
Abstract
We aimed to compare the accuracy and reliability of two segmentation tools for magnetic resonance (MR) volumetry (FreeSurfer and Neurophet AQUA) at two magnetic field strengths (1.5T and 3T). We included 101 patients for the 1.5T–3T dataset and 112 for the 3T–3T dataset from three hospitals and five open-source datasets. The mean volume difference and average volume difference percentage with the change in magnetic field strength were compared between the methods. The hippocampus volume was larger with FreeSurfer than the Neurophet AQUA. In most brain regions, the Neurophet AQUA yielded a smaller average volume difference percentage (all < 10%) than FreeSurfer (all > 10%). The Neurophet AQUA exhibited more stable connectivity and regularity of the segmented components. Regarding volume, the Neurophet AQUA had effect sizes and ICCs comparable to those of FreeSurfer across the magnetic field strengths. With FreeSurfer, the original volume difference was small, whereas the average volume difference percentage was small with the Neurophet AQUA. Image segmentation took 1 h with FreeSurfer and 5 min with the Neurophet AQUA. When choosing an automatic segmentation method, the differences in image processing time and volume variability due to changes in the magnetic field strength of these methods should be considered.
Similar content being viewed by others
Introduction
Accurate and reliable analysis of structural brain volume using magnetic resonance (MR) imaging (MRI) is critical in clinical settings. In the long-term follow-up of patients with dementia, differences in image acquisition methods must be considered for clinical interpretation1. Within the same hospital, MRI equipment may be upgraded during the follow-up period, and patients can visit multiple medical centers that use different MR image-acquisition methods2,3. Such changes, including changes in scanner models and magnetic field strength, can introduce substantial variability in the results obtained from commonly used, MR-based, automatic brain segmentation software4,5,6. This variability is likely to exceed the actual effect of biological changes in the brain, potentially compromising the validity of clinical diagnoses and research results2,3.
Automated methods for brain segmentation from MR images are widely used for detailed and consistent analyses7,8. Numerous automated segmentation software programs have been clinically approved by regulatory bodies such as the U.S. Food and Drug Administration and the European Medicines Agency9. These programs are eligible for insurance claims and are extensively used in the clinical setting. For clinical use, such programs must process the results to ensure accurate interpretation of follow-up MR images, even with changes in MRI acquisition methods. However, among the many MRI parameters, a change in the magnetic field strength may have a major effect on MRI outcomes, resulting in inconsistent measurements across scans of the same patient and inconsistent results in automatic segmentation1,5.
The performance of the automatic segmentation method in terms of the minimization of variability due to differences in the magnetic field strength can be evaluated from two main perspectives: accuracy and reliability10. Accuracy can be verified through visual assessment of segmentation quality and quantitative assessment of volume measurement. Reliability can be evaluated based on whether the volumetric measurements obtained from scans of the same patient by using different magnetic field strengths yield consistent results. Both aspects should be considered, as a bias toward either accuracy or reliability will not lead to valid results in clinical practice.
The aim of this study was to investigate the effects of differences in magnetic field strength and the test-retest reliability of structural MRI measurements. We compared the performance of two automated segmentation methods: the latest version of the widely used automated segmentation software, FreeSurfer11, and a commercially available software, Neurophet AQUA. Segmentation quality was visually evaluated for the two methods. The evaluation of reliability involved the scanning of patients by using both 1.5T and 3T MRI machines within 6 months. We determined the degree of reliability of the software for two images obtained via different magnetic field strengths and for two obtained with the same field strength (3T) within 6 months. We hypothesized that the reliability of Neurophet AQUA segmentation method for brain MRI between 1.5T and 3T would be similar to that of FreeSurfer and that use of the Neurophet AQUA segmentation method would increase overall reliability of automated brain volume segmentation. Indeed, Neurophet AQUA method exhibited similar reliability to that of FreeSurfer, with its own benefits and disadvantages.
