
Abstract
Accurate detection of surface defects on strip steel is essential for ensuring strip steel product quality. Existing deep learning based detectors for strip steel surface defects typically strive to iteratively refine and integrate the coarse outputs of the backbone network, enhancing the models’ ability to express defect characteristics. Attention mechanisms including spatial attention, channel attention and self-attention are among the most prevalent techniques for feature extraction and fusion. This paper introduces an innovative triple-attention mechanism (TA), characterized by interrelated and complementary interactions, that concurrently and iteratively refines and integrates feature maps from three distinct perspectives, thereby enhancing the features’ capacity for representation. The idea is from the following observation: given a three-dimensional feature map, we can examine the feature map from the three different yet interrelated two-dimensional planar perspectives: the channel-width, channel-height, and width-height perspectives. Based on the TA, a novel detector, called TADet, for the detection of steel strip surface defects is proposed, which is an encoder-decoder network: the decoder uses the proposed TA refines/fuses the multiscale rough features generated by the encoder (backbone network) from the three distinct perspectives (branches) and then integrates the purified feature maps from the three branches. Extensive experimental results show that TADet is superior to the state-of-the-art methods in terms of mean absolute error, S-measure, E-measure and F-measure, confirming the effectiveness and robustness of the proposed TADet. Our code and experimental results are available at https://github.com/hpguo1982/TADet.
Similar content being viewed by others


Introduction
As an important metal raw material, strip steel has been widely used in various fields such as bridge construction, transportation, and aerospace1,2,3. However, due to intricate industrial production environments and equipment factors, defects on strip steel surfaces often exhibit low contrast against the background, significant intra-class variability, and minimal inter-class differences, thereby posing formidable challenges to the strip steel surface defect detection system4. How to effectively refine and fuse the feature details of strip steel surface defects is one key to the success of the defect detector.
In recent years, deep learning methods have been successfully applied to the detection task of strip steel surface defects, and a prevalent approach is to extract and fuse coarse features obtained from the backbone network to enhance the representational capability of the feature maps, thereby improving the detection precision. For example, Xu et al.5 proposed an improved Generative Adversarial Network (GAN) model, which effectively identifies and classifies six types of surface defects on hot-rolled strip steel by introducing conditional label vectors and a multi-classification branch. Li et al.6 proposed an improved Faster R-CNN and FPN network that significantly enhanced the detection accuracy of surface defects on steel strips, especially in detecting tiny and slender defects, by augmenting the NEU dataset and adopting multi-scale feature fusion. Vannocci et al.7 improved the detection and classification of flatness defects in the steel industry by proposing a system where a detector and a classifier are responsible for defect localization and classification, respectively. Youkachen et al.8 designed a novel defect detection model that performs defect segmentation on hot-rolled steel strip surfaces using Convolutional Auto-Encoder (CAE) and a sharpening process, and validated the model’s efficiency on the NEU database. Luo et al.9 employed a fast and robust defect classification model using selectively dominant local binary patterns (SDLBPs), with intelligent search, pattern mapping, and adaptive weighting to enhance the nearest neighbor classifier. Although these convolutional neural network-based methods have achieved significant success in steel strip surface defect detection, they have certain limitations in extracting global features from images.
The attention mechanism is one of the most commonly used methods for extracting global feature maps with rich semantic and spatial information. For example, Zhao et al.10 proposed a novel feature-attention convolution module that extracts comprehensive feature information by capturing long-range feature relationships between the upper and lower layers, for the task of classifying surface defects on steel strips. Cui et al.1 designed an autocorrelation-aware aggregation network (A3Net) that includes both global autocorrelation modules and local autocorrelation modules to explore the autocorrelation of global and local information to generate more accurate salience maps. Zhou et al.2 employed a cascade feature integration module to fuse multibranch features, followed by a dense attention mechanism that progressively integrates features into the final salience map to focus more on the defect areas. Xin et al.11 introduced the CBAM attention mechanism in steel surface defect detection tasks, which considers both channel and spatial features while utilizing different levels of feature information to enhance feature expression capabilities. Song et al.12 designed an encoder-decoder residual network for defects’ detection on steel strip surfaces, which utilizes full convolutions and attention mechanisms to extract rich multilevel defect features, accelerating model convergence.
The aforementioned attention mechanisms including channel attention, spatial attention and self-attention effectively capture the relationships and significance among channels or spatial points within an image. One drawback of existing attention mechanisms is that they may not or seldom consider cross-dimensional interactions, such as the relationships between the channel and height, as well as between the channel and width. Indeed, we can re-examine a three-dimensional feature map from three different yet interrelated two-dimensional perspectives: channel-width, channel-height and width-height, and apply conventional attention mechanisms to each perspective for the extraction and fusion of the coarse multiscale features of the backbone network.
