
Abstract
When applying deep learning and image processing techniques for bridge crack detection, the obtained images in real-world scenarios have severe image degradation problem. This study focuses on restoring low-illumination bridge crack images corrupted by noise to improve the accuracy of subsequent crack detection and semantic segmentation. The proposed algorithm consists of a deep CNN denoiser and a normalized flow-based brightness enhancement module. By taking the noise spectrum as an input, the deep CNN denoiser restores image at a broad range of noise levels. The normalized flow module, employs a conditional encoder and a reversible network to map the distribution of normally exposed images to a Gaussian distribution, effectively improving the image brightness. Extensive experiments have demonstrated the approach can usefully recover low-illumination images corrupted by noise compared to the state-of-the-art methods. Furthermore, the algorithm presented in this study can also be applied to other image quality restoration with high generalization and robust abilities. And the semantic segmentation accuracy of the restored image is significantly improved.
Similar content being viewed by others
Introduction
China has placed significant emphasis on the maintenance and management of bridges, driven by the extensive development of transportation infrastructure. This focus is a result of the country’s substantial investment in improving bridge quality and functionality. Currently, the detection of bridge cracks primarily relies on manual inspection, which is supplemented by semi-automated detection using bridge inspection vehicles, as well as fully automated non-destructive testing methods. However, manual inspection of bridges has drawbacks, including being time-consuming, expensive, and having a low safety margin. While bridge inspection vehicles have somewhat improved the situation, many issues remain unresolved. The use of fully automated non-destructive testing methods is limited on a national scale due to their costly equipment and complex configuration.
In the field of bridge maintenance, deep learning and image processing techniques have revolutionized the detection of cracks, offering unprecedented insights. Processing bridge crack images yields crucial parameters such as crack length, width, and type. However, real-world images are far from ideal, plagued by complex backgrounds, noise, obstructions like rough surfaces, stains, fallen leaves, inadequate lighting, and shadows. This complexity undermines the accuracy of subsequent crack semantic segmentation, underscoring the pivotal role of developing robust bridge crack image restoration algorithms1,2.
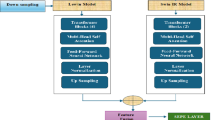
Existing algorithms excel in restoring either low-light or noisy images, yet they falter when faced with the dual challenge of low-light and noise-a scenario commonly encountered in bridge inspection imagery. To address this gap, our paper introduces a novel algorithm adept at restoring low-light bridge crack images under noisy conditions. This innovation is graphically illustrated in Fig. 1.

The method flowchart.
Our key contributions are three fold, which collectively position our algorithm as a groundbreaking advancement in the field of bridge crack detection and image restoration, poised to elevate the standard of bridge maintenance practices.
-
(1)
We present an integrated solution comprising a deep CNN denoiser and a normalization flow module, specifically engineered for image denoising and low-light image enhancement. This modular design is versatile, facilitating plug-and-play image restoration capabilities.
-
(2)
Our method outshines conventional approaches by markedly enhancing image brightness and eliminating noise, maintaining efficacy across a spectrum of noise intensities and low-light scenarios. This resilience empowers our algorithm to deliver superior outcomes in challenging imaging environments.
-
(3)
Beyond its specialized application, our algorithm showcases commendable generalization capabilities, extending its benefits to a broader array of image restoration tasks. Notably, images processed through our algorithm witness a substantial uplift in the precision of crack semantic segmentation, reinforcing its utility in advancing structural health monitoring and maintenance strategies.
The organization of this paper is arranged as follows. In the first section, we provide an overview of the current research on denoising and brightness enhancement. The second section presents the algorithm framework and provides details on the relevant model architecture. The third section encompasses the experimental setup, results, and discussions. Additionally, the limitations of our algorithm are also explored. The fourth section concludes the paper.