Results
Demographic characteristics
The 1.5T–3T dataset was utilized for reliability analysis, comprising a total of 101 patients: Asian (n = 30; 4 men, 26 women; age range: 55–88 years; mean ± standard deviation age: 69.5 ± 7.0 years) collected from Yonsei Severance Hospital (SEV) and Caucasian (n = 71; 39 men, 32 women; age range: 43–89 years; 73.6 ± 8.2 years) obtained from open-source databases, including the Alzheimer’s Disease Neuroimaging Initiative (ADNI)12, Open Access Series of Imaging Studies 3 (OASIS3)13, and Single Individual volunteer for Multiple Observations across Networks databases (SIMON)14. The 3T–3T dataset was also utilized for reliability analysis, comprising a total of 112 patients, consisting of Asian (n = 54; 18 men, 36 women; age range: 56–85 years; 74.0 ± 7.8 years) collected from Yeouido St. Mary’s Hospital (YID) and Boramae Hospital (BRM), Asian (n = 45; 23 men, 22 women; age range: 20–30 years; 23.5 ± 2.7 years) from the Beijing Connectivity-based Brain Imaging Research Database (C-BIRD)15, and Caucasian (n = 13; 6 men, 7 women; age range: 21–30 years; 25.2 ± 2.8 years) from the Precision In Neuroimaging database (PIN)4.
Segmentation quality
The segmentation quality was visually assessed for further comparison in this study. The evaluation was performed by comparing the ground truth (GT) produced through consensus by three radiologists with 15, 9, and 5 years of experience with Neurophet AQUA and FreeSurfer segmentation results. The evaluation variable was the Dice Similarity Coefficient (DSC), which is calculated by dividing the number of common voxels between the GT and segmentation tool result by the average number of voxels between the two results. The DSC is a number between 0 and 1, where 0 indicates that the two results have no elements in common, and 1 indicates that the two results are identical. The Dice Similarity Coefficient (DSC) was 0.8 or higher for both Neurophet AQUA and FreeSurfer regardless of the magnetic field strength in all participants (Table 1). The results of detailed regions are provided in Supplementary Table S1.
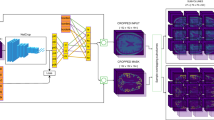
Segmentation with both methods was of sufficient quality, although subtle differences were observed. An example of 3T MR image segmentation performed on one patient using Neurophet AQUA and FreeSurfer methods is provided in Fig. 1. Compared with FreeSurfer, the Neurophet AQUA yielded stable connectivity, with the segmented region not invading other regions. As shown in the figure, this difference is especially visible in the hippocampus. FreeSurfer segmented the hippocampus by encroaching on the inferior lateral ventricle, whereas Neurophet AQUA method segmented the hippocampus into smaller parts without encroaching on the inferior lateral ventricle16.

Representative images of color-labeled images of the Neurophet AQUA and FreeSurfer segmentation methods. Examples of quality assessment for 3T MR images of one patient. On visual inspection, the Neurophet AQUA revealed stable connectivity (red arrows), and regularity of the segmented components compared to the FreeSurfer method. In the enlarged images, FreeSurfer showed rough boundaries. The differences in segmentation between the hippocampus and the inferior lateral ventricle are shown in detail in 3D. Abbreviation: MR, magnetic resonance.
