
Abstract
With the wave of artificial intelligence sweeping the world in recent years, UAVs is widely used in various fields. UAV path planning has attracted much attention from scientists as an essential part of UAV work. In order to design an efficient and reasonable 3D UAV path planning program, recent researchers have invented and improved many algorithms. This paper proposes an elite RIME algorithm for 3D UAV path planning. First, we propose an elite reverse learning population selection strategy based on piecewise mapping to enhance the population diversity of the algorithm for better exploration. Second, this paper proposes a stochastic factor-controlled elite pool exploration strategy so that the algorithm is difficult to enter the local optimum and can better explore the global optimum. Then, this paper proposes a hard frost puncture exploitation strategy based on the sine–cosine function so that the algorithm can find the global optimum faster during the exploitation process. Meanwhile, in order to test the performance of the algorithm proposed in this paper, we compare it with 13 other intelligent optimization algorithms that are classical and popular nowadays on 52 test functions in three test sets, CEC2017, CEC2020, and CEC2022, and obtain competitive results. Finally, we applied it to the 3D UAV path planning problem in three different terrain scenarios, and the ELRIME algorithm achieved good results in all of them. Especially in the 7-peak model, the ELRIME algorithm improves the performance of the RIME algorithm by a factor of two. In the 9-peak model, the average value aspect also reduce the cost by 91 compared to the RIME algorithm, and more importantly, it has the smallest fluctuation in 30 runs, which is among the most stable of all the compared algorithms. In the 12-peak model, its stability is also significantly enhanced, and in terms of worst-case cost, it improves the cost by 340 compared to RIME.
Similar content being viewed by others

Introduction
With the rapid development of artificial intelligence technology, UAVs are widely used in various fields (including aerial photography1 and filming, intelligent agriculture2, logistics and transportation, construction and infrastructure, scientific research and environmental monitoring3, and communication and networking) because of their strong survivability and good maneuverability. UAV path planning technology is one of the core technologies in the field of UAVs, which concerns the efficiency and safety of UAVs performing tasks in various application scenarios4. 3D UAV path planning refers to planning a 3D optimal path in a specified 3D area so that the UAV can reach its destination quickly and safely. Designing an efficient and reasonable UAV path planning scheme can ensure that the UAV effectively avoids various threatening areas and reaches the destination smoothly when performing the mission5. In short, UAV path planning is to plan one or more practically flyable routes from the starting point to the target point under the constraints of satisfying the UAV's performance and various threats. Generally, the planned path should be optimal, avoiding threats as much as possible, while the path cost should be minimized. Therefore, it is of great significance to research 3D UAV path planning6.
In order to perform path planning for UAVs in 3D environments, traditional path planning algorithms are often overwhelmed. Swarm intelligence algorithms, as heuristic methods that simulates collective behaviors in nature, show great promise in addressing 3D path planning for UAVs. The optimal solution of the objective function is found by simulating the behavior of natural groups such as flocks of birds, schools of fish and eagles so that the members of the group are highly cooperative. These algorithms constructed based on intuition or experience that gives an optimal or near-optimal solution to the problem in an acceptable time and space7. The core of this class of algorithms is exploration and exploitation. Since the optimal solution may exist anywhere in the entire search space, exploration involves searching as much of the search space as possible to find the globally optimal solution and avoid the algorithm converging to a local optimum. Exploitation refers to finding the optimal solution as quickly as possible by utilizing as much valid information as possible.
In most cases, there tends to be some correlation between the local optimal solution and the global optimal solution, and using these correlations to adjust the initial solution gradually, one can slowly search from the initial solution to the optimal solution. Metaheuristic algorithms aim to balance exploration and exploitation as much as possible. Therefore, our improved algorithm adjusts the "exploration" and "exploitation" of the original algorithm to give it better performance in solving optimization problems.
The algorithm proposed in this paper belongs to swarm intelligence algorithms so the following section will focus on these algorithms. Swarm intelligence algorithms are biologically inspired algorithms created by studying individuals' characteristics and their relationship with the group and the corresponding mechanisms8. It is an emerging field and an Artificial Intelligence (AI) component. Swarm intelligence algorithms can be an organic combination of evolutionary computation, artificial neural networks (ANNs), and fuzzy systems in various computational intelligence (CI) approaches9. They are nature-inspired methods for dealing with complex optimization problems where mathematical or traditional methods may not be effective10. This ineffectiveness is mainly due to the extreme complexity of the mathematical reasoning process, possible uncertainties, or inherent stochastic processes. Among heuristic algorithms, in addition to the intelligent population-based optimization algorithms that are the focus of this paper, some heuristics are inspired by natural evolution11, physical rules, and human behavior. Figure 1 illustrates some heuristic algorithms that are widely and hotly debated nowadays.