Related work
Low illumination image enhancement
Histogram equalization based method
The histogram equalization method was primarily based on different priors and constraints to enhance images under low-light conditions. Abdullah-Al-Wadud et al.3 utilized dynamic histogram strategies for image enhancement. Ibrahim4 and Lee5 respectively preserved image brightness by generating an output image with the same average intensity as the input image, while enhancing image contrast by amplifying the grayscale differences between adjacent pixels. Despite their ability to restore some image brightness, these methods still suffer from issues like excessive saturation, color distortion, and residual noise.
Retinex based method
Retinex enhanced low-light images by estimating their natural brightness. Ren6 effectively addressed the issue of non-uniform brightness in low-light image enhancement. Fu et al.7 incorporated prior information and used a linear ___domain model to compute the reflection and brightness components. Additionally, a fusion strategy was employed for enhancing low-illumination images8. Park et al.9 utilized a variational optimization-based Retinex approach. Li et al.10 enhanced image brightness by incorporating a noise map based on the Retinex model. Yu et al.11 dynamically adjusted low-light images through model parameter optimization.
Data-driven based method
Deep learning-based approaches for enhancing low-light images can be categorized into two main kinds: Retinex-based methods and end-to-end methods. Shen et al.12 applied a convolutional neural network to process the low contrast image problem. Wei et al.13 created a dataset consisting of low light and regular images and proposed an effective low light restoration algorithm based on the decomposition and brightness rectifying network. Yang et al.14 used the self-supervised learning strategy and only using low illumination image could finish the training. Zhang et al.15 dealt with three difficulties in low-light enhancement tasks that containing composition of the light map from a single image, removing degradation and training a good model with limited samples. Singh et al.16 could obtain the light normal image by estimating low light value of the input image. Zhao et al.17 introduced the network trained using the DIP method. However, despite the advancements made by these methods based on the Retinex theory, they still face challenges associated with the ideal assumptions underlying the Retinex methods.
End-to-end methods directly generate enhanced images from low-light images using convolutional layers. These methods do not rely on the Retinex theory and consider the imaging mechanisms of low-light images to effectively handle complex scenes. Wang et al.18 introduced intermediate illuminations in their network to establish a relationship between the input and desired enhanced results. This allowed the network to learn complex photographic adjustments from expert-repaired input/output image pairs. Ren et al.19 utilized a spatially variant recurrent neural network to enhance image structure and details. The network proposed by Hai et al.20 consisted of three sub-networks: Decom-Net, Adenoise-Net, and Relight-Net, which was respectively used for decomposition, denoising, contrast enhancement, and detail preservation. Guo et al.21 attempted to design a class of curves that could automatically map low-light images to enhanced images. The curve parameters were self-adaptive and depended only on the input images. Xu et al.22 extracted hierarchical features in images by exploring the mutual relationship. Wang et al.23 incorporated global brightness estimation and detail recovery for satisfactory results. The method proposed by Parihar et al.24 could solve the ill-posed problem of reflectance and illumination estimation. Lime25 utilized a luminance spectrum for recovering low-light images. Li et al.26 adopted a multi-step image enhancement strategy to finish the low light image restoration work. However, it should be noted that above mentioned methods do not explicitly consider the imaging mechanisms of low quality images, which limits their ability to effectively handle complex scenes.
Noise removing studies
The process of restoring a noisy image \(m\) is the solution itself \(q\), which can be obtained by addressing the problem of maximum a posteriori (MAP) estimation.
where \(\log j\left( {m\left| q \right.} \right)\) represented logarithm operation, \(m\) is the input image.
Equation (1) is reformulated:
The first data term, guarantees that the solution method. On the other hand, the second term, mitigates the ill-posed nature of the inverse problem in image restoration.
To separate the data term and the prior term in the equation, the half-quadratic splitting technique introduces an auxiliary variable \(u\), leading to a constrained optimization problem. The equation is resolved,
The parameter \(\mu\) is a regularization parameter, and this problem can be solved through iterative updates and solving sub-problems of \(q\) and \(d\).
