
Abstract
This study aimed to develop and validate a predictive model of all-cause mortality risk in American adults aged ≥ 18 years with diabetes. 7918 participants with diabetes were enrolled from the National Health and Nutrition Examination Survey (NHANES) 1999–2016 and followed for a median of 96 months. The primary study endpoint was the all-cause mortality. Predictors of all-cause mortality included age, Monocytes, Erythrocyte, creatinine, Nutrition Risk Index (NRI), neutrophils/lymphocytes (NLR), smoking habits, alcohol consumption, cardiovascular disease (CVD), urinary albumin excretion rate (UAE), and insulin use. The c-index was 0.790 (95% CI 0.779–0.801, P < 0.001) and 0.792 (95% CI: 0.776–0.808, P < 0.001) for the training and validation sets, respectively. The area under the ROC curve was 0.815, 0.814, 0.827 and 0.812, 0.818 and 0.829 for the training and validation sets at 3, 5, and 10 years of follow-up, respectively. Both calibration plots and DCA curves performed well. The model provides accurate predictions of the risk of death for American persons with diabetes and its scores can effectively determine the risk of death in outpatients, providing guidance for clinical decision-making and predicting prognosis for patients.
Similar content being viewed by others

Introduction
Diabetes mellitus is a metabolic disease marked by hyperglycemia1. In recent years, the prevalence of diabetes has shown an alarming increase with changes in diet and lifestyle and is developing into a major public health problem in the world2. Studies have reported that the prevalence of diabetes among adults (20–79 years) worldwide will increase to 7.7% by 2030, affecting 439 million adults3.
Diabetes is known to cause long-term and severe damage to multiple organs and body systems, such as the eyes, heart, kidneys, nerves, and blood vessels, and is a leading cause of blindness, heart attack, kidney failure, stroke, and amputation of lower limbs4. Studies reported that 2.9 million deaths a year are directly attributable to diabetes, a figure comparable to that of human immunodeficiency virus infection and the overall risk of death in participants with diabetes is almost twice that of those without diabetes5,6. Moreover, a multicounty data analysis from 19 data sources in 16 countries or jurisdictions demonstrated that the mortality of participants with diabetes decreased more rapidly than those without diabetes7. Furthermore, diabetes and its complications can also cause great physical suffering and financial burden to patients8. Therefore, it is necessary to predict mortality in diabetes and establish corresponding predictive models to develop aggressive prevention strategies for very high-risk participants that can help reduce the risk of premature death and improve prognosis.
The nomogram is not only a visual statistical prognostic tool, which is widely used in the prognostic assessment of clinical outcomes by calculating the score of potential predictors but also a simple, effective, and reliable prediction model, which can quickly provide clinical risk stratification for clinical care to make prognostic decisions9. To date, several studies have reported predictive models for diabetes and its complications10,11,12, but prediction models for all-cause mortality in a nationally representative person with diabetes have rarely been reported13. As there is no population-based study to establish a mortality risk prediction model for Americans with diabetes from NHANES, this study aims to construct an effective nomogram prediction model for adult (years ≥ 18) outpatient diabetes in the United States to predict their 3-year, 5-year, and 10-year risk of all-cause mortality, helping them benefit from better clinical interventions.
Results
Baseline characteristics of participants
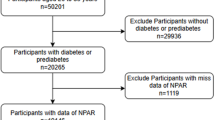
In this study, 7918 participants were included, as shown in Fig. 1. We weighed and adjusted all the results when comparing the two datasets. Among all participants in the study, the median age was 59.014 years (IQR, 58.74–59.29 years) and with 3887(49.62%) females and 4031(50.38%) males were recruited. At a median follow-up of 96 months and a total of 258 (28.61%) participants occurred deaths. Based on the weighted analyses, most of the patients were without a partner, higher than 9th Grate or 9th Grate, smoked less than 100 cigarettes, those who don't drink, had Hypertension, use of hypoglycemic drugs and use of antihypertensive drugs. Participants were divided into a training set and a validation set in a 7:3 ratio. The mean age of individuals in the training set cohort was 58.91 ± 0.27 years old, with 2681 males (48.76%) and 2866 females (51.24%) and the mean age of individuals in the training set cohort was 59.27 ± 0.41 years old, with 1206 males (51.61%) and 1165 females (48.39%). Participants in the two groups were statistically different in Marital status, RBC and fasting glucose. The training set and validation cohort showed similar characteristics in living habits, drug use, dietary intake and chronic diseases. And the specific detailed baseline characteristics of the two group participants are summarized in Table 1.

Flow chart of the study design.
