
Abstract
Inflammation can influence the development of CRC as well as immunotherapy and plays a key role in CRC. Therefore, this study aimed to investigate the potential of inflammation-related genes in CRC risk prediction. Inflammation gene models were constructed and validated by combining transcriptomic and single-cell data from TCGA and GEO databases, and the expression of inflammation-related genes was verified by RT-qPCR. We identified two molecular subtypes and three genetic subtypes, two risk subgroups according to median risk values, constructed a prognostic model including thirteen genes (TIMP1, GDF15, UCN, KRT4, POU4F1, NXPH1, SIX2, NPC1L1, KLK12, IGFL1, FOXD1, ASPG, and CYP4F8), and validated the performance of each aspect of the model in an external database. Patients in the high-risk group had worse survival with reduced immune cell infiltration and a greater tumor mutational load. The risk score correlated strongly with the immune checkpoints PD1, PDL1, PDL2, and CTLA4, and it is possible that high-risk patients are more sensitive to treatment involving immune checkpoints. In the single-cell data, GDF15 was most significantly expressed in cancer cell populations. Therefore, we further validated their expression in cells and tissues using qPCR. In summary, we developed a prognostic marker associated with inflammatory genes to provide new directions for subsequent studies and to help clinicians assess the prognosis of CRC patients as well as to develop personalized treatment strategies.
Similar content being viewed by others

Introduction
Colorectal cancer (CRC) is the third most common cancer and the second leading cause of cancer death globally, with 3.2 million CRC cases expected to occur worldwide in 20401. In recent decades, the view of cancer biology has shifted from a “cancer cell-centric” perspective to one in which tumor cells are located in a tumor microenvironment composed of fibroblasts, vascular cells, and inflammatory immune cells. All cells in the TME influence all stages of the tumor through close interactions, and the plasticity of tumor cells and surrounding cells in the TME is largely driven by inflammation2. Inflammation not only remodels the complex cellular components of the tumor microenvironment, creating tumor-supportive ecological niches through mutual crosstalk but also exerts direct protumorigenic signals and functions on epithelial and cancer cells to promote cancer3. Approximately 15–20% of cancer patients develop infection, chronic inflammation, or autoimmunity at the same tissue or organ site2. In particular, colorectal cancer, poorly controlled, long-standing inflammatory bowel disease and chronic inflammation of the bowel due to poor diet are associated with an increased incidence of colorectal cancer4.
There are three forms of inflammation in colorectal cancer: chronic inflammation prior to tumorigenesis, tumor-induced inflammation, and treatment-induced inflammation5. Some dietary and physical activity habits, e.g., smoking, alcohol consumption, obesity, etc., are risk factors for colorectal cancer6. Colitis-associated colorectal cancer (CAC) is thought to arise from the expansion of protumorigenic clones that replace wild-type colorectal epithelium during chronic inflammation-induced field cancerization of the large intestine7. In tumors, interleukin-6 (IL-6) secreted by human colorectal cancer-derived mesenchymal stem cells (CC-MSCs) promotes colorectal cancer cell progression through IL-6/JAK2/STAT3 signaling8. IL-6 is associated with lymph node metastasis, TNM stage and degree of differentiation in colorectal cancer patients and is a prognostic biomarker in cancer immunotherapy9. In addition, inflammation and cancer can also be promoted in certain pathological states, where chronic oxidative stress promotes the activation of inflammatory signaling pathways, leading to the activation of multiple transcription factors or the dysregulation of gene and protein expression, which can lead to the development of tumors or the survival of cancer cells10. Several features of aging (i.e., genomic instability, epigenetic changes, chronic inflammation, and ecological dysregulation) are very similar to specific cancer features, making aging an important risk factor for colorectal cancer (CRC)11,12. Therefore, inflammatory genes in different pathological states also affect colorectal cancer to different degrees, and further studies are needed to investigate the relationship between inflammation-related genes and the prognosis of colorectal cancer patients.
Colorectal cancer is one of the least effective tumors for immunotherapy. Although there is clear clinical evidence of a therapeutic role for immune checkpoint inhibitors in mismatch repair-deficient (MMR) or highly microsatellite unstable (MSI-H) metastatic colorectal cancers, the vast majority of patients with well-characterized MMR or microsatellite-stable (MSS) tumors do not benefit from immunotherapy13,14. Inflammatory states are usually accompanied by the production of free radicals, stimulation of cytokines, chemokines, and growth and angiogenic factors that promote tumorigenesis by damaging DNA, stimulating angiogenesis, and inducing cell proliferation15. Recent studies have shown that IL-17 A increases PD-L1 expression through the p65/nrf1/miR-15b-5P axis and enhances resistance to anti-PD-1 therapies. IL-17 A has been identified as a promising therapeutic target for sensitization to immune checkpoint inhibitor therapy in MSS CRC patients16. In addition, blocking IL-6 enhances MHC-I and PD-L1 expression and improves the tumor response to anti-PD-1 therapy17. Inflammatory indexes (II), such as the systemic immune inflammation index (SII) and aspartate aminotransferase lymphocyte ratio index (ALRI), were identified as prognostic markers for progression-free survival (PFS) and overall survival (OS) in patients with metastatic colorectal cancer receiving chemotherapy and bevacizumab18.
Thus, the inflammatory response plays an important role at any stage of the tumor, and multiple inflammatory indicators are associated with the prognosis of CRC patients. In this study, we constructed a robust signature of inflammatory genes (IRGs) in CRC by combining the expression of inflammatory response-related genes obtained from the TCGA database with bioinformatics data. We also validated the ability of the IRG risk score to predict the tumor microenvironment and immune cell infiltration. In conclusion, this study contributes to further understanding the relationship between the inflammatory response and CRC and provides more precise medication guidance for CRC patients.
Methods
Data collection and preprocessing
The scRNA-seq data involved in this study were obtained from the Gene Expression Omnibus (GEO) database (GSE161277), and we selected samples from 4 of the cancer tissues (GSM4904234, GSM4904236, GSM4904239, GSM4904245). The single-cell data were first quality controlled and filtered using the “Seurat” R package, in which each gene was expressed in at least 3 cells and at least 250 genes were expressed in each cell. Filtering criteria: low expression levels of genes were identified only with nFeature_RNA values > 100 and percent.mt values < 15. After this, 11,288 cells remained for After this, 11,288 cells remained for subsequent analysis. The “Harmony” R package was then used to integrate all samples. PCA (Principal Component Analysis) was used for dimensionality reduction of highly variable genes, after which the top 40 PCs were selected for graph-based cell clustering. The “Harmony” R package was then used to integrate all samples. Using the Uniform Manifold Approximation and Projection (UMAP) with “RunUMAP” and “FindClusters” functions for downscaling and clustering. Based on manual annotation of cell types using marker genes calculated through the “FindAllMarkers” function, the identified cell groups include: B cell cluster (MS4A1, CD79A, VPREB3), cancer cell cluster (CEACAM5, PIGR, EPCAM), T cell cluster (CD40LG, KLRB1, IL7R), natural killer T (NKT) cell cluster (GZMA, CCL5, NKG7), fibroblast cluster (IGFBP7, SPARCL1, MGP), macrophage cluster (CD68, APOE, C1QA), neutrophil cluster (TIMP1, S100A9, S100A8), and plasma cell cluster (JCHAIN, IGLC2, IGLC3).
