
Abstract
Metaheuristic optimization algorithms play a crucial role in solving complex real-world problems, including machine learning parameter tuning, yet many existing approaches struggle with maintaining an effective balance between exploration and exploitation, leading to premature convergence and suboptimal solutions. The traditional Parrot Optimizer (PO) is an efficient swarm-based technique; however, it suffers from inadequate adaptability in transitioning between exploration and exploitation, limiting its ability to escape local optima. To address these challenges, this paper introduces the Salp Navigation and Competitive based Parrot Optimizer (SNCPO), a novel hybrid algorithm that integrates Competitive Swarm Optimization (CSO) and the Salp Swarm Algorithm (SSA) into the PO framework. Specifically, SNCPO employs a pairwise competitive learning strategy from CSO, which divides the population into winners and losers. Winners are refined using SSA-inspired salp navigation, enabling enhanced global search in the early stages and a dynamic transition to exploitation. Meanwhile, losers are updated using PO’s communication strategy, reinforcing solution diversity and exploration. To validate the efficacy of SNCPO, rigorous experimental evaluations were conducted on CEC2015 and CEC2020 benchmark functions, four engineering design optimization problems, and Extreme Learning Machine (ELM) training tasks across 14 datasets. The results demonstrate that SNCPO consistently outperforms existing state-of-the-art algorithms, achieving superior convergence speed, solution quality, and robustness while effectively avoiding local optima. Notably, SNCPO exhibits strong adaptability to diverse optimization landscapes, reinforcing its potential for real-world engineering and machine learning applications.
Similar content being viewed by others

