental results
We commenced by training YOLOv5 and GBS-YOLOv5 on the VisDrone 2019 dataset. A stochastic gradient descent method was used to optimize the model during the training process. We adjusted the training batch to 16, the momentum to 0.937 and the image input size to 640 \(\times\) 640. The learning rate was set to 0.01. In addition, we used data enhancement methods such as mosaics and flips to extend the dataset during training. Of these, the experimental results for YOLOV5 and GBS-YOLOv5 were shown in Table 2. And Some GBS-YOLOv5 of the detection results were shown in Fig. 8.

Partial detection results graph of GBS-YOLOv5 algorithm on Visdrone dataset.
Table 2, we clear noticed that our proposed algorithm has been improved by 1.8 \(\%\) for precision (P), 3.1 \(\%\) for recall (R), 4.0 \(\%\) for [email protected] and 3.5 \(\%\) for [email protected]:0.95. Performance was further improved compared to the default YOLOv5s.
In addition to this, we compared the experimental results of the various algorithms on VisDrone. In order to compare the performance of GBS-YOLOv5 with various other algorithms more intuitively, we used [email protected] as performance metrics. And we tuned the model scaling factors of YOLOv3 as well as yolov3-spp to ensure that the model scaling was the same as YOLOv5s. The network model has a depth multiple of 0.33 and a network width multiple of 0.50. The experimental results for each type of model were shown in Table 3.
In Table 3, it could be easily seen that the proposed GBS-YOLOv5 model achieves better results in terms of accuracy compared to other detection models. The GBS-YOLOv5 had a 0.4\(\%\) higher UAV detection accuracy than the YOLOv5m. It also outperformed YOLOv3, YOLOv3-spp and YOLOv3-tiny by 4.0\(\%\), 3.8\(\%\) and 20.0\(\%\), respectively.
Ablation experiment
In this section, the results of the ablation experiments were also presented and analysed. The ablation experiments were performed on the VisDrone 2019 dataset. We contemplated that the main contribution of this paper was based on the Backbone, Neck section. Therefore, the ablation experiment was divided into three parts. The results of the experiments were shown in Table 4.
As seen in Table 4, YOLOv5+ESI, YOLOv5+SB, and YOLOv5+SPC were each added to YOLOv5 with the ESI block, SB block and SPC block, respectively. This would give us a better idea of whether the improvements we proposed were effective. On top of the default YOLOv5 model, only the ESI module was plused. The experimental results indicated that the accuracy of the model after the addition of ESI improved by 1.3\(\%\) over the original model. In the same way, we added only the SB module and it could be seen that the accuracy was reduced by 0.3\(\%\) compared to the original model. Since the SB module was designed to work against the SPC module, the 0.3\(\%\) reduction in accuracy was negligible. We added the SPC module to the original model, and by comparing the experimental results, the addition of the SPC module improved the accuracy by 2.3\(\%\) over the original model. Finally, the modules were assembled to form the GBS-YOLOv5. The precision of the ten categories was clearly seen in Table 4. The bicycle detection accuracy was reduced by 0. 8\(\%\) compared to the original model. The detection accuracy for the remaining nine categories was superior to the original model.
Conclusion
In this paper, the GBS-YOLOv5 algorithm based on YOLOv5 has been proposed. Three major contributions are listed. The first contribution is that an efficient spatiotemporal interaction module has been proposed to enhance the network’s ability to extract information about target features. The second contribution is that a shallow Bottleneck was proposed for the small target of UAV photography. It can enrich shallow feature information and help preserve small target information. The third point, we propose an spatial pyramid convolution module to improve small target detection performance through shallow information mining and feature fusion. The experiments demonstrated that the detection of our proposed GBS-YOLOv5 under the UAV dataset was better than that of other network models.
Data availability
All the images and experimental test images in this paper were from the open source VisDrone dataset. The VisDrone dataset was collected by the AISKYEYE team at the Machine Learning and Data Mining Laboratory of Tianjin University. The datasets analysed during the current study were available in the VISDRONE repository (https://github.com/VisDrone/VisDrone-Dataset).
