
Abstract
Accurately discerning lead–zinc open pit mining areas using traditional remote sensing methods is challenging due to spectral signature class mixing. However, machine learning (ML) algorithms have been implemented to classify satellite images, achieving better accuracy in discriminating complex landcover features. This study aims to characterise various ML models for detecting and classifying lead–zinc open pit mining areas amidst surrounding landcover features based on Sentinel 2 image analysis. Various associated band ratios and spectral indices were integrated with processed Sentinel 2 reflectance bands to enhance detection accuracy. Suitable bands highlighting lead and zinc mine areas were identified based on optimal index factor (OIF) analysis and various deep learning-based stacked encoders. Furthermore, 15 different ML classifiers were tested to identify optimised algorithms for accurately discriminating complex mining areas and associated landcover features. After detailed evaluation and comparison of their accuracies, the extra tree classifier (et) was the most effective, achieving an overall accuracy of 0.94 and a kappa coefficient of 0.93. The light gradient boosting machine classifier (lightgbm) and random forest classifier (rf) models also performed well, with overall accuracies of 0.937 and 0.936 and kappa coefficients of 0.925 and 0.925, respectively.
Similar content being viewed by others
Introduction
Minerals are crystalline elements or chemical compounds that have undergone rigorous geological and weathering processes over time and are found in the forms of ores. Production of mineral ores has significantly increased over the last few decades, with 9.6 to 11.3 billion metric tons from the year 1985 to 2000 and 18.7 billion metric tons in the year 2022 extracted for economic benefit and played a role in any Country’s growth1. The extraction of minerals ore involves extracting geological materials by mining through tunnels, shafts, or pits. Such materials are classified into metal, non-metal, and fuel minerals, which can be further divided into surface (open-cast or pit) and underground mining2. Open-cast mining, also known as open-pit mining, is used for extracting deep and extensive deposits that lack significant overburden coverage. Unstructured and unplanned mining activities with irregular monitoring can significantly impact on the environment and cause disasters like landslides or subsidence, or underground fire, like the 2021 mining wall collapse around the unstructured mines of Bhilwara Limestone mines3,4. Rampura Agucha mining area of Rajasthan state of India is renowned for its substantial lead–zinc (Pb–Zn) mineral reserves in ore of Galena, Sphalerite, etc5. Due to their presence in the rugged and inaccessible topography of semi-arid regions and inaccessible dense forests like the forest of Vachellia nilotica (Gum Arabic trees), they pose challenges to regular monitoring. In contrast, relied upon the traditional field based methods for classification and monitoring of these mining areas is challenging as well as time consuming.
In contrast, Remote Sensing technology has been widely used for such investigations and proven to a useful technique for complex mining areas mapping and detection. Different optical images, such as Landsat-8, ASTER, Sentinel-2, MODIS, etc., have been widely explored for land use land cover classification with respect to investigating mining areas6,7. In addition, recently, hyperspectral data (Hyperion, Enmap, Prisma) has been used in many studies for better discrimination of earth surface features due to its high spectral resolution and unique chemical sensing capability3,4,5. Various image processing techniques, such as the computation of band ratios and spectral indices, have been proven to be a standard method for highlighting different mineral ore zones and land cover classes6,8. Thermal infrared (TIR) data are utilised to highlight mineralogical indices, including the quartz index (QI), carbonate index (CI), and mafic index (MI). Commonly used band ratios generated using False Color Composite (FCC) images can detect alunite, kaolinite, propylitic alteration, argillic and phyllic alteration zones for possible mineral occurrences9,10,11. Additionally, SWIR Band and Thermal Infrared (TIR) data are utilized for band ratio approach for highlighting mineralogical potential regions, which include the quartz index (QI) for Quartz potential ores zones, carbonate index (CI) for Carbonate and bicarbonate bearing minerals, Hematite bearing ores region and mafic index (MI) to delineate Gabbro or amphibolite or other mineral contained in extrusive volcanic rocks12,13. A list of several band ratios and spectral indices used in several studies related to mineral exploration is shown in Table S2.
However, for the appropriate detection of mining areas and discriminating them with surrounding land cover features is difficult based on the implementation of a specific of combination of several spectral indices. Thus, integration of Machine Learning with image analytics has become an integral part for image classification. Various Machine learning (ML) algorithms have been employed for classifying land cover types, feature detection (a list of ML and deep learning-based studies in mining aspects have been shown in supplementary Table A). Many previous studies focus on identifying mining zones or provinces using simple machine learning classification algorithms such as Spectral Angle Mapper (SAM), Spectral Correlation Mapper (SCM), the Constrained Energy Minimization (CEM)14,15,16,17. Moreover, later on and beyond the year 2010, many new algorithms evolved under advanced machine learning classification techniques and works underway with uses of LIDAR data with K Nearest Neighbor (KNN) classification or Maximum Likelihood Classifier (MLC), Random Forest (RF) and Support Vector Machine (SVM), Regression Tree (RT), Artificial Neural Network ANN, Dempster-Shafer (D-S) Evidence Theory ensemble learning with significant accuracy for delineation of mining province18,19,20. In addition, a limited studies have also considered AutoML technique (which allow to implement a total of 15 different ML classifier collectively based on the PyCaret library in Python) for image classification. Apart from Machine learning- Deep learning object-based segmentation models like Fully Connected Deep Neural Networks (FCNNs), convolutional neural networks (CNNs or ConvNet), and residual networks (ResNets, ResCapsNet, Geo-Rnet), SegNet, UNet, DecovNet (3D CNN framework), and multiscale feature attention framework (MFAF), convolutional deep learning (CDL) are used for mine delineation and geochemical studies21,22,23. Moreover, various sorting techniques for encoding and decoding algorithm structures such as Gradient-Weighted Class Activation Mapping (Grad-CAM), Gate Convolutional Autoencoder (GCAE), bidirectional gradient verification (BiGradV) have been explored to segment different LU/LC or mining area with improved accuracy24,25.
