
Abstract
Object detection in drone aerial images is challenging due to the difficulty of small object detection and complex backgrounds. To address these issues, this paper proposes an improved object detection model, perception and target capture detector (PTCDet), to increase detection accuracy and robustness in complex scenes. Specifically, the proposed multiple feature extraction attention (MFEA) module significantly enhances the ability of the model to detect small objects through multidimensional feature map augmentation. The weighted perceptive field augmentation (WPFA) module is designed to improve the contextual awareness and feature representation of the model, optimizing detection accuracy for small objects. Based on the multiscale feature fusion structure, an enhanced scale fusion detection (ESFD) module is used to improve small object detection by generating larger scale feature maps. Ultimately, the inner focaler IoU loss (INFL) function effectively accelerates the regression of detection bounding boxes, enhancing the generalization ability and overall detection performance of the model. The experimental results on three public datasets demonstrate that PTCDet outperforms other detection algorithms. For example, on the VisDrone dataset, compared with the baseline model YOLOv8, [email protected] and [email protected]:0.95 are improved by 6.21% and 4.21%, respectively. PTCDet exhibits excellent performance in addressing complex backgrounds and small object detection, providing an effective and robust solution for object detection tasks in drone aerial images.
Similar content being viewed by others
Introduction
Today, drones play a significant role in various fields today because of their good mobility, ease of use, and low cost1. High-resolution aerial images can be used to detect and assess the impact of natural disasters2, such as floods, earthquakes, and fires. In agriculture, aerial images enable precise application of pesticides and fertilizers, and through advanced sensor and camera functions, they provide field monitoring data, helping farmers detect pests and diseases in a timely manner, thereby increasing crop yield and quality3. In environmental monitoring, aerial images can be used to assess air quality in real time, collect environmental data, and provide important data support for environmental protection and management4. With the development of computer vision technology, the processing and analysis of aerial images have become more intelligent and efficient, improving work efficiency and accuracy, showing great potential in multifield applications5, and substantially benefiting society.
The use of deep learning based on convolutional neural networks in object detection is widespread6,7. Deep learning methods based on convolutional neural networks can be divided into two categories according to the training process: single-stage methods and two-stage methods. Single-stage methods (such as the YOLO series8,9,10,11,12,13,14,15.) complete object detection in a unified network structure, with the advantages of fast speed and simple structure, but usually have poor detection accuracy, especially for addressing small objects and complex scenes. Two-stage methods (such as the R-CNN16,17,18,19 series) generate candidate regions and then classify and regress these candidate regions, significantly improving the detection accuracy and robustness through these staged processing steps; However, their speed is relatively slow, and the model complexity is relatively high. However, despite these methods achieving advanced performance on natural scene images (such as the MS COCO dataset), they face challenges when processing aerial images or videos, making it difficult to obtain satisfactory detection results. This is mainly because aerial images have special perspectives, lighting conditions, and background noise, which results inconsiderable variations in the appearance and size of target objects, as well as situations such as rotation and occlusion, which affect the performance of traditional object detection algorithms. Object detection in aerial images faces the following challenges: (1) Low-altitude images usually contain many densely packed small objects, making it difficult to detect distant objects because of their smaller size, and dense scenes may cause occlusion, increasing the difficulty of object detection; (2) Due to hardware resource limitations, general object detection algorithms reduce the size of high-resolution aerial images (e.g., downsizing to \(320\times 320\) or \(640\times 640\)), which may result in small objects being overlooked during detection; and (3) Object detection in aerial images must be performed in real-time, requiring a balance between the number of network parameters and accuracy. To address these issues, an increasing number of researchers have focused on small object detection.
However, existing small object detection algorithms face limitations in receptive fields, insufficient feature fusion, and poor performance in scenarios with low resolution and dense occlusion, especially in highly complex backgrounds or densely packed small object scenes. To address the critical challenges in UAV aerial image target detection, particularly the difficulties of accurately detecting small objects in complex backgrounds and varying scales, a perception and target capture detector(PTCDet) model is proposed, whose the main contributions are as follows:
-
1.
Enhanced Small Object Detection through the MFEA Module: The proposed multiple feature extraction attention (MFEA) module significantly improves the ability of the model to detect small objects in high-density and scale-variant scenarios. By integrating channel, spatial, and coordinate attention mechanisms, the module enhances the discrimination abilities of the model, enabling it to capture and distinguish subtle features more effectively, thereby addressing the challenge of detecting small and densely packed objects.
-
2.
Improved Contextual Awareness with the WPFA Module: The weighted perceptive field augmentation (WPFA) module is introduced to increase the contextual awareness and feature representation of the model. This module dynamically adjusts the receptive field, allowing the model to better understand and process objects of varying sizes and shapes, which is particularly challenging in aerial imagery where objects often appear in complex and cluttered backgrounds.
-
3.
Enhanced Scale Fusion with ESFD Module: To overcome the limitations of conventional multiscale feature fusion, the enhanced scale fusion detection (ESFD) module is incorporated. This module generates larger scale feature maps that are more effective in capturing the details of small objects, which are often lost during downsampling in traditional networks, thus improving detection performance in scenarios with small, low-resolution targets.
-
4.
Accelerated Bounding Box Regression with the INFL-CIoU: The inner focaler IoU loss (INFL) function replaces the traditional CIoU loss, offering a more nuanced approach to bounding box regression. By employing auxiliary boxes of varying scales, this function accelerates the convergence of bounding boxes, especially for small objects, and improves the generalization ability of the model across different detection tasks, addressing the challenge of balancing detection accuracy with computational efficiency.
-
5.