Some of the current popular heuristic algorithms.
In recent years, more and more population intelligence algorithms have been proposed because meta-heuristic algorithms have shown better results in solving problems in different fields, such as Ant Colony Optimization (ACO)12, Particle Swarm Optimization (PSO)13, Artificial Fish School (AFS)14, Bacterial Foraging Optimization (BFO)15, Artificial Bee Colony (ABC)16, Grey Wolf Optimizer(GWO)17, Bat Algorithm (BA)18, Nutcracker optimizer algorithm (NOA)19, Sea-horse optimizer (SHO)20, Spider wasp optimizer (SWO)21 and Zebra Optimization Algorithm (ZOA)22. However, the NFL (No Free Lunch)23 theorem states that no algorithm can perform well on all problems. While each algorithm has its strengths, it is also bound to have weaknesses. This motivates us to develop new algorithms and improve old ones to find the "optimal" algorithm to solve real-world problems.
The rime optimization algorithm (RIME) was proposed by Hang Su et al. in 202324. It is a heuristic optimization algorithm based on the formation process of freezing ice. It implements the exploration and exploitation behaviors in the optimization method by simulating frost's soft and hard rime growth process and constructing a soft rime search strategy and a hard rime puncture mechanism. The greedy selection mechanism in the algorithm is also improved to update the population in the optimal solution selection stage. However, in specific experiments, we found that the RIME algorithm has shortcomings, such as quickly falling into local optimum, and the exploration and exploitation phases cannot be well balanced.
To address the above shortcomings, this paper improves the original RIME algorithm using three strategies to obtain a novel algorithm called ELRIME. By comparing the other 13 contemporary classic and latest algorithms on 52 test functions on three test sets, CEC2017, CEC2020, and CEC2022, the results show that the algorithm proposed in this paper has faster convergence speed, higher convergence accuracy, better ability to escape local optima, and better performance compared with the original RIME algorithm. Finally, applications in 3D UAV path planning also prove that the ELRIME algorithm proposed in this paper has a significant advantage in solving practical problems and is strongly competitive compared with other algorithms.
A novel Elite Rime Optimization Algorithm (ELRIME) is proposed based on the Rime Optimization Algorithm (RIME), and the main contributions of this paper are as follows:
-
1.
An elite reverse learning population selection strategy based on Piecewise mapping is introduced to enhance the algorithm's performance by constructing diverse populations and selecting elite individuals for exploration and exploitation.
-
2.
A stochastic factor-controlled elite pool exploration strategy is proposed, which can more effectively prevent the algorithm from falling into a local optimum to improve its performance.
-
3.
A hard frost puncture exploitation mechanism based on the sine–cosine function is proposed to make the algorithm more effective in utilizing information, such as the current optimal solution, and to approach the global optimal solution faster.
-
4.
Fifty-two test functions validated the performance of ELRIME in three test sets: CEC2017, CEC2020, and CEC2022.
-
5.
The effectiveness and accuracy of the ELRIME algorithm proposed in this paper in solving practical problems are verified by solving the 3D UAV path planning problem.
The rest of the paper is organized as follows. Section "Related work" summarizes the related work of this paper. Section "Technical background" presents the technical background related to this paper. In Section "Experimental results and detailed analyses", we conduct corresponding experiments and analyze the experimental results. Section "ELRIME algorithm for 3D UAV path planning" applies the ELRIME algorithm proposed in this paper to 3D UAV path planning, and demonstrates that ELRIME achieves performance improvement based on RIME and has wide applicability. Finally, Section "Conclusion and prospects" summarizes and gives an outlook.
Related work
In recent years, swarm intelligence algorithms have been widely used in various fields such as path planning, cloud resource scheduling, engineering design problems, and feature selection. Dehghani, Mohammad et al. proposed a swarm-based algorithm called Northern Goshawk Optimization25, which models the behavior of the Northern Goshawk by simulating its hunting process for use in solving optimization problems. Zandavi, Seid Miad et al. proposed a novel stochastic dual simplex algorithm that utilizes a stochastic approach based on the simplex technique to obtain the optimal point and randomly distributes a dual simplex in the search space to find the best optimal point26. Moreover, the simplex complexes share the best and worst vertices with each other to improve the optimality of particles in the search space. Pozna, Claudiu et al. obtained a hybrid metaheuristic optimization algorithm by combining particle filtering with particle swarm optimization27. The optimization is performed by randomly generating particle swarms and scaling the search ___domain, which can be applied to fuzzy control systems to reduce energy consumption. Deng, Wu et al. proposed an enhanced MSIQDE algorithm based on hybrid multiple strategies28. It achieves optimal solutions by designing a new multiple population mutation evolution mechanism to ensure the relative independence and diversity of each subpopulation and by adopting a feasible solution space transformation strategy that maps quantum chromosomes from the unit space to the solution space. Zhu, Donglin et al. proposed an improved bare-bone particle swarm algorithm that initially uses dynamic lens-based contrastive learning to initialize the population and improve diversity29; designs an evolutionary strategy based on signal-to-noise distance to balance exploration and exploitation; and finally utilizes an ecological niche crowding invasive weed optimization algorithm to eliminate low-quality solutions and improve search efficiency. Priyadarshi, Neeraj et al. proposed a hybrid whale optimization algorithm with differential evolution that combines the exploitation capabilities of the whale optimization algorithm with the exploratory behavior of differential evolution to improve the tracking capabilities of whales in both stable and dynamic operating environments30. To allocate resources in 5G MEC networks, Laboni, Nadia Motalib et al. proposed a hyper-heuristic approach31. The proposed AWSH algorithm operates at a higher level, while the ant colony algorithm, whale optimization algorithm, positive cosine algorithm, and Henry gas solubility optimization algorithm work at a lower level to efficiently capture dynamically varying environmental parameters for solving the resource allocation problem.
In addition, Shi et al. proposed an improved frost-ice optimization algorithm for optimizing PV models32. It combines the Nelder-Mead simplex with the environmental stochastic interaction strategy and uses the stochastic mutual strategy as a complementary mechanism to enhance the spatial exploration ability of the solution, improving the algorithm's efficiency in performing a global search by facilitating external interactions and preventing it from falling into local optima. It also enhances the algorithm's local search capability by integrating Nelder-Mead simplexes, thereby improving its spatial search. Ruba Abu Khurma et al. proposed a binary adaptation of RIME to address the unique challenges posed by the feature selection problem33. They demonstrated on four different types of transfer functions as well as on the CEC2017 test set that the proposed state-of-the-art RIME algorithm exhibits excellent performance in global optimization and feature selection tasks. For the 3D path planning problem of unmanned surface vehicles, Gu et al. proposed a multi-strategy improved frost-ice optimization algorithm. It first utilizes Tent chaotic mapping to initialize the population and lay the foundation for later global optimization34; then utilizes adaptive updating strategies based on leadership and dynamic center of mass to guide the population in a more favorable direction; and finally utilizes oppositely based lens imaging control strategies to enhance population diversity and ensure convergence accuracy. Mahmoud Abdel-Salam et al. proposed an adaptive chaotic version of RIME for solving the feature selection problem35. Its use of intelligent population initialization with chaotic maps, a novel adaptive modification of symbiotic organisms to search for symbiotic phases, a novel hybrid mutation strategy, and a restart strategy improves population diversity and allows the algorithm to balance exploration and exploitation.
These various swarm intelligence algorithms have proved to be of significant research value. Especially in recent years, swarm intelligence algorithms have grown exponentially and many high-performance algorithms have emerged. Table 1 summarizes the literature in related work on algorithms that have achieved varying degrees of success in solving different optimization problems.
Technical background
To facilitate the reader's understanding, this section begins with a brief introduction to the original RIME algorithm, including its initialization, exploration, and exploitation strategy. Then, we focus on the ELRIME algorithm proposed in this paper and analyze its overall time complexity.
Rime optimization algorithm (RIME)
Since the algorithm proposed in this paper is an improvement on the RIME algorithm, this section briefly introduces the inspiration of RIME, its mathematical model, and the corresponding algorithmic principles.
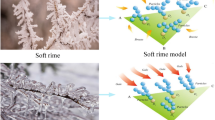
RIME is an icy deposit formed by uncondensed water vapor in the air that freezes at low temperatures and adheres to objects such as tree branches. Its growth process is influenced by temperature, wind speed, humidity, and airflow, and the rime formed under different conditions varies. Environmental factors and growth modes will limit the growth of rime; once a relatively stable state is reached, rime will stop growing. The growth of rime is mainly divided into two types: soft rime and hard rime; the difference mainly lies in the formation process influenced by wind speed. Soft rime is primarily generated in a breeze environment; its growth is slow and random. Hard rime is formed in a windy environment, and its growth speed is fast and almost unidirectional. The growth mechanism of rime also inspires the RIME algorithm, which constructs the exploration strategy by simulating the movement of soft rime particles. In addition, the crossover behavior of complex fog intelligence is simulated to construct the exploitation strategy. Finally, a greedy selection mechanism is proposed to enhance the algorithm's performance.
In order to simulate the growth mechanism of rime, RIME modeled the growth process of each rime bar by analyzing the effects of wind speed, freezing coefficient, the cross-sectional area of the attached material, and growth time. Modeling the kinematic behavior of each rime particle simulates the kinematic process by which each freezing fog particle agglomerates to form a freezing agent and ultimately generates frost as a bar crystal. RIME consists of four phases: initialization of the fog clusters, the proposed soft fog search strategy, the proposed hard rime punching mechanism, and the improvement of the greedy selection mechanism. The four phases of the rime algorithm are briefly described below.
Rime cluster initialization
In the RIME algorithm, each rime is considered the population of the algorithm, and the rime population formed by all agents is regarded as the population of the algorithm. First, the entire rime population is initialized. It consists of a rime-agent, and each rime-agent consists of \(d\) rime particles. The rime agent is shown in Eq. (1), and the rime population is shown in Eq. (2).
where \({S}_{i}\) is the ordinal number of the rime agent and \(R\) is the ordinal number of the rime particle.
Soft-rime search strategy
In a windy environment, the growth of soft rime is highly randomized, and the rime particles can freely cover most of the surface of the attached object while growing slowly in the same direction. Inspired by the growth of soft rime, the RIME algorithm proposes a soft rime search strategy, which is based on the five motion characteristics of the rime particles. The condensation process of each particle is simulated, and the position of the rime particles is calculated, as shown in Eq. (3).
where, \({R}_{ij}^{new}\) is the new position of the updated particle, and \(i\) and \(j\) denote the \(j\)-th particle of the \(i\)-th rime-agent. \({R}_{best,j}\) is the \(j\)-th particle of the best rime-agent in the rime-population \(R\). The parameter \({r}_{1}\) is a random number in the range (− 1,1) and \({r}_{1}\) controls the direction of particle movement together with \(\text{cos}\theta\) will change following the number of iterations, as shown in Eq. (4). \(\beta\) is the environmental factor, which follows the number of iterations to simulate the influence of the external environment and is used to ensure the convergence of the algorithm, as shown in Eq. (5). \(h\) is the degree of adhesion, which is a random number in the range (0,1), and is used to control the distance between the centers of two rime-particles. \({Ub}_{ij}\) and \({Lb}_{ij}\) are the upper and lower bounds of the escape space, respectively, which limit the effective region of particle motion. \(E\) is the coefficient of being attached, which affects the condensation probability of an agent and increases with the number of iterations, as shown in Eq. (6). \({r}_{2}\) is a random number in the range \((\text{0,1})\), which, together with \(E\), controls whether the particles condense, i.e., whether the particle positions are updated.
where \(t\) is the current number of iterations and \(T\) is the maximum number of iterations of the algorithm.
where the mathematical model of \(\beta\) is the step function, it denotes rounding; \(w\) is a constant 5, which is used to control the number of segments of the step function.
Hard-rime puncture mechanism
Under strong wind conditions, the growth of hard rime is more straightforward and regular compared to soft rime. When the freezing particles condense into hard rime, each rime agent can easily cross due to the same growth direction; this phenomenon is called rime puncture. The phenomenon of puncture inspires the RIME algorithm. It proposes a Hard-Rime puncture mechanism, which can be used to update the policy between agents so that the algorithm's particles can be exchanged, thereby improving the algorithm's convergence and its ability to escape local optima. The formula for replacement between particles is shown in Eq. (7).
where \({R}_{ij}^{new}\) is the new position of the updated particle and \({R}_{best,j}\) is the \(j\)-th particle of the best rime-agent in the rime-population \(R\). \({F}^{normr}\left({S}_{i}\right)\) denotes the normalized value of the current agent fitness value, indicating the change of the \(i\)-th rime-agent being selected. \({r}_{3}\) is a random number in range (− 1,1).
Positive greedy selection mechanism
Typically, meta-heuristic optimization algorithms use a greedy selection mechanism that replaces and records the best fitness value and the best agent after each update. The RIME algorithm proposes an active greedy selection mechanism to be used in population updating to improve global exploration efficiency. The idea is to compare the updated agents' fitness values with the pre-update agents' fitness values. If the updated fitness values are better than the pre-update values, the replacement of solution agents occurs. This strategy ensures that the population evolves more optimally with each iteration. The pseudo-code of the positive greedy selection mechanism is shown in Algorithm 1.

Pseudo code of the positive greedy selection mechanism.
The pseudocode of the RIME is presented in Algorithm 2.

Pseudocode of RIME.
In summary, first, inspired by the soft rime particle motion, the authors of the RIME algorithm designed a unique position update method and proposed the soft rime search strategy as the core optimization method of the algorithm. Second, inspired by the puncture crossover, the complex rime puncture mechanism is proposed to achieve dimensional crossover interchange between ordinary and optimal agents, which improves the algorithm's solution accuracy. Finally, based on the greedy selection mechanism, an improved positive greedy selection mechanism is proposed to increase the diversity of the population by altering the selection of the optimal solution, thereby preventing the algorithm from falling into a local optimum. The overall structure of the RIME algorithm is shown as pseudo-code and flowchart in Algorithm 2 and Fig. 2.

