
Abstract
In farming scenarios, cattle identification has become a key issue for the development of precision farming. In precision livestock farming, single-feature recognition methods are prone to misjudgment in complex scenarios involving multiple cattle obscuring each other during drinking and feeding. This paper proposes a decision-level identification method based on the multi-feature fusion of cattle faces, muzzle patterns, and ear tags. The method utilizes the SOLO algorithm to segment images and employs the FaceNet and PP-OCRv4 networks to extract features for the cattle’s faces, muzzle patterns, and ear tags. These features are compared with the Ground truth, from which the Top 3 features are extracted. The corresponding cattle IDs of these features are then processed using One-Hot encoding to serve as the final input for the decision layer, and various ensemble strategies are used to optimize the model. The results show that using the multimodal decision fusion method makes the recognition accuracy reach 95.74%, 1.4% higher than the traditional optimal unimodal recognition accuracy. The verification rate reaches 94.72%, 10.65% higher than the traditional optimal unimodal recognition verification rate. The research results demonstrate that the multi-feature fusion recognition method has significant advantages in drinking and feeding farm environments, providing an efficient and reliable solution for precise identification and management of cattle in farms and significantly improving recognition accuracy and stability.
Similar content being viewed by others

Introduction
With the rapid development of information technology, precision feeding1 has gradually become an important trend in modern animal husbandry. Precision feeding is a data-driven breeding method combining individualized management and environmental control, aiming to develop optimal feeding strategies by accurately monitoring and analyzing each cattle’s physiological and behavioral data, thereby improving production efficiency and animal welfare2. Precision farming can monitor and manage the farming environment, cattle behavior, and health status by utilizing sensors, the Internet of Things, big data analysis, and artificial intelligence technologies in real time, further optimizing farming efficiency, reducing production costs, and achieving sustainable development. Among them, cattle’s water and feed intake are regarded as important biological indicators, significantly impacting precision feeding. However, since drinking and feeding scenarios usually involve multiple cattle in a limited space, such as near water and feeding troughs, the environment is often complex, and cattle are crowded. In such cases, traditional single-modal cattle identification methods may face some challenges. For instance, features such as cattle ear tags or muzzle patterns may be difficult to identify clearly due to other cattle’s occlusion, feeding or water splashing, or poor equipment angles. Under such circumstances, the accuracy of cattle identification may decrease, making it difficult to obtain specific cattle feeding and drinking amounts. Therefore, cattle identification in drinking and feeding scenarios is one of the key issues in precision farming that has not been well resolved. Exploring more comprehensive and effective identification technologies is necessary to address the challenges posed by dense cattle populations and complex environments, thereby promoting the practical application of precision feeding.
Facial recognition of cattle3,4,5, as a primary identification feature, offers high recognition accuracy in static environments due to its unique structural characteristics. Chen, X. et al.6. in the context of precision dairy farming, utilized computer vision technology to monitor the physical condition of dairy cows and proposed a new deep network model, GPN, for cattle face re-identification. The experimental results showed that the GPN model and its improved version, GPN-ST, improved Rank-1 and map accuracy by 2.8% and 2.2%, respectively. Xu, B. et al.7. addressing the shortcomings of traditional non-biometric cattle identification methods in preventing theft, fraud, and duplicate registration, proposed a novel facial recognition framework, CattleFaceNet, which combines RetinaFace-mobile net and ArcFace to enhance the accuracy of individual cattle identification. The experiments demonstrated that CattleFaceNet achieved recognition accuracy of 91.3% in real-world scenarios, with a processing speed of 24 frames per second, outperforming traditional methods and showing great potential for real-time applications. Bergman, N. et al.8 developed and validated a novel biometric identification system for real-time cattle facial detection and recognition in dairy farms. They utilized YOLOv5 and Vision Transformer models, achieving a detection accuracy of 97.8% and a classification accuracy of 96.3%, providing an efficient and accurate biometric identification method for dairy cows.
Muzzle pattern recognition9,10,11,12 has significant advantages. It provides stable and unique identification features, similar to human fingerprints, with each cattle’s nasal mucosa texture being unique. This method is non-invasive and does not require direct contact with the cattle, reducing disturbance. By leveraging modern image processing technology, nose print features can be extracted and analyzed highly, significantly enhancing recognition accuracy. Kumar, S. et al.13. proposed a deep learning-based cattle identification method to address missed identifications, incorrect animal replacements, and fraudulent insurance claims. This method primarily relies on deep learning techniques, utilizing Convolutional Neural Networks (CNN) and Deep Belief Networks (DBN) for feature extraction and encoding them through Stacked Denoising Autoencoders (SDAE). Experimental results showed that the method achieved a recognition accuracy of 98.99%, significantly improving identification performance. Kumar, S. et al.14. proposed a low-cost framework for monitoring the health of individual dairy cows by utilizing perceived behavioral data and a nose print image database, combined with incremental decision tree classification technology and accelerometer monitoring methods. This system improved the quality of nose print images through image preprocessing and classified them using Support Vector Machines and incremental decision tree classifiers. Experimental results indicated that this method achieved a unique identification accuracy of 97.99%, significantly enhancing individual identification accuracy. Li, G. et al.15. aimed to achieve efficient individual cattle identification through deep learning techniques, optimizing management and monitoring, and improving production efficiency. They researched individual identification based on nose print patterns using deep learning, collecting 4,923 nose print images and evaluating 59 models. The results showed that the best recognition accuracy reached 98.7%, and data augmentation and weighted cross-entropy loss functions improved recognition performance. Lee, T. et al.16. utilized deep learning models to identify Hanwoo cattle using nose print images in closed farm environments, using 9,230 images of 336 Hanwoo cattle and cropping images with YOLO v8. Various versions of the EfficientNet v2 model were subjected to transfer learning with different optimizers, and the results indicated that the small version of the Lion optimizer achieved a validation accuracy of 0.981. In contrast, the small version of the Adam optimizer achieved a test accuracy of 0.970, demonstrating the potential of nose print patterns for individual cattle identification.
Ear tags17, as a traditional identification method, feature unique numbers and pattern information, effectively supporting identity verification in controlled environments. In large-scale livestock farms, the application of ear tags can simplify the identification process and enhance management efficiency. As early as 1996, Johnston et al.18. proposed using ear tags for cattle identification, which later became widely adopted in cattle identification systems. Typically, a tag or electronic tag is attached to a cow’s ear, offering uniqueness and enabling the distinction of individual cattle. Subsequently, Fosgate, G. T. et al.19. evaluated the retention of plastic ear tags in a widely managed buffalo population in Trinidad. The researchers conducted an ear tag retention experiment on 32 young buffaloes and recorded the loss of tags. Using parametric survival analysis models and the Gamma distribution model, they estimated the tags’ retention time and loss rate. The results showed that the median retention time of the tags was 272 days, with a loss rate of 0.0024 per day. Although further exploration of other technologies may be needed to improve identification accuracy and durability, the current performance of ear tags in practical applications still demonstrates significant stability and reliability. Gao, T. et al.20. proposed a vision-based automatic dairy cow ear tag recognition method to address the challenges of individual cow identification in modern pastures. The method utilizes a lightweight Small-YOLOV5s model for ear tag detection, combined with DBNet and CRNN for ear tag number recognition, achieving an accuracy of 92.1%, thereby advancing intelligent dairy farming.
However, although the methods above perform excellently in specific application scenarios such as closed and large-scale livestock farms, challenges still need to be solved in practical environments like drinking and feeding due to occlusion between cattle, body interlocking, and insufficient ambient lighting. Consequently, this paper will explore a fusion recognition method that leverages the comprehensive use of multi-modal features to mitigate the impact of errors from any single modality, aiming to address occlusion issues in feeding and drinking scenarios effectively.
In the field of multi-feature fusion21,22, there are numerous successful examples demonstrating its effectiveness and advantages in various recognition tasks. In the context of cattle identity recognition, multimodal fusion technology also shows great potential. Research and practical applications worldwide indicate that integrating information from different modalities can significantly improve the accuracy and stability of recognition systems.Alay, N. et al.23. (2020) proposed a deep learning-based multimodal biometric system that combines iris, facial, and finger vein features. Using convolutional neural networks (CNNs) and the VGG-16 model, they applied Adam optimization, categorical cross-entropy loss functions, image enhancement, and dropout techniques to prevent overfitting. Experiments with feature-level and score-level fusion methods showed that the system performed excellently on the SDUMLA-HMT dataset, achieving a feature-level fusion accuracy of 99.39% and a score-level fusion accuracy of 100%.El_Tokhy et al.24. (2021) introduced a robust tri-modal biometric authentication method that combines fingerprint, iris, and voice features. The paper describes three main biometric algorithms: the first algorithm uses the Boundary Energy Method (BEM) to extract fingerprint features, normalizes and combines iris features, and applies Dimensionality Reduction Method (DRM) for voice signals, with fusion performed using Summation/Fusion Center (FFC); the second algorithm uses region-based methods for fingerprints, SIFT for iris, and high-order statistics (HOS) for voice signals; the third algorithm combines region-based methods for fingerprints, SIFT for iris, and DRM for voice signals. Results indicated that the second algorithm achieved 100% classification accuracy with an SVM classifier and Summation FFC, while the first algorithm had the shortest computation time. The first algorithm also had the lowest EER, with Karhunen-Loeve Transform (KLT) and DRM showing the lowest ROC curves. Summation FFC provided more efficient results than Average FFC, demonstrating excellent performance in single-modal, dual-modal, and tri-modal authentication.Wang, Y. et al.25. (2022) proposed a CNN-based multimodal biometric system that fuses facial and finger vein features at the feature level, using self-attention mechanisms to obtain weights for the two biometric features, combined with RESNET residual structures for feature channel concatenation. They used AlexNet and VGG-19 models to extract facial and finger vein image features. Results showed that both models achieved recognition accuracies of over 98.4%, proving the effectiveness of multimodal feature fusion.Pathan, R. K. et al.26. (2023) introduced a multi-head CNN to improve American Sign Language (ASL) recognition accuracy. They combined image data with hand gestures, trained using the “Finger Spelling, A” dataset, and employed data augmentation and dynamic learning rate adjustment strategies to avoid overfitting. The model achieved a recognition accuracy of 98.981% on the test set, providing an efficient solution for human-computer communication in the deaf and mute communities.Chu, J. et al.27. (2024) aimed to address the Named Entity Recognition (NER) problem in aerospace field text data, proposing a model based on a Multi-Feature Fusion Transformer (MFT). This model combines lexical and radical features and uses a dual-layer feedforward neural network to enhance performance. Training on an aerospace dataset containing 30,000 Chinese sentences, the MFT model achieved an F1 score of 86.10%, demonstrating excellent entity recognition capabilities.
In modern precision livestock farming, cattle identity recognition faces significant challenges in drinking and feeding scenarios. These challenges mainly arise from obscuring and interlocking among cattle, which lead to the loss or misidentification of traditional single-modal features. To address this issue, this paper proposes a multi-feature decision-level fusion method, integrating three features: cattle faces, muzzle patterns, and ear tags, to tackle the identification difficulties of cattle in complex environments.The main contributions of this study are as follows:
-
(1)
Proposed Multifeature Decision-Level Fusion Method: This study proposes a method that integrates three features: cattle face, cattle muzzle pattern, and cattle ear tags. Given the compatibility challenges among these features, a decision-level fusion strategy was employed. Decision-level fusion is particularly well-suited for heterogeneous features with strong complementarity, combining the recognition results from different features, significantly improving overall recognition accuracy.
-
(2)
Implemented Multifeature Segmentation and Encoding: The method employs the SOLO algorithm to segment features of the cow’s face, nose print, and ear tag, reducing unnecessary information interference. Features are then extracted using FaceNet and PP-OCRv4 networks. After matching with the Ground truth, the Top 3 features are extracted, and the cattle IDs are converted into numerical vectors using One-Hot encoding to facilitate processing by machine learning algorithms.
-
(3)
Optimized Feature Selection and Model Fusion: By extracting the top 3 features to expand the search range, various classifiers, and ensemble learning methods were compared and selected at the decision level, ultimately optimizing the fusion recognition model.
The structure of this study is as follows: Section 1 introduces the dataset construction, outlines the organizational framework of the study, including SOLO model instance segmentation, single-modal feature extraction, and decision fusion model input and selection, and explains the performance evaluation metrics. Section 2 discusses the hyperparameter tuning of various models, compares single-modal experimental results and testing times, evaluates and analyzes fusion layer classifiers and ensemble models, and visualizes the results of single-modal and multi-feature decision fusion. Section 3 verifies the significant improvement in cattle identity recognition accuracy achieved by multimodal fusion technology in complex scenarios and highlights its potential for future applications in precision livestock farming for drinking and feeding scenarios. Section 4 summarizes the research and outlines future development directions.
Materials and methods
Dataset
The image data comes from Wulagai Ranch, Sunit, and Chahar Ranch in the Inner Mongolia Autonomous Region. In order to obtain comprehensive and high-quality data, the image acquisition needs to consider the effects of cattle breed differences, different scene environments, and the effects of smudging on facial occlusion on model recognition. The experiment includes 566 cattle of various breeds, as shown in Fig. 1, including Simmental cattle, Holstein cattle, West China cattle, Angus cattle, local yellow cattle, etc. It also expands the range of application scenarios, reduces the limitations, and makes the experiment more universal.
The collected data mainly consists of photos of cattle in the environment of feeding and drinking on the breeding farm, with multiple angles, front face, side face, etc., for each cattle. In addition, in order to collect as many cattle face images as possible, the photos collected in the natural state were used as supplementary data for the experiment, such as the behavior of the cattle eating grass, chewing, etc. After the video camera captured the videos of the cattle, the captured videos were classified, filtered, and decomposed into a series of consecutive image frames, and the apparent facial biometric features were carefully selected for the experiments, and the blurred photos, such as the obscurantist were removed, and the same pictures of the same cattle were saved into the same folder in the same classification.