Comprehensive Evaluation and Superior Performance: Extensive experiments conducted on the VisDrone, AI-TOD, and TinyPerson datasets demonstrate that the proposed PTCDet model outperforms existing detection algorithms. The model shows significant improvements in terms of the [email protected] and [email protected]:0.95 metrics, particularly in scenarios involving small object detection and complex background handling, highlighting its robustness and effectiveness.
The remainder of this paper is organized as follows: In “Background and related works”, we provide an overview of the YOLOv8 architecture and related work on small object detection. “Methods” details the improved model. “Experimentation and analysis” introduces the dataset used in our study, as well as the experiments and analysis. Conclusions are drawn in “Conclusion”.
Background and related works
Introduction of YOLOv8

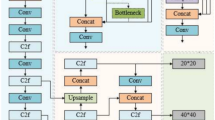
Diagram of the YOLOv8 network structure.
The YOLOv8 model architecture consists of four main parts: the input, backbone, neck, and head. Each part plays a crucial role, collectively ensuring the performance and efficiency of the model, as shown in Fig. 1.
In the input part, YOLOv8 adopts mosaic data augmentation technology, which creates a new hybrid image by randomly combining segments of multiple training images, thereby achieving rich scene representation and background variation to enhance the generalization ability of the model. Additionally, for different model configurations, YOLOv8 adjusts specific hyperparameters, such as enabling MixUp and CopyPaste data augmentation methods in larger models, to further enhance data diversity and model robustness during training.
The backbone part is primarily responsible for extracting necessary feature information from the input images. This part consists of several Conv modules, C2f modules, and an SPPF at the end. Each Conv module contains a Conv2d layer, a Batch-Norm2d layer, and an activation function, used to refine and process image features.
The C2f module draws on the residual connection design of the C3 module and the ELAN structure in YOLOv7, optimizing gradient flow and retaining rich feature information while ensuring that the model remains lightweight. SPPF20 enhances the adaptability of the model to scale variations by aggregating features at different scales.
The neck part is dedicated to feature fusion, utilizing a structure that combines a feature pyramid networks(FPN)21 and a path aggregation network(PAN)22 to enhance the semantic representation and localization accuracy of features extracted from the backbone at multiple scales. The head part is the output end of the model, processing the accumulated feature information to perform object classification and localization tasks.
In YOLOv8, the head adopts a decoupled head structure, separating classification and localization into independent subtasks to improve efficiency through focused differential processing. Additionally, the model removes the traditional anchor-based design and instead uses an anchor-free approach, which reduces the number of hyperparameters the model depends on and accelerates the detection process.
Related works
For small object detection, Wang et al.23 proposed the YOLO-ERF model, which embeds an effective receptive field (ERF) module in the backbone network, extending the receptive field of the convolutional kernel while maintaining rich local details. This enhances model performance in recognizing and locating small-scale objects in complex scenes without the need for additional context modules. The CGMDet multiscale object detector proposed by Zhou et al.24 uses the coordinate and global information aggregation module (CGAM) and feature fusion module (FFM). Combining positional information from lower-layer feature maps and improved bounding box regression loss, enhances the richness of contextual information, the effectiveness of multiscale feature fusion, the accuracy of small object detection results, and the convergence speed of the model. The improved YOLOv8s method proposed by Ma et al.25 enhances robustness to complex backgrounds and retains more fine-grained features by replacing the downsampling module and path aggregation network, thereby improving the detection of very small objects in complex scenes. Tang et al.26 improved the YOLOv7 network by reconstructing it, adding micro-object detection layers, and introducing recurrent gated convolution modules and coordinate attention mechanisms. This enhances the detection capabilities in dense occlusion scenarios with low-resolution images and reduces the inference time. Wang et al.27 proposed SADENet, which addresses information loss by designing a sample vertebra structure and introduces an enhanced context attention module (ECAM). By combining high and low-resolution feature maps and a bidirectional connection neck structure, the ECAM effectively improves the accuracy and robustness of small object detection in complex environments. Xiao et al.28 proposed a novel feature pyramid composite neural network structure, including a context enhancement module (CEM) and a feature purification module (FPM). By using multiscale dilated convolution features in the CEM to enhance contextual information and employing channel and spatial dimension purification processes in the FPM to fuse multiscale features, it effectively eliminates conflicting information and improves the performance of small object detection. Zhang et al.29 proposed Quad-FPN, which consists of four unique FPNs, ensuring excellent detection performance and adaptability to various scenarios. Xu et al.30 introduced GWFEF-Net, which enriches the feature library via dual-polarization feature enrichment (DFE), enhances and fuses multiscale polarized features via group-wise feature fusion (GFF), and balances the contribution of each polarized feature with hybrid pooling channel attention (HPCA), thereby reducing the false detection rate.
Methods

PTCDet network structure.
For object detection in UAV aerial images, high density and diverse proportions of small objects in the images are frequently encountered, which significantly increases the complexity of detection. Although the traditional YOLOv8 network structure has demonstrated good detection performance in multiple scenarios, its performance is insufficient to meet the increasingly stringent accuracy and response speed requirements for such specific scenarios. The primary challenge is the limited ability of the model to recognize small, highly overlapping, and dynamically changing targets, which directly affects the accuracy and real-time performance of detection.