Volume measurements
Table 2 provides a detailed comparison of the volumes measured using the two automated segmentation methods across various brain regions in both the right and left hemispheres17. In most regions (putamen, amygdala, inferior lateral ventricles, cerebellum, and cerebral white matter), slightly larger volumes were measured in both hemispheres via Neurophet AQUA than those measured via the FreeSurfer method (p < 0.001). In the case of the pallidum, FreeSurfer yielded larger volumes in the left hemisphere than the Neurophet AQUA (1.8 ± 0.3 vs. 2.0 ± 0.3 cm3, p < 0.001), and the Neurophet AQUA yielded larger volumes in the right hemisphere than FreeSurfer (2.3 ± 0.3 vs. 1.9 ± 0.3 cm3, p < 0.001). In the left hemisphere, the Neurophet AQUA resulted in slightly larger volumes for the caudate nucleus (3.6 ± 0.5 vs. 3.5 ± 0.6 cm3, p = 0.012), whereas no difference was observed in the right hemisphere (3.6 ± 0.6 vs. 3.6 ± 0.6 cm3, p = 0.536). Similarly, the thalamus volume was deemed larger with the Neurophet AQUA in the left hemisphere (7.5 ± 1.0 vs. 7.0 ± 1.0 cm3, p < 0.001), whereas no difference was detected in the right hemisphere (6.9 ± 0.9 vs. 7.0 ± 1.0 cm3, p = 0.827). Notably, the hippocampus volume was deemed larger with FreeSurfer in both hemispheres (3.4 ± 0.5 vs. 3.8 ± 0.6 cm3, p < 0.001 in the left hemisphere; 3.5 ± 0.5 vs. 3.9 ± 0.7 cm3, p < 0.001 in the right hemisphere). More detailed comparisons of the volume distributions of the 1.5T and 3T datasets are provided in Supplementary Tables S2 and S3, respectively.
Reliability
The comparison results of reliability across 1.5T–3T dataset are detailed in Table 3. For Neurophet AQUA, statistically significant differences in volume measurements were observed for most of the brain regions between the 1.5T and 3T datasets. Effect sizes were mostly small, ranging from − 0.409 to 0.243. Similar results were obtained using the FreeSurfer method at the same magnetic field strengths. Statistically significant differences (p < 0.001) were detected for several brain regions, (the cortical gray matter, cerebral gray matter, pallidum, thalamus, amygdala, and cerebral white matter). Effect sizes ranged from − 0.307 to 0.433, small to moderate, and ICCs ranged from 0.869 to 0.965, indicating satisfactory agreement.
The paired t-test results for both methods revealed a volume change with the magnetic field strength change. Considering both the effect size and ICC, both automated segmentation methods proved reliable in estimating brain region volumes across different magnetic field strengths.
Considering the significant volumetric discrepancies between the two automated segmentation methods (Table 2), a percentage-based comparison was added to the reliability evaluation (Table 4), to control for ROI size across the two methods.
Table 4 presents a comprehensive analysis of the average volume difference percentage (AVDP) between the Neurophet AQUA and FreeSurfer. The mean percentage difference in brain region volume between magnetic field strengths excluding relative volumetric trends between segmentation software, was assessed by calculating the amount of variance/bias in each of the datasets. The following equation was used:
This evaluation metric provides insights into the range of volumetric variability. A smaller AVDP indicates better reliability. For this analysis, four subgroups were considered: (a) segmentation of the 1.5T–3T dataset by using the Neurophet AQUA and (c) FreeSurfer, and (b) segmentation of the 3T–3T dataset by using the Neurophet AQUA and (d) FreeSurfer. As no criterion was available for evaluation of the AVDP between the 1.5T and 3T datasets, the evaluation was based on the AVDP of the 3T–3T dataset: (b) was used as the criterion for the results of (a), and (d) was used as the criterion for (b). The difference in performance between the two automatic segmentation methods is confirmed by comparing (a) and (c).
Most AVDPs were low in the 3T–3T dataset for both methods, as the magnetic field strength did not change. In the case of the Neurophet AQUA, the AVDP for the 1.5T–3T dataset was lower than that for 3T–3T dataset in the following regions: the putamen in both hemispheres (2.91%±2.48% vs. 3.04%±2.04%, p < 0.05 in the left hemisphere; 2.73%±2.49% vs. 3.21%±2.09%, p < 0.05 in the right hemisphere), the interior lateral ventricle (8.78%±9.21% vs. 11.22%±15.70%, p < 0.05), and cerebellum (2.13%±1.58% vs. 2.15%±2.12%, p < 0.05) of the right hemisphere. In the case of the AVDP of the 1.5T–3T dataset in the right thalamus of FreeSurfer was significantly lower than that of the 3T–3T dataset (5.05%±3.74% vs. 5.41%±4.48%, p < 0.05).