Introduction
ELM has emerged as a transformative paradigm in machine learning, especially for training single-hidden-layer feedforward neural networks (SLFNs). The ELM is an exceptional artificial neural network characterized by its swift training duration and outstanding generalization capabilities. In contrast to traditional gradient-based methods that require iterative weight adjustments and parameter tuning1,2, ELM employs a non-iterative learning process where input weights and biases are assigned randomly, and output weights are analytically computed using techniques such as the Moore–Penrose inverse3. This approach drastically reduces training time while maintaining competitive performance, making ELM particularly attractive. The advantages and functionalities of ELM have been demonstrated in several applications, including image processing4, pattern recognition5, cancer detection6, classification7, and fault diagnosis8. However, despite its computational efficiency, ELM faces hyperparameter tuning, accuracy, and generalization challenges, limiting its performance in complex and high-dimensional tasks9. To tackle these limitations, researchers have increasingly turned to Metaheuristic Algorithms (MAs), which offer flexible and adaptive solutions for enhancing ELM performance10. Among the various MAs, swarm intelligence (SI) algorithms have gained significant attention. SI is a sophisticated artificial intelligence discipline that employs various metaheuristic strategies inspired by the self-organized, intelligent, and collaborative behaviors of diverse insects and animals to solve real-world problems11. SI approaches consist of several homogeneous individuals engaging with one another and their surroundings through basic protocols to achieve an optimal solution. The agents are not exceptionally proficient individually. Nonetheless, their collaboration enables them to address intricate challenges12. Common SI algorithms include Particle Swarm Optimization (PSO)13, Ant Colony Optimization (ACO)14, Whale Optimization Algorithm (WOA)15, Salp Swarm Algorithm (SSA)16, Jellyfish Search Optimizer (JSO)17, Manta Ray Foraging Optimization (MRFO)18, Artificial Bee Colony (ABC)19, Dragonfly Algorithm (DA)20, Grasshopper Optimization Algorithm (GOA)21, Harris Hawks Optimization (HHO)22, Lion Optimization Algorithm (LOA)23, Bat Algorithm (BA)24, Cuckoo Search Algorithm (CSA)25, Firefly Algorithm (FA)26, Artificial Gorilla Troops Optimizer (AGT)27, and the Parrot Optimizer (PO)28. While these algorithms have been applied in various domains and achieved competitive results, MAs are not without limitations. One major challenge is their susceptibility to premature convergence, wherein the algorithm becomes stuck in suboptimal solutions, particularly in highly multimodal or noisy search spaces29,30. Many MAs struggle to maintain a balance between exploration (searching for new solutions) and exploitation (refining existing solutions), often leading to either insufficient exploration or inefficient exploitation31. Another limitation is their sensitivity to parameter settings; poorly chosen parameters can drastically reduce the algorithm’s effectiveness, requiring extensive tuning and increasing computational costs32. These limitations are particularly pronounced in high-dimensional and complex problems33,34. In response to these limitations, researchers have introduced various enhancements to traditional MAs35,36,37,38.
The Parrot Optimizer (PO) is a recently proposed swarm intelligence-based optimization algorithm inspired by the communication and learning behaviors of parrots. Four main behaviors: foraging, staying, talking, and fear of strangers, seen in domesticated Pyrrhura Molinae parrots, are codified into four unique formulas to aid in the search for optimal solutions. Unlike typical metaheuristic algorithms, which have discrete exploration and exploitation phases, each individual in the PO population randomly chooses one of these four behaviors during each iteration. This strategy more accurately represents the behavioral unpredictability observed in domesticated Pyrrhura Molinae parrots while also dramatically increasing population diversity. Due to this non-adaptive optimization approach, PO exhibits certain weaknesses, including premature convergence and an imbalance between exploration and exploitation, particularly in complex, high-dimensional search spaces. This study addresses the limitations of PO by introducing the Salp Navigation and Competitive-based Parrot Optimizer (SNCPO) for ELM training and global numerical optimization. The SNCPO addresses these limitations by combining the exploratory strengths and dynamic transition to the exploitation phase of the SSA with the competitive learning solution refinement capabilities of the CSO. SNCPO achieves a synergistic effect that balances exploration and exploitation while maintaining scalability and adaptability by integrating these two strategies. The key contributions of this research are as follows:
-
1.
Development of the SNCPO Algorithm: This study introduces the SNCPO algorithm by integrating the competitive learning strategy and the salp navigation mechanism. This integration of the salp navigation mechanism enhances the balance and adaptive transition between exploration and exploitation and facilitates local optima escape, as solution refinement through competitive learning effectively searches for better solutions, effectively addressing the limitations of the original PO.
-
2.
Comprehensive Benchmark Evaluation: Rigorous empirical validation is conducted using standard benchmark functions, including the CEC2015 and CEC2020 test suites, to assess the optimization performance of SNCPO.
-
3.
Application to Real-World Engineering Optimization Problems: The effectiveness of SNCPO is further validated through its application to four complex engineering design problems, showcasing its ability to produce high-quality solutions and demonstrating its potential for practical engineering applications.
-
4.
Extensive Experimental Evaluation on ELM Training: A rigorous experimental study is performed to assess the performance of SNCPO in optimizing the parameters of the ELM. The algorithm is tested on 14 datasets.
The manuscript is structured as follows: Sect “Literature review” provides a literature review of the current state of research, and Sect “Materials and methods” covers materials and methods. Sect “Experiment and discussion” discusses the experiment and findings, followed by the conclusion and future work in Sect “Conclusion and future work”.
Literature review
MAs, inspired by natural phenomena and biological processes, have demonstrated remarkable potential in optimizing various aspects of ELMs. Boriratrit et al. demonstrated the effectiveness of integrating algorithms with ELM to enhance forecasting precision. The study introduces a novel framework incorporating several algorithms. Using Thailand’s electric energy demand data, the proposed models were rigorously evaluated against state-of-the-art algorithms. The results show that Jellyfish Search Optimizer (JS) based ELM achieves superior accuracy, as demonstrated by the lowest root mean square error39. Wu et al.'s study investigates the performance of hybrid models combining the ELM with MAs, namely Whale Optimization Algorithm (WOA) and Flower Pollination Algorithm (FPA) for Pan Evaporation (Ep) prediction. The proposed WOA-ELM and FP-ELM models were compared with other ML models. Results demonstrated that FP-ELM achieved the highest accuracy40. Furthermore, Yang et al. proposed a novel method based on the ELM to extract unknown parameters of both electrochemical and simplified electrochemical solid oxide fuel cell models. Eight MAs were utilized for efficient parameter extraction. The performance of optimizer-based ELM was rigorously evaluated, and the results demonstrate the method’s effectiveness in achieving high accuracy, stability, speed, and robustness41. Also, Thieu et al. 's study addresses the challenges traditional models often encounter with nonlinearity, stochastic behavior, and convergence, specifically in accurate river streamflow prediction. The study proposes novel hybrid models combining ELM with advanced MAs, comprising the Runge–Kutta Optimizer (RUN), Weighted Mean of Vectors (INFO), and Pareto-like Sequential Sampling (PSS). Utilizing streamflow data, 20 hybrid models were evaluated. Results exhibited the superiority of mathematically inspired models in terms of accuracy, convergence, and stability. Notably, the PSS-ELM model attained the best performance42. Abba et al., optimized the ELM using four MAs: Genetic Algorithm (GA), PSO, Biogeography-Based Optimization (BBO), and a hybrid BBO-PSO to predict treated water quality parameters. Models performance was evaluated using several metrics. The BBO-PSO-ELM model demonstrated greater predictive performance compared to others43. Bacanin et al.’s. study addresses ELM’s limited performance due to reliance on the optimal tuning of weights and biases in the hidden layer, posing a continuous optimization challenge. To address this limitation, this study proposes a multi-swarm hybrid optimization approach that integrates three swarm intelligence MAs: the Firefly Algorithm (FA), Artificial Bee Colony (ABC), and Sine Cosine Algorithm (SCA). The novel method was rigorously assessed on seven benchmark classification datasets and compared against cutting-edge approaches. Results demonstrate superior generalization performance in terms of accuracy, precision, recall, and F1-score44. Dogan and Ozkan optimized the ELM model with the HHO and the PSO. The results demonstrated that the enhanced ELM models achieved superior stability and accuracy45.
More advanced research has applied hybrid or enhanced MAs, which integrate multiple algorithms or incorporate adaptive strategies to optimize ELM, thus reducing the susceptibility to premature convergence and improving the balance between exploration and exploitation. Zhong et al. introduced a hierarchical RIME algorithm featuring multiple search preferences aimed at addressing complex optimization problems to overcome the drawbacks of the original RIME algorithm, such as preserving population diversity and preventing premature convergence. The proposed algorithm divides the population into inferior, borderline, and superior layers according to their fitness. Each layer employs distinct search operators. The authors conducted extensive experiments on engineering problems, benchmark functions, and ELM optimization. Statistical analyses confirmed the superiority of the novel RIME optimizer, demonstrating its scalability and applicability46. Heidari et al. proposed an improved Grey Wolf Optimizer (GWO), termed OBLGWO, to overcome the shortcomings of the conventional GWO in solving complex optimization problems. The authors addressed its susceptibility to local optima and suboptimal convergence by incorporating opposition-based learning, random spiral-form motions, levy flight patterns, and greedy selection to enhance exploration, exploitation, and search efficiency. The novel OBLGWO was rigorously assessed on benchmark functions and Kernel Extreme Learning Machine (KELM) tuning. The findings underscore the efficacy of OBLGWO as a robust optimization tool for complex, real-world problems47. Cao et al. addressed the limitations of the ELM, particularly the random generation of connection weights and bias during training, which can lead to complexity and reduced generalization ability. To overcome these challenges, the authors introduced an enhanced Crow Search Algorithm (CSA) for optimizing ELM parameters. They incorporated PSO to improve global search effectiveness. In the later stages of iteration, a Gaussian function with a penalty coefficient was introduced to induce local perturbations, adaptively adjust parameters, and avoid entrapment in local optima. The improved CSA was then applied to optimize the ELM weights, achieving accurate prediction results48. Cai et al. proposed a novel parameter tuning strategy for the KELM based on an Improved Grey Wolf Optimization (IGWO) algorithm. Recognizing the critical impact of model parameters on KELM performance, the authors introduced a hierarchical mechanism to enhance the stochastic behavior and exploration capability of grey wolves in the optimization process. Specifically, the strategy incorporated a random local search around the optimal grey wolf for Beta wolves and a random global search for Omega wolves, thereby achieving an improved balance between exploration and exploitation. Experimental findings highlight the potential of IGWO as an effective tool for optimizing KELM parameters, enabling it to achieve superior performance in real-world scenarios49. Liu et al. proposed a modified Parrot Optimizer (PO) for ELM parameter tuning50. The authors proposed a Normal Cloud Parrot Optimization (NCPO) algorithm, which integrates the cloud model with the flocking behavior of Pyrrhura Molinae parrots to improve exploration and exploitation. NCPO-ELM achieved superior forecasting accuracy for photovoltaic energy prediction.