In view of the aforementioned issues, this study chooses YOLOv8 as the starting point and base model, and proposes the PTCDet model, whose detailed structure is shown in Fig. 2. The multiple feature extraction attention (MFEA) module effectively addresses the issue of low accuracy in small object detection and the interference of complex backgrounds in aerial images. Given that small objects are predominant in detection tasks, an enhanced scale fusion detection (ESFD) module is added to YOLOv8. This layer handles relatively high-resolution feature maps, making it extremely suitable for capturing small-sized targets that are easily lost in low-resolution feature maps. In the diagram, the purple sections represent our ESFD module. Additionally, the weighted perceptive field augmentation (WPFA) module is utilized to capture information more flexibly, thereby better adapting to features of different sizes and shapes. An inner focaler IoU loss (INFL) that consider the varying regression difficulties of different samples in the regression branch is proposed. By integrating the above components, PTCDet achieves excellent performance on multiple publicly available datasets.
Multiple feature extraction attention
In the current field of object detection, especially for small object detection, traditional feature extraction methods often perform poorly in high-density and scale-variant scenarios. Moreover, during the downsampling process, important details in the feature maps are frequently lost, which is particularly detrimental to the detection of small objects. To address these issues, this paper proposes a multiple feature extraction attention (MFEA) module. This module enhances the representation capability of feature maps from multiple dimensions by combining channel, spatial31, and coordinate attention mechanisms32, significantly improving the performance of small object detection. The specific structure is shown in Fig. 3.

Multiple feature extraction attention module.
The channel attention mechanism enhances model performance by emphasizing the importance of each channel in the feature map(C*H*W). The input feature map undergoes max pooling and average pooling operations, compressing the input feature map into a single value for each channel(C*1*1) and generating two different channel descriptors. These descriptors are then processed through a shared multilayer perceptron (MLP), which consists of a convolution layer, a ReLU activation function, and another convolution layer. This shared MLP reduces the number of parameters and computational complexity while ensuring consistency when the max pooling and average pooling outputs are processed. The processed pooling results are summed and passed through a sigmoid activation function to generate channel attention weights. These weights are multiplied by the original feature map, ultimately enhancing the feature representation capability of key channels.
The spatial attention mechanism enhances the spatial perception of the model by emphasizing the importance of specific spatial locations in the feature map. Specifically, the feature map undergoes max pooling and average pooling operations along the channel dimension, resulting in two single-channel feature maps(1*H*W). These two feature maps are then concatenated along the channel dimension to form a two-channel feature map. The concatenated feature map is processed by a convolution layer and a sigmoid activation function to generate spatial attention weights. These weights are multiplied by the original feature map, highlighting important areas in the feature map and thereby enhancing the feature representation capability of key spatial locations.
The coordinate attention mechanism combines channel and spatial attention to capture long-range dependencies in the feature map. The input feature map undergoes adaptive average pooling operations along the horizontal and vertical directions, generating two single-channel feature maps. Their sizes are C*H*1 and C*1*W, respectively.The horizontally pooled feature map retains its original width but compresses its height to 1, whereas the vertically pooled feature map retains its original height but compresses its width to 1. These two pooled feature maps are then concatenated along the channel dimension and processed by a convolution layer, followed by batch normalization and nonlinear activation. The processed feature map is then split again along the height and width dimensions and passed through two separate convolution layers and sigmoid activation functions to generate attention weights for the horizontal and vertical directions.These weights are multiplied by the original input feature map to reweight the original features, thereby enhancing the spatial and channel dependencies.
The MFEA module processes the input feature map through channel attention mechanism, spatial attention mechanism, and coordinate attention mechanism, obtaining three weighted feature maps. These three weighted feature maps are then concatenated along the channel dimension, and the number of channels is restored to the channel count of the original input via convolution. The output feature map integrates the advantages of all three attention mechanisms, allowing for more accurate capture of global information, spatial information, and directional information in the feature map. The output feature map is added to the original input feature map, preserving the input features and avoiding gradient vanishing and information loss. This module significantly enhances the ability of the model to capture detailed features in complex scenes while maintaining low computational cost, thereby improving the overall model performance. By incorporating multiple feature extraction strategies, the MFEA module excels in high-density and scale-varying scenarios, making it particularly suitable for small object detection tasks.

RFAConv module.
Weighted perceptive field augmentation module
In unmanned aerial scenarios, the number of small targets may be large, and as a result, traditional convolutional methods may face some issues. Traditional convolution operations usually focus only on local region features and disregard global contextual information. Therefore, this paper utilizes RFAConv33, which allows the network to focus on key information within specific regions and better consider global contextual information, effectively capturing the features of the target and its surrounding environment. The structure is shown in Fig. 4.
The input feature map \(\gamma\) is averaged, and a 1x1 convolution kernel is used to perform a convolution operation on it, obtaining the weight \(\gamma ^w\) at each pixel position. These weights can be regarded as the importance of each pixel point to the entire image, providing important prior information for subsequent feature-weighted fusion. This allows the network to learn and utilize key features in the image more effectively. The weight \(\gamma ^w\) at each pixel position can be represented by the following formula:
where i represents the sample index in the training batch, j represents the channel index, k represents the pooling convolution kernel size, and m and n represent the indices within the pooling kernel. Then, the weights W are normalized via the Softmax function to obtain the attention weights A at each position.
Next, to increase the nonlinear expression ability of the network and receptive field size during feature extraction, group convolution operations are performed on the input feature map \(\gamma\). The input feature map is divided into multiple groups, and each group undergoes independent convolution operations. The outputs of these groups are then combined to generate the corresponding feature representation F.
Where K is the convolution kernel, and \(*\) denotes the convolution operation. The feature representation F is multiplied by the corresponding attention weights A to obtain the weighted fused feature \(F'\), enabling the network to focus more on features useful for target detection and reducing interference from irrelevant information. This operation can be represented as:
The weighted fused feature \(F'\) is passed through a convolutional layer, resulting in the final output feature Y.

WPFA module.