Many researches have studied the image denoising task27,28,29,30,31,32,33,34,35,36,37,38. The key idea of the method proposed by Li et al.28 was to use neural autoencoders to define the priors of natural images. The above methods was plug-and-play, which was adaptive to address various image restoration problems. Lian et al.29 transformed existing denoisers into explicitly regularized terms that are relevant to denoising methods, enabling iterative optimization of image restoration problems. The researchers aimed to enhance the Deep Image Prior (DIP)31 by adding an explicit prior, which enriched the overall regularization effect so that images could be better recovered. More specifically, the researchers proposed to introduce the concept of denoising regularization (RED), which utilized existing noise cancelers to regularize the inverse problem. The Strengthen-Operate-Subtract (SOS) strategy and convolutional neural networks have been combined for both image denoising and real-world image denoising32, effectively improving the performance of denoising algorithms. Asem et al.33 proposed a method for image denoising based on dictionary learning algorithms in the wavelet ___domain, employing clustering coefficients derived from the second-generation wavelet at various decomposition levels. Xu et al.34 proposed the Externally Patch Prior-Guided Internal Clustering (EPPGIC) method, which employs a dictionary based on a Gaussian mixture model for internal denoising of similar patches guided by external patch priors. Choi et al.35 introduced the Consistent Neural Network, a deep neural network design that sought the optimal combination of image denoisers to enhance denoising performance. In this integrated strategy, the Integrated Residual Convolutional Neural Network (IRCNN)36 was employed. The Denoising Convolutional Neural Network (DnCNN)37 was primarily developed to exploit the underlying image structure. By taking an adjustable noise level plot as input in38, a single FFDNet was able to handle different levels of noise, as well as spatially varying noise.
The proposed method
The algorithm module in this paper consists of two parts. The first part is the denoising module, which is based on the deep CNN module. The second part is the brightness enhancement module, which is based on a normalized flow-based restoration strategy.
Image denoising
The denoising CNN network module used in this paper combines the U-Net architecture with residual blocks, enabling effective noise removal. This module comprises four scales, and each scale has an identity skip connection between the down-sampling (stride convolution) and upsampling (transposed convolution) operations. The channel numbers for each scale are 64, 128, 256, and 512, respectively, from the first to the fourth scale. Each scale incorporates four consecutive residual blocks for both down-sampling and upsampling. Notably, the first and last convolution layers, as well as the stride convolution and transposed convolution layers, do not employ activation functions. Additionally, each residual block incorporates merely a single ReLU activation function. This design contributes to enhancing the network’s robustness against noise and overall model performance. Moreover, the denoising module in this paper is bias-free, meaning no bias terms are utilized in all convolutional, strided convolutional, and transposed convolutional layers. The absence of bias facilitates the preservation of scale invariance crucial for image denoising tasks, averting potential degradation of generalization capabilities due to excessively large bias values.
Light enhancement
Low-light image enhancement aims to restore well-exposed images \(p_{h}\) when the input is low-light images \(p_{l}\). Pairs of images \(\left( {p_{l} ,p_{ref} } \right)\) are collected for training the model \(\Psi\), and the enhancement is achieved by computing the reconstruction loss \(w_{1}\), as described in Eq. 4.,
where \(\Psi \left( {p_{l} } \right)\) is the recovered well-exposed image and \(f\) represents the probability density function based on the reference image \(p_{ref}\), defined as follows,
In the equation, \(b\) is a learning rate constant. However, this training model has a limitation, which is that the predefined image distribution is not sufficient to differentiate between the generated realistic well-exposed images and images with noise or artifacts.
