
Abstract
Accurate forecasting and analysis of emerging pandemics play a crucial role in effective public health management and decision-making. Traditional approaches primarily rely on epidemiological data, overlooking other valuable sources of information that could act as sensors or indicators of pandemic patterns. In this paper, we propose a novel framework, MGLEP, that integrates temporal graph neural networks and multi-modal data for learning and forecasting. We incorporate big data sources, including social media content, by utilizing specific pre-trained language models and discovering the underlying graph structure among users. This integration provides rich indicators of pandemic dynamics through learning with temporal graph neural networks. Extensive experiments demonstrate the effectiveness of our framework in pandemic forecasting and analysis, outperforming baseline methods across different areas, pandemic situations, and prediction horizons. The fusion of temporal graph learning and multi-modal data enables a comprehensive understanding of the pandemic landscape with less time lag, cheap cost, and more potential information indicators.
Similar content being viewed by others

Introduction
Pandemics are global outbreaks of infectious diseases that affect many people across continents. The COVID-19 pandemic is one of the most significant pandemics of our time, impacting millions of individuals worldwide and causing lasting effects on our society. In order to combat pandemics, it is crucial to develop efficient solutions that facilitate the comprehension of their transmission and containment. This requires tracking and evaluating the evolution of pandemics through efficient monitoring and analysis of online resources that provide rich information, reflecting public knowledge and perceptions in a timely manner. For instance, the volumes of social media interests can serve as early indicators of COVID-19 waves1,2, and users’ content can unveil diverse perspectives on regulations, such as quarantine measures or vaccination strategies. Understanding these signals can help policymakers to combat pandemics by recognizing trends in their spread and impact on the population, as well as the efficacy of current countermeasures.
Traditional pandemic monitoring involves tracking hospital admissions, laboratory testing, and death rates, but can be expensive and lag in providing real-time disease spread updates. Compartmental models like SIR3 and statistical analyses such as ARIMA4 and Prophet5 use past data for predictions, are common approaches. However, these statistical models rely on assumptions and might lack data to precisely estimate factors like reproduction number in pandemic planning and forecasting.

Examples showing different stances on social media reacting to the pandemic and government regulations6.
Time-series forecasting with deep learning is one of the most effective methods for tracking pandemics’ evolution. Because of their data-driven learning process, deep learning-based methods are highly accurate in analyzing time-series data to identify patterns and trends that can help predict future outbreaks through historical statistics. By using deep learning algorithms, we can analyze large amounts of data quickly and accurately, making it easier to identify patterns and trends that might be missed by other methods. Recent works leveraged deep learning-based methods to learn statistics from earlier time stamps as prediction to forecast the COVID-19 pandemic incidence, achieving better performance comparing to traditional methods7.
One of the limitations of previous works in pandemic forecasting is that they frequently rely entirely on epidemiological data and ignore other information that might act as sensors or indicators of the pandemic’s patterns and evolution. Data from search engines, for example, can be used to monitor how individuals are looking for information about pandemics8,9. More crucially, social media data can be utilized to monitor how people are reacting to and feeling about a pandemic10,11. Although previous research has examined the connection between social media usage and pandemic trends12, there has been little use of deep learning techniques to predict and track the spread of the epidemic. We can gain a more complete view of how an epidemic is evolving and how effective various treatments might be by including external knowledge from social media into pandemic forecasting models. For instance, by monitoring social media data, we may pinpoint public health campaigns to regions where people are most worried about a pandemic. Figure 1 illustrates our motivated examples, which show different stances of social media users on the COVID-19 pandemic and on government regulations. As shown at the bottom of the figure, a person might be indifferent to the current pandemic situation but still have opinions on government policies, such as mandatory vaccinations. These different stances can lead to various future scenarios. For example, those who comply with government responses can help mitigate the spread of the disease, while those who do not may remain susceptible and potentially worsen the situation.
During pandemics, social media has emerged as a key source of information, offering real-time updates on the spread of diseases and people’s responses to them. Therefore, we investigate how pandemic tracking and analysis using deep learning algorithms can benefit from external knowledge from multi-modality, including social media and government regulations. More specifically, we construct graph-structured data from social media, treating each user as a node representing the current epidemic status. We dynamically capture interactions between users using temporal graph learning. Graph learning, particularly Graph Neural Networks (GNNs)13,14, is an important branch of machine learning that deals with learning from and representing a variety of real-world relational data, including citation networks, social networks, knowledge graphs, etc. Incorporating graph learning techniques and graph-structured representations offers a promising approach to overcome limitations of previous works in pandemic forecasting, where graphs can capture the structural and semantic information of the pandemic ___domain15,16,17.
In this work, we introduce MGLEP, a neural framework for forecasting and analyzing developing pandemics using big data sources and deep learning methods, including graph neural networks. We utilize the extremely recent COVID-19 pandemic and their effects on multiple areas as a case study. In order to trace and predict the evolution of the pandemic, we investigate the relationship between the pandemic risk factors and all other relevant data sources such as social media. Our framework will support many end users like politicians, policy makers, and general population for reference by providing complementary analysis and forecast information, leading to more effective crisis preventive and reaction times. Our contributions in this work are summarized as follows:
-
We propose a multi-modal neural framework named MGLEP for COVID-19 pandemic tracking and prediction,
-
We extract and combine data from multiple sources, including social signals and government stringency signals as additional indicators to monitor pandemic trends and predict future evolution,
-
We investigate the correlation and impacts of these multi-modal data on pandemic forecasting using deep learning and graph learning methods,
-
We conduct extensive experiments on multiple areas affected by the pandemics to show the usefulness and effectiveness of our proposed framework.
Source codes of our framework and reproducible baselines are made publicly available at https://github.com/DeepTensorAB/MGLEP for future research and benchmarking purposes.
Results
Baselines
We evaluate our proposed approach against several baselines that employ different techniques, including statistical, machine learning, and deep learning approaches. Results are shown in Tables 1 to 7. Bold indicates the best performance, while underline signifies the second best performance.
-
Numerical analysis: (i) AVG: average of the whole history are used to predict the future; (ii) AVG_WINDOW: average statistics of current prediction window are utilized to predict the future; and (iii) LAST DAY: the statistics of the current day are used as prediction.