Based on the discussion above, we propose a novel attention method, called TA (Triple-Attention), characterized by interrelated and complementary interactions, that extracts and fuses image feature maps from three distinct two-dimensional spatial perspectives, namely channel-height, channel-width and height-width, to enhance the features’ capacity for representation. According to the TA, a novel salient objection detector called TADet (TA-based salient objection detector) for strip surface defect detection is proposed, which is an encoder-decoder network: (1) the encoder uses backbone networks, such as ResNet and VGG, to extract coarse multiscale features of the strip steel image, and (2) the decoder employs the proposed TA to extract/fuse the encoded features from the channel-height, channel-width and width-height perspectives, respectively, and then fuses the refined multiscale feature maps of the three perspectives for the detection of the steel strip surface defects. Experimental results demonstrate that our method consistently outperforms other state-of-the-art methods with strong robustness and generalization capabilities.
The remainder of the paper is organized as follows: Section Related Works describes related works , Section Methods introduces the proposed method, Section Result and Discussion presents the experimental results, and finally, the work is summarized in Section Conclusion and Recommendation.
Related works
Salient detection method
In the past few years, salient object detection (SOD) methods have achieved significant success. The SOD methods can be broadly categorized into two groups: (1) conventional detectors; (2) deep-learning based detectors.
-
Conventional detectors:Conventional detectors try to manually construct low-level features, such as color, texture and contrast, feeding to conventional classifiers including SVM13, logistic regression14and neural networks15 for prediction. For example, Zhu et al.16 proposed a robust boundary connectivity (BC) and incorporated it into a salient optimization framework to achieve more reliable results. Peng et al.17 divided the image into two parts: a low rank matrix representing a visually consistent background and a sparse matrix representing different foreground target regions, and then constructed a fast Structured Matrix Decomposition (SMD) model based on the low rank matrix recovery theory. Huang et al.18 utilized target suggestions to estimate the significance score of each superpixel under the Multiple Instances Learning (MIL) framework, improving the accuracy of significance detection. The conventional detectors evaluate the saliency values by using the hand-crafted features. However, the drawbacks existing in these methods include multistage (non-end-to-end) learning processes, significant subjective influence and difficulty in extracting complex semantic features, leading to low segmentation precision.
-
Deep-learning based detectors: Deep-learning based detectors learn feature representations automatically from input data in an end-to-end manner without human intervention, thereby enhancing the model’s efficiency and precision. For example, Hou et al.19 introduced short skip connections for salient detection within the nested edge detection architecture. Deng et al.20 proposed a new Recursive Residual Refinement Network (\(\hbox {R}^3\)Net) that uses Residual Refinement Blocks (RRB) to detect salient regions in the image. Wu et al.21 proposed a cascaded partial decoder (CPD) framework, which discards the high-resolution features of shallower layers to reduce the complexity of the deep aggregation model. Zhou et al.22 constructed a diffusion matrix and seed vector based on diffusion to better distinguish between salient regions and background regions. Zhao et al.23 proposed a Pyramid Feature Attention Network (PFAN) to capture rich high-level contextual features and low-level spatial features for detecting salient objects. Liu et al.24 proposed a novel Pixel Context Attention (PiCANet) network to selectively learn the contextual information of each pixel. Liu et al.25 constructed a global guidance module and a feature aggregation module based on a U-shaped structure, enabling the gradual refinement of advanced semantic features for generating detailed salience maps. Qin et al.26 proposed a prediction refinement architecture (BASNet) in the task of boundary aware salient object detection, effectively segmenting salient target regions with clear boundaries.
In this paper, we employ deep-learning methods to extract multiscale features from strip steel surface defect images in an end-to-end manner. In addition, we design a novel attention called triple-attention (TA) to refine/fuse coarse multiscale features extracted by the backbone network, improving the detection performance of the detector on strip steel surface defects.
Attention mechanism
Attention mechanisms including channel attention, spatial attention and self-attention have been widely applied to computer vision tasks such as salient object detection27,28, image classification29,30,31,32and semantic segmentation33,34 in recent years, which enhance the model’s feature representation capability. For example, Wang et al.35 proposed a residual attention module to train deep networks for image classification, improving the performance of object recognition. Hu et al.36 developed a squeeze and excitation module (SE) that learns the weight of each channel and focuses on the information of specific channels to improve overall model performance. Unlike SE, Woo et al.37 proposed the Convolutional Block Attention Module (CBAM) that introduces the attentions in both channel and spatial dimensions, allowing for more flexible capture of important information about specific channels and spatial positions. Simões et al.38 introduced a new attention based differential network (AttentDifferNet) for industrial detection, which outperforms the standard differential network in detecting all objects in three anomaly detection datasets. Admass et al.39 used a mixed attention module for arrhythmia classification, optimizing the selection of extracted features to improve the model’s classification performance. Bi et al.40 constructed a bidirectional attention mechanism to learn weights of input features in both directions to extract hidden features, thereby predicting water quality time series. Tang et al.41 introduced a lightweight defect detection model for printed circuit boards (PCBs), utilizing a dual ___domain attention mechanism to effectively extract defect features of small-sized PCBs and improve the accuracy of defect recognition.
