
Abstract
Visible-Infrared Person Re-identification (VI-ReID) has been consistently challenged by the significant intra-class variations and cross-modality differences between different cameras. Therefore, the key lies in how to extract discriminative modality-shared features. Existing VI-ReID methods based on Convolutional Neural Networks (CNN) and Vision Transformers (ViT) have shortcomings in capturing global features and controlling computational complexity, respectively. To tackle these challenges, we propose a hybrid network framework called ReMamba. Specifically, we first use a CNN as the backbone network to extract multi-level features. Then, we introduce the Visual State Space (VSS) model, which is responsible for integrating the local features output by the CNN from lower to higher levels. These local features serve as a complement to global information and thereby enhancing the local details clarity of the global features. Considering the potential redundancy and semantic differences between local and global features, we design an adaptive feature aggregation module that automatically filters and effectively aggregates both types of features, incorporating an auxiliary aggregation loss to optimize the aggregation process. Furthermore, to better constrain cross-modality features and intra-modal features, we design a modal consistency identity constraint loss to alleviate cross-modality differences and extract modality-shared information. Extensive experiments conducted on the SYSU-MM01, RegDB, and LLCM datasets demonstrate that our proposed ReMamba outperforms state-of-the-art VI-ReID methods.
Similar content being viewed by others
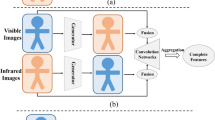
Introduction
In recent years, the enhancement of public safety awareness has driven the widespread application of person re-identification (Person ReID) technology in intelligent surveillance systems. Although significant progress has been made with visible (VIS) person ReID methods1,2,3,4, these approaches may encounter limitations when operating in low-light environments, as VIS cameras cannot capture clear images under such conditions. In contrast, infrared (IR) cameras are less affected by lighting variations, it has propelled the advancement of Visible-Infrared Person Re-Identification (VI-ReID) technology, which integrates VIS and IR imagery. This technology aims to overcome the limitations of visible person ReID and achieve cross-modality person image matching.
The core challenge of the VI-ReID task stems from the modality differences between VIS and IR images. Generally, there are two popular approaches to reduce this modality difference. The first approach is image-level methods5,6,7,8, which use generative adversarial networks (GANs) or other networks to generate intermediate or corresponding modality images. While these methods effectively reduce modality differences, they introduce generation noise.
The other approach is feature-level methods, which project cross-modality features into a common feature space to learn modality-shared features. Among them, some convolutional neural network (CNN)-based methods9,10,11,12,13 excel at capturing local features hierarchically, as shown in Figure 1(a). However, due to the receptive field limitations of CNNs, they are inadequate in capturing global contextual information, which is crucial for learning modality-shared morphological and structural features. To address this issue, some studies14,15have introduced Vision Transformers (ViT)16to construct long-range dependencies and capture global features. Nevertheless, these methods have been observed to overlook local feature details, sacrificing the learning of discriminative fine-grained features. To remedy this, some improved works17,18 have combined CNN and ViT to merge shallow and deep features. Although improvements were made, these methods still encounter challenges such as semantic mismatches and information redundancy between the two types of features, as well as high computational costs associated with ViT. Thus, efficiently integrating local and global features while maintaining computational efficiency remains a key issue to be solved.
The recent development of State Space Models (SSMs)19 has provided a new way to capture global contextual information, as shown in Figure 1(b). As a pioneering model based on SSMs, Mamba20not only exhibits excellent performance in modeling long-term dependencies but also maintains computational efficiency with linear growth in sequence length, positioning it as a potential new model to replace Transformers. This advancement has spurred deep application exploration of Mamba in various vision tasks21,22,23,24,25, achieving remarkable results. However, when we attempted to directly apply VMamba23 to the VI-ReID task, we found that although it exhibited high computational efficiency, the recognition performance was not as expected. The reason is that VI-ReID, compared to other visual tasks, requires an emphasis on extracting discriminative fine-grained features, and the original VMamba architecture has limited capability in capturing such features.
To address these limitations, we propose a CNN-Mamba hybrid network structure called ReMamba, aiming to combine the advantages of CNN in local feature extraction with Mamba’s powerful global information modeling capabilities, as shown in Figure 1(c). Specifically, we first use CNNs (such as ResNet) to extract multi-level local features. Subsequently, these features are progressively aggregated into VMamba, integrating the semantic information of multi-scale features from a global perspective. To overcome potential information redundancy and semantic inconsistency during aggregation, we design an Adaptive Feature Aggregation module, combined with an Auxiliary Aggregation (AA) loss to guide effective feature selection and semantic alignment, significantly enhancing the detail information in global representations. Additionally, we innovatively propose a Modality-consistent Identity Constraint (MIC) loss to simultaneously constrain cross-modality and intra-modality features, promoting smooth learning of shared modality features.
In summary, our contributions are mainly reflected in:
-
For the first time, we introduce the Mamba framework into the VI-ReID field, creating ReMamba, an efficient hybrid network architecture that integrates local and global information.
-
We design an Adaptive Feature Aggregation module combined with Auxiliary Aggregation loss, achieving effective feature selection and semantic alignment, optimizing the feature aggregation process, and helping the model better capture global semantic information and discriminative local information.
-
We develop a novel Modality-consistent Identity Constraint (MIC) loss to simultaneously constrain cross-modality features and intra-modality identity features, promoting the learning of modality-shared features.
-
Extensive experiments demonstrate the superior performance of ReMamba on benchmark datasets such as SYSU-MM01, RegDB, and LLCM, surpassing the current state-of-the-art methods.

This figure illustrates the different characteristics of CNNs (a), SSMs (b), and our proposed ReMamba (c) in processing person images. CNNs excel at extracting local texture details from images, while SSMs perform well in understanding the global contextual information of images. Our ReMamba method supplements the local information extracted by CNNs and embeds it into the global contextual representation captured by SSMs, thereby significantly enhancing the local details in the overall representation.