-
Machine learning-based models: (i) LIN_REG: Ordinary least squares Linear Regression fits a line to training samples for predicting future cases; (ii) GP_REG: Gaussian Process Regressor is a non-parametric regression model utilizes Gaussian processes; (iii) RAND_FOREST and (iv) XGBOOST: tree-based models.
-
Statistical models: (i) ARIMA4, a simple autoregressive moving average model leverage the entire history sequence as input; and (ii) PROPHET5, similar to ARIMA but with strong seasonality characteristics.
-
Deep learning models without graph topology: (i) A straightforward LSTM model, uses the sequence of the most recent d days as its input, (ii) \(\text {SE}_{transformer}\) and (iii)\(\text {SRE}_{transformer}\), baseline models using the popular transformer architecture for learning on extracted text embeddings from social media data. Self-attention is calculated between tokens of different users (extracted using the same pre-trained language model as MGLEP models). Then, the final embeddings are fused with LSTM for processing the time-series and making the final predictions.
-
\(\text {MGLEP}_{SR}\), \(\text{MGLEP}_{SE}\), \(\text {MGLEP}_{SRE}\): our proposed models (i) \(\text {MGLEP}_{SR}\) are baseline LSTM with an additional input features of regulations (R) information, (ii) \(\text {MGLEP}_{SE}\) is the model with temporal graph learning on pre-processed social media data (E - entity) from 1500 users for the default setting, and (iii) \(\text {MGLEP}_{SRE}\) is our final model with input from three different modality, including statistics as in traditional model, and regulations and social media data.
Implementation details
The proposed framework was implemented in PyTorch18, and experiments were carried out on an NVIDIA 3090Ti GPU. We train the model for a maximum of 300 epochs with early stopping. All models are optimized with AdamW optimizer19, \(10^{-3}\) initial learning rate, a batch size of 16, and input sequence length of 7. These hyperparameters are set empirically through grid search. For instance, the learning rate is selected from a set of three values: \(10^{-2}\), \(10^{-3}\), and \(10^{-4}\), and the input sequence length is chosen from 1, 7, or 14 days prior. This ensures that both the proposed method and the baseline methods are evaluated under optimal conditions. All experiments are repeated 5 times with different seeds. The last 20% time steps of the dataset are used as hold-out test set. Details regarding the data collected and used are described in following sections. Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), and R squared (\(R^2\)) are metrics used to evaluate and compare between models.
where \(y_i\) and \({\hat{y}}_i\) denote the ith statistics from ground truth data and predicted values of the models, and n is the total number of samples in the test set. The MAE metric indicates the average variance between the predicted values and the ground truth in the dataset (lower is better).
The RMSE metric in Equation 2 is the standard deviation of the residuals (prediction error) (lower is better).
The MAPE given in Equation 3 tells us about the mean of the total percentage errors (lower is better).
Finally, the Coefficient of Determination (R-squared metric) provides an insight into the similarity between real and predicted data, where the closer to 1 the R squared value is, the better. Here, \(RSS=\sum _{i=1}^n(y_i-{\hat{y}}_i)^2\) and \(TSS=\sum _{i=1}^n(y_i-{\overline{y}})^2\) denote the Residual Sum of Squares and the Total Sum of Squares, respectively.
Results
The evaluation results for short-term predictions are presented in Table 1, where it can be observed that for horizon values of 1 or 3, our proposed approaches underperform the baseline LSTM neural network method, which is the closest competitor to our proposed models. However, the performance of our models significantly improve on the New York state dataset, as shown in Table 2. The reason for this improvement may lie in the fact that the \(R^2\) score, which is calculated on the predictions for each state, being close to perfection (0.9820 for the horizon of 1) on the California dataset, but the \(R^2\) score on New York dataset is significantly lower, indicating a higher level of difficulty for learning and prediction on the latter dataset. In general, the \(\text {MGLEP}_{SE}\) method achieves the most impressive results for short-term forecasting, followed by the \(\text {MGLEP}_{SRE}\) model. This can be explained as the time lag between government efforts and their impact on the real-world situation spans multiple weeks. Incorporating this information for short-term prediction may adversely affect the effectiveness of the model. For New York, with a prediction horizon of 7, we observed lower standard deviations compared to the LSTM baseline. Detailed results are as follows: \(\text {MGLEP}_{SRE}\): \(\text {std}_{MAE}=\pm\)94.21, \(\text {MGLEP}_{SE}\): \(\text {std}_{MAE}=\pm\)101.86, \(\text {MGLEP}_{SR}\): \(\text {std}_{MAE}=\pm\)116.92, and LSTM: \(\text {std}_{MAE}=\pm\)150.31. This trend is also observable in the California dataset (\(\text {MGLEP}_{SRE}\): \(\text {std}_{MAE}=\pm\)155.03; \(\text {MGLEP}_{SE}\): \(\text {std}_{MAE}=\pm\)131.28; \(\text {MGLEP}_{SR}\): \(\text {std}_{MAE}=\pm\)67.73; LSTM: \(\text {std}_{MAE}=\pm\)83.69) and other metrics (RMSE, MAPE, and \(\text {R}^2\)). This consistency across different variants of our proposed model, metrics, datasets, and scenarios indicates that our method has higher stability and is less prone to overfitting compared to other baselines. Furthermore, upon comparison with \(\text {SE}_{transformer}\) and \(\text {SRE}_{transformer}\), which utilize the transformer architecture without correlation matrices for processing social media data, we observe that our methodology incorporating graph neural networks featuring spatial-temporal characteristics distinctively surpass these approaches. This outcome highlights the efficacy and suitability of our novel proposed approaches, both in constructing input graph structures and in learning algorithms, for addressing these types of multi-modality domains.
With respect to long-term prediction, our models achieve the best results across all three horizons with significant gaps compared to all other methods, as illustrated in Table 3 and 4. Generally, the best performed approaches are \(\text {MGLEP}_{SRE}\) and \(\text {MGLEP}_{SE}\) models, achieving 42.47%, 34.21%, and 10.62% lower MAE with horizon equals 14, 21, 28 days ahead than the best basline methods for California dataset, and 11.94%, and 7.50% lower MAE for horizon 14 and 21, on New York dataset. Moreover, for long-term prediction, \(\text {MGLEP}_{SR}\) models are able to obtain better results than the simple baseline LSTM models, compared to the results and analysis on short-term predictions. The model’s capability on forecasting the long-term trajectory of the pandemic means that it can provide valuable information and insights for government and policy makers on planning ahead and making informed, timely response to the pandemic. We also analyze the robustness and stability of the models with respect to different random initialization and data shuffling. The results again highlight the consistency and generalization of our models across metrics, datasets and scenarios. For example, on New York, with a prediction horizon of 14 days, our models show lower standard deviations than the baseline LSTM. In details: \(\text {MGLEP}_{SRE}\): \(\text {std}_{MAE}=\pm\)55.66, \(\text {MGLEP}_{SE}\): \(\text {std}_{MAE}=\pm\)29.93, \(\text {MGLEP}_{SR}\): \(\text {std}_{MAE}=\pm\)55.23, and LSTM: \(\text {std}_{MAE}=\pm\)68.71.