The combination of RFAConv and the C2F module forms the weighted perceptive field augmentation (WPFA) module, whose structure is shown in Fig. 5. Compared with the bottleneck, which focuses only on local feature extraction, RFAConv significantly enhances the capture and fusion of global contextual information by integrating a weighted receptive field perception mechanism. This improvement enables the model to focus more precisely on key information areas in the image, optimizing feature representation capability. By introducing group convolution, RFAConv further expands the receptive field of the model, enhancing its adaptability to targets of different sizes and complexities. The integration of the attention mechanism and weighted feature fusion not only strengthens the response of the model to important features in target detection but also effectively filters background noise, increasing higher accuracy and robustness in small object detection tasks. In summary, the WPFA module is better suited for small object detection in high-complexity drone-view images.
Enhanced scale fusion detection module
For object detection in dense crowds, the YOLOv8 model faces significant challenges. Occlusion caused by crowd density and the presence of small targets in the image often lead to missed detections. Additionally, the large downsampling factor of YOLOv8 makes it difficult for deeper feature maps to capture the details of smaller targets. As a result, small target features tend to disappear during the downsampling process, exacerbating the problem of missed detections.
To address these issues, this paper proposes an enhanced scale fusion detection (ESFD) module. This module introduces an innovative scale fusion branch to obtain information from \(160\times 160\) resolution feature maps, thereby capturing more shallow features of small targets. By upsampling and concatenating feature maps of different resolutions, the ESFD module effectively fuses shallow and deep feature maps, significantly improving the detection performance for small targets.
The introduction of the ESFD module effectively optimizes the performance of the YOLOv8 model in handling dense crowds and small object detection. By capturing more detailed information, the model significantly improves its ability to recognize targets of different scales while maintaining high resolution. This ensures robustness and accuracy in complex scenes. When the ESFD module is integrated, the PTCDet model demonstrates outstanding performance on multiple publicly available datasets, particularly in scenarios involving dense crowds and small object detection. The enhanced cross-scale information capture capability makes the model more robust and reliable in various complex environments.
Inner focaler IoU loss
In computer vision tasks for object detection, the IoU (intersection over union) loss function is widely used because of its effectiveness. YOLOv8 and YOLOv5 use the IoU-based CIOU loss, which improves the accuracy of the model by evaluating the position and size of the predicted boxes. The formula for CIOU loss is as follows:
where \({\rho ^2(b, b^{gt})}\) represents the Euclidean distance between the centre of the predicted box and the centre of the ground truth box; C represents the diagonal distance of the smallest enclosing box that can contain both the predicted box and the ground truth box; \(\alpha\) represents the weighting function, and its parameter v reflects the aspect ratio of the predicted box; \({w^{gt}}\) and \({h^{gt}}\) represent the width and height of the ground truth box, respectively w and h represent the width and height, respectively, of the predicted box. However, owing to the smaller width and height of small objects, this parameter may not accurately reflect the actual situation, leading to an unreasonable optimization process. In addition, small objects are easily affected by environmental factors and have difficulty adapting to scenes with large variations in object scale, which limits the applicability of CIOU loss. CIOU loss performs poorly in detecting objects with large aspect ratios or irregular shapes, lacks an adaptive mechanism, and fails to effectively address the balance issue between two samples, which limits the convergence speed of the model for samples with large differences. This makes its judgement ability and generalizability insufficient for small object detection.
To distinguish different regression samples during the regression process and to use auxiliary boxes of different scales for loss calculation to effectively accelerate the bounding box regression process, this paper proposes inner focaler IoU loss (INFL), where InnerIoU34 is shown in Fig. 6. When the prediction box of a detection model already has a high IoU value with the ground truth box for a certain target, this method uses a smaller auxiliary box to calculate the loss, which helps the model quickly converge and finely adjust those prediction boxes that are already close to accurate positions. In contrast, for prediction boxes that overlap less with the ground truth box (i.e., have a low IoU value), the method uses a larger auxiliary box for loss calculation. This expanded auxiliary box can cover more background and contextual regions, making it especially suitable for capturing and correcting those roughly located prediction boxes, thereby improving the regression ability of the model for low-IoU samples. The ground truth box and the anchor box are represented as \({b^{gt}}\) and b, respectively. The centres of the ground truth box and the inner ground truth box are denoted by \(\left( x_c^{gt}, y_c^{gt} \right)\), while the centres of the anchor box and the inner anchor box are denoted by \(\left( x_c, y_c \right)\). The width and height of the ground truth box are denoted by \(w^{gt}\) and \(h^{gt}\), respectively; the width and height of the anchor box are denoted by w and h, respectively; the width and height of the auxiliary bounding box are denoted by \(w_{inner}^{gt}\) and \(h_{inner}^{gt}\), respectively. The variable ratio corresponds to the IoU value scale factor, which typically ranges from [0.5, 1.5].

InnerIoU loss function.
