
Abstract
In real-life complex traffic environments, vehicles are often occluded by extraneous background objects and other vehicles, leading to severe degradation of object detector performance. To address this issue, we propose a method named YOLO-OVD (YOLO for occluded vehicle detection) and a dataset for effectively handling vehicle occlusion in various scenarios. To highlight the model attention in unobstructed region of vehicles, we design a novel grouped orthogonal attention (GOA) module to achieve maximum information extraction between channels. We utilize grouping and channel shuffling to address the initialization and computational issues of original orthogonal filters, followed by spatial attention for enhancing spatial features in vehicle-visible regions. We introduce a CIoU-based repulsion term into the loss function to augment the network’s localization accuracy in scenarios involving densely packed vehicles. Moreover, we explore the effect of the knowledge-based Laplacian Pyramid on the OVD performance, which contributes to fast convergence in training and ensures more detailed and comprehensive feature retention. We conduct extensive experiments on the established occluded vehicle detection dataset, which demonstrates that the proposed YOLO-OVD model significantly outperforms 14 representative object detectors. Notably, it achieves improvements of 4.7% in Precision, 3.6% in [email protected], and 1.9% in [email protected]:0.95 compared to the YOLOv5 baseline.
Similar content being viewed by others
Introduction
Vehicle detection is one of the important topics in the field of computer vision, which has a wide range of applications in driverless driving, vehicle counting, and intelligent transportation1,2,3. Object detector frameworks have made significant strides in accuracy and robustness in recent years, yet obstacles such as occlusion still limit them from reaching the level of human vision4. In the context of complex urban traffic, vehicles are often occluded by buildings, trees, pedestrians,and other vehicles, making them difficult to detect due to varying locations, proportions, and types of occlusions. The detection results of different models for two typical scenarios are shown in Fig. 1a to c.

The visual results of occluded vehicle detection and attention maps (using CAM++5) from the leading detectors and our method. (a) Detection results of YOLOv56. (b) Detection results of YOLOv77. (c) Detection results of our YOLO-OVD network. (d) Attention maps generated by YOLOv5. (e) Attention maps of YOLOv5 enhanced with our proposed GOA. (f) Attention maps generated by our method. Our method pays more attention to occluded areas, exhibiting clearer activation regions and more distinct activation boundaries, as shown by the orange dashed lines.
In the field of vehicle detection, occlusion can be divided into two main categories: mutual occlusion among vehicles, known as intra-class occlusion, and occlusion of vehicles by different entities, referred to as inter-class occlusion. In inter-class occlusion scenarios, occlusion of extraneous objects leads to the loss of vehicle features, hinders the expression of key feature information of the inspected vehicle, and makes it difficult for the object detector to extract and learn features of vehicles. In contrast, when occlusion occurs between vehicles, the region of interest (RoI) of the occluded vehicle may contain features of other vehicles, which not only interferes with the accurate localization of the vehicle, but also may cause a high degree of overlap between prediction frames. In the post-processing stage, the detector is very sensitive to the threshold of non-maximum suppression (NMS), and it is difficult to find a threshold t that applies to both sparse and dense objects, making it impossible to handle sparse and highly overlapping objects simultaneously8,9,10,11.
To address the issue of occlusion, some methods12,13,14 improve occlusion detection performance by designing part detectors based on the structural features of the occluded target, using a priori knowledge and structural information about the visible parts of the target. The need to train each part leads to an exponential increase in network overhead and necessitates labeling the dataset parts individually. To enhance the model’s ability in scenarios with a high density of targets, some studies10,11,14,15 focus on refining the loss function and optimizing the post-processing stages. In addition, some works16,17 integrate compositional models with DCNNs into a unified deep model, which can effectively ignore the occluded parts of vehicles. However, while this integration strategy bolsters the model’s capacity to handle occlusions, it concurrently escalates the intricacy and computational demands of the training process.
In response to the aforementioned analysis, we propose a novel detection network capable of recognizing occluded and dense vehicles in complex traffic environments, called YOLO-OVD. We consider that the model perceives only a fraction of the car in images regardless of occlusion presence, and enhancing the feature extraction capability of the network for the visible region of the vehicle is certainly a solution. Therefore, we design a novel Grouped orthogonal attention (GOA) module based on Orthonet18 for integration into the backbone to enhance the extraction capabilities of key vehicle features. The GOA module groups the input features, addressing the issues of initialization and computational demand of the original orthogonal filters in deep layers. Simultaneously, we employ channel shuffling to ensure information flow between groups and introduce spatial attention to enhance the spatial feature representation of vehicle-visible regions. Furthermore, to minimize information loss during the feature extraction process, which involves cascade downsampling, we have incorporated a Laplacian pyramid module. This module explicitly mitigates the information loss associated with feature downsampling, ensuring more detailed and comprehensive feature retention. To further cope with the intra-class occlusion problem, we introduce a modified RepLoss10 into the YOLO-OVD. By integrating CIoU into the repulsion term \(L_{RepGT}\), the modified RepLoss forces the prediction boxes to move apart, alleviating the computational cost and performance decline in dense object scenarios. As shown in Fig. 1d to f, after progressively adding our proposed modules, the network exhibits heightened attention to areas of occlusion, featuring distinctly clearer regions of activation and sharper activation boundaries, thereby enhancing precision in the ensuing steps of localization and recognition.