Related work
Single-modality person re-identification
Single-modality person re-identification endeavors to identify and retrieve pictures of people that have been taken exclusively under visible conditions. However, this process often faces challenges such as occlusion, illumination, and viewpoint variations. To overcome these challenges, most methods3,4,26employ convolutional neural networks (CNNs) (e.g., ResNet27) to obtain discriminative person feature representations. Recently, with the rise of the Vision Transformer (ViT)16 in the field of image analysis, He et al.2innovatively applied it to the single-modality person re-identification task to enhance long-range dependency learning among features. Additionally, metric learning strategies1,28,29, including triplet loss29, quadruplet loss1and group consistency loss28, have further improved model performance by introducing more refined feature constraints. Although significant achievements have been made in the field of visible person re-identification, the effectiveness of these methods is considerably diminished when applied to VI-ReID task due to the presence of modality differences.
Visible-infrared person re-identification
VI-ReID task aims to match images of individuals captured by different surveillance cameras under different modalities. It not only faces intra-modality variations present in visible person re-identification tasks but also significant inter-modality differences between visible and infrared modalities. Addressing these challenges, the VI-ReID research field has made significant progress, focusing mainly on two approaches: image-level methods and feature-level methods.
Image-level methods reduce modality differences by generating new auxiliary modality images. Commonly used methods based on generative adversarial networks (GANs)6,8generate corresponding modality images through image style transfer. These methods typically require complex network designs to generate and align cross-modality images. In contrast, other methods5,7,30 used lightweight networks to generate auxiliary intermediate modalities to alleviate modality differences. However, these generative modality compensation methods inevitably introduce noise.
Feature-level methods aim to map the features of two modalities into a unified representation space to address cross-modality and intra-modality differences. Specifically, some methods based on metric learning have emerged. Zhu et al.31 introduced a hetero-center loss for acquiring modality-shared features by imposing constraints on the intra-class center distance between the two modalities. Liu et al.32further extended this work by integrating the hetero-center loss with triplet loss. Although these methods alleviate modality differences, they are insufficient in constraining cross-modality features, making it difficult to extract deep modality-shared information. Additionally, some CNN-based studies9,10,12,33focus on capturing local features at the expense of global contextual information. Other methods14,15employ ViT16to construct global representations but overlook discriminative detailed texture information. Addressing these limitations, some improved methods17,18 attempt to integrate CNN components into the ViT architecture to enhance local feature learning. While achieving some progress, they do not fully consider the potential information redundancy and semantic bias between local and global information during integration.
Our approach belongs to the feature-level methods. Unlike traditional strategies that simply concatenate local and global features, our method first extracts local features at different levels and then gradually aggregates lower-level semantic information into the global representation in a layer-by-layer manner. During the aggregation process, we design an Adaptive Feature Aggregation module that allows the network to adaptively select and aggregate both types of information, ensuring that the network retains rich detailed information while constructing the global representation.
Mamba in vison
State Space Sequence Models (SSMs)19 provide a new way to globally handle contextual information. Their advantageous property of linear scaling with sequence length has garnered widespread attention for long-term dependency modeling. However, the fixed sequence transformation mechanism of SSMs limits their inference efficiency. Recently, Gu et al.20addressed this issue by incorporating a selection mechanism into SSMs, constructing a general model backbone named Mamba. Compared to Transformers, Mamba is more efficient as its computational complexity grows linearly with sequence length and has superior long-term dependency modeling capabilities. Recent research has applied Mamba to visual tasks, achieving remarkable results. Vim34and VMamba23provide new visual backbones. U-mamba24, SegMamba35, and VM-UNet36combine Mamba with traditional image segmentation frameworks, achieving performance breakthroughs in the medical image segmentation field. Additionally, Mamba has been widely applied in image restoration21,37, video understanding22,38, and multi-modal data processing25,39, further demonstrating its algorithmic framework’s adaptability and superiority.
Given the significant success of the Mamba model in various visual tasks, we aim to explore whether it can bring similar innovations to the VI-ReID task. However, initial attempts to directly apply VMamba23 to the VI-ReID task showed that, despite efficient processing, the identification accuracy was unsatisfactory. This is mainly due to the original VMamba design’s insufficient emphasis on local features, which are crucial for highlighting discriminative regions of person. To address this issue, we incorporate different scale features extracted by the CNN branch as local information, supplementing them sequentially into the VMamba network. By combining the Adaptive Feature Aggregation module, we reduce information redundancy and bridge semantic differences between the information, ensuring that local information is fully integrated during global representation construction. This enables the network to extract more discriminative multi-granularity person representations.
Preliminaries
State Space Models (SSMs)19 are defined by the linear ordinary differential equation (ODE):
This model uses a simple mapping transformation to project the one-dimensional input \(x(t)\in \mathbb {R}\) into the N-dimensional latent state \(h(t)\in \mathbb {R}^N\), which is then projected to the one-dimensional output \(y(t)\in \mathbb {R}\). Here, \(\textbf{A}\in \mathbb {R}^{N\times N}\) represents the state transition matrix, and \(\textbf{B}\in \mathbb {R}^{N\times 1}\) and \(\textbf{C}\in \mathbb {R}^{N\times 1}\) are the projection parameters, these parameters capture the internal state changes of the system.
Subsequently, the SSM algorithm commonly employs the zeroth-order hold (ZOH) rule for discretization, the process is defined as follows:
where \(\Delta \in \mathbb {R}^D\) denotes the time scale parameter, The transformation process converts \(\textit{A}\) and \(\textit{B}\) into discrete parameters \(\overline{A}\) and \(\overline{B}\), respectively. Once discretized, the SSM-based model can be calculated using RNN or CNN form, defined as equations (3) and (4) correspondingly.