The gene expression data and clinical data used in this study were obtained from the TCGA and GEO databases and from the TCGA-COAD and GSE37582 cohorts, respectively. After the exclusion of samples with incomplete follow-up information and survival data, 456 samples were included in the TCGA cohort (including 415 tumor samples and 41 normal samples). We used the “TCGAbiolinks” R package to acquire RNA-seq data and selected gene transcript matrices with expression values in transcripts per million bases (TPM) for TCGA-COAD. The clinical information collected included sex, age, pathological stage, pathological TM stage (N stage was excluded because it was missing from GSE37582), survival time, and survival status.
IRG differential gene identification and molecular subtype characterization
We downloaded a total of 15,333 inflammation-related genes encoding proteins from GeneCards. The “limma” R package was used to analyze the gene differences with the filtering conditions of |log2FC|≥2 and FDR < 0.001, and we ultimately obtained 1204 DEGs. Next, the “ggVolcano” R package was used to map the volcanoes. We used the “ConsensusClusterPlus” R script to classify the combined samples into different molecular subtypes based on the expression of DEGs using the optimal classification range of K = 2–9. Next, the Kyoto Encyclopedia of Genes and Genomes (KEGG) database was selected for functional variant analysis (GSVA). K‒M curves were used to determine differences in survival between the two subtypes. Finally, differences in immune cell infiltration between subtypes were analyzed using single-sample gene set enrichment analysis (ssGSEA) to further understand the changes in the immune microenvironment in different subtypes.
Identification, functional enrichment analysis, and prognostic analysis of genes with differential molecular subtypes among the IRGs
We screened the DEGs of the two molecular subtypes of IRGs based on the following screening conditions: |log2FC|≥1 and FDR < 0.05. Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) functional enrichment analyses were performed to further explore the potential functions and pathways of the IRGs19. Next, we analyzed DEGs and survival time using univariate Cox regression to screen for genes with prognostic features. The samples were categorized into different gene subtypes based on the expression levels of these prognostic genes. Finally, the prognostic ability of different gene subtypes was verified using K‒M.
Construction and validation of a prognostic signature for inflammation-related genes
First, we divided the samples from the two cohorts, TCGA-COAD and GSE39582, into a training set and a validation set at a ratio of 7:3. Supplementary Table 1 shows the baseline clinical characteristics after TCGA-COAD division. Next, we performed univariate Cox regression analysis of the 1204 DEGs related to overall survival (OS) to screen prognostic DEGs, used the “glmnet” function to perform least absolute shrinkage and selection operator (LASSO) analysis on the screened prognostic genes to further optimize the results, and finally used multivariate Cox regression to screen 13 characteristic genes for model construction. Modeling formulas: risk score = coef Σ (Genei) × exp (Genei).
The median risk value of the samples was calculated according to the model formula, and the samples were categorized into high-risk and low-risk groups. Next, we analyzed the differences in risk scores among molecular and genetic subtypes of IRGs to assess the predictive ability of risk scores in different subtypes. Sankey plots of sample allocation were drawn using the “ggalluvial” R package. K‒M survival analysis was performed to assess the difference in survival between patients in the different risk subgroups, progression-free survival (PFI) was estimated for each patient, and receiver operating characteristic (ROC) curves were plotted to assess the prognostic value of the genetic trait. In addition, we calculated the C-index of the risk model using the “pec” R package to assess the accuracy of the model.
Construction and verification of the nomogram
We used the “rms” R package to construct a line plot of risk scores combined with patient clinical characteristics to accurately predict patient survival and guide clinical practice. Calibration and decision curve analysis (DCA) were performed to validate the predictive power of the nomogram. In addition, 1-, 3-, and 5-year ROC curves were plotted to further evaluate the performance of the nomogram.
Functional enrichment analysis
We used the “cluster-Profiler” R package to analyze the GO and KEGG analyses as well as GSEA of the DEGs from the high- and low-risk groups to further understand the functions and pathways enriched by the IRGs19.
Analysis of the tumor immune microenvironment and immune checkpoints
We used the CIBERSORT algorithm to quantify the infiltration of 22 immune cell types in the tumor microenvironment and assessed their relationships with characterized genes. Single-sample GSEA using a set of immune-related genes was used to assess multiple immune functions in the high- and low-risk groups and to compare the activity of these immune functions between the two risk groups. Then, to assess the relationships between different subgroups and immunotherapy efficacy, the expression levels of various immune checkpoint molecules in the two risk subgroups were analyzed, and Pearson correlation analyses between selected immune checkpoint molecules and risk scores were performed.
Tumor mutation landscape
The tumor mutational burden (TMB) is the sum of the number of mutations that occur in tumor cells. In general, a higher TMB indicates a greater number of mutations in the tumor cells. Therefore, tumors with a high TMB may be more likely to respond positively to immunotherapy. We analyzed the differences in TMB between patients in the high-risk and low-risk groups. The samples were grouped according to the median TMB, and survival analysis was used to assess the survival of patients in different subgroups. The R package “maftools” was used to construct waterfall plots of genes in the two risk groups, as well as survival curves for the mutation group and the wild type group.
We conducted a comprehensive mutation analysis based on the mutation data from the TCGA database, focusing on all non-synonymous mutations. These included missense, nonsense, frameshift, splice site, translation start site, and nonstop mutations. Patients were categorized into two groups: mutant and wild type, based on the presence or absence of these mutations.
CRC cell lines and culture conditions
Human colorectal cancer cell lines (HCT116, HCT15, SW480, SW620) were obtained from MeisenCTCC (Zhejiang, China), and normal human intestinal epithelial cells (NCM460) were obtained from iCell (Shanghai, China). All cells were cultured in DMEM (Gibco, USA) supplemented with 10% fetal bovine serum (Gibco, USA) and 1% penicillin/streptomycin (P/S), under conditions of 37 °C, 5% CO₂, and 100% humidity.
Patient signed informed consent and quantitative reverse transcription PCR (RT-qPCR)
Patient samples were obtained from seven colorectal cancer patients who underwent initial endoscopic examination at the Affiliated Hospital of Southwest Medical University. The study was conducted in accordance with the Declaration of Helsinki, ethical approval was obtained from the Ethics Committee of the Affiliated Hospital of Southwest Medical University (No. KY2024266), and all patients signed an informed consent form. Tumor tissue samples were collected alongside adjacent non-tumor tissue located 2 cm from the tumor margin. Total RNA from CRC patient tissues was extracted according to the instructions of the SteadyPure Quick RNA Extraction Kit. A PrimeScript™ RT kit (TaKaRa) was used for reverse transcription. According to the manufacturer’s instructions, real-time quantitative polymerase chain reaction (qPCR) was performed to measure the mRNA expression of GDF15 in tumor and adjacent non-tumor tissues from 7 patients, as well as in the colorectal cancer cell lines HCT116, HCT15, SW480, SW620, and the normal intestinal epithelial cell line NCM460; primer sequences are shown in Supplementary Table 2. Three experimental wells were set up for each sample, and each experiment was independently repeated at least three times.
