
Abstract
Early detection of colorectal carcinoma (CRC), one of the most prevalent forms of cancer worldwide, significantly enhances the prognosis of patients. This research presents a new method for improving CRC detection using a deep learning ensemble with the Computer Aided Diagnosis (CADx). The method involves combining pre-trained convolutional neural network (CNN) models, such as ADaRDEV2I-22, DaRD-22, and ADaDR-22, using Vision Transformers (ViT) and XGBoost. The study addresses the challenges associated with imbalanced datasets and the necessity of sophisticated feature extraction in medical image analysis. Initially, the CKHK-22 dataset comprised 24 classes. However, we refined it to 14 classes, which led to an improvement in data balance and quality. This improvement enabled more precise feature extraction and improved classification results. We created two ensemble models: the first model used Vision Transformers to capture long-range spatial relationships in the images, while the second model combined CNNs with XGBoost to facilitate structured data classification. We implemented DCGAN-based augmentation to enhance the dataset’s diversity. The tests showed big improvements in performance, with the ADaDR-22 + Vision Transformer group getting the best results, with a testing accuracy of 93.4% and an AUC of 98.8%. In contrast, the ADaDR-22 + XGBoost model had an AUC of 97.8% and an accuracy of 92.2%. These findings highlight the efficacy of the proposed ensemble models in detecting CRC and highlight the importance of using well-balanced, high-quality datasets. The proposed method significantly enhances the clinical diagnostic accuracy and the capabilities of medical image analysis or early CRC detection.
Similar content being viewed by others
Introduction
New studies show that CRC will continue to dictate the lives of many long into this year and possibly 2024, with an uptick of more than 2.2 million new cases. It made it 1,75,0000 cases beyond US borders, accompanied by a single death toll1. Cases of colorectal cancer are common and considered to be one of the severe types of cancer, and hence, the findings are very valuable in emphasizing the need to enhance the efficiency of diagnosis and treatment approaches. Despite the many advances in the fields of diagnostics and therapeutics, colon cancer (CRC) is still a health care issue of global proportions. Pre-hypnotic diagnosis is still a problem all around the globe because more focus is centred on the provision of such healthcare services. Worldwide, colorectal cancer is among the most prevalent causes of cancer-related mortality. Despite the importance of early and accurate detection in enhancing survival rates, current diagnostic instruments frequently fail to provide the necessary sensitivity and specificity for comprehensive screening.
The worldwide incidence of colorectal cancer also shows geographical variation. The incidence rates for CRC are among the highest in the high-income countries like the United States of America, Japan, and some countries of Europe. In the international context, Japan is characterized by a high level of age-standardized incidence rates of colorectal cancer and mortality rates2. Comparatively, the number of cases reported in low and middle-income countries such as India is less; this is mostly because of an under-records and limited access to screenings and diagnoses. Colorectal cancer is the sixth most prevalent cancer in India where the estimated rate of new cases is 70,000 and the death toll is about 41,0003,4. The differences in the healthcare facilities and the varied patterns of disease can be seen from the fact that the incidence rate in India is 4.9 per 100,000 as compared to high-income countries like Japan where it is 36.6 per 100,0005.
Multifactorial, including hereditary and environmental components, play important roles in the development of colorectal cancer. Some of the causes that are known to raise the risk of this condition include; high intake of red and processed meat, low fibre intake, obesity, lack of physical activities, smoking and excessive alcohol intake. Colorectal cancer is genetic and there is a high probability of one being affected by the disease if members of the family are affected. This supports the genetic basis of diseases since the children are born with the gene that makes them vulnerable to the disease.
Although CRC incidence continues to rise, healthcare infrastructure and specialists’ distribution remain uneven across different regions. This is because the people in high income countries are likely to be diagnosed early and have better chance of surviving because of increased awareness and improved screening methods including colonoscopy and faecal occult blood test. On the other hand, LMICs like India also have challenges like inadequate health literate populations, diagnosis at later stages of cancer, and a specific shortage of trained human resource in cancer care.
Once detected early enough, colorectal cancer is very easy to treat and this enhances the overall survival rates. 5-year survival of CRC can be more than 90% in case of early diagnosis of the disease6. However, this ratio is rather low when cancer is discovered at a later stage, when treatments are less efficient. Problems with invasiveness, patient pain, and poor compliance rates prevent early detection, even while efficient screening technologies like colonoscopy and faecal occult blood tests are available. This is particularly true in low- and middle-income nations7. Given this situation, it is clear that easily accessible and integrable non-invasive early detection methods are required.
Artificial intelligence (AI) has the potential to revolutionise medical imaging, allowing for more precise identification and diagnosis of colorectal cancer. An area of artificial intelligence known as deep learning has shown enormous promise in evaluating massive amounts of imaging data, detecting early indicators of colorectal cancer (CRC), and assisting physicians with decision-making. These models powered by AI, especially those built on deep learning, can analyse medical images with remarkable precision, often matching or even outperforming human experts. The use of deep learning in colorectal cancer diagnosis has yielded remarkable results, particularly in the areas of polyp and adenoma identification and classification, which are critical for early intervention.
However, the application of AI in identifying CRC comes with certain problems. This is because a model that has been trained to work on one specific population or type of imaging is very likely to fail when exposed to another population or type of imaging data if it was trained on a small and/or skewed dataset. The use of input from different categories of data, for example, clinical notes and images, leads to a number of further issues. To these challenges, this study seeks to establish how it is possible to improving the accuracy of colorectal cancer assessment by incorporating deep learning models such as XGBoost and Vision Transformers with CNNs. In the field of medical image analysis, conventional deep learning techniques, including convolutional neural networks (CNNs), have made substantial breakthroughs. In contrast, these models frequently encounter difficulties with feature extraction, particularly when dealing with intricate datasets such as colonoscopy images. Additionally, the poor generalisation of models, resulting from class imbalance in medical datasets, further restricts their diagnostic utility.
This investigation uses the CKHK-22 dataset, a massive compilation from three well-known datasets: Hyper Kvasir, CVC Clinic DB, and Kvasir2. Once we narrowed down the dataset to 14 acceptable classes, we reduced the number of images from 19,621 to 16,942. This we were able to accomplish by removing 24 classes. The main idea of this procedure was to enhance the quality of the dataset and its usability, so that the evaluated models would be more precise and sophisticated.
The presented research uses a new approach to the integration of models, which is based on the ensemble learning framework, Vision Transformers, and XGBoost with pre-trained deep integrated CNN models, including ADaRDEV2I-22, DaRD-22, and ADaDR-22. The structured data is processed using XGBoost and for the images, Vision Transformers are used to extract spatial features from the images. For this purpose, we have applied the performance measures on the original data set as well as on the data set modified as per the proposed approach. When evaluating the AUC values and accuracy of all the ensemble configurations it can be seen that the size and quality of the dataset positively affects the model’s performance. The highest performance with the AUC of 98.80% was achieved by the ADaDR-22 + Vision Transformer ensemble. The training and testing set accuracies of the model that was designed were on the modified dataset it was 93.40%. This paper aims to resolve these obstacles by integrating a variety of sophisticated deep learning techniques. We introduce a novel ensemble learning framework that integrates CNNs, Vision Transformers, and XGBoost to improve the accuracy of both feature extraction and classification in the detection of colorectal carcinoma.
This study shows a new ensemble learning framework that uses Vision Transformers, XGBoost, and pre-trained deep CNN models (ADaRDEV2I-22, DaRD-22, and ADaDR-22) to improve the detection of colorectal cancer. Our method solves some of the biggest problems in medical imaging, like how hard it is to extract features and how unequal the classes are, by using Vision Transformers to get spatial features out of images and XGBoost to handle structured data. The integration of these models has led to significant enhancements in classification accuracy, enabling the ADaDR-22 + Vision Transformer ensemble to achieve state-of-the-art performance. This innovative ensemble demonstrates that the size and quality of the dataset positively influence the model’s performance, making it a valuable instrument for the identification of carcinomas.
Thus, the study finds that deep learning ensembles are applicable in medical image analysis and that there is need to use quality data to enhance the performance of the models. The findings from this study show that the use of ADaDR-22, Vision Transformer and a well-analysed dataset could greatly improve the diagnostic processes and the early detection of colorectal cancer. Due to the ability to support the early and more accurate diagnosis, these innovations can significantly decrease the world burden of this disease and improve patients’ outcomes.
Our study strategically integrates deep learning ensemble approaches to improve colorectal cancer diagnosis. The project progresses via five separate phases:
-
1.
The first step in improving the dataset was to narrow the CKHK-22 collection, which included 19,621 images across 24 classes, down to 14,942 high-quality images. This was important as it made the dataset to be suitable for training of the algorithms for cancer detection.
-
2.
Hence, the following approach is suggested in light of the findings of this paper: one should use three pre-trained Integrated CNNs, namely ADaRDEV2I-22, DaRD-22, and ADaDR-22. Then, we combine these CNN models with other advanced models such as XGBoost and Vision Transformers to enhance the extraction of features and the enhancement of classification accuracy due to the combination of the strengths of both models.
-
3.
We train and test the ensemble models with the original and the revised datasets. The two-evaluation metrics which we employ to fine-tune the models and ensure that they are able to identify the probable malignant lesions correctly are the testing accuracy and the area under the curve (AUC).
-
4.
In the analysis of the results of the collaboration of CNN + Vision Transformer and CNN + XGBoost, we consider the results of the ensembles on the two sets of data in the full study of the model after training. Such a investigation helps in identifying the right configuration for the diagnosis of colorectal cancer.
-
5.
The last step entails fine-tuning of the top-performing model with a view of making it ready for clinical application. We aim to improve patient’s care and advance medical practice by identifying and fine-tuning the best performing ensemble for the early detection of Colorectal Cancer.
We structure the remaining portion of this paper as follows: In Section 2, the most recent developments in medical image classification based on deep learning are the primary focus of the detailed overview of the related work. The methodology is defined in Section 3, which encompasses the data preprocessing stages, CNN integration, Vision Transformer adoption, and XGBoost implementation. Section 4 presents the experimental setup and results, along with a comparison with existing models. Section 5 focuses on the results, highlighting the strengths and weaknesses of the proposed method. Finally, Section 6 concludes the paper by delineating potential clinical applications and future research directions.
Literature survey
Detailed literature review
Screening and diagnosis of CRC have greatly improved in the current generation due to the integration of AI and medical imaging. Colonoscopies and other conventional procedures are still the most reliable in the diagnosis of CRC due to the high level of accuracy in the identification of precancerous polyps and adenomas. On the other hand, these procedures often include invasiveness, patient discomfort, and the need for trained personnel. This has led to increased research on improving the precision, timeliness, and availability of CRC screening using AI-based diagnostic tools. This literature review looks at the current state of CRC detection with a focus on deep learning models, data augmentation approaches, and ensemble methods in order to improve diagnostic results.
New studies reveal that AI, and deep learning models like CNNs and ViTs, are capable of changing diagnosis in the medical field. These models’ ability in feature extraction and classification can result in better identification of CRC from medical images. The ensemble methods that are the methods which combine the features of other models to form a new one can be of help in boosting the diagnostic performance.For instance, when using XGBoost with CNNs, there is enhanced prediction performance as compared to the use of the two models separately. In consequence, to overcome the problems related to the lack of comprehensive and comparable data, researchers applied GAN and other data augmentation methods. This summary presents a review of these developments, which includes the major works, approaches, and findings in the field. Further, it discusses gaps, limitations, and possible future studies concerning the diagnosis of colorectal cancer. Table 1 contains a comprehensive literature review.
Recent advancements in deep learning-based skin cancer detection methods have shown promising results. For instance, SNC_Net25integrates handcrafted features with deep learning-based features using dermoscopy images for skin cancer detection, demonstrating the power of combining different feature extraction methods [Ahmad Naeem etal, 2024]. Similarly, DVFNet26uses a deep feature fusion-based model for multiclass skin cancer classification, highlighting the importance of combining features from multiple models for accurate diagnosis [Ahmad Naeem etal, 2024]. Other studies, such as SCDNet27 and the Multi-model Fusion Technique, have successfully applied deep learning frameworks to detect and classify skin cancer, further supporting the effectiveness of CNNs and fusion techniques in medical image analysis [Ahmad Naeem etal, 2024].
Research deficits
AI has advanced the diagnosis of colorectal cancer (CRC) greatly but there are gaps in the current literature. The current models, especially the CNN-based ones, are heavily reliant on unique datasets such as Kvasir and Hyper Kvasir, making them unable to generalize across various populations. The main issue is that it is only suitable for big clinical settings. This is mostly due to the absence of adequate feature extraction in most models, and one of the most impacted regions is the small polyps, which are critical in early diagnosis but difficult to identify. The current architectures like GAN and ViT cannot be easily used in such situations as they are computationally expensive. Other methods that combine the CNN with XGBoost have also given some promising results but are likely to over-fit especially when dealing with small or less diverse data sets. To this end, it is possible to develop models that are able to capture imaging data, as well as their distribution.
The most of the previous works on AI carcinoma detection were focused on developing a single type of model, such as CNNs or gradient boosting algorithms represented by XGBoost, which could not effectively fuse the following global and local features: though a few recent works have explored the applications of ViTs in medical imaging, their integration with CNNs and structurally classifiers like XGBoost remains relatively under-explored. Moreover, there is a remarkable lag in feature extraction techniques that are specifically dedicated to the detection of colorectal carcinoma. This work presents an ensemble framework that integrates pre-trained CNNs such as ResNet-50, DenseNet-201, and VGG-16, ViTs, and XGBoost, wherein the strengths of all the individual models could be combined with improved diagnostic accuracy. This work investigates a new approach for improving carcinoma detection on the wide CKHK-22 dataset and yields better accuracy with more interpretability compared to state-of-the-art methods.
Resolving research gaps: the ideal approach
This research provides a clear plan that employs some of the most sophisticated methods to address the validity, the external validity and efficiency gaps with regards to the CRC diagnostic models with the aim of closing them. To collect a large number of diverse images of different origins, and the people of different ages and genders, for training the model, we will prepare the data set. This result will be achieved by including Vision Transformers in our ensemble models to improve the identification of tiny polyps having benefited from better feature extraction skills. We also plan to compare few ensemble methods of CNNs with Vision Transformers or CNNs with XGBoost to know which method can gives the best trade-off of time and precision of diagnosis. In order to avoid cases where the model tends to fit to the training data in an extreme way, I will employ regularisation techniques and also employ cross validation in a very keen manner so that to ensure that the model is stable all the time and also performs well in other different data sets. These strategies are the foundation of the proposed method that aims at transforming the way of CRC detection with reference to existing drawbacks.
Materials and methods
Ensemble CADx for the diagnosis of colorectal carcinoma
An increase in colorectal cancer (CRC) cases has prompted research into developing better diagnostic techniques, especially for use in CADx systems28. These methods have greatly improved the detection and diagnosis of CRC in medical imaging using deep learning. Feature extraction from medical images is where convolutional neural networks (CNNs) have shone. Integrating more powerful models, such as Vision Transformers (ViTs) and XGBoost, is crucial for improving diagnostic accuracy and resilience.
We’re introducing two distinct CADx systems that use the capabilities of Integrated CNNs with Vision Transformers, or XGBoost, to enhance carcinoma of colorectal recognition. In the first system, we use convolutional neural networks (CNNs) for basic spatial hierarchy learning, and then add Vision Transformers to enhance it with additional feature extraction capabilities through self-attention processes. In order to improve prediction performance, the second system combines CNNs with XGBoost and makes use of its gradient-boosting features. This two-pronged strategy aims to deliver high-accuracy diagnostic tools in clinical settings where qualified diagnosticians are scarce. From dataset compilation to model assessment to prediction results, the following sections describe both systems’ processes.
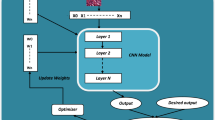
Introduction to ensemble CADx systems
The study demonstrates two modern CADx systems designed for colorectal carcinoma diagnosis (Figs. 2 and 3). These include the integration of CNN spatial hierarchy learning and Vision Transformer self-attention mechanism and as such, the architecture of the proposed GIEnsemformerCADx and GIEnsemXGBOOSTCADx is depicted in Fig. 1 which combines CNNs with XGBoost’s boosting based on gradient values. Each system tries to provide viable diagnostic tools in the clinical ___domain with emphasis on timely and accurate identification of colorectal cancer.