Feature selection and development of an individualized prediction model
Table S1 shows univariable COX regression, and the results show that age, race, marital status, education levels, smoking status, alcohol consumption, CVD, hypertension, use of insulin, use of statins, use of antihypertensive drugs, use of antihyperlipidemic drugs, BMI, white blood cells, lymphocytes, neutrophils, monocytes, hemoglobin, Erythrocyte, platelets, albumin, total cholesterol, uric acid, serum creatinine, LDL, dietary intake of energy, protein intake, carbohydrate intake, fiber intake, coffee intake, calcium intake, magnesium intake, iron intake, zinc intake, NRI, UAE, UA/HDL and FTC/HDL are potential risk factors for death in the diabetic population. Spearman correlation matrix analysis was also performed on statistically the significant variables in the univariate analysis to evaluate the cross-correlation between these variables as shown in Fig. S1. The 45 relevant features in the LASSO regression analysis are reduced to 11 potential predictors in Fig. 2A and B (using the non-zero coefficients of Lambda.1se). These features included age, monocytes, erythrocyte count, urinary albumin excretion rate (UAE), NLR, smoking status, alcohol consumption, CVD, serum creatinine, NRI, and use of insulin (Table 2). Multivariate Cox regression analysis results showed that the 11 variables were independent risk factors of all causes of death in participants with diabetes as shown in Table 2. Using these independent risk factors, we developed a nomogram prediction model for all-cause mortality risk in adults with diabetes over 3, 5, and 10 years (Fig. 3).

LASSO regression models to select risk factors for all-cause mortality in a diabetic population over 10 years. (A) 45 features of the coefficient curves of LASSO, where the coefficient curve plots are generated based on log(lambda) sequences. (B) Cross-validation is used in the optimal parameter (lambda) selection model in LASSO. Partial likelihood deviation (binomial deviation) curves were compared with plotted for log(lambda). The final LASSO coefficient curves for the 11 features were obtained.

Nomogram for estimating the risk of all-cause mortality in diabetes at 3,5,10 years. UAE urinary albumin excretion rate, NLR neutrophil–lymphocyte ratio, CVD cardiovascular disease, NRI National Death Index. Creatinine was categorized into 4 groups. Group 1 (Cr < 100); Group 2 (100 ≤ Cr < 200); Group 3 (200 ≤ Cr < 300); Group 4 (Cr ≥ 300). NRI was categorized into 4 groups: Group 1 (NRI < 83.5); Group 2 (83.5 ≤ NRI < 97.5); Group 3 (97.5 ≤ NRI < 100); Group 4 (NRI ≥ 100). How to use the nomogram: the position of each variable on the corresponding axis was found, a line was drawn on the point axis to indicate the number of points, the points for all variables were summed, and then a line was drawn from the total point axis to determine the probability of all-cause mortality at 3,5,10 years.
Performance of the all-cause mortality risk nomogram in adults with diabetes
Generally speaking, a C-index greater than 0.75 is considered a good predictive performance. The C-index of the nomogram was 0.790 (95% CI 0.779–0.801, P < 0.001) and 0.792 (95% CI 0.776–0.808, P < 0.001) in the training and validation sets, respectively. It indicates a fine accuracy in predicting all-cause mortality in an adult with diabetes. We plotted time-dependent ROC curves, the AUC value of the training set (Fig. 4A) was 0.815, 0.814 and 0.827 for 3, 5, 10 years and the AUC value of the validation set for 3, 5, 10 years was 0.812, 0.818 and 0.829 (Fig. 4B), respectively. And the AUC curves for the training test and validation set are showed in Fig. S2. Figure 5 shows the calibration curves of the model for predicting all-cause mortality risk in adults with diabetes at 3,5 and 10 years from the training and validation set. The calibration curves for the predicted all-cause mortality risk at 3, 5, and 10 years differ slightly from the ideal calibration curves in both datasets, but there is no significant difference between the predicted risk and the observed risk, in general, indicating that the prediction model is well calibrated. The DCA curve is performed on the data from the training and validation sets in Fig. 6. To verify the clinical effectiveness of the model, we conducted a decision curve analysis. On the Y-axis, the vertical distance to the X-axis showed the standard net benefit, while on the X-axis the threshold probability for diabetes. Each graph represented the clinical usefulness of the predictive model for all-cause deaths in the participants with diabetes in different corresponding years, as shown in Fig. 6, reflecting a good predictive efficiency. In addition, we also carried out tenfold internal crossover, and the verification results are shown in Table S2. Finally, we also found a negative interaction between CVD and insulin use, as shown in Tables S3, S4 and Fig. S3.

Time-dependent Receiver Operating Curve (ROC) analysis of the Nomogram model. (A) Training set. (B) Validation set.

Calibration curves for 3, 5, and 10-year mortality risk prediction for diabetes. (A) Training set for 3,5, and 10 years. (B) Validation set 3,5, and 10 years. X-axis represents the predicted risk of morbidity. Y-axis represents the actual diagnosis of diabetes. The solid line represents the performance; the closer to the diagonal dashed line, the better the prediction (the dashed line on the diagonal represents a perfect prediction of an ideal model).

Decision curve analysis (DCA) of the nomogram for the risk of mortality over 3, 5, and 10 years in a diabetic population. (A) Training set for 3 years. (B) Training set for 5 years. (C) Training set for 10 years. (D) Validation set for 3 years. (E) Validation set 5 years. (F) Validation set for 10 years. y-axis represents net benefit. The dashed line represents the all-cause mortality risk nomogram. The thin solid line represents the assumption that all patients die. The thin solid line represents the assumption that no patients die.