Based on the review of previous studies, it was observed that a large number of studies have relied solely on conventional approaches, such as band ratios or spectral indices, for land cover classification and the detection of mining areas26,27. Limited studies have utilized an integrated approach combining Machine Learning/Deep Learning and image analytics28,29. Additionally, the majority of studies have focused on mine delineation using object-based detection of mining classes with high-resolution images, rather than employing semantic segmentation with moderate-resolution satellite images like Sentinel-230,31. The appearance of lead and zinc open-cast mine areas is often similar to other land cover features, such as settlements and barren land, making it challenging to differentiate them using image classifiers based solely on spectral bands of moderate-resolution satellite images like Sentinel-2. Furthermore, the application of Machine Learning techniques using Sentinel-2 data for lead–zinc open-cast mine areas has not been widely explored in the study area (Rampur Agucha mine, Rajasthan), highlighting a significant research gap. To address this gap, the present study was designed to apply multiple ML models using the Auto-ML technique, integrating multiple band ratios/spectral indices and relevant spectral bands for the first time in this region.
The manuscript is structured to achieve the outlined objectives effectively. Started from the beginning with the introduction of the study that provides the necessary background and contextual foundation about open cast mining and models related to delineating the mining activities or other Landcover classes. After this step, a detailed methodology section was introduced with explanations of each section needed to fulfil in this research. In this section, the application of band ratios, Optimum Index Factor (OIF) bands, the use of training samples in the AutoML classification process, and image classification are discussed in detail. Finally, the results are subsequently analyzed and discussed, focusing on generating and interpreting different generated band ratios and OIF products. We also discussed the detailed results of the AutoML classifier and Stacked Encoding and how they helped us decide on the final three image-classified products. The article concludes by emphasizing the study’s significance and its success in bridging the identified research gap.
Study area
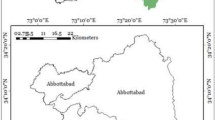
The Rampura Agucha Pb–Zn mining area is in southern Ajmer and northern Shahpura of Bhilwara District, Rajasthan, India, near the Gujarat state border. This mining area holds the world’s 5th most significant deposit of zinc and lead sulphides (sphalerite, galena) with 6.15 million metric tons of in-situ reserves, containing 1.96% lead (Pb) and 13.85% zinc (Zn)32. It is the third largest producer of zinc metal globally Geographically, it lies between 25°57’ N to 25°38’ N latitude and 75°35’E to 74°35’E longitude. The region experiences semi-arid conditions with an average summer maximum temperature of about 46 °C and winter temperatures of 22.2 °C to 9.3 °C. Annual precipitation is around 626.17 mm33. Geologically, it is part of the Archean craton within the Banded Gneissic Complex (BGC), overlain by the Aravalli and Delhi Super Group sedimentary rocks. The area is marked by the Aravalli Rakhabdev lineament separating the Delhi Supergroup orogen to the east and includes metasedimentary and metavolcanic rocks with granitic suites in the west34. The ore deposits at Rampura Agucha are found within various geological formations, including graphite-biotite sillimanite schist, garnet-biotite-sillimanite gneiss, amphibolite, pegmatite, calc-silicate rocks, and aplite35. The study area map was generated using QGIS 3.30 software. Figure 1a,b represent the ___location of the Rajasthan state boundary and the study site, respectively, which have been highlighted on the ESRI Topographic base map (Source: QGIS 3.30 inbuilt base map). Additionally, the study area is highlighted using ALOS PALSAR-generated hill shade and Sentinel-2 FCC in Fig. 1c,d.

(a) Location map of Rajasthan state, India (b) study area part on ALOS PALSAR DEM image in Southern Rajasthan (c) ALOS PALSAR DEM of the study area, and (d) Sentinel 2 image of the study area. (The map was created using Qgis 3.30 (open source); The software download link is https://www.qgis.org/download/).
Materials and methods
Data description
The study utilized Sentinel-2 multispectral data (S2) obtained from the Google Earth Engine (GEE) platform. Sentinel-2 products offer images with spatial resolutions of 10 m, 20 m, and 60 m across 12 spectral bands, and a temporal resolution of 5 days (details provided in Table 1). Based on a review of relevant literature on mining area classification, bands 2, band 3, band 4, band 5, band 8 and band 11–12 were used for analysis during the pre-monsoon season, as this period highlights distinct variations in features associated with mining activities, aiding their differentiation36. Additionally, the study incorporated ESRI Land Use/Land Cover (LU/LC) products, Google Earth Pro Maxar data, and ground validation for enhanced accuracy (Table 1).
Methodology
The present study focuses on the detection of lead and Zinc open-cast mining areas based on the analysis of various Sentinel-2 bands, analyzing band ratios/spectral indices through the implementation of AutoML classifiers. The adopted methodology (Fig. 2) can be classified into 5 different categories such as (1) satellite image processing, (2) implementation OIF, (3) generation of multiple band-ratios and spectral Indices, (4) Selection of suitable layers for lead–zinc detection and implementation of AutoML classifiers, (5) accuracy assessment of different classifiers, and (6) generation of lead–zinc open cast mining areas (Fig. 2).

Flowchart of methodology.
Satellite image processing
Various preprocessing techniques were applied to the satellite images acquired for the study. Atmospheric correction was performed using the Sen2cor model to generate true surface reflectance values (ranging from 0 to 1) by normalizing each band’s pixel values by dividing them by 10,000. Additionally, bands with a spatial resolution of 20 m were resampled to a resolution (standardized) of 10 m using the nearest neighbor method, ensuring uniformity across all bands used in the analysis. The preprocessing steps were executed on the Google Earth Engine (GEE) platform.
Generation of band ratios and spectral indices (BR)
Image processing techniques, such as band ratios and spectral indices, have been extensively used to detect various mineral deposits and differentiate land cover types. These methods enhance the spectral differences between bands, rescale the values, and represent the results as images. When classifying mining areas, the use of band ratios and spectral indices as layers offer a more efficient alternative compared to the use of geology and lithology layers, which require extensive fieldwork and laboratory analysis, making them time-consuming and labor-intensive. To identify lead and zinc mining zones, a total of 15 different band ratios and spectral indices have been utilized to emphasize mineral ore areas (Table 3). These include indicators for galena (lead) ore, iron oxide, ferric oxide compositions, siderite, pyrite, and unoxidized sulfide zones, which are particularly effective in highlighting hydroxyl-containing mineral ores. Apart from using band ratios, various image indices were also used for better discrimination of LULC features. To mask out vegetation cover from mining classes, vegetation indices such as Regional Vegetation Index with red edge band (RVI Red edge), Normalized Difference Vegetation Index (NDVI) were applied. Additionally, MNDWI was applied tohighlights water accumulated or flowing areas. All the adopted indices and band ratios are listed in (Table 2).