This paper utilizes normalized flows to model the complex distribution of well-exposed images, representing the conditional probability density function of well-exposed images as \(f_{flow} \left( {p\left| {p_{l} } \right.} \right)\). The low-light image or its features are used as the input for the conditional normalized flow \(\Psi\). The well-exposed image \(p\) is mapped to a latent variable \(g\) with the same dimension \(p\), denoted as \(g = \Psi \left( {p;p_{l} } \right)\). By employing the change of variables theorem, the relationship between \(f_{flow} \left( {p\left| {p_{l} } \right.} \right)\) and \(f_{z} \left( z \right)\) can be expressed as follows:
The parameters are estimated using maximum likelihood estimation to describe the characteristics of well-exposed images, which can be expressed as follows:
The invertible network \(\Psi\) is divided into a sequence of \(N\) reversible layers. \(k^{n} \left( {p_{l} } \right)\) represents the latent features of the encoder \(k\), and \(f_{g}\) denotes the probability density function (PDF) of the latent features \(g\).
Our proposed framework consists of two components: an encoder \(k\), which takes the low-light image \(p_{l}\) as input and outputs a lightness-invariant color mapping \(k\left( {p_{l} } \right)\) (can be seen as a reflectance mapping), and an invertible network that maps the well-exposed image to a latent encoding \(g\).
To generate a robust and high-quality lightness-invariant color mapping, we first extract the relevant features from the input image. These extracted features are then incorporated as part of the encoder, which consists of Residual-in-residual dense blocks (RRDB). The encoder includes the following components:
Histogram equalization
Histogram equalization is a technique that effectively improves the overall contrast of low-light images. The resulting image after histogram equalization can be seen as an image with improved lightness invariance. Including the histogram equalized image as part of the network input allows for better handling of underexposed or overexposed regions.
Color mapping
Inspired by the Retinex theory, the following equation is used for color mapping of the image:
In the equation, the term \(mean_{o}\) represents the average value of each pixel across the RGB channels.
Invertible network
Contrary to the encoder, which targets a one-to-one correspondence, the invertible network is oriented to capture a one-to-many mapping dynamic, accounting for the multifaceted illuminative variations that a single scenario might exhibit. Lighting conditions vary in a given scene. The invertible network primarily learns a one-to-many relationship and is composed of three levels. Each level consists of a compression layer and 12 flow steps.
Based on the assumption, normalized flows primarily learn the conditional distribution of well-exposed images given the low-light image/lightness-invariant color mapping. Normalized flows are expected to perform well under the condition of \(k\left( {p_{l} } \right)\) and \(O\left( {p_{ref} } \right)\) lightness-invariant color mapping because these two mappings are expected to be similar. The training framework is depicted in the following figure:
In the equation, \(f_{g}\) represents the probability density function (PDF) of the latent features.
To restore a low-light image to a well-exposed image, the color mapping \(k\left( {p_{l} } \right)\) is first extracted by the encoder. The latent features from the encoder are then used as a condition for the invertible network. For the sampling strategy of \(g\), one can randomly select a batch of \(g\) from the distribution and compute the average of the generated well-exposed images.
Experiments
The parameter setting
The performance of the proposed algorithm are compared with other effective brightness enhancement algorithms(LIME25, ZeroDCE21, DEEPUPE18, R2RNet20) and denoising(IRCNN36, FFDNet38, DNCNN37). The relevant code utilized was provided by the original authors. The quantitative evaluation metrics SSIM and PSNR are also applied to assess the experimental results. LPIPS, or Learned Perceptual Image Patch Similarity, is a deep learning-based metric for image quality assessment, calibrated to emulate Human Visual System perceptions of image differences, aiming for congruence with subjective human evaluations.
In the deep CNN denoiser, the batch size is set to 4 and an initial learning rate is 0.0001. The training epochs times is 80. In the normalization flow module, the patch size and batch size are respectively \(160 \times 160\) and 16. Adam is applied as the optimizer with a learning rate of \(5 \times 4^{ - 10}\). The experimental platform configuration for the methodology discussed herein consists of an NVIDIA GeForce RTX 3090 GPU, Ubuntu 20.04 operating system, and Python 3.8 programming environment.