Statistical analyses
Statistical analyses were performed using version 4.3.1 of R, GraphPad Prism 9. Significant quantitative differences between and among groups were calculated by one-way ANOVA and two-tailed t-test, respectively, and for non-normally distributed continuous variables, Wilcoxon rank sum test was used. Pearson’s analysis was applied for correlation analysis. The significance of the statistical results is indicated as ***P < 0.001, **P < 0.01, and *P < 0.05.
Results
Construction and prognostic analysis of molecular isoforms of inflammation-related DEGs in COAD
Our workflow diagram is shown in Fig. 1. First, we obtained 10,333 genes encoding proteins from the GeneCards database. Compared with those in normal samples, 1024 DEGs were detected in COAD tumor samples (Fig. 2A). To evaluate the molecular subtypes of COAD based on the differential expression of IRGs, an unsupervised consensus clustering algorithm was applied to all 1024 patient cohorts. K = 2 was considered to indicate optimal stability, and the COAD patients were categorized into two subtypes: clusters A and B (Fig. 2B). Next, Kaplan‒Meier survival analysis revealed significantly different survival outcomes between subtypes. Patients in cluster A exhibited lower survival than those in cluster B (Fig. 2C). GSVA was performed on both isoforms to analyze their biological behavior. Cluster A was predominantly enriched in extracellular matrix-receptor interactions and cell-matrix adhesion, whereas the remaining pathways (e.g., drug metabolism by cytochrome P450, fatty acid metabolism, and butyric acid metabolism) were highly enriched in cluster B (Fig. S1). In addition, we analyzed the differences in immune cell infiltration between the two subtypes using ssGSEA. Sixteen immune cells were highly infiltrated in Cluster A. The most prominent immune cells included myeloid-derived suppressor cells (MDSCs), regulatory T cells, and macrophages. Overall, 17 helper T cells and neutrophils exhibited high levels of immune cell infiltration in Cluster B (Fig. 2D).

Flowchart of the entire study.

Molecular and Genetic Subtype Analysis of IRGs. (A) Variance analysis volcano diagram (the dashed line indicates the filtering condition with logFC = 2, P = 0.001, and the blue dots in the graph represent genes that were downregulated in tumors, the red dots represent genes that were upregulated, and the gray dots represent genes that were not differentially expressed in tumors and normal tissues). FDR, false discovery rate; FC, fold change. (B) Consensus clustering matrix at k = 2 based on 1024 genes. (C) OS for both IRG subtypes. (D) Infiltration of 23 immune cells in the two IRG subtypes. (E) Histogram of GO enrichment analysis and KEGG pathway enrichment histogram of DEGs. (F) Consensus clustering matrix based on two IRG subtype DEGs at k = 3. (G) K‒M survival curves for three gene clusters. **Represents P < 0.01, ***Represents P < 0.001.
Construction and validation of gene subtypes based on IRG molecular subtype DEGs
To further understand the potential biological activities of IRGs in COAD, we performed differential analysis of genes in IRG clustersA and clusterB using the “limma” software package and identified 193 DEGs under the following filtering conditions: log|FC| ≥ 0.585 and corrected p value < 0.05. Functional enrichment analysis showed that these DEGs were predominantly enriched for biological functions related to the extracellular matrix (Fig. 2E) and that matrix metalloproteinases (MMPs) are an important class of enzymes in vivo that may lead to the metastasis of tumor cells by disrupting the extracellular matrix20. Pathway enrichment analysis revealed that the DEGs were enriched mainly in the following pathways: protein digestion and uptake, ECM-receptor interaction, adhesion to the cellular matrix, and the PI3K-Akt signaling pathway (Fig. 2E).
Then, we performed univariate Cox regression analysis of the DEGs to screen 77 genes with prognostic value. We genotyped the 77 prognostic genes again and obtained k = 3 clusters by the algorithm, thus obtaining three genotypes named Cluster A, Cluster B, and Cluster C (Fig. 2F). K‒M analysis revealed that patients in Cluster A had the worst survival, and those in Cluster B had better survival than those in Cluster A and Cluster C (Fig. 2G). Subsequent clinicopathologic heatmaps showed a continuous downward trend in the degree of gene expression in the three subtypes, suggesting that the majority of genes in the Cluster A subtype are risk factors for colon cancer and that genes that are highly expressed in Cluster B are protective factors (Fig. S2).
Construction and validation of the IRG-related prognostic signature
Previous IRG typing and genotyping methods have demonstrated great potential for determining the clinical prognosis of patients with colorectal cancer. To better utilize the predictive power of IRGs for COAD, we built a prognostic model. First, we performed a univariate Cox analysis on the 1024 DEGs obtained from the analysis of variance to obtain 97 prognostic genes. Then, the prognostic genes were subjected to LASSO regression analysis, and multivariate Cox regression was subsequently performed to avoid overfitting of the model (Fig. 3A, B). We eventually identified 13 key genes (Fig. 3C) and constructed an IRG-based risk score. IRG score = (0.327777843613415 * TIMP1 expression) + (-0.321505536641187 * GDF15 expression) + (0.519155635681503 * UCN expression) + (0.497663150446509 * KRT4 expression) + (0.704390071491466 * POU4F1 expression) + (0.979581063364134 * NXPH1 expression) + (0.302700609425077 * SIX2 expression) + (0.907534062215074 * CYP4F8 expression) + (0.342487252775221 * NPC1L1 expression) + (-0.360117110529824 * KLK12 expression) + (-1.05144522453045 * ASPG expression) + (0.361697071741414 * FOXD1 expression) + (0.319888833846153 * IGFL1 expression). The Sankey diagram shows the flow of data, with the low-risk group consisting only of cluster B in genotyping, which also corresponds to the fact that cluster B subtypes have the best survival. We then assessed the relationship between the two molecular typologies and the three genotypes and the risk scores and found that the risk scores for both the IRG typology and the Cluster A subtype of the genotypes were greater than those for the other subtypes, which also corresponded to the low survival of the Cluster A subtype (Fig. 3D–F).

Model construction and validation. (A) Penalty term cross-test plot for LASSO analysis. (B) Distribution of coefficients for LASSO analysis. (C) Forest plot of 13 model genes. (D) Sankey diagrams for various typologies and risk classifications. (E) Differences in risk scores between IRG subtypes. (F) Differences in risk scores between genotype subtypes. (G–I) OS rates for the testing set, training set, and external validation set. (J, K) Receiver operating characteristic (ROC) curves for the testing set and the training set. (L) Progression-free survival in the TCGA cohort.