Optimum index factor (S2_OIF)
Apart from the band ratio, this study also used different spectral bands selected based on the analysis of Optimum Index factor (OIF). OIF computes the importance of bands as per information contained, which is a useful method for band selection for better image classification to discriminate features. Higher OIF values indicate superior information for specific regions, characterized by high standard deviation, while lower values indicate deficient information and low correlation between bands. In this study, OIF was applied on 5 selected sentinel 2 bands (mentioned in “Data description” section) using Eq. (1) to identify useful bands for mining feature discrimination.
where (i) is the standard deviation of ratio i, and (j) is the correlation coefficient between two of the bands in three ratios46.
The Optimum Index Factor (OIF) was calculated using the ILWIS software developed by ITC, Netherlands. The OIF values represent combinations of three spectral bands, with each band assigned a value of 100. The most informative band combination is identified based on the OIF-derived values; a total value close to 300 (for a three-band combination) represents the most informative set of bands.
Training data collection
For the implementation of classification, initially, all the band ratio/spectral indices layers (15 layers shown in Table 2), as well as the OIF derived bands, were stacked to create three different sets of composite images (composite 1: band ratio/spectral Indices; composite 2: OIF derived bands; composite 3: band ratio/spectral Indices + OIF derived bands). Subsequently, the composite images were qualitatively assessed by examining various band combinations highlighting lead–zinc mine and other features. Based on the interpretation of these band combinations, training data was generated as a point file for different feature classes (Fig. 3). A total of six different classes of training data were created including cropland, fallow land, mining area, settlement, and vegetation. The total number of training samples collected for each class was based on following the 10-n formula (n = number of bands)47. As per the 10n formula, we have collected 900 total samples for six different classes for composite 1 (10 × 15 bands = 150 samples for each class; 150 × 6 = 900 samples for six classes) Similar approach was followed for selecting the number of samples for composite 2 and composite 3 (Table 3). For the classification validation, the total number of samples selected for each composite was split into an 80:20 ratio, where 80% of the sample was used for training, and the remaining 20% of the sample was used for validation (Fig. 3).

Training sample for different classes.
Auto-ML (pycaret library) classification
Automated Machine Learning or AutoML (pycaret library) classification tools are designed to identify the best-performing machine learning algorithm and its optimal input parameters for a given dataset and specific task. This process is inherently challenging, as selecting the most suitable model and fine-tuning it for a particular problem is both time-intensive for data scientists and computationally expensive48. It is an effective classification task, often outperforming traditional machine learning methods and showing promise in various applications, though they still require some human involvement and optimization48,49,50,51,52. They utilize images for feature engineering and data visualization or create recent-based Generative AL models52. In this present study, AutoML-based classification is extensively used on sample data, as described (Table 3). It is used to classify four types of data sets, and each dataset produces accuracy parameters for 15 different supervised classifiers.
Stacked autoencoder (SAE) for feature extraction (BR + S2_OIF + FE)
Feature band selection for feature extraction is critical to satellite imagery classification, especially when dealing with many spectral bands, such as the 20 bands used in this study. Including too many bands can lead to computational inefficiencies, model oversaturation, increased noise, and class mixing, complicating the classification process and raising computational costs53,54. To address this, it is common practice to optimize the selection of spectral bands, typically working with a maximum of 12–15 carefully chosen bands, to achieve optimal classification results55.
In this study, an Artificial Neural Network (ANN)-based Stacked Autoencoder (SAE) was implemented to optimize band selection. This unsupervised learning model compresses the input data into a reduced-dimensional representation, known as the "latent space." The encoder-decoder architecture of the autoencoder facilitates learning efficient representations, denoising input data, and improving feature Selection for complex datasets (Fig. 4). Integrating ___domain knowledge is essential for accurate feature extraction of mining areas53,54,56. This combination of ___domain expertise and model-driven results is crucial in determining the most effective brands for image classification.

Stacked autoencoder and decoder flow.
Accuracy assessment
Accuracy assessment is an important parameter to assess the performance of this study by using specific Eqs. 2–5 to compare overall accuracy57. Different approaches like band-ratios and spectral Indices (BR_SI), OIF-derived Sentinel-2 bands (OIF_bands), BR_SI + OIF_bands and selected optimized layer after applying Stack Auto-encoding composite dataset were evaluated across by using AutoML classifiers. Classification success was measured using overall accuracy, Kappa coefficient, ROC curve, and F1 score58. For evaluating classification success, accuracy assessment is very important. The Kappa coefficient evaluates agreement between methods widely used in remote sensing for land cover classification accuracy (equation vii)50. The Receiver Operating Characteristic (ROC) curve plots the true positives (sensitivity) vs. False Positives (1-Specificity). ROC evaluation through Area under Curve (AUC) represented the performance of ROC using a single value. If each value indicates an AUC value greater than 0.5, then the classifiers produce efficient results59. The F1 score, the harmonic mean of precision and recall, ranges from 0 to 1, where 1 indicates the best possible result (Eqs. 2–4). A high F1 score suggests a balanced performance60. Analyzing these parameters helped to identify the best-performing classifier for the classified product.
Generation of lead–zinc open-cast mining areas
Image classification is the most important parameter used in this study. In most studies, band selection for feature extraction is not done, or most work focuses on object detection. In this study, pixel-based semantic classification was done. We use Python-based Anaconda (Jupyter) for the classification, which helps classify the mining area efficiently and significantly differentiate significantly from settlement and surrounding features.
Result and discussion
This study has the potential to detect open-cast mines and settlements, barren land, and other land cover classes in the vicinity of the mining area. Based on proven techniques of earlier research, band ratio data were employed for discriminating probable mining detection and mine delineation43,44, while OIF (Optimum Index Factor) generated an invaluable band of importance and segregated from 12 complex bands of Sentinel 246. Using these parameters, Auto ML Multi-classifiers with Stacked Autoencoding algorithms have been employed by other researchers, yielding good accuracy48,49,53,54.