Flowchart of the RIME algorithm.
Proposed ELRIME
This section explains in detail the three improvement strategies proposed in this paper, i.e., Elite Reverse Learning Population Selection Strategy based on Piecewise Mapping, Elite Pool Exploration Strategy with Stochastic Factor Control36, and Hard Frost Piercing Exploitation Mechanism based on sine–cosine Function37. The time complexity of the ELRIME algorithm proposed in this paper, as well as the original RIME algorithm, is also analyzed to ensure that our proposed algorithm has not significantly increased the complexity of events while improving the performance of the original algorithm and ensuring that the time complexity of the proposed algorithm is within an acceptable range.
Elite reverse learning population selection strategy based on piecewise mapping
During the population initialization process of the original rime algorithm, individuals randomly update their position information. Due to the randomness of their positions, their randomly initialized positions may be far away from the global optimal solution. Therefore, the initialization will affect the exploration performance of the algorithm to a great extent. In summary, to optimize the impact of initialization on search performance, we propose an elite reverse learning population selection strategy based on piecewise mapping38, by which a better population can be obtained to shorten the time spent searching for the optimal solution. The strategy first initializes the population using Piecewise mapping to distribute the initial solutions as evenly as possible in the solution space39. The mapping is stochastic, ergodic, and initial value sensitive, which enables the algorithm to have a faster convergence rate. The process of generating chaotic sequences based on Piecewise mapping is shown in Eq. (8).
where d is the control parameter in 0.3 and denotes endpoints of four subintervals. This map obtains the chaotic sequences in (0,1).
In addition, we also introduce an elite reverse learning strategy40. Due to the feature that elite individuals contain more valid information than general individuals, this subsection constructs a reverse population through elite individuals in the current population to increase the diversity of the population, and selects the optimal individuals as the new generation of individuals from the new population composed of the current population and the reverse population to enter the next iteration41. In this paper, Eq. (9) is utilized to find the individual reverse solution.
where \(UB\) represents the upper boundary, \(LB\) represents the lower boundary, and \(X\left(i\right)\) indicates the current individual ___location information of the initialized population. Reverse individuals are obtained through elite reverse learning. Calculating the fitness of \(reverse\left(i\right)\) and comparing it with the fitness of the \(X\left(i\right)\). Better individuals are retained, which can be expressed by Eq. (10).
where, \(reverse\left(i\right)\) represents the reverse solution of the current individual, when the fitness value of the reverse solution is smaller than the fitness value of the current individual, the individual is updated, otherwise no update is performed.
Elite pool exploration strategies with stochastic factor control
In the original RIME algorithm, for its Soft-rime search strategy, the individual is dominated by the position of its current best individual and assisted by the five motion characteristics of the rime particles when updating its position, which is relatively single and easy to fall into the local optimum.
The exploration phase is crucial for the success of the optimization algorithm in finding a globally optimal solution and requires an extensive search in the search space to discover potential global optima. In general, we can add random perturbations to the current solution to explore different regions of the solution space or use a large step size in the initial stage of the search to cover a larger area quickly. As the algorithm progresses, the step size is gradually reduced to allow for a more refined search.
Therefore, we propose an elite pool exploration strategy controlled by stochastic factors, which makes the algorithm easier to jump out of the local optimum and find the global optimum. When \({r}_{2}<E\) is satisfied, we update Eq. (3), which is used to update the position in the soft frost ice phase, to Eq. (11).
We control the algorithm's exploration strategy by randomizing factors \({h}_{1}\) and \({h}_{2}\) to allow the algorithm to explore with different update rules to increase the algorithm's ability to jump out of local optimal solutions. In addition, we utilize an elite pool with multiple particles to ensure diversity in the algorithm's exploration, ensuring that the algorithm starts its search from different starting points to better explore the entire search space.
where \({h}_{1},{h}_{2}\) are the random factors used to select the position update strategy, which is a random number in the range (0,1). \(k1\) is a random integer in (1, 3), which is refreshed each time a ___location update is performed using the elite pooling strategy to enhance the randomness of the algorithm and allow it to have better performance. \(Elite\_pool\) is the elite pool, which contains the optimal, suboptimal, and third best solutions for the current situation. When the position is updated, one of them is randomly chosen as the dominant one, which can effectively avoid it from falling into the local optimum and make it easier to find the global optimum.
Mechanism of hard rime puncture exploitation based on sine–cosine function
In the original RIME algorithm, for its soft-rime search strategy, when an individual updates its position, the new position is derived based on the current best individual. However, this approach often leads the individual to fall into a local optimum during position updates. If we only update the position based on the current optimum, the result is likely to remain in the local optimum and fail to reach the global optimum.
In mathematics, the sine and cosine functions are periodic, and this periodicity can help algorithms explore the search space periodically, reducing the likelihood of falling into local optima. Additionally, the sine and cosine functions introduce diversity, enabling the algorithm to cover the entire search space more effectively and increasing the probability of finding a globally optimal solution.
Therefore, we propose a hard frost puncture exploitation mechanism based on the sine–cosine function, which uses the current individual position, the current optimal individual position, and the sine–cosine function to improve the hard frost puncture mechanism so that the algorithm can more easily jump out of the local optimum and find the global optimum42. In particular, we update Eq. (7), which is used to update the position in the challenging rime puncture phase, to Eq. (12).
where \({r}_{4}\) is an adaptive parameter, which is calculated by Eq. (13), and its value decreases uniformly from 2 to 0, ensuring the periodicity of the sine–cosine function and enabling better development of the algorithm. \({r}_{5}\) is a random number between 0 and \(2\pi\). Random initialization of \({r}_{5}\) in each iteration yields a different value, increasing the randomness of the algorithm and avoiding as much as possible the algorithm from falling into a local optimum. The periodicity feature of the sine–cosine function is then utilized to accelerate the convergence of the algorithm.
In summary, the pseudo-code of the ELRIME algorithm proposed in this paper is shown in Algorithm 3.