Although attention mechanisms help the model better understand contextual information including channels and spatial points in the image, these attentions may not or seldom consider cross-dimensional interactions. To address this issue, a new triple-attention (TA) module is proposed, which tries to focus on extracting/fusing multiscale features from three different perspectives, i.e., channel-height, channel-width and height-width, thereby exploring potential salience information and improving model performance.

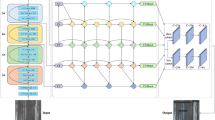
The architecture of TADet includes an encoder and a decoder. The encoder consists of a convolutional layer and ResNet Blocks. The decoder includes Triple-attentions (TA) followed by feature aggregation module (FAM).
Methods
Attention mechanisms have been successfully applied for the salient object detection of the strip steel surface defects, and the issue existing in conventional attention-based methods is that they may not or seldom consider cross-dimensional interactions, as aforementioned. Therefore, we propose a novel attention method called triple-attention (TA) to purify and integrate multiscale feature maps from the channel-height, channel-width, and height-width perspectives, respectively. Based on the TA, a novel encoder-decoder network called TADet (TA-based salient objection detector) is proposed for detecting the strip steel surface defects, as shown in Fig. 1. The encoder uses ResNet as the backbone network to extract rough multiscale features. The decoder utilizes the proposed TA to extract/fuse the encoded multiscale feature maps from the three branches (perspectives), namely channel-height, channel-width,and height-width, and then uses the proposed feature aggregation module to fuse the refined feature maps of the three branches.
Encoder network
In detection tasks, many deep-learning based methods pretrained on the large dataset ImageNet have been used as the encoder/backbone network to extract multiscale feature maps and Convolution-based networks including VGG, DarkNet and the ResNet are among the most often used methods because they excel at extracting low-level spatial details and high-level semantic information. In this study, we select ResNet-50, a convolutional residual network, as the encoder to extract the coarse multiscale feature maps of the strip steel surface, where skip-layer connections in the network are used to avoid gradient disappearance. Fig. 1(left) shows the structure of ResNet-50.
As shown in Fig. 1(left), the encoder consists of a convolutional layer followed by four residual learning blocks, i.e., Block-1, Block-2, Block-3 and Block-4, and the corresponding outputs of the residual blocks are denoted by \({{\textbf {R}}}_j\), \(j = \{0, 1, 2, 3, 4\}\). Note: \({{\textbf {R}}}_0\) is the output of the convolutional layer. Given an image with a size of \(h \times w\), the size of the feature map corresponding to ResNet Block-j, is \(\frac{h}{2^{j+1}}\times \frac{w}{2^{j+1}}\). The output of the j-th residual block, \({{\textbf {R}}}_j\), is feed into a triple-attention module to further extract/fuse features from three different perspectives.
Decoder network
In encoder-decoder models, attention mechanisms are often used by the decoder to refine and integrate the coarse features generated by the encoder due to its advantage of capturing channel and spatial contextual information in the image. However, existing attention mechanisms may not or seldom consider cross-dimensional interactions as aforementioned. Therefore, we propose a novel attention mechanism called Triple-attention (TA). TA refines/fuses multiscale features generated by the encoder from three different perspectives (branches). Then we uses the proposed feature aggregation module (FAM) to fuse these branch results, generating a saliency map with clear edge details. Fig. 1 shows the architecture of TA and FAM. More details about TA and FAM refer to Section Triple-attention Module and Section Feature Aggregation Module.
Triple-attention module
To address the issue of traditional attention mechanisms ignoring the interaction between dimensions, as aforementioned, we re-examine three-dimensional feature map of the image from the perspectives of channel-height, channel-width, and height-width, and then propose a novel triple-attention (TA) module for capturing channel and spatial contextual information in images, as shown in Fig. 1(right).
The TA consists of three parallel branches, i.e., TA-1, TA-2 and TA-3, corresponding to height-width, channel-width and channel-height perspectives, respectively, and TA-2 and TA-3 are respectively anti-clockwise rotated 90 along W-axis and anti-clockwise rotated 90 along the H-axis from TA-1. The input of TA-i, \(i = 1, 2, 3\), is the outputs of the ResNet-50 ,namely \({{\textbf {R}}}_0\), \({{\textbf {R}}}_1\), \({{\textbf {R}}}_2\), \({{\textbf {R}}}_3\), \({{\textbf {R}}}_4\) (refer to Section Encoder Network).