Band ratio and Spectral Indices (BR)
Sentinel-2 generated band ratios/indices successfully distinguish between probable mineral and non-mining areas, segregating regions based on the spectral reflectance properties of electromagnetic (EM) waves. Fifteen different band ratios were implemented to distinguish mineral-rich and non-mineral areas based on the insights from, geology and lithological data of the region. But when explored most previous studies it was observed that 12 to 13-band ratios are often employed to classify land types using machine learning or deep learning classifiers61,62,63. But for this study we try to incorporate maximum number of possible band ratio to get maximum information about the place with minimum class mixing. These band ratios effectively identified zones with mining activity, highlighting features like hydroxyl ores which is in deep purple colour (Fig. 5a), galena in deep brown pointed area (Fig. 5b), iron oxide with light violet colour highlight with box (Fig. 5c), and water content area (tailing pond) through the MNDWI in deep blue colour (Fig. 5d).

Band Ratio/Indices highlighting (a) Hydroxyl bearing mineral, (b) Galena or lead ore (c) Iron oxide bearing ore (d) Water (through MNDWI), (e) RVI Red Edge (f) NDVI Red Edge (g) Ferric oxide composition (h) Siderite (i) Sphalerite (j) Pyrite (k) Sulphide in unoxidized compound (l) Urban Index (m) New Built-up Index (n) Normalized Difference Built-up Index (NDBI) and (o) Bare Soil Index (BSI).
Non-mining land cover classes were mapped using vegetation-specific indices. The Red Edge-based Ratio Vegetation Index (RVI) emphasized healthy and dense vegetation highlighted in red colour, while the Normalized Difference Vegetation Index (NDVI) captured all vegetation types highlighted by light green patches (Fig. 5e,f). Ratios for ferric oxide and siderite highlighted iron minerals and soil compounds in indigo colour(Fig. 5g,h), while sphalerite ratios differentiated zinc from lead in light violet colour (Fig. 5i). Pyrite indices identified iron-rich hydrothermal minerals in orange and yellowish orange colour (Fig. 5j), and unoxidized sulfide ratios detected sulfide traces highlighted in white colour (Fig. 5k). Urban indices distinguished settlement areas from surroundings using off-white colour (Fig. 5l).
Land-use classes were further analyzed using urban indices, such as the New Built-up Index (in light cyan colour) and the Normalized Difference Built-up Index (deep cyan colour), to identify urban areas and impervious surfaces (Fig. 5m,n). The Bare Soil Index was used to detect semi-arid zones with exposed soil highlighted in navy-blue colour (Fig. 5o). Finally, All these band ratios for mineral and non-mineral classifications were subsequently integrated as inputs for classification using the AutoML classifier (PyCaret library), as summarized in Table 6.
OIF (S2_OIF)
OIF techniques has been widely used, proven method for selection of optimized bands for the classification of different land cover features64,65. In our study, OIF derived band were used for implementing various ML classifiers for better discrimination of lead zinc open-cast mine areas. In our study, six different chosen bands were used for the computation of OIF. Six different combinations of bands were observed with OIF values ranging from 185 to 224 (Table 4) Conceptually, the highest OIF values are considered as the best combinations66. As per the evaluation of six different OIF band combination, We chose 3 band combination based on qualitative and quantitative investigation (values close to 300) (Number 1, & 2 in Table 5). As per the qualitative investigation of the selected band combination (Table 4, Number 1–3), it was observed that band combination of Green–Red edge-NIR (224.80) was suitable for separating vegetation cover from mining areas. In addition, remaining selected band combinations (Green-NIR-SWIR1, 224.80; and Green–Red edge-SWIR2, 211.44) were found to be useful for better highlighting the mining areas compared to the other band combination (band combination number 4–6 in Table 4). In contrast, the selected the band combinations were stacked into a single composite and used to generate training samples (point data) for classification.
Composite product and stacked autoencoding feature extraction
Integrated the mineral and non-mineral based Band ratio data and Sentinel 2 informative OIF Bands produced a final stack of 20 band data, which later will be used for sample classification. However, during analyses of 20 band results, it was found that the combined product produced a hurdle in image classification. To overcome this problem, feature extraction was needed, for which 12 to 15 bands were selected for the classification of the image. However, after testing, it was found that 12 optimal bands produced appropriate results55. Therefore, to solve this problem of band selection, we took help from ___domain knowledge and used it on a feature extraction technique which is based on the ANN-based Stacked Autoencoder model, which refined band selection by encoding and decoding the data by using Leaky ReLU and ReLU model activation functions and later optimized the important band by using Adam optimizer (shown in Table 5). We also used some alternative techniques followed by previous studies, like PCA, ICA, MNF67, Jeffries–Matusita distance, and Bhattacharya68. But none of them could solve this problem of class mixing, where designated six distinctive classes of landcover area mixed and formed a mixture of four classes.
Assessment of auto-ML classifiers based on sample data
Training point data (as discussed in Sect. 3.3.4) was subsequently employed for classification using the AutoML (PyCaret) algorithm on Google Colab. The classification process yielded detailed accuracy reports for 15 different classifiers. Key performance metrics such as Accuracy/Overall Accuracy (OA), Area Under the Curve (AUC), F1 score, and Kappa values were calculated for each classifier. These metrics provided valuable insights into the performance of each classification approach, as summarized in (Tables 6, 7, 8, and 9).
The Sentinel-2 band ratio-extracted sample data used for AutoML classification demonstrated significant accuracy across various classifiers. The results indicate the following performance metrics:
-
Extra Trees (et): Overall Accuracy (OA) of 88.20%, F1 score of 87.81%, and Kappa value of 85.80%.
-
Random Forest (rf): Overall Accuracy (OA) of 87.60%, F1 score of 86.80%, and Kappa value of 85%.
-
Linear Discriminant Analysis (lda): Overall Accuracy (OA) of 86.50%, F1 score of 86.2%, and Kappa value of 83.70%.
These results highlight the robust performance of the classifiers, with Extra Trees achieving the highest accuracy among the tested models.
The Sentinel-2 OIF band-extracted sample data used for AutoML classification demonstrated notable accuracy across different classifiers. The performance metrics are as follows:
-
XGBoost: Overall Accuracy (OA) of 87.7%, F1 score of 87.2%, and Kappa value of 85.10%.