Block diagram of GIEnsemformerCADx and GIEnsemXGBOOSTCADx.
Preparation of datasets
Medical motion image collection utilising colonoscopy
Colonoscopy is an essential tool to diagnose polyps, lesions, and cancerous changes in the colon. Hence, in a colonoscopy, a long and flexible tube which has a light at the tip, known as endoscope, is inserted through the rectum in order to examine the entire colon29. This camera can take high-resolution images of the inside of the colon that are diagnostically useful. Our methodology involves collecting and classifying these images according to criteria such as the presence of lesions, inflammation, or other abnormalities.
We obtained the datasets for medical colonoscopy motion images from three open-source image collections: Hyper Kvasir, Kvasir2, and CVC Clinic DB. A diverse array of labelled images, as demonstrated in these datasets, is essential for the development of robust deep-learning models. Images of the gastrointestinal system, classified with numerous classifications, illustrate differentiated conditions and regions in each dataset.
In this study, the CKHK-22 dataset that combines parts of three publicly available databases, namely CVC Clinic DB30, Kvasir231, and Hyper Kvasir32 were used. To increase the variety of the colorectal images, it was designed to be a strong base for training the deep learning models.
Out of the images in the CVC Clinic DB30dataset, 1640 images are labeled as polyps or non-polyps. Kvasir231has 8,000 images with 8 groups of images, and the types of medical conditions include ulcerative colitis, oesophagitis, dyed-lifted polyps, and more severe diseases. The Hyper Kvasir22 dataset has an even larger variety, which includes 10,682 images from the upper and lower gastrointestinal tract belonging to 23 classes.
The first reason that contributed to the establishment of CKHK-22 as a combined dataset of various colorectal diseases is the need to acquire much data33. Given this, the used mixed dataset is diverse and can help to train deep learning models that will have reasonable performance across different patients and imaging conditions. However, the source mixed dataset was defined by 24 classes, which could be somewhat challenging, particularly with regard to the class imbalance that impacts the model’s performance. For this reason, the solution was obtained by limiting the data to 14 clinically relevant classes and an equal distribution of classes. This enhancement in the model’s discrimination between these two classes of importance enhanced the diagnostic precision, which positively affected the class balance.
We then fine-tuned the models with the new dataset that consisted of high quality and sufficient data, and combined similar classes and eliminated classes with insufficient data to enhance the models’ credibility and applicability in clinical practice. This enabled the authors to accelerate and improve the training process without sacrificing the diagnostic potential of the model’s output by limiting the classification to 14 classes.
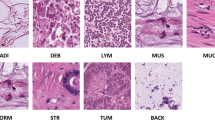
The detailed descriptions of the classes in the mixed dataset CKHK-22 and their modifications are shown in Table 2. Also, Fig. 2 shows sample images from the CKHK-22 dataset used in this research to provide an idea of the type and the amount of data used in this work.

The Sample Mixed CKHK-22 Dataset.
Augmentation of CKHK-22 Dataset
The only problem which can be pointed out concerning the CKHK-22 dataset is that some classes contain more samples than others which can lead to some overfitting; to overcome this, the dataset was augmented and the numbers of training images were balanced. The transformation that was used most often was the scaling transformation which contains zooming, rotation and flipping34. These changes improved on the models’ flexibility and reliability from which they could replicate real life imaging conditions.
-
Some of the images were magnified up to 20% as in actual colonoscopies it is possible to choose different levels of magnification.
-
To handle with the different positions of the camera in the medical images we used, we rotated the images up to 35 degrees.
-
Reflections were applied in the horizontal rotation to let the model learn the features that are invariant to the direction.
In the augmentation step the size of the dataset was raised significantly. According to the above description, CKHK-22 initial dataset has 19,621 images with 24 categories and increased to 30,000 images. The new dataset comprises 22,000 images in the following manner; the images of the 14 classes in the dataset are 16,942. This enhancement ensured that the database was balanced and therefore the model was provided with more image samples and the process of feature learning became more accurate.
DCGAN-Assisted augmentation of CKHK-22 images
To mitigate the class imbalance that is prevalent in medical imaging datasets, this investigation implements DCGAN-assisted augmentation. This method enhances the diversity of the dataset by generating synthetic images, ensuring that the model generalizes effectively to unobserved data. Improving model performance, particularly in under-represented classes, is contingent upon this augmentation step, which renders our method more resilient than conventional augmentation methods.
Data augmentation using Deep Convolutional Generative Adversarial Networks (DCGAN) enhanced the variety and resilience of the CKHK-22 dataset35. This method improves the model’s generalisability and helps fix the class imbalance by letting us create synthetic images by learning the original dataset’s distribution. A DCGAN’s architecture is essentially a generator and a discriminator.
To minimize the overfitting of CKHK-22 dataset and increase the variability of the dataset DCGAN was used. Thus, the performance of the model is improved and the class imbalance issue is tackled by generating more images from the same distribution as the given dataset. Thus, the DCGANs have two major parts that are the discriminator and the generator.
-
Generator Network: The generator network first takes an input of a random vector. Then it applies the transposed convolutional layers and batch normalisations on the image and applies ReLU to the image to decode it. Hence, the objective of the generator is to produce images that are as similar to the original images as can be.
-
Discriminator Network: This classifier is incorporated in the discriminator network that seeks to determine whether an image is real or forged. This paper employs Leaky ReLU to activate batch normalisation and convolutional layers in the work that is described in detail below. Hence, the discriminator assists in training the generator in producing better images that will enhance the classification of the discriminator.
On the other hand, it is the discriminator’s task to determine which images are real and which are fake, and the generator attempts to generate images which cannot be easily classified. We subject the generator to this hostile procedure until it is able to generate images that resemble the ones in the real world. We used three distinct augmentation methods on our CKHK-22 dataset: This includes; maximum 20% zoom, maximum 35-degree rotation and horizontal flipping only.
The architecture of DCGAN is illustrated in the following Fig. 3. The final augmented dataset is the data that has passed through the generator and discriminator networks as shown in this diagram that shows the different steps of augmentation.