The performances of the two automated segmentation methods were compared in terms of reliability across the 1.5T and 3T datasets. In all regions in which a significant difference in the AVDP was detected between the two methods, the Neurophet AQUA exhibited better reliability than FreeSurfer. In most regions (the caudate, putamen, pallidum, thalamus, amygdala, inferior lateral ventricles, cerebellum, and cerebral white matter) the Neurophet AQUA yielded a significantly smaller AVDP than FreeSurfer (p < 0.05). No significant differences were observed in the cortical gray matter, hippocampus, or cerebral gray matter AVDP. Figure 2 provides a detailed visualization of the differences in magnetic field strength between the hippocampus and cerebral white matter, confirming the reliability and stability of the two automated segmentation methods. In the case of the cerebral white matter, in which a significant AVDP difference was observed, the two methods greatly differed in terms of mean and SD (3.26%±2.54% vs. 6.99%±4.42% in the left hemisphere and 3.42%±2.43% vs. 7.18%±4.58% in the right hemisphere).

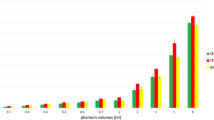
Bland–Altman plots at 1.5T and 3T X-axis: mean brain volume at 1.5T and 3T. The unit of volume on the X-axis is cm3. Y-axis: AVDP between 1.5T and 3T. The mean, lower (− 1.96 SDs), and upper (+ 1.96 SDs) limits of agreement are indicated by dotted lines. A negative difference on the y-axis indicates that the brain volume measured via 1.5T was smaller than that measured via 3T. Abbreviations: Lt, left hemisphere; Rt, right hemisphere; AVDP, average volume difference percentage; SD, standard deviation.
Discussion
The present study investigated the impact of varying magnetic field strengths on the reliability and accuracy of automated brain segmentation methods, specifically comparing FreeSurfer (version 7.1.0) and an Neurophet AQUA deep-learning-based approach. Our findings, consistent with prior research, emphasize the importance of considering MRI acquisition variations, including changes in magnetic field strength, when analyzing structural brain volumes.
Results from the latest FreeSurfer version (7.1.0) were analyzed, revealing slight differences in volume determination between FreeSurfer and our Neurophet AQUA. Although this discrepancy is statistically significant, the effect size is generally small, suggesting that the Neurophet AQUA measures volume numerically like FreeSufer. Further visual evaluation confirmed that both FreeSufer and Neurophet AQUA produced segmentation results of sufficient quality when compared to GT from an experienced radiologist. However, FreeSufer showed less smooth segmentation results than the Neurophet AQUA. In FreeSurfer, the segmentation results showed rough and uneven boundary that invaded other regions. In quantitative terms, FreeSurfer consistently resulted in larger hippocampal volumes.
Reliability analysis indicated the robustness of both methods in estimating brain region volumes across diverse magnetic field strengths. Significantly, our study showcased that our Neurophet AQUA outperformed FreeSurfer in terms of both variability and rate of change, even when confronted with varying magnetic field strengths ranging from 1.5T to 3T. With the Neurophet AQUA, the average of AVDP did not exceed 10% in any region, but with FreeSufer, the AVDP of the left amygdala (11.15%±7.71%) and the inferior lateral ventricles in both hemispheres (14.25%±13.41% in the left hemisphere and 12.61%±15.42% in the right hemisphere) exceeded 10%. Although no significant difference in AVDP was observed between the two methods for the hippocampus, the Neurophet AQUA generally yielded a more consistent AVDP than FreeSurfer.
This study contributes to the field in that we evaluated the effect of differences in magnetic field strength on automated brain segmentation methods according to small brain regions. Additionally, utilizing data from multiple hospitals and public databases, our study represents real-world data variability. A thorough reliability analysis, considering effect size and ICC, comprehensively assessed segmentation method performance. Percentage-based (ADVP) comparisons highlighted the Neurophet AQUA’s superior reliability across various brain regions.