Fig. 1(top-right) shows the architecture of the i-th branch (TA-i). For the j-th layer of TA-i, the inputs are the \({{\varvec{R}}}_j\), the output of ResNet Block-j (refer to Section Encoder Network), and \(\hat{{{\textbf {R}}}}_{j+1}\), the output of the (j+1) layer. Note: the input of the forth layer is \({{\textbf {R}}}_4\), the output of the ResNet Block-4. TA-i firstly concatenates the two feature maps, i.e., \({{\textbf {R}}}_j\) and \(\hat{{{\textbf {R}}}}_{j+1}\), through upsampling operation on \(\hat{{{\textbf {R}}}}_{j+1}\) followed by the concatenate operation. The front and back permutations of the j-th layer are used for axis rotation and restoration, respectively. Between the two permutations, Z-pool reduces the zeroth dimension of tensor to 2 by concatenating the average pool and max pool features along the zeroth dimension, and then SA employs the proposed spatial-attention (SA) module to extract context details obtained by Z-pool operation. Therefore, the process of the j-layer of TA-i is
where per and cat represent the permute operation and the concatenate operation, and the SA block is shown in Fig. 2.

The structure of the spatial attention module (SA).
Given the input feature map x, maximum pooling and average pooling are employed by Z-pool to respectively extract dominant features and smooth information, representing as \({{\textbf {P}}}_{\text {avg}}\) and \({{\textbf {P}}}_{\text {max}}\), respectively. Then SA concatenates the two feature maps, i.e., \({{\textbf {P}}}_{\text {avg}}\) and \({{\textbf {P}}}_{\text {max}}\), followed three \(3\times 3\) convolutions and a sigmoid activation function to obtain spatial attention weights \(\beta\), and finally, \(\beta\) are element-wise multiplied with the features \({{\textbf {x}}}\) to obtain the final output \({{\textbf {y}}}\). SA can be represented by the following equation
where \(\delta\), \(\beta \in [0, 1]\) and \(Conv_k\) represent the sigmoid operation, spatial attention coefficients and convolution operation with kernel size equal to \(k\times k\), respectively.
Feature aggregation module
In this section, we construct a simple yet effective feature aggregation module (FAM) to integrate feature maps that have been purified from the three different perspectives, i.e., channel-height, channel-width and height-width (refer to Section Triple-attention Module).

The structure of the feature aggregation module (FAM).
Fig. 3 shows the details of the proposed feature aggregation module (FAM). The inputs of FAM are the outputs of the triple attention (TA) module, i.e., \({{\textbf {F}}}_1\), \({{\textbf {F}}}_2\) and \({{\textbf {F}}}_3\) (corresponding to the three branches of height-width, channel-width and channel-height). FAM firstly concatenates the three feature maps, i.e., \({{\textbf {F}}}_1\), \({{\textbf {F}}}_2\) and \({{\textbf {F}}}_3\). Then upsample operation between two CBR are used to maintain the same resolution as the original input image, where CBR uses a convolution operation with a kernel size of \(1\times 1\), BN and the activation function of Relu to extract potential salient information. In addition, we use \(3\times 3\) convolution operation and \(1\times 1\) convolution operation to obtain the final output feature map \({{\textbf {F}}}_4\). Therefore, FAM is computed as
where \(Conv_k\) represent the convolution operation with the kernel size equal to \(k\times k\).
Loss funtion
In order to generate high-quality saliency maps, the proposed TADet uses a combination of fusion losses to train the proposed model, as shown in Fig. 1. Each fusion loss consists of structural similarity (SSIM42) loss, intersection over union (IOU43) loss and binary cross entropy (BCE44). Therefore, the loss function is defined as
where \(S_i\) is the saliency map predicted from \({{\textbf {F}}}_i\), corresponding to the i-th layer of the proposed method (as shown in Fig. 1). Note: \({{\textbf {F}}}_4\) is the fused feature map from the three branches, i.e., TA-1, TA-2 and TA-3, as discussed in Section Feature Aggregation Module.
The SSIM loss42 was originally proposed to capture the structural information of images by measuring the similarity between the images. We let \(a=\left\{ a_i|i=1,2,...,N^2\right\}\) and \(b=\left\{ b_i|=1,2,...,N^2\right\}\) be the pixel values of the predicted probability map S and the ground truth G, respectively. The SSIM is defined as
where \(\mu _a\), \(\mu _b\) and \(\delta _a^2\), \(\delta _b^2\) are the mean and variance of \({{\textbf {a}}}\) and \({{\textbf {b}}}\), respectively, and \(\delta _{ab}\) is the corresponding covariance. \(C_1\) and \(C_2\) are set to \(0.01^2\) and \(0.03^2\) to avoid dividing by zero.
The IOU loss43 is used to penalize inaccurate classification, which is defined as
where \(G(x, y)\in \{0,1\}\) is the ground truth on the (x, y) pixel of the image, where 0 represents the background and 1 represents the defective object. \(S(x, y)\in [0, 1]\) is the predicted probability of a defective object on the corresponding pixel.
The BCE loss44 is a commonly used loss function for binary classification/ segmentation tasks, and it can be used to evaluate the accuracy of the model on each sample by comparing the probability distribution between the model output and the true label. The BCE loss is defined as

Three types of defects on SD-saliency-900.
Result and discussion

Train-test-losses.