-
K-Nearest Neighbors (KNN): Overall Accuracy (OA) of 87.6%, F1 score of 86.5%, and Kappa value of 84.5%.
-
Random Forest (RF): Overall Accuracy (OA) of 87.1%, F1 score of 86.5%, and Kappa value of 84.4%.
These results highlight the effectiveness of the classifiers, with XGBoost achieving the highest accuracy among the tested models.
The Sentinel-2 and Band Ratio (BR + S2_OIF) composite product extracted sample data demonstrated significant improvements in classification accuracy when analyzed using AutoML. The classification results for key models are as follows:
Extra Trees (et): Overall Accuracy (OA) of 92.9%, F1 score of 92.9%, and Kappa value of 91.2%.
Light Gradient Boosting Machine (lightgbm): Overall Accuracy (OA) of 92.19%, F1 score of 92.19, and Kappa value of 90.61. Random Forest (rf): Overall Accuracy (OA) of 91.83%, F1 score of 91.79, and Kappa value of 90.18. These results highlight the enhanced classification performance achieved by integrating Sentinel-2 and Band Ratio composite data, with Extra Trees providing the highest accuracy among the evaluated classifiers.
The feature importance analysis for the Sentinel-2 Band Ratio/Indices/Feature Importance composite band samples, processed through ANN-based Stacked Autoencoding (S2 + BR + FI), produced highly accurate classification results using AutoML. The performance metrics for the classification are as follows:
-
Extra Trees (et): Overall Accuracy (OA) of 94.28%, F1 score of 94.29%, and Kappa value of 93.13%.
-
Light Gradient Boosting Machine (lightgbm): Overall Accuracy (OA) of 93.73%, F1 score of 93.73%, and Kappa value of 92.5%.
-
Random Forest (rf): Overall Accuracy (OA) of 93.62%, F1 score of 93.62%, and Kappa value of 92.46%.
Thus, a notable improvement in classification accuracy could be arrived at, with Extra Trees Classifier (et) achieving the highest performance metrics, indicating the effectiveness of the feature-optimized composite band data for AutoML classification. Though the other two classifiers, LightGBM and rf, could achieve high-performance metrics but slightly less than et.
Effectiveness of using stacked autoencoding derived bands
The effectiveness of the model performance was evaluated by using a comparison with the accuracy parameter for sample generated classification result of Band ratio, Sentinel 2 OIF data and Ann-based Stacked encoding (Fig. 6). Here; we have followed the steps performed by a previous study69 where they had analysed the change produce by each of the 15 classifiers (AutoML classifier) after using ANN Stacked Encoding technique on 20 bands of composite data and the data produces by15 bands of band ratio and 5 bands for Sentinel2 OIF importance. After examining the graph, it was clearly understood that the performance of the ANN Stack encoding technique improved every classifier result.

Overall accuracy of classifiers based on sample point data for the different approaches.
In addition to highlighting the advantages of a Stacked Autoencoding-based AutoML classifier over different used approaches, it also improves the classifier’s performance when comparing pre-and post-Stacked autoencoding results on Band Ratio (BR) and OIF (S2_OIF) composite products. Thus, the approach enhances each classifier’s performance after each subsequent step and finally improves the quality of the resulting image (Fig. 7).

Classifier overall accuracy based on point data before and after feature delineation.
Apart from Overall accuracy, the calculated F1 score is a machine-learning metric that measures the model’s predictive performance with the help of precision and recall. The F1 value of et increases from 87.81 for Band ratio and 85.89 for Sentinel 2 OIF to 94.29 for ANN Stacked Encoding accuracy which is considered as significant jump on this performance. On the other hand, Cohen’s kappa coefficient is an important statistic for measuring the effectiveness of the classifiers based on accessing perfect agreement between users and classification by product results. The Kappa Coefficient accuracy value of et from 85.8 for Band ratio and 83.79 for Sentinel 2 OIF to 93.13 for ANN Stacked Encoding accuracy. The Kappa Coefficient value takes a significant jump in accuracy and increases the ability of the classifier to perform best in image classification. These performance of accuracy in both the parameters shows tremendous improvement after each successive approach (Table 10). These ANN Stack Encoding based classifier technique produced better result than previous studies where the accuracy is not improved after classification under the ___domain of machine learning classifier using Multispectral satellite image70.
After verifying the accuracy of the classification, it was observed from the results that ANN based Stacked encoding was neither producing any overestimated values or nor it required any other hyperparameter tuning, to verify is robustness as a model. Now to further understand the performance of classifier’s effectiveness, we performed class-wise accuracy evaluation for different land use/land cover (LU/LC) categories, such as Crop Area (CP), Fallow Land (FL), Active Open Pit Mining Area (MA), Settlement (SET), Vegetation (VEG), and Water Body (WB). With the verification of Key parameter, we found that Overall Accuracy, F1 Score, and Kappa Coefficient, were evaluated, as shown in Fig. 8. The Receiver Operating Characteristic (ROC) curve, with Area Under the Curve (AUC) values, shows graphical values that lie between 0.5 and 1, indicating strong classification performance, especially in deciphering the class of open pit mining areas with settlement and barren land class etc., (Fig. 9). After verifying every accuracy parameter finally based on results performance, we choose to do image classification. We used et, lightgbm and rf based classifier models on the ANN Stacked Encoding based 12 band composite data on the satellite image.

Class-wise accuracy assessment graph.

Class wise ROC curve for all three classifier.
Sentinel 2 satellite image-based machine learning classification
After selecting the optimal 12 bands and classifying the sample data, three finalized classification algorithms were applied for image classification to identify open cast mining areas and nearby settlements and barren land semantically. These three classifier algorithms, demonstrated superior performance in distinguishing various classes, including open cast mining sites, were:
Extra trees classifier
The Extra Tree Classifier (et) achieved the best results, with an overall accuracy of 94.28% and a kappa coefficient of 0.91 for each class (Table 8). The satellite image data was classified using Python’s Anaconda Jupyter interface, the GDAL library, and the Extra Tree classification algorithm. The confusion matrix identified six distinct classes, which were validated using the existing LU/LC Atlas of ESRI , Google Earth Pro and field validation (Fig. 10a and Table 11).