References
Tao, Y., Zongyang, Z., Jun, Z., Xinghua, C. & Fuqiang, Z. Low-altitude small-sized object detection using lightweight feature-enhanced convolutional neural network. J. Syst. Eng. Electron. 32(4), 841–853 (2021).
Chen, C., Liu, B., Wan, S., Qiao, P. & Pei, Q. An edge traffic flow detection scheme based on deep learning in an intelligent transportation system. IEEE Trans. Intell. Transp. Syst. 22(3), 1840–1852 (2021).
Yang, Z. Pedestrian detection for intelligent vehicle based on bilayer difference features algorithm. In International Conference on Transportation Information and Safety (ICTIS), 337–340 (2015).
Prajwal, P., Prajwal, D., Harish, D. H., Gajanana, R., Jayasri, B. S. & Lokesh, S. Object detection in self driving cars using deep learning. In International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), 1–7 (2021).
Wang, X., Bai, X., Liu, W. & Latecki, L. J. Feature context for image classification and object detection. In Computer Vision and Pattern Recognition Conference 2011. IEEE, 961–968 (2011).
Kim, H., Lee, Y., Yim, B., Park, E. & Kim, H. On-road object detection using deep neural network. In International Conference on Consumer Electronics-Asia (ICCE-Asia), 1–4 (2016).
Böyük, M., Duvar, R. & Urhan, O. Deep learning based vehicle detection with images taken from unmanned air vehicle. In Innovations in Intelligent Systems and Applications Conference (ASYU) 1–4 (2020).
Xu, Y., Yu, G., Wu, X., Wang, Y. & Ma, Y. An enhanced Viola–Jones vehicle detection method from unmanned aerial vehicles imagery. IEEE Trans. Intell. Transp. Syst. 18(7), 1845–1856 (2017).
Jonnalagadda, M., Taduri, S. & Reddy, R. RealTime traffic management system using object detection based signal logic. In Applied Imagery Pattern Recognition Workshop (AIPR) 1–5 (2020).
Zhang, X. & Zhu, X. Vehicle detection in the aerial infrared images via an improved Yolov3 network. In International Conference on Signal and Image Processing (ICSIP), 372–376 (2019).
Avola, D. et al. A UAV video dataset for mosaicking and change detection from low-altitude flights. IEEE Trans. Syst. Man Cybern. Syst. 50(6), 2139–2149 (2020).
Everingham, M., Van Gool, L., Williams, C. K., Winn, J. & Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vision 88(2), 303–338 (2010).
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Deva, Dollár, P. & Zitnick, C. L. Microsoft COCO: Common objects in context. In European conference on computer vision. Springer 740–755 (2014).
Deng, J., Dong, W., Socher, R., Li, L. J., Kai, L. & Li, F. ImageNet: A large-scale hierarchical image database. Conference on Computer Vision and Pattern Recognition 248–255 (2009).
Puri, D. COCO dataset stuff segmentation challenge. In International Conference On Computing, Communication, Control And Automation (ICCUBEA) 1–5 (2019).
Borji, A. Complementary datasets to COCO for object detection. In arXiv:2206.11473 (arXiv preprint) (2022).
Cao, K .Y. Cui, X. & Piao, J. C. Smaller target detection algorithms based on YOLOv5 in safety helmet wearing detection. IN International Conference on Robotics and Computer Vision (ICRCV) 154–158 (2022).
Du, D., Zhu, P., Wen, L., Bian, X., Lin, H., Hu, Q., Peng, T., Zheng, J., Wang, X., Zhang, Y. & Zhang, L. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In International Conference on Computer Vision Workshop (ICCVW) 213–226 (2019).
Mueller, M., Smith, N. & Ghanem, B. A benchmark and simulator for UAV tracking. In European Conference on Computer Vision 445–461 (Springer, 2016).
Liu, Z., Gao, G., Sun, L. & Fang, Z. HRDNet: High-resolution detection network for small objects. In International Conference on Multimedia and Expo (ICME) 1–6 (2021).