Here, \(\textit{L}\) represents the length of the input sequence, \(\mathbf {\overline{K}}\in \mathbb {R}^L\) is the structured convolution kernel, and \(\text {*}\) denotes the convolution operation.
the recent state space model, Mamba20, achieves selectivity by making A, B, and C dependent on the input data, thereby allowing dynamic feature representation. This enables it to capture complex interactions in long sequence inputs, laying the foundation for applying SSMs to the field of image processing.

Overview of ReMamba, including a backbone, a Visual State Space (VSS) block, and an Adaptive Feature Aggregation (AFA) block. The AFA module is utilized for aggregating the local features extracted by the backbone and the global features obtained from the VSS blocks, concurrently supervised by the \({\mathscr {L}}_{AA}\) during the aggregation process. The ReMamba model is jointly optimized by \({\mathscr {L}}_{CE}\) and \({\mathscr {L}}_{MIC}\).
Methodology
Figure 2 provides an overview of the proposed ReMamba. Initially, a dual-stream ResNet-50 backbone is employed to capture multi-scale person features. Next, we progressively aggregate the multi-scale features extracted from the four stages of ResNet-50 into the Visual State Space (VSS) block. For instance, the shallow features output from stage 1 are input into stage 2 and the first VSS block to extract larger scale features and long-range dependencies. We then aggregate these two features, aiming to integrate low-level local information into higher-level semantic understanding. The core function of the VSS block is to integrate local features from previous stages and extract global semantic information for subsequent feature aggregation.
During the aggregation process, we noted potential information redundancy and semantic inconsistency between the multi-scale features extracted by the CNN branch and the high-level semantic features output by the VSS branch. To address this, we innovatively designed an Adaptive Feature Aggregation (AFA) module to adaptively filter feature and bridge the semantic differences between the two. During this period, we introduce an Auxiliary Aggregation loss (\({\mathscr {L}}_{AA}\)) to guide this aggregation process, thereby enhancing the complementary effect of the features’ semantics.
During training, the output from the fourth stage of the backbone network and the feature output produced by the final AFA module are input into the \({\mathscr {L}}_{CE}\) and \({\mathscr {L}}_{MIC}\), respectively, before and after batch normalization (BN) processing, to collaboratively propel the refinement of the ReMamba model.
VSS block
VSS block architecture
Motivated by the linear complexity advantage of Mamba20in handling long-sequence modeling, we introduce the Visual State Space (VSS) module23 into the VI-ReID task, with the intent to harness its ability to capture significant global information.The framework of the VSS module is shown in Figure 2(b). First, the input \(X\in \mathbb {R}^{H\times W\times C}\) are processed through a normalization layer and then split into two parallel branches. The features are processed by a linear layer and a 3\(\times\)3 depthwise convolution in the first branch. This step is followed by the SiLU activation function to enhance nonlinear expressive capability, after which the features enter the core 2D Selective Scan (SS2D) component for deeper and more sophisticated feature processing. The features output from the SS2D component undergo normalization again to ensure feature distribution stability. Meanwhile, the other branch has already been processed by a linear layer and SiLU activation. Subsequently, the features derived from these two branches are combined using the Hadamard product to integrate their distinct informational advantages. Finally, the fused features pass through a linear layer and are then connected to the initial features via a residual structure, generating the ultimate features \(X_{out}\):
In ReMamba, we default the number of VSS blocks \(L_{1}\), \(L_{2}\), and \(L_{3}\) to 2, 2, and 9, respectively.
2D selective scan
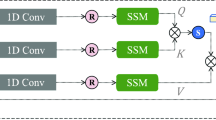
An overview of the 2D Selective Scanning (SS2D) is shown in Figure 3, consisting of three parts: scan expansion operation (Figure 3(a)), S6 operation (Figure 3(b)), and scan merge operation (Figure 3(c)). The scan expansion operation involves the unfolding of image patches into sequences. These unfolded sequences are then scanned in four distinct directions. This four-direction scanning strategy enables each pixel in the feature map to absorb information from pixels in different directions. Next, each generated feature sequence is processed by the S6 block(also known as Mamba), and finally, the feature sequences from the four different directions are merged to reconstitute the feature map. For the input feature z, the output feature \(\overline{z}\) after processing by the SS2D module can be represented as follows:

Illustration of the 2D Selective Scan (SS2D) operation on a person’s image. (a) Depicts the scan expansion operation. (b) Shows the Selective State Space block (S6 Block). (c) Illustrates the scan merging operation.
Herein, \(i\in \{1,2,3,4\}\)denotes one of the four specified scanning pathways, and expand( ) and merge( ) are the scan expansion and scan merge operations in23, respectively. S6 is the core operator in SS2D, achieving selectivity by making discrete parameters depend on the input data, thus allowing dynamic feature representation to capture complex interactions within long-sequence inputs.
Adaptive feature aggregation block
Given the muti-scale local features extracted by the CNN branch and the global features captured in the VSS stream, the model integrates these two types of features, using the cross-layer local features to complement the global semantic features, thereby enhancing the local clarity of the global information. However, this aggregation process faces two major challenges: information redundancy and semantic misalignment. To address these issues, we propose an Adaptive Feature Aggregation (AFA) module, as illustrated in Figure 2(c), to guide the aggregation process and ensure effective fusion of information and precise alignment of semantics. Subsequently, we will elaborate on the details of the AFA block.