(a) Extra tree classified image (b) light gradient boosting machine classified image (c) random forest classifier image.
Light gradient boosting machine classifier
The Light Gradient Boosting Machine (lightgbm) classifier also produced good results, achieving an overall accuracy of 93.7% and a kappa coefficient of 0.92. Using the same process as the Extra Tree Classifier, the satellite image was classified into six distinct classes, as visualized and verified through the confusion matrix produced from the image. Later, the classified results were validated with the LU/LC Atlas of ESRI , Google Earth Pro and field validation (Fig. 10b and Table 11).
Random forest classifier
The random forest (rf) classifier, applied similarly to the Extra Tree and Light Gradient Boosting Machine classifiers, produced good results with six distinct classes. It achieved an overall accuracy of 93.7% and a kappa coefficient of 0.927. The results were validated using the LU/LC Atlas of ESRI, Google Earth Pro and field validation (Fig. 10c and Table 11).
By analyzing these classified image results, it is evident that the distinction between the open-cast mining, settlement, and barren land classes has been successfully demarcated and clearly segregated. This outcome aligns well with the objectives, fulfilling the purpose of achieving accurate class differentiation visually (Fig. 10a-c).
Accuracy assessment and validation
Confusion matrix
See Table 11.
Conclusion
Sentinel-2 optical satellite data used in the study did allow delineation of the active lead–zinc open-pit mining areas of the Rampura Agucha mines, effectively distinguishing them from surrounding land use and land cover (LU/LC) classes. Using pre-monsoon data facilitated fewer atmospheric errors, and sun illumination was optimized, improving reflectance values. The primary aim was to separate active open-cast mining areas from settlements, barren land, and other land cover types to delineate legitimate mining zones, settlement areas, and additional LU/LC categories. Various band ratios and indices, such as hydroxyl-bearing ore indices, NDVI, NDWI, and urban built-up indices, were used to identify mining areas and other land features. These indices effectively highlighted ore mineral traces in hydroxyl-altered mining regions. Additionally, Optimum Index Factor (OIF) bands were generated to assist in identifying land features. However, it was found that Sentinel-2 OIF-generated bands faced challenges in distinguishing settlements from active open-pit mines due to similar colour representations, particularly with barren land and settlements.
Auto-ML classifier and deep learning-based encoding techniques effectively addressed such challenges, enhancing the distinction between such features. The feature-selected bands, generated using Stacked Autoencoders within ANN-based models, achieved an impressive 94% classification accuracy and improved the Area Under the Curve (AUC) to 99%. This methodology allowed for more effective segregation of mining and settlement classes. Among the classifiers tested, the Extra Trees (ET) Classifier demonstrated the highest performance, achieving an overall accuracy of 94.28%, an ROC-AUC score of 0.9940, an F1 score of 94.29%, and a Kappa value of 93.13%, outperforming both Light Gradient Boosting Machine and Random Forest classifiers. Thus, a critical gap could be bridged by employing even medium-resolution satellite data to distinctly classify lead–zinc open-pit mining areas from other LU/LC classes. This study opens the door for future opportunities to explore new models for feature extraction or ensemble methods using multispectral data. It demonstrates that effective results can be achieved without relying on high-resolution satellite images, reducing class mixing and improving accuracy. This study has other benefits as it highlights the zinc-lead open pit mining area, aiding authorities in forming policies to address unstructured or illegal mining activities. These activities pose health risks, pollute soil and water, cause erosion, and reduce crop productivity. The findings will help authorities formulate sustainable mining policies to minimize environmental and human harm.
Data availability
The dataset used and/or analyzed during present study shall be available from the corresponding author on reasonable request.
References
Gocht, W.R., Zantop, H. & Eggert, R.G. Mineral deposits and metallogenic concepts. In International Mineral Economics 5–21 (Springer, 1988). https://doi.org/10.1007/978-3-642-73321-5_2
C. Reichl. World Mining Data 2024. vol. 39 (Vienna, 2024).
Armstrong, M. et al. Adaptive open-pit mining planning under geological uncertainty. Resour. Policy 72, 102086 (2021).
Loupasakis, C., Angelitsa, V., Rozos, D. & Spanou, N. Mining geohazards-land subsidence caused by the dewatering of opencast coal mines: The case study of the Amyntaio coal mine, Florina, Greece. Nat. Hazards 70, 675–691 (2014).
Khan, R., Shaif, M. & Siddiquie, F. N. Mineragraphic studies of Pb-Zn ore deposits of Rampura-Agucha Area, Bhilwara Belt, Rajasthan. J. Sci. Res. 65, 39–50 (2021).
Adiri, Z., Lhissou, R., El Harti, A., Jellouli, A. & Chakouri, M. Recent advances in the use of public ___domain satellite imagery for mineral exploration: A review of Landsat-8 and Sentinel-2 applications. Ore Geol. Rev. 117, 103332 (2020).
Chniouar, M., Wafik, A., Daafi, Y. & Guglietta, D. Integrated remote sensing for geological and mineralogical mapping of Pb-Zn deposits: A case study of Jbel Bou Dahar region using multi-sensor imagery. Mining 4, 302–325 (2024).
Takodjou Wambo, J. D. et al. Identifying high potential zones of gold mineralization in a sub-tropical region using Landsat-8 and ASTER remote sensing data: A case study of the Ngoura-Colomines goldfield, eastern Cameroon. Ore Geol. Rev. 122, 103530 (2020).
Yajima & Taro. ASTER Data Analysis Applied to Mineral Resource Exploration and Geological Mapping (2014).
Lorenz, S. et al. Long-wave hyperspectral imaging for lithological mapping: A case study. In IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium 1620–1623. (IEEE, 2018). https://doi.org/10.1109/IGARSS.2018.8519362.
Sabins, F. F. Remote sensing for mineral exploration. Ore Geol. Rev. 14, 157–183 (1999).
Qiang, S. et al. Machine Learning for Open-Pit Mining: A Systematic Review. https://ssrn.com/abstract=4540535 (2023).
Ren, Z., Wang, L. & He, Z. Open-pit mining area extraction from high-resolution remote sensing images based on EMANet and FC-CRF. Remote Sens. (Basel) 15, 3829 (2023).