A major challenge in the field of occluded vehicle detection is the lack of available datasets of occluded vehicles in real traffic environments. The existing datasets are mainly synthetic, which means that models trained on these datasets may not generalize well to real-world scenarios4. Therefore, based on the UA-DETRAC19 dataset, we obtain the dataset UADETRA-OVD consisting of 8677 images that are abundant in instances of mutual vehicle occlusion and vehicles being occluded by other objects, through IoU threshold filtering and manual labeling.
Extensive experiments on the UADETRA-OVD benchmark demonstrate that our network outperforms 14 representative state-of-the-art object detection algorithms, highlighting that our proposed three modules can substantially improve the model’s adaptability to occlusion cases. The main contributions of our approach are as follows:
-
Based on UA-DETRAC, we establish the UADETRAC-OVD dataset, enriched with mutual occlusion of vehicles and occlusion of vehicles by other objects. The dataset is available at https://github.com/LittleGrey-hjp/OVD.
-
We propose a vehicle object detection framework, called YOLO-OVD, for effectively dealing with occlusion cases including intra-class and inter-class vehicle occlusions.
-
To tackle the challenge of detecting occluded vehicles in intricate urban traffic environments, YOLO-OVD utilizes a GOA module equipped with channel grouping and shuffling for efficient filter initialization, alongside spatial attention to further boost the occluded vehicle localization. The Laplacian-Guided Feature Fusion network aggregates features to ensure enhanced detail retention and comprehensive feature retention. We modified the RepLoss by integrating CIoU into the repulsion term to further cope with the mutual occlusion between vehicles.
-
The superiority of our approach is demonstrated through extensive experiments comparing with 14 representative state-of-the-art object detection algorithms on the OVD dataset. Comprehensive ablation experiments on the proposed modules are conducted to demonstrate their effectiveness in improving occluded vehicle detection.
The rest of this work is organized as follows. Section "Related work" briefly describes the work related to traditional occluded object detection and deep learning-based occluded object detection. Details of the proposed YOLO-OVD network for occluded vehicle detection are described in Sect. "Proposed method". Section Experiments and discussion first describes our UADETRAC-OVD dataset and then shows the evaluation and comparison results of the experiments. Finally, the conclusions and future work are given in Sect. Conclusion.
Related work
Occluded object detection via traditional method
Traditional occlusion object detection methods can be broadly classified into three categories, grayscale-based methods, boundary-based methods, and local feature-based methods. Jocher et al.20 identified curvature extreme points on the contour as key points and segments the object contour by connecting these points to identify occluded objects. While using curvature extreme points strengthens the segmentation’s stability, occlusion leads to the loss of many such points, thereby impacting the accuracy of object recognition. Herbert Bay et al.21 proposed SURF(Speeded-Up Robust Features) to extract local features by building pyramids through box filters based on integral images. By combining HOG features and discriminatively trained multi-scale deformable part models, the method proposed by Felzenszwalb et al.22 accurately recognizes feature representations of target shapes and structures at different scales. Wang et al.23 utilized a cascade Adaboost classifier where any sub-image eliminated in the last two stages is regarded as a suspected occluded vehicle. These suspected occluded vehicles are then compared with eight artificially established vehicle occlusion visual models using color histogram matching for classification. As mentioned above, traditional handcrafted features possess robust mathematical interpretability and significant value. However, existing deep learning-based object detection models overly rely on abstract features from deep network and completely abandon traditional handcrafted features that contain rich expert experience, which reduces the credibility of the model. So inspired by the ability of Laplacian Pyramid to successfully emphasize spatial differences in scales24, we introduce the knowledge-based Laplacian Pyramid into the deep network in this paper to improve the model performance.
Occluded object detection via deep learning
Amidst the swift advancements in deep learning, the ___domain of object detection has witnessed the advent of many generic object detection frameworks like R-CNN25, Faster R-CNN26, SDD27, YOLO28, etc., which have demonstrated significant effectiveness in detecting traditional images, but their performance is unsatisfactory in the presence of extreme situations such as occlusion. Ying et al.29 proposed the Pyramid Dual Pooling Attention Module (PDPAM), which integrates two distinct attention mechanisms in parallel to combine spatial and semantic information, thereby improving performance in vehicle detection. Su et al.30 proposed an occlusion-aware attention (OAA) module that utilizes higher-order statistical features of the overall representation to highlight the spatial details of the feature channel. SWD-FPN (Simplified Weighted Dual-Path Feature Pyramid Network), proposed by J.Luo et al.31, simplified the original dual-path fusion method and improved the robustness of the model in congested traffic environments by fusing features of different scales with different weights. Zou et al.32 investigated how different attention mechanisms affect the detection of occluded pedestrians. They introduce two guided attention mechanisms that help CNNs focus on important regions of the image, improving the model’s ability to recognize and locate occluded pedestrians. Zhan et al.33 proposed a lightweight Tri-layer plugin to augment the instance segmentation header, which directs the model to pay more attention to the partially occluded objects, by iteratively pooling RoI features based on predicted target masks. Xie et al.34 proposed a new partially occluded region of interest (PORoI) pooling unit that integrates a priori structural information about the target with visibility prediction into the network. Wen et al.35 designed a Regional Attention Module (RAM) to guide the regression branch and mask branch to concentrate on the current vehicle (foreground) and suppress the occlusions caused by other vehicles with similar structure or color (background). Zhang et al.16 unified the DCNN with the part-based models into Compositional Convolutional Neural Networks (CompositionalNets), which enhanced the robustness of the model for partially occluded object detection.