Cattle datasets.
A total of four datasets were collated, and a variety of data enhancement techniques (random cropping, rotation, scaling and light adjustment, etc.) were used to increase the diversity of the data, which were the cattle face dataset, cattle mouth shape dataset, cattle ear tagging dataset, and the fusion dataset:
-
The cattle face dataset comprises 566 cattle with 12,284 images for training and testing.
-
The cattle muzzle pattern dataset contains 6,902 images from 194 cattle for training and testing.
-
The cattle ear tag dataset consists of 183 cattle with 3,457 images for training and testing.
-
The fusion dataset consists of 176 cattle with 5,499 images for training and testing.
In these datasets, the images in the first three datasets are divided into training and testing sets in an 8:2 ratio. Each of the three individual modality models is trained and fine-tuned separately, with the best weights selected as the final parameters for each model. This step establishes a solid foundation for the subsequent decision fusion model. In the fusion dataset, images from the previous cattle face dataset that include all three key features—cattle face, cattle muzzle pattern, and cattle ear tag—are selected. Here, this coded vector dataset is divided according to the ratio of 8.5:1.5, with 85% used as the training set and 15% as the test set. Due to the multimodal blending involved, more training data is inherently needed to ensure that the model can adequately learn and fuse the different features and that the model has enough data for adequate learning and parameter tuning. This ratio not only ensures the effective fusion of different features by the model but also provides enough test data to evaluate the performance and reliability of the model, which makes the final fusion effect better.
Methodology
General framework
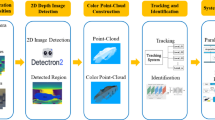
In precision farming scenarios such as feeding and drinking, where there are numerous and complex cattle, single-feature recognition methods are prone to misjudgments or loss of information. This study proposes a decision fusion recognition method based on three single-modal features: cattle face, muzzle pattern, and ear tag. The goal is to accurately identify each cattle to support more effective management of water intake and feed consumption, thereby ensuring the health and growth of the cattle. The overall experimental framework is illustrated in Fig. 2. The facial images of the cattle captured by the camera are transmitted to the background system. Preprocessing is done first, and the video is decomposed into a series of consecutive image frames, each representing a point in time in the video and usually measured in terms of frames per second (FPS). Simultaneously, diversified data augmentation techniques (such as rotation, scaling, and brightness adjustment) are applied to increase the diversity of the data. Subsequently, using SOLOv228 (Segmenting Objects by Locations v2), the three parts - cattle face, muzzle pattern, and ear tag - are segmented separately. Then, they are inputted into different models for single-modality recognition. After extraction, the 128-dimensional feature vectors of the cattle’s face and muzzle pattern, along with the ear tag text information, are matched with the Ground truth to extract the Top 3 features. Next, the cattle IDs are encoded using One-Hot encoding, and finally, the distance information along with the encoded One-Hot vectors is used as the final input for the decision layer fusion.
In the decision layer fusion part, different base learners and various integrated learning methods, such as Decision Tree, Logistic Regression, Bagging, VotingClassifier, etc., are used, and the best-performing method is selected as the final decision layer cattle identification method.