Abilio, O., Júnior, C. & Meneses, P. R. Spectral Correlation Mapper (SCM): An Improvement on the Spectral Angle Mapper (SAM). https://www.researchgate.net/publication/267721109 (2000).
Kruse, F. A., Lefkoff, A. B. & Dietz, J. B. Expert system-based mineral mapping in northern death valley, California/Nevada, using the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 44, 309–336 (1993).
Chang, C.-I. Constrained energy minimization (CEM) for hyperspectral target detection: Theory and generalizations. IEEE Trans. Geosci. Remote Sens. 62, 1–21 (2024).
Chakravarty, S., Paikaray, B.K., Mishra, R. & Dash, S. Hyperspectral image classification using spectral angle mapper. In 2021 IEEE International Women in Engineering (WIE) Conference on Electrical and Computer Engineering (WIECON-ECE) 87–90 (IEEE, 2021). https://doi.org/10.1109/WIECON-ECE54711.2021.9829585
Denœux, T. Logistic regression, neural networks and Dempster-Shafer theory: A new perspective. Knowl. Based Syst. 176, 54–67 (2019).
Rodriguez-Galiano, V., Sanchez-Castillo, M., Chica-Olmo, M. & Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 71, 804–818 (2015).
Thanh Noi, P. & Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using sentinel-2 imagery. Sensors 18, 18 (2017).
Wang, A., Wang, M., Wu, H., Jiang, K. & Iwahori, Y. A novel LiDAR data classification algorithm combined CapsNet with ResNet. Sensors 20, 1151 (2020).
Xie, H., Pan, Y., Luan, J., Yang, X. & Xi, Y. Open-pit mining area segmentation of remote sensing images based on DUSegNet. J. Indian Soc. Remote Sens. 49, 1257–1270 (2021).
Lv, H., Qian, W., Chen, T., Yang, H. & Zhou, X. Multiscale feature adaptive fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 19, 1–5 (2022).
Yan, X., Ai, T., Yang, M. & Tong, X. Graph convolutional autoencoder model for the shape coding and cognition of buildings in maps. Int. J. Geograph. Inf. Sci. 35, 490–512 (2021).
Song, W. et al. Bi-gradient verification for grad-CAM towards accurate visual explanation for remote sensing images. In 2019 International Conference on Data Mining Workshops (ICDMW) 473–479 (IEEE, 2019). https://doi.org/10.1109/ICDMW.2019.00074
Kavhu, B., Mashimbye, Z. E. & Luvuno, L. Climate-based regionalization and inclusion of spectral indices for enhancing transboundary land-use/cover classification using deep learning and machine learning. Remote Sens. (Basel) 13, 5054 (2021).
Guan, R. et al. Classification of heterogeneous mining areas based on ResCapsNet and Gaofen-5 imagery. Remote Sens. (Basel) 14, 3216 (2022).
Jena, B. et al. Artificial intelligence-based hybrid deep learning models for image classification: The first narrative review. Comput. Biol. Med. 137, 104803 (2021).
Zhao, S. et al. Land use and land cover classification meets deep learning: A review. Sensors 23, 8966 (2023).
Hossain, M. D. & Chen, D. Segmentation for object-based image analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogram. Remote Sens. 150, 115–134 (2019).
Li, C., Wang, D. & Kong, L. Application of machine learning techniques in mineral classification for scanning electron microscopy-energy dispersive X-ray spectroscopy (SEM-EDS) images. J. Pet. Sci. Eng. 200, 108178 (2021).
Vishwanath, U., Prasad, K.S. & Joshi, A. Geo-Metallurgical Studies of Rampura Agucha Deposit (2006).
Jain A.K. Government of India (2013).
Sugden, T.J., Deb, M. & Windley, B.F. The Tectonic Setting of Mineralisation in the Proterozoic Aravalli Delhi Orogenic Belt, Nw India, 367–390 (1990). https://doi.org/10.1016/S0166-2635(08)70175-0
Mishra, B. & Bernhardt, H.-J. Metamorphism, graphite crystallinity, and sulfide anatexis of the Rampura-Agucha massive sulfide deposit, northwestern India. Miner. Depos. 44, 183–204 (2009).
Gašparović, M. & Jogun, T. The effect of fusing sentinel-2 bands on land-cover classification. Int. J. Remote Sens. 39, 822–841 (2018).
Masoumi, F., Eslamkish, T., Honarmand, M. & Abkar, A. A. A Comparative study of landsat-7 and landsat-8 data using image processing methods for hydrothermal alteration mapping. Resour. Geol. 67, 72–88 (2017).
Imbroane, M.A., Melenti, C. & Gorgan, D. Mineral Explorations by Landsat Image Ratios. In Ninth International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC 2007) 335–340 (IEEE, 2007). https://doi.org/10.1109/SYNASC.2007.52
Segal Donald, B. Theoretical basis for differentiation of ferric-iron bearing minerals using Landsat MSS data. In 2nd Thematic Conference on Remote Sensing for Exploratory Geology, Symposium for Remote Sensing of Environment 949–951 (1982).
Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 27, 3025–3033 (2006).
Kanke, Y., Tubaña, B., Dalen, M. & Harrell, D. Evaluation of red and red-edge reflectance-based vegetation indices for rice biomass and grain yield prediction models in paddy fields. Precis Agric. 17, 507–530 (2016).
Chang, J. & Shoshany, M. Red-edge ratio normalized vegetation index for remote estimation of green biomass. In 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 1337–1339 (IEEE, 2016). https://doi.org/10.1109/IGARSS.2016.7729340
Andrew Oha, I., Donald Nnebedum, O. & Okonkwo, I. A. Alteration mapping for lead-zinc-barium mineralization in parts of the Southern Benue Trough, Nigeria, using ASTER multispectral data. Earth Sci. Res. 10, 61 (2021).
Kumar Gautam, V., Murugan, P. & Annadurai, M. A New Three Band Index for Identifying Urban Areas Using Satellite Images Image Georeferencing View Project Image Matching View Project A New Three Band Index for Identifying Urban Areas Using Satellite Images (2017).