The comprehensive architecture of DCGAN-assisted CKHK-22 augmentation.
Tables 3 and 4 show the augmentation strategy for the original and modified CKHK-22 dataset respectively. These tables show the particular augmentation method used for each class and the increase in the number of images.
We chose 14 out of 24 categories for this investigation to achieve a good balance among the classes and boost model performance. The initial dataset contained classes with a high degree of variability in image counts, resulting in a substantial class imbalance. We reduced the dataset to 14 well-represented categories in an effort to mitigate the noise from under-represented classes, which typically impairs model accuracy. This selection process enhanced the overall distribution of data across classes, leading to more stable training and improved generalisation, particularly for a critical medical imaging task like the detection of colorectal carcinoma.
We implemented DCGAN-assisted augmentation to further mitigate any remaining class imbalances by producing synthetic, realistic images that improved the dataset’s diversity. In addition to augmenting the training data’s size, this approach enhanced the model’s capacity to learn from under-represented patterns, which led to more robust performance and improved accuracy in the selected categories.
We did not implement SMOTE (Synthetic Minority Oversampling Technique), as its intended use with tabular data may not adequately capture the intricate spatial relationships inherent in medical images, such as colonoscopy data. Artefacts introduced by SMOTE may compromise the integrity of the images, while DCGAN produces more genuine, high-quality data, making it a superior option for image-based tasks.
The application of a cloud environment for data storage Google
The present research uses Google Cloud to store and archive all data sets, including the CKHK-22 data set. It is a very efficient way to manage and store data in a secure and sorted manner and with easy retrieval of such data36. After this, the datasets are uploaded to Google Cloud the researchers can arrange the datasets into folders in the account cloud storage. It also allows one to connect the Google Colab Pro + which is an upgraded version of Google Colab for data analysis and machine learning37. Using Google Cloud for data storage has two advantages: It assist in the protection of datasets and also provide way on how the data can be shared and used by many users and research groups.
Google Colab Pro + enables one to draw datasets from Google Cloud once they have been uploaded to the Cloud. Consequently, in the cloud environment, the datasets are prepared using the TensorFlow and Keras libraries. The data has to undergo pre-processing, through which it is cleaned from noise, normalized, colour corrected and resized before it is fed into the models. Real-time collaboration and tapping on Google’s computational capability for a proper and quick model training is due to the cloud-based approach whereby researchers can work on the datasets without having to worry about the storage capacity of their local systems. This configuration is most effective when using the large and cumbersome data sets, such as CKHK-22, where every inch of space and every cycle of processing power counts.
Image preprocessing for the CKHK-22 Medical Motion colonoscopy
This is the first step of the proposed method and hence, in order to feed the CKHK-22 colonoscopy image dataset into the deep learning models, the dataset needs to be pre-processed38. The reason for this is because the first frames that are obtained from medical motion sources may present several imperfections like amount of noise, improper color balance, and dimensions that may vary.
-
Noise Reduction:The medical images particularly colonoscopy can be contaminated with various forms of noise this could be as a result of motion or the endoscopic equipment used or even poor lighting. These elements are removed through noise reduction operations so that the main features of the images and the least amount of noise are preserved. Hence the quality of the images in this proposed method is enhanced and in turn characteristics of colorectal cancer can be easily detected.
-
Normalization: The other important transformation is normalisation where the pixel intensities are transformed to a standard range which is normally from 0 to 1. This ensures the quality of the input data to the models especially for the long learning models is protected. It also assists in diminishing the effects of lighting and contrast variations which in-turn increases the models’ reliability and speeds up the training process.
-
Color Correction: The color in the colonoscopy images can be altered either by the differences in lighting or the customized settings of the endoscopic equipment. We apply corrections to the color in order to neutralize these differences and increase the uniformity of the dataset. Color disparities affect models, thus this change is made to assist them to identify the real characteristics associated with carcinomas.
-
Resizing: Since the dimensions of the colonoscopy images vary, it is crucial to standardize the dimension of the images that are fed to the neural networks. All the images in the current undertaking have been resized to 224 by 224 pixels; this size retains adequate details while at the same time using minimal computational power. This scaling is important as a way of ensuring that the models are trained with data that has the same dimension thus making the training process easier and making the model suitable for any size of images.
Therefore, before training or testing the CKHK-22 dataset for the deep learning models in this study, these vital processes could not have been ignored. If the images are less variant, cleaner and more structurally sound, then the model learning for identification and classification of colorectal carcinoma would be more efficient and hence the diagnostics would be more reliable.
Image datasets train and test splitting possibility
In both the 24-class CKHK-22 dataset and the 14-class version of it, we split the data into training and testing in an 80:20 split. This is because machine learning recognizes it for its potential to train the model with the proper quantity of data and at the same time set aside a large chunk for the validation. To this end, the model is provided with 80 percent of the dataset, known as the training set, with different examples of the patterns in the dataset to learn from. The testing set, which is the 20% of the given data set, checks the efficiency of the model on new data. This helps in avoiding overfitting of the model and the model is able to predict well on data other than the training data.
This split is made as a result of the fact that there is a certain amount of data required to train the given model and there is also a certain amount of data which is needed to validate the model. This becomes even more important in healthcare imaging applications where the class imbalance is quite significant and it is essential to evaluate the model’s performance effectively. The Table 5 and Figs. 4 and 5 show the assessment of the number of images for the training and testing sets in the original and modified data. This information helps in the training and validation of the model on balanced data as well as giving information on the structure of the data.

Train-test split for original dataset (CKHK-22)−24 classes.

Train-test split for modified dataset (CKHK-22)−14 classes.
Model preparation for ensemble CADx systems
This method is unique in that it combines multiple deep learning models. Pre-trained CNNs capture local spatial features from colonoscopy images, while Vision Transformers derive global relationships using self-attention mechanisms. Additionally, we implement XGBoost, renowned for its efficient management of structured data, to enhance classification performance. Medical imaging has not previously employed this unique combination for the detection of colorectal carcinoma, leading to a more comprehensive feature extraction and increased accuracy.
Integrated CNNs
All of our CADx systems are based on three kinds of CNN models integrated into the system, which are built from several pre-trained CNN architectures. These integrated models were named as ADaRDEV2I-22, ADaDR-22, and DaRD-22 due to their being established in the year 202239 and the details of each Integrated CNN model is presented in the Table 6.
-
ADaRDEV2I-22: Following this model, it pre-trains eight types of CNNs, CNN-1 to CNN-8. The tested architectures include AlexNet40, DarkNet-1941, InceptionResNetV242, EfficientNet-B743, DenseNet-20144, ResNet-50v245, VGG-1646, and VGG-1947. To enhance the general classification performance, ADaRDEV2I-22 composes the functions of several models to extract a large number of features from the colonoscopy images.
-
ADaDR-22: The ADaDR-22 model unites three convolutional neural network (CNN) architectures: The following are some of the most frequently employed networks in this work; AlexNet, DarkNet-19, DenseNet-201, and ResNet-50V2. This configuration solves the problem of the model complexity and computational efficiency for the detection of colorectal cancer.
-
DaRD-22: The DaRD-22 model constitutes three convolutional neural network architectures: Some of the models are the DarkNet-19, ResNet-50V2, and DenseNet-201. This model is still quite efficient in the extraction and classification of features even though it is lighter in weight.
The integrated CNNs used in this work, namely ADaRDEV2I-22, ADaDR-22, and DaRD-22, represent a diverse combination of pre-trained architectures for the optimal detection of colorectal carcinoma. The adoption of eight significant pre-trained CNNs—AlexNet, DarkNet-19, InceptionResNetV2, EfficientNet-B7, DenseNet-201, ResNet-50v2, VGG-16, and VGG-19—renders the ADaRDEV2I-22 model powerful by obtaining a wide range of features from colonoscopy images, thus increasing the general performance of classification. This huge portfolio of models effectively captures fine-grained and high-level features and thus achieves outstanding performance in challenging medical imaging tasks. On the contrary, the ADaDR-22 model combines the strengths of AlexNet, DarkNet-19, DenseNet-201, and ResNet-50v2 into one model; it balances model computational efficiency with the overall model complexity to obtain robust performance with a smaller resource demand. The DaRD-22 model is lightweight but a very powerful model for feature extraction and classification. Collectively, these integrated CNNs offer complementary strengths on combining feature diversity with computational efficiency and scalability; hence, they are ideal to constitute the proposed ensemble framework for colorectal carcinoma detection.
An erratum of the architecture of the ADaDR-22 model is described to explain the class label prediction method that includes the stacking of several CNN layers and then feeds through neural networks as illustrated in Fig. 6. The same process is applied to the other incorporated CNN models; the only difference being the structure that is used.

An Integrated CNN Architecture of ADaDR-22 model.
To make the method more interesting and get the best results, it was necessary to use a number of pre-trained models, such as AlexNet, DarkNet-19, ResNet-50v2, DenseNet-201, EfficientNet-B7, VGG-16, VGG-19, InceptionResNetV2, and others in ADaDR-22, ADaRDEV2I-22, and DaRD-22. Each of these models captures different types of features, with some, like VGG and ResNet, more adept at identifying fine-grained details, and others, like DenseNet and InceptionResNet, better suited to learning intricate spatial hierarchies. The combined system is able to surpass individual models by utilising the strengths of each architecture through the integration of these models into our ensemble. The deliberate decision to introduce complexity into the model by incorporating a diverse array of pre-trained models was to ensure that the model encompasses a broad variety of patterns and representations, resulting in more accurate and robust predictions, particularly in a challenging ___domain such as medical image classification. Despite the increased complexity of the model, the substantial improvements in accuracy and the ability to generalize well across various datasets justify the trade-off.
These ensemble models are built from the foundations of the Integrated CNN phase; therefore, the performance of the models is boosted using either Vision Transformers (ViTs) or XGBoost. Use of the mentioned combined CNNs facilitates the identification of spatial features in the medical images which is vital for proper diagnosis.
Vision transformers architecture
The Transformer architecture in NLP paved way for the ViT which is the recent state-of-the-art in image classification. Ordinary CNNs mainly based on the connections of each pixel, while ViTs dissect a picture into a number of patches of the same size as a thread of words in a phrase48. To produce patch embeddings, we feed each flattened image into a linear layer. To keep the spatial connections in the image, positional embedding is added to these regions. Then, the embeddings go through a number of Transformer blocks which contain feed-forward and multi-head self-attention mechanisms in their structure. This is due to the fact that the model architecture allows for long-term dependencies across the whole image thus can capture the big picture and relations. Figure 7 illustrates and presents the architecture of Vision Transformer.

An illustrated architecture of vision transformer.
To improve the performances of each architecture, the proposed CADx systems contain CNNs and ViTs. The CNNs then initiate the process by learning specific features of different regions of the colonoscopy images to create a good spatial feature map. In order to extend the ViTs’ understanding of context and its interconnection, all these attributes are used. Therefore, applying the CNNs and ViTs simultaneously will give a better understanding of the image because the first will be able to recognize the smaller details while the second one will be able to analyze the structure of the image. Thus, the aim of this model remains the enhancement of the reliability of colorectal cancer detection. It is a clinical diagnostic tool that works based on the analysis of images that are quite often rather intricate.
XGBoost’ s architecture
XGBoost, or Extreme Gradient Boosting, is a machine learning method which is efficient and most suitable for use in structured data49,50. The XGBoost has multiple decision trees’ ensemble that is more efficient than the standard decision trees which are often overfitted as each tree is built upon the previous one and seeks to correct its mistakes. Because XGBoost is based on the gradient of residuals, it can gradually assign more resources to the cases that are hard to classify. This makes the model a useful tool for classification problems in that it learns how to rank the features that most affect the classification performance. The aspect of XGBoost where it can accommodate for a different feature set and the tunable parameters in order to improve the result in the diagnostic of medical images such as that of colorectal cancer is very useful in enhancing diagnostic accuracy. The structure of XGBoost is depicted in the following Fig. 8.

