
Abstract
The total cement energy consumption is around 5% of global industrial energy usage. In cement plants, mills consume half of this energy for dry grinding particles. However, grinding in tumbling mills is a random process, and a maximum of 5% of this energy would be directly devoted to particle size reduction. Thus, understanding interactions between operation variables and the mill energy consumption factors would be essential for sustainable cement production and green transition. Surprisingly, few investigations were conducted to study the energy consumption indexes of cement mills. Using a conscious lab “CL” as an advanced AI structure for industrial-scale problems could facilitate such an understanding of interactions within cement mill variables and promote controlling energy consumption for sustainable production. To fill the gap, this study developed a CL by examining different AI models (Random Forest, Support Vector Regression, Convolutional Neural Network, extreme gradient boosting, CatBoost, and SHapley Additive exPlanations) for modeling energy consumption indexes of a close ball mill circuit in a cement plant to address the effectiveness of operating variables. Explainable AI modeling highlighted interactions and measured the effectiveness of operating variables on mill energy consumption indexes. The airlift current and separator variables ranked the most effective operating factors on the mill energy consumption indexes. CatBoost, as an advanced AI model, showed the highest prediction accuracy for modeling (R2: 0.90). Such a CL model for a cement mill can be used for training operators, controlling the process, saving time and energy, reducing laboratory work, and scaling issues, and finally enhancing sustainability.
Similar content being viewed by others
Introduction
Cement plants use 110–120 kWh of electrical power per ton of their production (mainly for grinding). In the cement industry, the clinker grinding process accounts for approximately 40% of the electrical energy consumed1. Traditionally, ball mills are used in cement production to reduce raw material and clinker particle size. However, grinding in tumbling mills has a random mechanism, and only 1 to 5% of the devoted energy would be consumed to reduce the size of particles2,3. Around 5% of the world’s electricity production is consumed by cement plants. It was monitored that the power draw (consumed energy) range in ball mills is approximately l0 kWh/t (mill drive only) for soft, chalky limestone to 25 kWh/t for hard materials. For roller mills, the range may be 4.5–8.5 kWh/t3. In other words, as one of the most energy-intensive parts of the process, grinding in the cement industry needs significant process improvement to enhance the green transition and sustainable production4.
Controlling main motor power and elevator current is a typical tool for monitoring energy consumption in cement ball mills5,6. Understanding correlations between operational parameters and the mill energy index and ranking them based on their importance could help to optimize the mill power consumption. Few studies have been conducted on understanding the interaction between industrial tumbling mills’ power draw and other milling variables, where determining the mill power draw is crucial for designing, operating, and evaluating an efficient plant7,8,9. It is mainly reported that parameters such as feed rate (ton/hr), speed (rpm), length and diameter of the mill (m), and particle properties (size, density, working index, etc.) can be used for such an understanding and predicting a mill’ power draw10,11. Mathematical models, such as the population balance and residence time distribution, have been used to investigate possible relationships between these variables and mills’ energy consumption12,13,14. The main drawbacks of these models are that they are inconsistent, several factors of those models are not monitored in the plant, and their measurement would be quite challenging at the industrial scale. It has been well-documented that artificial intelligence (AI) systems play a key role in sustainable development15. AI models can solve complex problems that are frequently complicated to explain or visualize with human intelligence. Thus, using AI systems to model various mechanisms during grinding and understanding interactions could be essential in modifying energy and enhancing green production. However, there are quite a few investigations on AI modeling tumbling mills.
Tohry et al. (2020) applied Random Forest (RF) and its variable importance measurement to model the power draw of an industrial ball mill (used in a mineral processing plant). As a machine learning tool, they indicated that RF could accurately model the ball mill’s power draw and show the potential interactions within the plant’s monitored parameters16. As a most recent approach, the conscious lab (CL) concept has also been applied to model the ventilation of a cement industrial ball mill. CL is an AI structure that uses various explainable AI “EAI” to model interaction within industrial variables (using monitoring databases that come from plants). Using the CL approach, laboratory costs and scale-up challenges will be minimized, the process can be optimized, and personnel can be trained based on the process realities. The CL concept with different structures has successfully been applied to model complex problems17,18,19,20,21. Fatahi et al. (2021) indicated that a Boosted Neural Network with a CL structure could model relationships between ventilation variables and process parameters22. Few studies have been conducted in modeling with artificial intelligence algorithms in the context of cement and its processes. Fatahi et al. used the XGBoost algorithm on a raw material vertical roller mill in the cement industry; they found that the key factors influencing energy consumption include working pressure, input gas rate, and the superiority of XGBoost over other conventional modeling approaches was evident17. Another study developed a conscious-lab model using SHapley Additive exPlanations (SHAP)-XGBoost to accurately predict rotary kiln factors in a cement plant, demonstrating improved performance over typical explainable AI models19. A soft sensor was developed using Bayesian regularization and historical data to accurately predict raw meal fineness in a cement plant’s vertical roller mill, addressing material heterogeneity and outperforming other models23. Non-linear models, especially NARX networks, significantly outperformed linear models in system modeling. This led to the proposal of a neurocontroller expert system to enhance the quality, simplicity, and efficiency of the cement grinding process control24. A novel L/S-ConvGRU soft sensor model was developed to accurately predict cement surface area, outperforming traditional methods by effectively handling complex industrial data and improving prediction accuracy.