Proposed method
In the complex traffic environments of cities, vehicles frequently encounter obstructions from various entities like buildings, trees, and pedestrians, and often obscure one another. Such occlusions will lead to serious degradation of the model performance and have a devastating impact on decision-making in real-world applications such as autonomous driving and intelligent transportation. In this section, we first introduce the overall architecture of the occluded vehicle detection network (YOLO-OVD). Subsequently, we elaborate on the proposed GOA module and the traditional feature Laplacian Pyramid to show how we address the occlusion problems in the vehicle detection task. Finally, we introduce a modified RepLoss to optimize YOLO-OVD to further improve the detection accuracy in dense vehicle scenes.
Overview of YOLO-OVD
The YOLO series, serving as a generic object detector, has achieved impressive outcomes across a range of benchmark tests (e.g. MS-COCO36, PASCALVOC37) for object detection. However, like most other generic object detectors, the YOLO series does not consider how to cope with object detection in intricate scenes, especially when occlusion occurs, and there are still many challenging issues that have not been addressed. When vehicles are occluded, the loss of key features and the blending of features from the occluding vehicles can diminish the detector’s ability to extract and learn features of the detected vehicles. Additionally, when occlusion between vehicles occurs, it leads to a high degree of overlap in the prediction frames, posing a challenge to the existing YOLO loss function and non-maximal suppression (NMS) strategies. In view of these, we propose a vehicle detection network based on YOLOv5s6, which aims to deal with occlusion cases effectively while maintaining accurate detection of unoccluded vehicles.

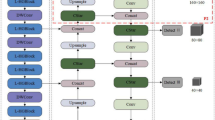
Overall architecture of YOLO-OVD. It consists of four parts: the GOA-CSP backbone network, the Laplacian Pyramid module, the Laplacian-Guided Feature Fusion network, and the detection head. GOA, which is our proposed grouped orthogonal attention, is integrated in the CSP layer to enhance the feature learning. Laplacian Pyramid Module is used to extract the Laplacian residual. CIoU-RepLoss compels the predicted bounding boxes to maintain a distance from the other ground truth boxes.
As shown in Fig. 2, the proposed network consists of four parts: the GOA-CSP backbone network, the Laplacian Pyramid module, the Laplacian-Guided Feature Fusion network, and detection head. Given an input image, it will go through two branches: the backbone network, which is responsible for extracting complex depth features of different scales from the image, and the Laplacian Pyramid module (LPM), which is responsible for extracting traditional handcrafted features of different scales from the image. To improve the feature extraction ability of our model and enable it to focus more on the unobstructed region, we introduce our designed GOA module in the CSP38 layer of the backbone network. After that, the Laplacian-Guided Feature Fusion network aggregates features from different scales of the backbone network and Laplacian Pyramid module. These aggregated features are further fused in the upstream aggregation path to generate a new feature pyramid, and then the feature maps of different scales are transmitted to the detection head. Finally, the detection head is used to generate the final bounding box with confidence score. In addition, we introduce CIoU-RepLoss into the network, which forces the prediction box away from the uncorrelated ground-truth boxes to enhance the robustness of the model to mutual vehicle occlusion.
Grouped orthogonal attention
The occlusion of irrelevant background will not only weaken the capacity of the network to extract the critical features of the vehicle, but also make the network pay more attention to the characteristics of the background objects, consequently degrading the model’s performance. We consider that even if a vehicle is not occluded by extraneous background, the models could still only perceive a portion of the vehicle in the image. To better cope with unrelated the challenges of extraneous background occlusion, we implement two strategies: enhancing the network’s capability for feature extraction and directing the network’s focus towards the vehicle’s unobscured regions. The attention mechanism is employed to boost the capability of identifying densely occluded objects while ensuring that the computational load remains manageable. Therefore, we design a novel grouped orthogonal attention (GOA) module based on Orthonet and add it to the residual position in the CSP layers of the network. The architecture and algorithmic process of the GOA module are depicted in Fig. 3 and Algorithm 1, respectively.

Illustration of grouped orthogonal attention. The module consists of five stages: 1. The input feature map X is uniformly grouped, with different numbers of groups at different depths; 2. Create orthogonal filters for these groups using the Gram-Schmidt orthogonalization method; 3. Extract the attention vectors for each group using the orthogonal filter and excitation, and then compute the weighted output features; 4. Merge the groups and shuffle the output channels; 5. Further enhance the outputs through a spatial attention module.
Attention mechanisms can enhance the representation of key features within the convolutional layers of a model. Orthonet suggests that the effectiveness of attention filters is primarily driven by the cosine orthogonality of the DCT kernel. Orthonet developed orthogonal filters to extract compressed vectors and employed the excitation proposed by SENet39 to obtain the attention vectors. The attention vectors are further multiplied with the input features to compute the weighted output features, and the residuals are added. \({{F}_{Ortho}}\) attention vector can be computed as follows:
where the function f(\(\cdot \)) denotes the filters initialization process, \({{F}_{Gram-Schmidt}}\) represents the application of the Gram-Schmidt process, Squeeze(\(\cdot \)) signifies the global pooling operation, \({\delta }\) indicates the ReLU activation function, \({\sigma }\) signifies the Sigmoid activation function, \({{W}_{1}}\) and \({{W}_{2}}\) are the weights of the fully connected layers, and \({\odot }\) represents the element-wise multiplication operation.

Grouped orthogonal attention.