Despite the advancements in MAs for optimizing ELM, several critical gaps persist, limiting their effectiveness in addressing the unique challenges posed by ELM optimization. One of the primary concerns is the scalability of existing MAs when applied to large datasets and high-dimensional features. Many traditional and enhanced optimization techniques struggle to maintain computational efficiency and solution quality as the problem complexity increases. Furthermore, a fundamental limitation of ELM arises from its random initialization of input weights and biases, which directly impacts model generalizability. This randomness often results in suboptimal parameter settings, leading to reduced predictive accuracy and inconsistency across different datasets. Current MAs, while effective in ELM training tasks, lack the adaptive mechanisms required to mitigate the effects of ELM’s inherent limitations and enhance its generalization capability.Additionally, most existing optimization approaches fail to achieve a dynamic balance between exploration and exploitation. While some algorithms prioritize extensive search (exploration) at the cost of slower convergence, others focus on rapid convergence (exploitation), increasing the risk of premature stagnation in local optima. This trade-off remains a persistent challenge in ELM optimization, necessitating the development of algorithms that can dynamically transition between global search and local refinement without compromising convergence speed or solution quality. A critical review of the literature reveals that while traditional and improved MAs have made significant strides in refining ELM optimization, existing approaches still suffer from limited generalizability, suboptimal prediction accuracy, and inefficient adaptation to high-dimensional tasks. These shortcomings underscore the need for advanced hybrid optimization strategies capable of adaptively balancing exploration and exploitation while enhancing ELM’s robustness across diverse problem domains.
Therefore, this research proposes SNCPO to address these gaps and the limitations of the traditional PO. The traditional PO suffers from several critical limitations that hinder its effectiveness in solving complex optimization problems. One of the primary challenges associated with conventional PO is the imbalance between exploration and exploitation, which often results in premature convergence and suboptimal solutions. The lack of an adaptive transition mechanism between these two phases significantly impairs the algorithm’s ability to escape local optima and conduct an efficient global search. Additionally, PO’s static search strategy fails to dynamically adjust to the evolving nature of the optimization landscape, thereby limiting its capacity to refine solutions effectively. To address these shortcomings, the SNCPO algorithm integrates the exploratory strengths and adaptive transition mechanisms of the SSA with the competitive learning-driven refinement capabilities of the CSO approach. SSA’s systematic, chain-based movement strategy enhances global exploration by ensuring a thorough search across the solution space, thereby mitigating the risks of premature convergence and increasing the likelihood of identifying globally optimal solutions. Furthermore, SSA’s adaptive transition mechanism enables a seamless shift from exploration to exploitation, enhancing the overall search efficiency. Simultaneously, CSO introduces a competitive learning paradigm that refines solutions through a population-based selection mechanism. By categorizing candidate solutions into winners and losers, CSO promotes selective updating strategies, where winners are refined using the salp navigation approach derived from SSA, while losers undergo enhancement via PO’s communication-based updating mechanism. This dual refinement strategy fosters diversity in the search process and prevents stagnation. With these complementary strategies, SNCPO achieves a synergistic balance between exploration and exploitation, effectively overcoming the limitations of traditional PO. The algorithm does not only enhance solution accuracy but also ensures adaptability and scalability across diverse and complex optimization problems, such as ELM parameter tuning. Consequently, SNCPO emerges as a robust and efficient optimization framework capable of addressing the complex challenges associated with modern optimization tasks. Although the study by Liu et al.50, has enhanced ELM using an improved PO, our research distinguishes itself by introducing a hybrid and adaptive approach. Specifically, our proposed SNCPO integrates a competitive learning strategy with an adaptive salp navigation mechanism, ensuring a more adaptive balance between exploration and exploitation.
Materials and methods
Parrot optimizer (PO)
The PO draws inspiration from the behavioral traits of Pyrrhura Molinae, a popular parrot species known for its sociability, trainability, and close bonding with owners. This parrot portrays four distinct behaviors namely: foraging, staying, communicating, and fear of strangers. These behaviors form the foundation of the PO algorithm. Foraging involves locating food in groups using visual and olfactory cues. Staying refers to random perching on an owner’s body. Communicating encompasses social interactions within the flock, while fear of strangers drives the birds to avoid unfamiliar individuals and seek safety with their owners. The stochastic nature of these behaviors motivates their integration into the PO framework28. The initial population of candidate solutions is determined randomly within predefined search space bounds. For a swarm size \(N\), maximum iterations \({Max}_{\text{iter}}\), and search space limits \(lb\) (lower bound) and \(ub\) (upper bound), the position of the \({i}^{\text{th}}\) individual is initialized according to Eq. (1).
\(rand(\text{0,1})\) denotes a uniformly distributed random number in the interval \([\text{0,1}]\), and \({X}_{i}^{0}\) represents the initial position of the \({i}^{\text{th}}\) individual. During foraging, individuals estimate food locations based on the host’s position. The positional update is given in Eq. (2).
where \({X}_{i}^{t}\) and \({X}_{i}^{t+1}\) denote the current and updated positions, respectively. \({X}_{\text{best}}\) is the best solution identified so far, \({X}_{\text{mean }}^{t}\) is the average position of the population, and \(Levy(dim)\) models the flight pattern using the Levy distribution. The term \(\left({X}_{i}^{t}-{X}_{\text{best }}\right)\cdot Levy(dim)\) simulates movement toward the host, while the second term incorporates group-level observations. The Levy distribution is computed as expressed in Eq. (3), (4), (5).
Here, \(\gamma =1.5\), and \(\Gamma\) denotes the gamma function. The staying behavior models random perching on the owner’s body. The position update is given in Eq. (6).
Here, ones \((1,dim)\) is a vector of ones representing random stopping points. This equation combines flight toward the host ( \({X}_{\text{best }}\cdot Levy(dim)\) ) and random perching. Communication involves interaction within the flock. Two scenarios are modeled with equal probability: joining the flock or communicating without joining the flock. The update rule is expressed in Eq. (7).
Here, \(P\) is an arbitrary number in \([\text{0,1}]\), and \({X}_{\text{mean }}^{t}\) denotes the flock’s center. To model avoidance of strangers, the update rule incorporates reorientation toward the host and distancing from strangers, as expressed in Eq. (8).
Proposed SNCPO
Salp navigation strategy
The SSA, proposed by Mirjalili et al.16, is a nature-inspired optimization algorithm that emulates the predation behavior of salp swarms. Salps are marine organisms that propel themselves through the water by ingesting it and forming chain-like structures during hunting to facilitate rapid population movement. In SSA, the salp swarm is separated into two roles: leaders and followers. The leader represents the individual at the forefront of the swarm, directing the group toward the prey while the followers come behind, adjusting their positions based on the leader’s movements. This hierarchical structure enables efficient exploration and exploitation of the search area. Leaders, positioned at the front of the swarm, adjust their position according to the position of the target (the best solution identified so far). The position update rule for the leaders in the \({j}^{\text{th}}\) dimension is given in Eq. (9).
Here, \({X}_{j}^{t+1}\) symbolizes the updated ___location of the leader in the \({j}^{\text{th}}\) dimension. \({X}_{j}^{best}\) represents the ___location of the target (best solution) in the \({j}^{\text{th}}\) dimension. \(l{b}_{j}\) and \(u{b}_{j}\) are the lower and upper bounds of the \({j}^{\text{th}}\) dimension, respectively. \({\alpha }_{2}\) and \({\alpha }_{3}\) are arbitrary numbers in the interval [0, 1]. \({\alpha }_{1}\) regulates the trade-off between exploration and exploitation, as shown in Eq. (10).
Here, \(t\) is the current iteration, and \({Max}_{\text{iter}}\) is the maximum number of iterations. The exponential decay of \({\alpha }_{1}\) ensures a gradual shift from exploration (early iterations) to exploitation (later iterations). The position update rule for the \({i}^{\text{th}}\) follower in the \({j}^{\text{th}}\) dimension is given in Eq. (11):
where \({X}_{j}^{t+1}\) designates the updated ___location of the \({i}^{\text{th}}\) follower in the \({j}^{\text{th}}\) dimension. The random parameters \({\alpha }_{2}\) and \({\alpha }_{3}\) in the leader update equation introduce stochasticity into the search process of SNCPO. This randomization allows the algorithm to explore portions of the search region that may otherwise remain unexplored, thereby boosting the likelihood of discovering globally optimal solutions. In SNCPO, this stochastic movement complements the interactions among search agents, preventing an early convergence of the population to suboptimal solutions. The exponential decay of \({\alpha }_{1}\) ensures a seamless transition from exploration to exploitation in SNCPO. During early iterations, when \({\alpha }_{1}\) is large, the leader explores more regions of the search space, increasing diversity. As \({\alpha }_{1}\) decreases over time, the leader focuses on exploiting promising regions near the best-known solution.
Competitive learning strategy
Competitive Swarm Optimization (CSO) is a recently developed variation of the PSO algorithm51. Unlike traditional PSO, which relies on personal best and global best locations to guide particle updates, CSO operates by retaining only the position \({X}_{i}^{t}=\left[{x}_{i,1}^{t},{x}_{i,2}^{t},\dots ,{x}_{i,D}^{t}\right]\) and velocity \({V}_{i}^{t}=\left[{v}_{i,1}^{t},{v}_{i,2}^{t},\dots ,{v}_{i,D}^{t}\right]\), here \(t\) denotes the generation index, and \(D\) represents the dimensionality of the problem52. In each generation, the population of \(N\) particles is arbitrarily split into \(N/2\) groups, with each group consisting of two particles. Among these pairs, the particle with better fitness is designated as the winner, while the other is labeled as the loser. The winners are carried over to the next generation without modification, whereas the losers undergo an update process that incorporates learning from the winners. This mechanism ensures that the population evolves through competition, promoting diversity and effective exploration. The losers are updated as mathematically expressed in Eqs. (12), (13).
\(l\) and \(w\) designate the indices of the loser and winner particles, respectively. \({X}_{l}^{t}\) and \({V}_{l}^{t}\) denote the ___location and velocity of the loser at generation \(t\). \({X}_{w}^{t}\) is the ___location of the corresponding winner particle. \(\overline{X}^{t}\) is the average ___location of the whole population at generation \(t\), \(\phi\) is a parameter that regulates the impact of the population’s average position \(\overline{X}^{t}\) on the loser’s movement. \({R}_{1},{R}_{2}\), and \({R}_{3}\) are uniform random numbers determined within the interval [0, 1]. The selection of winners and losers in the CSO algorithm is a pivotal step that governs the competitive interactions within the population. This process involves a pairing mechanism to ensure unbiased comparisons between individuals. The winner of the pair is determined based on the fitness values of the two individuals randomly chosen from the population. Mathematically, this is expressed as seen in Eq. (14).
fitness \(\left({p}_{1}\right)\) and fitness \(\left({p}_{2}\right)\) represent the objective function values of the respective particles randomly selected from the search population. The individual with the better (lower) fitness value is designated as the winner. The loser of the pair is determined as expressed in Eq. (15).
In this case, the individual with the inferior (higher) fitness value is labeled as the loser. The proposed SNCPO approach splits the individuals into two sets: winners and losers, based on fitness evaluations. This competitive learning mechanism ensures that only the fittest individuals (winners) directly influence the evolution of the population, while the less fit individuals (losers) undergo guided updates to improve their positions. By splitting the population, the algorithm introduces a dual-layered optimization process. Winners represent the elite solutions and are updated using the leader strategy from SSA, which promotes exploration and efficient transition to exploitation. Losers are updated using the communication strategy from PO to promote exploration and communication within the population. This division ensures that the model simultaneously focuses on refining promising solutions and exploring new portions of the search space.