However, this study also had several limitations. First, although we included a diverse dataset, we cannot rule out the potential influence of other uncontrolled variables, such as variations in image acquisition protocols within each magnetic field strength group. Additionally, we did not consider other factors that might have impacted the MRI data, such as differences in head position, motion artifacts, or scanner-specific hardware and software configurations4. Thus, we evaluated the variability of only the magnetic field strength. In future studies, these other factors should be explored in detail. Therefore, the generalizability of our results is limited, and they should be interpreted with caution. Second, the observed volume differences between the two automated segmentation methods, although statistically significant, may have limited clinical significance. Further research is required to determine the clinical relevance of these differences18. The same applies to the visual quality of the two methods. In this study, we targeted small brain regions. As visual confirmation of such small brain regions is challenging, the accuracy of such assessment may be improved if several experts evaluate the results of FreeSurfer and the Neurophet AQUA19.
We demonstrated that MRI datasets with different magnetic field strengths can be used to obtain robust measurements of brain volume, using both the latest version of the widely used automatic segmentation software20, FreeSurfer, and our proposed Neurophet AQUA. Both methods yielded high accuracy and reliability across different brain regions. However, the strengths and weaknesses of the two methods differ and should be considered in their selection. FreeSurfer yields a small difference in the original volume between 1.5T and 3T MR images, but considered as a variable percentage, the difference is larger than that of the Neurophet AQUA, the operation time is 1 h per image, and some image failures occurred. The Neurophet AQUA has a relatively large difference in the original volume, but the AVDP percentage is significantly smaller than that of FreeSurfer, and the SD is small; therefore, it yields more consistent results. In addition, segmentation with the Neurophet AQUA was possible within 5 min per image, and no segmentation failures occurred.
These results provide valuable insights for clinicians and researchers who use automated segmentation methods in various settings. The exceptional reliability of the Neurophet AQUA in specific brain regions suggests its potential advantages for specific applications. Further research on 7T over 1.5T and 3T MRI is needed to improve the accuracy and reliability of automated brain segmentation in clinical practice and research21.
Methods
Study participants
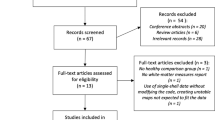
A graphical representation of the participant inclusion process is provided in Fig. 3. Data were sourced from three domestic hospitals and five publicly available databases. The following exclusion criteria were applied to participants within these datasets: (1) contraindications to MRI (e.g., a pacemaker or metal in the body), (2) history of head trauma, and (3) own or first/second-degree family history of neurological or psychiatric disorders22. After applying these exclusion criteria, the data of 233 patients were evaluated in this study, comprising 112 patients with images obtained with both 1.5T and 3T magnetic field strengths (the 1.5T–3T dataset) and 121 with both images obtained with a magnetic field strength of 3T (3T–3T dataset). To ensure data quality, we excluded images that failed the analysis in FreeSurfer and those that were blurry from the analysis, resulting in the inclusion of 223 patients in the study.

Flow chart of the study population. The flow chart of this study is organized from initial collection to final analysis. Abbreviations: CN, cognitive normal; MCI, mild cognitive impairment; AD, Alzheimer’s disease; ADNI, Alzheimer’s Disease Neuroimaging Initiative database; OASIS3, Open Access Series of Imaging Studies 3 database; SIMON, Single Individual volunteer for Multiple Observations across Networks database; C-BIRD, Connectivity-based Brain Imaging Research Database at Beijing Normal University; PIN, Precision in Neuroimaging database.
Informed consent
Use of the data obtained from the hospitals in Korea were reviewed by each institutional review board (Yonsei Severance Hospital: 1-2021-0025, Yeouido St. Mary’s Hospital: SC20DSDP0121, and Boramae Hospital: 30-2020-325) according to ethical research practices. All patients provided informed consent for the use of their data for research, and we strictly adhered to Korean data protection and privacy regulations, ensuring confidentiality and security of the data throughout the research process.
Image acquisition
MRI data were acquired using scanners from three well-known manufacturers in the field of MRI technology: Philips, SIEMENS, and GE, representing a wide range of instrument models, according to the multicenter nature of the study. The image acquisition protocols are summarized in Table 5. We believe that this dataset effectively mirrors the variability that occurs in in clinical practice.