However, as the network layers deepen, the number of feature channels increases, and the feature map size decreases, the quantity \(W \times H\) of orthogonal matrices that can be initialized for the feature map \(X\in {{R}^{C \times W \times H}}\) becomes less than the channel count C. Consequently, it is unfeasible to initialize a random filter that aligns with the dimensions of the feature map. To solve this issue, inspired by ShuffleNet40, we first perform grouping of the input feature X, subsequently applying orthogonal channel attention to each group separately (residuals and some convolution operations are discarded compared to Orthonet), followed by shuffling the output channels. Grouping lessens the computational effort while ensuring the number of initialized orthogonal matrices in deep layers, and shuffling facilitates the flow of information between feature channels. The channel attention vector of GOA can be computed as follows:
where \([{{F}^{1}}_{input}, {{F}^{2}}_{input}\ldots {{F}^{n}}_{input}]\) denotes n groups of the feature \({{F}_{input}}\in {{\mathbb {R}}^{h\text \!\!\times \!\!\text w\times c}}\), MLP stands for a parameter-shared multilayer perceptron, cat(\(\cdot \)) denotes concatenation along the channel dimension, and Shuffle(\(\cdot \)) represents channel shuffling.
Moreover, we also incorporate a spatial attention mechanism designed to direct the model’s focus toward the unobstructed region of the vehicle within the image. It helps the network discern fine details and relationships between elements, improving detection performance in cluttered environments. The architecture of spatial attention is shown in Fig. 4.

Illustration of spatial attention. The input feature undergoes a series of transformations through pooling, convolutional, and ReLU layers to derive the attention vector. The attention vector is then applied to the input features through element-wise multiplication to generate the final output.
Laplacian pyramid
Traditional features, designed by experienced experts based on well-established mathematical theories, possess strong interpretability and have achieved favorable results in many applications. However, existing deep learning-based object detection models overly and singularly rely on the features of deep networks, completely discarding traditional handcrafted features, which reduces the credibility of the model’s decisions. Recognizing the unique value of traditional handcrafted features and the superior representational capacity of deep features, we incorporate Laplacian Pyramid into the deep feature pyramid in YOLO-OVD to improve the model performance and convergence speed.

Illustration of Laplacian residuals, detailing sequential down-sampling and up-sampling to capture multi-scale representations.
The Laplacian Pyramid has been effectively applied in depth estimation24, and image restoration41, etc. Its ability to emphasize scale-space differences focuses on different details of the image at different scales, with low resolution focusing on the base texture information akin to the base layer (base layer), and high resolution focusing on finer texture specifics. First, the Laplacian residual is computed as shown in Fig. 5. The input image undergoes processing via the LPM to obtain the Laplacian residual \({{L}_{k}}\), where:
where k denotes the layer index in the Laplacian Pyramid. \({{I}_{k}}\) denotes the result of downsampling the input image and UP(\(\cdot \)) represents the upsampling operation. The Laplacian residual \({{L}_{k}}\) is the difference between the feature map \({{I}_{k}}\) at the current scale and the feature map \({{I}_{k+1}}\) at a smaller scale after upsampling. In this module, we consistently adopt bilinear interpolation to adjust the image size. After constructing the Laplacian Pyramid, we integrate it into the downstream aggregation path in the neck of the network as in Eq. (4).
where \({{L}_{3 \times W \times H}}\) denotes the output feature map of LPM, \({{X}_{C \times W \times H}}\) denotes the output feature map of backbone network, and \({{Conv}_{1\times 1}}\) denotes the convolution kernel size of 1x1 to adjust the number of channels.
CIoU-repulsion loss
When occlusion occurs between vehicles, it not only interferes with the respective feature extraction but also causes issues such as an imbalance between positive and negative samples, severe overlap of prediction frames resulting in regression difficulties, and inaccurate localization9,10,11,14,15. The GOA module shows effectiveness in dealing with vehicle inter-class occlusion, yet it is prone to situations such as imprecise localization when vehicles are dense and the occlusion situation is more intricate. Wang et al.10 experimentally validated that the object detector constructed with conventional loss functions have limitations in detecting occluded crowds and for the first time proposed RepLoss from the perspective of loss functions to address the issue of object density. RepLoss is driven by two motivations: the attraction of targets to the proposed bounding boxes and the repulsion exerted by surrounding targets on the proposals. RepLoss comprises three components:
where \({L}_{Attr}\) is the attraction term that forces the predicted bounding box to be close to its designated ground-truth box, and \({L}_{RepGT}\) and \({L}_{RepBox}\) are repulsion terms that forces the prediction bounding boxes away from the ground-truth box with the second-highest IoU and other prediction bounding boxes respectively. The coefficients \(\alpha \) and \(\beta \) balance the weights of the auxiliary losses.
Nevertheless, when objects are extremely dense and all predicted bounding boxes are very close to each other, \({L}_{RepBox}\) will force all the prediction bounding boxes to repel each other, resulting in significant computational costs and leading to deviations between the predicted results and the actual ground truth box positions. Likewise, \({L}_{RepGT}\) compels the prediction bounding box away from the target box with the second-highest IoU, potentially causing offset in the prediction boxes when the samples are overly dense. Given these, we partially refine RepLoss by substituting \(Smoot{{h}_{ln}}\)42 in \({L}_{RepGT}\) with CIoU43, a metric extensively used in YOLOv5, as shown in Eq. (6). The newly derived repulsion loss term \(L_{RepGT}^{CIoU}\) is combined with the loss function of YOLOv5 to jointly guide network learning.