Overall design diagram.
SOLO instance segmentation
In cattle identity recognition for cattle feeding and drinking scenarios in the breeding farms, it is necessary to accurately locate and identify the parts of the cattle face, the cattle muzzle pattern, the ear tag, etc. To significantly reduce the retrieval time of the whole image and to be able to focus on a specific part of the image to a greater extent, SOLOv2 is introduced here to achieve the accurate segmentation of each part to realize background denoising. The SOLOv2 model is used as a state-of-the-art instance segmentation algorithm. Compared with the traditional segmentation methods, the SOLO algorithm is a combination of target detection and semantic segmentation, which reduces the processing flow of multiple stages, improves the system’s overall efficiency, dramatically accelerates the recognition speed of each unimodal model, and improves the accuracy. The SOLO algorithm is superior in dealing with small target objects, which is very suitable for dealing with the cattle’s facial feature information. It can dynamically segment each cattle face instance in the image without using the traditional anchor frame, normalization, or bounding box detection methods. The model structure is shown in Fig. 3, With efficient network architecture and excellent performance.

SOLOv2 cattle face instance segmentation model.
Firstly, the semantic segmentation information of the original image is obtained through the FCN (Fully Convolutional Networks) layer, which can accept input images of any size and output pixel-level predictions of the corresponding size compared to traditional Convolutional Neural Networks (CNNs). Then, an innovative approach is used to generate a mask for the cattle face, decoupling the process into two steps: mask kernel prediction and mask feature learning, which is responsible for generating the convolution kernel and the feature map convolved with it, respectively. This dynamic convolutional computation allows the model to capture the boundaries and details of the cattle accurately face instances, improving the segmentation’s accuracy. To further optimize the segmentation results, the SOLOv2 model also employs Matrix NMS (Matrix Non-Maximally Significant Value) suppression to reduce the time of the forward inference, improving the inference’s efficiency. Finally, by adjusting the transparency of the mask, the part outside the cattle face mask can be filled with white to obtain a clear foreground image of the cattle face, which effectively removes the background noise and improves the quality and usability of the image.
This study employed a step-by-step validation tuning method to select hyperparameters. Initially, a set of preliminary hyperparameter combinations was established based on preliminary experiments. Then, a series of small-scale experiments were conducted to observe the impact of each hyperparameter. Hyperparameters that showed significant improvement were fine-tuned, and the model’s performance in different scenarios was repeatedly tested and evaluated, ultimately determining the optimal hyperparameter configuration. Specifically, we used a ResNet with a depth of 50 as the backbone network and introduced Deformable Convolutions (DCN) in several stages to enhance the ability to capture edge features of cattle faces. The Feature Pyramid Network (FPN) was designed with five output layers to better handle features of cattle face, cattle muzzle pattern, and ear tag at different scales. The bounding box head (bbox_head) was set to include four classes to cover cattle faces, cattle patterns, ear tags, and backgrounds, with three layers of stacked convolutions to ensure the representation capability of multi-layer feature maps. For the loss function, the model utilized Dice Loss and Focal Loss to optimize instance segmentation and classification accuracy, respectively. The mask feature head (mask_feat_head) also used 32 normalization configurations to ensure good training performance even with smaller batch sizes. The learning rate was set to 0.01 during training and adjusted according to batch size to ensure stability. During inference, 500 candidate regions were retained to accelerate non-maximum suppression, and a masking threshold of 0.5 was set to ensure the accuracy of segmentation results.
By selecting and adjusting these hyperparameters, we customized the SOLOv2 model, significantly improving the accuracy and efficiency of cattle identification. Experimental results showed that the model achieved an average precision (AP) of 98.89% on the test set and reduced the loss function to 7.979%, indicating the model’s robustness and recognition capability. The introduction of SOLOv2 technology greatly enhanced recognition speed and efficiency. By transmitting segmented images to different models for independent recognition, with each model focusing on specific features, information mixing and redundant computations were avoided, thus accelerating the recognition process. This step-by-step approach improved recognition accuracy and increased overall processing efficiency, providing a more convenient and efficient solution for subsequent experiments and applications.
Feature extraction
The three parts of the feature-segmented images are obtained separately by the SOLOv2 instance segmentation model, which effectively removes the cumbersome background and reduces image interference, thus speeding up the recognition speed of the subsequent models. These segmented images will be used as inputs to different models to obtain the feature vectors of the cattle face and the cattle muzzle pattern, as well as the text information of the ear tag from these models as inputs to the final decision layer.
Using the foreground images of cattle faces segmented by SOLOv2 as input to the recognition model, this module employs the FaceNet neural network model for cattle face identification. FaceNet29 is an ideal choice for biometric recognition due to its powerful feature extraction capability and excellent generalization performance. Its design relies on deep convolutional neural networks, and its training on large-scale datasets enables it to capture subtle biometric feature information efficiently.
The core of FaceNet lies in its end-to-end training approach and triplet loss function. This loss function minimizes the distance between feature representations of images of the same cattle while maximizing the distance between feature representations of images from different cattle, achieving precise individual distinction in the high-dimensional feature space. This method improves recognition accuracy and enhances the model’s stability and robustness when dealing with different cattle face images.
FaceNet uses Inception-ResNet-v1 as its backbone network. This structure builds upon Inception-v430 by incorporating Residual Network (ResNet) modules. Inception-ResNet-v1 combines the advantages of multi-scale feature extraction by using parallel convolutional kernels and pooling layers to capture both local details and global information about cattle faces. The introduction of residual networks addresses the gradient vanishing problem in deep networks, allowing the network to be trained deeper, thereby improving the representation capability of features. The input to this network is 160 × 160 × 3 cattle face image, which is processed by the network to produce initial features of size 3 × 3 × 1792. The model ultimately generates a 128-dimensional feature vector through average pooling and fully connected layers, representing the unique information about the cattle’s face, as shown in Fig. 4.