Pseudo-code of the SNCPO algorithm.
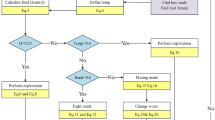
As seen in Algorithm 1, SNCPO initializes its parameters at the initial stage, which include population size \(N\), maximum iterations \({Max}_{\text{iter,}}\), and control parameters such as \({\alpha }_{1}\). The optimization process proceeds iteratively for \({Max}_{\text{iter}}\) iterations, during which the fitness function is computed for each solution to assess its quality, and the best and worst positions are identified to guide the search process. A key feature of SNCPO is its competitive learning mechanism, where the population is randomly paired, and individuals are classified as winners or losers based on their fitness values using pairwise comparison using a permutation list as expressed in Eq. (14) and (15). Winners representing elite solutions are updated using the leader update mechanism from the SSA, as seen in Eq. (9), which refines their positions near the best-known solution to enhance exploitation and exploration. The \({\alpha }_{1}\) parameter dynamically adjusts the transition from exploration as iteration increases. In the early stages, winners can efficiently search the problem space for near-global solution regions; as iteration reaches the maximum, winners can gradually refine their solutions. Conversely, losers, representing less fit solutions, are updated using the PO communication strategy, as seen in Eq. (8), which promotes exploration by encouraging diverse movements within the search space. Upon completing all iterations, the algorithm returns the best solution found, representing the optimal or near-optimal position in the search space. Combining competitive learning with SSA’s salp navigation and PO strategies, this hybrid approach enables SNCPO to successfully address complex optimization problems by leveraging the complementary strengths of exploration and exploitation, adaptively transitioning between exploration and exploitation, compared to the traditional PO, which randomly applies different strategies to the population. Thereby ensuring strong performance across various problem domains. The Flowchart of SNCPO is illustrated in Fig. 1.

SNCPO flowchart.
Computation complexity of SNCPO
The computational complexity of the SNCPO algorithm can be analyzed by examining the key operations performed during its execution. Initially, the algorithm requires \(O(N\cdot D)\) computations for the random initialization of \(N\) solutions within a \(D\)-dimensional problem space. During each iteration, the fitness function is evaluated for all \(N\) solutions, incurring a cost of \(O(N\cdot F)\), where \(F\) represents the computational cost of evaluating the fitness function for a single solution. Additionally, the pairwise competition process involves generating a random permutation of the population and performing fitness-based comparisons, which collectively require \(O(N)\) operations. The position updates for winners and losers, guided by the salp navigation and PO strategies, respectively, involve arithmetic operations and random number generation, contributing \(O(N\cdot D)\) computations per iteration. Since these steps are repeated for \({Max}_{\text{iter}}\) iterations, the total computational complexity of SNCPO is \(O(\left.{\text{Max}}_{\text{iter }}\cdot N\cdot (F+D)\right)\).
ELM training
Original ELM
The ELM is a feed-forward neural network characterized by its single hidden layer, which has demonstrated exceptional performance in both regression and classification tasks3. Unlike traditional neural network-based methods, ELM eliminates the need for iterative tuning of hidden layer parameters. Instead, the weights and biases of the input layer neurons are arbitrarily assigned45. The activation functions for the hidden layer neurons can include Sigmoid, ReLU, or Tanh functions, while a linear activation function is typically employed for the output layer neurons. As illustrated in Fig. 2, ELM’s architecture comprises three layers: the input, hidden, and output. For an ELM network with \(M\) neurons in the hidden layer and \(N\) samples, the output of the model can be mathematically expressed as given in Eq. (16).
where \({o}_{j}\) denotes the output vector of the ELM. \({\beta }_{i}\) denotes the output weights linking the hidden layer to the output layer. \(g(\cdot )\) is the activation function applied to the hidden layer neurons. \({w}_{i}\) represents the input weights connecting the input layer to the hidden layer. \({b}_{i}\) is the bias value associated with the \({i}^{\text{th}}\) hidden neuron. \({x}_{j}\) is the \({j}^{\text{th}}\) input sample. The hidden layer output matrix \(H\) can be calculated as defined in Eq. (17) from Eq. (16).