We conduct comprehensive ablation studies to investigate the impact of the size of the input social media graph on our COVID-19 prediction model. In particular, we reduce the number of users selected for building the graph from the original 1,500 users to 1,000 and 500, respectively. Our hypothesis is that as we decrease the number of users, the amount of information provided by the social media data would be significantly reduced. The results in Table 5 for the California region confirm our hypothesis, showing a degradation in performance with a decrease in the number of nodes for both short-term and long-term forecasting. The findings have implications for future research in that it is critical to take the size of the input social media network into account when developing a model for predicting COVID-19 instances. The size of the social media graph directly influences the richness and diversity of the data captured, allowing the model to capture a more nuanced understanding of public sentiments, behaviors, and trends related to the pandemic.
Table 6 illustrates the ablation study on different number of nodes for the input social media graph of our COVID-19 prediction model for New York dataset. The results are consistent with experiment on California dataset, where a degradation in performance with a decrease in the number of nodes for both short-term and long-term forecasting can be seen.
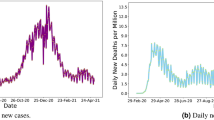
In order to assess the usefulness and effectiveness of our proposed methods in different stages of the pandemic, we perform an additional experiment by collecting data for another 150 days, thereby increasing the total amount of data collected. We then train and evaluate the same models and baselines on this new dataset, the results of which are presented in Table 7 and visualized in Figure 2. It is worth noting that this new test set for California state exhibits a higher variance compared to the previous forecasting range, where statistics gradually decrease with sharp changes. Nevertheless, our models outperform the baselines and achieve the best performance on both test sets. These results indicate the robustness and generalizability of our approaches in combating the COVID-19 pandemic in different stages of its evolution.
Discussion
Forecasting results. In the real world, COVID-19 is a complex pandemic, and many factors that cannot be seen by previous statistics can lead to different future scenarios. For example, if a government implements a strict lockdown, the number of new cases will likely decrease. However, if a government lifts all restrictions, the number of new cases will likely increase. This is why it is important to consider multiple information sources when forecasting the spread of COVID-19. Our proposed method, MGLEP and its variants incorporate multiple information sources effectively, leading to better performances, lower errors, and sustained accuracy, particularly in long-term predictions, compared to other popular forecasting models. MGLEP enjoys these benefits due to it being able to learn the dynamic relationships between various factors that affect the spread of COVID-19, such as official government policy, and social stances against the pandemic or situation. Moreover, our ablation results clearly demonstrate that the availability of more information significantly enhances the reliability of our forecasting models. Comparisons between our methods and baselines that do not utilize the graph structure of social media data also highlight the efficacy of our graph-structure generation process and temporal graph learning framework. The results not only underline the effectiveness in learning and extracting information of the models, but also emphasize on the usefulness of input multimodal data.
Additionally, our experiment results show that MGLEP is adaptable and robust to different situations and history. This means that it can be used to forecast the spread of COVID-19 in different countries and regions, even if the pandemic is evolving rapidly. The predictions made by MGLEP can be leverage by different beneficial group such as the authorities to develop appropriate strategies in order to deal with the spread of this pandemic. An example is that MGLEP can be used to forecast the impact of different government policies on the spread of the virus.
Our ablation study demonstrates that the default setting of using 1500 nodes to build the social media graph is sufficiently large to showcase the effectiveness of our model. Moreover, our framework is designed to be scalable, capable of handling graphs of various sizes. As the Twitter graph expands, the performance of MGLEP correspondingly improves. Therefore, we anticipate that MGLEP’s performance will further enhance with larger datasets.
Finally, it’s important to highlight the automated nature of the forecasting process with MGLEP. The entire process can be automated and seamlessly updated whenever new information becomes available. This automation is possible due to our framework’s reliance on openly accessible data from the Internet, which can be efficiently gathered through automated web crawling.

Forecasting results on test set for the newly collected period of California state dataset (a) Infectious cases. (b) Hospitalized cases.
Model limitations. Although some of the proposed models performed well according to certain metrics, we found several shortcomings in the models that we tested. One limitation is that MGLEP takes time to realize the trend depending on the dynamic at the considered area, as information from different sources, such as the effects of government policies takes time to be reflected in the data. For example, in the case of New York state, it takes effect immediately while in the case of California, it takes about 14 days. Additionally, the underlying factors that affect the infection of COVID-19 are diverse, and it can be difficult to capture all of them through the multiple data sources used by MGLEP. Another limitation of MGLEP is that similar to other deep learning methods, it is a black-box model. This means that we cannot easily understand how it makes its predictions, and can make it difficult to trust or explain the model’s predictions.
Future research directions. There are several ways in which MGLEP can be improved in the future. An interesting future research direction is to enrich our framework with more information regarding the pandemic situation, such as regional age population, mobility, or virus variants. Another direction can be interested in explainability methods, such as identifying important nodes or features through temporal graph learning, or understanding the most valuable factors that affect the forecasting results. This would make us more confident in the predictions of the model and would help us to better understand the dynamics of the pandemic.
Related Work
Pandemic forecasting
Traditional approaches leverage statistical models have been widely used to forecast COVID-19. These approaches involve analyzing past epidemic data using statistical and time-series methodologies to identify patterns and trends, which can then be used to forecast future outbreaks. Methods like autoregressive integrated moving average (ARIMA)4 and Prophet5 are effective at identifying trends in stationary time-series data and handling periodic patterns, respectively. One alternative to forecast pandemics, such as COVID-19 pandemic, is through the use of compartmental models20,21,22. These models divide a population into compartments, such as susceptible, exposed, and infected individuals (SIR model), and use mathematical equations to describe the dynamic and transitions between each group. However, it is important to acknowledge that leveraging statistical models for pandemic forecasting has its limitations, as they presumptively assume a linear relationship between past and future time-series. Such methods rely on certain assumptions and may lack the data necessary to accurately address all the relevant issues.