Nevertheless, no investigation addressed intercorrelations within the operating variables of a cement ball mill with their representative energy consumption parameters. To fill the gap, this study, with a novel approach, was structured as a CL by examining various machine learning methods (RF, support regression machine (SVR), Convolutional Neural Network (CNN), and extreme gradient boosting (XGB), and CatBoost (CB)). As an advanced EAI tool, SHAP and Pearson correlation were used to explore the potential interaction between model input variables and the mill energy consumption parameters (motor currents and main elevator current).
Materials and methods
Dataset
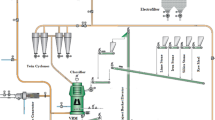
The data were provided from the monitoring section of the clinker ball mill in closed circuits from line 1 of the Ilam cement plant in Ilam (west of Iran) (Fig. 1). The plant has two cement production lines that produce 5300 TPD cement. The clinker and gypsum enter the mill by a conveyor belt to be ground into a fine powder as cement and transported by bucket elevator to cement silo storage. Almost 4% of gypsum is added during the grinding to control the setting properties of the produced cement. The ball mill has a double drive whose nominal power of each drive is 1750 KW. It also has two compartments (1sth: coarse grinding and 2nd: fine grinding), a 4.20 m diameter, and a 13 m length with 80 t/h capacity (made by PSP Company from Pˇrerov, Czechia). The mill’s rotation speeds are usually constant (15 rpm), and there is approximately a fixed one-year period of changing liners and charging the grinding media. Table 1 summarizes the critical operating parameters collected during standard operation. The data set includes two types of variables: manipulable variables and controlled variables. Manipulable variables are those set by the operator and are referred to as set points. Controlled variables include the responses of various actuators in the grinding circuit and are related to the manipulable variables. In this study, over 2600 records were recorded in the control room under different operational conditions to ensure the reliability of the data, as they are real-world industrial system data recorded with high frequency (2600 times, once per hour). The data set related to the manipulable variables, such as Separator Flap, Total Feed Rate, EP Fan Flap, and Separator Speed, were recorded as input parameters. In contrast, other variables were recorded as output parameters.

Schematic of cement ball mill circuit, and sensors for monitoring variables.
Air Lift Current (A) is the current draw of the motor for the airlift, which is directly related to the mill output rate of material and the total feed rate. Mill Output Temperature (˚C) is the outlet temperature of the mill and indicates the temperature of the cement produced. Ventilation after mill (mbar) is the ventilation after the mill. Ventilation before the electrostatic precipitator (EP) Fan (mbar) shows the suction leading to the EP fan, depending on the position of the EP fan flap. EP ΔP (mbar) is the pressure difference before and after the electro filter. EP Fan Flap (%) is the position of the EP flap that is adjusted based on the required suction. Separator Flap (%) is the position of the separator flap, which is the amount of air needed to separate the materials inside the air separator.
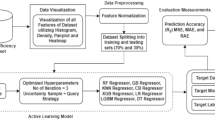
Separator speed (rpm) is the rotation speed of the separator that is adjusted to achieve the required particle size distribution. The separator motor current (A) is the current draw of the separator motor. Separator fan current (A) is the current draw of the motor’s separator fan. This fan provides the air required for separation, and the position of the separator flap depends on it. Total feed rate: The aggregate tonnage of clinker and gypsum is the mill’s feed rate. All data, including power data recorded in this study regarding current intensity, are derived from the actuators (motors) performance response, which are sent online to the control room through the plant’s control system. Power data are visible to mill operators in the control room in real-time and online. In this study, during various operational conditions over the monitoring and measurement period, power data were recorded by the control room’s monitoring system. Variables were monitored hourly. After cleaning and removing missing data and outliers, 2499 cleaned data points were used for modeling. The flowchart of the methodology used to model energy consumption indexes of the industrial cement ball mill is shown in Fig. 2.

The flowchart of the proposed methodology.
Machine learning methods
SHapley Additive exPlanations (SHAP)
Shapley Additive Explanations (SHAP) is a groundbreaking method in machine learning interpretability that provides valuable insights into the predictions of complex models. Developed by Lundberg and Lee25, SHAP leverages Shapley values from cooperative game theory to explain the contribution of each feature to the model’s output. By computing the average marginal contributions of all feature permutations, SHAP quantifies the impact of individual features on the prediction, offering a comprehensive understanding of the model’s decision-making process26. This unique approach enables users to interpret black-box models and gain insights into the factors driving the predictions, enhancing transparency and trustworthiness in machine-learning applications27.
SHAP provides local and global explanations for model predictions, allowing users to understand the importance of each feature at the instance level and across the entire dataset. By decomposing the model’s output into contributions from individual features, SHAP offers a nuanced view of how each input variable influences the prediction, enabling users to identify critical factors and assess the model’s behavior comprehensively. The interpretability provided by SHAP enhances the transparency of machine learning models and facilitates model debugging, feature engineering, and decision-making processes28,29.
SHAP can provide meaningful insights into the model’s inner workings and highlight areas for optimization and refinement. By visualizing feature importance, interaction effects, and prediction explanations, SHAP empowers users to make informed decisions, validate model assumptions, and enhance the interpretability of complex machine learning systems. Mathematically speaking, the output is expressed as the summation of the input features of the model, multiplied by the corresponding SHAP values as follows:
where \(f\) represents the mapping function represented by the machine learning model; \(N\) is the number of input features; \({\varphi }_{0}\) denotes the average of all predictions; \({\varphi }_{i}\) is the SHAP value for the i-th attribute; and \({X}_{i}{\prime}\) represents the coalition vector for the i th component, which can be calculated from the original input \({X}_{i}\) using a mapping function expressed as \({X}_{i}={h}_{x} \left({X}_{i}{\prime}\right)\)30,31,32.