Extraction of feature vectors from the network.
-
(2) Biometric feature extraction of cattle muzzle pattern.
The foreground image of the cattle’s face, segmented by SOLOv2, is input to the recognition model. The FaceNet neural network model is used in The original input image, segmented by SOLOv2, from which the cattle’s muzzle part is automatically extracted. Since the cattle’s muzzle pattern is relatively small, the pixel size is increased to obtain a higher resolution image, and the image size of the cattle’s muzzle pattern is set to 358 × 358 × 3 as the input of the model so that the model can process it more accurately. The FaceNet neural network model is also used here, and MobileNet_v1 is used as the backbone network of the FaceNet model due to its lightweight feature. It is used as a convolutional feature extractor, enabling the model to run efficiently on a computer with limited resources. It has a simpler structure than InceptionResNetv1, making it more suitable for recognizing cattle muzzle patterns without resulting in an overly large model. It is ideal for identifying the cattle’s-eye mirror texture without the phenomenon of overfitting due to the complexity of the model.
The foreground image of the cattle’s face, segmented by SOLOv2, is input to the recognition model. The FaceNet neural network model is used in The original input image, segmented by SOLOv2, from which the cattle’s muzzle part is automatically extracted. Since the cattle’s muzzle pattern is relatively small, the pixel size is increased to obtain a higher resolution image, and the image size of the cattle’s muzzle pattern is set to 358 × 358 × 3 as the input of the model so that the model can process it more accurately. The FaceNet neural network model is also used here, and MobileNet_v1 is used as the backbone network of the FaceNet model due to its lightweight feature. It is used as a convolutional feature extractor, enabling the model to run efficiently on a computer with limited resources. It has a simpler structure than InceptionResNetv1, making it more suitable for recognizing cattle muzzle patterns without resulting in an overly large model. It is ideal for identifying the cattle’s-eye mirror texture without the phenomenon of overfitting due to the complexity of the model.
MobileNetv1 is a network structure consisting of two parts: sequence convolution and 1 × 1 convolution, where sequence convolution is composed of 13 depth-separable convolutional layers, each including a 3 × 3 convolution and a batch normalization layer, after which the ReLU6 activation function is applied to accelerate the training of the neural network, while the 1 × 1 convolution serves as an output feature vector, which is then globally average pooling to reduce the size of the feature map, and after the last convolutional layer, classification is performed by a fully connected layer.
In this regard, in the unimodal training process, the cattle face and cattle muzzle pattern recognition models, respectively, used the Triplet Loss function to optimize the discriminative ability of the models by minimizing the distance between the facial feature vectors of the same cattle and maximizing the distance between the facial feature vectors of different castles, with equations such as (1):
Where N represents the number of samples, \({\left[ \cdot \right]_+}\)represents the function to take the positive value, which takes 0 when the value in the parentheses is negative, otherwise, it takes the value itself, \(\left\| {} \right.\cdot \left. {} \right\|_{2}^{2}\)represents the Euclidean distance, \(f(\cdot )\)represents the function to extract the features of the network, i, \(x_{i}^{p}\), and \(x_{i}^{n}\) denote the anchor samples, the positive samples, and the negative samples of the i th sample, respectively, and\(\alpha\)represents the hyperparameters, which are used to regulate the distances between the positive and negative samples. The unimodal model of the cattle face and cattle muzzle patterns is trained by decreasing the distance between the anchor samples and the positive samples and increasing the distance between the anchor samples and the negative samples, which makes the feature vectors learned by the model more discriminative and more accurately identifies different targets. The ternary loss function can effectively optimize the representation of feature vectors and improve the accuracy and stability of cattle face and cattle muzzle patterns recognition.
-
(3) In the actual farming environment, photographing cattle ear tags often face various challenges, such as poor lighting conditions, complex backgrounds, and tag misalignment or damage. These factors can adversely affect the accuracy of tag recognition. The PP-OCRv431 model has been designed with these real-world complexities and has undergone targeted optimizations.
Firstly, in farming settings, ear tag photography is frequently impacted by lighting variations, such as direct sunlight or shadow interference, which can lead to uneven illumination and make the text on the tag difficult to read. The PP-OCRv4 model improves its backbone network, PP-LCNetV3, to effectively extract text information from images with significant lighting changes. Additionally, the parallel branch fusion PFhead structure used in PP-OCRv4 can extract features from different image layers and fuse them, enhancing the model’s robustness in dealing with complex backgrounds. This allows the model to accurately detect and recognize text on tags even when the background is cluttered or there are interfering objects.
Secondly, ear tags in farming environments may become misaligned due to the movement of the cattle or become damaged and worn from prolonged exposure. The PP-OCRv4 model employs a dynamic adjustment strategy for the shrink ratio during text detection and recognition, which better accommodates tag misalignment and irregular shapes, thus improving recognition accuracy. The text correction module within the model can also automatically adjust the tag image when detecting tilt or distortion, ensuring the precision of the final recognition results. Furthermore, PP-OCRv4 enhances text detection in complex environments by introducing CML’s distillation loss optimization, reducing recognition errors caused by tag wear and tear.
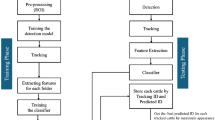
Lastly, the photographic conditions for cattle ear tags in farms can vary, which may result in images with different resolutions. PP-OCRv4 utilizes a multi-scale training strategy to handle input images of various resolutions effectively, whether the tag image is high-definition or low-resolution. This capability ensures that PP-OCRv4 can adapt to different shooting conditions in the farm environment, maintaining the stability and reliability of the recognition system, as shown in Fig. 5.

PP-OCRv4 model flowchart.
PP-OCRv4 has made numerous technical optimizations and improvements, allowing the model to maintain efficient and accurate ear tag recognition capabilities under complex and variable farming conditions. This provides strong support for cattle identification and offers significant technical assurance for applying multi-feature fusion in precision farming.
Decision fusion
For decision-level fusion, this experiment is constructed as a typical machine learning classification problem, whose core objective is to determine the final unique cattle ID by integrating the prediction results given by three independent recognition models, defining the inputs and outputs of the problem as follows:
Input
Three independent recognition models for the same image gave the top 3 predicted cattle IDs and their corresponding confidence levels.
-
Cattle face recognition model input:\(F{\text{ }}={\text{ }}\{ (I{D_{f1}},{C_{f1}}),(I{D_{f1}},{C_{f2}}),(I{D_{f1}},{C_{f3}})\}\)
-
Muzzle pattern identification model input:\(N{\text{ }}={\text{ }}\{ (I{D_{n1}},{C_{n1}}),(I{D_{n1}},{C_{n2}}),(I{D_{n1}},{C_{n3}})\}\)
-
Ear tag identification model input:\(E={\text{ }}\{ (I{D_{e1}},{C_{e1}}),(I{D_{e1}},{C_{e2}}),(I{D_{e1}},{C_{e3}})\}\)
Where \(I{D_{xi}}\) denotes the ith most probable cattle \(ID\) predicted by the recognition model, \(Cxi\) denotes the corresponding confidence level, and \(x \in \left\{ {f,n,e} \right\}\) represents the cattle face \((f)\), the cattle muzzle pattern \((n)\), and the cattle ear tag \((e)\), respectively. After considering the inputs comprehensively, decision-level fusion algorithms were employed, using several base learners and a series of ensemble classifiers in comparative experiments to select the optimal model for fusion.
Input several different features to generate unique cattle \(ID\), define a fusion formula for weighted voting (only one of the most used fusion formulas in integration is defined here), and set each candidate cattle as \(I{D_j}\), which has a confidence weighted sum in each model:
In this formula, \(\alpha ,\beta ,\gamma\) represent the weight coefficients for the cattle faces, cattle muzzle patterns, and ear tags models, respectively. The weights are adjusted based on the results of subsequent single-modal experiments. \(\delta (I{D_j},I{D_{xi}})\) is an indicator function,\(\delta (I{D_j},I{D_{xi}})=1\)when
\(I{D_j}=I{D_{xi}}\); otherwise,\(\delta (I{D_j},I{D_{xi}})=0\).
The final decision output for the cattle \(ID\) is:
Output: That is, the cattle \(ID\) with the largest confidence weighted sum is chosen as the final prediction result, denoted as \(IDfinal\).
-
(1)
Data pre-processing at the decision-making level.
Before integrating various features, data processing and storage are crucial. To achieve the best feature representation for each cattle, we manually selected the clearest, highest-quality, and most distinctive images from the fused dataset, totaling 176 sample images. These images were then input into a trained deep learning model to extract three unimodal feature vectors: cattle face, muzzle pattern, and ear tag. These features were stored as Ground truth in a Redis database.
After storing the Ground truth features, we removed these sample images from the original fused dataset, retaining 5,323 images as comparison test data. We then extracted features again using the three unimodal deep learning models and calculated the Euclidean distance and Levenshtein distance between these images and the Ground truth. For the three modalities of each image, we extracted the three nearest Top matches (a total of 9 Top matches). This method expanded the feature retrieval range and improved the accuracy of feature matching. By selecting multiple similar features, we reduced the probability of mismatches, ensuring the accuracy of subsequent identification. During this process, we ensured that each test image corresponds to 9 Top matches, each containing the cattle ID and distance information.
To prevent the influence of the size relationship between IDs on the fusion decision results, we adopted an innovative One-Hot encoding approach. The cattle IDs obtained from the matches were encoded using One-Hot encoding, with different images of the same cattle assigned a unified One-Hot code. Assuming there are N cattle in this study, the corresponding One-Hot encoding will have N dimensions. Each dimension represents a specific cattle, with the value of the dimension corresponding to the cattle ID being 1, while all other dimensions are 0. This encoding method ensures that the ID representations between cattle are independent and eliminates any ordinal relationships between categories, providing effective support for the data processing and training of the subsequent fusion model.
We then used the Top 3 features extracted from the three unimodal features (including the One-Hot encoded IDs and distance values) as the input features for decision layer fusion. In the data storage and management process, the One-Hot encoded vectors served as keys in the Redis database, bound to the unique IDs of the cattle. Redis, being a high-performance key-value storage database, is particularly well-suited for handling large-scale real-time data. In our system, each key in Redis corresponds to a One-Hot encoded vector, which is associated with the corresponding cattle ID in the database. This approach not only ensures the uniqueness and independence of each cattle feature but also significantly enhances the efficiency of database queries and feature retrieval through the binary structure of One-Hot encoding.
In summary, our data processing and storage solution offers multiple advantages for cattle IDs through One-Hot encoding. It simplifies data processing by allowing cattle IDs to be utilized as numerical vectors directly by machine learning algorithms and eliminates potential misinterpretations of order associated with numerical IDs. Furthermore, One-Hot encoding significantly enhances model performance, especially in tree-based models and neural networks, while improving database indexing and retrieval efficiency. For dynamic cattle management systems, this encoding method makes it flexible and convenient to add new cattle, providing an efficient and stable foundation for managing large-scale herds.
In multi-dimensional space, we used Euclidean distance to evaluate the similarity between feature vectors, as shown in Eq. (4):
In the experiment, the threshold is a key parameter to determine whether the similarity between two facial images of cattle is high enough to conclude that they belong to the same animal. We calculated the Euclidean distance between the 128-dimensional feature vectors and found that shorter distances indicate higher similarity. The experimental results showed that when the distance is less than or equal to 1.080, it can be determined that the images represent the same cattle; otherwise, they are different animals, as shown in Fig. 6.