Deep learning have been applied to make predictions about the spread of COVID-19 pandemic and achieve high performances7,23. With the enormous dataset of records such as infected and hospitalized cases collected on a daily basis, deep learning is considered a suitable approach, as neural networks can learn and update from data effectively. Sequential models such as Recurrent Neural Network (RNN) and Long Short Term Memory (LSTM)24 have been applied and seen high performances for forecasting COVID-19 pandemic, both at world-wide or country level25,26, and more fine-grained levels including state and county levels27,28,29,30. Unlike conventional approaches, deep learning can incorporate external knowledge and adapt to changing circumstances, improving their predictive capabilities. These approaches, or fusion of multiple neural network models, can incorporate a wide range of data sources, including social media, to provide a more comprehensive view of the pandemic and its potential impacts.
To our best knowledge, previous research has only attempted to integrate basic indicators or indices, overlooking the dynamic, intricate information contained in user-generated content8,12,31. Incorporating these valuable signals into neural networks remains a challenge but has the potential to provide a more comprehensive view of the pandemic and its potential impacts1,9,32.
Leveraging external resources for time-series forecasting
Previous studies have explored the connection between social media interests and pandemic trends. In9, the authors highlight a strong correlation between peak of search volume on COVID-19 pandemic and the development of the pandemic, upto 20 days earlier than the issuance of official warnings. The authors of1 also discovered a close connection between the evolution of the COVID-19 crisis and social media user’s sentiments toward different phases of the pandemic. Another work33 makes use of the social impact of media coverage to support the compartment model for pandemic prediction. Post-processed indicators such as internal movement index and economic response have been incorporated as additional input features to sequence models for forecasting future statistics34,35. Differing from them, our method considers every aspect of user response through social media and government regulations against the pandemic. To achieve greater accuracy in pandemic forecasting, we analyze individual tweets and search for relevant social events.
There has been a significant amount of interest in effectively leveraging social media as an external knowledge source for more accurate pandemic forecasting. In31, the authors used tweet count (the amount of tweets related to COVID-19) per day as an additional input to an LSTM model and achieve better results than using statistics only. Taking a step further, in12, the collected tweets are then further extracted into two main features, representing user sentiment and topic of interest. These features are used as additional input features to an ARIMAX model, which is an extension of ARIMA. Furthermore, in36, important keywords are extracted and curated into a keyword cloud to present the most important information for each day and input to a MLP module for pandemic prediction. Perhaps the most relevant works to this paper are16,17 where the authors extract the most popular keywords per day and view them as a graph structure and employ graph algorithms to learn on those representations.
In this study, in contrast to prior works, we incorporate data from multiple different sources, with social media as an important knowledge source where we build graph structure with each user as node, or an indicator on the current status of the epidemic, and dynamically represent the interaction between them through temporal graph neural networks13,37,38. Our approach comprehensively considers various aspects of user responses on social media and government regulations pertaining to the pandemic.
Temporal graph neural networks forecasting models
Graph neural networks (GNNs) have gained significant attention in various learning tasks, such as image recognition39,40, estimating quantum chemical computation41,42,43, predicting protein interfaces44, etc. GNNs generalize the concept of convolution neural networks to non-Euclidean domains, allowing for local operations on the nodes and edges of a graph13,45. The most popular GNNs is Message Passing Neural Networks (MPNNs)42 in which the graph convolution is defined via the message passing scheme that propagates and then aggregates the vectorized information between each node and its local neighborhood.
To handle evolving features and connectivity over time, temporal graph neural networks have been introduced. Unlike static graphs, temporal graphs are usually represented by a sequence of node interactions over continuous time instead of an adjacency matrix. Temporal GNNs aim to capture both the temporal and structural information of the temporal graphs by introducing a node memory that represents the state of the node at a given time, acting as a compressed representation of the node’s past interactions. Temporal GNNs combine graph encoding techniques with time-series encoding architectures such as LSTM and Transformers, forming a powerful deep learning framework. They find applications in various domains, such as traffic prediction, where they outperform traditional methods by incorporating spatial relationships of road networks and temporal dynamics of traffic conditions46,47,48. In the analysis of brain networks, temporal GNNs utilize invasive techniques like electrocorticography (ECoG) to uncover temporal patterns and gain insights into brain network dynamics48.
In our apporach, by leveraging the temporal and structural aspects of graph representation in social media data, temporal GNNs enhance modeling capabilities for understanding evolving complex systems and forecasting pandemic statistics.
Preliminaries
Time-series forecasting
Originally proposed in24, Long short-term memory (LSTM) has been the dominant recurrent network architecture for learning from sequences of data. Unlike standard feedforward neural networks, LSTM can process and retain the temporal correlations between adjacent time steps, due to its feedback connections. For a historical time step t, the output \(y_t\) will not only depend on \(x_t\) but also from previous iterations through hidden state \(h_{t-1}\) and memory variable \(c_{t-1}\):
where \(\Gamma _u\) and \(\Gamma _f\) are “update gate” and “output gate”, calculated through a sigmoid (\(\sigma\)) activation function to determine the percentage of new memory \(\tilde{c}_t\) to keep and the percentage of old memory \(c_{t-1}\) to forget, respectively. The “output gate” \(\Gamma _o\) allows information to be revealed appropriately due to the sigmoid function then the weights are updated by the element-wise multiplication of \(\Gamma _o\) and memory cell \(c_t\) activated by the non-linear \(\tanh\) function.
A simpler, more intuitive version of LSTM called Gated-Recurrent Unit (GRU)49, combined the cell memory and the hidden state variable into \(h_t\) to transfer information. Therefore, a GRU only has two gates, a “reset gate” and an “update gate”.