The TCGA and GEO cohorts were then divided into training and test groups at a 7:3 ratio, and each cohort was divided into high- and low-risk groups based on the median value of the risk score. K‒M survival analyses revealed that patients in the low-risk group had good prognoses in all three cohorts (Fig. 3G–I). The area under the curve for subjects’ work characteristics at 1, 3, and 5 years was 0.716, 0.693, and 0.763 for the TEST group and 0.822, 0.811, and 0.793 for the TRAIN group, respectively (Fig. 3J, K). Survival analysis for progression-free survival in patients in the TCGA cohort also revealed better survival in the low-risk group (Fig. 3L). These data demonstrate the good predictive power of IRG-based risk profiles.
Independent prognostic value of inflammatory risk profiles and the construction and validation of a nomogram
To further explore the prognostic potential of risk characteristics, we integrated three common clinical characteristics (age, sex, and stage) and subjected the risk scores to univariate Cox analysis and multivariate Cox regression analysis. Our analysis revealed that stage and risk score were independent prognostic factors for this disease (p < 0.001) (Fig. 4A). The C-index was primarily used to evaluate the ability of the model; therefore, we compared the C-indexes of the risk score and other clinical traits for disease prediction, and the C-indexes of the risk score were all greater than those of the other clinical traits and were close to 0.8 (Fig. 4B). These data provide further evidence of the ability of the prognostic model to predict disease.

Independent prognostic analysis and construction and validation of the nomogram. (A) Univariate and multivariate Cox regression analyses of risk scores and other clinicopathologic characteristics. (B) Comparison of risk scores with the C-index for clinical traits. (C) A nomogram combining risk scores and other clinical characteristics. (D) Calibration curve for the nomogram. (E) Decision curve analysis (DCA) of the nomogram. (F) 1-, 3-, and 5-year ROC curves.
Nomogram prediction models have demonstrated considerable potential for clinical application. In this study, we integrated risk scores with clinicopathological characteristics to develop novel nomogram models. These models provide individualized predictions by incorporating each patient’s unique clinicopathological data and risk score. For instance, in a randomly selected patient with a risk score of 229, the model predicted 1-year, 3-year, and 5-year survival probabilities of 0.925, 0.820, and 0.667, respectively (Fig. 4C). The calibration curves at 1, 3, and 5 years showed good agreement between the actual survival probabilities and the nomogram predictions (Fig. 4D). DCA analyses showed good validity for both nomogram and risk values (Fig. 4E). In addition, the one-, three-, and five-year risk scores and the ROC curve of the nomogram had the highest AUC values (AUC > 0.75) (Fig. 4F).
Correlation analysis of the IRG risk score and clinicopathologic characteristics of patients with COAD
To assess the clinical significance of the IRG risk score, we combined patient information from the TCGA and GEO cohorts, including sex, age, stage, and TN stage. We performed a chi-square test of each clinical characteristic against the risk score and found that all clinical characteristics except sex differed between the high- and low-risk groups (Fig. 5A). Next, we performed percentage statistics on the frequency of each clinical characteristic in the high- and low-risk groups, and the violin plots showed that the risk scores were able to distinguish the staging and TN staging well and that patients who were more likely to have lymph node metastasis (N staging) and advanced tumor staging (stage staging) had higher risk scores (Fig. 5B–F).

Relationships between risk scores and clinical traits. (A) Circle diagrams for two risk subgroups. (B–F) Age, sex, stage, T stage, and N stage in the two risk subgroups and risk scores in the two groups.
Functional enrichment analysis of different IRG risk subgroups
We identified DEGs between the high- and low-risk groups of IRGs by differential expression analysis, followed by GO and KEGG functional enrichment analysis. In the BP category, DEGs may play important roles in “epidermal development” and “epidermal cell differentiation”. Among the cellular component (CC) terms, “corrupted envelope” was the most common term among the DEGs. In the field of molecular function (MF), “receptor ligand activity”, “glycosaminoglycan binding”, “cytokine activity”, and “G protein-coupled receptor binding” were identified as possible DEGs (Fig. 6A). In addition, the results of KEGG analysis suggested that the DEGs might be involved in the “signaling pathways regulating pluripotency of stem cells” and “Hippo signaling pathway” (Fig. 6B). These data suggest that DEGs may be involved in cell signaling for epidermal growth and differentiation. Next, GSEA showed that pathways such as the citric acid cycle (TCA cycle), pentose and glucuronide interconversion, and peroxisomes were enriched in the low-risk group (Fig. 6C). The TCA cycle is a major intracellular energy production pathway, and colorectal cancer cells often exhibit abnormal TCA cycle activity21. Pathways enriched in the high-risk group include cell adhesion molecules and extracellular matrix-receptor interactions (Fig. 6D). ECM not only affects tumor malignancy and growth but also influences the tumor response to therapy22.

Functional enrichment analysis of DEGs in the two risk subgroups. (A, B) GO and KEGG functional analyses. (C) GSEA pathway analysis in the low-risk group. (D) GSEA pathway analysis in the high-risk group.
Immune cell infiltration and immune checkpoint analysis between the two risk subgroups
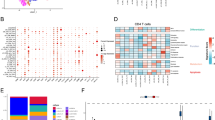
The role of the immune microenvironment in tumor progression is closely related to patient prognosis. Therefore, in our study, the correlation of prognosis-related signature genes with 22 tumor immune infiltrating cells (TIICs) was first analyzed using the CIBERSORT algorithm (Fig. 7A). Each of the characterized genes correlated with a variety of immune cells; in particular, FOXD1 showed a strong positive correlation with CD8 + T cells and a significant negative correlation with M0 macrophages. Next, we quantified the enrichment scores of immune infiltrating cells and functions using the single sample gene set enrichment analysis (ssGSEA) approach. The results showed that four TIIC enrichment scores were greater in the high-risk affected group (iDCs, NKT cells, NK cells, and Tfh cells). Similar results were observed for two immune-related functions (macrophage and type I IFN response) (Fig. 7B-C). In addition, the risk score also correlated significantly with the initial CD4 + T-cell count (Fig. 7D). With the initial success of melanoma treatment, immunotherapy has rapidly become the mainstay of treatment for many types of solid cancers23. In our study, most of the immune checkpoint genes (CD276, CD70, HHLA2, etc.) were expressed at higher levels in the high-risk group than in the low-risk group, suggesting that patients in the high-risk group were more sensitive to treatment involving immune checkpoints (Fig. 7E). In addition, the risk score showed a significant positive correlation with the immune checkpoints PD1, PDL1, PDL2, and CTLA4 (Fig. 7F). These results suggest a potential link between the IRG model we constructed and immune infiltration, as well as the possibility that the risk score could predict the outcome of immunotherapy in patients.