Automated methods for image volumetry processing
T1-weighted volumetric images were processed using automated segmentation. Each patient’s brain MRI was uploaded to the server of the software tool, and both methods employed a cross-sectional pipeline for test-retest analysis. This approach involved processing the scans at every time point independently for each patient, allowing for a comprehensive evaluation of the brain structures in each MRI session.
FreeSurfer
The FreeSurfer software version 7.1.0 (https://surfer.nmr.mgh.harvard.edu, Harvard University, Boston, MA, USA) uses a template-driven approach for volumetric and surface-based segmentation11,23. The processing involved automated steps for quantification of brain region volumes and detection of potential abnormalities. Initially, data preprocessing, including motion correction, skull stripping24, and intensity normalization, was performed to enhance image quality and consistency. Subsequently, the brain was inflated to a spherical shape for precise alignment to a common spherical space by using Talairach atlas coordinates. FreeSurfer’s advanced segmentation algorithms were used to identify various brain regions, such as cortical structures, subcortical structures, and ventricles. The software provided 110 volume labels, and additional cortical or cerebral gray matter volumes were calculated using the provided formulae. However, image volumetry processing with this software demonstrated relatively low efficiency, with a processing time of 3 h per patient.
Neurophet AQUA
For the purpose of AQUA segmentation, we used the training data of 746 T1-weighted images with a high quality of 300, a medium quality of 363 and a low quality of 83. The training data also gathered considering multi-center and multi-vendor data as described in previous study25. Based on the Nested U-Net26, we developed a deep learning-based segmentation algorithm using the SAU-Net architecture25. As part of preprocessing, image resampling was performed with 1 mm iso-cubic and right-anterior-superior reorientation. A histogram-based intensity regularization was applied before the images were cropped to local patches by using uniform sampling. The local patches were fed into the network and the network was iteratively trained using data augmentation techniques such as Gaussian noise, random blur, bias field, affine transformation, and elastic deformation. In the next step, we used the 3D ResNeSt block with a channel-wise attention module and an Evolving Normalization-Activation (EvoNorm) layer in each convolution block. After this, we performed hierarchical transfer learning with freeze the weights except for the normalization and output layers using a level-wise training dataset for image quality (Fig. 4). Then, the predicted results from the 3D local patches were segmented and combined with a fixed size and overlay to segment the entire MR image more efficiently (Fig. 4). With these processes, approximately 100 regions of interest (ROIs) were obtained in the cortex and subcortex in approximately five minutes.

Illustrations of hierarchical transfer learning using a level-wise training dataset for image quality.
Statistical analysis
Statistical analysis was performed using R version 4.2.2 and Python 3.10.12 to assess brain region volumes and identify significant differences between groups. Parametric and non-parametric statistical tests were used according to the results of normality (the Shapiro–Wilk test) and equal variances (Levene’s test) tests.
We determined the differences in volume measurements by region between the two automated segmentation methods by subdividing the 1.5T and 3T datasets for each method and obtaining the original volume for each region. The volume difference between the segmentation methods for the entire dataset was deemed more important than the volume difference per patient; therefore, an independent t-test was conducted.
Reliability was evaluated for both the 1.5T-3T dataset and the 3T-3T dataset. The reliability result of the 3T-3T dataset was used as reference during evaluation of the 1.5T-3T dataset reliability. The evaluation largely comprised a comparison of the original volume and a comparison of volume percentages.
First, we used paired t-tests to evaluate the deflection of the original volume that occurred as a function of the field strength for each automated segmentation method. The ICC and effect size were calculated for accurate interpretation, considering not only the statistical significance of the differences but also their magnitude and concordance27. The reliability of each method for each magnetic field strength was assessed as the absolute agreement of single measurements by using a two-way mixed-model ICC. We interpreted the ICC values according to the following guideline: values less than 0.50, between 0.50 and 0.75, between 0.75 and 0.90, and greater than 0.9 are indicative of poor, moderate, good, and excellent reliability, respectively28. Cohen’s d was calculated as indicator of effect size to determine the practical significance of the observed differences in brain region volume. The following guidelines were used to interpret effect sizes: an effect size ≤ 0.2 is small, 0.5 is medium, and ≥ 0.8 is large29.