Cattle face distance comparison.
For the cattle muzzle pattern feature, we similarly calculated the effect of the threshold value on the recognition result. The experimental results show that when the distance is less than or equal to 1.19, it can be determined that the cattle muzzle pattern belongs to the same cattle and vice versa for different cattle, as shown in Fig. 7.

Cattle muzzle pattern distance comparison.
For cattle ear tag information, which generally consists of numbers or letters, this experiment uses Levenshtein distance, which is used to measure the degree of difference between two strings, to calculate the similarity between the OCR recognition results and the preset labels, the formula is shown in (5). The distance \({\text{D}}(i,j)\), represents the minimum number of editing operations between the first I characters of the string M and the first j characters of the string N. \({\text{1}}(a.i. \ne bi)\) is the Indicator Function, which is used to judge whether the two characters are not the same or not, then it is recorded as 1. Otherwise, it is 0.
-
(2)
Selection of integration algorithm.
The experiment involves fusion at the highest level of image integration, the “decision layer,” using a newly created dataset as the input. We employed various base learners, such as logistic regression, decision trees, and Gaussian Naive Bayes. We combined them with multiple ensemble algorithms, including Bagging, Boosting, Stacking, and VotingClassifier, to integrate the predictions of these base learners. By applying these methods for training and testing, we aim to optimize the fusion effect and select the best-performing model.
Logistic regression is a commonly used classification algorithm for binary classification problems by mapping the output of a linear function to between 0 and 1 via a \(sigmoid\) function. In this experiment, logistic regression is used to handle the task of classification of features such as cattle face, cattle muzzle pattern, and cattle ear tag, which are extracted and used as input features to the logistic regression model to predict the category of the cattle. Here, \(p(y=1|x)\) is the probability that the output will be category 1 given input b, and \(p(y={\text{0}}|x)\) is the probability that the output will be category 0. w is the weight vector of features, and b is the bias term. The formula is as in (6):
A decision tree is a classification algorithm based on a tree structure that gradually divides the cattle-only datasets into categories through a series of decision nodes. In the construction process, the best features are selected to divide the data to construct a tree structure to represent the relationship between different categories. In this process, a critical judgment metric we focus on is the Gini Index (Gini), which is used to measure the purity or uncertainty of the datasets. The Gini Index is obtained by considering all possible categories at a given node, calculating the sum of the squares of the probabilities of occurrence of each category, and then subtracting this sum from 1. If the Gini index of a node is lower, it means that the data of that node is more pure, i.e., more samples belong to the same category. The formula for the Gini index is shown in (7):
In this equation, D is the fused dataset, y is the number of categories, and \({P_k}\) is the proportion of the k th category sample in the dataset. The Gini index measures the probability that two randomly selected samples from the dataset will have inconsistent category labels. When constructing the decision tree, we choose the division scheme that can minimize the Gini index as the optimal division to construct a decision tree model with good generalization ability.
Gaussian Naive Bayes is based on Bayes’ theorem and the assumption of independence between features. It is used to deal with classification problems with continuous type features. In this experiment, Gaussian Naive Bayes is used to deal with the cattle dataset, and the algorithm is used to model the features of the cattle and make classification predictions based on the conditional probabilities of the features. In the predictive probability formula, \(p\left( {{x_i}|y} \right)\) is the probability that the output is of category y given the input x. \(\mu y\) is the mean of feature x under category y, and \(\sigma _{y}^{2}\) is the variance of feature x under category y. Its prediction probability formula is shown in (8):
Combining the above base learners with different algorithms and characteristics for decision making, experiments were conducted using methods such as Bagging, Random Forest, and Boosting for model integration in the expectation of obtaining more complete prediction results. In addition, methods such as VotingClassifier, Stacking, etc. are added to combine the prediction results of different models and combine multiple strategies for experimental evaluation.
Bagging already reduces the risk of overfitting by randomly sampling the dataset to increase the diversity of the models, so there is no need for an additional combinatorial approach to increase the diversity of the models. Still, it is possible to compare several different base learners and compare the performance; we use the features of the cattle’s face, the cattle’s muzzle pattern, and the ear tags to train several sub-models and integrate their predictions. The formula is as in (9):
Take the fusion training set \(D=\{(x_1,y_1),(x_2,y_2),\dots,(x_m,y_m)\}\); \(\varsigma\) is the base learning algorithm; the number of training rounds is T, and the process is \({h_t}=\varsigma (D,{D_{bs}})\), \({D_{bs}}\) is the sample distribution generated by self-sampling. Random Forest is an integrated learning method comprising multiple decision trees classified by voting or averaging. Multiple features may be necessary in a cattle dataset when identifying different cattle species. By applying these features to each tree in a random forest, they can all look at the data from different perspectives and learn different patterns and regularities. In a random forest, each tree consists of different random samples and features to increase the diversity of the model. In the prediction function, \(\hat {y}\) is the final classification result, N is the number of trees, and \(fi(x)\) is the prediction result of the ith tree. The prediction function is shown in (10):
Boosting is different from Bagging in that it trains a series of weak learners through iteration, constantly adjusting the sample weights so that the cattle-only samples that were misclassified in the previous round get more attention in the next round, thus continually improving the model performance in a strong learner, standard algorithms are LightGBM, Gradient Boosting, XGBoost, etc., the sample weight update formula and the weak classifier weight calculation formula are the most core algorithms in Boosting, as shown in (11).
Where \(w_{i}^{{(t)}}\)denotes the weight of sample i in the t th iteration, \(\alpha t\) denotes the weight of the tth weak learner, \(yi\) denotes the true label of sample i, \(ht(xi)\) denotes the prediction result of the tth weak learner to sample i, and \(et\) denotes the error for the t th weak learner.
Stacking is an advanced integrated learning method that, when dealing with cattle-only datasets, composes a new feature matrix for the prediction results of each base classifier, such as the Logistic Regression mentioned above, the Decision Tree, etc., for the dataset. This feature matrix and the corresponding labels are then used to train the meta-classifier to integrate the base classifiers’ predictions better and generate the final classifier.
The VotingClassifier uses either hard or soft voting to decide the outcome of the cattle-only predictions. Hard voting is by simple majority voting as in Eq. (12), and soft voting takes into account the weights of the individual base learnings as well as the confidence level as in Eq. (13).
Where \({h_i}\) is the learner that will predict a token from the set of category tokens \(\left\{c_1,c_2,\dots c_N\right\}\), the predicted output of \({h_i}\) on sample x is represented as an N-dimensional vector \(\left(h_i^1(x);h_i^2(x);\dots h_i^N(x)\right)\), and \(h_{i}^{j}(x)\) is the output of hi on category token \({c_j}\).
In the final fusion process, we retrieved the newly encoded dataset from the Redis database and processed the features from different modalities. First, we expanded and weighted the features and reordered them according to a specific sequence. Then, the dataset was divided into training and testing sets with an 80:20 ratio. Next, the processed features were input into various base classifiers, and grid search was used to optimize the hyperparameters of each classifier to evaluate their performance.
We applied the four base learners to the Bagging, Stacking, and VotingClassifier ensemble algorithms. For Bagging, we used a single-test approach to evaluate each base learner’s performance. In the experiments with Stacking and VotingClassifier, we conducted permutation tests, trying different combinations of base learners to explore the optimal ensemble effect. Additionally, we tested three different Boosting algorithms: Gradient Boosting Classifier, LightGBM, and XGBoost.
Finally, we assessed the stability of the models through cross-validation, selected the best-performing classifiers, and determined the optimal parameter settings. The final recognition result involved comparing the predicted class labels with the cattle IDs in the database. The cattle ID was directly printed if all decision-makers output the same result. In the rare case where multiple decision-makers produced different results, we further analyzed the weights of the decision-makers and printed the result with the highest weight. This decision fusion technique enhanced the accuracy and robustness of the classifiers, making the final results more scientifically reliable.
Model performance evaluation metrics
When evaluating the classification performance of machine learning models, we need to compare the effect of single data modal models and integrate multiple data modal models. We also need to consider the performance of different classifiers and various classifiers. To objectively evaluate these models, this experiment quotes the metrics of accuracy, precision, recall, and F1 score for performance evaluation, which are formulated as follows:
-
(1)
Accuracy is the ratio of the number of samples correctly classified by the classifier to the total number of samples. Calculated as in (14):
TP (True Positive): the number of samples that the model correctly predicts as positive; FN (False Negative): the number of samples that the model correctly predicts as unfavorable; FP (False Positive): the number of samples that the model incorrectly predicts as positive, TN (True Negative): the number of samples that the model incorrectly predicts as unfavorable. TN (True Negative): the number of samples where the model incorrectly predicts a positive sample as a negative sample.
-
(2)
Precision measures the number of samples correctly predicted as positive by the classifier as a proportion of all samples predicted as positive. Calculated as in (15):
-
(3)
Recall measures the number of samples correctly predicted by the model as positive cases as a proportion of the total number of positive samples. Calculated as in (16):
-
(4)
F1_Score is the reconciled average of precision and recall, combining the accuracy and completeness of the model. Calculated as in (17):
-
(5)
Validation Rate measures the proportion of samples correctly validated by the model as positive examples out of all true positive samples, given a specific False Acceptance Rate (FAR) x. Here, x is dynamically determined and automatically selected based on the model’s performance during the validation process.Calculated as in (18):
-
(6)
False Acceptance Rate (FAR) is a measure of the proportion of negative examples (i.e., samples that are actually in the negative category) that are incorrectly predicted as positive examples by the classifier. The indicator is mainly used to evaluate the model’s ability to identify negative examples, and the lower the value of FAR is, the better the performance of the model. Calculated as in (19):
Through the comprehensive performance evaluation, their classification ability can be better judged to obtain the optimal model and algorithm. One of the things to note is that for the calculation of the experimental results of the ear tag, there may be a case of failing to identify the ear tag number. Then, there will be a case where the denominator is 0 when the above performance evaluation calculation is carried out. So, in the classification task, when a category has no samples in the real sample, the ‘zero_division’ parameter is introduced here, and the result determines that the denominator is 1, thus optimizing the experimental results.
Experiment and analysis
For the identification of cattle in feeding and drinking scenarios within a breeding farm environment, the process mainly consists of five key components: multi-part feature segmentation of the cattle, feature extraction, feature matching to extract the Top 3, ID encoding, and the final decision layer fusion.The instance segmentation and cattle face feature extraction models are successfully deployed using Tornado Web and TF Serving frameworks. Different base learners and multiple integrated learning methods are used in the decision layer to comprehensively compare the experimental results and select the best classification recognition model as the final cattle identification result. In this experiment, various data analysis methods present the experimental results by comparing the data tables and analyzing and discussing the results. In the experimental design, we compare the performance of multimodal fusion methods with that of individual models. We compare several integrated fusion strategies with the base learner fusion strategy in the fusion methods. The experiments are as follows:
Experimental environment and model parameter tuning optimization method
The system specifications, experimental setup, and model parameter tuning methods are detailed in Table 1. The decision layer fusion experiments involved conducting a grid search within a predefined parameter space, testing various parameter combinations, and evaluating each combination’s performance using cross-validation. Subsequently, based on the cross-validation results, the parameter range was refined to select the optimal parameter set for the final model. This experimental design effectively enhanced the model’s performance and generalization capability, ensuring the reliability and reproducibility of the results.
Experimental results of a single model
In the context of cattle feeding and drinking scenarios on the farm, a method integrating three features—cattle face, muzzle pattern, and ear tag—was proposed for cattle identification. By introducing SOLO instance segmentation, the original images were segmented into key areas, and the segmented images were then processed by different models, significantly accelerating the recognition speed and improving efficiency. Specifically, Inception_ResNetv1 was chosen for cattle face data due to its strong capability to handle complex detail features, providing higher recognition accuracy. Mobile-NetV1 was selected for nose ring pattern experiments to leverage its efficient computational performance and suitability for simple image features, enhancing processing speed while maintaining good accuracy. Lastly, the ear tag was recognized using the highly effective PP-OCRv4 model. This model selection strategy ensured optimal recognition performance for different features and overall system efficiency. The experimental results for each feature’s best single-modal recognition performance are summarized in Table 2.
Overall, the cattle face recognition model (Inception_ResNetv1) performs the best in accuracy, reaching 0.94352. Although its validation rate is lower at 0.78241, it shows good performance in terms of error acceptance rate. The muzzle patterns recognition model (MobileNetV1) has the highest validation rate at 0.84067 and an accuracy of 0.93939. Despite a slightly higher error acceptance rate, its overall performance is quite good. The ear tag recognition model (PP-LCNetV3) exhibits relatively stable performance, with an accuracy of 0.85399 and an error acceptance rate of 0.00032.
The difference between accuracy and validation rate typically reflects the model’s adaptability between training and validation data. While the cattle face recognition model (Inception_ResNetv1) shows the highest accuracy, its complex structure may lead to overfitting, affecting the validation rate. High accuracy often indicates excellent performance on training data, but a lower validation rate suggests insufficient generalization on new data. The higher validation rate of the muzzle pattern recognition model (MobileNetV1) indicates better adaptability to different data. However, its slightly lower accuracy might be due to the simpler model structure, which may struggle with complex feature recognition. The ear tag recognition model (PP-LCNetV3) demonstrates good stability, with relatively balanced accuracy and validation rates, and a low error acceptance rate indicates strong rejection capability for misidentifications. Therefore, the accuracy and validation rate differences are primarily attributed to model complexity, feature extraction capability, and the parameter settings during training and validation.
Regarding recognition speed, the cattle face recognition model (Inception_ResNetv1) has a processing time of 0.356 s per image. Due to its large and complex structure, including multiple layers of residual blocks and convolutional layers, it is computationally intensive, resulting in a longer recognition time. The nose ring pattern recognition model (MobileNetV1) has the shortest processing time, at 0.029 s per image. MobileNetV1’s use of depthwise separable convolutions and lightweight design significantly boosts processing speed, making it highly suitable for real-time applications. The ear tag recognition model (PP-LCNetV3) has a processing time of 0.106 s per image, which is intermediate between the cattle face and muzzle pattern models, indicating a good balance in recognition speed.
In the single-modal testing of this study, the recognition models based on cattle face and muzzle pattern features demonstrated high accuracy. However, due to the high similarity of features between individual cattle, especially in complex breeding environments, the models occasionally encountered misclassifications. A similarity score calculation method was used to evaluate the matching of cattle face and muzzle pattern features, as shown in Formula 20.
The higher the score, the greater the similarity of the match; conversely, a lower score indicates a lower similarity. As shown in Fig. 8, the images with misclassifications illustrate the matching results of the cattle face and muzzle patterns features.