We conduct the experiments using a Hewlett Packard Core i5, sixth-generation, 8 GB RAM, and a Colab Pro GPU that was manufactured by Google. This section presents all the experiments conducted on a challenging public dataset SD saliency-90045. This dataset contains 900 cropped images with three types of defects: inclusions, patches, and scratches, as shown in Fig. 4, and each image is associated with a pixel level label of size \(200\times 200\). Following Ref12., the training set with 540 images (180 images for each type of defects) were randomly selected from the SD-saliency-900 dataset, and 270 images (90 images for each type of defects) were affected by salt and pepper noise interference (\(\rho =20\%\)). At the training stage, each image I was adjusted to \(256\times 256\) pixels and randomly cropped to \(224\times 224\) pixels, and then normalized by Z-score, i.e., \(\frac{I-\mu }{\delta }\), where \(\mu\) and \(\delta\) are equal to 0.4669 and 0.2437, respectively. During the testing stage, each image was adjusted to \(256\times 256\), and the corresponding predicted salience map was scaled to the resolution of \(200\times 200\)for evaluation through bilinear interpolation. The parameters of the encoder were initialized using ResNet-50 trained on ImageNet46, while the remaining parameters were initialized using the default settings of PyTorch. AdamW47 with an initial learning rate of \(lr=0.001\) and \(\alpha =0.9\) is selected as the optimizer, and other parameters are set to default values. The batch size is 8 and the iteration number is set to 25K due to the test loss converging around 25K iterations, as shown in Fig. 5.
Several metrics including the F-measure (\(F_\beta\))48, Mean Absolute Error (MAE)49, S-measure (SM)50and E-measure51 were used to evaluate the performance of the proposed TADet. The F-measure comprehensively considers the accuracy and recall of salience detection results, which is formulated as \(F_\beta =\frac{\left( 1+\beta ^2\right) \times Precision \times Recall}{\beta ^2\times Precision + Recall}\), where \(\beta\) is a parameter used to adjust the relative importance of Precision and Recall (\(\beta ^2=0.3\)). The MAE is a commonly used metric to measure the degree of average absolute difference between the normalized saliency map and the ground truth, defined as \(MAE=\frac{1}{n}\sum |S_i-G|\). The S-measure is used to measure the structural similarity of image segmentation results, namely the degree of structural consistency between the predicted saliency map and the true segmentation. The SM is defined as \(SM = \alpha \times F_{obj} + \beta \times F_{reg}\), where \(F_{obj}\) and \(F_{reg}\) represent the structural similarity of objects and structural similarity of regions, respectively, and \(\alpha\) and \(\beta\) represent the weight coefficients to balance the contribution of different parts to the overall structural similarity (\(\alpha = 0.7\) and \(\beta = 0.3\)). The E-measure is used to evaluate the similarity or matching degree between the predicted saliency map and the actual image, which is defined as \(E_\epsilon =\frac{1}{w\times h}\sum _{x=1}^{w}\sum _{y=1}^{h}\psi S\left( x,y\right)\), where \(\psi\) represents enhanced alignment matrix.

Quantitative evaluation of different models on the SD-saliency-900 disturbed with salt and pepper noise whose level are 0%, 10%, and 20% from top to bottom. (a), (c), and (e) present F-measure curves and (b), (d), and (f) present PR curves.
Ablation study
We conduct a series of ablation experiment to evaluate the effectiveness of essential components of the proposed TADet, i.e., ResNet (backbone), triple-attention module (TA) and feature aggregation module (FAM) in terms of MAE, SM, and \(F_\beta\). All experiments are performed on the SD saliency-900 dataset. Table 1 shows the quantitative evaluation results and the details of the table are as follows:
-
ResNet+FM: TADet uses the ResNet-50 to extract rough multiscale feature maps followed by average pooling layers to generate salience maps and then fuses the salience maps to obtain the final prediction.
-
ResNet+TA+FM: After extracting rough multiscale feature maps by ResNet-50, TADet uses TA to extract interactions between different dimensions (channel-height, channel-width and height-width) from multiscale feature maps, followed by average pooling layers to generate salience maps.
-
ResNet+SA+FM: Similar to ResNet+TA+FM with exception that TADet uses one branch of TA. Similar to spatial attention (SA) to extract spatial information from multiscale feature maps.
-
ResNet+FAM: Similar to ResNet+FM with exception that TADet uses FAM to fuse the feature maps.
-
ResNet+TA+FAM: This is the proposed method.
As shown in Table 1, TADet with all components (i.e., ResNet, TA and FAM) achieved the best performance, verifying the effectiveness of the key components ResNet, TA and FAM in the proposed model. Besides, TADet with TA outperformed TADet with SA, indicating that multiple branches of TA complement each other, thereby enhancing the performance of the model.

Visualization comparison of different models on the SD-saliency-900. (a) input images, (b) ground truth, (c) RCRR, (d) 2LSG, (e) BC, (f) SMD, (g) MIL, (h) PFANet, (i) NLDF, (j) DSS, (k) \(\hbox {R}^3\)Net, (l) BMPM, (m) PoolNet, (n) PiCANet, (o) CPD, (p) BASNet, (q) SAMNet, (r) ITSD, (s) \(\hbox {F}^3\)Net, (t) MINet, (u) EDRNet, (v) DACNet, (w) ours.