ELM model.
Then, Eq. (17) can be converted into matrix form, as shown in Eq. (18).
There \(H\) is the hidden layer output matrix, explicitly defined in Eq. (19).
\(\beta\) which is the output weight vector is expressed in Eq. (20)
\(y\) which is the target output vector is defined in Eq. (21)
In the ELM approach, the input weights \({w}_{i}\) and biases \({b}_{i}\) are arbitrarily allocated, and the output weights \(\beta\) are computed using the generalized inverse Moore–Penrose (MP) matrix of \(H\). Specifically, the output weights \(\hat{\beta }\) are calculated as given in Eq. (22)
where \(\hat{\beta }\) is the approximate output weight vector. \(H^{\dag }\) is the Moore–Penrose generalized inverse of the hidden layer output matrix \(H\).
Proposed SNCPO-ELM model
The individual vectors within the population used for optimization in SNCPO-ELM model are constructed as a combination of input weights \((w)\) and hidden biases (b). The proposed SNCPO is employed to calculate the optimal input weights and biases, with the goal of enhancing the performance of the ELM classifier on several datasets. The search for the best solution occurs within a \((n\times H+H)\) dimensional search space, where \(n\) denotes the number of input features, and \(H\) represents the number of hidden neurons. Both \({w}_{i}\) (input weights) and \({b}_{i}\) (hidden biases) are randomly initialized within the range \([-\text{10,10}]\). For each individual in the SNCPO population, the corresponding output weights are calculated, and the fitness of each individual is subsequently assessed. The fitness of each individual is evaluated based on the classification accuracy achieved on the training set. Accuracy is a widely used metric in classification studies and measures the proportion of correct predictions relative to the overall number of samples. It is mathematically expressed Eq. (23)
Here \({T}_{P}\) denotes the true positives and represents correctly predicted positive samples. \({T}_{N}\) represents true negatives, representing correctly predicted negative samples. \({F}_{P}\) is false positives, representing incorrectly predicted positive samples. While \({F}_{N}\) is false negatives, represents incorrectly predicted negative samples. The SNCPO-ELM model is shown in Fig. 3.

SNCPO-ELM model.
Experiment and discussion
To validate the robustness and credibility of the experimental results, this study exclusively utilizes the CEC 201553 and CEC 202054 benchmark suites. These benchmark functions are systematically classified into distinct categories. For the CEC 2015 suite, the functions are grouped as follows: F1-F2 represent unimodal functions, F3-F5 denote simple multimodal functions, F6-F8 correspond to hybrid functions, and F9-F15 encompass composition functions. Similarly, the CEC 2020 test suite comprises F16, which includes single-modal functions; F17-F19, representing basic multimodal functions; F20-F22, grouped as hybrid functions; and F23-F25, which consists of composition functions. The parameter configurations for each algorithm used in the experiment for comparison are comprehensively outlined in Table 1. Key experimental parameters have been carefully defined to maintain consistency and fairness in the evaluation process. These include a maximum iteration limit of 5000, 30 independent runs for statistical reliability, a problem dimensionality of 30, and a population size of 30. The proposed SNCPO algorithm is benchmarked against a set of comparative algorithms, which are as follows: Parrot Optimizer (PO)28, Aquila Optimizer (AO)55, Exponential Distribution Optimizer (EDO)56, Grey Wolf Optimizer (GWO)57, Moth Flame Optimization (MFO)58, Opposition Based Learning Path Finder Algorithm (OBLPFA)59, Sine Cosine Algorithm (SCA)60. This rigorous setup ensures that the performance evaluations are both comprehensive and rigorous.
Statistical and convergence analysis of compared optimizers on the CEC2015
To comprehensively evaluate the efficacy of the SNCPO algorithm, an extensive experiment using the CEC2015 benchmark functions is conducted, comparing its performance against several state-of-the-art optimization algorithms. The experimental results, as summarized in Table 2, illustrate the superior performance of SNCPO across multiple optimization functions. In Table 2, the best results obtained for each function are highlighted in bold, underscoring the effectiveness of SNCPO in solving complex optimization tasks. A thorough analysis of Table 2 reveals that the SNCPO algorithm consistently achieves near-optimal solutions across a wide range of benchmark functions, significantly outperforming the original PO algorithm. This superior performance can be attributed to SNCPO’s ability to maintain a well-balanced interplay between global exploration and local exploitation, which is a critical factor in achieving optimal solutions. Additionally, Table 2 presents key performance evaluation metrics, including the average (AVG) and standard deviation (STD) values, providing valuable insights into the comparative performance of SNCPO relative to other optimization approaches.
Upon scrutinizing the statistical results of SNCPO on the CEC2015 benchmark suite, it becomes evident that SNCPO outperforms seven competing optimization algorithms in both convergence accuracy and stability. Specifically, for unimodal functions F1 and F2, SNCPO consistently attains more optimal solutions compared to other approaches, such as MFO, EDO, and GWO. This clearly demonstrates the enhanced exploitation capabilities of SNCPO, which stem from its strategic incorporation of competitive learning and adaptive salp navigation techniques. The ability of SNCPO to refine solutions efficiently allows it to surpass traditional optimization techniques, making it highly suitable for unimodal function optimization. For multimodal functions (F3–F5), SNCPO continues to demonstrate its robustness by effectively navigating complex search landscapes. Although GWO exhibits strong convergence behavior in F3, SNCPO maintains competitive performance across these functions, particularly in F4 and F5, where its AVG values surpass those of PO, AO, and SCA. This suggests that the integration of salp navigation and competitive learning strategies significantly enhances the algorithm’s ability to escape local optima and explore promising regions of the search space. The capacity to transition seamlessly between exploration and exploitation enables SNCPO to exhibit superior optimization performance in problems where conventional optimizers struggle.
While GWO achieves the best results for F3, SNCPO’s performance aligns with the No Free Lunch (NFL) theorem, which asserts that no single optimization algorithm can universally outperform all others across all problem types. Nevertheless, SNCPO continues to demonstrate strong convergence characteristics in multimodal functions, highlighting its adaptability and robustness. In the case of hybrid functions (F6–F8), which assess an algorithm’s ability to balance exploration and exploitation effectively, SNCPO exhibits notable performance improvements. Although its performance in F6 is slightly less optimal compared to other methods, it demonstrates a significant advantage in F7 and F8, achieving superior convergence results. The improved performance in these functions can be attributed to SNCPO’s adaptive exploration–exploitation mechanism, which dynamically adjusts the search strategy based on the characteristics of the optimization problem. Similarly, for composite functions (F9–F15), which present highly complex and irregular search landscapes, SNCPO exhibits remarkable performance, particularly in F10, F12, and F13. The superior performance of SNCPO in these functions underscores its capability to effectively manage optimization problems that require simultaneous exploration of multiple diverse regions while refining solutions to achieve high accuracy. This success is largely due to the combined impact of competitive learning and adaptive salp navigation strategies, which provide the algorithm with a refined ability to transition smoothly between search phases. While SNCPO generally outperforms other optimization techniques, there are instances where it achieves slightly less optimal solutions compared to MFO and EDO. However, the overall statistical results confirm its reliability and robustness, as evidenced by its consistently strong performance across multiple problem types.
Although Table 2 provides valuable statistical insights into the numerical performance of SNCPO and its comparative algorithms, it does not offer a clear depiction of their convergence behaviors over iterations. This crucial aspect of algorithm evaluation is instead illustrated in Figs. 4 and 5, which present convergence curves and box plots, respectively. Figure 4, which showcases the convergence trajectories of SNCPO and other algorithms, reveals that SNCPO achieves significantly faster convergence rates compared to most competing optimizers across the majority of benchmark functions. This rapid convergence can be attributed to SNCPO’s salp navigation and competitive learning strategies, which enable search agents to thoroughly explore promising solution regions in the early stages of optimization while ensuring rapid convergence toward optimal solutions in later iterations. As depicted in Fig. 4, SNCPO demonstrates a gradual yet decisive descent in functions F1 and F2, highlighting its superior exploitation capabilities compared to PO, AO, EDO, GWO, OBLPFA, MFO, and SCA. This performance advantage arises from the integration of competitive learning refinement techniques and the adaptive salp navigation mechanism, both of which facilitate an effective and adaptive transition between exploration and exploitation. For multimodal functions (F3–F5), the convergence patterns further reinforce SNCPO’s superior search efficiency. While GWO exhibits noteworthy convergence characteristics in F3, SNCPO demonstrates exceptional local escaping capabilities in F4 and F5. This is evident in the continued descent of its convergence curve, in contrast to the relatively stagnant trends observed in OBLPFA, SCA, and EDO. SNCPO’s improved performance in these functions is a direct consequence of its enhanced adaptive exploration strategy, which enables it to avoid premature convergence and systematically refine solutions to achieve optimal accuracy. In hybrid functions (F6–F8), which pose a significant challenge due to their intricate mixture of multiple function landscapes, SNCPO displays a well-balanced transition between exploration and exploitation. However, while it shows slightly suboptimal performance in F6, its ability to dynamically adjust its search behavior results in superior convergence in F7 and F8. The enhanced adaptability of SNCPO in these functions ensures that it consistently identifies high-quality solutions, reinforcing its competitive advantage over conventional algorithms. Lastly, in composite functions, which represent some of the most complex optimization landscapes, SNCPO achieves outstanding performance, particularly in F10, and F12. This success can be attributed to its refined exploitation-exploration balance, which is facilitated by the synergistic effects of competitive learning and the adaptive salp navigation strategy. These methodological enhancements collectively contribute to SNCPO’s strong convergence efficiency, positioning it as a powerful tool for addressing complex real-world optimization problems.