Categorical Boosting (CatBoost)
CatBoost33, short for Categorical Boosting, is a robust implementation of Gradient Boosted Decision Trees (GBDT) that significantly refines the traditional GBDT technique. One of the key strengths of CatBoost lies in its efficient handling of high cardinality categorical variables. Unlike popular GBDT techniques such as XGBoost and LightGBM, CatBoost utilizes a unique approach to dealing with categorical features, particularly those with high repeatability. CatBoost can effectively process categorical features without extensive memory and computational resources by employing modified target-based statistics during training. This feature sets CatBoost apart in GBDT algorithms, making it a preferred choice for datasets with sparse or infrequently occurring categorical variables34.
Furthermore, CatBoost introduces novel techniques such as Ordered Target statistics and Ordered Boosting to enhance the performance and accuracy of gradient boosting models. By iterating through random permutations of the dataset, CatBoost ensures that specific training examples are appropriately utilized for encoding categorical components and estimating the rate of change of the loss function. This systematic approach, as highlighted by Hancock and Khoshgoftaar35, not only improves the model’s ability to handle sparse or infrequently occurring categorical variables but also helps reduce variance in estimates, thereby enhancing the overall predictive capabilities of the algorithm.
Moreover, CatBoost’s emphasis on level-wise tree growth and symmetric trees is pivotal in optimizing the model’s predictive power. By employing a consistent feature selection strategy at each level of tree growth, CatBoost ensures a balanced and efficient tree structure, contributing to improved model performance. The algorithm’s capability to handle categorical features without manual preprocessing and efficiently handle high cardinality categorical variables make CatBoost a versatile and powerful tool for various machine learning tasks. The innovative features and optimizations offered by CatBoost position it as a leading choice for practitioners seeking advanced boosting algorithms with categorical feature support33,34. CatBoost can identify the input features’ relative importance in making predictions. The importance of a feature within a single decision tree is calculated as follows:
where \(N\) represents the total number of trees or iterations the algorithm is executed. The value \({J}_{j}^{2}\) indicates each feature’s overall significance or importance across the model36.
Extreme Gradient Boosting (XGBoost)
Extreme Gradient Boosting (XGBoost) is a cutting-edge machine learning algorithm that has gained widespread popularity for its exceptional performance in various predictive modeling tasks. Developed by Tianqi Chen and Carlos Guestrin37, XGBoost is an optimized implementation of gradient boosting that leverages parallel tree boosting to solve classification and regression problems efficiently. By incorporating regularization techniques such as L1 regularization (Lasso) and L2 regularization (Ridge), XGBoost enhances model generalization and prevents overfitting, leading to more robust and accurate predictions38,39,40,41. The algorithm’s ability to handle large datasets, high-dimensional feature spaces, and diverse data types makes it a primary choice for data scientists and machine learning practitioners across different industries.
XGBoost is highly stable and proficient at effectively managing outliers and noisy data, which is one of its notable advantages. XGBoost’s regularization methods and ensemble learning approach help mitigate the impact of outliers on the model’s performance, ensuring reliable predictions even in noisy or incomplete data. Additionally, XGBoost’s parallel processing capabilities enable efficient training and prediction on large datasets, making it well-suited for real-world applications where scalability and speed are crucial42,43. The algorithm’s low bias and variance and its robustness to outliers contribute to its superior performance compared to traditional machine learning methods, especially in scenarios with complex data patterns and diverse input features39.
Furthermore, XGBoost provides a comprehensive framework for hyperparameter tuning and model optimization, allowing users to fine-tune the algorithm’s parameters to achieve the best possible performance. Experts can optimize the model’s predictive accuracy and generalization capabilities by systematically exploring different hyperparameter configurations. Overall, XGBoost is a versatile and powerful machine learning tool that handles complex datasets, delivers high predictive accuracy, and provides valuable insights for data-driven decision-making. The objective function used by XGBoost has two main parts: a convex loss function and a regularization term as follows:
where \(L\left(\cdot \right)\) is the loss function and \(\Omega \left(\theta \right)=\gamma T+\frac{1}{2}\lambda {\Vert w\Vert }^{2}\) is a regularization function. The regularization function \(\Omega \left(\theta \right)\) has two components—a term \(\gamma T\) that penalizes the number of leaf nodes \(T\) in the model, and a term \(\frac{1}{2}\lambda {\Vert w\Vert }^{2}\) that penalizes the magnitude of the weights \(w\) associated with each leaf node. The parameters \(\gamma\) and \(\lambda\) control the strength of these respective penalties, allowing the model complexity to be regulated44,45.
Random forest
Random Forest (RF) is a versatile and powerful ensemble machine learning algorithm widely used for classification and regression tasks. Developed by Leo Breiman46, RF is based on the concept of decision trees and operates by constructing a multitude of decision trees during the training phase. Each tree in the ensemble is built using a random subset of the features and a bootstrapped sample of the training data. This randomness helps to decorate the individual trees, leading to a diverse set of predictors that collectively form a robust and accurate model. RF’s ability to handle high-dimensional data and large feature spaces makes it a popular choice in various domains47,48,49.