Method of using nomogram
The Nomogram model is used to obtain the corresponding scores for each variable and the sum of these scores were recorded as the total score, with the highest score corresponding to 100 points. The total predicted probability was the risk of all-cause death for the participants with diabetes.
In the study, the formula for the Nomogram was as follows:
Score = (1.43*Age−21.43) + (Monocyte*10.08) + (− 2.38*Erythrocyte + 20.22) + (UAE*0.020) + (NLR*1.29) + (Score of Smoking status) + (Score of Alcohol consumption) + (Score of CVD) + (Score of Cr) + (Score of NRI) + (Score of Insulin using).
And the smoking status are classified as never (0), former (4.29), and now (12.91); Alcohol consumption are classified as never (3.73), mild (0), and moderate (6.36); CVD are classified as no (0) and yes (10.04); Cr are classified as Cr < 100 (0), and 100 ≤ Cr < 200 (5.68), 200 ≤ Cr < 300(10.54), Cr ≥ 300(14.11); NRI are classified as NRI < 83.5(17.96),83.5 ≤ NRI < 97.5(8.20), 97.5 ≤ NRI < 100(5.59), NRI ≥ 100(0); Insulin using are classified as no (0) and yes (4.64).
Discussion
To the best of our knowledge, this is the first predictive model of all-cause mortality in an outpatient population with diabetes using the NHANES database. The nomograms not only have good recognition feature and higher prediction accuracy than the existing prediction tools but is easy to use. In addition, the scoring system can clearly and intuitively present the probability of clinical outcomes, which can facilitate better clinical decision-making and physician–patient communication14. However, only a few studies have attempted to use large national sample data to predict the risk of all-cause death in people with diabetes. In our nationally representative sample of American adults with diabetes, we developed and validated an 11-item mortality index to predict the 3-year, 5-year, and 10-year all-cause mortality risk, incorporating relevant covariates such as individual demographic characteristics, dietary condition, lifestyle, chronic disease, use of the drug, and laboratory examination indicators available in the NHANES database. We found that higher age, higher levels of Monocyte, UAE, Cr, and NLR, smoking, with a history of CVD, and use of insulin were significantly associated with increased risk of all-cause mortality, while higher levels of NRI, erythrocyte and mild alcohol consumption were associated with reduced risk of all-cause mortality. The proposed nomogram model includes only common and readily available clinical demographic data, blood analysis indicators, medical history, and medication history variables and shows good predictive performance. For example, the C index value of the training group was 0.790 (95% CI 0.779–0.801, P < 0.001) and the verification cohort group was 0.792 (95% CI 0.776–0.808, P < 0.001). Moreover, the calibration curve, ROC curve, and DCA curve also show good consistency between the actual observations and the predictions.
To date, many models10,13,15,16,17,18,19,20,21,22,23 have been developed to predict the risk of all-cause mortality in patients with type 2 diabetes. However, predictive models developed based on one specific population are often not directly applicable to populations in different countries due to many differences in race, socioeconomic factors, and disease management. Several models10,15,16,17 had been developed to predict the risk of all-cause mortality among people with type 2 diabetes in different parts of Asia, such as Hong Kong, Taiwan, Guangxi, and Shanghai. In addition, a national study reported an all-cause mortality risk prediction model for Chinese adults aged 20–80 years with diabetes10. Previous studies have pointed to some unique characteristics of diabetes populations in Western countries, such as a preponderant association with ethnicity, the older onset of diabetes, a higher risk of complications, and the preponderant use of medications13,19,21,22,23. However, predictors of all-cause mortality from diabetes developed based on the United States population covering very few ethnicities, only African Americans and European Americans24,25,26. Therefore, it is highly desirable to build a specific all-cause mortality risk prediction model for diabetes in the national American population to help achieve more accurate risk prediction.
In recent years, a growing number of studies17,19,25,26,27,28,29 have reported that age, smoking habits, Cr, Monocyte, insulin use and prior history of CVD significantly affect the risk of death in persons with diabetes. In a prospective cohort study30, low B-containing lipoproteins to circulating erythrocytes was associated with increased mortality and cardiovascular risk, which supports our results. The association between UAE and all-cause mortality was reported in a 10-year follow-up study of residents from the Wan Shou Road community in northern China, which concluded that the urinary albumin-to-creatinine ratio was an important risk factor for all-cause mortality in this population31. And our results were also proved by a large study from the Netherlands32, which found that UAE predicted both cardiovascular and non-cardiovascular death in the general population. In addition, malnutrition is highly associated with mortality from various diseases33,34. Malnutrition is considered a global health problem that not only affects people's subjective quality of life, complication rates, and shortened life expectancy but also becomes more severe as the age pyramid changes. The NRI is a simple and accurate screening tool for nutritional status indicators35. Persons with diabetes are often at high risk of malnutrition due to increased nutritional requirements and severe acute inflammatory responses. Malnutrition, in turn, causes malnourished populations to be more susceptible to vascular endothelial cell injury and cardiovascular-related events because it significantly affects the body's regulation of blood glucose, cytokine parameters, and hormones36. Multiple studies have shown that NRI improved patients’ prediction of clinical outcomes37,38,39. In the study, NRI played a critical role in predicting the risk of all-cause mortality in persons with diabetes.