Data collection
This study utilized a dataset of bridge crack images provided by the Fujian Provincial Institute of Traffic Sciences, comprising merely 265 samples. To enhance the model’s generalization and robustness, data augmentation techniques were employed, involving adjustments to image brightness and the introduction of random noise. This effectively expanded the image repository, simulating the variable real-world conditions, thereby strengthening the model’s capability to handle complex scenarios.
Consequently, the constructed training set was augmented to 2,369 images, encompassing a broad spectrum of crack characteristics, ensuring the model’s deep understanding of crack representations. An additional independent test set of 976 images, was established to impartially assess the model’s performance when confronted with unseen data.
The ablation part
Component testing
Testing the effectiveness of each component in this method. By employing variants of this method, specifically dedicated to low-light enhancement and denoising separately. The experimental results, as shown in Fig. 2, included the real-world acquired bridge crack image (Fig. 2a), denoised image (Fig. 2b), low-light enhanced image (Fig. 2c), and the image simultaneously for both low-light enhancement and denoising (Fig. 2d). As depicted in Fig. 2b, when denoising part alone was applied, it removed most of the noise from the image, revealing detailed texture information and resulting in a smoother image. But the overall image still lacked brightness. As shown in Fig. 2c, using only the illumination improvement part could restore the brightness of original image, but failed to effectively remove image noise. After restoration, most regions of the image suffered from a loss of detailed information and were still heavily affected by noise. As illustrated in Fig. 2d, simultaneous low-light enhancement and denoising noticeably improved contrast and brightness in the dark areas of the degraded image, effectively removed image noise, and restored rich texture information, resulting in a satisfactory visual outcome.

Component testing.
Pre-treatment or post-treatment
Most brightness enhancement methods could improve the brightness of darker areas, but often resulted in certain regions becoming overexposed. Image denoising algorithms could remove some noise, but often introduced artifacts in the recovered image. While brightness enhancement methods and denoising algorithms could complement each other, simply combining them did not effectively solve the problem of restoring low-light images corrupted by noise. Figure 3a was the input image. As shown in Fig. 3b, c, and d, using LIME as a pre-processing step and denoising algorithms FFDNet or IRCNNNet as post-processing step yielded unsatisfactory results. The recovered images suffered from severe loss of texture details and poor image quality. On the other hand, as shown in Fig. 3e, f, and g, they used denoising algorithm IRCNN as a pre-processing step and brightness enhancement algorithms LIME and Zero-DCE as post-processing steps. The results showed the details of the recovered image being obscured, and the brightness of the recovered image appearing unnatural with persistent noise. In contrast, our proposed algorithm was capable of simultaneously enhancing brightness and removing image noise, while preserving rich texture and detail information in the recovered image without masking any details, as shown in Fig. 3h.

Pre-treatment or post-treatment.
Comparison on noise removing
Figure 4 was the original image. To further validate our algorithm on denoising, different Gaussian noise parameter values of 25 and 50 were respectively added, and the results was Fig. 5. Figure 5a represented the images after noise addition, while Fig. 5b, c, d, e showed the results of IRCNN, FFDNet, DNCNN, and our method, respectively. Table 1 provided a quantitative comparison. From the results, it could be observed that when the noise parameter value was set to 25, IRCNN, FFDNet, and DNCNN achieved similar results to our method, but the quantitative metrics of PSNR and SSIM demonstrated the superiority of our approach. When the noise parameter value was set to 50, IRCNN, FFDNet, and DNCNN exhibited unsatisfactory restoration results with residual noise and obscured image details. In contrast, our method yielded impressive results. Furthermore, the quantitative metrics of PSNR, SSIM, Runtime and FLOPs further proved the superiority of our approach.

The normal exposure image.


The noise removing experiment.
Comparison on image enhancement
The visual results comparison
Regarding the obtained real-world bridge crack images under normal exposure, as shown in Fig. 4, a set of images with different brightness levels was created by reducing the original image brightness to 70%, 50%, and 10%, as depicted in Fig. 6a. A comparison was made between our method and several algorithms, including LIME, ZeroDCE, DEEPUPE, and R2RNet, as shown in Fig. 6b–f. All results were generated using the code provided by the authors’ website, with the recommended parameter settings.