RF can reduce overfitting and improve generalization performance. By aggregating the predictions of multiple decision trees, RF can mitigate the high variance often associated with individual trees, resulting in a more stable and reliable model. Additionally, RF is known for its robustness to outliers and noisy data, making it suitable for real-world applications where data quality may vary. The ensemble nature of RF also allows it to capture complex relationships in the data and make accurate predictions, even in the presence of noise and uncertainty50,51. Using an input feature vector \(x={\left[{x}_{1},{x}_{2},\ldots ,{x}_{n}\right]}^{T}\), the RF method calculates the output \(\widehat{\tau }\left(x\right)\) as follows:
where \(B\) is the total number of trees and \({\widehat{\tau }}_{b}\left(x\right)\) represents the estimate given by the b th tree20,52,53.
Support Vector Regression
Support Vector Regression (SVR) is a powerful supervised machine learning method designed explicitly for regression problems. Like Support Vector Machines (SVM) for classification, SVR aims to minimize the generalization error bound rather than focusing solely on minimizing the training error54. This approach makes SVR particularly effective in handling complex nonlinear relationships between input and output variables. By mapping observations into a higher-dimensional feature space through nonlinear transformations, SVR can capture intricate patterns in the data and provide accurate predictions55.
One of the key advantages of SVR is its high generalization capability and robustness to outliers. Unlike traditional regression methods, SVR is not heavily influenced by outliers in the dataset, making it suitable for real-world applications where data may contain noise or anomalies. Additionally, SVR exhibits low computational complexity in high-dimensional spaces, meaning that its performance does not degrade as the dimensionality of the input space increases. This scalability makes SVR a versatile tool for efficiently handling large and complex datasets56,57.
Furthermore, SVR is known for its ability to obtain a global solution, which ensures the model’s stability and reliability across different datasets. By optimizing the parameters of the linear function using a regularization parameter and slack variables, SVR can effectively balance the trade-off between model complexity and prediction accuracy. This feature makes SVR a popular choice in various fields, including geosciences, engineering, and finance, where accurate predictions and robust models are essential for decision-making and problem-solving58,59. SVR employs the following function to address the regression problem:
where w is the weight of the matrix, \(\varphi (x)\) denotes the multidimensional space comprising the input vector x, and b represents the bias19,60.
Convolutional Neural Network
Convolutional Neural Networks (CNNs) have emerged as a powerful tool in deep learning, particularly in image processing and computer vision. These networks are designed to mimic the visual processing of the human brain, making them highly effective in tasks such as image recognition, segmentation, and classification. CNNs consist of neurons with learnable weights and biases, organized into multiple layers that enable the network to learn complex features from input data. One of the key distinguishing features of CNNs is their ability to leverage the spatial structure of data through convolutional layers, which extract features by applying filters across the input data. This process allows CNNs to capture hierarchical patterns and relationships within data61,62.
The architecture of a CNN typically includes convolutional layers followed by pooling layers and fully connected layers. Convolutional layers use filters to convolve over the input data, extracting features at different spatial locations. Pooling layers then downsample the feature maps, reducing the computational complexity while retaining important information. The fully connected layers at the network’s end combine the extracted features to make predictions or classifications. Through back-propagation, CNNs are trained on labeled datasets to adjust their weights and biases iteratively, optimizing their performance on specific tasks. This training process allows CNNs to learn to recognize patterns and features in the data, enabling them to generalize well to unseen examples and make accurate predictions63,64.
Results and discussion
Prediction
From the entire database, 70, 15, and 15% of the records were randomly split for various examined AI models’ training, validation, and testing phases (respectively). The considered machine learning models were tuned (Table 2), and their optimum hyperparameter values were adjusted through a try-and-error system using the Grid Search method. Moreover, the validation set was used to avoid overfitting and improve the models’ generalization. The results of AI models (Table 3) indicated that XGBoos and CatBoost had the highest accuracy within the examined model; however, exploring the model errors (Fig. 3) highlighted that CatBoost was the most accurate model for predicting the energy consumption factors. Moreover, to evaluate whether the superiority of CatBoost was statistically significant, a two-tailed Welch’s t-test with a significance level \(\alpha =0.05\) was applied for RMSE of the test set between CatBoost and other methods. Welch’s t-test is a nonparametric univariate statistical test used when the two samples have unequal variances65. The last column of Table 3 shows the p value of the two-tailed Welch’s t-test. As can be seen, in all comparisons, the null hypothesis is clearly rejected based on the tests with a 95% confidence level (p value < 0.05), giving statistically significant results.

Variation between actual and predicted the cement ball mill’s energy consumption factors.
According to Eq. 6, the power measured in kw directly relates to the current. Here, I is the current (A), V is the voltage (V), and cos φ is the power factor, equal to 0.88 in the cement production at the Ilam cement plant17.
If the value \(\sqrt{3} VCos\varphi\) is considered constant (C). Power can be expressed as in Eq. 7.
As can be seen, power has a direct relationship with current. Therefore, predicting the current directly depends on the power and energy consumed.
Generally, when comparing these models, it can be mentioned that ensemble methods such as RF, XGBoost, and CatBoost combine the predictions of multiple base models, often resulting in higher accuracy than individual models. RF is a bagging model, whereas XGBoost and CatBoost employ boosting techniques, necessitating less complex feature engineering. XGBoost confronts challenges, including prediction shift and gradient boosting bias, while CatBoost mitigates prediction shift through its ordered boosting methodology. Moreover, it circumvents gradient-boosting biases by employing oblivious Decision Trees and applying a consistent splitting criterion across all tree levels20,66. CNNs can leverage the spatial structure of data through convolutional layers, which extract features by applying filters across the input data. This process allows CNNs to capture hierarchical patterns and complex nonlinear relationships within data; however, they are computationally intensive and require substantial resources for training. CNNs typically require large amounts of data for effective training. SVR encounters limitations due to its kernel function. Notably, empirical findings from prior studies20,67,68,69,70 indicated the superior performance of CatBoost over alternative machine learning techniques such as SVR, RF, and XGBoost in regression tasks.