The non-parametric Kruskal–Wallis test was used to compare AVDP distributions between multiple groups, and the Holm test for post hoc analysis was performed to identify specific between-group differences. We conducted a more comprehensive evaluation of these disparities via Bland–Altman plots, focusing on critical regions. These plots provide a visual representation of the potential systematic biases and extent of variability among the measurements. A mean difference of approximately zero in the plot implies the absence of systematic bias. Additionally, the compactness of the agreement limits reveals the degree of disparity between the measurements at 3T and 1.5T.
All statistical analyses were two-sided and performed with the significance level set at p < 0.05. The results of the statistical tests were interpreted to draw meaningful conclusions regarding the impact of the studied factors on brain region volume.
Data availability
The data that support the findings will be available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
References
Lysandropoulos, A. P. et al. Quantifying brain volumes for multiple sclerosis patients follow-up in clinical practice – comparison of 1.5 and 3 Tesla magnetic resonance imaging. Brain Behav. 6, e00422. https://doi.org/10.1002/brb3.422 (2016).
Jovicich, J. et al. Brain morphometry reproducibility in multi-center 3T MRI studies: A comparison of cross-sectional and longitudinal segmentations. Neuroimage 83, 472–484 (2013).
Lee, H., Nakamura, K., Narayanan, S., Brown, R. A. & Arnold, D. L. Estimating and accounting for the effect of MRI scanner changes on longitudinal whole-brain volume change measurements. Neuroimage 184, 555–565 (2019).
Hedges, E. P. et al. Reliability of structural MRI measurements: The effects of scan session, head tilt, inter-scan interval, acquisition sequence, FreeSurfer version and processing stream. Neuroimage 246, 118751. https://doi.org/10.1016/j.neuroimage.2021.118751 (2022).
Ammari, S. et al. Influence of magnetic field strength on magnetic resonance imaging radiomics features in brain imaging, an in vitro and in vivo study. Front. Oncol. 10, 541663. https://doi.org/10.3389/fonc.2020.541663 (2021).
Hu, Y. et al. A multi-modal MRI data processing pipeline with test–retest reliability and predicative validity assessments. Hum. Brain Mapp. 44, 2062–2084 (2023).
Brewer, J. B., Magda, S., Airriess, C. & Smith, M. E. Fully-automated quantification of regional brain volumes for improved detection of focal atrophy in Alzheimer disease. Am. J. Neuroradiol. 30, 578–580 (2009).
van den Heuvel, T. L. A. et al. Automated detection of cerebral microbleeds in patients with traumatic brain Injury. Neuroimage Clin. 12, 241–251 (2016).
Lee, J. Y., Park, J. E., Chung, M. S., Oh, S. W. & Moon, W. J. Expert opinions and recommendations for the clinical use of quantitative analysis software for MRI-based brain volumetry. Taehan Yongsang Uihakhoe Chi 82, 1124–1139 (2021).
Heinen, R. et al. Robustness of automated methods for brain volume measurements across different MRI field strengths. PLoS ONE 11, e0165719. https://doi.org/10.1371/journal.pone.0165719 (2016).
Fischl, B. FreeSurfer. Neuroimage 62, 774–781 (2012).
Petersen, R. C. et al. Alzheimer’s disease neuroimaging initiative (ADNI): Clinical characterization. Neurology 74, 201–209 (2010).
Marcus, D. S., Fotenos, A. F., Csernansky, J. G., Morris, J. C. & Buckner, R. L. Open access series of imaging studies: Longitudinal MRI data in nondemented and demented older adults. J. Cognit. Neurosci. 22, 2677–2684 (2010).
Duchesne, S. et al. The Canadian dementia imaging protocol: Harmonizing national cohorts. J. Magn. Reason Imaging 49, 456–465 (2019).
Lin, Q. et al. A connectivity-based test-retest dataset of multi-modal magnetic resonance imaging in young healthy adults. Sci. Data 2, 150056. https://doi.org/10.1038/sdata.2015.56 (2015).