Diabetes is characterized by systemic chronic inflammation accompanied by increased oxidative stress. The NLR, in turn, is a good proxy for the balance between pro- and anti-inflammatory pathway activation and is often used as a proxy to quantify the degree of inflammation. Therefore, the importance of NLR level on the prognosis of diseases has been widely concerned40,41. In our statistical analysis, increased levels of NLR in the diabetic population were positively associated with all-cause mortality, which is consistent with the previous study42. Interestingly, we also found that it was mild and moderate alcohol consumption that significantly reduced the risk of death from diabetes. A review also noted that alcohol consumption may be associated with a reduced risk of death at light to moderate drinking levels of up to 14 g per day for women and 28 g per day for men43. Meanwhile, a study by Polsky and colleagues found that light to moderate alcohol consumption was associated with a lower risk of all-cause mortality in diabetes44.
The strengths of this study are as follows. Firstly, we use a sufficiently large nationally representative sample. Secondly, besides demographic information, we include not only lifestyle and laboratory-related indicators of chronic disease, but also dietary data on risk factors, which means that we are able to construct a comprehensive risk model that accurately predicts the risk of all-cause mortality in diabetes. Thirdly, this model obtained good prediction accuracy by cross-validation of the model, indicating strong internal validity of the results. Fourth, we also found a negative interaction between CVD and insulin use. Finally, we provide a nomogram tool that allows simple assessment of the 3, 5, and 10-year all-cause mortality risk in diabetes, which can be easily and time-effectively applied in clinical settings.
There are some limitations to this study. First, this is a retrospective study, and further prospective studies are needed at a later stage to validate our results. Second, although we included as many risk factors as possible, we cannot completely rule out the possibility of missing others. Finally, the population in this study was adults with diabetes in the United States, so the prediction model may not be applicable to populations in other countries.
The model provides a powerful tool for clinical care to identify the risk of death in persons with diabetes and facilitate timely interventions that ultimately improve the quality of survival and extend patient life.
Methods
Study design and population
This cohort study design strictly adheres to the guidelines of TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis)45 and met the framework of the prognostic Research Strategy (PROGRESS). Data from nine contiguous cycles of the National Health and Nutrition Examination Survey (NHANES) 1999–2016, a series of stratified, multistage, complex, and probability cluster samples designed by the National Center of Health Statistics of the Centers for Disease Control and Prevention aimed to assess the health status of citizens in the US, which is publicly released on a two-year cycle and all of it analyzed in the manuscript can available on the website: https://wwwn.cdc.gov/nchs/nhanes/search/default.aspx. Participants were invited to stay at home or to a mobile screening center (MEC) to answer relevant demographic information, lifestyle, and dietary questions posed by professionally trained staff, and to have their blood drawn as directed. From 1999 to 2016, the total sample size was 87,991 participants, including 50,787 (58%) who were ≥ 18 years. We selected the participants with legitimate follow-up data (50,695) and excluded people with non-diabetic (42,777), leaving a final sample of 7918. In this study, 70% of the participants in the NHANES 1999–2016 cycle were selected for the training set, while the validation set consisted of 30% of the participants from the nine cycles. Specific details about the study’s sampling and exclusion criteria are shown in Fig. 1. The data were analyzed from January 4, 2023, to March 10, 2023. All participants signed informed consent forms and the NHANES survey protocol was approved by the National Center for Health Statistics Research Ethics Review Committee. The ethics approval numbers are Protocol #98-12, Protocol #2005-06, Continuation of Protocol#2005-06, and Protocol #2011-17. You can find it at this website: NCHS Ethics Review Board Approval (cdc.gov).
Diagnosis of diabetes
Diabetes is diagnosed by including these conditions and must meet one of the following criteria: the doctor told you have diabetes, HemoglobinA1c (HbA1c) (%) > 6.5, fasting glucose (mmol/L) ≥ 7.0, random blood glucose (mmol/L) ≥ 11.1, two-hour OGTT blood glucose (mmol/L) ≥ 11.1 and use of c or insulin. Hypoglycemic drugs include the following drugs: biguanides, sulfonylureas, thiazolidinediones, dipeptidyl peptidase 4 inhibitors, Glp-1 receptor agonists, sodium-glucose cotransporter-2, alpha-glycosidase inhibitors, and glycerides.
Outcomes
The follow-up all-cause mortality as of December 31, 2019, was determined from the NHANES Public-Use Association Mortality File, obtained by the National Center for Health Statistics (NCHS) in conjunction with the National Death Index (NDI) using a probabilistic matching algorithm46. During the entire follow-up period, any subjects who did not match any of the death records were considered alive.