Intercorrelations-SHAP
SHAP and Pearson’s correlation explored relationships between operating variables and the mill’s energy consumption representative factors modeled by CatBoost. Such an assessment helps to understand which factors have the highest importance and impact on energy consumption and the magnitude of their relationship. Based on the SHAP value (Fig. 4), the separator motor current has the highest effectiveness on the main elevator current. They showed a positive correlation. The airlift current had the highest negative interaction with the main elevator current, which decreased with the airlift current increase. The airlift current also showed the highest effectiveness on both ball mill energy consumption (Fig. 5). By increasing the airlift current, the motor current decreased (negative SHAP value on average). The magnitude of interactions between operating variables and motor currents was the same for both motors. However, the ranking of variables was slightly different.

SHAP value of the operating variables for their correlation with the main elevator current.

SHAP value of the operating variables for their correlation with the main motor current.
Exploring interactions between energy consumption indexes (Fig. 6) indicated a positive correlation (r: 0.62) between motor currents with quite a high confidence level (p value ≤ 0.001). Such a correlation would be the main reason that mainly all operating variables showed the same magnitude of interactions with the motor 1 and 2 currents (Fig. 5). The main elevator current also had a negative correlation (r: ~ − 0.36; p value ≤ 0.001) with motor currents highlighted that by increasing the motor currents, the main elevator current was decreasing.

Pearson correlation between operating variables.
The Pearson correlation assessment (Fig. 6) also showed several significant intercorrelations within various operating variables. For example, the ventilation after the mill demonstrated a significant positive interaction with the EP fan flap, and the separator flap had a significant positive interaction with the separator motor current. Generally, through cement grinding in a closed ball mill circuit, the mill discharge is conveyed by a bucket elevator to a separator. With control of the power (current) of the bucket elevator, the mill supply rate is adjusted to achieve the target power value. Coarse material as rejects are re-circulated to the inlet mill for further grinding, and the fine product is vented directly to the EP by airlift71. The airlift conveyor comprises a vertical cylindrical pressure vessel with an aeration pad at the bottom and conveying air nozzle passing upwards through the center of the pad. The quantity of material conveyed increases with vessel filling height, and blower pressure is a surrogate for material flow rate3. In the air separator, the separator speed and airflow at inlet and outlet separation are effective in the particle size distribution of the product because centrifuges and gravity forces carry out separation, as well as the interaction of drag forces72. Measuring the power or current of a mill motor is the most straightforward way to control the load of a mill73. The mill main motor is monitored for its current and power, as these parameters indicate the mill fill level72. Measuring the power or current of a mill motor is the most straightforward way to control the load of a mill73. The mill main motor is monitored for its current and power, as these parameters indicate the mill fill level72.
During grinding in a closed circuit, the relation between the current motor of the elevator and the reject material of the separator provides information on the amount of material exiting the mill outlet, and the rejected material indicates the amount of material recycled to the mill or the final product to the silo. Separator speed influences energy consumption because significant changes in the separator speed are required to improve the particle size distribution1,74. The cut size of the separator is the critical control parameter and is mainly controlled by separator speed75. The ball mill’s main motor and elevator power lift the grounded material to the separator. The elevator power is the measure of the mill load, while the main drive load is the measure of the dynamical part of the mill load due to the material’s residence inside the mill76. The product flow rate can be changed by changing the power of the separator fan. Hence, it increases the power drawing of the separator fan, causes an increase in the product flow rate, and affects the PSD of the product and separator speed76. The power consumption of the mill motor (current) indicates the operating conditions in the tube mill, such as the total material level, the condition of the grinding media and liner, system variables, and circulating load77. All these interactions were evaluated and ranked by SHAP-Pearson and through the conscious lab structure.
The main elevator current of the mill, located at the mill’s output, indicates the rate of the powdered product exiting the mill. As mentioned earlier, it is directly related to the power consumption of the elevator. SHAP analysis highlighted the ranking of two variables, airlift current and separator motor current, in predicting the current of the main elevator, emphasizing the significance of key energy factors in the mill grinding circuit. Through operator training in cement plants, these findings can serve as a knowledge-based strategy to help mill operators better understand and make more logical decisions during mill operations. The result of such decisions is the optimization and reduction of energy consumption.