First, given the local features \(F_l\in \mathbb {R}^{C_l\times H_l\times W_l}\) output by the CNN branch and the global features \(F_g\in \mathbb {R}^{C_g\times H_g\times W_g}\) output by the VSS block, where \(\text {C}\), \(\text {H}\) and \(\text {W}\) represents channel dimension, height and width of the feature maps, respectively. Noting the inconsistency in feature dimensions and sizes between these two features, we use 1x1 convolution and max pooling to align \(F_{l}\) with \(F_{g}\), resulting in \(F_l\in \mathbb {R}^{C_g\times H_g\times W_g}\). Subsequently, both features are flattened to 2D for subsequent feature processing. This process can be described as follows:
Here, \(\{F_l^{\prime },F_g^{\prime }\}\in \mathbb {R}^{C_g\times N}, N=H_g\times W_g.\)
Second, to address the feature redundancy problem, we designed an Adaptive Feature Selection (AFS) mechanism. This mechanism dynamically adjusts the importance of input features by automatically learning weights, achieving weighted input data to eliminate feature redundancy and obtain more effective feature representations. Specifically, for the adjusted local feature \({F}_{l}^{\prime }\), it first passes through two consecutive fully connected layers \(\psi _l^1\) and \(\psi _l^2\), with a ReLU activation function inserted in between to enhance nonlinear expressive capability. Subsequently, a Softmax function is applied to the output of \(\psi _l^2\) to obtain feature weights, which are multiplied by \({F}_{l}^{\prime }\) to get the weighted feature \(\overline{F_{l}^{\prime }}\). Furthermore, we introduce a pair of learnable parameters \(\gamma _l\) and \(\beta _l\) to perform scaling and shifting adjustments on the weighted feature and combine it with the original weighted feature through residual connection to obtain the AFS-processed local feature \(F_l^{AFS}\). The learnable parameters \(\gamma _l\) and \(\beta _l\) are obtained by mapping \(\overline{F_{l}^{\prime }}\) through fully connected layers \(\Phi _l^1\) and \(\Phi _l^2\). This process can be described as follows:
Here, \(\odot\) denotes the Hadamard product. Similarly, for the adjusted global feature \({F}_{g}^{\prime }\), we have:
Third, to resolve the semantic inconsistency between local and global features, we introduce a Cross-Attention mechanism that promotes interaction and information integration between the two features, bridging the semantic gap:
Subsequently, we exchange the queries \(Q_{l}\) and \(Q_{g}\) of the two features to calculate cross-attention, achieving feature interaction, and concatenate the obtained features to get the fused feature \(Z_{c}\):
where \(d_{k}\) is the scaling factor.
Finally, to enhance the semantic information of the fused feature, we employed a self-attention operation on the fused feature \(Z_{c}\) to obtain the final output of the module \(Z_{out}\). Notably, in the design of the Adaptive Feature Aggregation (AFA) module, we only use two attention modules to obtain the benefits of attention with minimal parameter cost.
Here, \(\{Q_z,K_z,V_z\}={\mathscr {F}}_{qkv}^z(Z_{c})\).
Loss metrics
Modal consistency identity constrained loss
To simultaneously address the issues of inter-modal heterogeneity and intra-modal identity variance, we propose a novel Modal Consistency Identity Constrained Loss (\({\mathscr {L}}_{MIC}\)) to optimize cross-modality matching performance, As shown on the right side of Figure 2(a). Specifically, unlike the traditional HC loss31, which reduces modal differences by constraining intra-class center distances across different modalities, we adopt a new strategy that pushes all features of one modality towards the feature center of another modality. This approach aims to deeply explore shared information between modalities and enhance the constraints between cross-modality features. However, this feature aggregation process may blur the boundaries between features of different identities, thus reducing classification clarity. To overcome this issue, we calculate identity centers of different classes within the same modality and increase the feature distance between them, promoting a compact intra-class spatial distribution for each identity to enhance the discriminability of identity samples.
Specifically, for the j-th feature of identity i in the VIS modality, it can be represented as \(f_V^{ij}\), and the corresponding IR modality feature is denoted as \(f_T^{ij}\). To reduce computational cost, we employ a random selection process to choose P identities. For each selected identity, K VIS and IR images are randomly sampled. This sampling procedure results in a mini-batch of size \(2\times \textit{P}\times \textit{K}\). In a mini-batch, the VIS features and IR features of person identity i can be represented as follows:
Subsequently, for all visible modality features \(f_{V}^{i}\) and infrared modality features \(f_{V}^{i}\) corresponding to identity i, we proceed to calculate their respective feature centers:
Following this, In order to aggregate features towards the center of another modality, we respectively compute the centers for both modalities:
Up to this point, the proposed Modal Consistency Identity Constrained Loss can be formulated as follows:
\({\mathscr {D}}(\cdot ,\cdot )\) denotes the Euclidean distance between two feature vectors, \(f_V=\sum _{i=1}^Pf_V^i\) and \(f_T=\sum _{i=1}^Pf_T^i\) represent all VIS features and IR features in a mini-batch. m and n are different identities in the mini-batch, \(\alpha\) is the margin term, and \([z]_+=max(z,0)\).
In Equation (16), the first term functions to pull the features of modality one towards the feature center of modality two to reduce modal differences. The second term increases the distance between identity centers of different classes within the same modality, ensuring that intra-class feature distances are less than inter-class feature distances. This promotes a compact intra-class space and enhances the discriminability of the features.