The image enhancement experiment.
As shown in Fig. 6b, when the image brightness was set to 70% and 50% of the original image, most of the brightness information could be restored. However, overexposure and artifacts occurred at the image edges, resulting in excessive smoothing and over saturation in certain areas. As shown in Fig. 6c, When the image brightness was set to 10% of the original image, ZeroDCE performed well in enhancing the brightness information. However, some fine details were masked, demonstrating ZeroDCE’s capability in handling extremely low-light conditions.As shown in Fig. 6d, When the image brightness was reduced to 10% of the original image, DEEPUPE failed to restore the low brightness image. In extremely low brightness conditions, DEEPUPE’s image enhancement capability was inferior to ZeroDCE.As depicted in Fig. 6e, When the image brightness was reduced to 10% of the original, the restored image by R2RNet exhibited unnatural brightness information.
As shown in Fig. 6f, the results of our proposed method were presented. It could be observed that, compared to other methods, our approach effectively restored image brightness information and enhanced the contrast of details and textures. It preserved clear details and produced natural exposure in high-contrast areas. When the image brightness was reduced to 10% of the original, our method successfully enhanced the dark regions while preserving more textures and details. Additionally, our proposed method prevented excessive enhancement and color loss in bright areas.
The quantitative comparison
The quantitative outcomes, delineated in Table 2, unequivocally showcased that our proposed method secured superior metric scores relative to competing approaches, thus underscoring the algorithmic excellence of our solution. A nuanced exception arose when image luminance was halved; here, LIME’s SSIM score reached 0.970, marginally eclipsing our method’s performance. Yet, as Fig. 6b vividly illustrates, the restoration outcomes via LIME were marred by prominent ringing artifacts bordering the image edges—a visual anomaly that our method effectively mitigated, as substantiated by our metric achieving the lowest LPIPS value, indicative of superior perceptual fidelity.
Generalization ability
To validate the performance of our algorithm on other scenario images, we selected three images from different scenes and compared the results with the LIME and ZeroDCE, as shown in Figs. 7 and 8, respectively. It could be observed that LIME effectively restored some of the image’s brightness information, resulting in a relatively natural appearance. However, there were still dark areas in the recovered images, and artifacts could be seen around the image borders. The results of ZeroDCE were unsatisfactory, as the brightness of the recovered images appeared unnatural, and the details were heavily obscured. In contrast, our algorithm demonstrated effective image restoration in the three scenarios. The overall brightness of the recovered images was significantly enhanced, and the images exhibited rich detail information. The experiments validated the generalization ability of the proposed method.

Other application 1.

Other application 2.
Image semantic segmentation results
This section mainly discussed the influence of image quality restoration on image semantic segmentation. Figure 9 were the experimental results. Figure 9a, b, c and d were respectively the input image, the restored image, the semantic result of Fig.(a) and Fig.(b) the The red circle marked the difference between semantic segmentation images before and after image restoration. It could be seen that the semantic segmentation of bridge crack image after image restoration was more accurate, and the complete crack information was displayed. In addition, the image before restoration had a wrong crack semantic segmentation, as shown in Fig. 9c.

The comparison results of image segmentation.
Discussion
The proposed method demonstrates notable superiority in both noise reduction and brightness enhancement. Its denoising performance outstrips IRCNN, FFDNet, and DNCNN, especially under high noise levels (50), where finer detail preservation and leading PSNR and SSIM values are achieved. Regarding brightness enhancement, even at 10% luminance, the method effectively recovers details, avoids overexposure and color loss, and generally excels with higher PSNR and SSIM values compared to LIME, ZeroDCE, DEEPUPE, and R2RNet. Though LIME marginally surpasses in SSIM at 50% brightness, the proposed method maintains a lead in overall brightness enhancement efficacy. However, slight overexposure and artifacts may occur in edge regions when coping with extreme luminance variations, indicating areas for improvement in future research.