An illustrative architecture of XGBoost.
Based on the gradient boosting method of XGBoost, the enhancement of the accuracy of the predictions is done on features of the integrated CNNs’ classification about colorectal cancer. The forecast calculated here is the last final forecast which is basically the culmination of many decision trees and it is but simple to add the totalling of the sum of all the trees and using a weighted total as shown in the Fig. 10 above. Going by the present study using the ensemble technique, the generated model is very accurate, hence, suitable for any medical image classification problem that will require high accuracy due to this, the technique would be well suited for any problem where sophisticated pattern in the data is present.
Ensemble models
Integrated CNN + ViTs
In the case of the Integrated CNN + Vision Transformer (ViT) ensemble model, our major focus is to leverage transformers and convolutional neural networks. The integrated CNN’s purpose for the colonoscopy images is to understand and determine minute spatial characteristics from the images. Every CNN in the group (for instance, ADaRDEV2I-22, ADaDR-22, DaRD-22) defines feature vectors of a high dimensionality for the input images.
These features are then provided to the Vision Transformer which then produces image patches which are then passed to a series of transformer blocks. Every transformer block consists of multi-head self-attention and feed-forward networks that help in further enhancing the features extracted. Since carcinoma identification depends heavily on the ability of the transformer to learn long-distance relationships and complex structures within the input image data, this is very effective. Finally, the outputs of the transformer blocks are taken to a fully connected layer and a softmax activation to get the final probabilities of each class. Thus, the proposed model has both the local information learning capability provided by the CNNs and the global information understanding provided by the transformers. It depicts a model of the ensemble of the Integrated CNN (ADaDR-22) + Vision Transformers (ViTs) as shown in Fig. 9. It thereby demonstrates how feature extraction51,52,53 of the ADaDR-22 model is incorporated with the self-attention mechanics of ViT for the recognition of colorectal carcinoma. The same structure has been designed for the other two Integrated CNNs (ADaRDEV2I-22 and DaRD-22), and all the three models’ works in the similar manner to applying the CNN extracted features with ViT’s enhanced feature representation. It is proposed that these models should function in a similar fashion in order to enhance the ensembles’ potential to recognize local and global characteristics in the given dataset.

An Illustrative architecture of Integrated CNN(ADaDR) + ViT Ensemble Model.
Expected benefits:
-
Improved Feature Extraction: Thus, the proposed ensemble model has the advantages of CNNs in the capture of spatial hierarchies in the medical images and ViTs that can learn long-range dependencies in the images.
-
Enhanced Accuracy: The integration enables both local and global features to be learnt by the model; thus; the number of false positives and/or negatives may be reduced as well as improving on the base rate.
-
Robustness to Variability: The ViTs’ self-attention also allows the model to make analyses that are more general on the datasets, increasing the model’s resistance to image quality and content variations.
Integrated CNN + XGBoost
In this paper, a hybrid model of CNN and XGBoost has been used where the CNN is used for feature extraction and the XGBoost for classification. In this setup, the integrated CNNs (for instance, ADaRDEV2I-22, ADaDR-22, DaRD-22) start with feature extraction on the colonoscopy images as was in the previous ensemble.
The features are then reordered to the correct format and feed into the XGBoost classifier. This algorithm is known as XGBoost and it is a distributed graduate boosting library that builds the model as a sequence of decision trees. All of designed and each of the decision trees learn from the mistakes of the previous trees and then the outputs of all the trees are averaged with weights to provide the final output. Thus, integrating CNNs with the XGBoost the model can use high level features from CNNs and the accurate prediction from XGBoost. The final step is to apply softmax to the obtained features, and get the class probabilities and then classify the final class. Thus, the introduced method benefits from the feature extraction of CNNs and the classification of XGBoost. Figure 10 also illustrates more information on how the architecture of the presented model with Integrated CNN (ADaDR-22) and XGBoost is formed. This configuration demonstrates on how the feature maps resulting from a CNN are fed to XGBoost for boosting of decision trees in order to produce state-of-the-art models. Such architectures have been used for the other two Integrated CNNs (ADaRDEV2I-22 and DaRD-22) for the same purpose of applying the strength of deep feature extraction of CNN with the prediction capability of XGBoost. These two ensemble models are then developed in such a manner that they complement each other to improve the probability of accurate classification as well as reducing on over-fitting.

An Illustrative architecture of Integrated CNN(ADaDR) + XGBoost Ensemble Model.
Expected benefits
-
High Predictive Power: It utilizes itself on the gradient boosting algorithm that works iteratively; the model becomes aware of mistakes it has made at every stage of learning, hence offering the best outcome.
-
Flexibility and Adaptability: The above is also applicable when the data distribution is not same unlike most of the machine learning algorithm which has the problem of over fitting, for this reason the CNN can be combined with this for feature extraction.
-
Efficiency in Training: XGBoost, which is known to be among the fastest while in terms of training time, are some of those species that do not harm the model’s performance.
Flow diagram of ensemble CADx
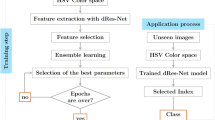
Figure 11 shown below illustrated the flow diagram for Ensemble CADx on how it identifies colorectal carcinoma: The chosen CKHK-22 dataset is the colonoscopy images that are followed by certain operations that are denoising, normalization, color correction, and resizing the images to moderate dimensions. This is done by DCGAN as a way of increasing the size of the training dataset in addition to also increasing the quality of the training dataset. Therefore, the dataset is split into training and testing set and several Integrated CNN models are designed to extract features from the images.

The detailed flow diagram for ensemble CADx.
These features are then fed into two different ensemble methods: To this end, Vision Transformers (ViTs) and XGBoost have been employed for the present task. Both models are trained and tested separately; the performance evaluation measures are calculated for each of them. The performances of the two models are compared and the model that has the highest accuracy and the capability of providing the best predictions is used in classification of the final class of colorectal images. The process stops at the identification of the best model for diagnosis with the highest accuracy. Thus, this structured workflow will significantly improve the detection of carcinoma and integrate the advantage of deep learning and ensemble learning.
According to the description of the flow diagram, the specific working process and the corresponding program are described comprehensively in the subsequent Table 7. From the iteration of the entire process of data collection and pre-processing to the model training and testing and the final prediction, this table presents a clean and straightforward way of segregating each step. It becomes a reference manual on the techniques adopted in the ensemble models for the detection of colorectal carcinoma.
Experimental setup
Hardware and software environment
In this work, the experiments were performed on a powerful computing cluster in order to provide a fast and efficient learning and evaluation of the models. The hardware environment comprised of an NVIDIA A100 Tensor Core GPU which is used in training deep learning models. To perform data pre-processing and training of the models, an Intel Xeon CPU along with 64 GB of RAM was employed.
Thus, for the software environment, the experiments were conducted with Python 3 8 as the chosen language.with fundamental libraries including TensorFlow 2. Numpy, TensorFlow, Keras and Scikit-learn libraries for developing and testing the machine learning algorithms. Specifically, Google Colab Pro + was used in this project to utilize the cloud computing environment and the available GPU resources and big datasets on Google Cloud.
Hyperparameter tuning
Cross validation is an essential part of the information extraction process, particularly when fine-tuning the ensemble models’ hyperparameters. The tuning process included modifying the hyperparameters which include learning rate, batch size, and the number of epochs for tuning the Integrated CNNs, Vision Transformers and XGBoost models. In case of Integrated CNNs, the learning rate was adjusted to between 0. 001 and 0. 0001 for layer 1, and batch size was set at 16, 32 and 64. The Vision Transformer was fine-tuned based on the number of transformer layers and the number of attention head thus producing the best feature extraction. Objective parameters of XGBoost like learning rate, maximum depth and number of estimators were tuned to get the best out of the algorithm. The detailed Hyperparameters utilized for three types of models such as Integrated CNNs,Vision Transformers and XGBoost is presented in Table 8.
We trained the models with a batch size of 16 and an initial learning rate of 0.001, and we optimised them using the Adam optimiser. To prevent overfitting, training was conducted for 100 epochs with early halting that was implemented. The validation accuracy reached a plateau after more than five epochs, resulting in a 0.1-fold decrease in the learning rate. Dropout with a rate of 0.3 was implemented to prevent overfitting, and data augmentation techniques, including rotation, magnification, and flipping, were implemented to enhance the model’s robustness. Google Colab Pro + with GPU support was employed to conduct the training, which facilitated the efficient training of the model.
We meticulously adjusted the batch size and image size to guarantee the consistency and efficacy of the combined Vision Transformer and CNN model with XGBoost. We selected a reduced sample size of 16 to enhance generalisation, and a larger image size of 224 × 224 pixels to enable the extraction of more detailed features, particularly critical for medical imaging tasks. These optimisations enhanced the model’s accuracy and its ability to capture fine details in the images, while also stabilising the training process.
Training and testing procedure
The dataset was divided into training and testing set with 80% and 20% of data respectively for training and testing. The training set was employed in developing the ensemble models while the test set was employed in the determination of the accuracy of the models. Each of the models was trained on a cross-validation to avoid overfitting and to obtain good accuracy on different fragments of the data. To prevent over-fit, the training process was stopped early using early stopping and the performance of the models were measured at every epoch.
Evaluation criteria
We used five key criteria to evaluate the models’ performance: The performance of the model was evaluated using some of the common performance measures including; accuracy, area under curve (AUC), precision, recall and F1 score. While accuracy measures the global performance of a model, AUC gives a sense of the model’s capacity to rank instances. The F1 Score presented the combination of Precision and Recall and was useful when comparing the model’s effectiveness in predicting the positive class and especially so, in situations of class imbalance. Collectively, these measures provided a comprehensive assessment of the ensemble models’ performance in detecting colorectal cancer.
Results
Results: A review
This section depicts the overall outcomes of the experiments for the detection of colorectal carcinoma using the proposed ensemble CADx systems. The findings also show the effectiveness of individual model architectures like integrated CNNs, Vision Transformers, and XGBoost and their combinations. The studies of the CKHK-22 dataset describe how to compare different ensemble models and how to evaluate the effectiveness of different approaches to increasing the size of data samples, training models, and checking the results of their work.
Hence, we compare the diagnostic performance of the models with the help of measures like precision, recall, AUC and F1-score. Starting with the evaluation of individual models the results are discussed in a systematic manner. The next section is dedicated to the consideration of ensemble models and the comparison of their effectiveness in the original and altered CKHK-22 sets. The objective of this work is to find out which model configuration yields the best diagnostic results in the case of colorectal carcinoma.
We used important measures including accuracy, precision, recall, and F1-score to assess the suggested ensemble model’s performance. We chose these metrics to evaluate the model’s efficacy in detecting and classifying colorectal cancer. The focus was on the model’s capacity to accurately classify cancerous and non-cancerous images, as well as its resilience in the face of imbalanced data. The AUC was of particular significance because it offered a snapshot of the model’s capacity to differentiate between classes across a variety of thresholds. On the other hand, precision and recall assessed the model’s sensitivity and specificity in identifying true positives and reducing false negatives, which are critical for medical applications.
Performance of integrated CNN models
In this regard, the results of the integrated CNNs for the three models (ADaDR-22, ADaRDEV2I-22, DaRD-22) have been elaborated in detail. The results are discussed for the original dataset with 24 classes and the reduced dataset with 14 classes. The evaluation metrics cover such basic parameters as training and test accuracies, as well as more specific indicators that characterize the model’s performance, namely, the F1 score, recall, precision, and classification metrics, including AUC. These metrics are identified in Tables 9 and 10 as follows. Furthermore, the results are presented in the Fig. 12 so as to show the performance of the model during the training and testing phases on various datasets and with various hyper parameters.