where \({{P}^{+}}=\{P\}\) signifies the set of all positive samples. \(\bar{G}=\{G\}\) denotes the set of all ground truth frames. \({{B}^{P}}\) represents the prediction bounding boxes obtained after regression offset based on the proposal bounding box P. \(G_{Rep}^{P}\) is the ground-truth box with the maximum CIoU, excluding the box matched with P. \({{L}_{CIoU}}\) as shown below:
where b and \({{b}^{gt}}\) respectively denote the centroids of the prediction and ground-truth bounding boxes, and then the square of the Euclidean distance is calculated. c denotes the diagonal length of the minimum closure region of the prediction and true frames. In this work, we categorize all vehicles into a single class, thereby transforming it into a binary classification problem. Moreover, the regression loss goal of YOLOv5 is consistent with the \({{L}_{Attr}}\) item target of RepLoss, leading us to maintain YOLOv5’s regression loss. Finally, we discard the \({{L}_{RepBox}}\) term, which requires significant computational resources, to get our definitive loss function:
where \({{L}_{Box}}\) represents the bounding box regression loss, \(L_{RepGT}^{CIoU}\) represents the repulsion loss, \({{L}_{obj}}\) represents the confidence loss, and \({{L}_{cls}}\) represents the class loss. The coefficients \({\lambda }_{1}\), \({\lambda }_{2}\), \({\lambda }_{3}\) and \({\lambda }_{4}\) are the equilibrium loss weights, which are set to 0.15, 0.15, 1.0, 0.05 respectively. \({{L}_{Box}}\) is calculated utilizing CIoU loss, while \({{L}_{obj}}\) and \({{L}_{cls}}\) are computed using binary cross-entropy loss.
Experiments and discussion
OVD dataset
One of the current challenges in occluded vehicle detection is the scarcity of datasets of occluded vehicles in authentic traffic environments. Most of the currently available datasets are synthetic, which not only increase the training cost but also may not generalize well to real-world scenarios or adapt to the complexity of the occlusion problem when training models on such datasets4. Therefore, to train and evaluate the network we proposed, we establish an occluded vehicle detection dataset based on the UA-DETRAC dataset, named OVD (Occluded Vehicle Detection Dataset). UA-DETRAC stands out as a challenging large-scale dataset for real-world vehicle detection and tracking, which was mainly captured on road overpasses in Beijing and Tianjin and manually annotated with 8250 vehicles and 1.21 million object boxes. However, directly applying UA-DETRAC to our task suffers from the following drawbacks: (1) The UA-DETRAC dataset is a video sequence frame dataset with short inter-frame intervals, resulting in image redundancy; (2) The dataset contains instances of duplicate annotations; (3) A majority of the images lack scenarios with vehicle occlusion; (4) The annotations contain numerous invalid vehicles that are completely occluded; (5) Vehicles occluded by other objects or situated at the image periphery (which can also be considered as occluded) are frequently unlabeled. To address these issues, we employ methods including IoU filtering and manual annotation, resulting in a refined OVD dataset. Specifically, we retain one image every ten frames, discarding those without occlusion objects or where objects are completely obscured. Furthermore, we have meticulously annotated all instances of occluded vehicles within the UA-DETRAC dataset.

Examples of different scenarios in the OVD dataset (right) compared with the initial dataset (left). The red boxes indicate the original annotations, the green boxes represent the newly annotated vehicles, and the orange dashed boxes denote the discarded annotations.
Our OVD dataset consists of 8677 images of vehicles in intricate traffic scenarios, with each image abundant in instances of vehicles occluding each other and being occluded by other objects. Fig. 6 displays two typical image examples in the OVD dataset, each of which contains three cases: no occlusion, intra-class occlusion, and inter-class occlusion.
Implementation details
The proposed YOLO-OVD operates on a Linux system using the PyTorch framework, with a software configuration that included CUDA 10.2, Python 3.9, and PyTorch 1.9.1. Hardware specifications include an Intel(R) Xeon(R) CPU E5-2620 v4 2.10GHz with 32GB RAM and an NVIDIA TITAN RTX GPU boasting 24GB of memory. For model optimization, we employ the stochastic gradient descent (SGD) optimizer with a mini-batch size of 8, where the momentum parameter and weight decay are set to 0.937 and 0.0005, respectively. The total number of learning epochs and the initial learning rate are set to 100 and 0.01, respectively. To accelerate the convergence speed of the model, we utilized transfer learning with MSCOCO pre-trained weights. In addition, the input size is 640 with a stride of 32. Especially, we disable data augmentation techniques like Mosaic and Mixup44 before training, as they could potentially impair the model’s performance. The performance of the baseline YOLOv5 and our model, with data augmentation both enabled and disabled, is compared and presented in Table 1. Data augmentation increases sample diversity, thereby generally enhancing model recall and generalization capabilities. However, in our specific experiments, we observe that certain data augmentation techniques might alter the natural occlusion structures of objects. This alteration could introduce noise into the learning process, potentially affecting some performance metrics such as accuracy.
Comparison with state-of-the-arts
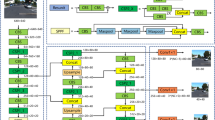
To assess the performance of YOLO-OVD, we employ four widely recognized metrics in the field of object detection, namely precision P, recall R, [email protected], and [email protected]:0.95, as denoted in previous work45. The proposed YOLO-OVD is compared with 14 state-of-the-art (SOTA) object detection methods and methods specifically designed for occluded object detection, including Faster R-CNN26, Spare R-CNN46, Retinanet47, YOLOv348, YOLOv449, YOLOv56, OD-UTDNet50, PP-YOLOv251, PP-YOLOE52, YOLOv77, YOLOv8, and DINO53. Detailed results are reported in Table 2. Observations indicate that, compared to these state-of-the-art (SOTA) methods, the proposed YOLO-OVD achieves optimal performance with 0.791 precision (P), 0.760 [email protected], and 0.615 [email protected]:0.95, at the cost of a slight reduction in recall. Additionally, its number of parameters ranks among the best in comparison with the selected methods.