Conclusions
This study focuses on restoring low-light and noisy bridge crack images. The approach includes a deep CNN denoiser and a normalized flow module. The objective is to enhance the accuracy of subsequent crack semantic segmentation. Experimental results demonstrate that our algorithm successfully restores low-light and noisy images, surpassing existing methods in terms of both brightness enhancement and denoising. Furthermore, the proposed method has a strong generalization and robust ability. However, it is important to note that the algorithm may encounter challenges when dealing with the motion blurry image. Addressing these limitations requires further research in the future.
Data availability
The data could be obtained by sending an email to the first author Guangying Qiu.
References
Lin, F. & Scherer, R. J. Concrete bridge damage detection using parallel simulation. Autom. Constr. 119, 103283 (2020).
Chen, Y. et al. Analysis of bridge health detection based on data fusion. Adv. Civ. Eng. 2022, 6893160 (2022).
Abdullah-Al-Wadud, M. et al. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53(2), 593–600 (2007).
Land, E. H. The Retinex theory of color vision. Sci. Am. 237(6), 108–128 (1977).
Lee, C., Lee, C. & Kim, C. S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 22(12), 5372–5384 (2013).
Ren, X. et al. Joint enhancement and denoising method via sequential decomposition 1–5 (IEEE, 2018).
Fu, X. et al. A weighted variational model for simultaneous reflectance and illumination estimation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2782–2790 (2016).
Fu, X. et al. A fusion-based enhancing method for weakly illuminated images. Signal Process. 129, 82–96 (2016).
Park, S. et al. Low-light image enhancement using variational optimization-based Retinex model. In IEEE International Conference on Consumer Electronics 70–71 (2017).
Li, M. et al. Structure-revealing low-light image enhancement via robust Retinex model. IEEE Trans. Image Process. 27(6), 2828–2841 (2018).
Yu, S. Y. & Zhu, H. Low-illumination image enhancement algorithm based on a physical lighting model. IEEE Trans. Circuits Syst. Video Technol. 29(1), 28–37 (2019).
Shen, L. MSRnet: Low-light image enhancement using deep convolutional network. Preprint at http://arxiv.org/abs/1711.02488 (2017).
Wei, C. et al. Deep Retinex decomposition for low-light enhancement. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 147–155 (2018).
Zhang, Y., Zhang, J. & Guo, X. Kindling the darkness: A practical low-light image enhancer. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 1632–1640 (2019).
Zhang, Y., Zhang, Di. B. & Wang, C. Self-supervised image enhancement network: Training with low light images only. Preprint at http://arxiv.org/abs/2002.11300 (2020).
Chen, L. et al. Structure-preserving and color-restoring up-sampling for single low-light image. IEEE Trans. Circuits Syst. Vdeo Technol. 32(4), 1889–1902 (2022).
Zhao, Z. et al. Retinex DIP: A unified deep framework for low-light image enhancement. IEEE Trans. Circuits Syst. Vdeo Technol. 32(3), 1076–1088 (2022).
Wang, R. et al. Underexposed photo enhancement using deep illumination estimation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 6849–6857 (2019).
Lu, Y. X. et al. AoSRNet: All-in-one scene recovery networks via multi-knowledge integration. Knowl.-Based Syst. 294, 111786 (2024).
Hai, J. et al. R2RNet: Low-light image enhancement via real-low to real-normal network. https://doi.org/10.48550/arXiv.2106.14501 (2021).
Guo, C. et al. Zero-reference deep curve estimation for low light image enhancement. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 1780–1789 (2020).
Xu, K. et al. HFMNet: Hierarchical feature mining network for low-light image enhancement. IEEE Trans. Instrum. Meas. 71, 1–14 (2022).
Gao, Y., Xu, W. Y. & Lu, Y. X. Let you see in Haze and sandstorm: two-in-one low-visibility enhancement network. IEEE Trans. Instrum. Meas. 72, 5023712 (2023).