Convergence chart of SNCPO and other optimizers on CEC2015.


Box plots of SNCPO and other optimizers on CEC2015.
Beyond convergence analysis, the stability and reliability of SNCPO were further assessed through box plot evaluations, as illustrated in Fig. 5. The box plots provide a statistical representation of solution variability across multiple independent runs, thereby offering insights into the consistency of each algorithm. As seen in Fig. 5, the reduced lengths of SNCPO’s box plots indicate minimal variation across different optimization runs, confirming its strong reliability and stability. This consistency is particularly important in practical applications, where reliable convergence to high-quality solutions is essential. The observed stability of SNCPO can be attributed to its robust search strategy, which prevents erratic behavior and ensures that the algorithm maintains a steady convergence trajectory.
Statistical and convergence analysis of compared optimizers on the CEC2020
To rigorously evaluate the optimization capabilities of the proposed SNCPO algorithm, the CEC2020 benchmark functions were employed to assess its effectiveness in comparison with state-of-the-art optimization techniques. These benchmark functions, which encompass unimodal, multimodal, hybrid, and composite functions, serve as a comprehensive test to validate the efficacy and robustness of optimization algorithms in solving complex numerical optimization problems. The experimental outcomes for the SNCPO algorithm, alongside the comparative optimizers, are systematically presented in Table 3. As evidenced in Table 3, the SNCPO algorithm consistently outperforms the other algorithms across multiple benchmark functions. Specifically, for functions F16, F17, F18, F19, F20, F21, F22, F24, and F25, SNCPO achieves significantly lower average (AVG) values, demonstrating its superior convergence properties and ability to attain high-quality solutions. More notably, in the case of unimodal functions F17, F18, and F19, SNCPO exhibits remarkable performance by achieving the best mean values across all competing algorithms. This superior performance underscores SNCPO’s enhanced exploitation capabilities, which can be attributed to its refined solution refinement strategies facilitated by the integration of the competitive learning technique and the adaptive salp navigation strategy.
In contrast, competing algorithms such as AO, EDO, OBLPFA, and MFO exhibit suboptimal performance in addressing unimodal functions due to their inherent limitations in achieving adequate exploitation. These algorithms tend to yield suboptimal solutions due to premature convergence and insufficient refinement mechanisms, which hinder their ability to explore promising regions effectively. SNCPO, however, overcomes these challenges by leveraging its competition-based learning approach, which enhances solution refinement and strengthens its capacity to converge toward optimal solutions with greater precision. For multimodal functions spanning F20 to F22, SNCPO once again demonstrates superior optimization capabilities, achieving the best mean values across these benchmark functions. The inherent difficulty of multimodal functions lies in their complex landscape, which consists of numerous local optima that can mislead optimization algorithms into suboptimal regions. Despite this challenge, SNCPO exhibits a strong ability to navigate these complex search spaces effectively. In contrast, EDO, GWO, MFO, and OBLPFA achieve comparatively lower mean values when solving multimodal functions, indicating their limitations in escaping local optima and maintaining solution diversity. SNCPO’s superior performance in these functions is largely attributed to its adaptive salp navigation strategy, which facilitates a balanced transition between exploration and exploitation. This adaptive mechanism ensures that the algorithm does not stagnate in local optima, thereby improving the overall convergence behavior. With regard to hybrid functions (F23–F25), SNCPO further distinguishes itself by demonstrating superior convergence capabilities, particularly in functions F24 and F25, where it achieves the best mean values. The hybrid functions in CEC2020 are designed to assess an optimizer’s ability to effectively transition between exploration and exploitation, given their composition of multiple distinct sub-functions with varying characteristics. While GWO exhibits competitive performance in handling hybrid functions and achieves a superior solution in F23, SNCPO remains the dominant algorithm in F24 and F25 due to its efficient transition strategy between exploration and exploitation. This advantage is directly linked to the fusion of the competitive learning technique with the adaptive salp navigation strategy, which collectively enhances SNCPO’s capability to dynamically adjust its search behavior based on the problem landscape.
To further investigate the search efficiency of SNCPO and its comparative algorithms, a detailed visual examination was conducted through the analysis of convergence curves, as illustrated in Fig. 6. These convergence curves provide insights into each algorithm’s search efficiency and optimization dynamics when tackling the challenging CEC2020 benchmark test functions. By analyzing these curves, a deeper understanding of the algorithms’ convergence behaviors can be obtained, shedding light on their ability to effectively explore and exploit the search space. Notably, the proposed SNCPO algorithm demonstrates highly competitive convergence speeds, successfully identifying promising solution regions of the benchmark functions at various stages of the optimization process. A consistent pattern of a steep decline is evident across all convergence curves of SNCPO, particularly in functions F16, F17, F18, F19, F20, F21, F22, F24, and F25. This observation highlights SNCPO’s exceptional ability to rapidly identify high-quality solutions during the early stages of the optimization process. Such an ability is crucial for real-world optimization applications, where rapid convergence to optimal or near-optimal solutions is often required. Additionally, Fig. 6 provides empirical evidence of SNCPO’s robust exploration capability, as observed through the consistent spread of solutions across the optimization process. The ability to maintain exploration throughout the search space is a critical attribute of an effective optimization algorithm, ensuring that it does not become trapped in local optima. This is primarily attributed to the adaptive salp navigation strategy, which allows SNCPO to sustain a dynamic balance between exploration and exploitation. Unlike other algorithms that exhibit premature convergence or stagnation, SNCPO effectively mitigates these issues by strategically switching between search phases, thereby enhancing its overall optimization performance. Furthermore, the convergence curves reveal that SNCPO achieves a steady decline in mean values during the early iterations while maintaining variability, which signifies its capacity to explore diverse regions of the search space before converging towards the global optimum in later iterations. This gradual yet directed convergence process is instrumental in ensuring the robustness and reliability of the algorithm across multiple optimization scenarios. Beyond convergence analysis, the robustness and consistency of the SNCPO algorithm were further examined through box plot analysis, as presented in Fig. 7. Box plots offer a visual representation of the performance stability of each optimization algorithm across multiple independent runs. The results depicted in Fig. 7 highlight SNCPO’s remarkable consistency, as indicated by the reduced length of the box plots. The shorter box lengths suggest lower variability in the obtained solutions, reflecting the algorithm’s ability to consistently achieve stable and reliable optimization outcomes across different trials.


Convergence chart of SNCPO and other optimizers on CEC2020.