Multi-loss optimization
In addition to our proposed \({\mathscr {L}}_{MIC}\), we also incorporate the cross-entropy loss (\({\mathscr {L}}_{CE}\))40 to further enlarge inter-class differences. Furthermore, we designed an auxiliary aggregation loss \({\mathscr {L}}_{AA}\) to supervise the aggregation process of local features into global features. This loss is composed of \({\mathscr {L}}_{MIC}\) and \({\mathscr {L}}_{CE}\) and is flexibly adjusted in its contribution to the total loss by the parameter \(\lambda\), the auxiliary aggregation loss can be formulated by:
By jointly minimizing these three losses, we optimize the network in an end-to-end manner. The final loss definition can be formulated as follows:
Experiments
Datasets and experimental settings
Datasets
To comprehensively evaluate the performance of the proposed model, we conducted experiments on three publicly accessible datasets for VI-ReID: SYSU-MM0141, RegDB42, and LLCM43. As the first large-scale dataset for VI-ReID, SYSU-MM01 encompasses imagery acquired through four VIS cameras and two IR cameras. comprising a total of 30,071 VIS images and 15,792 IR images, these images are collected from 491 unique identities. RegDB consists of 412 pedestrians captured by dual cameras, with each pedestrian having 10 VIS images and 10 IR images, totaling 8,240 images. LLCM includes images from nine different cameras deployed in low-light environments, covering 1,064 pedestrians with 25,626 VIS images and 21,141 IR images.
Evaluation metrics
The evaluation of VI-ReID model performance relies on two important metrics: Cumulative Matching Characteristic (CMC) and mean Average Precision (mAP). CMC assesses the probability of finding a correct match within the top-k retrieval results, and in our experiments, we report the Rank-1 accuracy. The mAP measures the average retrieval performance, reflecting both precision and recall comprehensively. All reported results are the averages of 10 independent evaluations.
Implementation details
We implemented the proposed method and conducted all experiments using a single Nvidia A40 GPU with the PyTorch framework. First, we adopted a dual-stream ResNet-50 network pre-trained on ImageNet as our baseline model. In the training environment, the dimensions of all input images were uniformly adjusted to 3\(\times\)384\(\times\)192, applying data augmentation skills such as horizontal flipping and random erasing44. The learning rate was initialized to \(1\times 10^{-2}\) and gradually increased to \(1\times 10^{-1}\) during the first 10 epochs using a warm-up strategy. Subsequently, the learning rate was reduced by a factor of 0.1 at the 25th, 65th, and 90th epochs, with the entire training process lasting 120 epochs. During the training process, for every mini-batch, we employed a random selection strategy to choose 6 distinct identities. For each selected identity, we further randomly sampled 4 visible images and 4 infrared images for training purposes. The SGD optimizer with a momentum parameter set to 0.9 was uesd for the optimization process.
Comparison with state-of-the-art methods
To validate the efficacy and superiority of our proposed ReMamba model, we conduct a comparative assessment against contemporary state-of-the-art methodologies for VI-ReID. This evaluation is performed on widely recognized public datasets including SYSU-MM01, RegDB, and LLCM.
SYSU-MM01: As shown in Table 1, our proposed ReMamba outperforms all other state-of-the-art methods. Specifically, in the all-search mode, ReMamba achieved an 80.1\(\%\) Rank-1 accuracy and 78.1\(\%\) mAP, in the indoor-search mode, the model achieved an 85.4\(\%\) Rank-1 accuracy and 87.9\(\%\)mAP. The comparison includes various baseline methods such as image-level methods AlignGAN6, X-Modality5, and CAJ51; feature projection-based methods MPANet12, DEEN43, and SAAI53; ViT-based methods CMTR49and PMT15; and modality-specific methods MSCLNet54. Our experimental results clearly surpass those of these methods
RegDB: As evidenced in Table 1, ReMamba showcases compelling performance even on the relatively smaller RegDB dataset. For the VIS to IR mode, the proposed ReMamba achieved a 91.2\(\%\) Rank-1 accuracy and 84.6\(\%\) mAP. For the IR to VIS mode, ReMamba obtained a 90.9\(\%\) Rank-1 accuracy and 84.4\(\%\) mAP. The outcomes underscore that the proposed ReMamba effectively mitigates the differences between VIS and IR modalities.
LLCM: Table 1 also presents the comparison results of ReMamba and SOTAs on the LLCM dataset. In the IR to VIS mode, ReMamba achieved a 57.1\(\%\) Rank-1 accuracy and 63.9\(\%\)mAP. Additionally, in the VIS to IR mode, ReMamba significantly outperformed the second-best performing method, DEEN43, achieving a 64.9\(\%\) Rank-1 accuracy and 68.4\(\%\) mAP. Regardless of the test mode, ReMamba consistently achieved the best performance, demonstrating the model’s robust discrimination capability.
Ablation studies
In this subsection, we perform ablation studies to validate the efficacy of the proposed ReMamba model. All experiments for these ablation studies are conducted on the SYSU-MM01 dataset.
Effectiveness of each component
To evaluate the contribution of each core component to the performance of ReMamba, we assessed their impact by progressively removing specific modules, including the Visual State Space (VSS) module, the Adaptive Feature Aggregation (AFA) module, the Modal Consistency Identity Constrained Loss (\({\mathscr {L}}_{MIC}\)), and the Auxiliary Aggregation Loss (\({\mathscr {L}}_{AA}\)). The experimental results are shown in Table 2, with all experiments using the dual-stream ResNet-50 model pre-trained on ImageNet as the baseline (EXP 1) to ensure fairness in comparison.
Starting from EXP 2, adding the VSS block resulted in a performance improvement, indicating that building long-range dependencies between features can effectively enhance the model’s discriminative ability.
Subsequently, in EXP 3, adding the AFA block led to significant improvements in Rank-1/mAP by 5.5\(\%\)/10.6\(\%\) and 6.5\(\%\)/7.9\(\%\) in the all-search and indoor-search modes, respectively. This robustly demonstrates that the AFA block can effectively mitigate feature redundancy and bridge the semantic gap between local and global features, allowing local information to be efficiently aggregated into global representations to form discriminative person representations.
In EXP 4, adding \({\mathscr {L}}_{MIC}\) to the baseline yielded a considerable improvement, indicating that \({\mathscr {L}}_{MIC}\) can effectively alleviate modal discrepancies and reduce intra-modal variations. However, in EXP 5 and EXP 6, individually adding \({\mathscr {L}}_{MIC}\) or \({\mathscr {L}}_{AA}\) to the configuration already containing VSS and AFA (based on EXP 3) resulted in only slight improvements in Rank-1 performance, with overall results remaining unsatisfactory.