Conclusion
A conscious lab structure for assessing and modeling energy consumption indexes of a closed ball mill circuit for a cement plant based on monitoring operating variables was implemented as an innovative approach to understanding interactions within the process, decreasing randomness, and managing energy consumption. Considering various advanced AI models indicated that AI methods could accurately model the ball mill energy consumption factors. Catboost, as one of the most recent machine-learning methods, showed the highest accuracy and could predict the motor and elevator current with the lowest RMSE (< 3.5) and highest coefficient of determination (R2 < 0.90). Exploring the interactions and conducting variable importance measurements (SHAP-Pearson correlations) within operating variables to assess their effectiveness in predicting energy consumption indexes highlighted significant correlations within the energy consumption indexes, meaning monitoring and controlling could be implemented on one of them. SHAP results indicated that the airlift current, separator speed, and current were the most effective operating variables. However, certain limitations must be acknowledged. This study relied on available operational data, which, while extensive, may not fully capture all underlying complexities of the cement milling process. Potential biases in data collection, measurement errors, or missing variables could affect model generalizability. Additionally, AI models, including CatBoost and SHAP, may have challenges interpreting feature interactions for highly non-linear relationships. Future research should explore integrating additional data sources, such as sensor fusion and real-time monitoring, to enhance model robustness and improve predictions. In general, the modeling outcomes of this study indicated that SHAP-CatBoost as a robust structure could be applied to generating conscious labs dedicated to energy consumption and advantage sustainable production.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Hosten, C. & Fidan, B. An industrial comparative study of cement clinker grinding systems regarding the specific energy consumption and cement properties. Powder Technol. 221, 183–188 (2012).
Bouchard, J., LeBlanc, G., Levesque, M., Radziszewski, P. & Georges-Filteau, D. Breaking down energy consumption in industrial grinding mills. CIM J. 10, 157–164 (2019).
Alsop, P. A. Cement Plant Operations Handbook: For Dry Process Plants (Tradeship Publications Ltd, 2007).
Sahoo, N. & Kumar, A. others: Review on energy conservation and emission reduction approaches for cement industry. Environ. Dev. 44, 100767 (2022).
Hecht, H. M. & Derick, G. R. A low cost automatic mill load level control strategy. In Proceedings of 38th Cement Industry Technical Conference, 341–349 (1996).
Soleymani, M. M., Fooladi, M. & Rezaeizadeh, M. Experimental investigation of the power draw of tumbling mills in wet grinding. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 230, 2709–2719 (2016).
Heath, A., Keikkala, V., Paz, A. & Lehto, H. A power model for fine grinding HIGmills with castellated rotors. Miner. Eng. 103, 25–32 (2017).
Bbosa, L. S., Govender, I. & Mainza, A. Development of a novel methodology to determine mill power draw. Int. J. Miner. Process. 149, 94–103 (2016).
Bbosa, L. S., Govender, I., Mainza, A. N. & Powell, M. S. Power draw estimations in experimental tumbling mills using PEPT. Miner. Eng. 24, 319–324 (2011).
Datta, A. & Mishra, B. K. Power draw estimation of ball mills using neural networks. Min. Metall. Explor. 16, 57–60 (1999).
Powell, M. S. & Nurick, G. N. A study of charge motion in rotary mills Part 3—Analysis of results. Miner. Eng. 9, 399–418 (1996).
Fatahi, R. & Barani, K. Modeling and simulation of vertical roller mill using population balance model. Physicochem. Probl. Miner. Process. 56, 24–33 (2020).
Barani, K., Azadi, M. R. & Fatahi, R. An approach to measuring and modelling the residence time distribution of cement clinker in vertical roller mills. Miner. Process. Extr. Metall. 131, 158–165 (2022).
Fatahi, R., Pournazari, A. & Shah, M. P. A cement Vertical Roller Mill modeling based on the number of breakages. Adv. Powder Technol. 33, 103750 (2022).
Goralski, M. A. & Tan, T. K. Artificial intelligence and sustainable development. Int. J. Manag. Educ. 18, 100330 (2020).
Tohry, A., Chelgani, S. C., Matin, S. S. & Noormohammadi, M. Power-draw prediction by random forest based on operating parameters for an industrial ball mill. Adv. Powder Technol. 31, 967–972 (2020).
Fatahi, R., Nasiri, H., Dadfar, E. & Chehreh Chelgani, S. Modeling of energy consumption factors for an industrial cement vertical roller mill by SHAP-XGBoost: a “conscious lab” approach. Sci. Rep. 12, 7543. https://doi.org/10.1038/s41598-022-11429-9 (2022).
Chehreh Chelgani, S., Nasiri, H. & Tohry, A. Modeling of particle sizes for industrial HPGR products by a unique explainable AI tool- A “Conscious Lab” development. Adv. Powder Technol. 32, 4141–4148. https://doi.org/10.1016/j.apt.2021.09.020 (2021).
Fatahi, R. et al. Modeling operational cement rotary kiln variables with explainable artificial intelligence methods—A “conscious lab” development. Part. Sci. Technol. 41, 715–724. https://doi.org/10.1080/02726351.2022.2135470 (2023).
Chehreh Chelgani, S., Nasiri, H., Tohry, A. & Heidari, H. R. Modeling industrial hydrocyclone operational variables by SHAP-CatBoost—A “conscious lab” approach. Powder Technol. 420, 118416. https://doi.org/10.1016/j.powtec.2023.118416 (2023).
Tohry, A., Yazdani, S., Hadavandi, E., Mahmudzadeh, E. & Chelgani, S. C. Advanced modeling of HPGR power consumption based on operational parameters by BNN: A “Conscious-Lab” development. Powder Technol. 381, 280–284 (2021).
Fatahi, R. et al. Ventilation prediction for an industrial cement raw ball mill by BNN—A “conscious lab” approach. Materials (Basel) 14, 3220 (2021).
Belmajdoub, F. & Abderafi, S. Efficient machine learning model to predict fineness, in a vertical raw meal of Morocco cement plant. Results Eng. 17, 100833 (2023).
Pawuś, D. & Paszkiel, S. Identification and expert approach to controlling the cement grinding process using artificial neural networks and other non-linear models. IEEE Access 12, 26364–26383 (2024).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 30, 4765–4774 (2017).