Potential predictors
Potential predictive variables were evaluated based on clinical experience, scientific knowledge, and predictors identified in previously published articles37,45,46,47,48,49,50,51. The standard questionnaire collected information on demographic characteristics, habits of life, and medical history. Demographic characteristics (age, gender, ethnicity, Marital status, education levels), living habit (smoking status and drinking habits), dietary intake (energy, protein, carbohydrate, fiber, Caffeine, calcium, magnesium, iron and zinc), body measure characteristics (body mass index (BMI), Laboratory parameter (white blood cells, lymphocytes, neutrophils, monocytes, hemoglobin, Erythrocyte, platelets (PLT), uric acid (UA), urinary albumin excretion rate (UAE), serum creatinine(Cr), low-density lipoprotein (LDL), triglycerides (TG), fasting glucose (Glu), glycosylated hemoglobin, fast total cholesterol (FTC), UA/HDL, TG/HDL, FTC/HDL, neutrophils/lymphocytes (NLR), and albumin)), disease history(Hypertension, cardiovascular disease (CVD)), Medication history (hypoglycemic drugs, antihypertensive medication, statins, insulin drugs, Antihyperlipidemic drugs)were evaluated by staff. Ethnicities were categorized as non-Hispanic white, non-Hispanic black, Mexican American, or other. Marital status was classified as never married, having a partner (married or living with a partner), or without a partner (widowed, divorced, or separated). Education levels were classified as lower than 9th grade, and higher than 9th grade, or 9th grade. Smoking status was defined as the timeline of cigarettes and numbers in life: never (smoked less than 100 cigarettes), former (smoked more than 100 cigarettes in life and smoke not at all now), now (smoked more than 100 cigarettes in life and smoke some days or every day).
Participants were categorized as “never”, “mild”, and “moderate” based on the number of drinks per day he/she had drunk: Participants who drank before but don't drink now and those who never drank before were defined as “never”; “mild” were considered to be drinking alcohol ≤ 1 drink for women in 1 year and ≤ 2 drinks for men in 1 year; “moderate” were considered to be drinking alcohol ≥ 2 drinks for women in 1 year and ≥ 3 drinks for men in 1 year52. Data for the dietary interview portion were collected from the 24-h Recall Questionnaire, which was collected by the National Center for Health Statistics (NCHS) of the United States Department of Agriculture. BMI was calculated as weight (kg)/height (m2). Blood pressure was measured by a trained technician according to a standard means, using a manual mercury sphygmomanometer to measure participants’ blood pressure, with every individual being measured three times. The laboratory parameters were obtained from the Hemal Biochemistry File. Fasting glucose53 was monitored in the morning after a 9-h fast and after the initial venipuncture. CVD was defined as congestive heart failure/coronary heart disease/angina/heart attack or stroke. The hypertensive population was defined as the participants with a history of hypertension diagnosis or use of antihypertensive medication, or with SBP ≥ 140 mmHg or DPB ≥ 90 mmHg54. Antihypertensive drugs were defined as beta receptor blockers, calcium channel blockers, angiotensin receptor blockers, and diuretics. The Nutrition Risk Index (NRI) = (1.519*serum albumin (g/L)) + (41.7*body weight (kg)/ideal weight (kg))55. Fasting triglyceride and glucose simple index (TyG) = Triglyceride(mg/dl) *fasting glucose(mg/dl)/256.
Statistical analysis
We considered complex sampling designs and sample sizes during the data analysis in accordance with NHANES analysis guidelines57. And the present data can represent a sample population of 26,572,054. The missing data in selected variables were multiplied using the predictive average matching method in the chain equation algorithm, and the five estimated data sets were analyzed separately. Finally, the results were combined using Rubin's rule58. To compare the differences between the validation and training sets, continuous variables were expressed as weighted means with standard deviations and compared using Student's t-test; categorical variables were expressed as cases (n) and percentages (%) and compared using Rao Scott's χ2 test. Correlation analysis was performed using Person correlation for continuous variables.
In variable selection, univariate Cox-proportional hazard regression was used to select variables associated with outcome events, and uncorrelated variables are eliminated. After that, the minimum absolute contraction and selection operator (LASSO) regression (“Glmnet” package 4.2–6 edition) was used to screen the variables in the training set and non-zero coefficient variables were regarded as risk factors in the LASSO regression model. Finally, multivariate Cox-proportional hazard regression was used to screen out variables that are highly independent and correlated with outcome events. In univariate and multivariate bivariate Cox regression analysis, a two-sided P < 0.05 was regarded as a significant difference. The penalty function in LASSO regression was beneficial to avoid overfitting and build a robust model. Based on the results of the multivariate logistic regression analysis, a nomogram was formulated. To test the accuracy of the prediction model of the nomogram, time-dependent receiver operating characteristic (ROC) curves, an area under the curve (AUC), and consistency index (C-index) were calculated using data from the training and validation sets, respectively. LASSO regression through selecting the minimum λ criterion to determine potential predictors as the plots of versus log (λ) and area under the receiver operating characteristic (AUC) value. In addition, both calibration plots and decision curve analysis (DCA) used a bootstrap method with 1000 resamples. To assign a value to each variable when creating the risk scores, we create categories for some of the continuous variables in the model. These categories were created based on the distribution of each variable. The β coefficients of the covariates of the final selected variables were used to assign points to each risk factor, which were then added together to obtain an overall score. All analyses were performed using the statistical software package R (http://www.r-project.org; version 4.2.2, The R Foundation) and Free Statists (version 1.9).