Ochs, A. L., Ross, D. E., Zannoni, M. D., Abildskov, T. J. & Bigler, E. D. For the Alzheimer’s disease neuroimaging initiative. Comparison of automated brain volume measures obtained with NeuroQuant® and FreeSurfer. J. Neuroimaging 25, 721–727 (2015).
Lee, J. Y. et al. Clinically available software for automatic brain volumetry: Comparisons of volume measurements and validation of intermethod reliability. Korean J. Radiol. 22, 405–414 (2021).
Marchewka, A. et al. Influence of magnetic field strength and image registration strategy on voxel-based morphometry in a study of Alzheimer’s disease. Hum. Brain Mapp. 35, 1865–1874 (2014).
Mulder, E. R. et al. Hippocampal volume change measurement: quantitative assessment of the reproducibility of expert manual outlining and the automated methods FreeSurfer and FIRST. Neuroimage 92, 169–181 (2014).
Gronenschild, E. H. B. M. et al. The effects of FreeSurfer version, workstation type, and Macintosh operating system version on anatomical volume and cortical thickness measurements. PLoS ONE 7, e38234. https://doi.org/10.1371/journal.pone.0038234 (2012).
Kerchner, G. A. Ultra-high field 7T MRI: A new tool for studying Alzheimer’s disease. J. Alzheimers Disease 26, 91–95 (2011).
Reijmer, Y. D., Leemans, A., Brundel, M., Kappelle, L. J. & Biessels, G. J. Disruption of the cerebral white matter network is related to slowing of information processing speed in patients with type 2 diabetes. Diabetes 62, 2112–2115 (2013).
Dale, A. M. & Fischl, B. Sereno, M. I. Cortical surface-based analysis. Neuroimage 9, 179–194 (1999).
Ségonne, F. et al. A hybrid approach to the skull stripping problem in MRI. Neuroimage 22, 1060–1075 (2004).
Lee, M. et al. Split-attention U-Net: A fully convolutional network for robust multi-label segmentation from brain MRI. Brain Sci. 10, 974. https://doi.org/10.3390/brainsci10120974 (2020).
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. UNet++: A nested U-Net architecture for medical image segmentation. Deep. Learn. Med. Image Anal. Multimodal Learn. Clin. Decis. Support (2018) 11045, 3–11 (2018).
Olejnik, S. & Algina, J. Measures of effect size for comparative studies: Applications, interpretations, and limitations. Contemp. Educ. Psychol. 25, 241–286 (2000).
Koo, T. K. & Li, M. Y. A Guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 15, 155–163 (2016).
Sullivan, G. M. & Feinn, R. Using effect size—or why the P value is not enough. J. Grad Med. Educ. 4, 279–282 (2012).
Acknowledgements
This research was supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute(KHIDI), funded by the Ministry of Health&Welfare, Republic of Korea (grant number : RS-2020-KH107144).
Funding
We are grateful for the financial support that made this research possible, provided by the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: RS-2020-KH107144).
Author information
Authors and Affiliations
Contributions
H.L., R.E.Y.K. and H.W.K. contributed to conceptualization.H.L. drafted the original manuscript, conducted statistical analysis, performed data collection, and prepared tables and figures. R.E.Y.K. and D.K. provided project leadership, supervised the study, granted approval, and curated the data. R.E.Y.K. and H.W.K. participated in study supervision, formal analysis. M.L. and J.K. contributed to software support. D.K. managed resources and funding.H.K.L., J.Y.L., and E.K. were responsible for patient data collection and care. All authors critically reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lee, H., Kim, H.W., Lee, M. et al. Evaluating brain volume segmentation accuracy and reliability of FreeSurfer and Neurophet AQUA at variations in MRI magnetic field strengths. Sci Rep 14, 24513 (2024). https://doi.org/10.1038/s41598-024-74622-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-74622-y
This article is cited by
-
Hypothalamus and intracranial volume segmentation at the group level by use of a Gradio-CNN framework
International Journal of Computer Assisted Radiology and Surgery (2025)