Immune microenvironment and immune checkpoint analysis. (A) Heatmap of the correlation of immune-infiltrating cells with 13 model genes. (B) Scoring of immune cells in the high- and low-risk groups. (C) Scoring of immune cell function in the high- and low-risk groups. (D) Correlation of the risk score with the number of infiltrating immune cells. (E) Expression levels of immune checkpoint molecules in the high- and low-risk groups. (F) Correlations between the risk score and the immune checkpoints PDCD1 (PD1), CD274 (PDL1), PDCD1LG2 (PDL2), and CTLA. *Represents P < 0.05, **Represents P < 0.01, ***Represents P < 0.001.
Tumor mutation load and mutation landscape analysis
The tumor mutational burden (TMB) is the total number of mutations in a tumor cell and is usually expressed as the number of mutations per million base pairs (megabase, Mb). We analyzed the mutation frequency and TMB in the high- and low-risk groups. The 20 genes with the highest mutation frequencies are shown in Fig. 8A. TMB occurred in 92.97% of the samples in the low-risk group, with APC mutations being the most significant (71%). TMB occurred in 98.48% of patients in the high-risk group, and the APC gene was also mutated most significantly in the low-risk group (70%). The tumor mutational burden (TMB) was significantly higher in the high-risk group compared to the low-risk group (Fig. 8B), indicating an elevated TMB in the high-risk group. Kaplan-Meier (K-M) analysis revealed that patients in the low-TMB group generally exhibited better overall survival (Fig. 8C). Furthermore, we combined TMB status with risk scores and observed that patients with a combination of high TMB and low risk or low TMB and low risk had the most favorable overall survival outcomes (Fig. 8D).

Tumor mutation burden (TMB) and mutation landscape analysis. (A) Waterfall plot of mutations in the low- and high-risk groups. (B) Differences in tumor mutation load between risk subgroups. (C) OS in the high-TMB and low-TMB groups. (D) OS of patients in subgroups stratified by both the TMB and risk score. (E, F) K-M curves of patients in the USH2A and TP53 gene mutation groups and patients in the wild type group. (G) K-M curves of patients in the USH2A and TP53 gene simultaneous mutation group and patients in the wild type group. (H) Landscape of immune cell infiltration in USH2A mutant and wild type groups. Mutant: mutation; WT: wild type.
In addition, we analyzed the impact of mutations in the top 20 most frequently mutated genes on the survival outcomes of patients with and without mutations. Patients with mutations in the USH2A and TP53 genes demonstrated better survival outcomes compared to those without these mutations24. However, patients with concurrent mutations in both USH2A and TP53 exhibited poorer survival outcomes (Fig. 8E-G). Moreover, we found that CD8 + T cells and activated NK cells were highly enriched in the USH2A-mutant group, suggesting that USH2A mutations may trigger an immune response in the host (Fig. 8H).
Analysis of scRNA-seq data and validation of model genes
First, we obtained 11,288 cells according to the parameter settings (nFeature_RNA > 100 and percent. mt < 15; Fig. S3A, B). To eliminate batch effects, four samples were integrated using the “Harmony” R package (Figure S3C, D). Subsequently, UMAP was applied to downscaling and clustering of the first 2000 variant genes (Fig. 9A, B). We utilized a combination of automated and manual annotation methods to classify the 14 clusters into 8 major cell types, including cancer cells (CEACAM5, PIGR, EPCAM), T cells (CD40LG, KLRB1, IL7R), natural killer T cells (GZMA, CCL5, NKG7), B cells (MS4A1, CD79A, VPREB3), plasma cells (JCHAIN, IGLC2, IGLC3), macrophages (CD68, APOE, C1QA), fibroblasts (IGFBP7, SPARCL1, MGP) and neutrophils (TIMP1, S100A9, S100A8) (Fig. 9C). We demonstrate the percentages of various cell populations in four single-cell samples (Fig. 9D). Next, we showed the expression of the model genes in various cell populations, and the results showed that the model genes GDF15, POU4F1, NXPH1, SIX2, CYP4F8, NPC1L1, KLK12, ASPG, FOXD1, and IGFL1 were better expressed in cancer cells, with GDF15 being the most pronounced in the cancer cell population, while TIMP1 was more strongly expressed in neutrophils and UCN was more highly expressed in B cells than in cancer cells (Fig. 9E, F).

The scRNA-seq data revealed validation of CRCs with different annotations and heterogeneous expression patterns as well as model genes. (A) A total of 14 clusters were identified through downscaling and clustering. (B) These eight clusters are recognized as different types of cells by their respective marker genes. (C) Expression of the top 3 most prominent marker genes in each cell population. (D) Stacked histogram of individual cell population occupancy in 4 cancer tissue samples. (E) Circle plot of average expression of model genes across cell populations, red indicates upregulation of gene expression, gray indicates downregulation of gene expression. (F) Expression levels and distribution of TIMP1, GDF15, UCN, POU4F1, NXPH1, SIX2, CYP4F8, NPC1L1, KLK12, ASPG, FOXD1, IGFL1 in different tumor subtypes.
Validation of the model gene GDF15 at the tissue and cellular level in colorectal cancer
We further examined the expression profile of the model gene GDF15 in clinical samples from CRC patients by qPCR and found that the expression level of GDF15 was higher in CRC tissues (Fig. 10A). In addition, we validated the expression of GDF15 in colorectal cancer cell lines. The results showed that GDF15 was highly expressed in CRC cell lines HCT116, HCT15, SW480, SW620, and LOVO compared with normal intestinal epithelial cells NCM460 (Fig. 10B). The above data suggest that high expression of GDF15 gene may be a risk factor for CRC.

Validation of qPCR for the inflammatory gene GDF15. (A) mRNA expression levels of GDF15 in patient-derived tumor tissues and paracancerous tissues. (B) mRNA expression levels of GDF15 in normal intestinal epithelial cells NCM460, CRC cells HCT116, HCT15, SW480, SW620. Each experiment was repeated three times. *p < 0.05, **p < 0.01, ***p < 0.001, ****p < 0.0001.
Discussion
To date, inflammation has become a hotspot for all types of neoplastic diseases as well as preneoplastic diseases, the link between inflammation and tumorigenesis has been well established in the last two decades, and inflammatory bowel inflammation is an important risk factor for colon carcinogenesis25. The accumulation of inflammatory genetic alterations and loss of normal cellular regulatory processes are not only associated with cancer growth and progression but also lead to the expression of tumor-specific and tumor-associated antigens, which may activate antitumor immunity26. In the tumor microenvironment, antigen-specific adaptive immune responses are impeded, as soluble cytokines prevent T-cell infiltration, and cell surface signals are modulated to suppress lymphocyte-mediated killing activity27. Currently, MSI-H/dMMR is the only recognized biomarker that can be used to guide immunotherapy for colon cancer28. A small proportion of patients with microsatellite-stabilized (MSS) or proficient MMR (pMMR) mutations can benefit from immunotherapy, whereas a large proportion of MSI-H/dMMR patients exhibit intrinsic or acquired resistance to immunotherapy29. Therefore, the identification of new biomarkers or prognostic markers is crucial, and powerful biomarkers are needed for the stratification of colorectal cancer patients and assessment of the tumor immune microenvironment. Currently, studies have demonstrated the predictive ability of inflammation-related genes in colorectal cancer, and in this study, we screened genes in a novel way and combined them with data from single-cell sequencing, identified new inflammation-related genes, and confirmed the value of the genes for prognostic prediction in patients with colorectal cancer through our validation.