To further intuitively evaluate the effectiveness of YOLO-OVD in intricate traffic scenes, we experiment our method and others under two representative traffic scenarios, each containing three cases: no occlusion, inter-class occlusion, and intra-class occlusion. The comparative visualizations of the detection outcomes are illustrated in Figs. 7 and 8 .

Detection results of YOLO-OVD with other best-performing 7 methods in a traffic scenario rich in intra-class occlusion. It is evident that our detector outperforms other competitors, achieving the best detection results. The other detectors exhibited varying degrees of missed detections, with some even failing to detect unoccluded vehicles.

Detection results of YOLO-OVD with other best-performing 7 methods in a traffic scenario rich in inter-class occlusion. Our method and YOLOv7 outperform other competitors, with ours showing higher confidence and reliability.

Visualization of the original image and three detection head features in different scenarios. (a) Original Image. (b) Attention maps of Large-scale detection head. (c) Attention maps of Medium-scale detection head. (d) Attention maps of Small-scale detection head.

Detection results of YOLO-OVD, Faster R-CNN, PP-YOLOE, and YOLOv7 in dense scenes. The Faster R-CNN suffers from significant leakage and misdetection, while PP-YOLOE and YOLOv7 display notable missed detections. In contrast, our method is able to handle severely congested situations effectively.
As shown in Figs. 7 and 8, compared to our method, most detectors can somewhat overcome occlusion but are more susceptible to missed detections, with some even failing to detect vehicles that are unoccluded. Additionally, YOLOv7 shows performance closely aligned with our model, but ours exhibits higher confidence and fewer parameters. Since the integration of our GOA and LPM modules into YOLO-OVD boosts its feature extraction capabilities, focusing more on unoccluded regions, thereby lessening the impact of occlusions on detection precision. It can also be seen from the activation maps visualized in Fig. 9 that YOLO-OVD exhibits heightened attention to areas of occlusion, featuring distinctly clearer regions of activation and sharper activation boundaries, thereby enhancing precision in the subsequent steps of localization and recognition. As a result, our YOLO-OVD demonstrates better performance in detecting occluded vehicles.
Furthermore, there has been a significant rise in the number of vehicles on the roads recently, leading to increasingly challenging and congested traffic environments. To further delve the capability of YOLO-OVD, we pick the top three methods, namely Faster R-CNN, PP-YOLOE, and YOLOv7, based on the visualization results in Figs. 7 and 8, and test them alongside ours in two more complicated and jammed traffic situations. The detection results are depicted in Fig. 10.
As observed in Fig. 10, in the case of heavily crowded vehicles, Faster R-CNN suffers from significant leakage and misdetection, while PP-YOLOE and YOLOv7 both had a certain degree of missed detections. Compared to these state-of-the-art detectors, the YOLO-OVD adapts better to such congested scenarios, capable of detecting the majority of the vehicles we aim to identify, with higher confidence. This indicates that our model maintains strong performance even in dense traffic situations.
Ablation study
In this subsection, we execute a stepwise ablation study to further substantiate the effectiveness of our proposed method and the efficiency of the proposed modules, including the GOA module, LPM, and \(L_{RepGT}^{CIoU}\) loss. Starting with the original YOLOv5s as our baseline, we incrementally integrate each of the three modules into the baseline model as:
To ensure fairness, all models are trained for 100 epochs with the same hyperparameter settings, and identical evaluation metrics are used for performance assessment. The detailed performance of these variants is comprehensively documented in Table 3.
As observed in Table 3, our full model (V4) surpasses other schemes and each of our modules makes a significant contribution to the occluded vehicle detection task. The addition of GOA to YOLOv5s significantly increased P and [email protected] by 3.2% and 2.3%, respectively, at the expense of a slight decrease in recall and [email protected]:0.95. After further incorporating the LPM module on top of GOA, the situation refined, and the network performance was further improved. Ultimately, our final network consisting of all modules yields the optimal detection performance, indicating that the three modules are complementary.

The convergence process of YOLOv5 with and without LPM. (a) Loss values for the training process, (b) Loss values for the validation process.
Additionally, to confirm that the handcrafted knowledge Laplacian Pyramid can significantly elevate the model’s performance and convergence, we undertake comparative evaluations of regression loss values across the training and validation process. The detailed experimental outcomes are illustrated in Fig. 11. It can be observed that the red curve converges to a lower loss value faster than the blue curve, particularly in the initial stages of training, and is smoother, reflecting a more stable convergence process. Furthermore, LPM module boosts the model’s performance with negligible additional parameters and computational demand.
Finally, Table 3 reveals that the GOA module makes a considerable contribution to the network performance, and in order to further evaluate the advantages of GOA, we carry out an ablation study comparing it with other prevalent attention mechanisms, including SE39, CBAM54, CA55, and EMA56. The detailed performance results are presented in Table 4. CA, EMA, and GOA exhibited superior performance, with GOA demonstrating more pronounced comprehensive benefits, particularly enhancing the precise detection of vehicles in complicated traffic scenarios.