It was not until EXP 8, where both \({\mathscr {L}}_{MIC}\) and \({\mathscr {L}}_{AA}\) were incorporated into the network to form the complete ReMamba, that Rank-1/mAP improved by 4.6\(\%\)/3.0\(\%\) and 3.7\(\%\)/2.6\(\%\) in the all-search and indoor-search modes, respectively. This outcome underscores that applying \({\mathscr {L}}_{MIC}\) for both intra-modal and inter-modal constraints, along with \({\mathscr {L}}_{AA}\) for auxiliary aggregation, allows for mutual benefits in feature constraining, significantly optimizing performance.
Finally, in EXP 7, removing the AFA module and the \({\mathscr {L}}_{AA}\) resulted in a significant decline in performance compared to the fully configured ReMamba. This outcome further demonstrates the critical role of the AFA module and the \({\mathscr {L}}_{AA}\) in the overall efficiency of the system.
The influence of the hyperparameters \(\lambda\)
To systematically analyze the impact of the hyperparameter \(\lambda\) on performance, we conducted a detailed quantitative evaluation under the all-search mode on the SYSU-MM01 dataset, summarizing the results in Figure 4. As we can see, the model attains its peak Rank-1 accuracy and mean Average Precision (mAP) when the hyperparameter \(\lambda\) is set to 0.5.

The impact of varying values of the hyperparameter \(\lambda\) on the performance of the SYSU-MM01 dataset.
Comparison with ViT and gated CNN
In this study, we employed the Visual State Space (VSS) block as a pivotal component to process global information, while ViT16and Gated CNN55 have been proven effective in VI-ReID or other long-sequence tasks. Therefore, we compared these three methods to explore the best strategy for capturing long-range dependencies. For fairness, when comparing the other two methods, we only replaced the original VSS block with ViT and Gated CNN, respectively, without altering the rest of the network architecture and training settings. As shown in Table 3, the VSS block significantly outperformed both the ViT and Gated CNN in the all-search and indoor-search modes of the SYSU-MM01 dataset. Additionally, the VSS block had a noticeably lower parameter count than the other two. This result verifies the VSS block’s superior capability in computational efficiency and in constructing and leveraging long-range feature dependencies.
The influence of each components in AFA module
The proposed Adaptive Feature Aggregation (AFA) module reduces information redundancy and addresses semantic differences through feature selection and interaction. This module consists of three main components: feature selection, cross-attention, and self-attention mechanisms. To understand the specific contribution of each component of the AFA module to model performance, we designed and conducted a series of ablation studies on the SYSU-MM01 dataset. As shown in Table 4, in the all-search mode, using cross-attention combined with concatenation for feature interaction and fusion improved performance by 2.1\(\%\) in Rank-1 and 2.7\(\%\) in mAP compared to using concatenation alone. Furthermore, adding self-attention further boosts Rank-1 by 0.8\(\%\) and mAP by 2.5\(\%\), strengthening feature semantic representation. Finally, by integrating the feature selection component to form a complete AFA module, the model’s Rank-1 and mAP increased by an additional 3.8\(\%\), strongly confirming the critical role of adaptive feature selection in eliminating redundant features during feature fusion.
Visualization analysis
Feature distribution visualization
To investigate the effectiveness of ReMamba, we first visualized the intra-class and inter-class feature distances using the LLCM dataset, the corresponding results are presented in Figures 5(a-c). It can be seen that, compared to the initial features (Figure 5(a)) and baseline features (Figure 5(b)), the mean distances (vertical lines) between intra-class and inter-class features in ReMamba (Figure 5(c)) were expanded. This indicates that ReMamba not only effectively reduced the distances of similar features and increased the separations between different classes but also significantly alleviated the modal discrepancies between VIS and IR features, thereby enhancing cross-modality matching performance.
Subsequently, we utilized t-SNE56 to plot the feature distributions obtained by different methods on the LLCM dataset in a 2D plane (see Figures 5(d-f)). Compared to the baseline, ReMamba excelled in increasing the compactness of intra-class features and expanding inter-class distances, contributing to a more compact and distinct intra-class feature space. These intuitive visual evidences collectively confirmed the effectiveness of ReMamba in reducing modal discrepancies and enhancing feature discriminability.

Figures (a-c) illustrate the intra-class distances in blue and inter-class distances in green for VIS and IR features on the LLCM dataset. Figures (d-f) depict the 2D distribution of person features from both VIS and IR modalities on the same dataset. Here, triangles denote VIS modality features, and circles represent IR modality features.
Retrieval result
In order to provide further validation of the effectiveness of the ReMamba model, we presented the top 10 retrieval samples for a query on the LLCM dataset, as shown in Figure 6. In this display, the retrieved images that are marked with green borders represent correct matches, while those with red borders indicate incorrect matches. The first two rows for each method represent the retrieval results from IR to VIS test mode, and the last two rows represent the retrieval results from VIS to IR test mode. It is evident that the ReMamba model exhibited enhanced discriminative ability compared to the baseline, significantly improving both ranking results and retrieval accuracy.

Visualization of the Rank-10 retrieval results on the LLCM dataset. Here, red boxes denote incorrect matches, whereas green boxes highlight correct identifications. Figure (a) showcases the outcomes using the baseline method, in contrast, figure (b) presents the results achieved by our proposed ReMamba framework.