In this study, we first classified patients into two different molecular subtypes based on IRG expression by an unsupervised consistent clustering method. Patients with IRG subtype A had poorer overall survival than those with subtype B, and there were also significant differences in pathways enriched in different subtypes and different immune cell infiltrates. We reclassified COAD patients according to the DEGs between the two subtypes. These results initially demonstrated the prognostic value of IRGs in COAD. In addition, we screened 13 genes with prognostic value using univariate Cox regression, LASSO regression, and multivariate Cox regression and then constructed risk-prognostic models. There were significant differences in survival between the high- and low-risk groups in the different cohorts, and the area under the curve (AUC) of the receiver operating characteristic (ROC) curve (AUC) curve (AUC) was also high. More importantly, the C-index, which evaluates the performance of the model, is superior to all other clinical characteristics. For better clinical application, we constructed a nomogram, and the ROC curves were able to predict the survival time of patients at 1, 3, and 5 years very well. In addition, there were significant differences in clinicopathologic correlation, TME, immune checkpoint analysis and TMB between the high-risk and low-risk groups. Therefore, our constructed prognostic profile of inflammatory genes can assist in the clinical diagnosis of COAD patients, as well as the development of personalized and precise treatments for patients.
We screened 13 genes associated with inflammation and the prognosis of colon cancer patients. The TIMP1, GDF15, UCN, KRT4, POU4F1, NXPH1, SIX2, NPC1L1, KLK12, IGFL1, and FOXD1 genes have been studied in tumors in a correlative manner. In addition to that, we classified all the cells into cancer cells, T cells, natural killer T cells, B cells, plasma cells, macrophages, fibroblasts, and neutrophils based on the markers of each cell population after quality control and filtering the results of single-cell sequencing of four cancer tissue samples from the GSE161277 data. And the expression of model genes in each cell population was verified at the single-cell level. One of them, tissue inhibitor of metalloproteinases 1 (TIMP1) has been identified in a variety of genetic prognostic studies and was the first natural collagenase inhibitor to be discovered30. High TIMP1 expression is positively associated with poor prognosis in lung, brain, prostate, breast, colon and several other cancers31. TIMP1 causes tumor proliferation and metastasis through the FAK-PI3K/AKT and MAPK pathways in colon cancer32. Growth differentiation factor 15 (GDF15) is a member of the transforming growth factor (TGF) superfamily. GDF15 has been implicated in obesity, aging, cardiovascular disease, and the progression of a number of cancers, including colorectal and ovarian cancers33. In our single-cell analysis, GDF15 was the most significantly expressed gene in the cancer cell population. In addition, in vitro experimental validation, GDF15 expression was higher in colorectal cancer tumor tissues than in paracancerous tissues and in colorectal cancer cell lines compared to normal intestinal epithelial cells, thus the results of our qPCR validation were consistent with the results in the database. Phase 2 studies of ponsegromab, a monoclonal antibody targeting GDF15, are currently underway34. FOXD1 plays a role in a wide range of tumors and can be of prognostic value in predicting the prognosis of patients with colorectal cancer through the ERK 1/2 pathway and promoting tumor progression35,36. In conclusion, a portion of the genes for constructing predictive models are closely related to tumor development, and we also screened genes that are still lacking in tumor research; therefore, the molecular mechanisms and phenotypes of these biomarkers in cells need to be further investigated.
The role of the tumor microenvironment in oncology research has been clearly defined by researchers as a highly structured ecosystem containing cancer cells surrounded by multiple nonmalignant cell types. The TME includes a rich diversity of immune cells, cancer-associated fibroblasts (CAFs), endothelial cells (ECs), pericytes, and other cell types that vary by tissue37. In our analysis, the immune function of macrophages was upregulated in the high-risk group. Recent studies have shown that CXCL8 polarizes tumor-associated macrophages (TAMs) to the M2 phenotype, leading to increased M2 macrophage infiltration in CRC and reduced CD8 + T-cell infiltration, resulting in an immunosuppressive microenvironment38. In the low-risk group, the immune function of NK cells was upregulated, and NK cells also play a crucial role in bowel cancer. It is widely accepted that low levels of NK cell infiltration and/or impaired NK cell function are associated with poor overall patient survival and recurrence of CRC after treatment39. We also evaluated immune checkpoints that were differentially expressed between the high- and low-risk groups, and the risk scores showed significant positive correlations with important PD1, PDL1, PDL2, and CTLA4 checkpoints. Cytotoxic T lymphocyte-associated protein 4 (CTLA-4) and programmed cell death protein 1 (PD-1), two inhibitory checkpoints commonly found on activated T cells, have been found to be the most reliable targets for the treatment of cancer40,41. The inflammatory cytokine interleukin 17 (IL-17) can upregulate PD-L1 protein expression in HCT116 CRC cells through activation of NF-κB and ERK1/2 signaling42. Smad7 is a negative regulator of TGF-β signaling, and its deficiency induces CD103 + PDL2/1 + DCs and Tregs to attenuate DSS-induced colitis43. Using single-cell sequencing, a recent study analyzed immune and stromal cell dynamics in neoadjuvant PD-1-blocked d-MMR/MSI-H CRC patients and showed that in patients with immunotherapy-pathologically complete remission (pCR) tumors, the proportions of CD8 + Trm-mitotic cells, CD4 + Tregs, proinflammatory IL1B + Mono cells, and CCL2 + fibroblasts after treatment were consistently decreased, whereas the proportions of CD8 + Tem cells, CD4 + Th cells, CD20 + B cells, and HLA-DRA + endothelial cells increased, providing yet another new insight into the mechanisms of ICI therapy44. When the level of inflammation in a patient’s body is elevated, the response to ICIs is also decreased, and MSI-H CRC patients with inflammatory diseases are at increased risk of developing resistance to ICIs through neutrophil-associated T-cell depletion and hence ICI resistance45. Furthermore, in our genomic mutation landscape analysis46,47, patients with USH2A mutations exhibited significantly worse survival outcomes compared to those without mutations. Notably, the mutation group showed greater enrichment of CD8 + T cells and activated NK cells, consistent with findings from related studies. These results suggest that USH2A mutations may serve as a broadly applicable biomarker for predicting responses to ICIs in solid tumors48.Our study has several limitations: we performed external validation using only one database, GEO, and in the future, we will use several different databases for joint validation. Second, the TCGA database we analyzed contains Western case data and therefore lacks representative prospective data. We validated the expression level of only one model gene in vitro, and further validation of the mechanism of action of other genes in colorectal cancer is needed.