Parsa, A. B., Movahedi, A., Taghipour, H., Derrible, S. & Mohammadian, A. K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 136, 105405 (2020).
Wen, X., Xie, Y., Wu, L. & Jiang, L. Quantifying and comparing the effects of key risk factors on various types of roadway segment crashes with LightGBM and SHAP. Accid. Anal. Prev. 159, 106261 (2021).
Mangalathu, S., Shin, H., Choi, E. & Jeon, J.-S. Explainable machine learning models for punching shear strength estimation of flat slabs without transverse reinforcement. J. Build. Eng. 39, 102300 (2021).
Mao, H. et al. Driving safety assessment for ride-hailing drivers. Accid. Anal. Prev. 149, 105574 (2021).
Chehreh Chelgani, S., Nasiri, H. & Alidokht, M. Interpretable modeling of metallurgical responses for an industrial coal column flotation circuit by XGBoost and SHAP-A “conscious-lab” development. Int. J. Min. Sci. Technol. 31, 1135–1144. https://doi.org/10.1016/j.ijmst.2021.10.006 (2021).
Zhou, K. et al. Data-driven prediction and analysis method for nanoparticle transport behavior in porous media. Measurement 172, 108869 (2021).
Bussmann, N., Giudici, P., Marinelli, D. & Papenbrock, J. Explainable machine learning in credit risk management. Comput. Econ. 57, 203–216 (2021).
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 31 (2018)
Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv preprint, arXiv:1810.11363 (2018)
Hancock, J. T. & Khoshgoftaar, T. M. CatBoost for big data: an interdisciplinary review. J. Big data. 7, 1–45 (2020).
Zeng, H., Shao, B., Dai, H., Yan, Y. & Tian, N. Prediction of fluctuation loads based on GARCH family-CatBoost-CNNLSTM. Energy 263, 126125 (2023).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785–794 (2016)
Yun, K. K., Yoon, S. W. & Won, D. Prediction of stock price direction using a hybrid GA-XGBoost algorithm with a three-stage feature engineering process. Expert Syst. Appl. 186, 115716 (2021).
Huang, J.-C. et al. Predictive modeling of blood pressure during hemodialysis: a comparison of linear model, random forest, support vector regression, XGBoost, LASSO regression and ensemble method. Comput. Methods Programs Biomed. 195, 105536 (2020).
Nasiri, H., Homafar, A. & Chehreh Chelgani, S. Prediction of uniaxial compressive strength and modulus of elasticity for Travertine samples using an explainable artificial intelligence. Results Geophys. Sci. 8, 100034. https://doi.org/10.1016/j.ringps.2021.100034 (2021).
Gómez-Ríos, A., Luengo, J. & Herrera, F. A study on the noise label influence in boosting algorithms: AdaBoost, GBM and XGBoost. In International Conference on Hybrid Artificial Intelligence Systems, 268–280 (2017)
Movsessian, A., Cava, D.G., & Tcherniak, D. 'Interpretable machine learning in damage detection using Shapley Additive Explanations’, ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part B: Mechanical Engineering. https://doi.org/10.1115/1.4053304 (2021).
Qiu, Y., Zhou, J., Khandelwal, M., Yang, H., Yang, P. & Li, C. Performance evaluation of hybrid WOA-XGBoost, GWO-XGBoost and BO-XGBoost models to predict blast-induced ground vibration. Eng. Comput. 1–18 (2021).
Jiang, F., Yang, J., Cheng, Y., Zhang, X., Yang, Y., Gao, K., Peng, J. & Huang, Z. An aging-aware soc estimation method for lithium-ion batteries using xgboost algorithm. In 2019 IEEE International Conference on Prognostics and Health Management (ICPHM) 1–8 (2019).
Ma, J. et al. Analyzing the leading causes of traffic fatalities using XGBoost and grid-based analysis: a city management perspective. IEEE Access 7, 148059–148072 (2019).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Hou, S., Liu, Y. & Yang, Q. Real-time prediction of rock mass classification based on TBM operation big data and stacking technique of ensemble learning. J. Rock Mech. Geotech. Eng. (2021)
Gong, H., Sun, Y., Shu, X. & Huang, B. Use of random forests regression for predicting IRI of asphalt pavements. Constr. Build. Mater. 189, 890–897 (2018).
Ouallouche, F., Lazri, M. & Ameur, S. Improvement of rainfall estimation from MSG data using Random Forests classification and regression. Atmos. Res. 211, 62–72 (2018).
Scornet, E. et al. Consistency of random forests. Ann. Stat. 43, 1716–1741 (2015).
Wager, S. & Athey, S. Estimation and inference of heterogeneous treatment effects using random forests. J. Am. Stat. Assoc. 113, 1228–1242 (2018).
Bühlmann, P. et al. Analyzing bagging. Ann. Stat. 30, 927–961 (2002).
Farzipour, A., Elmi, R. & Nasiri, H. Detection of Monkeypox cases based on symptoms using XGBoost and shapley additive explanations methods. Diagnostics 13, 2391. https://doi.org/10.3390/diagnostics13142391 (2023).
Premalatha, M. & Lakshmi, C. V. SVM trade-off between maximize the margin and minimize the variables used for regression. Int. J. Pure Appl. Math. 87, 741–750 (2013).
Lawal, A. I. & Kwon, S. Application of artificial intelligence to rock mechanics: An overview. J. Rock Mech. Geotech. Eng. 13, 248–266 (2021).