Conclusion
In this paper, We propose a novel CNN-Mamba hybrid framework that integrates a backbone network, a Visual State Space (VSS) module, and an Adaptive Feature Aggregation (AFA) module, aiming to better fuse detailed information with global semantic information. Specifically, we adopt a progressive aggregation strategy, gradually aggregating multi-scale local features extracted by the backbone network into the global representation extracted by VSS block to enhance the clarity of local details in the global representation. Considering the potential issues of information redundancy and semantic deviation during feature aggregation, we design the AFA block to automatically filter features and bridge semantic gaps. Simultaneously, we introduce an Auxiliary Aggregation loss to supervise this aggregation process. Extensive experiments on publicly available datasets SYSU-MM01, RegDB, and LLCM validate the effectiveness of our method.
Data availibility
The datasets analyzed during this study are available in the following public ___domain resources: https://github.com/wuancong/SYSU-MM01, http://dm.dongguk.edu/link.html, https://github.com/ZYK100/LLCM.
References
Chen, W., Chen, X., Zhang, J. & Huang, K. Beyond triplet loss: a deep quadruplet network for person re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, 403–412 (2017).
He, S. et al. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF international conference on computer vision, 15013–15022 (2021).
Luo, H., Gu, Y., Liao, X., Lai, S. & Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 0–0 (2019).
Ye, M. et al. Deep learning for person re-identification: A survey and outlook. IEEE transactions on pattern analysis and machine intelligence 44, 2872–2893 (2021).
Li, D., Wei, X., Hong, X. & Gong, Y. Infrared-visible cross-modal person re-identification with an x modality. In Proceedings of the AAAI conference on artificial intelligence 34, 4610–4617 (2020).
Wang, G. et al. Rgb-infrared cross-modality person re-identification via joint pixel and feature alignment. In Proceedings of the IEEE/CVF international conference on computer vision, 3623–3632 (2019).
Zhang, Y., Yan, Y., Lu, Y. & Wang, H. Towards a unified middle modality learning for visible-infrared person re-identification. In Proceedings of the 29th ACM international conference on multimedia, 788–796 (2021).
Zhong, X. et al. Visible-infrared person re-identification via colorization-based siamese generative adversarial network. In Proceedings of the 2020 International Conference on Multimedia Retrieval, 421–427 (2020).
Liu, S. & Zhang, J. Local alignment deep network for infrared-visible cross-modal person reidentification in 6g-enabled internet of things. IEEE Internet of Things Journal 8, 15170–15179 (2020).
Park, H., Lee, S., Lee, J. & Ham, B. Learning by aligning: Visible-infrared person re-identification using cross-modal correspondences. In Proceedings of the IEEE/CVF international conference on computer vision, 12046–12055 (2021).
Wei, Z., Yang, X., Wang, N. & Gao, X. Flexible body partition-based adversarial learning for visible infrared person re-identification. IEEE Transactions on Neural Networks and Learning Systems 33, 4676–4687 (2021).
Wu, Q. et al. Discover cross-modality nuances for visible-infrared person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4330–4339 (2021).
Hu, W., Liu, B., Zeng, H., Hou, Y. & Hu, H. Adversarial decoupling and modality-invariant representation learning for visible-infrared person re-identification. IEEE Transactions on Circuits and Systems for Video Technology 32, 5095–5109 (2022).
Liang, T., Jin, Y., Liu, W. & Li, Y. Cross-modality transformer with modality mining for visible-infrared person re-identification. IEEE Trans. Multim. 25, 8432–8444. https://doi.org/10.1109/TMM.2023.3237155 (2023).
Lu, H., Zou, X. & Zhang, P. Learning progressive modality-shared transformers for effective visible-infrared person re-identification. In Williams, B., Chen, Y. & Neville, J. (eds.) Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2023, Washington, DC, USA, February 7-14, 2023, 1835–1843, https://doi.org/10.1609/AAAI.V37I2.25273 (AAAI Press, 2023).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint[SPACE]arXiv:2010.11929 (2020).
Feng, Y. et al. Visible-infrared person re-identification via cross-modality interaction transformer. IEEE Trans. Multim. 25, 7647–7659. https://doi.org/10.1109/TMM.2022.3224663 (2023).
Zhao, J. et al. Spatial-channel enhanced transformer for visible-infrared person re-identification. IEEE Trans. Multim. 25, 3668–3680. https://doi.org/10.1109/TMM.2022.3163847 (2023).
Gu, A., Goel, K. & Ré, C. Efficiently modeling long sequences with structured state spaces. The International Conference on Learning Representations (ICLR) (2022).
Gu, A. & Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. First Conference on Language Modeling (2024).
He, X. et al. Pan-mamba: Effective pan-sharpening with state space model. arXiv preprint[SPACE]arXiv:2402.12192 (2024).
Li, K. et al. Videomamba: State space model for efficient video understanding. ECCV (2024).
Liu, Y. et al. Vmamba: Visual state space model. CoRR[SPACE]arXiv:2401.10166, https://doi.org/10.48550/ARXIV.2401.10166 (2024).
Ma, J., Li, F. & Wang, B. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint[SPACE]arXiv:2401.04722 (2024).
Qiao, Y. et al. Vl-mamba: Exploring state space models for multimodal learning. arXiv preprint[SPACE]arXiv:2403.13600 (2024).
Chen, G., Lin, C., Ren, L., Lu, J. & Zhou, J. Self-critical attention learning for person re-identification. In Proceedings of the IEEE/CVF international conference on computer vision, 9637–9646 (2019).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Chen, D., Xu, D., Li, H., Sebe, N. & Wang, X. Group consistent similarity learning via deep crf for person re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, 8649–8658 (2018).
Wang, G., Lin, L., Ding, S., Li, Y. & Wang, Q. Dari: Distance metric and representation integration for person verification. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30 (2016).
Hu, W. & Hu, H. Domain-private factor detachment network for nir-vis face recognition. IEEE Transactions on Information Forensics and Security 17, 1435–1449. https://doi.org/10.1109/TIFS.2022.3160612 (2022).