Pseudocode of ELRIME.
Theoretical analysis of algorithmic convergence
In the design and application of intelligent optimization algorithms, convergence is a key factor in assessing the algorithm's effectiveness. Proving an algorithm's convergence is crucial, as it refers to the ability to find a global optimal solution or an approximate solution within a finite number of steps. Algorithms with good convergence not only ensure effectiveness and reliability in solving complex problems but also provide stability and predictability across different application scenarios. In contrast, algorithms without proven convergence may yield uncertain or inconsistent results, affecting the accuracy and trust in decision-making. Therefore, this section performs a convergence analysis of the enhanced frost-ice optimization algorithm to demonstrate its convergence properties.
Markov modeling of the ELRIME algorithm
The Markov model is a mathematical framework used to describe a stochastic process where the future state depends only on the current state and is independent of previous states43. The evolution of intelligent optimization algorithms such as PSO, GWO, and ACO can be modeled as Markov processes. In the ELRIME algorithm, the position updates of the frost-ice particles depend solely on the current state and are independent of past states, making it inherently a stochastic process. Therefore, this subsection uses the Markov model to represent this stochastic process, which will be described and defined mathematically in detail below.
Definition 1
(RIME particle states and RIME particle state space). The state of the RIME particle consists of the position where the RIME particle is located, denoted \(X\), where \(X\in A\), \(A\) denotes the space of feasible solutions. The set of all possible states of the RIME particle constitutes the state space of the RIME particle, denoted \(Y=\left\{X|X\in A\right\}\).
Definition 2
(RIME particle population states and RIME particle population state spaces). The RIME particle population state consists of all RIME particle states, denoted \(s=({X}_{1},{X}_{2},\dots ,{X}_{N})\), where \({X}_{i}\) denotes the state of the \(i\) RIME particle and \(N\) denotes the population size. The state space of a population of RIME particles consists of the set of all possible states of the population of RIME particles, denoted \(S=\left\{s=({X}_{1},{X}_{2},\dots ,{X}_{N})|{X}_{i}\in Y,1\le i\le N\right\}\).
Definition 3
(state equivalence). Define a function \(\psi (s,X)\), \(\forall s\in S\), \(X\in s\), denoted \(\psi (s,X)=\sum_{i=1}^{N} {\chi }_{|X|}({X}_{i})\). where \({\chi }_{|X|}\) denotes the schematic function of the event, and \(\psi (s,X)\) denotes the number of RIME particle population states \(s\) that contain RIME particle states \(X\). If there are two RIME particle populations \({S}_{1},{S}_{2}\in S\), for \(\forall X\in Y\), \({s}_{1}\) and \({s}_{2}\) are said to be equivalent if \(\psi ({s}_{1},X)=\psi ({s}_{2},X)\), denoted as \({s}_{1}\sim {s}_{2}\).
Definition 4
( State equivalence classes). From the equivalence relation “ ~ ” on \(S\) one can analogize the equivalence class of RIME particle population states, denoted \(Le=S/\sim\). abbreviated RIME particle population equivalence classes. The following properties exist for it:
Property 1 Any RIME particle population state within a certain equivalence class \(Le\) is equivalent to each other, i.e. \({s}_{i}\sim {s}_{j}\), \(\forall {s}_{i},{s}_{i}\in Le\);
Property 2 Any RIME particle population state inside \(Le\) is not equivalent to any RIME particle population state outside \(Le\), denoted as \({s}_{i}<\ne >{s}_{j}\), \(\forall {s}_{i}\in Le\), \(\forall {s}_{j}\in Le\);
Property 3 There is no intersection of any two equivalence classes, i.e. \(Le_{1} \cap Le_{2} = \emptyset ,\;\forall Le_{1} \ne Le_{2} ;\)
Definition 5
(RIME particle state transfer). For \(\forall {X}_{i}\in s\), the RIME particle state is shifted from \({X}_{i}\) to \({X}_{j}\) in one step in the ELRIME algorithm iteration, denoted \({T}_{s}({X}_{i})={X}_{j}\).
Theorem 1
In the ELRIME algorithm, the expression for the transfer probability \(P({T}_{s}({X}_{i})={X}_{j})\) of the state \({X}_{i}\) of the RIME particle from one step to \({X}_{j}\) is given by:
Testimonial Depending on the population of RIME particles as a set of point sets in the hyperspace, the process of updating the position of frost ice particles is an inter-transition between a set of point sets in the hyperspace. According to Definition 3 and the geometric properties of ELRIME algorithm, the transfer probability of the RIME particles to transfer from state \({X}_{i}\) to state \({X}_{j}\) in one step during the soft frost ice search phase is known as:
where \({p}_{1}({x}_{i}\to {x}_{j})\) is calculated by Eq. (16).
After the RIME particle goes through the soft frost ice search phase to get a new solution, it also needs to go through the hard frost puncture mechanism to find out if there is a better solution, so the transfer probability of the hard frost puncture phase of the RIME particle from state \({X}_{i}\) to state \({X}_{j}\) in one step is obtained:
where \({p}_{2}\left({x}_{i}\to {x}_{j}\right)\) is calculated by Eq. (18).
where \(X\) is multidimensional, the volume of the hyperspace cube is denoted by the absolute value, and the vector additions and subtractions are denoted by the plus and minus signs. Since the ELRIME algorithm is realized by two stages, the soft RIME search stage and the hard RIME puncture mechanism, the transfer probability \(P({T}_{s}({X}_{i})={X}_{j})\) of the state of the RIME particles to be transferred from \({X}_{i}\) step to state \({X}_{j}\) is jointly determined by Eqs. (15) to (18), which are proved.
Definition 6
(RIME particle population state transfer probability). For \(\forall {s}_{i}\in S\), \(\forall {s}_{j}\in S\), during the iteration of the ELRIME algorithm, the state of the RIME particle population is shifted from \({s}_{i}\) to \({s}_{j}\) in one step, denoted as \({T}_{S}({s}_{i})={s}_{j}\). The transfer probability of the state of the RIME particle population shifted from \({s}_{i}\) to \({s}_{j}\) in one step is \(P({T}_{S}({s}_{i})={s}_{j})=\prod_{N}^{m=1} P({T}_{s}({X}_{im})={X}_{jm})\), That is, the probability that the state of the population of RIME particles is transferred from one step to the state of the population of RIME particles to the state of the population of RIME particles at the same time; is the number of individuals in the population.
Theorem 2
The sequence of RIME particle population states \(\left\{\begin{array}{c}s(t):t>0\end{array}\right\}\) in the ELRIME algorithm is a finite number of its sub-Markov chains.
Testimonial The search space is finite in any optimization algorithm, so any RIME particle state \({X}_{i}\) is finite, so the state space of RIME particles \(Y\) is finite. A RIME particle population state space \(s=\left(\begin{array}{c}{X}_{1},{X}_{2},\dots ,{X}_{N}\end{array}\right)\) consists of \(N\) RIME particles, \(N\) is a finite positive integer, so the RIME particle population state space \(S\) is finite.
From the state transfer probability of RIME particle population, the transfer probability \(P({T}_{S}(s(t))=s(t+1))\) of any \(s(t)\in S\), \(s(t+1)\in S\) in the state sequence \(\left\{\begin{array}{c}s(t):t>0\end{array}\right\}\) of RIME particle population is determined by the state transfer probability \(P({T}_{s}(X(t)=X(t+1))\) of all the RIME particles in the RIME particle population. From Theorem 1, it is known that the state transfer probability \(P({T}_{s}(X(t)=X(t+1))\) of any RIME particle within the RIME population is only related to the state \(X(t)\) at the moment \(t\), the random factor \(r\), the adaptive RIME parameter \(h\), and the upper and lower limit values of the search space, so that \(P({T}_{S}(s(t))=s(t+1))\) is also related to the state at the moment \(t\) only, i.e., the state sequence \(\left\{\begin{array}{c}s(t):t>0\end{array}\right\}\) of the RIME particle population has Markov property. And because the state space is a columnable set, the RIME particle population state space \(S\) is finite, so it constitutes a finite Markov chain.
By Theorem 1, \(P({T}_{s}(X(t)=X(t+1))\) is only related to the state \(X(t)\) at moment \(t\), but not to moment \(t\). Therefore, the sequence of RIME particle population states \(\left\{\begin{array}{c}s(t):t>0\end{array}\right\}\) is a finite chi-square Markov chain.
Convergence analysis of the ELRIME algorithm
Definition 7 (set of optimal state ).
\({\varvec{G}}\) The globally optimal solution for an optimization problem \(\langle Y,f\rangle\) is \({g}_{b}\), The set of optimal states is defined as \(G=\{{s}^{*}=({X}_{1},{X}_{2},\dots ,{X}_{N})|f(X)=f({g}_{b}),s\in S\}\). The case of \(G\subset S\) is considered here, since if \(G=S\), then the set of solutions in the feasible solution space is also optimal, optimization makes no sense.
Definition 8 (set of optimal population state ).
\({\varvec{H}}\) For a globally optimal solution to an optimization problem \(\langle Y,f\rangle\), The optimal set of population states is defined as \(H=\{q=({s}_{1},{s}_{2},\dots ,{s}_{n})|\exists {s}_{i}\in G,1\le i\le n\}\).
Lemma 1
Assume that the Markov chain has a nonempty closed set \(E\), and there does not exist another non-empty closed set \(O\) such that E∩0 = ∅, Then there is \({\text{lim}}_{n\to \infty }P({X}_{n}=j)={\pi }_{j}\) when \(j\in E\) and \(\underset{n\to \infty }{lim} P\left({X}_{n}=j\right)=0\) when \(j\notin E\).
Theorem 3
As the number of iterations tends to infinity, the sequence of population states converges to the optimal set of population states \(H\).
Testimonial In the ELRIME algorithm, the RIME particle position update strategy uses an optimal individual preservation mechanism, whereas the number of iterations increases, better values than the previous ones will be obtained, and no update will be performed when a worse value than the previous one occurs. So \(P({X}_{k+1}\notin G\mid {X}_{k}\in G)=0\), therefore \(G\) is a closed set with probability 1.
From Definition 8, it follows that \(\exists {s}_{i}\in G\), The \(k\) th iteration has \({q}_{k}=({s}_{1},{s}_{2},\dots ,{s}_{n})\in H\). In closed set \(G\), Then there must exist \({X}_{k+1}\in G\), at the \(k+1\) th iteration, a population state \({q}_{k+1}=({s}_{1},{s}_{2},\dots ,{s}_{n})\in H\). So \(P({q}_{k+1}\notin H\mid {q}_{k}\in H)=0\). It follows that \(H\) is a closed set over the state space \(S\).
Suppose that the state space \(S\) also has a nonempty closed set \(M\), and \(M\cap H=\varnothing\). Assumption \({q}_{i}=({g}_{b},{g}_{b},\dots ,{g}_{b})\in H\), \(\forall {q}_{j}=({s}_{j1},{s}_{j2},\dots ,{s}_{jn})\in M\) existence \(f({s}_{jc})>f({g}_{b})\). From the Chapman-Kolmogorov equation it follows that \({P}_{{s}_{i},{s}_{j}}^{l}=\sum_{{s}_{{n}_{1}}\in s} \sum_{{s}_{n-1}\in s} P\left({T}_{s}\left({s}_{i}\right)={s}_{{n}_{1}}\right)P\left({T}_{S}\left({s}_{{n}_{1}}\right)={s}_{{n}_{2}}\right)\cdots P\left({T}_{S}\left({s}_{{n}_{-1}}\right)={s}_{j}\right).\)
Therefore, for each transfer probability \(P({T}_{s}({s}_{{r}_{c+i}})={s}_{{r}_{c+i+1}})\) in the C-K equation \({P}_{{s}_{i},{s}_{j}}^{l}\) in an infinite number of iterations satisfies \(P({T}_{s}({s}_{{r}_{c+i}})={s}_{{r}_{c+i+1}})>0\). In summary, 1 is not a non-empty closed set, which contradicts the assumption. Therefore, there is only one closed set \(H\) in the state space \(S\), containing no closed sets other than \(G\).
In summary, it follows from Lemma 1 that Theorem 3 holds.
Lemma 2
(Global convergence theorem) Suppose \(f\) is a measurable function and the measurable space \(A\) is a subset of measurables on \({R}^{n}\). \(f\) satisfies the following conditions:
(1)\(f\left(D\left(x,\zeta \right)\right)\le f\left(x\right),\) if \(\zeta \in A\), then \(f(D(x,\zeta ))\le f(\zeta )\).
(2) For any Borel subset \(B\) of \(A\), if \(\text{s.t. v[B]>0}\) then \(\prod_{\infty }^{k=0} (1-{\mu }_{k}[B])=0\), and \(\{{x}_{k}{\}}_{k=0}^{\infty }\) is the sequence generated by Algorithm \(D\), then \(\underset{k\to \infty }{lim} P({x}_{k}\in {R}_{\varepsilon ,M})=1\), where \(P({x}_{k}\in {R}_{\varepsilon ,M})\) is the probability measure of solution \({x}_{k}\) in \({R}_{\varepsilon M}\) at step \(K\) of the algorithm.
Theorem 4
The ELRIME algorithm has global convergence.
From Lemma 2, for the ELRIME algorithm, the current optimal solution during the iteration is saved as
Therefore, the ERIME algorithm saves the best position in the population in each iteration, clearly satisfying condition (1). It shows that the current best solution is always preserved in iterations. From Theorem 3, when the number of iterations tends to infinity, the sequence of population states converges to the optimal set of population states \(H\), indicating that the sequence of population states will converge to the optimal set after enough iterations or infinity. Therefore, the probability of not finding a globally optimal solution is 0, then \(0<{\mu }_{k}[B]<1\), i.e., \(\prod_{\infty }^{k=0} (1-{\mu }_{k}[B])=0\) satisfies condition (2). Therefore, by the global convergence theorem, it can be concluded that ELRIME is a globally convergent algorithm.
Computational time complexity
The complexity of the algorithm mainly depends on population initialization, fitness calculation and position update. In this algorithm, the complexity also depends on these three processes44. Firstly, the complexity of population initialization is \(O(n)\) since the initial population size is \(N\). For position update, in the soft rime phase, it is necessary to update all the frost ice individuals, which has a complexity of \(O({n}^{2})\). In the hard frost puncture phase, the time complexity of the two extreme cases is \(O(n)\) and \(O({n}^{2})\). In addition to this, the time complexity of the forward greedy mechanism is \(O(n)\) and finally, the time complexity of computing the fitness value is \(O(n*logn).\) the complexity of this algorithm is \(O(n*(n+{log}_{n}))\), and the newly proposed ELRIME algorithm in this paper does not change the structure of the original RIME algorithm, but only adjusts its position update strategy. So, the time complexity of the new improved ELRIME algorithm is also \(O(n*(n+{log}_{n}))\). In summary, the newly proposed algorithm in this paper has not significantly increased the time complexity of the original algorithm while improving it.
Experimental results and detailed analyses
In this section, we evaluate the performance of the ELRIME algorithm on various benchmark test sets. First, we present the specific details of these benchmark test sets in tabular form. Next, we show the algorithms and their parameter settings used for comparison with the ELRIME algorithm. We then conduct both qualitative and quantitative analyses to demonstrate that the proposed algorithm outperforms the original RIME algorithm. Finally, we analyze the time complexity of the ELRIME algorithm to ensure that it enhances the performance of the original algorithm without significantly increasing its complexity. All experiments are conducted using the MATLAB 2023a platform with a 2.90 GHz Intel Core i7-10700F CPU and 8 GB of RAM.
Benchmark test functions
Benchmarking functions are essential in determining the performance of an algorithm. They provide a platform to compare and evaluate the performance of different intelligent optimization algorithms. In this paper, we use the CEC2017 test set45, CEC2020 test set46, and CEC2022 test set47 to test the performance of ELRIME and compare it with the classical algorithms of the day, the latest algorithms, and high-performance algorithms. Among the 52 test functions in these three test sets, single-peak, multi-peak, and composite functions are included, through which the performance of the ELRIME algorithm proposed in this paper can be comprehensively tested. The details of the test sets are shown in Tables 2, 3, and 4.
To help readers unfamiliar with test functions understand the underlying parameters, we will reference the Kepler Optimization Algorithm (KOA), proposed by Mohamed Abdel-Basset et al. in 2023, and its experimental results. The KOA algorithm has demonstrated significant success in its tests. For instance, on the CEC2017 test set, functions F1, F2, and F3, the KOA algorithm consistently achieved the theoretical optimal values, showcasing its effectiveness. The algorithm was able to find the global optimal values for these functions without falling into local optima. For function F4, the KOA algorithm produced an average result of 504, while the theoretical optimal value is 500, indicating that the algorithm's results are very close to the theoretical optimum. This proximity serves as a robust evaluation criterion for the algorithm’s performance.
In optimization problems, \(Dim\) represents the dimension of the problem space or the number of decision variables. For example, in a 30-dimensional optimization problem, there are 30 decision variables that need to be determined. The search range defines the interval within which each decision variable can take values. For instance, if the search range for function F1 is [− 100, 100], and its dimension is 30, the algorithm explores values within this range for each of the 30 decision variables. This implies that the algorithm seeks the optimal solution within a 30-dimensional hypercube.
Competitor algorithms and parameters setting
In this section, we compare the ELRIME algorithm proposed in this paper with 13 other classic, state-of-the-art, and high-performance algorithms to verify that this algorithm has strong performance. The algorithms used for comparison include Particle Swarm Optimization (PSO)48, Grey Wolf Optimization (GWO)49, Whale Optimization Algorithm (WOA)50, Artificial Gorilla Troops Optimizer (GTO)51, Snake Optimizer (SO)52, Dung beetle optimizer (DBO)53, Constriction Coefficient Based Particle Swarm Optimization and Gravitational Search Algorithm (CPSOGSA)54, Gold rush optimizer (GRO)55, Red‑tailed hawk algorithm (RTH)56, Great Wall Construction Algorithm (GWCA)57, SHADE58, LSHADE59, and SHADE_cnEpSin60. Table 5 summarizes the parameters to be used by these intelligent optimization algorithms in the optimization process and the corresponding parameter values. It is worth noting that the parameter values are set according to Ref. 's recommendations.
Qualitative analysis of ELRIME
In order to test the performance of the ELRIME algorithm proposed in this paper, a qualitative analysis will be performed in this section, which includes convergence behavior analysis, population diversity analysis, exploration and exploitation analysis, and modified impact analysis. During the qualitative analysis, the algorithm population size was set to 30, and the maximum number of iterations was set to 1000.
Analysis of the convergence behavior
In order to analyze the convergence performance of the ELRIME algorithm proposed in this paper, Fig. 3 shows the convergence behavior of the algorithm on different test functions61. The figure's first column shows the benchmark function's two-dimensional shape. The second column shows the final positions of the search agents, and the red dots indicate the positions of the optimal solutions. The search agents are distributed in the parameter space, but their locations are mainly near the optimal solution, which indicates that the algorithm has a strong exploitation capability. In addition, the third column shows how the average fitness value changes throughout the iterations. Although the average fitness value is high initially, it slowly becomes smaller and stabilizes as the number of iterations increases, indicating the algorithm has good convergence ability. The fourth column shows the trajectory of the search agent in the first dimension, and it can be seen that there are apparent fluctuations at the beginning of the iteration. However, as the number of iterations increases, the trajectory gradually stabilizes. This indicates that the algorithm can jump out of the local optimum and find the global optimal solution. The last column shows the convergence curve of the algorithm, which can be seen that the algorithm converges quickly. The convergence curve for a single-peaked function with only one optimal solution appears relatively smooth, indicating that the optimal solution can be obtained through iteration. However, it is necessary to continuously jump out of the local optimal solutions for functions with multiple local optimal solutions during the search process to find the global optimal solution. Therefore, its convergence curve shows a step-like shape. It is shown that when the algorithm encounters a local optimal solution, it can jump out well and continue to find the global optimal solution. In summary, the ELRIME algorithm proposed in this paper has good convergence.