Comparison with State-of-the-art methods
In order to validate the effectiveness and robustness of the proposed TADet on the strip steel surface defect detection, TADet was compared with 20 state-of-the-art salience detection methods, including RCRR57, 2LSG22, BC16, SMD17, MIL18, PFANet23, NLDF56, DSS19, \(\hbox {R}^3\)Net20, BMPM52, PoolNet25, PiCANet24, CPD21, BASNet26, ITSD54, \(\hbox {F}^3\)Net53, MINet55, SAMNet58, DACNet2, and EDRNet12. To ensure fairness in comparison, we run the source codes provided by the authors or the results of the corresponding papers. All salience maps were adjusted to the same size as the original image to ensure consistency and comparability in the evaluation.
Fig. 6 shows the curves of the compared twenty-one methods in terms of PR and F-measure. From Fig. 6, TADet outperformed all the other state-of-the-art models. In particular, the PR curve of TADet was closest to the coordinates (1, 1), and its F-measure curve covered the curves of the other models. Furthermore, we observed from Figs. 6(c), 6(d), 6(e) and 6(f) that all the 21 compared methods were sensitive to severe salt and pepper noise interference (\(\rho = 10\% ,20\%\)), and TADet outperformed other recently released methods, such as DACNet, \(\hbox {F}^3\)Net, MINet, and EDRNet. These results strongly confirmed the effectiveness and robustness of our proposed model.
Table 2 presents the quantitative results of the compared methods in terms of the MAE, SM,\(F_\beta\), and \(E_\epsilon\). From the Table 2, the proposed model achieved the best performance compared to the other models. Specifically, compared to BASNet, our method reduced the MAE by 0.61% and improves the SM, \(F_\beta\), and \(E_\epsilon\) by 2.22%, 3.17% and 1.55%, respectively. Compared to the salience target detection model EDRNet (DACNet) for strip steel, the proposed model improved SM, \(F_\beta\), and \(E_\epsilon\) by 1.25% (0.78%), 1.96% (1.5%) and 0.92% (0.73%) respectively, while reducing MAE by 0.39% (0.27%). These results indicated that the method proposed in this article has achieved significant improvements compared to existing models. Besides, after introducing 10% and 20% noise in the training set, our method was also superior to other methods.
Fig. 7 shows the visual comparison of the proposed TADet with other advanced methods on the nine images and the last column shows the visual results of TADet. From Fig. 7, TADet was obviously better than the methods, i.e., fully and accurately segmenting the defect areas. Specifically, for the first three rows of defect images with low contrast between the defect area and the background, TADet accurately and completely detected defect areas without introducing any background information, and in contrast, others either incorrectly highlight the background area or fail to completely segment the defect areas. For the middle three rows of defect images with fine details, TADet generated significant results with clear boundary detail information while some models have blurred boundaries in the segmented defect areas. For the last three rows of images with complex backgrounds, TADet effectively detected defect areas from the complex backgrounds. To sum up, TADet achieved complete segmentation of defect areas in different scenarios, verifying the effectiveness of TADet in the strip steel surface defect detection task.
Conclusion and recommendation
This paper presents an innovative attention mechanism called triple-attention (TA) to re-examine the feature map from the three different yet interrelated two-dimensional planar perspectives: the channel-width, channel-height, and width-height perspectives. Then, a novel TA-based salient object detector (TADet) for the detection of strip steel surface defects is proposed, which is an encoder-decoder network: the decoder uses the proposed TA refines/fuses the multiscale rough features generated by the encoder (backbone network) from three distinct perspectives (branches) and then uses the proposed feature aggregation module to integrate the purified feature maps of the three branches. A large number of experiments conducted on the SD saliency-900 dataset show that TADet is significantly superior to the current state-of-the-art methods. TADet provide an important solution for industrial defect detection to accurately detect defects. However, further research is needed to improve the generalization performance in the field of salient object detection.
Code availability
Our code and experimental results are available at https://github.com/hpguo1982/TADet
References
Cui, W. et al. Autocorrelation-aware aggregation network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 72, 1–12 (2023).
Zhou, X. et al. Dense attention-guided cascaded network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 71, 1–14 (2022).
Guo, H. et al. A nested u-shaped residual codec network for strip steel defect detection. Applied Sciences. 12, 11967 (2022).
Dong, H. et al. Pga-net: Pyramid feature fusion and global context attention network for automated surface defect detection. IEEE Trans. Ind. Informatics. 16, 7448–7458 (2020).
Xu, L., Tian, G., Zhang, L. & Zheng, X. Research of surface defect detection method of hot rolled strip steel based on generative adversarial network. IEEE. (2019).
Li, K., Wang, X. & Ji, L. Application of multi-scale feature fusion and deep learning in detection of steel strip surface defect. IEEE. (2019).