Examples of the incorrect matches.
For cattle face features, the similarity score for correct matches is 0.94, while the score for incorrect matches is 0.95. For muzzle patterns, the similarity score for correct matches is 0.91, while the score for incorrect matches is 0.92. The high similarity of these features and the impact of lighting conditions have led to incorrect matches by the model. The next step in the research involves using decision fusion methods to integrate the results from cattle face, muzzle patterns, and ear tags recognition models, aiming to further improve overall recognition accuracy while maintaining a low false acceptance rate.
Additionally, we conducted a real-world test of the cattle ear tag recognition model. Using Postman for testing, the model successfully identified the ear tag numbers from the input images. The test results are shown in Fig. 9, where the ear tag number “18” has a confidence of 0.9981, and the ear tag number “0211” has a confidence of 0.9953. The model also provided the coordinates of the identified regions.

Cattle ear tags OCR recognition results.
Comparison experiments of different classifiers in the fusion layer
In this experiment, a decision layer fusion technique for cattle was explored. Four base classifiers (Decision Tree et al.) were first used to classify these features independently, aiming to evaluate each classifier’s performance when these features are used alone. By comparing the performance metrics of different base classifiers, including accuracy, precision, recall, F1 score, and validation score, we can get a preliminary understanding of the strengths and weaknesses of each base classifier. As shown in Fig. 10, some of the more common base learners, such as Decision Tree, Logistic Regression, Gaussian Naïve Bayes and Random Forest, were first selected.