Convergence behavior of ELRIME in the search process.
Analysis of the population diversity
In order to verify the population diversity of the ELRIME algorithm, we use Eq. (19) to calculate the population diversity in this subsection62. Where \({I}_{c}\) denotes the rotational inertia, \({X}_{id}\left(t\right)\) denotes the value of the \(d\) th dimension of the \(i\) th search agent at iteration \(t\), and \({C}_{d}\) denotes the dispersion of the totality with respect to its center of mass \(C\) in each iteration, as computed in Eq. (20).
Figure 4 illustrates the results of the test of population diversity for ELRIME and RIME. There are significant fluctuations in the population diversity measured by \({I}_{c}\) in the early stage of the iteration63. However, as the iterative process proceeds, the \({I}_{c}\) value gradually stabilizes at a higher level, which demonstrates that the ELRIME algorithm proposed in this paper is able to effectively avoid premature convergence and staying at a local optimum that cannot be jumped out. Such various experimental results show that ELRIME has great potential in finding the optimal solution.

The population diversity of ELRIME and RIME.
Analysis of the exploration and exploitation
Meta-heuristic algorithms divide the optimization process into two phases: exploration and exploitation64. In order to enhance the robustness of the algorithm, we then need to balance the two phases of exploration and exploitation. This section uses Eq. (21) and Eq. (22) to calculate the percentage of exploration and exploitation, respectively. Where \(Div\left(t\right)\) is calculated by Eq. (23).
The analysis results are shown in Fig. 5. From the experimental results; it can be seen that for the unimodal functions, the exploitation percentage of ELRIME increases steadily with the increase in the number of iterations and reaches a faster convergence rate65. For other functions, ELRIME's exploration and utilization percentages fluctuated initially, but overall, ELRIME effectively balanced exploration and exploitation based on different benchmark functions.

The analysis of the exploration and exploitation of ELRIME and RIME.
Impact analysis of the modification
This paper proposes a new ELRIME algorithm by improving the RIME algorithm. To verify that each improvement strategy of the original RIME algorithm in this paper improves its performance66. In this subsection, we analyze the effects of the proposed elite reverse learning population selection strategy based on Piecewise mapping, the elite pool exploration strategy with random factor control, and the hard frost puncture exploitation mechanism based on sine–cosine function on the original algorithm, respectively. The experimental results are shown in Fig. 6. In the legend, RIME is the original RIME algorithm, RIME1 is the algorithm that adds the elite reverse learning population selection strategy based on Piecewise mapping to the original RIME algorithm, RIME2 is the algorithm that adds the randomized factor-controlled elite pool exploration strategy to the original algorithm, and RIME3 is the algorithm that adds the sine–cosine based function based hard frost puncture exploitation mechanism, ELRIME is the algorithm that integrates the three new strategies, which is the algorithm proposed in this paper. From the experimental results, for unimodal functions, each of our proposed strategies improves the convergence speed of the original RIME algorithm, which indicates the applicability of the new strategies. For multimodal functions, our proposed new strategies are more likely to make the algorithm converge prematurely and jump out of the local optimum. In conclusion, ELRIME plays a crucial role in achieving robust optimization67.