Conclusion
In this work, we propose a network tailored for detecting occluded vehicles, which was trained and validated on a real-world vehicle detection dataset abundant in occlusion cases that we have established. To effectively tackle occlusion challenges in vehicle detection tasks, we design a GOA module to enhance the network’s feature extraction capacity. Moreover, the integration of the traditional feature of the Laplacian Pyramid serves to augment the network’s feature output and facilitate faster convergence. In addition, the \(L_{RepGT}^{CIoU}\) loss is introduced to enhance the network’s precision in localizing vehicles in dense scenes. Finally, we conduct extensive comparative experiments and ablation experiments to prove the effectiveness of our proposed network, showing that YOLO-OVD performs favorably against 14 representative SOTA algorithms. In the future work, we intend to concentrate on vehicle detection from drone perspectives, which encompasses challenging scenarios including small-scale targets, occlusions, and low-contrast environments. This concentration not only addresses the intricacies of aerial image interpretation but also strives to advance detection accuracy under diverse operational conditions. By tackling these complexities, we aim to significantly improve the reliability and robustness of UAV-based surveillance and monitoring systems.
Data availibility
The datasets generated during and/or analysed during the current study are available at https://github.com/LittleGrey-hjp/OVD.
References
Hoanh, N. & Pham, T. V. A multi-task framework for car detection from high-resolution uav imagery focusing on road regions. IEEE Trans. Intell. Transp. Syst.[SPACE]https://doi.org/10.1109/TITS.2024.3432761 (2024).
Ashraf, K., Varadarajan, V., Rahman, M. R., Walden, R. & Ashok, A. See-through a vehicle: Augmenting road safety information using visual perception and camera communication in vehicles. IEEE Trans. Veh. Technol. 70(4), 3071–3086 (2021).
Zheng, Z., Li, X., Xu, Q. & Song, X. Deep inference networks for reliable vehicle lateral position estimation in congested urban environments. IEEE Trans. Image Process. 30, 8368–8383 (2021).
Saleh, K., Szénási, S. & Vámossy, Z. Occlusion handling in generic object detection: A review. In IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), 000477–000484 (IEEE, 2021).
Chattopadhay, A., Sarkar, A., Howlader, P. & Balasubramanian, V. N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), 839–847 (IEEE, 2018).
Jocher, G., Chaurasia, A., Stoken, A., Borovec, J., Kwon, Y., Michael, K., Fang, J., Wong, C., Yifu, Z., Montes, D. et al. ultralytics/yolov5: v6.2-yolov5 classification models, apple m1, reproducibility, clearml and deci. ai integrations, Zenodo (2022).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7464–7475 (2023).
Chen, J. et al. A new method based on YOLOv5 and multiscale data augmentation for visual inspection in substation. Sci. Rep. 14, 9362. https://doi.org/10.1038/s41598-024-60126-2 (2024).
Zhan, G., Xie, W. & Zisserman, A. A tri-layer plugin to improve occluded detection. Preprint at http://arxiv.org/abs/2210.10046 (2022).
Wang, X., Xiao, T., Jiang, Y., Shao, S., Sun, J. & Shen, C. Repulsion loss: Detecting pedestrians in a crowd. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7774–7783 (2018).
Huang, X., Ge, Z., Jie, Z. & Yoshie, O. Nms by representative region: Towards crowded pedestrian detection by proposal pairing. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10750–10759 (2020).
Wang, Q., Xu, N., Huang, B. & Wang, G. Part-aware refinement network for occlusion vehicle detection. Electronics 11(9), 1375 (2022).
Zhang, K., Xiong, F., Sun, P., Hu, L., Li, B. & Yu, G. Double anchor r-cnn for human detection in a crowd. Preprint at http://arxiv.org/abs/1909.09998 (2019).
Zhang, S., Wen, L., Bian, X., Lei, Z. & Li, S. Z. Occlusion-aware r-cnn: Detecting pedestrians in a crowd. In Proc. of the European Conference on Computer Vision (ECCV), pp. 637–653 (2018).
Li, X. et al. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural. Inf. Process. Syst. 33, 21002–21012 (2020).
Kortylewski, A., Liu, Q., Wang, A., Sun, Y. & Yuille, A. Compositional convolutional neural networks: A robust and interpretable model for object recognition under occlusion. Int. J. Comput. Vis. 129, 736–760 (2021).
Stone, A. et al. Teaching compositionality to cnns. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR) 2017, 732–741. https://doi.org/10.1109/CVPR.2017.85 (2017).
Salman, H., Parks, C., Swan, M. & Gauch, J. Orthonets: Orthogonal channel attention networksIn 2023 IEEE International Conference on Big Data (BigData), pp. 829–837 (IEEE, 2023).
Wen, L. et al. Ua-detrac: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 193, 102907. https://doi.org/10.1016/j.cviu.2020.102907 (2020).
Bai, X., Yang, X. & Latecki, L. J. Detection and recognition of contour parts based on shape similarity. Pattern Recognit. 41(7), 2189–2199 (2008).
Bay, H., Ess, A., Tuytelaars, T. & Van Gool, L. Speeded-up robust features (surf). Comput. Vis. Image Underst. 110(3), 346–359 (2008).
Felzenszwalb, P., McAllester, D. & Ramanan, D. A discriminatively trained, multiscale, deformable part model. In 2008 IEEE Conference on Computer Vision and Pattern Recognition, 1–8 (IEEE, 2008).
Wang, H., Cai, Y., Chen, X. & Chen, L. Occluded vehicle detection with local connected deep model. Multimed. Tools Appl. 75, 9277–9293 (2016).
Song, M., Lim, S. & Kim, W. Monocular depth estimation using Laplacian pyramid-based depth residuals. IEEE Trans. Circuits Syst. Video Technol. 31(11), 4381–4393 (2021).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587 (2014).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2016).
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, A. C. Berg, Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, pp. 21–37 (Springer, 2016).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788 (2016).