Ethics approval and consent to participant
This study is an analysis of the publicly available NHANES data. Informed consent was obtained from NHANES participants by the National Center for Health Statistics Research Ethics Review Board and the ethics approval number are Continuation of Protocol #98–12, Protocol #2005–06, Continuation of Protocol#2005–06, and Protocol #2011–17. You can find it at this website: NCHS Ethics Review Board Approval (cdc.gov). The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.
Data availability
All the data are available to the public and were used in the manuscript and can be available on the website: https://wwwn.cdc.gov/nchs/nhanes/search/default.aspx.
Abbreviations
- NHANES:
-
National health and nutrition examination survey
- LASSO:
-
Least absolute selection and shrinkage operator
- ROC:
-
Receiver operating characteristic
- DCA:
-
Decision curve analysis
- NRI:
-
Nutrition risk index
- NLR:
-
Neutrophils/lymphocytes
- CVD:
-
Cardiovascular disease
- TRIPOD:
-
Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis
- PROGRESS:
-
Prognostic research strategy
- MEC:
-
Mobile screening center
- HbA1c:
-
HemoglobinA1c
- NCHS:
-
National center for health statistics
- NDI:
-
National death index
- BMI:
-
Body mass index
- WBC:
-
White blood cell
- RBC:
-
Red blood cell
- PLT:
-
Platelet
- Glu:
-
Glucose
- Cr:
-
Creatinine
- UA:
-
Uric acid
- TG:
-
Triglycerides
- UAE:
-
Urinary albumin excretion rate
- FTC:
-
Fast total cholesterol
- LDL:
-
Low-density lipoprotein cholesterol
- HDL:
-
High-density lipoprotein cholesterol
- TyG:
-
Triglyceride-glucose index
- DM:
-
Diabetes mellitus
References
Dong, P.-T., Lin, H., Huang, K.-C. & Cheng, J.-X. Label-free quantitation of glycated hemoglobin in single red blood cells by transient absorption microscopy and phasor analysis. Sci. Adv. 5(5), eaav0561 (2019).
Gautheron, J. et al. The necroptosis-inducing kinase RIPK3 dampens adipose tissue inflammation and glucose intolerance. Nat. Commun. 7, 11869 (2016).
Shaw, J. E., Sicree, R. A. & Zimmet, P. Z. Global estimates of the prevalence of diabetes for 2010 and 2030. Diabetes Res. Clin. Pract. 87(1), 4–14 (2010).
Gregg, E. W. et al. Trends in cause-specific mortality among adults with and without diagnosed diabetes in the USA: An epidemiological analysis of linked national survey and vital statistics data. Lancet 391(10138), 2430–2440 (2018).
Roglic, G. et al. The burden of mortality attributable to diabetes: realistic estimates for the year 2000. Diabetes Care 28(9), 2130–2135 (2005).
Li, S., Wang, J., Zhang, B., Li, X. & Liu, Y. Diabetes mellitus and cause-specific mortality: A population-based study. Diabetes Metab. J. 43(3), 319–341 (2019).
Magliano, D. J. et al. Trends in all-cause mortality among people with diagnosed diabetes in high-income settings: A multicountry analysis of aggregate data. Lancet Diabetes Endocrinol. 10(2), 112–119 (2022).
Selvin, E., Coresh, J. & Brancati, F. L. The burden and treatment of diabetes in elderly individuals in the U.S. Diabetes Care 29(11), 2415–9 (2006).
Balachandran, V. P., Gonen, M., Smith, J. J. & DeMatteo, R. P. Nomograms in oncology: More than meets the eye. Lancet Oncol. 16(4), e173–e180 (2015).
Shao, X. et al. Development and validation of a prediction model estimating the 10-year risk for type 2 diabetes in China. PLoS One 15(9), e0237936 (2020).
Mo, M. et al. Development and validation of a prediction model for survival in diabetic patients with acute kidney injury. Front. Endocrinol. (Lausanne) 12, 737996 (2021).
Wu, B., Niu, Z. & Hu, F. Study on risk factors of peripheral neuropathy in type 2 diabetes mellitus and establishment of prediction model. Diabetes Metab. J. 45(4), 526–538 (2021).
McEwen, L. N. et al. Predictors of mortality over 8 years in type 2 diabetic patients: Translating Research Into Action for Diabetes (TRIAD). Diabetes Care 35(6), 1301–1309 (2012).
Wang, H. et al. Predicting medication nonadherence risk in a Chinese inflammatory rheumatic disease population: Development and assessment of a new predictive nomogram. Patient Prefer Adher. 12, 1757–1765 (2018).