Comparison of different improvement strategies.
Quantitative evaluation
This section will quantitatively evaluate the ELRIME algorithm proposed in this paper. First, we will compare ELRIME with 13 other classical, currently popular, high-performance algorithms in 30, 50, and 100 dimensions using the CEC2017 test set to determine its performance in numerical experiments. Second, to validate the algorithm more broadly, this section utilizes the CEC2020 and CEC2022 test set to analyze the algorithm quantitatively. In this section, we set the initial population to 30 and the maximum number of iterations to 1000 for testing12.
Compare using CEC 2017 test functions
This subsection compares the ELRIME algorithm proposed in this paper with 13 other classical, currently popular, and high-performance algorithms. In order to verify the performance of the algorithms more comprehensively, we performed the test comparisons on 30, 50, and 100 dimensions of the CEC2017 test set, respectively. Supplementary Tables 1, 2, and 3 show the mean (Ave), standard deviation (std), and rank sum test p-values of the ELRIME algorithm and its comparison algorithms for 30 independent runs in 30, 50, and 100 dimensions, respectively. The last two rows of the table analyze all comparison algorithms. The first row represents the average Friedman's ranking, and the second row represents the final ranking values of all compared algorithms. These results show that the ELRIME algorithm proposed in this paper achieved the most significant victory and the first overall ranking.
As can be seen from the data in the table, in the 30-dimensional case, out of the 30 functions in the CEC2017 test set, the mean value obtained by the ELRIME algorithm is greater than that obtained by RIME only for two functions, F13 and F30, and the ELRIME algorithm outperforms the RIME algorithm for the rest of the 28 functions. Moreover, among all the compared algorithms, the ELRIME algorithm achieves the best performance on the F3, F5, F6, F7, F8, F9, F11, F16, F20, F21, F22, F23, F24, F26, F27, and F29 functions, and its 30-run mean value achieves the lowest value among the 15 algorithms. In addition, the ELRIME algorithm performs slightly worse than the RIME algorithm in the 50- and 100-dimensional cases, and only in the 4-function case. Thus, in summary, the ELRIME algorithm performance is superior to RIME.
In addition, Fig. 7 shows the convergence curves of the algorithm proposed in this paper and its comparison algorithm, indicating that the ELRIME algorithm continues to improve when it does not reach the global optimum. Figure 8 shows the Friedman rankings of ELRIME and its comparison algorithms in the 30, 50, and 100 dimensions on the CEC2017 test set, respectively. Figure 9 shows the results of the 15 algorithms on the three dimensions of the CEC2017 test set more comprehensively in the form of a box-and-line diagram, and it can be seen that ELRIME achieves excellent results. This proves that the algorithm has excellent global exploration and local utilization abilities and also proves the effectiveness and accuracy of the ELRIME algorithm proposed in this paper.


Comparison of convergence speed of different algorithms on CEC2017 test set.

Friedman ranking of each algorithm on the CEC2017 test set.


Boxplot analysis for different algorithms on the CEC2017 test set.
From the results in the figure, it can be seen that in many cases, the convergence of the RTH algorithm is faster, but it is easy to fall into the local optimum and cannot find the global optimal solution well. Although the ELRIME algorithm converges more slowly, it slowly jumps out of the local optimal solution and finds the global optimal solution as the iteration progresses. Especially in the F10 function, compared with other algorithms, ELRIME algorithm is slower to converge, but it can constantly jump out of the local optimal solution, and the final convergence accuracy is better than other comparative algorithms. From these results, it can be seen that the ELRIME algorithm has good exploration performance compared to other algorithms.
Compare using CEC 2020 test functions
This subsection compares the ELRIME algorithm proposed in this paper with 13 other classical, currently popular, and high-performance algorithms. In order to verify the performance of ELRIME more comprehensively, we compare it to the 20-dimension of the CEC2020 test set. Supplementary Table 4 shows the mean (Ave), standard deviation (std), and p-values of ELRIME and its comparison algorithms for 30 independent runs in 20 dimensions. The last two rows of the table statistically analyze all comparison algorithms. The first row represents Friedman's average ranking, and the second represents the final ranking values for all compared algorithms. These results show that the ELRIME algorithm proposed in this paper achieves the most significant victory with the first overall ranking.
The table data shows that the ELRIME algorithm outperforms RIME algorithm in all 10 functions of CEC2020 test set when comparing the mean values of 30 runs, which proves the effectiveness of our improvement strategy, which shows significant improvement in the algorithm's performance. Especially on the F7 function, the ELRIME algorithm achieves an order of magnitude improvement. Compared to the other algorithms, the ELRIME algorithm has an average Friedman ranking of 3 on 10 functions and a final ranking of 1 out of 15 algorithms, while the RIME algorithm has an average ranking of 5.22 and a final ranking of 5. It can be seen that, in the Friedman test, the SO, RTH, and GRO algorithms outperform on the CEC2020 test set on the RIME algorithm, but after our improvement, the ELRIME algorithm can outperform SO, RTH and GRO algorithm. It further proves the effectiveness of our improvement.
In addition, Fig. 10 shows the convergence curve, indicating that ELRIME improves continuously when it does not reach the global optimum. Figure 11 shows the Friedman rankings of ELRIME and its comparison algorithms on the CEC2020 test set in the 20-dimension. Figure 12 shows the results of the 15 algorithms on the 20-dimension of the CEC2020 test set more comprehensively in the form of a box plot, and it can be seen that ELRIME achieves excellent results. This proves that the algorithm has excellent global exploration and local utilization capabilities and proves the effectiveness and accuracy of the ELRIME algorithm proposed in this paper.

Comparison of convergence speed of the different algorithms on CEC2020 test set.

Friedman ranking of each algorithm on the CEC2020 test set.

Boxplot analysis for the different algorithms on the CEC2020 test set.
Compare using CEC 2022 test functions
This subsection compares the ELRIME algorithm proposed in this paper with 13 other classical, currently popular, and high-performance algorithms. In order to verify the performance of ELRIME more comprehensively, we compare it to the 20-dimension of the CEC2022 test set. Supplementary Table 5 shows the mean (Ave), standard deviation (std), and p-values of ELRIME and its comparison algorithms for 30 independent runs in 20 dimensions. The last two rows of the table statistically analyze all comparison algorithms. The first row represents Friedman's average ranking, and the second represents the final ranking values for all compared algorithms. These results show that the ELRIME algorithm proposed in this paper achieves the most significant victory with the first overall ranking.
The tabular data show that the ELRIME algorithm performs only slightly worse than the RIME algorithm on F1 out of the 12 functions in the CEC2020 test set; it is close to the RIME algorithm on the F2 and F11 functions. On the remaining 9 functions, the ELRIME algorithm outperforms the RIME algorithm. On the F3, F4, F5, F7, F8, F9, F10, and F12 functions, the average of the ELRIME algorithm is the best among the 15 compared algorithms. Its average ranking by the Friedman test on 12 functions is 3.25, which is in first place among 15 algorithms, and the ranking results show that the average ranking of the RIME algorithm is worse than the GRO and SO algorithms, and the ELRIME algorithm outperforms the GRO and SO algorithms after our improvement.
In addition, Fig. 13 shows the convergence curve, indicating that ELRIME improves continuously when it does not reach the global optimum. Figure 14 shows the Friedman rankings of ELRIME and its comparison algorithms on the CEC2022 test set in the 10-dimension. Figure 15 shows the results of the 15 algorithms on the 20-dimensions of the CEC2022 test set more comprehensively in the form of a box plot, and it can be seen that ELRIME achieves excellent results. This proves that the algorithm has excellent global exploration and local utilization capabilities and proves the effectiveness and accuracy of the ELRIME algorithm proposed in this paper.

Comparison of convergence speed of the different algorithms on CEC2022 test set.

Friedman ranking of each algorithm on the CEC2022 test set.