Zhu, Y. et al. Hetero-center loss for cross-modality person re-identification. Neurocomputing 386, 97–109 (2020).
Liu, H., Tan, X. & Zhou, X. Parameter sharing exploration and hetero-center triplet loss for visible-thermal person re-identification. IEEE Transactions on Multimedia 23, 4414–4425 (2020).
Hu, W., Yang, Y. & Hu, H. Pseudo label association and prototype-based invariant learning for semi-supervised nir-vis face recognition. IEEE Transactions on Image Processing 33, 1448–1463. https://doi.org/10.1109/TIP.2024.3364530 (2024).
Zhu, L. et al. Vision mamba: Efficient visual representation learning with bidirectional state space model. Forty-first International Conference on Machine Learning (2024).
Xing, Z., Ye, T., Yang, Y., Liu, G. & Zhu, L. SegMamba: Long-range Sequential Modeling Mamba For 3D Medical Image Segmentation . proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024 LNCS 15008 (2024).
Ruan, J. & Xiang, S. Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint[SPACE]arXiv:2402.02491 (2024).
Guo, H. et al. Mambair: A simple baseline for image restoration with state-space model. ECCV (2024).
Chaudhuri, S. & Bhattacharya, S. Simba: Mamba augmented u-shiftgcn for skeletal action recognition in videos. arXiv preprint[SPACE]arXiv:2404.07645 (2024).
Xie, X. et al. Fusionmamba: Dynamic feature enhancement for multimodal image fusion with mamba. arXiv preprint[SPACE]arXiv:2404.09498 (2024).
Luo, H., Gu, Y., Liao, X., Lai, S. & Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 0–0 (2019).
Wu, A., Zheng, W.-S., Yu, H.-X., Gong, S. & Lai, J. Rgb-infrared cross-modality person re-identification. In Proceedings of the IEEE international conference on computer vision, 5380–5389 (2017).
Nguyen, D. T., Hong, H. G., Kim, K. W. & Park, K. R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 17, 605 (2017).
Zhang, Y. & Wang, H. Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2153–2162 (2023).
Zhong, Z., Zheng, L., Kang, G., Li, S. & Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI conference on artificial intelligence 34, 13001–13008 (2020).
Wu, A., Zheng, W.-S., Yu, H.-X., Gong, S. & Lai, J. Rgb-infrared cross-modality person re-identification. In Proceedings of the IEEE international conference on computer vision, 5380–5389 (2017).
Choi, S., Lee, S., Kim, Y., Kim, T. & Kim, C. Hi-cmd: Hierarchical cross-modality disentanglement for visible-infrared person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10257–10266 (2020).
Ye, M., Shen, J., J. Crandall, D., Shao, L. & Luo, J. Dynamic dual-attentive aggregation learning for visible-infrared person re-identification. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVII 16, 229–247 (Springer, 2020).
Fu, C. et al. CM-NAS: cross-modality neural architecture search for visible-infrared person re-identification. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, 11803–11812, https://doi.org/10.1109/ICCV48922.2021.01161 (IEEE, 2021).
Jiang, K. et al. Cross-modality transformer for visible-infrared person re-identification. European Conference on Computer Vision 480–496 (2022).
Ye, M., Ruan, W., Du, B. & Shou, M. Z. Channel augmented joint learning for visible-infrared recognition. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, 13547–13556, https://doi.org/10.1109/ICCV48922.2021.01331 (IEEE, 2021).
Liu, J. et al. Learning memory-augmented unidirectional metrics for cross-modality person re-identification. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, 19344–19353, https://doi.org/10.1109/CVPR52688.2022.01876 (IEEE, 2022).
Qiu, L. et al. High-order structure based middle-feature learning for visible-infrared person re-identification. Proceedings of the AAAI Conference on Artificial Intelligence 38, 4596–4604 (2024).
Fang, X., Yang, Y. & Fu, Y. Visible-infrared person re-identification via semantic alignment and affinity inference. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, 11236–11245, https://doi.org/10.1109/ICCV51070.2023.01035 (IEEE, 2023).
Zhang, Y., Zhao, S., Kang, Y. & Shen, J. Modality synergy complement learning with cascaded aggregation for visible-infrared person re-identification. In Avidan, S., Brostow, G. J., Cissé, M., Farinella, G. M. & Hassner, T. (eds.) Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XIV, vol. 13674 of Lecture Notes in Computer Science, 462–479, https://doi.org/10.1007/978-3-031-19781-9_27 (Springer, 2022).
Yu, W. & Wang, X. Mambaout: Do we really need mamba for vision? CoRR[SPACE]arXiv:2405.07992, https://doi.org/10.48550/ARXIV.2405.07992 (2024).
van der Maaten, L. & Hinton, G. Visualizing data using t-sne. Journal of Machine Learning Research 9, 2579–2605 (2008).
Acknowledgements
This article is supported by the Key Research and Development Program of the Autonomous Region (No.2022B01008), the Tianshan Science and Technology Innovation Leading talent Project of the Autonomous Region (No. 2022TSYCLJ0037), the National Natural Science Foundation of China (No. 62262065), the National Key R&D Program of China (No. 2022ZD0115802) and the National Science Foundation of China(No. 62341206).
Author information
Authors and Affiliations
Contributions
Geng is responsible for manuscript drafting, review, editing, as well as model design and implementation. Peng is responsible for manuscript review and editing. Yang is responsible for funding acquisition and supervision. Chen is responsible for formal analysis and data curation. Lv, Li, and Shao are responsible for software design. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Geng, H., Peng, J., Yang, W. et al. ReMamba: a hybrid CNN-Mamba aggregation network for visible-infrared person re-identification. Sci Rep 14, 29362 (2024). https://doi.org/10.1038/s41598-024-80766-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-80766-8