Finally, the last hidden state variable \(h_t\) can be used to predict the corresponding output value \({\hat{y}}_t\) through a fully connected layer with softmax activation function:
Temporal graph learning algorithms
Graph neural networks (GNNs) are a class of neural networks that operate on graph-structured data. Graphs are a powerful method to represent many types of data, such as social networks, biological networks, and traffic flows. GNNs are capable of learning the relationships between nodes in a graph. They generalize the concept of convolutional neural networks to non-Euclidean domains by defining local operations on the nodes and edges of a graph. A typical GNN layer operate on input graph \({\mathcal {G}}=({\varvec{X}},{\varvec{E}},{\varvec{A}})\) can be formulate as in Equation 8.
where \({\varvec{X}} \in {\mathbb {R}}^{N\times D_X}\) represents node matrix, each of the N nodes has \(D_X\) features, and \({\varvec{A}} \in {\mathbb {R}}^{N\times N}\) is a weighted adjacency matrix encoding set of edges \({\varvec{E}}\). The graph convolution operator \(\star\) can be approximated by first-order Chebyshev polynomial expansian and generalized to high-dimensional45,50 with learnable parameter \({\varvec{W}} \in {\mathbb {R}}^{D_X \times D_Y}\).
Temporal Graph Neural Networks are an extension of GNNs that can handle temporal graphs, i.e., graphs that change over time. Unlike static graphs, temporal graphs are usually represented by a sequence of node interactions over continuous time instead of an adjacency matrix. Temporal GNNs aim to capture both the temporal and structural information of the temporal graphs by introducing a node memory that represents the state of the node at a given time, acting as a compressed representation of the node’s past interactions. In this work, we follow the framework of recent studies, including GCRN37, AGCRN47, and MPNN LSTM15, that utilize recurrent neural network on top of graph convolution operators. We leverage a simplified approach and use GRU as the recursive network architecture.
This framework allows MGLEP to learn the dynamic interactions between entities, act as nodes, or indicators to the current status of the pandemic and between different time stamps throughout the evolution of the pandemic.
Pre-trained Language models
Since we are dealing with free-text data to capture population’s reactions to the pandemic, more specifically, user-generated content sourced from social media, it is crucial to extract meaningful information before constructing the graph-structured representation of the data. In recent years, large pre-trained language models have revolutionized the field of natural language processing such as Bidirectional Encoder Representations from Transformers (BERT)51. These models have demonstrated exceptional capabilities in understanding and generating human language. BERT’s underlying architecture, based on Transformer52, employs self-attention mechanisms to capture dependencies between words or tokens in a sentence. This enables BERT to comprehend the contextual information of a word based on its surrounding words, leading to more accurate language understanding and representation. By pre-training BERT on massive amounts of textual data and a wide variety of tasks, such as masked language modeling and next sentence prediction, the model learns a rich language representation that can be fine-tuned for specific downstream tasks.
Building upon recent advancements in applying large pre-trained models to ___domain-specific data53,54, we leverage BertTweet55, a variant of BERT as our main feature extractor for text embeddings. The model has been trained on a large amount of Twitter data, especially including a sub-set of COVID-19 related data, and its effectiveness in capturing the nuanced meanings and signals conveyed in text data has been well-established. By leveraging BertTweet, we can obtain high-quality features that accurately represent the semantic content of social media posts surrounding the COVID-19 pandemic, and enables us to discover valuable patterns and trends that contribute to a comprehensive understanding of the social media landscape during the global health crisis.
Methodology
MGLEP

Overall architecture of MGLEP - a multi-modal framework for enhanced pandemic forecasting with external sources. MGLEP incorporates both pandemic related metrics and population’s reactions on social media into the forecasting to better capture the dynamic properties of emerging pandemics.

Comparison between amount of tweets posted and number of new COVID-19 cases per day. (a) In California state. (b) In New York state.
In this section, we present the multi-modality framework and techniques employed in our study to effectively extract and model multi-modal data for COVID-19 forecasting. Our approach aims to harness the power of social media data, specifically user-generated content, and government stringency index, to gain valuable insights to the evolution of the pandemic. We describe the key components of our framework, including data pre-processing, feature extraction, graph-based representation with temporal graph learning, and multi-modal learning. The main components of our proposed framework are depicted in Figure 3.
One goal of our multi-modality framework is to effectively incorporate signals from human-generated text data through social media platform, offering valuable reflections of the population’s response to the pandemic, as exampled in Figure 1, that can be signals for future status of the pandemic. This importance can also be underscored by the sheer amount of Covid-19 discussion over time, strongly correlating with pandemic statistics, as shown in Figure 4, showcasing the potential valuable information from the social media source. Details about our social media data collection process is provided in the next Section. In general, we crawled over 74 million tweets using the Twitter API and tweet IDs related to COVID-19 provided in56. For our study, we filtered tweets base on their geo-___location tags and only included English tweets. For each area of interested, we randomly selected tweets from 1,500 different users. Extracting meaningful features from text data is crucial for constructing a comprehensive understanding of the information shared on social media platforms. While other works proposed another direction of extracting indices like sentiment, this might discard necessary information, such as sentiment about COVID-19, but not about current government response to the pandemic. These nuanced details about responses to government policies or specific events related to the pandemic are essential for an in-depth understanding of public perception and behavior, which can significantly impact pandemic forecasting and response strategies. As discussed in previous sections, by employing pre-trained language model, specifically BertTweet, as text feature extractor, we ensure to capture rich insights contained within user-generated content, especially in relation to COVID-19 pandemic. Our framework enables integrating various modalities to capture the complex and temporal dynamics of emerging pandemics. We obtain temporal embedding for each user by utilizing BertTweet on their text data as follows:
where t denotes the timestamp, \(user_i\) denotes the i-th user in our social media data, and \(post_j\), \(j \in (t, user_i)\) denotes the text obtained from the tweets of the i-th user at time t. The inclusion of user interactions and shared information across users is crucial for further analysis. In order to capture the correlations and dependencies between users, it is imperative to construct a graph-structured representation of the pre-processed data. In contrast to existing works that leverage interactions such as following or retweet57, aiming more at analyzing the evolution of users or relationships which may not suitable for the current task, our approach employs a temporal graph based on embedding similarity between user content and sentiment. This proposed graph-based approach allows us to model the interactions and information flow through graph neural networks, capturing the dynamics and valuable insights related to the ongoing pandemic from social media signals. It is an end-to-end learning algorithm to discover the underlying graph structure, capturing the correlation among time-series data in a data-driven manner. More specifically, define node embeddings extracted from pre-trained language model as \({\varvec{X}}^{{\mathcal {G}}}_t := [x_{t, user_1}, x_{t, user_2}, \ldots , x_{t, user_N}]^T \in {\mathbb {R}}^{N\times D_X},\) and the continuous adjacency matrix can be calculated as the dot-product similarity matrix of the node embeddings: \({\varvec{A}}^{\mathcal {G}}_t = {\varvec{X}}^{{\mathcal {G}}}_t \cdot {{\varvec{X}}^{{\mathcal {G}}}_t}^T \in {\mathbb {R}}^{N \times N}\). This graph-based representation captures the temporal and structural information of user interactions, enabling our model to learn and predict the evolution of the pandemic adaptively. However, to enable effective learning with temporal graph learning algorithms, there are two downsides with this approach: first, large embedding dimension lead to incorrect adjacency matrix calculation. Second, may include information not directly related to our downstream task, and take up resources in training and evaluating. Inspired from AGCRN47, we employed a node-specific learnable embeddings that allows us to map input dimension to a lower intermediate embedding dimension:
where g denotes the filter parameterized by W and E, while \(\star\) denotes the graph convolution operator. \({\varvec{E}}\) is a learnable intermediate node embedding matrix, \({\varvec{E}} \in {\mathbb {R}}^{N \times D_{emb}}\). The input node matrix is multiplied with the node embedding \({\varvec{E}}\), resulting in an updated representation, where \({\varvec{E}}\) is learnable, meanings that the representation is specific for each node and its pattern. Then, the integrated node embeddings are further multiplied by the weight matrix \({\varvec{W}}\) to incorporate the influence of the node-specific features. Moreover, we replace the normalized graph Laplician matrix50 by computing the inner product of the intermediate node embedding matrix \({\varvec{E}}\) with its transpose \({\varvec{E}}^T\). This operation captures the pairwise relationships between node embeddings and produces a matrix of shape \(N \times N\). We apply the rectified linear unit (ReLU) activation function to introduce non-linearity and ensure positive values in the resulting matrix. The \(\text {softmax}\) function is then applied to normalize the values across matrix row, ensuring that the row sums to 1. This step allows us to obtain a valid probability distribution representing the importance or relevance of each node, or each user, with respect to others.
This graph convolution operation is plugged into the framework in Equation 9, and the final temporal graph learning algorithm is shown in Equation 12:
where g denotes learnable weights with respect to different embeddings. To complement the multi-modal nature of our framework, we incorporate government stringency features that provide valuable insights into the pandemic response at a regional level. Government stringency features capture the level of restrictions, policies, and interventions implemented by authorities to mitigate the spread of COVID-19. These features serve as an important contextual signal to enhance the understanding of the evolving dynamics in our model.
Specifically, we utilize the raw data and formula proposed in58 to compute an indicator on the level of government stringency. However, recognizing the complexity of this ___domain, we compare and analyze each individual indicator, as well as the averaged general stringency index, to identify the most suitable indicator for the current pandemic situation. In Figure 5, we present the correlation levels between index and the number of new COVID cases for two indicators, with different time lags. The results suggest a strong relationship between the restriction on internal movement to the status of the pandemic. Hence, in the refined version of our framework, we leverage this specific indicator as a measure of government stringency.
Since this indicator can be represented as a vector for each day, similar to the statistical metrics of the pandemic, we can employ a sophisticated recurrent neural network (i.e., Equation 5 and Equation 6) to learn solely on this feature. Alternatively, we have the option to combine, or concatenate it with the pandemic statistics and learn through a unified recurrent network. Through extensive experimentation, we have found that the latter approach yields superior performance, and thus, it is our final choice for incorporating the government stringency indicator into our framework.
Finally, in order make accurate predictions, it is crucial to integrate the information from multiple modalities in our framework. We achieve this by fusing the embeddings obtained from different modalities, namely statistical features, government stringency features, and social-media graph-based features. The fusion process is performed using the equation:
where \({\varvec{H}}_{t+T}^{\{stat, reg\}}\) is the learned embeddings of recurrent neural network for statistical metrics, \({\hat{y}}_{t+T}\) represents the predicted value for the time step \(t+T\), where T is the forecasting horizon. Embeddings from various ___domain, capturing the relevant information for each modality, are fused using the concatenation operator \(\oplus\) to create a unified feature representation.
Using the aforementioned equation to integrate the embeddings from multi-modality, our system successfully combines a variety of information sources while utilizing the complementary nature of different modalities for enhanced forecasting performance. This comprehensive approach enables us to capture the intricate dynamics and interdependencies within the data, leading to more accurate and reliable forecasts for the future evolution of the pandemic.
Multimodal data collection process
In this study, as shown in Table 8, we utilized three different types of data sources to gain insights into the COVID-19 pandemic and its development.
-
COVID-19 Statistic Data. We leverage the statistic dataset from Johns Hopkins University59 with 450 data points from August 1, 2020, to November 30, 2021. Each data point is represented as the number of confirmed COVID-19 infections or serious, hospitalized cases in a given area per day. Our final task is time-series forecasting on this multi-variate statistics with different horizons to predict the trajectory of the pandemic. Then, trained models can be a valuable tool in responding to the pandemic, as it can support policymakers give better decisions about how to allocate resources, implement public health measures, and prepare for the future.
-
COVID-19 Government Responses and Regulations Data. The stringency index data58 is a valuable resource in understanding the level of government response to the COVID-19 pandemic. The index is represented as a numeric value between 0 to 100 and includes nine different indicators, such as the closure of schools and workplaces, cancellation of public events, restrictions on gatherings, and orders to shelter in place. Figure 5 displays the correlation values between the stringency index and record restrictions on internal movement between regions and the daily statistics of new infected cases. Interestingly, both time-lag horizons exhibit a clear trend of correlation values peaking at around 30 days. Moreover, the correlation of record restrictions on internal movement with new infected cases is consistently higher than that of the stringency index. This is also observed when considering new hospitalized cases. The found correlation trends imply that the current government response can act as a valuable indication to forecast how the epidemic will develop in the future.