Conclusion
In this study, we comprehensively analyzed the IRGs of CRC patients and developed a prognostic model based on inflammatory gene correlation, which exhibited excellent ability to predict the OS of patients. Risk subgroups based on risk scores had their own unique characteristics in terms of the immune microenvironment and immune checkpoints. In addition, we validated the model genes at the single-cell level, and GDF15, which is most pronouncedly expressed in cancer cell populations, was also well validated at the CRC tissue and cellular levels, but further studies are needed to determine its mechanism in CRC.
Data availability
The transcriptomic data and clinical information for this study were obtained from the TCGA database (https://portal.gdc.cancer.gov/). External validation set data were downloaded from the GEO database (https://www.ncbi.nlm.nih.gov/geo/). Further data requests are available by contacting the corresponding authors.
References
Morgan, E. et al. Global burden of colorectal cancer in 2020 and 2040: Incidence and mortality estimates from GLOBOCAN. Gut 72, 338–344. https://doi.org/10.1136/gutjnl-2022-327736 (2023).
Greten, F. R. & Grivennikov, S. I. Inflammation and cancer: Triggers, mechanisms, and consequences. Immunity 51, 27–41. https://doi.org/10.1016/j.immuni.2019.06.025 (2019).
Denk, D. & Greten, F. R. Inflammation: The incubator of the tumor microenvironment. Trends Cancer 8, 901–914. https://doi.org/10.1016/j.trecan.2022.07.002 (2022).
Birch, R. J. et al. Inflammatory bowel disease-associated colorectal cancer epidemiology and outcomes: An English population-based study. Am. J. Gastroenterol. 117, 1858–1870. https://doi.org/10.14309/ajg.0000000000001941 (2022).
Schmitt, M. & Greten, F. R. The inflammatory pathogenesis of colorectal cancer. Nat. Rev. Immunol. 21, 653–667. https://doi.org/10.1038/s41577-021-00534-x (2021).
Marmol, I., Sanchez-de-Diego, C., Pradilla Dieste, A. & Cerrada, E. Jesus Rodriguez Yoldi, M. Colorectal carcinoma: A general overview and future perspectives in colorectal cancer. Int. J. Mol. Sci. 18 https://doi.org/10.3390/ijms18010197 (2017).
Zhou, R. W., Harpaz, N., Itzkowitz, S. H. & Parsons, R. E. Molecular mechanisms in colitis-associated colorectal cancer. Oncogenesis 12, 48. https://doi.org/10.1038/s41389-023-00492-0 (2023).
Zhang, X. et al. Human colorectal cancer-derived mesenchymal stem cells promote colorectal cancer progression through IL-6/JAK2/STAT3 signaling. Cell Death Dis. 9 https://doi.org/10.1038/s41419-017-0176-3 (2018).
Zheng, J., Wang, X., Yu, J., Zhan, Z. & Guo, Z. IL-6, TNF-α and IL-12p70 levels in patients with colorectal cancer and their predictive value in anti-vascular therapy. Front. Oncol. 12 https://doi.org/10.3389/fonc.2022.997665 (2022).
Bardelcikova, A., Soltys, J. & Mojzis, J. Oxidative stress, inflammation and colorectal cancer: An overview. Antioxidants 12 https://doi.org/10.3390/antiox12040901 (2023).
López-Otín, C., Pietrocola, F., Roiz-Valle, D., Galluzzi, L. & Kroemer, G. Meta-hallmarks of aging and cancer. Cell Metabol. 35, 12–35. https://doi.org/10.1016/j.cmet.2022.11.001 (2023).
Crossland, N. A. et al. Fecal microbiota transplanted from old mice promotes more colonic inflammation, proliferation, and tumor formation in azoxymethane-treated A/J mice than microbiota originating from young mice. Gut Microbes 15 https://doi.org/10.1080/19490976.2023.2288187 (2023).
Ciardiello, D. et al. Immunotherapy of colorectal cancer: Challenges for therapeutic efficacy. Cancer Treat. Rev. 76, 22–32. https://doi.org/10.1016/j.ctrv.2019.04.003 (2019).
Lichtenstern, C. R., Ngu, R. K., Shalapour, S., Karin, M. & Immunotherapy Inflamm. Colorectal Cancer Cells 9, doi:https://doi.org/10.3390/cells9030618 (2020).
Landi, S. et al. Polymorphisms within inflammatory genes and colorectal cancer. J. Negat. Results Biomed. 5 https://doi.org/10.1186/1477-5751-5-15 (2006).
Liu, C. et al. Blocking IL-17A enhances tumor response to anti-PD-1 immunotherapy in microsatellite stable colorectal cancer. J. Immunother. Cancer 9 https://doi.org/10.1136/jitc-2020-001895 (2021).
Li, W. et al. Blockade of IL-6 inhibits tumor immune evasion and improves anti-PD-1 immunotherapy. Cytokine 158, 155976. https://doi.org/10.1016/j.cyto.2022.155976 (2022).
Passardi, A. et al. Inflammatory indices as prognostic markers in metastatic colorectal cancer patients treated with chemotherapy plus Bevacizumab. Ther. Adv. Med. Oncol. 15, 17588359231212184. https://doi.org/10.1177/17588359231212184 (2023).
Kanehisa, M. & Goto, S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 28, 27–30. https://doi.org/10.1093/nar/28.1.27 (2000).
Omer, U., Zeynep, Y., Fatih, T. & Ibrahim Halil, Y. Elevated expression levels of COX-2, IL-8 and VEGF in colon adenocarcinoma. Cell. Mol. Biol. 69, 146–150. https://doi.org/10.14715/cmb/2023.69.6.22 (2023).
Pavlova, N. N. & Thompson, C. B. The emerging hallmarks of cancer metabolism. Cell Metab. 23, 27–47. https://doi.org/10.1016/j.cmet.2015.12.006 (2016).
Henke, E., Nandigama, R. & Ergün, S. Extracellular matrix in the tumor microenvironment and its impact on cancer therapy. Front. Mol. Biosci. 6, 160. https://doi.org/10.3389/fmolb.2019.00160 (2019).
Ganesh, K. et al. Immunotherapy in colorectal cancer: Rationale, challenges and potential. Nat. Rev. Gastroenterol. Hepatol. 16, 361–375. https://doi.org/10.1038/s41575-019-0126-x (2019).
Wang, G. et al. PTPRD/PTPRT mutation correlates to treatment outcomes of immunotherapy and immune landscape in pan-cancers. Chin. J. Cancer Res. 35, 316–330. https://doi.org/10.21147/j.issn.1000-9604.2023.03.09 (2023).
Terzić, J., Grivennikov, S., Karin, E. & Karin, M. Inflammation and colon cancer. Gastroenterology 138, 2114.e2105. https://doi.org/10.1053/j.gastro.2010.01.058 (2010).