The definition of InnerIoU is as follows:
InnerIoU loss retains the fundamental characteristics of IoU loss, with values also ranging within [0,1] and a curve shape similar to the IoU deviation. However, InnerIoU loss exhibits unique advantages and features for addressing scale differences between the auxiliary box and the actual box. Specifically, InnerIoU loss introduces auxiliary boxes to flexibly handle regression tasks of different scales. When the scale of the auxiliary box is smaller than that of the actual box, the loss function yields larger gradient values for samples with high IoU values, quickly optimizing prediction boxes that are approximately correctly located, thus accelerating the convergence process for these samples. Conversely, when the auxiliary box scale is larger than the actual box scale, InnerIoU loss can expand the effective range of regression, enabling even prediction boxes with initial low IoU values to be effectively adjusted and improved, enhancing the ability of the model to handle low-IoU samples. The application of the InnerIoU to existing IoU-based bounding box regression loss functions is defined as follows:
To focus on different regression samples in various detection tasks, the InnerIoU loss is reconstructed via a linear interval mapping method to enhance the bounding box regression effect. When the InnerIoU is less than the low threshold d=0.2, the loss is kept at 0, implying that InnerIoU values within this range do not have an additional impact on the loss, as they are already considered sufficient35. This is because we aim to reduce the impact of low IoU samples on the overall loss, prevent gradient explosion at the early stages of training, and focus model resources on more promising samples. When the InnerIoU value is between the lower threshold d = 0.2 and the higher threshold u=0.8, the loss is linearly reconstructed as \({(InnerIoU-d)/(u-d)}\), thereby imposing greater penalties on samples with lower IoU values, encouraging the model to better learn boundary regression. When the InnerIoU exceeds a higher threshold of u=0.8, the loss is set to 1, as the IoU has surpassed the set threshold, and the overlap between the target and the predicted bounding boxes is sufficiently high, requiring no additional penalty. This can avoid overoptimizing these already well-performing samples, prevent overfitting, and improve the generalization ability of the model. INFL-IoU loss is expressed by the following formula:
It is combined with the CIoU to form the INFL-CIoU loss function, as shown in the following formula:
Experimentation and analysis
Dataset
The VisDrone201936 dataset was created by the AISKYEYE team from the Machine Learning and Data Mining Lab at Tianjin University. This object detection dataset comprises 6471 training images, 548 validation images, and 1610 test images, with a total of 10 categories: pedestrian, person, bicycle, car, van, truck, tricycle, awning tricycle, bus, and motorcycle. The scenes in the dataset typically feature complex situations and densely distributed objects, making it suitable for effectively validating improvements to the YOLOv8 algorithm.
Experimental environment and evaluation metrics
All the experiments in this paper were conducted on a computer with a 3050ti GPU and PyTorch 1.13.1. The learning rate was set to 0.01, adjusted by the cosine annealing algorithm, with the momentum of stochastic gradient descent (SGD) set to 0.937, and data augmentation was performed via the mosaic method. The resolution of the input images was uniformly set to \(640\times 640\). All the models were trained for a total of 200 epochs, and to ensure the fairness of the experiments, no pretrained models were used during training. Each result is the average of five training runs.
To fully verify the efficiency of the proposed method, the models were evaluated in terms of average precision (AP), parameter count (Params), and mean average precision (mAP). AP is the area under the precision-recall (PR) curve, which is defined as follows:
The precision (P) and recall (R) are defined as:
The true positive (TP) represents the number of samples that are actually positive and classified as positive by the classifier. The false positive (FP) represents the number of samples that are actually negative but classified as positive by the classifier. The false negative (FN) represents the number of samples that are actually positive but classified as negative by the classifier. mAP is calculated by computing the AP for each category and then averaging the AP values of all categories, as defined in Eq. (17). AP50 represents the AP value when the IoU threshold is set to 0.5. mAP represents the mean AP value calculated with IoU thresholds ranging from 0.5 to 0.95 with a step size of 0.05. The mAP loss is shown in the following formula:
where N represents the number of categories.
Ablation study
Module ablation experiments
To validate the specific impact of the improvement strategies adopted in PTCDet on the algorithm, ablation experiments were designed to verify the contribution of each module to the network. The ablation experiments in this section were conducted on the VisDrone dataset. The specific experimental results are shown in Table 1. \(\surd\) indicates the adoption of the improvement strategy.
After the MFEA module was used in the benchmark network, the [email protected] increased from 38.72 to 39.93%, and the [email protected]:0.95 increased from 23.01 to 23.62%. This demonstrates that the MFEA module combines channel, spatial, and coordinate attention mechanisms to enhance the representation capability of feature maps from multiple dimensions, enabling the model to more accurately capture the detailed features of small objects, thereby improving detection accuracy. Additionally, the F1 score increased from 43.22 to 44.11%, indicating that the introduction of the MFEA module enhanced the overall detection capability of the model.
When both the MFEA and the WPFA are used, the [email protected] increases to 40.63%, the [email protected]:0.95 increases to 24.21%, and the F1 score increases to 44.50%, further enhancing the flexibility and adaptability of the model to different scenes. By dynamically adjusting the receptive field, the model can more accurately identify and handle targets of different sizes, which is especially effective for detecting targets with significant size variations in drone aerial images.
When ESFD is introduced and combined with the use of MFEA and WPCA, the [email protected] of the model increases to 43.91%, the [email protected]:0.95 reaches 26.62%, and the F1 score increases to 45.82%. The addition of ESFD enhanced the ability of the model to detect small targets, addressing the issue of potentially missing important targets in low-resolution feature maps.
When the MFEA, the WPFA, ESFD, and the INFL-CIoU are used simultaneously, the detection accuracy of the model is the highest, with [email protected] increasing to 44.93%, [email protected]:0.95 increasing to 27.22%, and the F1 score increasing to 46.52%. The INFL loss function performs well in performing regression tasks at different scales by introducing auxiliary boxes and linear interval mapping methods, especially for small object detection and samples with low IoU values.

Comparison of mAP results.
Visualizing the mAP@50 of PTCDet and the original YOLOv8, as shown in Fig. 7, reveals that PTCDet consistently results in higher mAP values than the baseline YOLOv8 across the entire detection threshold range. This significant improvement is reflected mainly in the [email protected] metric, highlighting that PTCDet has more comprehensive optimizations in terms of small object detection accuracy, scene adaptability, and overall detection robustness.