Zheng, Z. et al. Single image brightening via multi-scale exposure fusion with hybrid learning. IEEE Trans. Circuits Syst. Video Technol. 31(4), 1425–1435 (2021).
Guo, Y. et al. MDSFE: Multiscale deep stacking fusion enhancer network for visual data enhancement. IEEE Trans. Instrum. Meas. 72, 5004012 (2023).
Li, J., Feng, X. & Hua, Z. Low-light image enhancement via progressive-recursive network. IEEE Trans. Circuits Syst. Video Technol. 31(11), 4227–4240 (2021).
Asem, K. Natural digital image mixed noise removal using regularization Perona-Malik model and pulse coupled neural networks. Soft Comput. 27(21), 15523–15532 (2023).
Li, S. et al. Multi-channel and multi-model-based autoencoding prior for grayscale image restoration. IEEE Trans. Image Process. 29, 142–156 (2020).
Lian, O. et al. Compressed sensing MRI based on the hybrid regularization by denoising and the epigraph projection. Signal Process. 170, 107444 (2020).
Khmag, A. Additive Gaussian noise removal based on generative adversarial network model and semi-soft thresholding approach. Multimed. Tools Appl. 82(5), 7757–7777 (2023).
Lempitsky, V., Vedaldi, A. & Ulyanov, D. Deep image prior. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 9446–9454 (2018).
Chen, C. et al. Real-world image denoising with deep boosting. IEEE Trans. Pattern Anal. Mach. Intell. 42(12), 3071–3087 (2020).
Asem, K., Rahman, R. A. & Noraziahtulhidayu, K. Clustering-based natural image denoising using dictionary learning approach in wavelet ___domain. Soft Comput. 23, 8013–8027 (2018).
Xu, J., Zhang, L. & Zhang, D. External prior guided internal prior learning for real-world noisy image denoising. IEEE Trans. lmage Process. 27(6), 2996–3010 (2018).
Choi, J. H., Elgendy, O. A. & Chan, S. H. Optimal combination of image denoisers. IEEE Trans. Image Process. 28(8), 4016–4031 (2019).
Zhang, K., Zuo, W. & Gu, S. Learning deep CNN denoiser prior for image restoration. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2808–2817 (2017).
Zhang, K., Zuo, W. & Chen, Y. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 26(7), 3142–3155 (2017).
Zhang, K., Zuo, W. & Zhang, L. FFDNet: toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. lmage Process. 27(9), 4608–4622 (2018).
Funding
This research is supported by the This research is supported by the National Natural Science Foundation of China under Grant No.32301700, Jiangxi Poyang Talented Support Plan·Young Science and Technology Talent Lift Project under Grant No.2023QT09, Jiangxi Provincial Natural Science Foundation under Grant No.20232BAB215023, China Postdoctoral Science Foundation under Grant No.2023M741157, N0.2024T170270, Fujian Provincial Transportation Technology Project under Grant No.ZH202308, the open project of State Key Laboratory of Performance Monitoring and Protecting of Rail Transit Infrastructure, East China Jiaotong University (Grant No. HJGZ2023206).
Author information
Authors and Affiliations
Contributions
Guangying Qiu wrote the manuscript, Dan Tao revised the paper. Dequan You revised language errors. Linming Wu helped to add the experimental results.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qiu, G., Tao, D., You, D. et al. Low-illumination and noisy bridge crack image restoration by deep CNN denoiser and normalized flow module. Sci Rep 14, 18270 (2024). https://doi.org/10.1038/s41598-024-69412-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-69412-5
Keywords
This article is cited by
-
High-resolution image reflection removal by Laplacian-based component-aware transformer
Scientific Reports (2025)
-
An Improved Crack Detection Method on Asphalt Pavement via Integrating Adaptive Denoising Filters into Semantic Segmentation Network
International Journal of Pavement Research and Technology (2025)