Karin, M. & Shalapour, S. Regulation of antitumor immunity by inflammation-induced epigenetic alterations. Cell. Mol. Immunol. 19, 59–66. https://doi.org/10.1038/s41423-021-00756-y (2022).
Franzolin, G. & Tamagnone, L. Semaphorin signaling in cancer-associated inflammation. Int. J. Mol. Sci. 20 https://doi.org/10.3390/ijms20020377 (2019).
Yang, X. et al. Genomic characterization and immunotherapy for microsatellite instability-high in cholangiocarcinoma. BMC Med. 22 https://doi.org/10.1186/s12916-024-03257-7 (2024).
Hou, W., Yi, C. & Zhu, H. Predictive biomarkers of colon cancer immunotherapy: Present and future. Front. Immunol. 13, 1032314. https://doi.org/10.3389/fimmu.2022.1032314 (2022).
Grünwald, B., Schoeps, B. & Krüger, A. Recognizing the molecular multifunctionality and interactome of TIMP-1. Trends Cell. Biol. 29, 6–19. https://doi.org/10.1016/j.tcb.2018.08.006 (2019).
Jackson, H. W., Defamie, V., Waterhouse, P. & Khokha, R. TIMPs: Versatile extracellular regulators in cancer. Nat. Rev. Cancer 17, 38–53. https://doi.org/10.1038/nrc.2016.115 (2017).
Song, G. et al. TIMP1 is a prognostic marker for the progression and metastasis of colon cancer through FAK-PI3K/AKT and MAPK pathway. J. Exp. Clin. Cancer Res. 35, 148. https://doi.org/10.1186/s13046-016-0427-7 (2016).
Du, Y. N. & Zhao, J. W. GDF15: Immunomodulatory role in hepatocellular carcinoma pathogenesis and therapeutic implications. J. Hepatocell. Carcinoma 11, 1171–1183. https://doi.org/10.2147/jhc.S471239 (2024).
Groarke, J. D. et al. Phase 2 study of the efficacy and safety of ponsegromab in patients with cancer cachexia: PROACC-1 study design. J. Cachexia Sarcopenia Muscle. 15, 1054–1061. https://doi.org/10.1002/jcsm.13435 (2024).
Pan, F., Li, M. & Chen, W. FOXD1 predicts prognosis of colorectal cancer patients and promotes colorectal cancer progression via the ERK 1/2 pathway. Am. J. Transl. Res. 10, 1522–1530 (2018).
Zong, Y. et al. Combination of FOXD1 and Plk2: A novel biomarker for predicting unfavourable prognosis of colorectal cancer. J. Cell. Mol. Med. 26, 3471–3482. https://doi.org/10.1111/jcmm.17361 (2022).
de Visser, K. E. & Joyce, J. A. The evolving tumor microenvironment: From cancer initiation to metastatic outgrowth. Cancer Cell 41, 374–403. https://doi.org/10.1016/j.ccell.2023.02.016 (2023).
Shao, Y. et al. CXCL8 induces M2 macrophage polarization and inhibits CD8(+) T cell infiltration to generate an immunosuppressive microenvironment in colorectal cancer. Faseb J. 37, e23173. https://doi.org/10.1096/fj.202201982RRR (2023).
Fionda, C. et al. NK Cells and other cytotoxic innate lymphocytes in colorectal cancer progression and metastasis. Int. J. Mol. Sci. 23 https://doi.org/10.3390/ijms23147859 (2022).
Wei, S. C., Duffy, C. R. & Allison, J. P. Fundamental mechanisms of immune checkpoint blockade therapy. Cancer Discov. 8, 1069–1086. https://doi.org/10.1158/2159-8290.Cd-18-0367 (2018).
Ribas, A. & Wolchok, J. D. Cancer immunotherapy using checkpoint blockade. Science 359, 1350–1355. https://doi.org/10.1126/science.aar4060 (2018).
Wang, X. et al. Inflammatory cytokines IL-17 and TNF-α up-regulate PD-L1 expression in human prostate and colon cancer cells. Immunol. Lett. 184, 7–14. https://doi.org/10.1016/j.imlet.2017.02.006 (2017).
Garo, L. P. et al. Smad7 controls immunoregulatory PDL2/1-PD1 signaling in intestinal inflammation and autoimmunity. Cell Rep. 28, 3353–3366.e3355. https://doi.org/10.1016/j.celrep.2019.07.065 (2019).
Li, J. et al. Remodeling of the immune and stromal cell compartment by PD-1 blockade in mismatch repair-deficient colorectal cancer. Cancer Cell 41, 1152–1169e1157. https://doi.org/10.1016/j.ccell.2023.04.011 (2023).
Sui, Q. et al. Inflammation promotes resistance to immune checkpoint inhibitors in high microsatellite instability colorectal cancer. Nat. Commun. 13, 7316. https://doi.org/10.1038/s41467-022-35096-6 (2022).
Long, J. et al. Identification of NOTCH4 mutation as a response biomarker for immune checkpoint inhibitor therapy. BMC Med. 19 https://doi.org/10.1186/s12916-021-02031-3 (2021).
Lu, M. et al. Pan-cancer analysis of SETD2 mutation and its association with the efficacy of immunotherapy. Npj Precis. Oncol. 5 https://doi.org/10.1038/s41698-021-00193-0 (2021).
Mao, Y. et al. The landscape of objective response rate of anti-PD-1/L1 monotherapy across 31 types of cancer: A system review and novel biomarker investigating. Cancer Immunol. Immunother. 72, 2483–2498. https://doi.org/10.1007/s00262-023-03441-3 (2023).
Funding
This study was supported by grants from the Science and Technology Planning Project of Sichuan Province (2022YFS0626), the “Luzhou Municipal People’s Government-Southwest Medical University” Technology Strategy Project (2023LZXNYDJ001), the Sichuan Science and Technology Program (2023RCM198), and School Youth Fund of Southwest Medical University(2022QN021).
Author information
Authors and Affiliations
Contributions
WY and YA conceived and designed the study. QJ, CZ, LY, and SL obtained the data and performed the statistical analysis. WX, GL, XS, MC and CX performed the experiments and analyzed the data. WY drafted the manuscript. ML and ZY revised the manuscript for intellectual content and language.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
The human tissues obtained in our study were approved by the Ethics Committee of the Affiliated Hospital of Southwest Medical University in accordance with the Declaration of Helsinki (1964).
Consent for publication
All participants signed an informed consent form prior to the study, which was approved by the Affiliated Hospital of Southwest Medical University (No. KY2024266).
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yin, W., Ao, Y., Jia, Q. et al. Integrated singlecell and bulk RNA-seq analysis identifies a prognostic signature related to inflammation in colorectal cancer. Sci Rep 15, 874 (2025). https://doi.org/10.1038/s41598-024-84998-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-84998-6