Loss function ablation experiment
This study experimentally optimized the ratio parameter in the INFL-CIoU loss function to more effectively apply it to small object detection tasks. The specific experimental results are shown in Table 2. The experiments were conducted on the basis of the YOLOv8 baseline model. In the INFL-CIoU loss function, a ratio of 1.2 yields the best performances because it moderately expands the auxiliary box, balancing the learning and regression capabilities of both high IoU and low IoU samples. This setting provides broader background information to optimize low IoU samples while maintaining precise adjustments and positioning accuracy for high IoU samples. In contrast, a ratio of 1.1 slightly enlarges the auxiliary box but does not significantly improve the positioning of low IoU samples, leading to insufficient gradient information and adversely affecting the generalization ability of the model. On the other hand, a ratio of 1.3, although it expands the regression range for low IoU samples, introduces excessive background noise due to the overly large auxiliary box, interfering with the fine-tuning and positioning accuracy of high IoU samples. Therefore, a ratio of 1.2 increases the optimization capability for low IoU samples without affecting the fine-tuning of high IoU samples, achieving a balance between the precision and generalization ability of the loss function.
Comparative experiments
The PTCDet algorithm was compared with other mainstream common algorithms (including YOLOv5, YOLOX37, YOLOv8, RT-DETR38, YOLOv6, and YOLOv7) on the Visdrone dataset. Additionally, the algorithm was compared with two of the latest UAV-specific models, Gold-YOLO39 and ASF-YOLO40. The experimental results are shown in Table 3. The PTCDet algorithm has the highest average detection accuracy, with [email protected] reaching 44.93%, which is higher than those of all the other tested models. The size of the PTCDet model is 20.53 MB and the number of parameters is 12.12 M, which shows that it maintains a good balance between accuracy and complexity. The YOLOv6s algorithm performs poorly in this scenario, with the lowest average detection accuracy and many parameters at 18.53 M, only slightly lower than YOLOv8m and RT-detr-R18. The transformer-based RT-DETR-R18 algorithm performs well in this scenario, with [email protected] reaching 41.92%, second only to the proposed PTCDet algorithm, but its parameter count and model size are significantly larger at 20.00 M and 38.54 MB, respectively. In summary, the PTCDet algorithm performed well on the Visdrone dataset, achieving the highest detection accuracy with the fewest parameters. These experimental results demonstrate the superior performance of the PTCDet algorithm.
To validate the superior performance of the PTCDet algorithm, multiple scenarios were selected for visual analysis of the detection results, as shown in Fig. 8. As shown in the figure, owing to the high density and small scale of the targets, all the tested models exhibited some missed and false detections. The YOLOv8 model, in particular, revealed more severe issues, especially with occluded targets. For example, the YOLOv8 algorithm performs poorly in detecting occluded vehicles, particularly under nighttime conditions where false detections are more severe and the algorithm repeatedly misidentifies targets in certain areas of the image. In contrast, the proposed PTCDet algorithm yields lower rates of false and missed detections in scenarios involving occluded targets, successfully detecting occluded persons multiple times.In summary, the PTCDet algorithm shows significant performance improvements over the YOLOv8 algorithm, offering substantial practical value.

VisDrone detection images.
To analyse the accuracy changes of each category under the Visdrone dataset more intuitively between the PTCDet algorithm and the YOLOv8 algorithm, the experimental results are shown in Table 4. where A: pedestrians, B:people, C:bicycle, D:car, E:van, F:truck, G:tricycle, H:awning-tricycle, I:bus, and J:motor. The PTCDet model significantly outperforms the original YOLOv8 in terms of detection accuracy for various targets in the VisDrone dataset. The improved model shows significant enhancements in detection accuracy for pedestrians, small objects (such as bicycles and motorcycles), and easily confused targets (such as trucks and buses). For example, the mAP for pedestrian detection increased from 41.71% to 53.32%, and for bicycle detection , it increased from 13.22% to 16.94%, indicating that the improved model has higher accuracy and robustness in handling complex backgrounds and relatively small targets. Additionally, PTCDet shows significant improvements in detection accuracy for vehicle targets (such as cars, trucks, and buses). For example, the mAP for the truck category increased from 34.23% to 38.83%, and for the car category, it increased from 79.23% to 84.62%, highlighting its strong ability to detect vehicle-type targets. The increased overall mAP0.5 value further validates the effectiveness of the RFACONV module, which enhances the ability of the model to perceive and extract of key features by integrating global context information and attention mechanisms, effectively improving the accuracy and overall performance of various target detection methods. Overall, PTCDet demonstrates significant advantages over YOLOv8 in detecting targets across various categories, particularly in handling small and overlapping targets in complex backgrounds, fully demonstrating the effectiveness and superiority of the improved method.
Comparison of different datasets
To comprehensively validate the generalization ability of the improved model and its performance in complex detection environments, extensive testing was conducted on the TinyPerson and AI-TOD datasets, which respectively target different sizes and complexities of object detection scenarios, respectively.
TinyPerson dataset
The TinyPerson dataset41 aims to detect tiny humans, collect high-resolution videos from various websites, extract images every 50 frames and remove some duplicate images. TinyPerson consists of 1,610 annotated images with a total of 72,651 annotations. It includes two categories: sea person and earth person, and is split into training and testing sets at an 8:2 ratio. The specific experimental results are shown in Table 5. The PTCDet algorithm achieved the highest average detection accuracy, with mAP@50 and mAP0.5:0.95 being 29.41% and 10.92%, respectively, outperforming the other tested algorithms. The TinyPerson dataset specifically focuses on the detection of extremely small objects. Compared with the other tested models, the PTCDet model demonstrated significant performance, with a notable improvement in the detection accuracy for small objects. This result shows significant progress in the improved ability of the model to capture details and handle small object information, confirming its competitive advantage in detecting small objects.