Rahar, P. S. & Pal, M. Comparison of various indices to differentiate built-up and bare soil with sentinel 2 data, 501–509 (2020). https://doi.org/10.1007/978-981-13-7067-0_39
Chavez, P. S. StatMethodMSSRatios-OIF-1982. J. Appl. Photograph. Eng. 8, 23–30 (1982).
Lillesand, T. M. & Kiefer, R. W. Remote Sensing and Image Interpretation (Wiler Publisher, 2008).
Koren, O., Hallin, C. A., Koren, M. & Issa, A. A. AutoML classifier clustering procedure. Int. J. Intell. Syst. 37, 4214–4232 (2022).
Pol, U. Automl: Building an classfication model with pycaret. Ymer https://doi.org/10.37896/YMER20.11/50 (2021).
Topsakal, O. & Akinci, T. C. Classification and regression using automatic machine learning (AutoML)—Open source code for quick adaptation and comparison. Balkan J. Electr. Comput. Eng. 11, 257–261 (2023).
Sarangpure, N. et al. Automating the machine learning process using PyCaret and streamlit. In 2023 2nd International Conference for Innovation in Technology, INOCON 2023 (Institute of Electrical and Electronics Engineers Inc., 2023). https://doi.org/10.1109/INOCON57975.2023.10101357.
Li, K.-Y. et al. An automated machine learning framework in unmanned aircraft systems: New insights into agricultural management practices recognition approaches. Remote Sens. (Basel) 13, 3190 (2021).
Riz, E., Demir, B. & Bruzzone, L. Domain adaptation based on deep denoising auto-encoders for classification of remote sensing images. In (eds. Bruzzone, L. & Bovolo, F.) 100040K (2016). https://doi.org/10.1117/12.2241982
Yu, J. & Liu, G. Extracting and inserting knowledge into stacked denoising auto-encoders. Neural Netw. 137, 31–42 (2021).
Lozano-Tello, A., Siesto, G., Fernández-Sellers, M. & Caballero-Mancera, A. Evaluation of the use of the 12 bands vs. NDVI from sentinel-2 images for crop identification. Sensors 23, 7132 (2023).
Madani, H. & McIsaac, K. Spectral perturbation method for deep learning-based classification of remote sensing hyperspectral images. In Image and Signal Processing for Remote Sensing XXV (eds. Bruzzone, L., Bovolo, F. & Benediktsson, J. A.) 30 (SPIE, 2019). https://doi.org/10.1117/12.2534459.
Huang, D. et al. Accuracy assessment model for classification result of remote sensing image based on spatial sampling. J. Appl. Remote Sens. 11, 1 (2017).
Pham, K., Kim, D., Park, S. & Choi, H. Ensemble learning-based classification models for slope stability analysis. Catena (Amst) 196, 104886 (2021).
Zerrouki, N. & Bouchaffra, D. Pixel-based or Object-based: Which approach is more appropriate for remote sensing image classification? In 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC) 864–869 (IEEE, 2014). https://doi.org/10.1109/SMC.2014.6974020
Fourure, D., Javaid, M. U., Posocco, N. & Tihon, S. Anomaly detection: How to artificially increase your F1-score with a biased evaluation protocol (2021).
Yassine, H., Tout, K. & Jaber, M. Improving LULC classification from satellite imagery using deep learning—EUROSAT dataset. In The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XLIII-B3-2021, 369–376 (2021).
Nguyen, N. M. T. & Liou, N.-S. Detecting surface defects of achacha fruit (Garcinia humilis) with hyperspectral images. Horticulturae 9, 869 (2023).
Bahadur, K. C. Improving landsat and IRS image classification: evaluation of unsupervised and supervised classification through band ratios and DEM in a mountainous landscape in Nepal. Remote Sens. (Basel) 1, 1257–1272 (2009).
Hu, L., Wang, Q. & Xing, T. An algorithm of improved optimum index factor band selection from hyperspectral remote sensing image. DEStech Trans. Comput. Sci. Eng. https://doi.org/10.12783/dtcse/pcmm2018/23658 (2018).
Acharya, T. D., Yang, I. T. & Lee, D. H. Land cover classification of imagery from landsat operational land imager based on optimum index factor. Sens. Mater. 30, 1753 (2018).
Qaid, A. M. & Basavarajappa, H. T. Application of optimum index factor technique to landsat-7 data for geological mapping of North East of Hajjah, Yemen. J. Sci. Res. 3, 84–91 (2008).
Uddin, M. P., Mamun, M. A. & Hossain, M. A. PCA-based feature reduction for hyperspectral remote sensing image classification. IETE Tech. Rev. 38, 377–396 (2021).
Sen, R., Goswami, S., Mandal, A. K. & Chakraborty, B. An effective feature subset selection approach based on Jeffries-Matusita distance for multiclass problems. J. Intell. Fuzzy Syst. 42, 4173–4190 (2022).
Biswas, R. & Rathore, V. S. Discernment of complex lithologies utilizing different scattering and textural components of SAR and optical data through machine learning approaches in Jaisalmer, Rajasthan, India. J. Appl. Remote Sens. 17, 044507 (2023).
Kim, G., Kim, S. & Jang, B. Classification of mathematical test questions using machine learning on datasets of learning management system questions. PLoS One 18, e0286989 (2023).
Acknowledgements
The open-source dataset was used using the Google Earth engine for this study. We are grateful to the European Space Agency, ITC Netherland, and IIRS, Dehradun supported ILWIS software. The authors sincerely thank all the reviewers for sparing their invaluable time to review this manuscript. We also acknowledge ESRI for providing Land Cover Atlas and Google Earth Pro for giving high-resolution images for validation purposes.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study’s conception and design. A. Abhishek Kumar Ojha conceptualized the research, performed image analysis and learning-based coding, and wrote the original draft. B. Raja Biswas contributed to coding and bringing out the image results using a machine learning classifier and edited the manuscript. C. Akhouri Pramod Krishna supervised the work and contributed to technical discussions and manuscript writing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ojha, A.K., Biswas, R. & Krishna, A.P. Stacked encoding and AutoML-based identification of lead–zinc small open pit active mines around Rampura Agucha in Rajasthan state, India. Sci Rep 15, 5766 (2025). https://doi.org/10.1038/s41598-025-89672-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-89672-z