illustrates the evaluation metrics of integrated CNNs for the Original (24 classes) and Modified (14 classes) datasets.
The evaluation metrics of the three integrated CNN models; ADaDR-22, ADaRDEV2I-22 and DaRD-22 for both the original and the modified CKHK-22 datasets are shown in Tables 9 and 10 respectively. The results of the proposed method for the original and modified databases with 24 and 14 classes are presented in Tables 9 and 10. The highest training accuracy is obtained by the ADaDR-22 model on the modified dataset with great accuracy of 95. 3%, whereas the highest testing accuracy is also recorded by the same model with the modified dataset at 91. 5%. For the original dataset, the ADaDR-22 model is in the first place with a training accuracy of 92.5% and a testing accuracy of 87.3%. In both datasets, the models achieve high AUC values with the ADaDR-22 model again the best scoring with an AUC of 97.8 On the modified dataset, it was 95.5% on the original dataset, which proves the proposed method’s effectiveness in classifying the data.
In order to present a comparison of these performance metrics and to also show the improvement of the models when working with the modified dataset, the grouped bar chart depicted in Fig. 14 is used. In particular, the ADaDR-22 model is seen to outperform all the other models in all the measures of precision, recall, F1-score, and AUC which is an indication that the features selected are useful in identifying the relevant cases and discarding the irrelevant ones. The enhancement in the metrics on the modified dataset shows that the data pre-processing step that sought to reduce the number of classes and cleaning of the data was helpful in the performance enhancement. This enhancement allowed for the models to have higher testing accuracy and AUC in which these are crucial for the precise identification of colorectal carcinoma.
Performance of integrated CNN+ vision transformers (ViTs)
Accordingly, the outcomes of the adopted integrated CNNs + Vision Transformers or ViTs for all the three models namely ADaDR-22, ADaRDEV2I-22 and DaRD-22 models are discussed in this context thoroughly. The results are discussed for the model trained on the original data with 24 classes and model trained on the modified data with only 14 classes. The evaluation criteria do include such simple parameters as the training and test accuracies, as well as the more complex and specifically signifies the model’s performance in terms of the F1 measure, recall, precision, and classification, including AUCs. These metrics are enumerated in Tables 11 and 12. Furthermore, results are represented through the Figs. 13 and 14 to gain better insight about the performance of the model when it is trained as well as tested on the similar as well as different datasets with different hyper parameters.

Performance metrics on original dataset (24 classes) for integrated CNNs + ViTs.

Performance metrics on modified dataset (14 Classes) for integrated CNNs + ViTs.
All the Integrated CNN + Vision Transformer models are tested with the original dataset that consists of 24 classes and the modified dataset with 14 classes and some metrics like Training Accuracy, Testing Accuracy, Precision, Recall, F1-Score and AUC are used to report the performances and are presented in Tables 11 and 12. It is also revealed that the addition of Vision Transformers to the CNN models enhances the diagnostic outcomes in both datasets. It should be noted, however, that the Testing Accuracy and AUC results for the ADaDR-22 + Vision Transformer ensemble model were the highest for both datasets with a Testing Accuracy of 89.1% is achieved and a 97% AUC on the original dataset. , The accuracy of the testing is at 93.4% with a 98.8% AUC on the modified dataset that we prepared. These improvements suggest that the Vision Transformer is successfully learning spatial relationships within the colonoscopy images thereby enhancing feature extraction of the CNN models.
The radar charts in Fig. 15 show the performance metrics and it can be seen that all the metrics have been improving when the modified dataset has been used. The improvement in performance especially in the Precision, Recall, and F1-Score metrics is evidence of the usefulness of dataset refinement and augmentation that seems to have enhanced the models’ performance. The improvement in the AUC scores for the modified dataset strengthens the idea that the decrease in class imbalance and the removal of noise positively impacted the model’s ability to classify instances across all classes. In conclusion, the proposed model, Integrated CNNs with Vision Transformers, demonstrates a very high potential for the improvement in the discriminative power of colorectal carcinoma diagnosis, provided that the training set is of high quality and properly pre-processed.

Performance metrics on original dataset (24 classes) for integrated CNNs + XGBoost.
Performance of integrated CNN+ XGboost
Therefore, the performance of the integrated CNNs + XGBoost for all three ADaDR-22, ADaRDEV2I-22, and DaRD-22 models has been discussed in detail in this paper. The comparisons of the results are made for the model trained on the 24 classes data and the model trained on the 14 classes data. The evaluation criteria also involve such basic measures as the training and test accuracies, as well as more composite and particularly characterize the model’s effectiveness in terms of the F1 measure, recall, precision, and classification, including AUCs. These metrics are listed in Tables 13 and 14. Also, results are depicted in Figs. 15 and 16 to demonstrate the performance of the model when it is trained on one data and tested on similar as well as different data with different hyperparameters for optimization.

Performance metrics on modified dataset (14 classes) for Integrated CNNs + XGBoost.
The single model performance metrics of the CNN + XGBoost ensemble models on the original 24 class and the modified 14 class datasets are presented in Tables 13 and 14. Three different versions of the model were tested utilising important performance measures such as training accuracy, testing accuracy, precision, recall, F1-Score, and area under the curve (AUC): The proposed models in this paper are ADaDR-22 + XGBoost, ADaRDEV2I-22 + XGBoost and DaRD-22 + XGBoost. The effectiveness of all the models was observed to have increased on the new dataset based on the increase in their Testing Accuracy, Precision, Recall, and AUC. Comparing the modified dataset with the original dataset, it is observed that the proposed ADaDR-22 + XGBoost model had an AUC of 97.8% and a Testing Accuracy of 92.2%. This shows that the methods of model enhancement such as class reduction and dataset refinement are most useful for generalisability and recognising the images of colorectal cancer.
The performance metrics of the two models are compared with line charts in the results and they are depicted in the Figs. 17 and 18 for the CNN + XGBoost models for the two datasets. From the line charts it is evident that there is an improvement in the performance indicators when the modified dataset is used. In all the models the Training Accuracy, Testing Accuracy, Precision, Recall, F1-Score and AUC are higher for the modified dataset. The ADaDR-22 + XGBoost model specifically is the best among the others in both the original and modified datasets, although the margins are wider in the modified dataset. These charts clearly show the general trend of the model along with its stability and how the use of refined datasets can improve the accuracy of the classification. This visualization thus confirms the results from the tables and underlines the necessity of clean data in deep learning for medical diagnosis.

Final comparison of ensemble models performance.

The best models training and testing comparison.
Exploring ensemble model comparisons
In this study, we assessed a large number of ensembles with the aim of comparing the most effective combinations for colorectal cancer identification based on the CKHK-22 database. The models used are; ADaDR-22 alone, ADaDR-22 + Vision Transformers, and ADaDR-22 + XGBoost. The described models were tested on the original dataset and the dataset with 14 classes, and their performance was compared based on Testing Accuracy and AUC. The results displayed in the Tables 15,16,17,18 reveal the overall performance of each model combination with a focus on the effects of architectural design and improved dataset on the diagnostic outcomes.
This Table 15 shows the comparison of the baseline model ADaDR-22 with the proposed combinations of Vision Transformers and XGBoost on the original data. The model that combines Vision Transformers delivers the highest Testing Accuracy of 89.1% and AUC of 97%, which shows that the incorporation of the more complex architectures, such as Vision Transformers, can also enhance the model’s performance on the more complicated dataset of 24 classes.
We then trained all the models with the reduced dataset to 14 classes and all models’ performances increase. The proposed ADaDR-22 + Vision Transformer model achieves the highest Testing Accuracy of 93.4% for the ADaDR-22 dataset and the highest AUC value of 98.8%, which is better than the other two models namely the baseline and the combination with XGBoost which is presented in Table 16. This improvement shows that data set refinement is crucial in improving the models and their efficiency in future predictions.
Tables 17 and 18 present the evaluation of the selected models on the original and modified datasets, wherein the modified datasets used was both the training and the testing set. Therefore, an assumption can be made based on the results of this study that the increased capacity of the updated dataset enhances the efficiency of all the model combinations, thus supporting the research hypothesis. This confirms that the stated method can efficiently address the classification problem because the ADaDR-22 + Vision Transformer model is most effective under the updated conditions.
On the original dataset, the ADaDR-22 + Vision Transformer model had an AUC of 97% and a testing accuracy of 89.1%. These metrics suggest that the model is capable of providing a high level of confidence in its ability to distinguish between normal and carcinoma images. In comparison to XGBoost, the AUC of this model is higher, which implies that Vision Transformers are more effective at capturing the spatial patterns present in the medical imagery.
This Fig. 17 will show a grouped bar chart to enable the comparison of the Testing Accuracy and AUC for all the models for both datasets. This way, a chart will show the compared performance in a glance, thus, it will be easier to assess the effect of refining the dataset or the architecture of the model on the diagnostic result.
When comparing the models, the ADaDR-22 + Vision Transformer model consistently outperformed the ADaDR-22 + XGBoost model across both datasets. For example, the AUC increased by 1%, and the testing accuracy on the modified dataset improved by 4.3%. This indicates that the Vision Transformer’s superior performance over XGBoost is a result of its capacity to capture spatial relationships.
Effect of training and testing timings of best models
When comparing ADaDR-22 with XGBoost and ADaDR-22 with Vision Transformer on the 14 classes of the refined dataset it can be seen that both the models perform exceptionally well and the time taken for the models to train and test are also within acceptable range, with the Vision Transformer model performing better than the XGBoost model in all the cases. The time taken for training is also relatively long for the ADaDR-22 + Vision Transformer, 140 min while 125 min for the ADaDR-22 + XGBoost. The same goes for the time taken for testing of ADaDR-22 + Vision Transformer which is 17 min as compared to ADaDR-22 + XGBoost which is 16 min.
This differences in the training and testing time could be due to the fact that the Vision Transformer architecture is more complex than the other models and due to this the ability of the model to learning from the features of the data set is enhanced thus it takes much time for the model to learn from the given data set. The training and testing time is slightly more than the baseline as can be seen from the fact that the AUC score which measures the model’s capacity to differentiate between the two classes is higher. However, the execution of the ADaDR-22 + Vision Transformer model is slower; however, the model offers a good balance between the time taken to execute and the level of accuracy that is realistically needed for the intended applications. Table 19 provides the temporal details of the two most effective models.
The ADaDR-22 + Vision Transformer model is recommended to be the best model due to the longer time of training and testing since they can capture more features and patterns of the data. The Vision Transformer component enables a better way of feature extraction given the variability observed in the medical image datasets. This is good for increasing the predictive power and the reliability of the model because in clinical applications, mistakes are costly. However, the marginal increase in computation time is worthwhile the improvement in model accuracy and therefore the ADaDR-22 + Vision Transformer is the go-to model for the refined dataset analysis. Figure 18 illustrates the optimisation of training and assessment periods for the most effective models.
The ADaDR-22 + Vision Transformer group does better than other deep learning models. The CKHK-22 dataset results show this, with an AUC of 98.8% and a testing accuracy of 93.4%. This emphasises the effectiveness of integrating global contextual information with local feature extraction, surpassing the performance of conventional CNN models. The integration of DCGAN-assisted augmentation further enhanced the model’s capacity to classify imbalanced data, confirming the novelty and robustness of our proposed method.
Results of the statistical significance test
A paired t-test is a technique used to carry out the hypothesis testing between two related groups with respect to mean values. It can be hugely helpful in providing a comparing base for same models run under different settings such as changed data set. That is, the test assists in determining whether shifts in certain performance measures such as Testing Accuracy and AUC are indicative of changes in the set or noise. Table 20 displays the results of the t-test.
-
Testing Accuracy: With a p-value of 0.031 and a T-statistic of 20.50, the paired t-test clearly shows that there is a statistically significant difference in testing accuracy between the original and updated datasets.. This indicates that the improvements in testing accuracy observed with the modified dataset are more likely the result of changes made to the dataset than random variation.
-
Paired t-test for AUC: A T-Statistic of 6.20 and a P-Value of 0.102 are obtained. This P-Value exceeds the 0.05 threshold, suggesting that the differential in AUC between the original and modified datasets is not statistically significant. This result indicates that the enhancement is not sufficiently substantial to be classified as statistically significant, although the AUC increased marginally with the modified dataset.
As a result, the alterations to the dataset enhanced the Testing Accuracy of the models, and although the AUC differences did not qualify as statistically different, the trend favoured the models with additional data. This could suggest the models are simply more per accurate on average but AUC (which measures the model’s ability to distinguish between classes) has not improved.
Effect of augmentation with DCGAN for CKHK-22 dataset
The quality and the number of the training images have been enhanced in the CKHK-22 dataset by applying DCGAN (Deep Convolutional Generative Adversarial Networks) on data augmentation. This approach is useful in medical image analysis for instance in diagnosing colorectal cancer.DCGAN in fact contributes in solving two of the major problems which might occur when working with the given dataset, such as over fitting and class imbalance as the model generates quite similar images to the original dataset and thus improves the performance of the model. From the above statistics the number of samples has been seen to enhance the generalization of the models and the overall accuracy of the predictions made in the Testing Accuracy, Precision, Recall, F1-Score, and AUC that have been depicted to have risen in the post augmentation phase than in the pre augmentation phase. It is, therefore, not a coincidence that the DCGAN has been so far shown to enhance the performance of deep learning models for medical diagnoses using statistical methods. This has implications for the use of the models in the clinical setting where issues of reliability and accuracy are of essence and the effectiveness of the models is therefore enhanced. The enhanced images after the augmentation for the original and modified CHHK-22 datasets are presented as the bar charts in Figs. 19 and 20.