The detection results were visualized by randomly selecting images, as shown in Fig. 9. The YOLOv8 algorithm resulted in many missed detections, whereas the proposed PTCDet algorithm performed well in this scenario.

TinyPerson detection images.
AI-TOD dataset
The AI-TOD dataset42 provides 700,621 object instances across 28,036 aerial images, covering 8 categories. Compared with existing aerial image object detection datasets, the average object size in AI-TOD is approximately 12.8 pixels, which is much smaller than that of other targets. The AI-TOD dataset includes eight different object categories: airplane, bridge, storage tank, ship, swimming pool, car, pedestrian, and windmill. The training set consists of 11,214 samples, whereas the test set contains 2804 samples. The specific experimental results are shown in Table 6. The PTCDet algorithm achieved the highest average detection accuracy, with mAP@50 and mAP0.5:0.95 being 47.13% and 21.82%, respectively, outperforming the other tested algorithms. For the AI-TOD dataset, which involves the detection of small objects in aerial images, the model must effectively handle high spatial resolution and complex backgrounds. PTCDet also outperformed the other tested algorithms on this dataset, demonstrating the ability to maintain high accuracy detection in complex backgrounds. This performance validates the excellent ability of the improved model to analyse and handle targets in complex background situations.

AI-TOD detection images.
The detection results were visualized by randomly selecting images, as shown in Fig. 10. As shown in the figure, the YOLOv8 algorithm again resulted in many missed detections in this scenario, whereas the proposed PTCDet algorithm performed well and remained superior to YOLOv8.
Heatmap visualization analysis
Using heatmaps to observe the detection results provides intuitive visual evidence, thereby further validating the superiority of our proposed algorithm. In the Grad-CAM43 method, for the final generated heatmap, feature maps with rich spatial information receive more attention, whereas those with sparse spatial information are relatively disregarded during the visualization process. The limitation of this method is that the generated heatmaps may not effectively cover image scenes containing multiple targets or a single complex target, thereby impacting the improvement of model accuracy and interpretability.
In contrast, Grad-CAM++44 effectively overcomes this problem by giving appropriate attention to all feature maps in the final heatmap. This advanced method finely balances the contributions of each feature map, ensuring that the heatmap generation process can more comprehensively capture the diverse targets and complex objects in the image, thereby improving model interpretability and accuracy. Therefore, this study uses Grad-CAM++ to compare the heatmaps of the baseline and improved models, as shown in Fig. 11. The PTCDet model focuses more on detecting targets with less interference from background information, and presents deeper colours in the target areas. This means that the attention of the model is more concentrated on these key areas, reflecting enhanced feature extraction and target detection capabilities. In contrast, the YOLOv8 model is easily affected by background information and focuses less on the targets, as indicated by lighter colours in the target areas, leading to decreased detection accuracy. In conclusion, the improvement strategy adopted in this paper is highly effective.

VisDrone heatmap comparison.
Conclusion
On the basis of the YOLOv8 baseline model, this paper proposes the PTCDet model, which demonstrates significant innovations and advantages in the field of small object detection in UAV aerial images. Compared towith existing detection methods, PTCDet achieves a breakthrough in detecting small objects in high-density and multiscale scenarios by introducing the multiple feature extraction attention (MFEA) module. The MFEA module not only integrates channel, spatial, and coordinate attention mechanisms to enhance the representation of feature maps from multiple dimensions but also specifically addresses the shortcomings of traditional methods in complex scenes, significantly improving the adaptability and accuracy of the model. Additionally, the weighted perceptive field augmentation (WPFA) module expands the perceptive range of the model, effectively resolving issues of false positives and missed detections in complex backgrounds, thereby greatly enhancing detection precision and flexibility. The enhanced scale fusion (ESFD) module optimizes multiscale feature fusion, successfully overcoming the challenge of small objects being overlooked at lower resolutions. The inner focal IoU loss (IFIL) function applies differentiated penalties for targets of varying sizes and shapes, significantly improving the regression accuracy for diverse object sizes. These innovations collectively ensure the superior performance of PTCDet for complex backgrounds and small object detection tasks. The experimental results show that PTCDet significantly outperforms existing baseline models on datasets such as VisDrone, AI-TOD, and TinyPerson, particularly in terms of [email protected] and [email protected]:0.95 metrics.
Despite the excellent performance of the model in detecting small objects in dense scenes, its generalization ability still requires further optimization for scenarios involving significant variations in object shapes and sizes. Additionally, the model may still encounter false positives or missed detections when faced with extremely complex backgrounds, indicating that more refined optimizations may be necessary in future research.
Data availibility
All the images and experimental test images in this paper were from the open source VisDrone dataset, TinyPerson dataset and AI-TOD dataset. These datasets analyzed during the current research period can be found at the following website. Visdrone:(https://github.com/VisDrone/VisDrone-Dataset), TinyPerson: (https://github.com/ucas-vg/TinyBenchmark) and AI-TOD: (https://github.com/jwwangchn/AI-TOD).
References
Zhou, L. et al. A multi-scale object detector based on coordinate and global information aggregation for uav aerial images. Remote Sens. 15, 3468 (2023).
Wang, W., Fang, C. & Liu, T. Multiperiod unmanned aerial vehicles path planning with dynamic emergency priorities for geohazards monitoring. IEEE Trans. Industr. Inf. 18, 8851–8859 (2022).