Comparison of base classifiers performances.
From the analysis of the above figure, we get that logistic regression and random forest integrated all the indexes perform better, the decision tree performs worse compared to the first two, and finally, Gaussian plain Bayes performs worse in all the indexes. Further, a variety of different classifiers are combined to test the impact on classification performance, try a variety of combinations, use integrated learning methods, evaluate the combined performance of different classifiers through a variety of judging indicators, and compare the results of a variety of integrated classification, as shown in Table 3:
In this study, by comparing various ensemble learning methods, we comprehensively analyzed evaluation metrics such as accuracy, precision, validation rate, recall, and F1 score and found that the combination of Voting Classifier: Lr、RF performed the best. The logistic regression model effectively captures linear features and is suitable for handling high-dimensional data such as cattle faces, muzzle patterns, and ear tags. The core idea is to convert the output of the linear regression model into probability values using a logistic function (i.e., sigmoid function) and then classify based on these probabilities. Random Forest can handle complex nonlinear relationships and high-dimensional data, with excellent overfitting resistance, and maintains high recognition accuracy even in cases where cattle’s biological features are obscured or partially missing. Combining these two base learners in the VotingClassifier creates a natural complementarity, significantly improving recognition performance.
However, despite the theoretical performance enhancement of various multi-feature decision fusion methods, some combinations did not meet expectations, as shown in the experimental tables. This phenomenon can be analyzed from multiple perspectives. Firstly, the interaction between different modal features and optimizing fusion strategies are crucial. Improper feature fusion may lead to information redundancy or conflicts, thereby reducing the model’s overall performance. For example, some features may not significantly contribute to the final classification decision or even introduce noise, affecting recognition accuracy. Secondly, base learners’ selection and combination strategy in ensemble learning is also critical to the final performance. Although the combination of logistic regression and Random Forest in Voting Classifier performs well, other combinations, such as decision trees and Gaussian Naive Bayes, might result in decreased overall performance due to feature adaptation issues between base learners. The heterogeneity of features and the differences in base learners’ data processing capabilities may cause some ensemble methods to perform worse than single-modal methods.
Additionally, regarding the speed of the fused model, since its computation time mainly depends on the recognition speed of each single modality, the slowest result among the three single modalities can be considered a reasonable estimate for the speed of the fused model.
The final model achieved an accuracy of 95.74% across all test datasets, significantly surpassing traditional single-modal recognition methods. This multi-feature decision-level fusion technique not only effectively overcomes the limitations of single-modal recognition, such as susceptibility to occlusion and lower accuracy, but also provides a more efficient and reliable solution for individual identification and precision management in livestock farming.
Visualisation and analysis of results
To further validate the robustness and generalization capability of the experimental results, this study conducted a more detailed visual analysis of the recognition performance for both single-modal and multi-modal approaches. We tested ROC curves for four individual modalities and compared them with the ROC curve of the multi-modal fusion method to assess their respective recognition performance. As shown in Fig. 11, in ROC curve analysis, the closer the curve is to the top-left corner, the better the model’s performance. This is because the horizontal axis of the ROC curve represents the False Positive Rate (FPR), and the vertical axis represents the True Positive Rate (TPR), also known as sensitivity.

Comparison of ROC curves across different modalities.
The results show that the fusion recognition method has the curve closest to the top-left corner, indicating that it achieves a high true positive rate at a low false positive rate, demonstrating the best performance. The curve for muzzle pattern recognition ranks next, followed by ear tag recognition and facial recognition. Overall, the multi-feature fusion recognition method exhibits significant advantages in the experiments, showing better recognition performance than single-feature recognition methods.
Discussion
In modern livestock farming, precision farming requires accurate cattle feeding and drinking behavior monitoring to enhance farming efficiency and ensure herd health. However, in these complex real-world scenarios, the accuracy of cattle identification still faces numerous challenges, and its reliability and applicability need further research. To address this, we conducted validation of cattle identification during feeding and drinking processes in actual scenarios and performed small-scale tests using both unimodal and multimodal fusion recognition methods.
To achieve precise cattle identification, we selected a farm in Ar Horqin Banner, Chifeng City, Inner Mongolia. Ten cattle were randomly chosen for this experiment to validate the method in real-world conditions. A Hikvision 3T26WDV3-L 4MM camera was installed directly in front of the feeding and drinking areas. This camera features full-range rotation and automatic focusing capabilities, allowing it to capture high-precision dynamic images of the cattle’s heads and transmit them in real-time to the backend system. The backend system integrates three advanced single-modal recognition models for identifying cattle faces, muzzle patterns, and ear tags. Additionally, the system deploys a “VotingClassifier: Lr, RF” recognition model based on optimal decision-level fusion technology, combining logistic regression and random forest algorithms for accurate identification, ultimately generating a unique ID for each cattle. This allows for precise recording and analysis of each cattle’s behavior data, providing data support for precision management.
In complex real-world scenarios, factors such as cattle posture, environmental lighting changes, color patterns, and partial occlusion of features can affect the performance of single-modal recognition, as shown in Fig. 12.

Actual and complex scene.
We first conducted unimodal recognition tests with five randomly selected cattle in feeding scenarios in the experiment. For instance, as shown in Fig. 13, the unimodal cattle face recognition result for one of the cattle was ID 9,689,231,120,663, which was correct; the muzzle pattern recognition result was 258,230,825,404, which did not match the actual result; and the ear tag recognition result was ID 9,689,231,120,663, which was correct. This indicates that under conditions of sufficient lighting and clear images, the accuracy of unimodal recognition for cattle faces and ear tags is relatively high. However, muzzle pattern recognition accuracy is lower and is easily affected by occlusion and changes in lighting. There may also be cases where feed sticks to the nose, causing deviations in muzzle pattern recognition results.
In drinking scenarios, we also randomly tested five cattle with unimodal recognition. For example, as shown in Fig. 14, the unimodal cattle face recognition result for one of the cattle was ID 000060_0001, which was incorrect; the muzzle pattern recognition result was YM118273, which was correct; and the ear tag recognition result was ID YM118273, which was correct. This demonstrates that during drinking, the muzzle pattern may become clearer due to water washing, thus improving the accuracy of muzzle pattern recognition. However, reflections in the drinking scene, head movements of the cattle, or variations in coat color may interfere with cattle face recognition, leading to inaccurate results. Additionally, ear tag recognition may also be affected by ear tag detachment or obstruction by dirt, which could impact recognition accuracy.

Actual feeding scene.