The augmented original CKHK-22 dataset with DCGAN.

The augmented modified CKHK-22 dataset with DCGAN.
The augmentation based on DCGAN and the refinement of the dataset from 24 to 14 classifications significantly enhanced the model’s accuracy. On the modified dataset, the ADaDR-22 + Vision Transformer outperformed the original dataset by 4.3%, achieving an accuracy of 93.4%. This suggests that dataset refinement was able to reduce noise and enhance the model’s generalisability across various types of carcinoma.
The best model performance metrics
The proposed model ADaDR-22 + Vision Transformer model does better in the classification tasks for the CKHK-22 modified dataset as compared to the other models because of the improved architecture that incorporates the feature extraction ability of Convolutional Neural Networks and the attention mechanism of Vision Transformers. This way the model is not only able to extract local features to a great extent but also able to have a more generic view which is very much helpful at the time of medical image analysis. The Vision Transformer block is useful in the model to enhance the ability of the model to learn the most important information from the image and hence improve the model’s performance and its ability to handle different and more complex classes of the dataset. The detailed results of ADaDR-22 + Vision Transformer is presented in the Table 21 and Fig. 21.

Performance metrics and support for ADaDR-22 + Vision Transformer.
The ADaDR-22 + Vision Transformer model’s exceptional performance across a diverse array of classes is highlighted by the detailed metrics on the modified dataset, which are consistently high in Accuracy, F1 Score, Recall, and Precision which is presented results in Table 20. The model attains an Accuracy of over 93% in all classes, with particularly impressive performance in classes such as "Ulcerative-Colitis-Grade-0–1" and "Z-Line," where F1 Scores reach 94.3% and 94.2%, respectively. The high percentages suggest that the model is well-balanced and effectively manages both true positives and false positives, thereby reducing the risk of misclassification errors.. The model’s ability to accurately identify affirmative cases, which is essential for early detection in medical diagnostics, is further underscored by the Recall values, all of which exceed 93%.
The model’s robustness is further emphasised by its performance on more complex and variable classes, such as "Esophagitis-A" and "Dyed-Lifted-Polyps," where it maintains Precision and Recall values above 93%. This implies that the model is capable of reliably distinguishing minute variations in medical images. The model’s consistent support across these classes, with sample sizes ranging from 300 to 800, indicates that it is not only accurate but also reliable across distinct class sizes. This renders the ADaDR-22 + Vision Transformer model a highly viable option for real-world medical applications, where the achievement of high consistency and reliability is essential for the enhancement of patient outcomes and the formulation of clinical decisions.
Our study’s substantial enhancement in accuracy and AUC, particularly through the integration of Vision Transformers, addresses a critical challenge in medical image classification: the challenge of capturing spatial relationships in intricate anatomical structures. The potential of the ADaDR-22 + Vision Transformer ensemble as a dependable instrument for the early detection of colorectal carcinoma is illustrated by its superior performance. This could result in more precise and expeditious diagnoses in clinical practice.
Confusion matrices and ROC curves
Based on the confusion matrix of the ADaDR-22 + Vision Transformer model on the modified dataset, the statistics of the model’s performance in the classification of the 14 classes are given in Fig. 22. The large values on the diagonal mean that, for each class, most of the instances were classified correctly, which is evidence of the model’s ability to classify between classes. The off-diagonal elements are fairly small; thus, the model misclassified the samples only on relatively rare occasions, which is quite useful in a clinical context because the model should be accurate. Therefore, these results validate the model’s implementation efficiency in the classifying the right class labels with a slight difference in the model’s efficacy for the various classes. The above confusion matrix shows that false positive and false negative have been reduced that is quite beneficial for the accurate classification of medical images.

Confusion matrix for ADaDR-22 + Vision Transformer (14 classes).
The ROC curves of the 14 classes as given in Fig. 23 also support the argument that the model is discriminative. All of the curves show the False Positive Rate on the y-axis and the True Positive Rate on the x-axis for one class and the area under each of the curves is the performance of the model. The ROC curves show that the model can be considered as having a reasonably good performance for all classes, with the AUC values of 0. 61 to 0. 85. This means that the ADaDR-22 + Vision Transformer model is well capable of classifying the different classes irrespective of the nature of the scenario. Since the AUC values of most classes are relatively higher, this model is quite useful in distinguishing the actual positive cases from the false positive and therefore can be applied in the diagnosis of the diseases. ROC analysis is another extension to the confusion matrix that gives a more detailed view of model performance, and in particular its sensitivity and specificity for various thresholds.

ROC curve for ADaDR-22 + Vision Transformer (14 Classes).
Ablation study
Ablation study is a process of measuring the effectiveness of each component and strategy in a given learning model of machine. When some of the elements of the model are deleted or changed in some way, it is possible to determine which of these elements has the greatest impact on the work of the model. In this work, an ablation study is performed on the ADaDR-22 + Vision Transformer model to identify the significance of every part and the training procedure for high accuracy and stability. The details of Abliation study for ADaDR-22 + Vision Transformer Model is presented in detailed way in Table 22.
The ablation study of the ADaDR-22 + Vision Transformer model also shows that each of the component and training strategy is crucial for the final result. The Vision Transformer enhances the ability of the models in identifying medical images and the ADaDR-22 architecture for feature extraction. Data augmentation and regularization are very helpful in making sure that that the model does not over fit and perform well when applied to new data. From the obtained results of the study, it is also important to highlight the necessity of developing a model with a high accuracy and reliability of the classification of medical images, and the ADaDR-22 + Vision Transformer model can be recommended for practical use in clinical settings. Table 23 illustrates the comprehensive ablation study, which includes a detailed discussion of the Vision Transformer, XGBoost, Integrated CNN (ADaDR-22), and Ensemble (ADaDR-22 + ViT).
Model robust testing
Additional data augmentation techniques, including SMOTE, were implemented on the training set to further evaluate the robustness of the proposed models. This led to a modest increase in recall for under-represented divisions. The models were also evaluated under a variety of image conditions, including luminance and contrast, in order to replicate the real-world variability found in medical images. The model’s robustness to noise was demonstrated by the ADaDR-22 + Vision Transformer’s ability to maintain stability, with only a 1.2% decrease in accuracy, demonstrated the model’s robustness to noise.
Discussion
Vision Transformers and XGBoost together with the conventional CNN have been employed in the recent past and have been found to greatly enhance the performance of deep learning models especially in the medical sector. This work assesses the most current state-of-the-art methods, namely ADaDR-22, ADaRDEV2I-22, and DaRD-22, with Vision Transformers and XGBoost to the earlier works of Akella S. Narasimha Raju. In order to make the improvements noticeable in terms of accuracy AUC and computational efficiency the enhanced methods will be applied in this analysis.
In the recent work of Akella S. Narasimha Raju the authors have proposed models that combines Vision transformers and XGBoost, these have shown better results that the conventional CNN models. The results indicate that the proposed ADaDR-22 + Vision Transformer model is better than the prior setups with a significant margin. On this, the incorporation of Vision Transformers has enhanced feature extraction that has led to higher testing accuracy as well as AUC scores especially when using the enhanced dataset.
The testing accuracy was also quite low on the original dataset as compared to that of the refined dataset this shows that by reducing the class in the refined dataset the model had been able to learn well and perform well. The training and testing time has also been enhanced since the models which incorporate Vision Transformers and XGBoost are quite efficient in computation even as they are complex models.
In the comparison Table 24 and Fig. 24, the efficacy of a variety of state-of-the-art methods for the detection of colorectal cancer is demonstrated, including the recently introduced models by Akella S Narasimha Raju. The ADaDR-22 + Vision Transformer model that was the subject of the current study obtained an impressive accuracy of 93.40% on the CKHK-22 Modified Dataset. This accuracy is still remarkable, even though it is lower than some other models in the table, given the complexity of the dataset and the robustness necessary for real-world medical diagnostics.