Awad, M. & Khanna, R. Support vector regression. In Efficient learning machines, 67–80. (Springer, 2015).
Wolff, B. Support vector regression for solar power prediction. Fakultät II– Informatik, Wirtschafts- und Rechtswissenschaften Department für Informatik. Dissertation zur Erlangung des Grades, eines Doktors der Naturwissenschaften (Dr. rer. nat.), M.Sc. geboren am 30.12.1985 in Nordhorn Oldenburg, den 12. April 2017 (2017).
Zhang, D. et al. Modeling and simulating of reservoir operation using the artificial neural network, support vector regression, deep learning algorithm. J. Hydrol. 565, 720–736 (2018).
Peng, Y., Albuquerque, P. H. M., de Sá, J. M. C., Padula, A. J. A. & Montenegro, M. R. The best of two worlds: Forecasting high frequency volatility for cryptocurrencies and traditional currencies with Support Vector Regression. Expert Syst. Appl. 97, 177–192 (2018).
Homafar, A., Nasiri, H. & Chehreh Chelgani, S. Modeling coking coal indexes by SHAP-XGBoost: Explainable artificial intelligence method. Fuel Commun. 13, 100078. https://doi.org/10.1016/j.jfueco.2022.100078 (2022).
Jia, Y., Kaul, C., Lawton, T., Murray-Smith, R. & Habli, I. Prediction of weaning from mechanical ventilation using convolutional neural networks. Artif. Intell. Med. 117, 102087 (2021).
Huo, W. et al. Performance prediction of proton-exchange membrane fuel cell based on convolutional neural network and random forest feature selection. Energy Convers. Manag. 243, 114367 (2021).
Zhang, Z. et al. A haze prediction method based on one-dimensional convolutional neural network. Atmosphere (Basel) 12, 1327 (2021).
Wang, C., Xiong, R., Tian, J., Lu, J. & Zhang, C. Rapid ultracapacitor life prediction with a convolutional neural network. Appl. Energy. 305, 117819 (2022).
Nasiri, H. & Ebadzadeh, M. M. MFRFNN: Multi-functional recurrent fuzzy neural network for chaotic time series prediction. Neurocomputing 507, 292–310. https://doi.org/10.1016/j.neucom.2022.08.032 (2022).
Ibrahim, A.A., Ridwan, R.L., Muhammed, M.M., Abdulaziz, R.O. & Saheed, G.A. Comparison of the CatBoost classifier with other machine learning methods. Int. J. Adv. Comput. Sci. Appl. 11 (2020)
Chelgani, S.C. et al. Study Relationship between Inorganic and Organic Coal Analysis with Gross Calorific Value by Multiple Regression and ANFIS. Int. J. Coal Prep. Utilization. 31(1), (2011).
Luo, M. et al. Combination of feature selection and catboost for prediction: The first application to the estimation of aboveground biomass. Forests 12, 216 (2021).
Yu, J., Chang, X., Hu, S., Yin, H. & Wu, J. Combining travel behavior in metro passenger flow prediction: A smart explainable Stacking-Catboost algorithm. Inf. Process. Manag. 61, 103733 (2024).
Li, Y. et al. Research on prediction model of iron ore powder sintering foundation characteristics based on FOA-Catboost algorithm. Alex. Eng. J. 86, 603–615 (2024).
Hamdani, R. Ball mill driven with gearless mill drive. In 2000 IEEE-IAS/PCA Cement Industry Technical Conference. Conference Record (Cat. No. 00CH37047), 55–68 (2000).
Andreatta, K., Apóstolo, F. & Nunes, R. Soft sensor for online cement fineness predicting in ball mills. In International Seminar of Science and Applied Technology (ISSAT 2020), 422–428 (2020).
Melero, M. G. et al. Electric motors monitoring: An alternative to increase the efficiency of ball mills. Renew. Energy Power Qual. J. 1, 849–854 (2014).
Lepore, R., Wouwer, A. V. & Remy, M. Modeling and predictive control of cement grinding circuits. IFAC Proc. 35, 43–48 (2002).
Duda, W. H. Cement--Data--Book International Process Engineering in Cement Industry, French and European Pubns; ISBN: 0828802041, 3 (1985)
Sivanandam, V., Kannan, R., Srinivasan, S. & Muralidharan, G. Data driven models for cement grinding circuit. Int. J. Adv. Intell. Paradig. 9, 414–435 (2017).
Oseni, M. I., Okon, N. E. & Ager, P. Tribological processes in a ball mill for ordinary portland cement production. Aust. J. Basic Appl. Sci. 5, 360–365 (2011).
Acknowledgements
This manuscript resulted from a project financially supported by CAMM3, the Center of Advanced Mining and Metallurgy, a center of excellence at the Luleå University of Technology, Sweden, and the WISE-WASP project.
Funding
Open access funding provided by Lulea University of Technology.
Author information
Authors and Affiliations
Contributions
S. C: Supervision, Foundation, Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Writing—original draft, Writing—review & editing, R. F.: Conceptualization, Methodology, Validation, Resources, Writing—original draft, H. N.: Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Writing—original draft, Writing—review & editing. A. P.: Conceptualization, Validation, Formal analysis, Resources.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chehreh Chelgani, S., Fatahi, R., Pournazari, A. et al. Modeling energy consumption indexes of an industrial cement ball mill for sustainable production. Sci Rep 15, 18514 (2025). https://doi.org/10.1038/s41598-025-03232-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-03232-z