Wan, E. Y. F. et al. Prediction of five-year all-cause mortality in Chinese patients with type 2 diabetes mellitus—A population-based retrospective cohort study. J. Diabetes Complicat. 31(6), 939–944 (2017).
Li, T.-C. et al. Development and validation of prediction models for the risks of diabetes-related hospitalization and in-hospital mortality in patients with type 2 diabetes. Metabolism 85, 38–47 (2018).
Qi, J. et al. Developing a prediction model for all-cause mortality risk among patients with type 2 diabetes mellitus in Shanghai, China. J. Diabetes 15(1), 27–35 (2023).
Yang, X. et al. Development and validation of an all-cause mortality risk score in type 2 diabetes. Arch. Intern. Med. 168(5), 451–457 (2008).
Wells, B. J. et al. Predicting 6-year mortality risk in patients with type 2 diabetes. Diabetes Care 31(12), 2301–2306 (2008).
Islam, Z. et al. Prediabetes, diabetes, and the risk of all-cause and cause-specific mortality in a Japanese working population: Japan Epidemiology Collaboration on Occupational Health Study. Diabetes Care 44(3), 757–764 (2021).
Fernandez, C. et al. Plasma levels of the proprotein convertase furin and incidence of diabetes and mortality. J. Intern. Med. 284(4), 377–387 (2018).
Ramírez-Prado, D. et al. Predictive models for all-cause and cardiovascular mortality in type 2 diabetic inpatients. A cohort study. Int. J. Clin. Pract. 69(4), 474–84 (2015).
De Cosmo, S. et al. Development and validation of a predicting model of all-cause mortality in patients with type 2 diabetes. Diabetes Care 36(9), 2830–2835 (2013).
Hayek, S. S. et al. Predicting mortality in African Americans with type 2 diabetes mellitus: Soluble urokinase plasminogen activator receptor, coronary artery calcium, and high-sensitivity C-reactive protein. J. Am. Heart Assoc. 7(9), e008194 (2018).
Gillum, R. F., Mussolino, M. E. & Madans, J. H. Diabetes mellitus, coronary heart disease incidence, and death from all causes in African American and European American women: The NHANES I epidemiologic follow-up study. J. Clin. Epidemiol. 53(5), 511–518 (2000).
Raffield, L. M. et al. Predictors of all-cause and cardiovascular disease mortality in type 2 diabetes: Diabetes heart study. Diabetol. Metab. Syndr. 7, 58 (2015).
Mlekusch, W. et al. Serum creatinine predicts mortality in patients with peripheral artery disease: Influence of diabetes and hypertension. Atherosclerosis 175(2), 361–367 (2004).
Yang, L. et al. Peripheral monocyte count is an independent predictor of all-cause mortality in type 2 diabetes with macro-vascular complications. Medicine (Baltimore) 99(4), e18876 (2020).
Chiu, S.Y.-H., Chen, Y. I., Lu, J. R., Ng, S.-C. & Chen, C.-H. Developing a prediction model for 7-year and 10-year all-cause mortality risk in type 2 diabetes using a hospital-based prospective cohort study. J. Clin. Med. 10(20), 4779 (2021).
de Vries, M. A. et al. Erythrocyte-bound apolipoprotein B in atherosclerosis and mortality. Eur. J. Clin. Investig. 47(4), 289–296 (2017).
Zhang, A. et al. The relationship between urinary albumin to creatinine ratio and all-cause mortality in the elderly population in the Chinese community: A 10-year follow-up study. BMC Nephrol. 23(1), 16 (2022).
Hillege, H. L. et al. Urinary albumin excretion predicts cardiovascular and noncardiovascular mortality in general population. Circulation 106(14), 1777–1782 (2002).
Kaegi-Braun, N., Mueller, M., Schuetz, P., Mueller, B. & Kutz, A. Evaluation of nutritional support and in-hospital mortality in patients with malnutrition. JAMA Netw. Open 4(1), e2033433 (2021).
Kobayashi, I. et al. Geriatric Nutritional Risk Index, a simplified nutritional screening index, is a significant predictor of mortality in chronic dialysis patients. Nephrol. Dial. Transplant. 25(10), 3361–3365 (2010).
Perioperative total parenteral nutrition in surgical patients. N. Engl. J. Med., 325(8), 525-32 (1991).
Rajamanickam, A., Munisankar, S., Dolla, C. K., Thiruvengadam, K. & Babu, S. Impact of malnutrition on systemic immune and metabolic profiles in type 2 diabetes. BMC Endocr. Disord. 20(1), 168 (2020).
Ma, X.-T. et al. Nutritional risk index improves the GRACE score prediction of clinical outcomes in patients with acute coronary syndrome undergoing percutaneous coronary intervention. Front. Cardiovasc. Med. 8, 773200 (2021).
Correa-Rodríguez, M. et al. The prognostic nutritional index and nutritional risk index are associated with disease activity in patients with systemic lupus erythematosus. Nutrients 11(3), 638 (2019).