Vannocci, M. et al. Flatness defect detection and classification in hot rolled steel strips using convolutional neural networks. In Advances in Computational Intelligence - 15th International Work-Conference on Artificial Neural Networks, IWANN 2019, Gran Canaria, Spain, June 12-14, 2019, Proceedings, Part II, vol. 11507 of Lecture Notes in Computer Science, 220–234 (Springer, 2019).
Youkachen, S., Ruchanurucks, M., Phatrapomnant, T. & Kaneko, H. Defect segmentation of hot-rolled steel strip surface by using convolutional auto-encoder and conventional image processing. Image processing. (2019).
Luo, Q. et al. Surface defect classification for hot-rolled steel strips by selectively dominant local binary patterns. IEEE Access. (2019).
Zhao, W., Song, K., Wang, Y., Liang, S. & Yan, Y. Fanet: Feature-aware network for few shot classification of strip steel surface defects. Measurement. 208, 112446 (2023).
Xin, H. & Zhang, K. Surface defect detection with channel-spatial attention modules and bi-directional feature pyramid. IEEE Access. 11, 88960–88970 (2023).
Song, G., Song, K. & Yan, Y. Edrnet: Encoder-decoder residual network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 69, 9709–9719 (2020).
Rivera-Romero, C., Muñoz-Minjares, J., Lastre-Dominguez, C. & Lopez-Ramirez, M. Optimal image characterization for in-bed posture classification by using svm algorithm. Big Data Cogn. Comput. 8, 13 (2024).
Liu, M., Guo, C. & Xu, L. An interpretable automated feature engineering framework for improving logistic regression. Appl. Soft Comput. 153, 111269 (2024).
Ahmadzadeh, M., Abazari, A., Ghafouri, M., Ameli, A. & Muyeen, S. A deep convolutional neural network-based approach to detect false data injection attacks on pv-integrated distribution systems. IEEE Access. 12, 2803–2816 (2024).
Zhu, W., Liang, S., Wei, Y. & Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, 2814–2821 (2014).
Peng, H. et al. Salient object detection via structured matrix decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 39, 818–832 (2017).
Huang, F., Qi, J., Lu, H., Zhang, L. & Ruan, X. Salient object detection via multiple instance learning. IEEE Trans. Image Process. 26, 1911–1922 (2017).
Hou, Q. et al. Deeply supervised salient object detection with short connections. IEEE Trans. Pattern Anal. Mach. Intell 41, 815–828 (2017).
Deng, Z. et al. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th international joint conference on artificial intelligence, Stockholm, Sweden, 684690 (2018).
Wu, Z., Su, L. & Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 3907–3916 (2019).
Zhou, L., Yang, Z., Zhou, Z. & Hu, D. Salient region detection using diffusion process on a two-layer sparse graph. IEEE Trans. Image Process. 26, 5882–5894 (2017).
Zhao, T. & Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 3085–3094 (2019).
Liu, N., Han, J. & Yang, M. Picanet: Pixel-wise contextual attention learning for accurate saliency detection. IEEE Trans. Image Process. 29, 6438–6451 (2020).
Liu, J. J., Hou, Q., Cheng, M. M., Feng, J. & Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 3917–3926 (2019).
Qin, X. et al. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 7479–7489 (2019).
Gao, Y., Gao, L. & Li, X. A hierarchical training-convolutional neural network with feature alignment for steel surface defect recognition. Robotics Comput. Integr. Manuf. 81, 102507 (2023).
Li, J., Pan, Z., Liu, Q. & Wang, Z. Stacked u-shape network with channel-wise attention for salient object detection. IEEE Trans. Multim. 23, 1397–1409 (2021).
Bhattacharjee, S., Shanmugam, P. & Das, S. Attention-guided convolution neural network assisted with handcrafted features for ship classification in low-resolution sentinel-1 sar image data. IEEE Access 12, 48668–48685 (2024).
Kulyabin, M. et al. Attention to the electroretinogram: Gated multilayer perceptron for asd classification. IEEE Access 12, 52352–52362 (2024).
Li, P., Wang, H., Wang, Z., Wang, K. & Wang, C. Swin routiformer: Moss classification algorithm based on swin transformer with bi-level routing attention. IEEE Access 12, 53396–53407 (2024).
Chen, F. et al. Dual-path and multi-scale enhanced attention network for retinal diseases classification using ultra-wide-field images. IEEE Access 11, 45405–45415 (2023).
Zhou, Y. et al. Semantic segmentation of surface cracks in urban comprehensive pipe galleries based on global attention. Sensors 24, 1005 (2024).
Fu, J. et al. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 3146–3154 (2019).
Wang, F. et al. Residual attention network for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 3156–3164 (2017).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognitio, Salt Lake City, UT, USA, 7132–7141 (2018).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. Cbam: Convolutional block attention module. ECCV 3–19 (2018).
Simões, F., Kowerko, D., Schlosser, T., Battisti, F. & Teichrieb, V. Attention modules improve image-level anomaly detection for industrial inspection: A differnet case study. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 8246–8255 (2024).