Boxplot analysis for the different algorithms on the CEC2022 test set.
Time complexity analysis of ELRIME and RIME
For a metaheuristic algorithm, it is not only necessary that it has good performance. We also need to focus on its time complexity68. The best is to make its performance very good while keeping its time complexity as small as possible. From the above experiments, we know that the performance of the ELRIME algorithm proposed in this paper is improved on the original RIME. In this section, we analyze the improved algorithm's time complexity and the original algorithm's time complexity69. During the experiments, we set the population size to 30 and the number of iterations to 1000. The running times of the ELRIME and RIME algorithms on each function of the CEC2017 test set are listed in Table 6, respectively.
As can be seen from the results in the table, the ELRIME algorithm takes about twice as long as the RIME algorithm to execute in practice on most functions. And in the UAV path planning process, safety is the most basic and important requirement, so we can sacrifice part of the time to increase the safety of UAV path planning. Hence, the ELRIME algorithm proposed in this paper improves the performance of the RIME algorithm with only a slight loss in its time complexity, which is acceptable for the UAV path planning problem, where the most important thing is the need to ensure the safety of UAV flight. This further proves the superior performance of the proposed algorithm.
ELRIME algorithm for 3D UAV path planning
In this section, we fully consider the threat area, the height of the threat area, etc., model the UAV flight situation, and use the ELRIME algorithm proposed in this paper to plan the 3D UAV path in order to verify that the algorithm proposed in this paper not only has a better performance on the CEC test function but also has a greater competitiveness in the specific application.
Modeling of the UAV flight environment
With the continuous development of society, drones have been widely used in various fields due to the advantages of easy operator training and avoiding casualties when carrying out missions. In the process of a UAV mission, whether it can obtain a feasible and safe path affects whether its mission can be well accomplished. We systematically study UAV path planning in complex environments, modeling according to realistic scenarios70. In urban environments, building construction, weather threats, and no-fly zones mainly affect drone flight trajectories. It is essential to bypass these threat zones during the drone's mission. The modeling details are as follows.
First, we set the drone start point to \(({x}_{s},{y}_{s},{z}_{s})\) and the end point to \(({x}_{d},{y}_{d},{z}_{d})\). The path of the UAV flying from the start point to the end point is formed by a set of points \(({p}_{1}, {p}_{2}, ... , {p}_{n})\). where the point \({p}_{k}\) is a point in three-dimensional space depending on \(({x}_{k},{y}_{k},{z}_{k})\). In this model, we model the cost of UAV flights, the objective function is shown in Eq. (24).
where, \({F}_{cost}\) is the total objective function, \({F}_{path}\) denotes is a function of path length, \({F}_{height}\) denotes a function of the standard deviation of the height, \({F}_{smoooth}\) is a function of the smoothness of the planning path, and \({K}_{i}\) \((i=\text{1,2},3)\) is the weight is a function of \({F}_{path}\), \({F}_{height}\), and \({F}_{smoooth}\), respectively. furthermore, the weights satisfy Eq. (25).
In this experiment, the parameters \({K}_{1}\) = 0.4, \({K}_{2}\) = 0.4, and \({K}_{3}\) = 0.2 were set.
Typically, when solving UAV path planning problems, the length of the complete planned path is critical for most path planning tasks. Obviously, shorter paths save more time, save more fuel and provide higher reliability. \({F}_{path}\) is calculated by Eq. (26).
where \(\left({x}_{k}, {y}_{k}, {z}_{k}\right)\) is the kth waypoint in the planned path.
At the same time, for most UAVs, the flight altitude should not change too much. It is well known that a stable flight altitude contributes to safety and reduces the burden on the control system. \({F}_{height}\) is calculated by Eq. (27).
where \({Z}_{meanseq}\) is calculated from Eq. (28)
However, UAVs usually operate in a very inefficient state when they are turning. So \({F}_{smooth}\) is calculated by Eq. (29).
In this section, the parameter Q is set to π as suggested. where Ci is calculated by Eq. (30)
where \({D}_{Xi}\), \({D}_{yi}\), \({D}_{Zi}\) are the differences of neighboring elements in the sequences \(x\_seq\), \(y\_seq\), \(z\_seq\), and \(n\) is the number of elements in \({D}_{X}\), \({D}_{y}\), \({D}_{Z}\).
Obstacle and Ground are the obstacle set and ground set respectively in the planning space. Here we utilize Eq. (31) to model the Obstacle set and Ground set.
Analysis of experimental results
In this section, we conduct experiments with the starting point set to \((\text{0,0},20)\) and the end point set to \((\text{200,200,30})\). In order to eliminate the chance of the calculation results, we run the algorithm independently for 30 times to find its mean value to plan the 3D UAV path. Our solution generates a path consisting of line segments. A smooth path is designed based on cubic spline interpolation using the start point, endpoint, and two points generated by metaheuristic techniques.
For a comprehensive validation of the ELRIME algorithm, three different terrain scenarios were selected for UAV 3D path planning. The three different terrain scenarios are 7 peaks, 9 peaks and 12 peaks. The experimental results are shown in Table 7.
The results in Table 7 show the best, median, worst, and mean values for 30 independent runs of the algorithm. In a 3D environment, we judge a path not only by its path length, but usually also by its smoothness and height cost, among others. Especially for UAVs, if the planned path is not smooth, it will make the UAV jittery during the mission and cannot fulfill the mission well. Similarly, the altitude of the UAV will also have an impact on the UAV's mission; if the UAV is flying too high, it will consume too much energy and will not be able to perform the mission for a long period of time. Therefore, in this section, these three factors are considered in our results. The results in the table are computed by path length cost, altitude cost and smoothness cost. Among them, path length cost and height cost account for 0.4 and smoothness cost accounts for 0.2, i.e., \({F}_{cost}\) in Eq. (18), where the path cost is calculated by Eq. (20), the height cost is calculated by Eq. (21), and the smoothness cost is calculated by Eq. (23).
Observing the data in the table, it can be seen that although the ELRIME algorithm did not obtain the optimal results in some metrics, in terms of the average results of 30 runs, the ELRIME algorithm achieved the best results in all three scenarios. In the 7-peak model, the path cost of ELRIME planning is 246.11, which is only 0.06 different from the optimal result among the 9 algorithms. In addition, in terms of the median of 30 runs and the worst result, the ELRIME algorithm achieves the best result among the 9 algorithms. The improvement over RIME is approximately twofold. In the 9-peak model, the mean and worst values planned by the ELRIME algorithm are the best among the 9 algorithms. The difference between its optimal and worst values is only 8.11, which is the most stable among the 9 algorithms. In the 12-peak model, the ELRIME algorithm is the best in all four metrics listed in the table, with an improvement of 12 in the average cost compared to the RIME algorithm, and 212 compared to the worst WOA algorithm. Most importantly, in terms of the worst cost compared to the RIME algorithm, with an improvement of 340, the cost of the ELRIME planning is only 1/2 of the cost of the RIME algorithm planning. In summary, the ELRIME algorithm achieves very good results both in terms of optimality-seeking performance and stability; it also has good robustness in different environment models with high convergence accuracy, a strong ability to jump out of local optima, and is able to effectively plan a path that is both efficient and smooth. It still has a significant advantage in complex environments.
The nine paths produced by these methods are shown in Fig. 16. From the figure, we can see that the paths generated by ELRIME are very smooth compared to the other paths.