Ying, Z. et al. Large-scale high-altitude uav-based vehicle detection via pyramid dual pooling attention path aggregation network. IEEE Trans. Intell. Transp. Syst.[SPACE]https://doi.org/10.1109/TITS.2024.3396915 (2024).
Su, Y., Sun, R., Shu, X., Zhang, Y. & Wu, Q. Occlusion-aware detection and re-id calibrated network for multi-object tracking, https://arXiv abs/2308.15795, https://api.semanticscholar.org/CorpusID:261339644 (2023).
Luo, J., Fang, H., Shao, F., Hu, C. & Meng, F. Vehicle detection in congested traffic based on simplified weighted dual-path feature pyramid network with guided anchoring. IEEE Access 9, 53219–53231 (2021).
Zou, T., Yang, S., Zhang, Y. & Ye, M. Attention guided neural network models for occluded pedestrian detection. Pattern Recognit. Lett. 131, 91–97 (2020).
Zhan, G., Xie, W. & Zisserman, A. A tri-layer plugin to improve occluded detection. In BMVC (2022).
Zhang, S., Wen, L., Bian, X., Lei, Z. & Li, S. Z. Occlusion-aware r-cnn: Detecting pedestrians in a crowd. In textitProc. of the European Conference on Computer Vision (ECCV), pp. 637–653 (2018).
Zhang, W., Liu, C., Chang, F. & Song, Y. Multi-scale and occlusion aware network for vehicle detection and segmentation on uav aerial images. Remote Sens.[SPACE]https://doi.org/10.3390/rs12111760 (2020).
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P. & Zitnick, C. L. Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, Springer, pp. 740–755 (2014).
Everingham, M., Van Gool, L., Williams, C. K., Winn, J. & Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 88, 303–338 (2010).
Wang, C.-Y., Liao, H.-Y. M., Wu, Y.-H., Chen, P.-Y., Hsieh, J.-W. & Yeh, I.-H. Cspnet: A new backbone that can enhance learning capability of cnn. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 390–391 (2020).
Shu, X., Yang, J., Yan, R. & Song, Y. Expansion-squeeze-excitation fusion network for elderly activity recognition. IEEE Trans. Circuits Syst. Video Technol. 32(8), 5281–5292 (2022).
Zhang, X., Zhou, X., Lin, M. & Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6848–6856 (2018).
Paris, S., Hasinoff, S. W. & Kautz, J. Local laplacian filters: Edge-aware image processing with a Laplacian pyramid. Commun. ACM 58(3), 81–91. https://doi.org/10.1145/2723694 (2015).
Girshick, R. Fast r-cnn. In Proc. of the IEEE International Conference on Computer Vision, 1440-1448 (2015).
Zheng, Z. et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 52(8), 8574–8586. https://doi.org/10.1109/TCYB.2021.3095305 (2022).
Zhang, H., Cisse, M., Dauphin, Y. N. & Lopez-Paz, D. mixup: Beyond empirical risk minimization. In: International Conference on Learning Representations, https://openreview.net/forum?id=r1Ddp1-Rb (2018).
Liu, B.-Y., Chen, H.-X., Huang, Z., Liu, X. & Yang, Y.-Z. Zoominnet: A novel small object detector in drone images with cross-scale knowledge distillation. Remote Sens.[SPACE]https://doi.org/10.3390/rs13061198 (2021).
Sun, P. et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14449–14458. https://doi.org/10.1109/CVPR46437.2021.01422 (2021).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 318–327. https://doi.org/10.1109/TPAMI.2018.2858826 (2020).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement, http://arxiv.org/1804.02767 https://api.semanticscholar.org/CorpusID:4714433 (2018).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. Preprint at http://arxiv.org/abs/2004.10934 (2020).
Wang, Y. et al. Detecting occluded and dense trees in urban terrestrial views with a high-quality tree detection dataset. IEEE Trans. Geosci. Remote Sens. 60, 1–12 (2022).
Huang, X., Wang, X., Lv, W., Bai, X., Long, X., Deng, K., Dang, Q., Han, S., Liu, Q., Hu, X. et al. Pp-yolov2: A practical object detector. Preprint at http://arxiv.org/abs/2104.10419 (2021).
Xu, S., Wang, X., Lv, W., Chang, Q., Cui, C., Deng, K., Wang, G., Dang, Q., Wei, S., Du, Y. et al. Pp-yoloe: An evolved version of yolo. Preprint at http://arxiv.org/abs/2203.16250 (2022).
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M. & Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. Preprint at http://arxiv.org/abs/2203.03605 (2022).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proc. of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018).
Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13713–13722 (2021).
Li, X., Zhong, Z., Wu, J., Yang, Y., Lin, Z. & Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proc. of the IEEE/CVF International Conference on Computer Vision, pp. 9167–9176 (2019).
Funding
The research is supported by ’YangFan’ major project (No.[2020]05) from Guangdong Province of China.
Author information
Authors and Affiliations
Contributions
Jinpeng He: Conceptualization, Methodology, software, Writing - original draft; Huaixin Chen: Funding acquisition, Supervision; Biyuan Liu: Formal analysis, Writing - review &editing; Sijie Luo: Validation, Writing - review& editing; Jie Liu: Investigation, Resources.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
He, J., Chen, H., Liu, B. et al. Enhancing YOLO for occluded vehicle detection with grouped orthogonal attention and dense object repulsion. Sci Rep 14, 19650 (2024). https://doi.org/10.1038/s41598-024-70695-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-70695-x
Keywords
This article is cited by
-
AquaYOLO: Advanced YOLO-based fish detection for optimized aquaculture pond monitoring
Scientific Reports (2025)