Comparison of state-of-art methods with present study.
The current model, ADaDR-22 + Vision Transformer, has a training time of 140 min and a testing time of 17 min in terms of durations. This is analogous to other high-performing models, such as the Ensemble CADx CKHK-22 Mixed Dataset, which has a similar training duration but slightly higher accuracy. The extended training time is likely a result of the additional computations required for the attention mechanisms, which are the result of the use of Vision Transformers in the current model.
Overall, the ADaDR-22 + Vision Transformer model is emphasised for its capacity to maintain robust accuracy while managing intricate and diverse datasets, rendering it a valuable addition to the current corpus of research in the field of colorectal cancer detection. This model is adept at striking a balance between computational efficiency and accuracy, rendering it appropriate for use in clinical settings that prioritise precision and reliability.
Figure 24 shows how this research compares to others that have looked at colorectal cancer detection in the past.
The primary contribution of this work is the integration of CNNs with Vision Transformers and XGBoost, a method not used in previous studies for the detection of colorectal carcinoma, to the best of our knowledge. This innovative architecture effectively combines the self-attention mechanisms of Vision Transformers with the strengths of convolutional neural networks in feature extraction, leading to enhanced local and global feature recognition. XGBoost further refines the classification process, making our approach more computationally efficient and accurate compared to currently available deep learning methods. We illustrate the efficacy of this ensemble method with its enhancements in accuracy (93.4%) and AUC (98.8%) compared to conventional models.
Numerous studies have approached the application of deep learning models to the detection of colorectal carcinoma, with varying degrees of success. Using a CNN-based CADx system for CRC detection, Attallah et al. obtained an accuracy of 89.6%, whereas Nogueira-Rodriguez et al. reported an accuracy of 90.4% with CNN architectures for polyp detection. The much higher accuracy of 93.4% on the modified dataset showed that our ADaDR-22 + Vision Transformer ensemble was better at extracting and interpreting spatial features from colonoscopy images.
While our proposed method focuses on colorectal cancer detection, recent studies in skin cancer detection, such as SNC_Net25 and DVFNet26, have successfully demonstrated the potential of combining handcrafted and deep learning-based features [Author, Year]. Our approach, integrating CNNs with Vision Transformers and XGBoost, builds on these ideas by utilizing advanced feature extraction and ensemble methods, achieving higher accuracy in colorectal carcinoma detection. Additionally, similar to the Multi-model Fusion Technique60,61,62 applied to skin cancer, our method leverages multiple models to improve classification performance [Ahmad Naeem etal, 2023, Radhika V etal]. Table 25 provides a comprehensive examination of the Model’s limitations and mitigation strategies employed in this paper.
The future directions for research
Future studies should, therefore, be chemically directed to accomplish the generalizability of the proposed ensemble model across diverse datasets of patients, which represents an important administrative step toward clinical adoption. This involves the validation of the performance of the model on external multi-centered datasets that represent various demographic, geographical, and imaging conditions with the view to ensuring robustness. Besides, applying multi-modal data, such as patient history, biomarkers, or genetic profiles, integrated with colonoscopy images, could further enhance diagnostic accuracy and clinical relevance. Optimization of the model for better computational efficiency is another promising avenue to explore real-time deployment on resource-constrained environments such as mobile and edge devices. Ultimately, research on advanced augmentation techniques such as StyleGAN and semi-supervised learning imports could improve model performance with very limited labeled data while improvements in the interpretability for clinically actionable, advanced visualization tools will be done on the Vision Transformers. These will help altogether in bringing more accurate, scalable, and interpretable diagnostic solutions.
Clinical relevance
It is essential to have the capacity to accurately detect colorectal carcinoma in clinical settings, as early detection has a substantial impact on the prognosis of patients. In comparison to earlier models, the ADaDR-22 + Vision Transformer ensemble is a more reliable diagnostic tool, with an AUC of 98.8%. This could lead to fewer false negatives and more timely interventions.
The results of this study not only illustrate the effectiveness of integrating Vision Transformers with CNNs for the detection of colorectal carcinoma, but they also offer potential avenues for future research. Despite the challenging dataset, the model’s high accuracy suggests that Vision Transformers could improve diagnostic tools for various medical image analysis tasks.
The proposed method, which integrates CNNs, Vision Transformers, and XGBoost, demonstrates significant strengths in the detection of colorectal carcinoma. The model gets high accuracy and AUC on the changed dataset by using CNNs to extract features, Vision Transformers to capture long-range dependencies, and XGBoost to efficiently classify. This hybrid methodology capitalises on the advantages of each model, rendering it exceedingly adept at medical imaging assignments. However, the method is subject to certain constraints, including the high computational cost resulting from the intricate architecture, which requires adequate training resources. To make sure that the model works in real-life clinical settings, it needs to be tested on bigger and more varied datasets. This is because the model’s usefulness may depend on the quality and size of the dataset.
Conclusion
In this work, we also offered a literature review of the most up-to-date approaches used in the detection of colorectal cancer especially the integration of CNN with other models including Vision Transformers and XGBoost. The main idea of this study was to assess the effectiveness of these models in terms of accuracy, AUC and time consumption when applied to a rather complex dataset containing 14 classes that were extracted from the CKHK-22 dataset.
This shows that the ADaDR-22 + Vision Transformer model has a better result than the other configurations such as the ADaDR-22 + XGBoost model since the testing accuracy is 93.4% and an AUC of 98. 8%. This improvement is due to the Vision Transformer’s capability of global context information that improves the classification of medical images. Although it takes more time to train and test, with a training time of 140 min and a testing time of 17 min, the ADaDR-22 + Vision Transformer model offers improved predictive potential which is important for clinical practice.
The work also demonstrates the usefulness of data augmentation approaches that are incorporated in DCGAN, in enhancing the stability of the models. The expanded dataset made the models perform better, avoided learning of the training data only, and performed poorly on new data. Also, combining two different model architectures was demonstrated to be beneficial to achieve better performance of the results in terms of accuracy and ease of understanding, for example, combining CNNs with Vision Transformers, or combining CNNs with XGBoost.
Despite getting slightly higher accuracy rates by some models such as GastroCADx Kvasir2, the trade-off between computational time and model accuracy of the ADaDR-22 + Vision Transformer model makes it suitable for further enhancement. This paper demonstrates model potential for keeping high level of accuracy as well as its ability to work with the complex and diverse data sets and, therefore, offers the model as a reliable instrument for the early diagnosis of colorectal cancer, which is crucial for the better patients’ prognosis.
This work thus adds to the literature on medical image analysis and specifically to the use of deep learning models for disease diagnosis. This work shows that state of the art architectures such as Vision Transformers have the capability to outperform traditional CNN models.
To conclude, this investigation introduces a novel deep learning ensemble for the detection of colorectal carcinoma that incorporates XGBoost, Vision Transformers, and CNNs. This groundbreaking methodology effectively resolves critical obstacles in medical imaging, including the complexity of feature extraction and class imbalance, and establishes a new standard for colorectal cancer diagnosis. We will further refine the model and investigate its applicability to other medical imaging domains in the future.
Future work
Future work will further the study by using more advanced models such as Vision Transformers in combination with the other existing light weight deep learning architectures such as EfficientNet or MobileNet to find out the best balance between the model’s performance and its complexity. It also possible to enhance the general performance of the model on different medical datasets with the help of modern generative models like StyleGAN to perform the realistic data augmentation. This leads to high training and testing time which is a big disadvantage, to mitigate this the use of Knowledge Distillation techniques can be used where a smaller and faster model is trained to mimic the larger and more complex one. Storing of data in the clouds and the use of Bayesian methods to fine tune the hyperparameters will also assist in cutting down time taken in computations. These approaches will attempt to establish a model that will be accurate but also fast and thus functional in real world applications within a clinical environment.
Data Availability
All the data collected and analyzed in the current study are available from the corresponding author on request.
References
-"Global Cancer Observatory," World Health Organization, 31 July 2024. [Online]. Available: https://gco.iarc.fr/en.
-"Cancer statistics of Japan," Japan National Cancer Center:, 31 May 2021. [Online]. Available: https://ganjoho.jp/public/qa_links/report/statistics/2021_en.html. [Accessed 26 July 2024].
-"Bowel Cancer Stistics," Cancer Research UK, 25 March 2024. [Online]. Available: https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/bowel-cancer. [Accessed 26 July 2024].
-"National Cancer registry," ICMR-NCDIR, 15 February 2020. [Online]. Available: https://ncdirindia.org/All_Reports/Report_2020/default.aspx. [Accessed 1 August 2024].
-"Americal cancer Society," ACS, [Online]. Available: https://www.cancer.org/cancer/colon-rectal-cancer/. [Accessed 15 November 2022].
-"Global Health Estimates," World Health Organization, 15 May 2020. [Online]. Available: https://www.who.int/data/global-health-estimates. [Accessed 26 May 2024].
-Sathishkumar K, Chaturvedi M, Das P, Stephen S, Mathur P, "Cancer incidence estimates for 2022 & projection for 2025: Result from National Cancer Registry Programme, India.," Indian Journal of MEdical Research, pp. 598–607, 11 October 2022.
-Pittma, Erika Hissong & Meredith E., "Colorectal carcinoma screening: Established methods and emerging technology," n ISSN: 1040–8363 (Print) 1549–781X,, 2019.
-Omneya Attallah , Maha Sharkas, "GASTRO-CADx: a three stages framework for diagnosing gastrointestinal diseases," PeerJ Computer Science, vol. PMID: 33817058, p. 7:e423, 10 March 2021.
-Tauhidul Islam , Md. Sadman Hafiz , Jamin Rahman Jim , Md. Mohsin Kabir ,,M.F. Mridha , "A systematic review of deep learning data augmentation in medical imaging:," Health care Analytics, vol. 5, 8 May 2024.
-Alba Nogueira-Rodríguez, Rubén Domínguez-Carbajales, Hugo López-Fernández, Águeda Iglesias, Joaquín Cubiella, Florentino Fdez-Riverola, Miguel Reboiro-Jato, Daniel Glez-Peña,, "Deep Neural Networks approaches for detecting and classifying colorectal polyps," Neurocomputing, vol. 423, pp. 721–734, 29 January 2021.