-
Social Media Data. We crawl a total amount of more than 74 million tweets using Twitter API and tweets ids of all tweets related to COVID-19 released by Banda et al.56. The original authors leveraged Twitter Stream for collecting all tweets in the category of COVID-19 chatter, with over 4 million tweets a day. We filtered out tweets with geo-___location tags in either California state or New York state in this exploratory study. Moreover, we filtered out all tweets that are not in English. We randomly keep all tweets from 1,500 different users for each ___location. The distributions of tweets over time with respect to statistics of newly confirmed cases are illustrated in Figure 4. A strong correlation between the two time-series can be recognized, although there is a noisy period at the start. This is likely due to the initial confusion and fear surrounding the appearance of COVID-19, which led to a high volume of discussions about the virus worldwide. As the situation became more stable and people gained a better understanding of the pandemic affection on their own regions, the amount of tweets posted became more relevant and had a higher correlation with users’ areas of residence. To account for this, we excluded data from the initial few months of the pandemic and only collected data starting from August 1, 2020.

Correlations between Stringency Index or Restrictions on internal movement to daily infected cases of COVID-19 across different time-lags.
Conclusion
In this work, we present a novel framework named MGLEP that combines temporal graph neural networks and multi-modal data for accurate pandemic forecasting. By integrating various big data sources, including social media content, we effectively capture the complex dynamics of emerging pandemics. Our framework outperforms traditional approaches by leveraging the potential of pre-trained language models and generating graph-structured data. Extensive experiments conducted with multiple variants of our proposed method demonstrate the effectiveness of our framework in providing timely and comprehensive insights into the pandemic landscape. The fusion of temporal graph learning and multi-modal data enables a deeper understanding of the evolving patterns and indicators, leading to more informed public health management and decision-making. Our approach offers a promising direction for leveraging big data in pandemic research and provides a foundation for future advancements in the field.
Data Availibility
The COVID-19 statistics leveraged in this study are available from Johns Hopkins University Center for Systems Science and Engineering in the COVID-19 repository, https://github.com/CSSEGISandData/COVID-19. The COVID-19 Government Responses and Regulations Data is sourced from The Oxford Covid-19 Government Response Tracker (OxCGRT), https://github.com/OxCGRT/covid-policy-dataset. The social media data are crawled from Twitter social media platform by tweets related to COVID-19 released by Covid-19 Twitter chatter dataset for scientific use, https://github.com/thepanacealab/COVID19_twitter.
References
Quach, H.-L. et al. Using ‘infodemics’ to understand public awareness and perception of sars-cov-2: A longitudinal analysis of online information about covid-19 incidence and mortality during a major outbreak in vietnam, july-september 2020. PLoS ONE 17, e0266299 (2022).
Comito, C. How covid-19 information spread in U.S.? The role of twitter as early indicator of epidemics. IEEE Trans. Serv. Comput. 15, 1193–1205 (2022).
Kermack, W. O. & Mckendrick, À. G. A contribution to the mathematical theory of epidemics. Proceedings of The Royal Society A: Mathematical, Physical and Engineering Sciences 115, 700–721 (1927).
Chatfield, C. Time-series forecasting (Chapman and Hall/CR, 2000).
Taylor, S. J. & Letham, B. Forecasting at scale. Am. Stat. 72, 37–45 (2018).
Tran, T. K., Vu, X.-S. & Jiang, L. Sobigdemicsys: A social media based monitoring system for emerging pandemics with big data. In 2022 IEEE Eighth International Conference on Big Data Computing Service and Applications (BigDataService), 103–107 (2022).
Kırbaş, İ, Sözen, A., Tuncer, A. D. & Kazancıoğlu, F. Ş. Comparative analysis and forecasting of COVID-19 cases in various european countries with ARIMA, NARNN and LSTM approaches. Chaos, Solitons & Fractals 138, 110015 (2020).
Dai Y, W. J. Identifying the outbreak signal of covid-19 before the response of the traditional disease monitoring system. I PLoS Negl Trop Dis.14 (2020).
Higgins, T. S. et al. Correlations of online search engine trends with coronavirus disease (COVID-19) incidence: Infodemiology study. JMIR Public Health Surveill. 6, e19702 (2020).
Tsao, S.-F. et al. What social media told us in the time of COVID-19: A scoping review. The Lancet Digital Health 3, e175–e194 (2021).
Li, L., Ma, Z., Lee, H. & Lee, S. Can social media data be used to evaluate the risk of human interactions during the COVID-19 pandemic?. International Journal of Disaster Risk Reduction 56, 102142 (2021).
Lamsal, R., Harwood, A. & Read, M. R. Twitter conversations predict the daily confirmed Covid-19 cases. Appl. Soft Comput. 129, 109603 (2022).
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M. & Monfardini, G. The graph neural network model. IEEE Trans. Neural Networks 20, 61–80 (2009).
Zhou, J. et al. Graph neural networks: A review of methods and applications. AI Open 1, 57–81 (2020).
Panagopoulos, G., Nikolentzos, G. & Vazirgiannis, M. Transfer Graph Neural Networks for Pandemic Forecasting. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (2021).
Zhou, Y., Jiang, J.-Y., Chen, X. & Wang, W. #stayhome or #marathon? social media enhanced pandemic surveillance on spatial-temporal dynamic graphs. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, CIKM ’21, 2738-2748 (Association for Computing Machinery, New York, NY, USA, 2021).
Jiang, J.-Y. et al. COVID-19 surveiller: toward a robust and effective pandemic surveillance system based on social media mining. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences380 (2021).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems (eds Wallach, H. et al.) (Curran Associates Inc., 2019).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations (2019).
Postnikov, E. B. Estimation of COVID-19 dynamics “on a back-of-envelope’’: Does the simplest SIR model provide quantitative parameters and predictions?. Chaos, Solitons & Fractals 135, 109841 (2020).
Fernández-Villaverde, J. & Jones, C. I. Estimating and simulating a SIRD model of COVID-19 for many countries, states, and cities. J. Econ. Dyn. Control 140, 104318 (2022).
Tang, B. et al. Estimation of the transmission risk of the 2019-nCoV and its implication for public health interventions. J. Clin. Med. 9, 462 (2020).
Liu, F. et al. Predicting and analyzing the COVID-19 epidemic in china: Based on SEIRD. LSTM and GWR models. PLoS ONE 15, e0238280 (2020).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Masum, M., Shahriar, H., Haddad, H. M. & Alam, M. S. r-lstm: Time series forecasting for covid-19 confirmed cases with lstmbased framework. In 2020 IEEE International Conference on Big Data (Big Data), 1374–1379 (2020).
Chandra, R., Jain, A. & Chauhan, D. S. Deep learning via LSTM models for COVID-19 infection forecasting in India. PLoS ONE 17, e0262708 (2022).