Convergence chart of SNCPO and other optimizers on CEC2020.
Time complexity analysis
Tables 4 and 5 present the average computation times (in seconds) of the proposed SNCPO algorithm and traditional optimizers on the CEC2015 and CEC2020 benchmark functions. The results reveal a clear computational advantage for the AO and SNCPO algorithms over conventional methods. Notably, traditional optimizers such as GWO, MFO, OBLPFA, and SCA consistently exhibit higher computational demands, with MFO demonstrating the most pronounced inefficiency across both benchmark suites. This underperformance of MFO is attributed to its reliance on complex flame attraction mechanisms and iterative parameter adjustments, which amplify computational overhead, particularly in high-dimensional or multimodal landscapes. The AO algorithm, however, achieves the lowest average computation time across all test functions in both CEC2015 and CEC2020. This efficiency is primarily due to its minimalist design, characterized by a low-parameter configuration and reduced number of iterative loops. The absence of redundant calculations enables AO to minimize computational burden while maintaining robust search capabilities.
When comparing the SNCPO algorithm to its predecessor, the traditional PO algorithm. As shown in Table 4 (CEC2015), the original PO algorithm requires significantly longer computation times than SNCPO in the majority of functions, with exceptions observed only in F1, F2, F6, and F7. A similar pattern is evident in Table 5 (CEC2020), where SNCPO outperforms PO in most functions except F16, F17, and F18. This disparity is rooted in the redesign of SNCPO optimization process, which eliminates redundant mathematical operations inherent in the traditional PO framework. Specifically, SNCPO adopts a dual-update strategy: winners are refined using the SSA operator, while losers are updated via PO’s communication strategy. This structural simplification reduces computational loops and arithmetic complexity, thereby minimizing overhead without compromising solution quality. While SNCPO demonstrates superior average performance, the residual cases where PO outperforms SNCPO highlight the influence of problem-specific characteristics. For instance, in low-dimensional or unimodal functions (e.g., F1, F2), the overhead of SNCPO’s SSA operator may outweigh its benefits, whereas PO’s straightforward position update mechanism executes more efficiently. Also, functions with regular or symmetric landscapes align more closely with PO’s inherent design principles, enabling it to converge rapidly with less accurate results. Conclusively SNCPO showed improved computational cost compared PO.
Non-parametric analysis
In this study, the Wilcoxon signed-rank test61 was employed as a nonparametric statistical method with a significance threshold of 0.05. According to the Wilcoxon signed-rank test, if the p-value falls below the significance level, it implies a statistically significant improvement. On the contrary, if the p-value surpasses the significance level, it implies no notable difference between the methods being compared. This approach allows for a robust performance contrast between the SNCPO and compared algorithms. Additionally, the Friedman test62 was utilized to assess the average rankings of the algorithms, providing additional insight into their overall performance. As shown in Table 6, the results of the Friedman test reveal that the SNCPO ranks first among the compared algorithms, demonstrating its ability to deliver superior solutions on the benchmark test suite. A detailed examination of the Wilcoxon signed-rank test results highlights the strong competitive edge of the SNCPO over other optimizers, with statistically significant improvements observed in the majority of instances. However, it is important to acknowledge that GWO exhibited enhanced performance in a few benchmark functions. Despite this, the SNCPO consistently outperforms the majority of its counterparts, reaffirming its effectiveness and reliability in optimization scenarios.
Exploration vs exploitation
Analyzing the equilibrium between the exploration and exploitation stages of the SNCPO can yield valuable insights for addressing real-world optimization challenges. To ensure a thorough evaluation of the SNCPO, this study delves into the algorithm’s exploration and exploitation abilities based on the benchmark functions examined. Figure 8 illustrates the balance between the exploratory and exploitative behaviors of the SNCPO. In the figure, the red curve represents the algorithm’s exploration tendencies, and the blue curve highlights its exploitation abilities. From Fig. 8, it is evident that for relatively straightforward unimodal functions (F1, F16) and simple multimodal functions (F5), the exploration ratio remains low meaning SNCPO was swift in identifying promising regions quickly. In the case of F5, the SNCPO briefly alternates between exploration and exploitation during the early stages of iteration, aiming to maintain a dynamic equilibrium. As observed in Fig. 8, when tackling more intricate hybrid functions (F20) and composition functions (F9, F25), the SNCPO sustains a balanced interplay between exploration and exploitation. However, there is a noticeable decline in exploration as the algorithm identifies promising regions, followed by an intensified focus on exploitation.

Exploration vs exploitation analysis of SNCPO.
An exception is observed in F9, where the SNCPO initially increases the proportion of exploration while reducing exploitation until the mid-iteration phase. This adjustment serves to expand the global search, thereby mitigating the risk of the algorithm being confined in deceptive local optima when handling more complex functions. The SNCPO enhances its exploration behavior through the salp navigation and PO mechanism, which introduces diversity into the population. By continuously adapting the search ___domain in this manner, the algorithm ultimately converges to the global optimum as the slap navigation transitions to the exploitation strategy.
Engineering problem
Welded beam problem (WBP)
The Welded Beam Design (WBD) is a real-world engineering problem focused on minimizing the fabrication cost of a welded beam. Figure 9 illustrates the design configuration along with its corresponding mathematical formulation63. Equation (24) and (25) are minimized based on the constraints in Eq. (26) to (40).
While: \(0.1\le {x}_{1},{x}_{4}\le 2\text{ and }0.1\le {x}_{2},{x}_{3}\le 10\).

Welded beam design illustration.
Compression spring problem (CSP)
The objective of the CSP is to reduce the spring’s weight, posing a practical challenge in engineering. Figure 10 illustrates the schematic of the design, and the mathematical model for it is presented below 63. Equation (41) and (42) are minimized based on the constraints in Eq. (43) to (46).

Tension/compression spring design illustration.
Speed reducer design (SRD)
The optimization of speed reducer designs has attracted significant interest within the field of mechanical engineering, given its crucial role in controlling machine speeds. The main goal of this optimization process is to minimize the weight of the speed reducer while adhering to the constraints set by its essential components. Seven key design variables are critical in determining the weight: the gear face width (\({x}_{1}\)), the teeth module (\({x}_{2}\)), the number of pinion teeth (\({x}_{3}\)), the length of the first shaft between bearings (\({x}_{4}\)), the length of the second shaft between bearings (\({x}_{5}\)), and the diameters of the first (\({x}_{6}\)) and second shafts (\({x}_{7}\))64. A schematic representation of this problem is provided in Fig. 11, and the mathematical formulation is expressed in Eq. (47) subject to Eq. (48) to (58).
with \(\begin{gathered} 2.6 \le x_{1} \le 3.6,{\text{~}}0.7 \le x_{2} \le 0.8,{\text{~}}2.6 \le x_{1} \le 3.6,{\text{~}}17 \le x_{3} \le 28,{\text{~}}7.3 \hfill \\ \le x_{4} \le 7.8,\;7.8 \le x_{5} \le 8.3,{\text{~}}2.9 \le x_{6} \le 3.9\;{\text{and }}5 \le x_{7} \le 5.5\;. \hfill \\ \end{gathered}\)

Speed reducer design.
Three bar Truss design (TBTD)
The aim of this problem is to reduce the weight of the structure, as depicted in Fig. 1265. This optimization task can be redefined as a problem involving two parameters, denoted as \({x}_{1}\) and \({x}_{2}\). Let \(X\) = [\({x}_{1}\),\({x}_{2}\)], where \({x}_{1}\) and \({x}_{2}\) are randomly chosen from the interval [0, 1]. The mathematical representation of Fig. 12 is provided in Eq. (59), while the constraints are specified in Eqs. (60), (61), and (62).
where: \(l = 100{\text{cm}};P = \frac{2kN}{{{\text{cm}}^{2} }};\sigma = \frac{{2{\text{kN}}}}{{{\text{cm}}^{2} }},\;{\text{Interval}}:0 \le x_{1} ,x_{2} \le 1\)

Three-bar Truss design parameters.
Table 7 provides a comprehensive statistical evaluation of the experimental results obtained from the comparative analysis of SNCPO and other state-of-the-art optimization algorithms across four challenging engineering optimization problems. The experimental setup for this evaluation is consistent with previous benchmarks, with an iteration count of 5000 and a population size of 30. To ensure a fair and unbiased comparison, the parameter settings outlined in Table 1 were maintained across all competing optimization techniques. The results in Table 7 present the AVG and STD values obtained over 30 independent runs, offering valuable insights into the performance, stability, and reliability of each algorithm. A thorough assessment of the statistical findings clearly demonstrates that SNCPO emerges as a highly competitive optimization approach, consistently identifying near-optimal or optimal solutions in the majority of the tested engineering problems. Its effectiveness is highlighted by its ability to achieve the lowest AVG function values for several problem instances while maintaining competitive performance in others. These findings underscore the robustness and adaptability of SNCPO, reinforcing its potential for solving complex real-world engineering optimization tasks. More specifically, the results in Table 7 reveal that SNCPO achieved the best mean value for both the WBP and the CSP. This superior performance underscores the algorithm’s capacity to navigate complex constraint landscapes while effectively balancing exploration and exploitation. The ability of SNCPO to outperform other algorithms in these engineering problems suggests that the newly introduced search strategy effectively guides the optimization process toward optimal solutions while maintaining solution feasibility and constraint satisfaction.
In the case of the TBTD problem, SNCPO exhibited highly competitive performance relative to other cutting-edge metaheuristic algorithms. Specifically, its results were on par with those achieved by AO, EDO, and OBLPFA, with SNCPO obtaining one of the best mean values for this problem. This further illustrates the algorithm’s robustness, demonstrating that SNCPO is well-equipped to handle engineering design problems characterized by complex nonlinear constraints and multiple interacting decision variables. The ability to maintain competitive performance in structural design optimization highlights the efficiency of SNCPO in balancing exploration and convergence precision. For the SRD problem, the experimental results indicate that MFO achieved the most optimal mean value. However, SNCPO still exhibited commendable competitiveness, achieving mean values that closely approached that of MFO. This finding aligns with the No Free Lunch (NFL) theorem, which postulates that no single optimization algorithm can consistently outperform all others across all problem types. The variation in performance across different problems reaffirms that different optimization strategies are more suited to specific problem structures. Despite MFO obtaining the best mean solution for SRD, SNCPO demonstrated a strong capacity to explore high-quality solutions, further establishing its credibility as a reliable engineering optimization algorithm. In addition to the numerical statistical analysis presented in Table 7, the convergence behavior of SNCPO, alongside the other compared algorithms, is depicted in Fig. 13. These convergence plots provide a visual representation of the solution progression over iterations, offering deeper insights into the search efficiency and optimization dynamics of each algorithm. The ability of SNCPO to converge rapidly toward high-quality solutions reinforces its practical applicability in engineering design problems, where computational efficiency and solution accuracy are of paramount importance.