Zhu, P., Wen, L., Du, D., Bian, X., Fan, H., Hu, Q. & Ling, H. Detection and tracking meet drones challenge. arXiv:2001.06303 (arXiv preprint) (2020).
Xie, X. & Lu, G. A research of object detection on UAVs aerial images. In International Conference on Big Data and Artificial Intelligence and Software Engineering (ICBASE) 342–345 (2021).
Misra, D. Mish: A self regularized non-monotonic activation function. arXiv:1908.08681 (arXiv preprint) (2019).
Jana, A. P., Biswas, A. & Mohana, YOLO based detection and classification of objects in video records. In International Conference on Recent Trends in Electronics, Information and Communication Technology (RTEICT) 2448–2452 (2018).
Gongguo, Z. & Junhao, W. An improved small target detection method based on Yolov3. International Conference on Electronics, Circuits and Information Engineering (ECIE) 220–223 (2021).
Xu, Q. et al. Research on small target detection in driving scenarios based on improved Yolo network. IEEE Access 8, 27574–27583 (2020).
Mahendru, M. & Dubey, S. K. Real time object detection with audio feedback using Yolo vs. Yolov3. In International Conference on Cloud Computing, Data Science & Engineering (Confluence) 734–740 (2021).
Rao, Y., Zhao, W., Tang, Y., Zhou, J., Lim, S. N. & Lu, J. Hornet: Efficient high-order spatial interactions with recursive gated convolutions. arXiv:2207.14284 (arXiv preprint) (2022).
Geng, Z. & Chen, G. A Novel real-time grasping method cobimbed with YOLO and GDFCN. In Joint International Information Technology and Artificial Intelligence Conference (ITAIC) 500–505 (2022).
Xie, J., Pang, Y., Nie, J., Cao, J. & Han, J. Latent feature pyramid network for object detection. In IEEE Transactions on Multimedia 1 (2022).
Xing, H., Wang, S., Zheng, D. & Zhao, X. Dual attention based feature pyramid network. China Commun. 17(8), 242–252 (2020).
Bayhan, E., Ozkan, Z., Namdar, M. & Basgumus, A. Deep learning based object detection and recognition of unmanned aerial vehicles. In International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA) 1–5 (2021).
Noori, M., Mohammadi, S., Majelan, G. S., Bahri, A. & Havaei, M. DFNet: Discriminative feature extraction and integration network for salient object detection. Eng. Appl. Artif. Intell. 89, 103419 (2020).
Yang, T. & Tong, C. Small traffic sign detector in real-time based on improved YOLO-v4. In International Conference on High Performance Computing and Communications; 7th International Conference on Data Science and Systems; 19th International Conference on Smart City; 7th International Conference on Dependability in Sensor, Cloud and Big Data Systems and Application (HPCC/DSS/SmartCity/DependSys) 1318–1324 (2021).
Zhu, P. Convolutional neural networks based study and application for multicategory skin cancer detection. In International Conference on Electronic Communication and Artificial Intelligence (IWECAI) 558–561 (2022).
özbay, M. & Şahingil, M. C. A fast and robust automatic object detection algorithm to detect small objects in infrared images. In Signal Processing and Communications Applications Conference (SIU) 1–4 (2017).
Xing, C., Liang, X. & Yang, R. Compact one-stage object detection network. In International Conference on Computer Science and Network Technology (ICCSNT) 115–118 (2020).
Luo, J., Yang, Z., Li, S. & Wu, Y. FPCB surface defect detection: A decoupled two-stage object detection framework. IEEE Trans. Instrum. Meas. 70, 1–11 (2021).
Bai, T. Analysis on two-stage object detection based on convolutional neural networks. In International Conference on Big Data and Artificial Intelligence and Software Engineering (ICBASE) 321–325 (2020).
Lecun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998).
Iandola, N. F., Han, S., Moskewicz, W. M., Ashraf, K., Dally, J. W. & Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv:1602.07360 (arXiv preprint) (2016).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In IEEE Conference on Computer Vision and Pattern Recognition 580–587 (2014).
Girshick, R. Fast R-CNN. In IEEE International Conference on Computer Vision (ICCV) 1440–1448 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2017).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask R-CNN. In IEEE International Conference on Computer Vision (ICCV) 2980–2988 (2017).