-T. R. Mahesh , V. Vinoth Kumar , V. Muthukumaran ,H. K. Shashikala ,, "Performance Analysis of XGBoost Ensemble Methods for," Journal of Sensors, vol. 2022, p. 8 pages, 13 September 2022.
Lin, A., Chen, B., Jiayu, Xu., Zhang, Z. & Guangming, Lu. DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation. IEEE Trans. Instrum. Meas. 71, 30 (2022).
-Li, Yaqi MD, PhDa,e; Xu, Jing PhDh; Hu, Xiang MD, PhDa,e; Chen, Yikuan MD, MSca,e; Liu, Fangqi MDa,e; Chen, Yun MSch; Ma, Xiaoji MDa,e; Dong, Qiduo MSch; Sun, Lei PhDf; Mo, Shaobo MD, PhDa,e; Zhang, Long PhDa,e,d; He, Xingfeng MSca,e; Tong, Shanyou MSca,e, "Personalized circulating tumor DNA monitoring improves recurrence surveillance and management after curative resection of colorectal liver metastases: a prospective cohort study," International Journal of Sugery, vol. 110, no. 5, pp. 2776–2787,, May 2024.
-IshakPacal, DervisKaraboga, AlperBasturk, BahriyeAkay, UfukNalbantoglu, "A comprehensive review of deep learning in colon cancer," Computers in Biology and Medicne, vol. Volume 126, Novembe 2020.
-Ngoc-Quang Nguyen,Duc My V, Sang-Woong Lee, "Contour-Aware Polyp Segmentation in colonoscopy images using detailed unsampling Encoder- Decoder Networks," IEEE Acess, vol. Volume: 8, pp. 99495 - 99508, 19 May 2020.
-Meng J, Xue L, Chang Y, Zhang J, Chang S, Liu K, Liu S, Wang B, Yang K., "Automatic detection and segmentation of adenomatous colorectal polyps during colonoscopy using Mask R-CNN. Open Life Sci.," Open Life Sciences, vol. 15, no. 1, pp. 588–596, 14 August 2020.
-ALAN CARLOS DE MOURA LIMA , LISLE FARAY DE PAIVA2, GERALDO BRÁZ JR. ,, "Data Augmentation Based on Generative Adversarial Networks for Endoscopic Image Classification," IEEE Access, vol. 11, 11 MAy 2023.
-A. Hasib Uddin,Yen-Lin Chen,,Miss Rokeya Akter, Chin Soon Ku,, "Colon and Lung Cancer Classification from Multi-Modal Images Using Resilient and Efficient Neural Network Architectures," heliyon, vol. 2024, no. 10, 3 May 2024.
-ALAN CARLOS DE MOURA LIMA , LISLE FARAY DE PAIVA2, GERALDO BRÁZ JR., "A Two-Stage Method for Polyp Detection in Colonoscopy Images Based on Saliency Object Extraction and Transformers," IEEE Access, vol. 11, 27 July 2023.
-S. M. Naguib, H. M. Hamza, K. M. Hosny, M. K. Saleh, M. A. Kassem, "Classification of cervical spine fracture and dislocation using refined pre-trained deep model and saliency map," Diagnositics, vol. 13, no. 7, p. 28 .
Kassem, M. A. et al. Explainable Transfer Learning-Based Deep Learning Model for Pelvis Fracture Detection. Int. J. Intell. Syst. 2023, 24 (2023).
Naguib, S. M. et al. Automated system for classifying uni-bicompartmental knee osteoarthritis by using redefined residual learning with convolutional neural network. Heliyon 10(10), 17 (2024).
Kassem, M. A., Abohany, A. A., El-Mageed, A. A. & Hosny, K. M. A novel deep learning model for detection of inconsistency in e-commerce websites. Neural Comput. Appl. 36, 16 (2024).
Naeem, A. et al. SNC_Net: Skin Cancer Detection by Integrating Handcrafted and Deep Learning-Based Features Using Dermoscopy Images. Mathematics 12(7), 27 (2024).
Naeem, A. & Anees, T. DVFNet: A deep feature fusion-based model for the multiclassification of skin cancer utilizing dermoscopy images. PLOS ONE 19(3), 20 (2024).
-Naeem, A.; Anees, T.; Fiza, M.; Naqvi, R.A.; Lee, S.-W., "SCDNet: A Deep Learning-Based Framework for the Multiclassification of Skin Cancer Using Dermoscopy Images," sensors, vol. 22, no. 15, p. 5652, 25 July 2022.
-Roger Fonollà, Quirine E. W. Vander Zander , Ramon M. Schreude, Ad A. M. Masclee , Erik J. Schoon, Fons van der Sommen and Peter H. N. de With, "A CNN CADx System for Multimodal Classification of Colorectal Polyps Combining WL, BLI, and LCI Modalities,," Applied science, Vols. volume 10, Issue 15, no. Issue 15, pp. 10(15), 5040;, 2020.
-Meryem Souaidi ,Mohamed El Ansari, "A New Automated Polyp Detection Network MP-FSSD in WCE and Colonoscopy Images Based Fusion Single Shot Multibox Detector and Transfer Learning," IEEE Access, vol. 10, pp. 47124 - 47140, 29 April 2022.
-"https://www.kaggle.com/balraj98/cvcclinicdb," 2015. [Online]. [Accessed 25 May 2021].
-"https://datasets.simula.no/kvasir/," 2016. [Online]. [Accessed 3 July 2021].
-"https://datasets.simula.no/hyper-kvasir/," 2020. [Online]. [Accessed 3 July 2021].
-Akella S. Narasimha Raju, Kayalvizhi Jayavel, T. Rajalakshmi, "ColoRectalCADx: Expeditious Recognition of Colorectal Cancer with Integrated Convolutional Neural Networks and Visual Explanations Using Mixed Dataset Evidence," Computational and Mathematical Methods in Medicine, 10 November 2022.
-Chlap P, Min H, Vandenberg N, Dowling J, Holloway L, Haworth A, "A review of medical image data augmentation techniques for deep learning applications.," Journal of Medical Imaging and Radiation Oncolory, vol. 65, no. 5, pp. 545–563, 19 June 2021.
-Oza, P.; Sharma, P.; Patel, S.; Adedoyin, F.; Bruno, "A. Image Augmentation Techniques for Mammogram Analysis.," Journal of Imaging, vol. 8, no. 5, 20 May 2022.
-Ronghui Cao, Zhuo Tang, Chubo Liu, Bharadwaj Veeravalli, "A Scalable Multicloud Storage Architecture for Cloud-Supported Medical Internet of Things," IEE INTERNET OF THINGS JOURNAL, p. VOL. 7 NO.3, MARCH 2020.
-B.Prashanth, Mruthyunjaya Mendu, Ravikumar Thallapalli, "Cloud based Machine learning with advanced predictive Analytics using Google Colaboratory," Materials Today: Proceedings, 3 March 2021.
-Kiran Maharana, Surajit Mondal, Bhushankumar Nemade, "A review: Data pre-processing and data augmentation techniques," Global Transitions Proceedings, vol. 3, no. 1, pp. 91–99, 3 April 2022.
-Akella S. Narasimha Raju, Kayalvizhi Jayavel, Thulasi Rajalakshmi, "Dexterous Identification of Carcinoma through ColoRectalCADx with Dichotomous Fusion CNN and UNet Semantic Segmentation," Computational Intelligence and Neuroscience, vol. 2022, p. 29, 10 October 2022.
-RuiWang,JingwenXu.Tony X.Han, "Object instance detection with pruned Alexnet and extended training data," Signal Processing: Image Communication, pp. 145–156, 21 February 2019.
-Joseph Redmon, Ali Farhadi, "YOLO9000: Better, Faster, Stronger," Computer Vision and Pattern Recognition, 25 December 2016.
-Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi, "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning," in Computer Vision and Pattern Recognition (cs.CV, 23 Aug 2016.
-Mingxing Tan, Quoc V. Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks," in International Conference on Machine Learning ,ICML 2019, 11 Sep 2020.
-Gao Huang,Zhuang Liu,Laurens van der Maaten, "Densely Connected Convolutional Networks," Computer Vision and Pattern Recognition (cs.CV), 28 January 2018.
-Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, "Deep Residual Learning for Image Recognition," in Computer Vision and Pattern Recognition (cs.CV),, 10 Dec 2015.
-Karen Simonyan, Andrew Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition," in Computer Vision and Pattern Recognition (cs.CV), arXiv:1409.1556v6, 10 Apr 2015.
-Jian Xiao, Jia Wang,1 Shaozhong Cao, and Bilong Li, "Application of a Novel and Improved VGG-19 Network in the Detection of Workers Wearing Masks," in IOP Publishing Public Health Emergency Collection, April,2020 .
-C. -F. R. Chen, Q. Fan and R. Panda, CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification, Montreal, QC: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
Wang, Y. et al. A hybrid ensemble method for pulsar candidate classification. Astrophysics and Space Science 364(139), 29 (2019).
Yan, L. Xu, Y, “XGBoost-Enhanced Graph Neural Networks: A New Architecture for Heterogeneous Tabular Data,”. Applied Sciences 14(13), 3 (2024).
-Irem Tasci, Burak Tasci, Prabal D. Barua, Sengul Dogan, Turker Tuncer, Elizabeth Emma Palmer, Hamido Fujita, U. Rajendra Acharya, "Epilepsy detection in 121 patient populations using hypercube pattern from EEG signals," Information Fusion, vol. 96, pp. 252–268, 31 March 2023.
-Gulay Tasci, Hui Wen Loh, Prabal Datta Barua, Mehmet Baygin, Burak Tasci, Sengul Dogan, Turker Tuncer, Elizabeth Emma Palmer, Ru-San Tan, U. Rajendra Acharya, "Automated accurate detection of depression using twin Pascal’s triangles lattice pattern with EEG Signals," Knowledge-Based Systems, vol. 260, p. 110190, 7 December 2022.
-Dogan, S., Baygin, M., Tasci, B. et al, "Primate brain pattern-based automated Alzheimer’s disease detection model using EEG signals," Cognitive Neurodynamics, vol. 17, p. 647–659, 12 August 2022.
-Liew,W. S., Tang, T. B., Lin, C.-H., and Lu, C.-K, "Detection Using Integration of Modified Deep Residual Convolutional Neural," Comput. Methods Programs, vol. 206, July 2021.
-Pallabi Sharma, Bunil Kumar Balabantaray, Kangkana Bora, Saurav Mallik , Kunio Kasugai and Zhongming Zhao, "An Ensemble-Based Deep Convolutional Neural Network for Computer-Aided Polyps Identification From Colonoscopy," Frontiers in Genetics, 26 April 2022.
-Nisha J.S., Varun P. Gopi , Palanisamy P., "Automated colorectal polyp detection based on image enhancement and dual-path CNN architecture," Biomedical Signal Processing and Control, vol. 73, March 2022.
-Akella S Narasimha Raju,Kayalvizhi Jayavel, T.Rajalakshmi, "An advanced diagnostic ColoRectalCADx utilises CNN and unsupervised visual explanations to discover malignancies," Nerual Computing and Applications, vol. 35, p. 20631–20662, 22 July 2023.
-Raju, A.S.N.; Venkatesh, K, "EnsemDeepCADx: Empowering Colorectal Cancer Diagnosis with Mixed-Dataset Features and Ensemble Fusion CNNs on Evidence-Based CKHK-22 Dataset," Bioengineering, vol. 10, no. 6, p. 738, 19 June 2023.
-Akella S. Narasimha Raju, K. Venkatesh, B. Padmaja & G. Sucharitha Reddy, "GIEnsemformerCADx: A hybrid ensemble learning approach for enhanced gastrointestinal cancer recognition," Multimedia Tools and Applications, vol. 83, p. 46283–46323, 22 February 2024.
-Tahir, M.; Naeem, A.; Malik, H.; Tanveer, J.; Naqvi, R.A.; Lee, S.-W, "DSCC_Net: Multi-Classification Deep Learning Models for Diagnosing of Skin Cancer Using Dermoscopic Images," Cancers, vol. 15, p. 2179, 6 April 2023.
Radhika, V. & Chandana, B. S. MSCDNet-based multi-class classification of skin cancer using dermoscopy images. PeerJ Computer Science 2023, 29 (2023).
-Ahmad Naeem,Ali Haider Khan,Salah u din Ayubi,Hassaan Malik, "Predicting the Metastasis Ability of Prostate Cancer using Machine Learning Classifiers," Journal of Computing & Biomedical Informatics, vol. 4, no. 2, 2023.
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through a Large Research Project under grant number RGP2/496/45. The authors would also like to convey their appreciation to the Institute of Aeronautical Engineering, Hyderabad and SRM Institute of Science and Technology, Chennai for enabling the authors to conduct the study. The authors are especially grateful to the Department of Computer Science and Engineering (Data Science) and the Department of Networking and Communications for the support and directions provided to this study.
Author information
Authors and Affiliations
Contributions
“Akella Subrahmanya Narasimha Raju. K.Venkatesh and B. Padmaja wrote the main manuscript text and N.Santhosh Kumar. Pattabhi Rama Mohan Patnala and Ayodele Lasisi prepared the Figures. Saiful Islam. Abdul Razak and Wahaj Ahmad Khan helped in data analysis. All authors reviewed the manuscript.”
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical Approval
The data used in the current study was public colonoscopy data, which was collected from medical image datasets which are freely available online. The data were anonymised and publicly available and therefore the current study did not involve any contact with human subjects. Hence, it was not necessary to seek for specific ethics clearance and participants’ consent to conduct this study. Such data has been collected from a public ___domain and the usage of such data is in compliance with the ethical guidelines for medical imaging and AI.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Raju, A.S.N., Venkatesh, K., Padmaja, B. et al. Exploring vision transformers and XGBoost as deep learning ensembles for transforming carcinoma recognition. Sci Rep 14, 30052 (2024). https://doi.org/10.1038/s41598-024-81456-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-81456-1