Jiao, Z. et al. Prognostic utility of nutritional risk index in patients with head and neck soft tissue sarcoma. Nutrients 15(3), 641 (2023).
Scilla, K. A. et al. Neutrophil-lymphocyte ratio is a prognostic marker in patients with locally advanced (Stage IIIA and IIIB) non-small cell lung cancer treated with combined modality therapy. Oncologist 22(6), 737–742 (2017).
King, A. H. et al. Elevated neutrophil-lymphocyte ratio predicts mortality following elective endovascular aneurysm repair. J. Vasc. Surg. 72(1), 129–137 (2020).
Lee, S. et al. Development of a predictive risk model for all-cause mortality in patients with diabetes in Hong Kong. BMJ Open Diabetes Res. Care 9(1), e001950 (2021).
Hendriks, H. F. J. Alcohol and human health: What is the evidence?. Annu. Rev. Food Sci. Technol. 11, 1–21 (2020).
Polsky, S. & Akturk, H. K. Alcohol consumption, diabetes risk, and cardiovascular disease within diabetes. Curr. Diab. Rep. 17(12), 136 (2017).
Collins, G. S., Reitsma, J. B., Altman, D. G. & Moons, K. G. M. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement. BMJ 350, g7594 (2015).
Wolffenbuttel, B. H. R., Heiner-Fokkema, M. R., Green, R. & Gans, R. O. B. Relationship between serum B12 concentrations and mortality: Experience in NHANES. BMC Med. 18(1), 307 (2020).
Katsimpris, A. et al. Prediction of type 2 diabetes mellitus based on nutrition data. J. Nutr. Sci. 10, e46 (2021).
Alkhatatbeh, M. J., Hmoud, Z. L., Abdul-Razzak, K. K. & Alem, E. M. Self-reported sleep bruxism is associated with vitamin D deficiency and low dietary calcium intake: A case-control study. BMC Oral Health 21(1), 21 (2021).
Quan, J. et al. Development and validation of the CHIME simulation model to assess lifetime health outcomes of prediabetes and type 2 diabetes in Chinese populations: A modeling study. PLoS Med. 18(6), e1003692 (2021).
Deberneh, H. M. & Kim, I. Prediction of type 2 diabetes based on machine learning algorithm. Int. J. Environ. Res. Public Health 18(6), 3317 (2021).
Xiao, Y. et al. Elevated serum creatinine levels and risk of cognitive impairment in older adults with diabetes: A NHANES study from 2011–2014. Front. Endocrinol. (Lausanne) 14, 1149084 (2023).
Rattan, P. et al. Inverse association of telomere length with liver disease and mortality in the US population. Hepatol. Commun. 6(2), 399–410 (2022).
Xie, X. et al. Association between triclocarban and triclosan exposures and the risks of type 2 diabetes mellitus and impaired glucose tolerance in the National Health and Nutrition Examination Survey (NHANES 2013–2014). Environ. Int. 136, 105445 (2020).
Chobanian, A. V. et al. The seventh report of the joint national committee on prevention, detection, evaluation, and treatment of high blood pressure: The JNC 7 report. JAMA 289(19), 2560–2572 (2003).
Przekop, Z. et al. Efficacy of the nutritional risk index, geriatric nutritional risk index, BMI, and GLIM-defined malnutrition in predicting survival of patients with head and neck cancer patients qualified for home enteral nutrition. Nutrients 14(6), 1268 (2022).
Minh, H. V. et al. Assessment of preferred methods to measure insulin resistance in Asian patients with hypertension. J. Clin. Hypertens. (Greenwich) 23(3), 529–537 (2021).
Ruan, Z. et al. Association between psoriasis and nonalcoholic fatty liver disease among outpatient US adults. JAMA Dermatol. 158(7), 745–753 (2022).
Pabinger, I. et al. A clinical prediction model for cancer-associated venous thromboembolism: a development and validation study in two independent prospective cohorts. Lancet Haematol. 5(7), e289–e298 (2018).
Acknowledgements
We thank the researchers, staff, and participants of the National Health and Nutrition Examination Survey for their contributions to making this analysis possible. We also thanks to Zhang Jing (Shanghai Tongren Hospital) for his work on the NHANES database. His outstanding work, nhanesR package and webpage, makes it easier for us to explore NHANES database.
Author information
Authors and Affiliations
Contributions
Conceptualization, X.S.; methodology, X.S.; software, X.S., L.Y.; validation, L.Y; formal analysis, X.S., L.Y.; investigation, X.S., X-H-Z, L.Y.,; resources, X.S; data curation, X.S., L.Y and X-H-Z.; writing—original draft preparation, X.S.; writing—review and editing, X.S., X-H-Z., L.Y., J-F-Z and P-F-W; visualization, X.S., X-H-Z., J-F-Z and P-F-W.; supervision, L.J and S-Z-S. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shen, X., Zhang, X.H., Yang, L. et al. Development and validation of a nomogram of all-cause mortality in adult Americans with diabetes. Sci Rep 14, 19148 (2024). https://doi.org/10.1038/s41598-024-69581-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-69581-3