Minaee, S. et al. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 44(7), 3523–3542 (2022).
Zhao, Z. Q., Zheng, P., Xu, S. T. & Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 30(11), 3212–3232 (2019).
Vinod, G. & Padmapriya, G. An adaptable real-time object detection for traffic surveillance using R-CNN over CNN with improved accuracy. In International Conference on Business Analytics for Technology and Security (ICBATS) 1–4 (2022).
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. You only look once: Unified, real-time object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 779–788 (2016).
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S. Fu, Y. C. & Berg, A. C. Ssd: Single shot multibox detector. In European Conference on Computer Vision 21–37 (2016).
Lin, T. Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 318–327 (2020).
Ma, Y., Yang, J., Li, Z., & Ma, Z. YOLO-cigarette: An effective YOLO network for outdoor smoking real-time object detection. In International Conference on Advanced Cloud and Big Data (CBD) 121–126 (2022).
Redmon, J. & Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. In arXiv:1804.02767 (arXiv preprint) (2018).
Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. Yolov4: Optimal speed and accuracy of object detection. In arXiv:2004.10934 (arXiv preprint) (2020).
Zhu, X., Lyu, S., Wang, X. & Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) 2778–2788 (2021).
Wang, C. Y., Bochkovskiy, A. & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv:2207.02696 (arXiv preprint) (2022).
Qiu, M., Huang, L. & Tang, B. H. ASFF-YOLOv5: Multielement detection method for road traffic in UAV images based on multiscale feature fusion. Remote Sens. 14(14), 3498 (2022).
Sudars, K., Namatēvs, I., Judvaitis, J., Balašs, R., Ņikuļins, A., Peter, A., Strautiņa, S., Kaufmane, E. & Kalniņa, I. YOLOv5 deep neural network for quince and raspberry detection on RGB images. In Workshop on Microwave Theory and Techniques in Wireless Communications (MTTW) 19–22 (2022).
Liu, W., Quijano, K. & Crawford, M. M. YOLOv5-tassel: Detecting tassels in RGB UAV imagery with improved YOLOv5 based on transfer learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 15, 8085–8094 (2022).
Acknowledgements
This work was supported by QLUTGJHZ2018019.
Author information
Authors and Affiliations
Contributions
X.D.: (1) development or design of methodology; creation of models. (2) Verification, whether as a part of the activity or separate, of the overall replication/ reproducibility of results/experiments and other research outputs. (3) Programming; computer programming; computer code implementation and algorithm support; Testing of existing code components. (4) Analyze synthetic research data, and analyze and discuss the feasibility of experimental design. (5) The first draft of the paper was written. H.L.: (1) formulation or evolution of overarching research goals and aims. (2) Revision of the paper. (3) Acquisition of the financial support for the project leading to this paper. (4) Responsible for submission work. J.G.: (1) provide technical support during the experiment. (2) Conducting a research and investigation process. H.C.: (1) Revision of the paper during writing. (2) The production of comparative experiments. L.B.: experimental results of the production of pictures. H.L.: (1) revision of the paper during writing. (2) The production of comparative experiments. (3) Analyze and discuss the feasibility of experimental design.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, H., Duan, X., Lou, H. et al. Improved GBS-YOLOv5 algorithm based on YOLOv5 applied to UAV intelligent traffic. Sci Rep 13, 9577 (2023). https://doi.org/10.1038/s41598-023-36781-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-36781-2
This article is cited by
-
Automatic recognition of construction waste based on unmanned aerial vehicle images and deep learning
Journal of Material Cycles and Waste Management (2025)
-
An improved YOLOv11 algorithm for small object detection in UAV images
Signal, Image and Video Processing (2025)
-
Research on X-ray Image Fusion Algorithm for Food Foreign Object Detection
Journal of Nondestructive Evaluation (2025)
-
MPE-YOLO: enhanced small target detection in aerial imaging
Scientific Reports (2024)
-
Constrained trajectory optimization and force control for UAVs with universal jamming grippers
Scientific Reports (2024)