Hamzenejadi, M. H. & Mohseni, H. Fine-tuned yolov5 for real-time vehicle detection in uav imagery: Architectural improvements and performance boost. Expert Syst. Appl. 231, 120845 (2023).
Zhang, R. et al. Multi-scale adversarial network for vehicle detection in uav imagery. ISPRS J. Photogramm. Remote. Sens. 180, 283–295 (2021).
Jin, R. & Lin, D. Adaptive anchor for fast object detection in aerial image. IEEE Geosci. Remote Sens. Lett. 17, 839–843 (2019).
Xu, X., Zhang, X. & Zhang, T. Lite-yolov5: A lightweight deep learning detector for on-board ship detection in large-scene sentinel-1 sar images. Remote Sens. 14, 1018 (2022).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. A survey on deep-learning-based real-time sar ship detection. Remote Sens. 779–788 (2016).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 779–788 (2016).
Redmon, J. & Farhadi, A. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7263–7271 (2017).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. arXiv preprint. arXiv:1804.02767 (2018).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Glenn, J. Ultralytics yolov5. https://github.com/ultralytics/yolov5 (2022).
Li, C. et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976 (2022).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7464–7475 (2023).
Glenn, J. Ultralytics yolov8. https://github.com/ultralytics/ultralytics (2023).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 580–587 (2014).
Girshick, R. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, 1440–1448 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
Cai, Z. & Vasconcelos, N. Cascade r-cnn: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 43, 1483–1498 (2019).
He, K., Zhang, X., Ren, S. & Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37, 1904–1916 (2015).
Lin, T.-Y. et al. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2117–2125 (2017).
Liu, S., Qi, L., Qin, H., Shi, J. & Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 8759–8768 (2018).
Wang, X. et al. Yolo-erf: lightweight object detector for uav aerial images. Multimedia Syst. 29, 3329–3339 (2023).
Zhou, L. et al. A multi-scale object detector based on coordinate and global information aggregation for uav aerial images. Remote Sens. 15, 3468 (2023).
Ma, M. & Pang, H. Sp-yolov8s: an improved yolov8s model for remote sensing image tiny object detection. Appl. Sci. 13, 8161 (2023).
Tang, F., Yang, F. & Tian, X. Long-distance person detection based on yolov7. Electronics 12, 1502 (2023).
Wang, Z.-Q. & Dong, X.-M. Sadenet: A supervised attention delicate enhanced network for subtle person detection. Inf. Sci. 643, 119239 (2023).
Xiao, J. et al. Tiny object detection with context enhancement and feature purification. Expert Syst. Appl. 211, 118665 (2023).
Zhang, T., Zhang, X. & Ke, X. Quad-fpn: A novel quad feature pyramid network for sar ship detection. Remote Sens. 13, 2771 (2021).
Xu, X. et al. A group-wise feature enhancement-and-fusion network with dual-polarization feature enrichment for sar ship detection. Remote Sens. 14, 5276 (2022).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I.-S. Cbam: Convolutional block attention module. arXiv preprint arXiv:1807.06521 (2018).
Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. arXiv preprint arXiv:2103.02907 (2021).
Zhang, X. et al. Rfaconv: Innovating spatial attention and standard convolutional operation. arXiv preprint arXiv:2304.03198 (2023).
Zhang, H., Xu, C. & Zhang, S. Inner-iou: more effective intersection over union loss with auxiliary bounding box. arXiv preprint arXiv:2311.02877 (2023).
Zhang, H. & Zhang, S. Focaler-iou: More focused intersection over union loss. arXiv preprint arXiv:2401.10525 (2024).
Du, D. et al. Visdrone-det2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF international conference on computer vision workshops, 213–216 (2019).
Ge, Z., Liu, S., Wang, F., Li, Z. & Sun, J. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
Zhao, Y. et al. Detrs beat yolos on real-time object detection. arXiv preprint arXiv:2304.08069 (2023).
Wang, C. et al. Gold-yolo: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 36 (2024).
Kang, M., Ting, C.-M., Ting, F. & Phan, R. Asf-yolo: A novel yolo model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 147, 105057 (2024).
Yu, X., Gong, Y., Jiang, N., Ye, Q. & Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 1257–1265 (2020).
Wang, J., Yang, W., Guo, H., Zhang, R. & Xia, G.-S. Tiny object detection in aerial images. In 2020 25th international conference on pattern recognition (ICPR), 3791–3798 (IEEE, 2021).
Selvaraju, R. R. et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, 618–626 (2017).
Chattopadhay, A., Sarkar, A., Howlader, P. & Balasubramanian, V. N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE winter conference on applications of computer vision (WACV), 839–847 (IEEE, 2018).
Acknowledgements
This work was supported by a grant from the National Natural Science Foundation of China (No.62105093)
Author information
Authors and Affiliations
Contributions
Conceptualization, J.S. and Y.Q.; methodology, Y.Q.; software, Y.Q.; validation, Y.Q., Y.H. and Z.J.; formal analysis, Z.J.; investigation, J.S.; resources, Y.Q.; data curation, Y.H.; writing—original draft preparation, Y.Q.; writing—review and editing, Z.J.; visualization, J.S.; supervision, J.S.; project administration, H.Y.; funding acquisition, J.S. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Su, J., Qin, Y., Jia, Z. et al. PTCDet: advanced UAV imagery target detection. Sci Rep 14, 27403 (2024). https://doi.org/10.1038/s41598-024-78749-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-78749-w
Keywords
This article is cited by
-
A global object-oriented dynamic network for low-altitude remote sensing object detection
Scientific Reports (2025)
-
MRYOLO: Accurate and real-time Recognition of Pylon Construction Progress based on UAV Images
Signal, Image and Video Processing (2025)