Actual drinking scene.
Next, we validated the multi-feature fusion recognition models in two scenarios. In these scenarios, multiple unimodal features were separately used to extract the Top 3 features. This approach ensures an expanded search range while keeping the program from becoming overly complex or redundant, effectively processing the final results. As shown in Figs. 13 and 14, by performing decision fusion with nine features and inputting them into the final decision-level model “Voting Classifier: Lr, RF,” we obtained the correct cattle IDs.
In both feeding and drinking scenarios, the multi-feature fusion methods outperformed individual unimodal recognition results, compensating for the limitations of single-feature recognition and significantly improving the overall accuracy. This improvement can be attributed to the advantages of multi-feature fusion methods in handling issues such as cattle occlusion or missing features. By integrating features from cattle faces, muzzle patterns, and ear tags, we were able to address the limitations of unimodal recognition and enhance the overall accuracy of the identification system.The overall validation results are shown in Table 4:
As shown in the tables, the fusion accuracy reached 90%. For example, in the recognition of Cattle No. 4 and No. 6, despite errors in two of the modalities, the final fusion recognition result was still correct. This highlights the unique advantage of Top 3 feature selection. Although unimodal recognition might make errors on the first attempt, database retrieval allows for the comparison of confidence levels in the second and third choices, ultimately leading to the correct result through fusion. This significantly enhances recognition accuracy.
In real-world scenarios, unimodal recognition can be adversely affected by complex environmental factors, such as changes in lighting or obstruction by feed, especially when many cattle are gathered at a water source and body overlap may obscure some features. In such cases, the disadvantages of unimodal recognition become more apparent. Multi-feature fusion technology, by integrating recognition results from different modalities, provides a more comprehensive and accurate assessment compared to unimodal recognition. The complementarity of different features effectively reduces the errors that may arise from a single feature, improving overall accuracy and robustness.
Conclusion and future
In this study, we propose a decision-level fusion method based on cattle faces, muzzle patterns, and ear tags to address the issues faced by traditional unimodal recognition methods in farm scenarios involving cattle feeding and drinking, particularly when a single feature is obscured or missing. We first applied the SOLO algorithm for image segmentation and combined it with the FaceNet and PP-OCRv4 network models to process the segmentation results, extracting three types of features: cattle face, muzzle patterns, and ear tags. Next, we employ a Top 3 feature extraction strategy to select the most relevant features, and then perform One-Hot encoding on the cattle IDs corresponding to these features. Finally, we input the encoded IDs and distance information into the optimal model for decision layer fusion.
In the decision fusion phase, we compared various ensemble learning methods and selected the Voting Classifier with logistic regression (Lr) and random forest (RF) as the best recognition models. The experimental results show that the recognition accuracy of the multi-feature decision-level fusion method reached 95.74%, an improvement of 1.4% over traditional unimodal recognition; the verification rate was 94.72%, an increase of 10.65% compared to traditional unimodal recognition. These improvements significantly enhance the robustness and accuracy of the recognition system.
Through this precise cattle identification technology, managers can more accurately track each cattle’s growth, weight, and feed consumption, enabling personalized management. This not only improves farming efficiency and cattle health but also significantly enhances the management benefits of modern livestock farming. In the future, we will continue to explore and optimize different feature fusion strategies to further advance the intelligence and modernization of livestock farming, providing stronger technical support for precision complex farming.
Data availability
The datasets generated and/or analysed in the current study are not publicly available due to data being collected in collaboration with third-party cattle farms but are available from the corresponding author upon request.
References
Wang Guoyan. Research on precision feeding technology in animal husbandry. Agricultural Sci. Dev. 3 (3), 25–27 (2024).
Fisher, M. W. Pastoral farming ethics and economics–aligning grazing practices and expectations. Front. Veterinary Sci. 7, 209 (2020).
Weng, Z. et al. Cattle face recognition based on a two-branch convolutional neural network. Comput. Electron. Agric. 196, 106871 (2022).
Hao, W. et al. A novel Jinnan individual cattle recognition approach based on mutual attention learning scheme. Expert Syst. Appl. 230, 120551 (2023).
Xu, X., Deng, H., Wang, Y., Zhang, S. & Song, H. Boosting cattle face recognition under uncontrolled scenes by embedding enhancement and optimization. Appl. Soft Comput. 164, 111951 (2024).
Chen, X. et al. Holstein cattle face re-identification unifying global and part feature deep network with attention mechanism. Animals. 12 (8), 1047 (2022).
Xu, B. et al. CattleFaceNet: a cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 193, 106675 (2022).
Bergman, N., Yitzhaky, Y. & Halachmi, I. Biometric identification of dairy cows via real-time facial recognition. Animal. 18 (3), 101079 (2024).
Kumar, S. & Singh, S. K. Automatic identification of cattle using muzzle point pattern: a hybrid feature extraction and classification paradigm. Multimedia Tools Appl. 76, 26551–26580 (2017).
Shojaeipour, A. et al. Automated muzzle detection and biometric identification via few-shot deep transfer learning of mixed breed cattle. Agronomy. 11 (11), 2365 (2021).
Kumar, S. & Singh, S. K. Cattle recognition: A new frontier in visual animal biometrics research. Proceedings of the national academy of sciences, india section A: physical sciences 90 (4), 689–708 (2020).
Bello, R. W., Talib, A. Z. H. & Mohamed, A. S. A. B. Deep belief network approach for recognition of cow using cow nose image pattern. Walailak J. Sci. Technol. (WJST). 18 (5), 8984–8914 (2021).
Kumar, S. et al. Deep learning framework for recognition of cattle using muzzle point image pattern. Measurement. 116, 1–17 (2018).
Kumar, S., Chaube, M. K. & Kumar, S. Secure and sustainable framework for cattle recognition using wireless multimedia networks and machine learning techniques. IEEE Trans. Sustainable Comput. 7 (3), 696–708 (2021).
Li, G., Erickson, G. E. & Xiong, Y. Individual beef cattle identification using muzzle images and deep learning techniques. Animals. 12 (11), 1453 (2022).
Lee, T., Na, Y., Kim, B. G., Lee, S. & Choi, Y. Identification of individual Hanwoo cattle by muzzle pattern images through deep learning. Animals. 13 (18), 2856 (2023).
Pretto, A., Savio, G., Gottardo, F., Uccheddu, F. & Concheri, G. A Novel low-cost Visual ear tag Based Identification System for Precision beef Cattle Livestock Farming (Information Processing in Agriculture, 2022).
Johnston, A. M. & Edwards, D. S. Welfare implications of identification of cattle by ear tags. Vet. Rec. 138 (25), 612–614 (1996).
Fosgate, G. T., Adesiyun, A. A. & Hird, D. W. Ear-tag retention and identification methods for extensively managed water buffalo (Bubalus bubalis) in Trinidad. Prev. Vet. Med. 73 (4), 287–296 (2006).
Gao, T. et al. Research on the vision-based dairy cow ear tag Recognition Method. Sensors. 24 (7), 2194 (2024).
Modak, S. K. S. & Jha, V. K. Multibiometric fusion strategy and its applications: a review. Inform. Fusion. 49, 174–204 (2019).
Kushwaha, A., Khare, A. & Prakash, O. Human activity recognition algorithm in video sequences based on the fusion of multiple features for realistic and multi-view environment. Multimedia Tools Appl. 83 (8), 22727–22748 (2024).
Alay, N. & Al-Baity, H. H. Deep learning approach for multimodal biometric recognition system based on fusion of iris, face, and finger vein traits. Sensors. 20 (19), 5523 (2020).
El_Tokhy, M. S. Robust multimodal biometric authentication algorithms using fingerprint, iris and voice features fusion. J. Intell. Fuzzy Syst. 40 (1), 647–672 (2021).
Wang, Y., Shi, D. & Zhou, W. Convolutional neural network approach based on multimodal biometric system with fusion of face and finger vein features. Sensors. 22 (16), 6039 (2022).
Pathan, R. K. et al. Sign language recognition using the fusion of image and hand landmarks through multi-headed convolutional neural network. Sci. Rep. 13 (1), 16975 (2023).
Chu, J., Liu, Y., Yue, Q., Zheng, Z. & Han, X. Named entity recognition in aerospace based on multi-feature fusion transformer. Sci. Rep. 14 (1), 827 (2024).
Lu, Y. et al. A deep learning method for building facade parsing utilizing improved SOLOv2 instance segmentation. Energy Build. 295, 113275 (2023).
Schroff, F., Kalenichenko, D. & Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the lEEE conference on computer vision and pattern recognition (pp. 815–823) (2015).
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI conference on artificial intelligence (Vol. 31, No. 1). (2017).
Du, Y. et al. Pp-ocrv2: Bag of tricks for ultra lightweight ocr system. arXiv preprint arXiv:2109.03144 (2021).
Funding
This study was funded by the following projects:
Inner Mongolia Nature Science Fund (2024MS06022) ;
Inner Mongolia Nature Science Fund (2024MS06026) ;
Inner Mongolia Autonomous Region Science and Technology Programme (2023YFSW0014) ;
Science and Technology Programme of Kundulun District, Baotou City, Inner Mongolia (JB2022001) ;
Science and technology to promote the development of Inner Mongolia’s key projects (XM2021BT12) ;
Basic Research Projects of Colleges and Universities in Inner Mongolia Autonomous Region.
(2023QNJS193);
Research and Development of Cattle Lip Recognition Application System in Livestock Insurance Business (2023QNJS046).
Author information
Authors and Affiliations
Contributions
D. L. was responsible for writing the experimental section and drafting the paper; D. L. and Q. L. were responsible for the methodological design of the experimental study; D. L. and B. L. were accountable for validating the research results; Q. L. and B. L. were responsible for the formal analysis of the data; D. L. and M. H. were responsible for data collection and organization; Y. W. and Q. L. were responsible for reviewing and editing the paper; M. Y. and Y. W. assisted in the experimental research; Q. L. was responsible for supervising the entire experimental study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, D., Li, B., Li, Q. et al. Cattle identification based on multiple feature decision layer fusion. Sci Rep 14, 26631 (2024). https://doi.org/10.1038/s41598-024-76718-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-76718-x
This article is cited by
-
Semi-automated annotation for video-based beef cattle behavior recognition
Scientific Reports (2025)