Admass, W. & Bogale, G. Arrhythmia classification using ecg signal: A meta-heuristic improvement of optimal weighted feature integration and attention-based hybrid deep learning model. Biomed. Signal Process. Control. 87, 105565 (2024).
Bi, J., Chen, Z., Yuan, H. & Zhang, J. Accurate water quality prediction with attention-based bidirectional lstm and encoder-decoder. Expert Syst. Appl. 238, 121807 (2024).
Tang, J. et al. A lightweight surface defect detection framework combined with dual-___domain attention mechanism. Expert Syst. Appl. 238, 121726 (2024).
Wang, Z., Simoncelli, E. P. & Bovik, A. C. Multiscale structural similarity for image quality assessment. In The Thrity-Seventh Asilomar Conference on Signals, Systems & Computer, Pacific Grove, CA, USA 2, 1398–1402 (2003).
Rahman, M. A. & Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In International symposium on visual computing, Las Vegas, NV, USA, 234–244 (2016).
Boer, P., Kroese, D., Mannor, S. & Rubinstein, R. A tutorial on the cross-entropy method. Ann. Oper. Res. 134, 19–67 (2005).
Song, G., Song, K. & Yan, Y. Saliency detection for strip steel surface defects using multiple constraints and improved texture features. Optics and Lasers in Engineering 128, 106000 (2020).
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, Miami, Florida, USA, 248–255 (2009).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2015).
Achanta, R., Hemami, S., Estrada, F. & Susstrunk, S. Frequency-tuned salient region detection. In 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 1597–1604 (2009).
Perazzi, F., Krähenbühl, P., Pritch, Y. & Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In 2012 IEEE conference on computer vision and pattern recognition, Providence, RI, USA, 733–740 (2012).
Cheng, M. & Fan, D.-P. Structure-measure: A new way to evaluate foreground maps. Int. J. Comput. Vis. 129, 2622–2638 (2021).
Fan, D.-P., Gong, C., Cao, Y., Ren, B. & Cheng, M.-M. Ali borji: Enhanced-alignment measure for binary foreground map evaluation. CoRR[SPACE]arXiv: abs/1805.10421 (2018).
Zhang, L., Dai, J., Lu, H., He, Y. & Wang, G. A bi-directional message passing model for salient object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, 1741–1750 (2018).
Wei, J., Wang, S. & Huang, Q. F³net: fusion, feedback and focus for salient object detection. In Proceedings of the AAAI conference on artificial intelligence, New York, USA 34, 12321–12328 (2020).
Zhou, H., Xie, X., Lai, J. H., Chen, Z. & Yang, L. Interactive two-stream decoder for accurate and fast saliency detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 9141–9150 (2020).
Pang, Y., Zhao, X., Zhang, L. & Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 9413–9422 (2020).
Luo, Z. et al. Non-local deep features for salient object detection. In Proceedings of the IEEE Conference on computer vision and pattern recognition, Honolulu, HI, USA, 6609–6617 (2017).
Yuan, Y., Li, C., Kim, J., Cai, W. & Feng, D. Reversion correction and regularized random walk ranking for saliency detection. IEEE Trans. Image Process. 27, 1311–1322 (2018).
Liu, Y., Zhang, X.-Y., Bian, J.-W., Zhang, L. & Cheng, M.-M. Samnet: Stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans. Image Process. 30, 3804–3814 (2021).
Acknowledgements
This work is in part supported by [Science and Technology Plan Project of Henan Province], grant number [242102210092], [Xinyang Normal University Graduate Research Innovation Fund], grant number [2024KYJJ010], [Key Scientific Research Projects of Higher Education Institutions in Henan Province], grant number [25B520004], [Open Found of the Engineering Research Center of Intelligent Swarm Systems, Ministry of Education], grant number [ZZU-CISS-2024004], and [Henan Joint Fund for Science and Technology Research], named [Optimization of the CLIP Algorithm Based on Transformer-based Multimodal Neural Networks and Its Application in Video Surveillance Systems].
Author information
Authors and Affiliations
Contributions
Conceptualization, L.Z., X.L., Y.S. and H.G.; methodology, L.Z., X.L. and H.G.; software, X.L. and H.G.; validation, L.Z., X.L. and H.G.; formal analysis, L.Z., X.L., Y.S. and H.G.; investigation, L.Z., X.L., Y.S. and H.G.; resources, L.Z. and H.G.; data curation, L.Z., X.L., Y.S. and H.G.; writing—original draft preparation, L.Z., X.L. and H.G.; writing—review and editing, L.Z.; visualization, L.Z. and X.L.; supervision, L.Z., X.L. and H.G.; project administration, L.Z., X.L., Y.S. and H.G.; All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, L., Li, X., Sun, Y. et al. Triple-attentions based salient object detector for strip steel surface defects. Sci Rep 15, 2537 (2025). https://doi.org/10.1038/s41598-025-86353-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-86353-9