Optimization path diagram for each comparison algorithm.
Conclusion and prospects
In this paper, we propose the ELRIME algorithm, which first introduces an elite backward learning strategy based on piecewise mapping to enhance the population diversity of the original algorithm, improving both exploration and exploitation. Secondly, a stochastic factor-controlled elite pool exploration strategy is proposed to prevent the algorithm from falling into local optima. Finally, a hard frost puncturing mechanism based on the sine–cosine function is proposed to accelerate the approach to the optimal solution, aiming to achieve the global optimum during exploitation. To test the performance of the proposed algorithm, we conduct both qualitative and quantitative analyses, which yield better results. Additionally, to verify the practicality of the algorithm, we model it based on a realistic environment and use it for 3D UAV path planning. Competitive results are obtained when compared with today’s popular intelligent optimization algorithms.
However, while this paper demonstrates that the proposed algorithm exhibits better performance, there are still many shortcomings. but it performs poorly when dealing with some multimodal functions and sometimes convergence is slow when dealing with high-dimensional problems. In addition, we have not deeply studied the population initialization and boundary control methods.
In the future, we will focus on addressing these limitations and further improving the algorithm. Additionally, we plan to apply it to more realistic problems, including robot path planning, cloud resource scheduling, and prediction problems.
Data availability
All data generated or analysis during this study are included in this published article.
References
Tian, X. Discussion on the absence of legal regulation of aerial photography act of Chinese unmanned aerial vehicle. Adv. Soc. Sci. Educ. Hum. Sci. 300, 421–425 (2018).
Gong, X. et al. Exploration of a new model of pig circular economy breeding under intelligent agriculture. J. Phys. 1622, 012070 (2020).
Li, Y. The structure of monitoring node and monitoring center of environmental monitoring system. E3S 245, 02015 (2021).
Huang, G., Hu, M., Yang, X. & Lin, P. Multi-UAV cooperative trajectory planning based on FDS-ADEA in complex environments. Drones 7, 55 (2023).
Roberge, V., Tarbouchi, M. & Labonté, G. Comparison of parallel genetic algorithm and particle swarm optimization for real-time UAV path planning. IEEE Trans. Ind. Inf. 9, 132–141 (2013).
Li, B., Li, Q., Zeng, Y., Rong, Y. & Zhang, R. 3D trajectory optimization for energy-efficient UAV communication: A control design perspective. IEEE Trans. Wireless Commun. 21, 4579–4593 (2022).
Gharehchopogh, F., Namazi, M., Ebrahimi, L. & Abdollahzadeh, B. Advances in sparrow search algorithm: A comprehensive survey. Arch. Comput. Methods Eng. 30, 427–455 (2023).
Chen, J., Zhang, Y. & Luo, Y. In A Unified Frame of Swarm Intelligence Optimization Algorithm Vol. 135 (ed. Tan, H.) 745–751 (Springer, 2012).
Tang, J., Liu, G. & Pan, Q. A review on representative swarm intelligence algorithms for solving optimization problems: Applications and trends. IEEE-CAA J. Autom. Sin. 8, 1627–1643 (2021).
Bharti, V., Biswas, B. & Shukla, K. Recent Trends in Nature Inspired Computation with Applications to Deep Learning 294–299 (IEEE, 2020). https://doi.org/10.1109/confluence47617.2020.9057841.
Winson, M. K. & Kell, D. B. Going places: Forced and natural molecular evolution. Trends Biotechnol. 14, 323–325 (1996).
Luo, Q., Wang, H., Zheng, Y. & He, J. Research on path planning of mobile robot based on improved ant colony algorithm. Neural Comput. Appl. 32, 1555–1566 (2020).
Khare, A. & Rangnekar, S. A review of particle swarm optimization and its applications in Solar Photovoltaic system. Appl. Soft Comput. 13, 2997–3006 (2013).
Zhu, Y., Wang, C., Sun, J. & Yu, F. A chaotic image encryption method based on the artificial fish swarms algorithm and the DNA coding. mathematics 11, 767 (2023).
Xu, X. & Chen, H. Adaptive computational chemotaxis based on field in bacterial foraging optimization. Soft Comput. 18, 797–807 (2014).
Karaboga, D., Gorkemli, B., Ozturk, C. & Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 42, 21–57 (2014).
Gupta, S. & Deep, K. A novel Random Walk Grey Wolf Optimizer. Swarm Evol. Comput. 44, 101–112 (2019).
Wang, Y. et al. A novel bat algorithm with multiple strategies coupling for numerical optimization. Mathematics 7, 135 (2019).
Abdel-Basset, M., Mohamed, R., Jameel, M. & Abouhawwash, M. Nutcracker optimizer: A novel nature-inspired metaheuristic algorithm for global optimization and engineering design problems. Knowl.-Based Syst. 262, 110248 (2023).
Tang, W. et al. Pyrethroid pesticide residues in the global environment: An overview. Chemosphere 191, 990–1007 (2018).
Abdel-Basset, M., Mohamed, R., Jameel, M. & Abouhawwash, M. Spider wasp optimizer: A novel meta-heuristic optimization algorithm. Artif. Intell. Rev. 56, 11675–11738 (2023).
Trojovská, E., Dehghani, M. & Trojovský, P. Zebra optimization algorithm: A new bio-inspired optimization algorithm for solving optimization algorithm. IEEE Access 10, 49445–49473 (2022).
Lynn, N. & Suganthan, P. Ensemble particle swarm optimizer. Appl. Soft Comput. 55, 533–548 (2017).
Su, H. et al. RIME: A physics-based optimization. Neurocomputing 532, 183–214 (2023).
Dehghani, M., Hubálovsky, S. & Trojovsky, P. Northern Goshawk optimization: A new swarm-based algorithm for solving optimization problems. IEEE Access 9, 162059–162080 (2021).
Zandavi, S., Chung, V. & Anaissi, A. Stochastic dual simplex algorithm: A novel heuristic optimization algorithm. IEEE Trans. Cybern. 51, 2725–2734 (2021).
Pozna, C., Precup, R., Horváth, E. & Petriu, E. Hybrid particle filter-particle swarm optimization algorithm and application to fuzzy controlled servo systems. IEEE Trans. Fuzzy Syst. 30, 4286–4297 (2022).
Deng, W., Xu, J., Gao, X. & Zhao, H. An enhanced MSIQDE algorithm with novel multiple strategies for global optimization problems. IEEE Trans. Syst. Man Cybern.-Syst. 52, 1578–1587 (2022).
Zhu, D. et al. Improved bare bones particle swarm optimization for DNA sequence design. IEEE Trans. Nanobiosci. 22, 603–613 (2023).
Priyadarshi, N., Bhaskar, M. & Almakhles, D. A novel hybrid whale optimization algorithm differential evolution algorithm-based maximum power point tracking employed wind energy conversion systems for water pumping applications: Practical realization. IEEE Trans. Ind. Electr. 71, 1641–1652 (2024).
Laboni, N. et al. A hyper heuristic algorithm for efficient resource allocation in 5G mobile edge clouds. IEEE Trans. Mobile Comput. 23, 29–41 (2024).
Shi, J. et al. Environment random interaction of rime optimization with Nelder-Mead simplex for parameter estimation of photovoltaic models. Sci. Rep. 14, 15701–15701 (2024).
Abu Khurma, R. et al. Advanced RIME architecture for global optimization and feature selection. J. Big Data 11, 89 (2024).
Gu, G., Lou, J. & Wan, H. A multi-strategy improved rime optimization algorithm for three-dimensional USV path planning and global optimization. Sci. Rep. 14, 12603 (2024).
Abdel-Salam, M., Hu, G., Celik, E., Gharehchopogh, F. S. & El-Hasnony, I. M. Chaotic RIME optimization algorithm with adaptive mutualism for feature selection problems. Comput. Biol. Med. 179, 108803–108803 (2024).
Yang, L. et al. In Particle Swarm Optimization Algorithm Based on Robust Control of Random Discrete Systems (eds Li, S. et al.) 1089–1093 (Springer, 2017).
Khalilpourazari, S. & Pasandideh, S. Sine-cosine crow search algorithm: Theory and applications. Neural Comput. Appl. 32, 7725–7742 (2020).
Nagatani, T. Complex motion of elevators in piecewise map model combined with circle map. Phys. Lett. A 377, 2047–2051 (2013).
Wang, X. & Yang, J. A privacy image encryption algorithm based on piecewise coupled map lattice with multi dynamic coupling coefficient. Inf. Sci. 569, 217–240 (2021).
Song, Y. et al. MPPCEDE: Multi-population parallel co-evolutionary differential evolution for parameter optimization. Energy Convers. Manag. 228, 113661 (2021).
Li, M., Liang, F. & Liu, J. CFO Algorithm Using Niche and Opposition-Based Learning 362–365 (IEEE, 2018). https://doi.org/10.1109/CIS2018.2018.00086.
Attia, A., El Sehiemy, R. & Hasanien, H. Optimal power flow solution in power systems using a novel Sine-Cosine algorithm. Int. J. Electr. Power Energy Syst. 99, 331–343 (2018).
Wu, D., Xu, S. & Kong, F. Convergence analysis and improvement of the chicken swarm optimization algorithm. IEEE Access 4, 9400–9412 (2016).
Wang, H. et al. Firefly algorithm with neighborhood attraction. Inf. Sci. 382, 374–387 (2017).
Yu, C. et al. SGOA: Annealing-behaved grasshopper optimizer for global tasks. Eng. Comput. 38, 3761–3788 (2022).
Wen, C. et al. Modified remora optimization algorithm with multistrategies for global optimization problem. Mathematics 10, 3604 (2022).
Sun, B., Sun, Y. & Li, W. Multiple Topology SHADE with Tolerance-based Composite Framework for CEC2022 Single Objective Bound Constrained Numerical Optimization (IEEE, 2022). https://doi.org/10.1109/CEC55065.2022.9870395.
Anantathanavit, M. & Munlin, M. Radius Particle Swarm Optimization 126–130 (IEEE, 2013).
Panda, M. & Das, B. In Grey Wolf Optimizer and Its Applications: A Survey Vol. 556 (eds Nath, V. & Mandal, J.) 179–194 (Springer, 2019).
Mirjalili, S. & Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 95, 51–67 (2016).
Abdollahzadeh, B., Gharehchopogh, F. & Mirjalili, S. Artificial gorilla troops optimizer: A new nature-inspired metaheuristic algorithm for global optimization problems. Int. J. Intell. Syst. 36, 5887–5958 (2021).
Cui, L. & Liao, J. Intelligent power grid energy supply forecasting and economic operation management using the snake optimizer algorithm with Bigur-attention model. Front. Energy Res. 11, 1273947 (2023).
Xue, J. & Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. https://doi.org/10.1007/s11227-022-04959-6 (2022).
Rather, S. & Bala, P. Constriction coefficient based particle swarm optimization and gravitational search algorithm for multilevel image thresholding. Expert Syst. 38, 12717 (2021).
Zolfi, K. Gold rush optimizer: A new population-based metaheuristic algorithm. Oper. Res. Decis. 33, 230108 (2023).
Ferahtia, S. et al. Red-tailed hawk algorithm for numerical optimization and real-world problems. Sci. Rep. 13, 12950 (2023).
Guan, Z., Ren, C., Niu, J., Wang, P. & Shang, Y. Great Wall Construction Algorithm: A novel meta-heuristic algorithm for engineer problems. Expert Syst. Appl. 233, 120905 (2023).
Oh, W., Koh, I. & O’Brien, W. Estimation of visual shade matching errors with 2 shade guides. Quintessence Int. 40, 833–836 (2009).
Mohamed, A., Hadi, A., Fattouh, A. & Jambi, K. LSHADE with Semi-Parameter Adaptation Hybrid with CMA-ES for Solving CEC 2017 Benchmark Problems 145–152 (IEEE, 2017).
Hong, L., Guo, Y., Liu, F. & Wang, B. A variant of the united multi-operator evolutionary algorithms using sequential quadratic programming and improved SHADE-cnEpSin. Inf. Sci. 622, 652–681 (2023).
Malone, C. et al. Behavioral convergence in defense behaviors in pair bonded individuals correlates with neuroendocrine receptors in the medial amygdala. Behav. Brain Res. 452, 114556 (2023).
Cheng, S. & Shi, Y. In Normalized Population Diversity in Particle Swarm Optimization Vol. 6728 (eds Tan, Y. et al.) 38–45 (Springer, 2011).
Ito, H., Ogden, R., Langenhorst, T. & Inoue-Murayama, M. Contrasting results from molecular and pedigree-based population diversity measures in captive zebra highlight challenges facing genetic management of zoo populations. Zoo Biol. 36, 87–94 (2017).
Marin-Idarraga, D., Gonzalez, J. & Medina, C. Factors affecting the effect of exploitation and exploration on performance: A meta-analysis. BRQ-Bus. Res. Q. 25, 312–336 (2022).
Luo, C., Kumar, S., Mallick, D. & Luo, B. Impacts of exploration and exploitation on firms performance and the moderating effects of slack: A panel data analysis. IEEE Trans. Eng. Manag. 66, 613–620 (2019).
Jia, C., Fang, Z., Yao, L. & Zhang, J. Tooth flank modification to reduce transmission error and mesh-in impact force in consideration of contact ratio for helical gears. Proc. Inst. Mecha. Eng. Part C 235, 4475–4493 (2021).
Burnard, M., Posavcevic, M. & Kegel, E. Examining the evolution and convergence of wood modification and environmental impact assessment in research. Iforest-Biogeosci. For. 10, 879–885 (2017).
Lee, R. & Chen, I. The Time Complexity Analysis of Neural Network Model Configurations 178–183 (IEEE, 2020). https://doi.org/10.1109/MACISE49704.2020.00039.
Mihailovic, D., Mimic, G., Nikolic-Djoric, E. & Arsenic, I. Novel measures based on the Kolmogorov complexity for use in complex system behavior studies and time series analysis. Open Phys. 13, 1–14 (2015).
Yang, L., Qi, J., Xiao, J. & Yong, X. A Literature Review of UAV 3D Path Planning 2376–2381 (IEEE, 2014).
Acknowledgements
This work is supported in part by the National Natural Science Foundation of China's top- level program under grant No.52275480, and by the National important project under grant No.2020YFB1713300, and by the Guizhou Provincial Department of Science and Technology Project under grant No.QKHZYD[2023]002 and in part by the Guiyang Science and Technology Platform Construction Project under Grant No.ZKHT[2023]7-2.
Author information
Authors and Affiliations
Contributions
Cankun Xie: Conceptualization, Methodology, Writing—original draft, Formal analysis, Data curation, Writing—review & editing, Software. Shaobo li: Conceptualization, Resources, Supervision, Formal analysis. Shenwei Fu: Visualization, Formal analysis, Writing—review & editing. Xinqi Qin: Software, Writing—review & editing, Resources. Xingxing Zhang: Methodology, Visualization Resources, Software.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xie, C., Li, S., Qin, X. et al. Multiple elite strategy enhanced RIME algorithm for 3D UAV path planning. Sci Rep 14, 21734 (2024). https://doi.org/10.1038/s41598-024-72279-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-72279-1
Keywords
This article is cited by
-
A spherical vector-based adaptive evolutionary particle swarm optimization for UAV path planning under threat conditions
Scientific Reports (2025)
-
Hybridization of metaheuristic algorithms for resource scheduling in distributed robotic control system
Discover Applied Sciences (2025)