Nikparvar, B., Rahman, M. M., Hatami, F. & Thill, J.-C. Spatio-temporal prediction of the COVID-19 pandemic in US counties: modeling with a deep LSTM neural network. Sci. Rep. 11, 21715 (2021).
Lucas, B., Vahedi, B. & Karimzadeh, M. A spatiotemporal machine learning approach to forecasting COVID-19 incidence at the county level in the USA. International Journal of Data Science and Analytics 15, 247–266 (2022).
Hy, T. S., Nguyen, V. B., Tran-Thanh, L. & Kondor, R. Temporal multiresolution graph neural networks for epidemic prediction. In Xu, P. et al. (eds.) Proceedings of the 1st Workshop on Healthcare AI and COVID-19, ICML 2022, vol. 184 of Proceedings of Machine Learning Research, 21–32 (PMLR, 2022).
Panagopoulos, G., Nikolentzos, G. & Vazirgiannis, M. Transfer graph neural networks for pandemic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence35, 4838–4845 (2021).
Tran, V. & Matsui, T. Tweet analysis for enhancement of Covid-19 epidemic simulation: A case study in Japan. Front. Public Health 10, 806813 (2022).
Ibrahim, M. R. et al. Variational-LSTM autoencoder to forecast the spread of coronavirus across the globe. PLoS ONE 16, e0246120 (2021).
Bae, S., Sung, E. C. & Kwon, O. Accounting for social media effects to improve the accuracy of infection models: Combatting the COVID-19 pandemic and infodemic. Eur. J. Inf. Syst. 30, 342–355 (2021).
Khan, F. M., Kumar, A., Puppala, H., Kumar, G. & Gupta, R. Projecting the criticality of COVID-19 transmission in India using GIS and machine learning methods. Journal of Safety Science and Resilience 2, 50–62 (2021).
Xu, L., Magar, R. & Farimani, A. B. Forecasting COVID-19 new cases using deep learning methods. Comput. Biol. Med. 144, 105342 (2022).
Chew, A. W. Z., Pan, Y., Wang, Y. & Zhang, L. Hybrid deep learning of social media big data for predicting the evolution of covid-19 transmission. Knowl.-Based Syst. 233, 107417 (2021).
Seo, Y., Defferrard, M., Vandergheynst, P. & Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Neural Information Processing (eds Cheng, L. et al.) 362–373 (Springer, 2018).
Wu, Z., Pan, S., Long, G., Jiang, J. & Zhang, C. Graph WaveNet for deep spatial-temporal graph modeling. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (International Joint Conferences on Artificial Intelligence Organization, 2019).
Chen, Z.-M., Wei, X.-S., Wang, P. & Guo, Y. Multi-label image recognition with graph convolutional networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5177–5186 (2019).
Nguyen, H. D., Vu, X.-S. & Le, D.-T. Modular graph transformer networks for multi-label image classification. In Proceedings of the AAAI Conference on Artificial Intelligence35, 9092–9100 (2021).
Duvenaud, D. K. et al. Convolutional networks on graphs for learning molecular fingerprints. Advances in neural information processing systems28 (2015).
Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O. & Dahl, G. E. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, 1263-1272 (JMLR.org, 2017).
Hy, T. S., Trivedi, S., Pan, H., Anderson, B. M. & Kondor, R. Predicting molecular properties with covariant compositional networks. J. Chem. Phys. 148, 241745 (2018).
Fout, A., Byrd, J., Shariat, B. & Ben-Hur, A. Protein interface prediction using graph convolutional networks. In Advances in Neural Information Processing Systems (eds Guyon, I. et al.) (Curran Associates Inc., 2017).
Defferrard, M., Bresson, X. & Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Advances in neural information processing systems29 (2016).
Li, Y., Yu, R., Shahabi, C. & Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. In International Conference on Learning Representations (2018).
Bai, L., Yao, L., Li, C., Wang, X. & Wang, C. Adaptive graph convolutional recurrent network for traffic forecasting. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20 (Curran Associates Inc., Red Hook, NY, USA, 2020).
Nguyen, D. T., Nguyen, M. D. T., Hy, T. S. & Kondor, R. Fast temporal wavelet graph neural networks. arXiv preprint arXiv:2302.08643 (2023).
Cho, K. et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–1734 (Association for Computational Linguistics, Doha, Qatar, 2014).
Kipf, T. N. & Welling, M. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (2017).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North (Association for Computational Linguistics, 2019).
Vaswani, A. et al. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, 6000-6010 (Curran Associates Inc., Red Hook, NY, USA, 2017).
Lee, J. et al. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2019).
Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthcare3 (2021).
Nguyen, D. Q., Vu, T. & Nguyen, A. T. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 9–14 (2020).
Banda, J. M. et al. A large-scale covid-19 twitter chatter dataset for open scientific research-an international collaboration. Epidemiologia 2, 315–324 (2021).
Rossi, E. et al. Temporal graph networks for deep learning on dynamic graphs. In ICML 2020 Workshop on Graph Representation Learning (2020).
Hale, T. et al. A global panel database of pandemic policies (oxford COVID-19 government response tracker). Nat. Hum. Behav. 5, 529–538 (2021).
Dong, E., Du, H. & Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet. Infect. Dis 20, 533–534 (2020).
Acknowledgements
The project is partially funded by the STINT Mobility Grants for Internationalisation in Sweden (no: MG2020-8848). The computations was enabled by the supercomputing resource Berzelius provided by National Supercomputer Centre at Linköping University and the Knut and Alice Wallenberg foundation. The authors would like to express their gratitude to Dr. Thanh Vu, Dr. Thanh-Son Nguyen, Dr. Khuong Nguyen, and respected reviewers for their suggestions and comments provided throughout the project.
Funding
Open access funding provided by Umea University.
Author information
Authors and Affiliations
Contributions
Conceptualization: T.S.H., L.J., and X.S.V. Methodology: K.T.T., L.J., and X.S.V. Software: K.T.T. Analysis: K.T.T., T.S.H. Validation: L.J., and X.S.V. Paper preparation: K.T.T., T.S.H., L.J., and X.S.V. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tran, KT., Hy, T.S., Jiang, L. et al. MGLEP: Multimodal Graph Learning for Modeling Emerging Pandemics with Big Data. Sci Rep 14, 16377 (2024). https://doi.org/10.1038/s41598-024-67146-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-67146-y