Convergence curve of SNCPO and other optimizers on engineering problems.
Experiments in ELM training
In this section, the parameter settings outlined in Table 1 are consistently applied across all competing optimization algorithms to ensure a fair and unbiased comparison. The number of iterations is set to 50, and the search range for determining the optimal weight and bias values of the ELM model is within the range of -10 to 10. To comprehensively evaluate the effectiveness of the SNCPO in optimizing the ELM model, 14 benchmark datasets obtained from the UCI Machine Learning Repository66 were utilized. Table 8 provides a detailed description of these datasets, capturing their key characteristics, such as the number of instances, attributes, and problem complexity. The experimental results, which summarize the accuracy performance in terms of the average (AVG) and standard deviation (STD) over 30 independent runs, are presented in Table 9. These results provide critical insights into the optimization effectiveness of SNCPO when employed in machine learning parameter tuning, particularly in training the ELM model. The findings indicate that the SNCPO consistently outperforms its counterparts, delivering superior accuracy across the majority of datasets. This underscores its robustness, stability, and efficiency in optimizing neural network parameters, which are crucial for ensuring high generalization performance in predictive modeling tasks. A more detailed analysis of Table 9 reveals that the SNCPO achieves superior average accuracy across most datasets compared to conventional optimization algorithms, including the PO, AO, EDO, MFO, OBLPFA, and SCA. The superior performance of SNCPO can be directly attributed to its innovative hybridization of competitive learning and the salp navigation strategy, which synergistically enhance its exploration and exploitation capabilities. By leveraging competitive learning, SNCPO facilitates improved solution refinement, ensuring that optimal weight and bias values are efficiently identified for ELM training. Simultaneously, the salp navigation strategy enables dynamic adjustments in the search process, preventing premature convergence and promoting global search efficiency.
Furthermore, the adaptability of SNCPO in handling machine learning optimization tasks is evident from its ability to maintain stable performance across multiple independent runs, as reflected in its relatively low STD values in Table 9. This stability is a key factor in real-world applications, where machine learning models require consistent optimization to deliver reliable predictions. The superior balance between exploration and exploitation achieved by SNCPO ensures that it effectively navigates complex search spaces, leading to optimal solutions that enhance the predictive accuracy of ELM. The experimental findings presented in this section affirm that the SNCPO is highly effective in machine learning parameter optimization. Its ability to outperform existing optimization techniques demonstrates its practical utility in training ELM models and, by extension, other machine learning architectures that rely on efficient parameter tuning. Given these promising results, future research could further explore the application of SNCPO in optimizing deep learning models, hyperparameter tuning, and feature selection, reinforcing its relevance in advancing the field of artificial intelligence.
Conclusion and future work
In this study, we introduced the SNCPO, a novel hybrid metaheuristic algorithm designed to overcome the inherent limitations of the traditional PO. By integrating the pairwise competitive learning strategy from CSO with the adaptive navigation mechanism of the SSA, SNCPO effectively enhances population diversity, mitigates premature convergence, and achieves a well-balanced trade-off between exploration and exploitation. Extensive experimental evaluations on benchmark test functions (CEC2015 and CEC2020), real-world engineering optimization problems, and ELM training tasks demonstrated that SNCPO outperforms several contemporary optimization algorithms in terms of robustness, convergence speed, and solution accuracy. The results indicate that SNCPO consistently achieves superior optimization performance across various problem domains, reinforcing its potential as a powerful optimization tool.
Despite its notable advantages, SNCPO does present certain limitations. One of the primary challenges is its slightly higher computational cost compared to the traditional PO in a few optimization problems, which stems from its additional improvement mechanisms. Additionally, while SNCPO outperforms existing algorithms in most cases, a few benchmark functions indicate that further improvements in search efficiency are required to enhance its capability in highly complex landscapes. Future research directions will focus on enhancing the scalability of SNCPO for high-dimensional optimization problems and exploring its applicability in more advanced machine learning models beyond ELM. Further developments may include parallelized implementations to improve computational efficiency and adaptability. Moreover, extending the SNCPO framework to domains such as feature selection, image processing, and renewable energy optimization could further underscore its versatility and real-world applicability. These advancements will contribute to solidifying SNCPO’s role as a state-of-the-art optimization approach for solving complex, multidimensional problems across various scientific and engineering disciplines.
Data availability
The data obtained through the experiments are available upon request from corresponding author. To protect study participant privacy, the data will be available upon request.
References
WH Bangyal, R Shakir, A Ashraf, ZU Qayyum, NU Rehman. Automatic Detection of Diabetic Retinopathy from Fundus Images using Machine Learning Based Approaches. In 2023 25th International Multitopic Conference (INMIC). 1–6. https://doi.org/10.1109/INMIC60434.2023.10465796. (2023).
WH Bangyal, M Iqbal, A Bashir, G Ubakanma. Polarity Classification of Twitter Data Using Machine Learning Approach. In 2023 International Conference on Human-Centered Cognitive Systems (HCCS). 1–6. https://doi.org/10.1109/HCCS59561.2023.10452557. (2023).
Huang, G.-B., Zhu, Q.-Y. & Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 70(1), 489–501. https://doi.org/10.1016/j.neucom.2005.12.126 (2006).
Huérfano-Maldonado, Y. et al. A comprehensive review of extreme learning machine on medical imaging. Neurocomputing 556, 126618. https://doi.org/10.1016/j.neucom.2023.126618 (2023).
Zong, W. & Huang, G.-B. Face recognition based on extreme learning machine. Neurocomputing 74(16), 2541–2551. https://doi.org/10.1016/j.neucom.2010.12.041 (2011).
Kadhim Ajlan, I., Murad, H., Salim, A. A. & Fadhil Bin Yousif, A. Extreme learning machine algorithm for breast cancer diagnosis. Multimed. Tools Appl. https://doi.org/10.1007/s11042-024-19515-y (2024).
Huang, G.-B., Zhou, H., Ding, X. & Zhang, R. ‘Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 42(2), 513–529. https://doi.org/10.1109/TSMCB.2011.2168604 (2012).
Wong, P. K., Yang, Z., Vong, C. M. & Zhong, J. Real-time fault diagnosis for gas turbine generator systems using extreme learning machine. Neurocomputing 128, 249–257. https://doi.org/10.1016/j.neucom.2013.03.059 (2014).
Yıldırım, H. & Revan Özkale, M. LL-ELM: A regularized extreme learning machine based on $$L_{1}$$-norm and Liu estimator. Neural Comput. Appl. 33, 10469–10484. https://doi.org/10.1007/s00521-021-05806-0 (2021).
Eshtay, M., Faris, H. & Obeid, N. Metaheuristic-based extreme learning machines: a review of design formulations and applications. Int. J. Mach. Learn. Cybern. 10(6), 1543–1561. https://doi.org/10.1007/s13042-018-0833-6 (2019).
Osaba, E. & Yang, X.-S. Applied Optimization and Swarm Intelligence: A Systematic Review and Prospect Opportunities 1–23 (Springer, 2021).
Monga, P., Sharma, M. & Sharma, S. K. A comprehensive meta-analysis of emerging swarm intelligent computing techniques and their research trend. J. King Saud. Univ. Comput. Inf. Sci. 34, 9622–9643 (2022).
Wang, D., Tan, D. & Liu, L. Particle swarm optimization algorithm: an overview. Soft Comput. 22(2), 387–408. https://doi.org/10.1007/s00500-016-2474-6 (2018).
Dorigo, M., Birattari, M. & Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 1(4), 28–39. https://doi.org/10.1109/MCI.2006.329691 (2006).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 (2016).
Mirjalili, S. et al. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191. https://doi.org/10.1016/j.advengsoft.2017.07.002 (2017).
Chou, J.-S. & Truong, D.-N. A novel metaheuristic optimizer inspired by behavior of jellyfish in ocean. Appl. Math. Comput. 389, 125535. https://doi.org/10.1016/j.amc.2020.125535 (2021).
Zhao, W., Zhang, Z. & Wang, L. Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications. Eng. Appl. Artif. Intell. 87, 103300. https://doi.org/10.1016/j.engappai.2019.103300 (2020).
Karaboga, D. Artificial bee colony algorithm. Scholarpedia 5(3), 6915. https://doi.org/10.4249/scholarpedia.6915 (2010).
Meraihi, Y., Ramdane-Cherif, A., Acheli, D. & Mahseur, M. Dragonfly algorithm: a comprehensive review and applications. Neural Comput. Appl. 32(21), 16625–16646. https://doi.org/10.1007/s00521-020-04866-y (2020).
Mirjalili, S. Z., Mirjalili, S., Saremi, S., Faris, H. & Aljarah, I. Grasshopper optimization algorithm for multi-objective optimization problems. Appl. Intell. 48(4), 805–820. https://doi.org/10.1007/s10489-017-1019-8 (2018).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 97, 849–872. https://doi.org/10.1016/j.future.2019.02.028 (2019).
Yazdani, M. & Jolai, F. Lion optimization algorithm (LOA): A nature-inspired metaheuristic algorithm J. . Comput. Des. Eng. 3(1), 24–36. https://doi.org/10.1016/j.jcde.2015.06.003 (2016).
Yang, X. & Hossein Gandomi, A. Bat algorithm: a novel approach for global engineering optimization. Eng. Comput. 29, 464–483. https://doi.org/10.1108/02644401211235834 (2012).
Gandomi, A. H., Yang, X.-S. & Alavi, A. H. Cuckoo search algorithm: a metaheuristic approach to solve structural optimization problems. Eng. Comput. 29(1), 17–35. https://doi.org/10.1007/s00366-011-0241-y (2013).
Johari, N. F., Zain, A. M., Noorfa, M. H. & Udin, A. Firefly algorithm for optimization problem. Appl. Mech. Mater. 421, 512–517. https://doi.org/10.4028/www.scientific.net/AMM.421.512 (2013).
Abdollahzadeh, B., Soleimanian Gharehchopogh, F. & Mirjalili, S. Artificial gorilla troops optimizer: A new nature-inspired metaheuristic algorithm for global optimization problems. Int. J. Intell. Syst. 36, 5887–5958 (2021).
Lian, J. et al. Parrot optimizer: Algorithm and applications to medical problems. Comput. Biol. Med. 172, 108064. https://doi.org/10.1016/j.compbiomed.2024.108064 (2024).
Cotta, C. Harnessing memetic algorithms: a practical guide. TOP https://doi.org/10.1007/s11750-024-00694-8 (2025).
Ul Hassan, N. et al. Improved opposition-based particle swarm optimization algorithm for global optimization. Symmetry https://doi.org/10.3390/sym13122280 (2021).
Yang, X.-S. Nature-inspired optimization algorithms: Challenges and open problems. J. Comput. Sci. 46, 101104. https://doi.org/10.1016/j.jocs.2020.101104 (2020).
Abualigah, L., Diabat, A., Mirjalili, S., Abd Elaziz, M. & Gandomi, A. H. The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 376, 113609. https://doi.org/10.1016/j.cma.2020.113609 (2021).
Qaraad, M., Aljadania, A. & Elhosseini, M. Large-scale competitive learning-based salp swarm for global optimization and solving constrained mechanical and engineering design problems. Mathematics 11(6), 1362. https://doi.org/10.3390/math11061362 (2023).
Qaraad, M., Amjad, S., Hussein, N. K. & Elhosseini, M. A. An innovative quadratic interpolation salp swarm-based local escape operator for large-scale global optimization problems and feature selection. Neural Comput. Appl. 34(20), 17663–17721. https://doi.org/10.1007/s00521-022-07391-2 (2022).
Abualigah, L. et al. Improved reptile search algorithm by salp swarm algorithm for medical image segmentation. J. Bionic Eng. 20(4), 1766–1790. https://doi.org/10.1007/s42235-023-00332-2 (2023).
Chhabra, A., Hussien, A. G. & Hashim, F. A. Improved bald eagle search algorithm for global optimization and feature selection. Alex. Eng. J. 68, 141–180. https://doi.org/10.1016/j.aej.2022.12.045 (2023).
Gharehchopogh, F. S. An improved Harris Hawks optimization algorithm with multi-strategy for community detection in social network. J. Bionic Eng. 20(3), 1175–1197. https://doi.org/10.1007/s42235-022-00303-z (2023).
Gharehchopogh, F. S. & Ibrikci, T. An improved African vultures optimization algorithm using different fitness functions for multi-level thresholding image segmentation. Multimed. Tools Appl. 83(6), 16929–16975. https://doi.org/10.1007/s11042-023-16300-1 (2024).
Boriratrit, S., Srithapon, C., Fuangfoo, P. & Chatthaworn, R. Metaheuristic extreme learning machine for improving performance of electric energy demand forecasting. Computers https://doi.org/10.3390/computers11050066 (2022).
Wu, L. et al. Hybrid extreme learning machine with meta-heuristic algorithms for monthly pan evaporation prediction. Comput. Electron. Agric. 168, 105115. https://doi.org/10.1016/j.compag.2019.105115 (2020).
Yang, B. et al. Extreme learning machine based meta-heuristic algorithms for parameter extraction of solid oxide fuel cells. Appl. Energy 303, 117630. https://doi.org/10.1016/j.apenergy.2021.117630 (2021).
Van Thieu, N., Nguyen, N. H., Sherif, M., El-Shafie, A. & Ahmed, A. N. Integrated metaheuristic algorithms with extreme learning machine models for river streamflow prediction. Sci. Rep. 14(1), 13597. https://doi.org/10.1038/s41598-024-63908-w (2024).
Abba, S. I. et al. Optimization of extreme learning machine with metaheuristic algorithms for modelling water quality parameters of Tamburawa water treatment plant in Nigeria. Water Resour. Manag. https://doi.org/10.1007/s11269-024-04027-z (2024).
Bacanin, N. et al. Multi-swarm algorithm for extreme learning machine optimization. Sensors 22, 4204. https://doi.org/10.3390/s22114204 (2022).
Dogan, M. & Ozkan, I. A. Determination of wheat types using optimized extreme learning machine with metaheuristic algorithms. Neural Comput. Appl. 35(17), 12565–12581. https://doi.org/10.1007/s00521-023-08354-x (2023).
Zhong, R., Zhang, C. & Yu, J. Hierarchical RIME algorithm with multiple search preferences for extreme learning machine training. Alex. Eng. J. 110, 77–98. https://doi.org/10.1016/j.aej.2024.09.109 (2025).
Heidari, A. A., Ali Abbaspour, R. & Chen, H. Efficient boosted grey wolf optimizers for global search and kernel extreme learning machine training. Appl. Soft Comput. 81, 105521. https://doi.org/10.1016/j.asoc.2019.105521 (2019).
Cao, L., Yue, Y., Zhang, Y. & Cai, Y. Improved crow search algorithm optimized extreme learning machine based on classification algorithm and application. IEEE Access 9, 20051–20066. https://doi.org/10.1109/ACCESS.2021.3054799 (2021).
Cai, Z. et al. Evolving an optimal kernel extreme learning machine by using an enhanced grey wolf optimization strategy. Expert Syst. Appl. 138, 112814. https://doi.org/10.1016/j.eswa.2019.07.031 (2019).
Liu, H. et al. Hybrid prediction method for solar photovoltaic power generation using normal cloud parrot optimization algorithm integrated with extreme learning machine. Sci. Rep. 15(1), 6491. https://doi.org/10.1038/s41598-025-89871-8 (2025).
Cheng, R. & Jin, Y. A competitive swarm optimizer for large scale optimization. IEEE Trans. Cybern. 45(2), 191–204. https://doi.org/10.1109/TCYB.2014.2322602 (2015).
Chen, X. & Tang, G. Solving static and dynamic multi-area economic dispatch problems using an improved competitive swarm optimization algorithm. Energy 238, 122035. https://doi.org/10.1016/j.energy.2021.122035 (2022).
JJ Liang, BY Qu, PN Suganthan, Q Chen. Problem definitions and evaluation criteria for the CEC 2015 competition on learning-based real-parameter single objective optimization. Computational Intelligence Laboratory, Zhengzhou University, Zhengzhou China and Technical Report, Nanyang Technological University, Singapore, Technical Report vol 29. Technical Report201411A. (2015).
Wagdy, A. et al. Problem Definitions and Evaluation Criteria for the CEC 2021 Special Session and Competition on Single Objective Bound Constrained Numerical Optimization (Nanyang Technological University, 2020).
Abualigah, L. et al. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 157, 107250. https://doi.org/10.1016/j.cie.2021.107250 (2021).
Abdel-Basset, M., El-Shahat, D., Jameel, M. & Abouhawwash, M. Exponential distribution optimizer (EDO): a novel math-inspired algorithm for global optimization and engineering problems. Artif. Intell. Rev. 56(9), 9329–9400. https://doi.org/10.1007/s10462-023-10403-9 (2023).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey Wolf optimizer. Adv. Eng. Softw. 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 89, 228–249. https://doi.org/10.1016/j.knosys.2015.07.006 (2015).
Talha, A., Bouayad, A. & Malki, M. O. C. An improved pathfinder algorithm using opposition-based learning for tasks scheduling in cloud environment. J. Comput. Sci. 64, 101873. https://doi.org/10.1016/j.jocs.2022.101873 (2022).
Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133. https://doi.org/10.1016/j.knosys.2015.12.022 (2016).
García, S., Fernández, A., Luengo, J. & Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 180(10), 2044–2064. https://doi.org/10.1016/j.ins.2009.12.010 (2010).
Derrac, J., García, S., Molina, D. & Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 1(1), 3–18. https://doi.org/10.1016/j.swevo.2011.02.002 (2011).
Alsayyed, O. et al. Giant Armadillo optimization: A new bio-inspired metaheuristic algorithm for solving optimization problems. Biomimetics https://doi.org/10.3390/biomimetics8080619 (2023).
Alabdulhafith, M. et al. A modified Bonobo optimizer with its application in solving engineering design problems. IEEE Access 12, 134948–134984. https://doi.org/10.1109/ACCESS.2024.3455550 (2024).
Sharma, S., Saha, A. K. & Lohar, G. Optimization of weight and cost of cantilever retaining wall by a hybrid metaheuristic algorithm. Eng. Comput. 38(4), 2897–2923. https://doi.org/10.1007/s00366-021-01294-x (2022).
Van Thieu, N., Houssein, E. H., Oliva, D. & Hung, N. D. IntelELM: A python framework for intelligent metaheuristic-based extreme learning machine. Neurocomputing 618, 129062. https://doi.org/10.1016/j.neucom.2024.129062 (2025).
Funding
Open access funding provided by Manipal Academy of Higher Education, Manipal
This work was funded by Manipal Academy of Higher Education.
Author information
Authors and Affiliations
Contributions
O.R.A: Conceptualization, Methodology, Formal Analysis, Original Draft; A.K.F: Editing, Methodology, Original Draft, Experiments; G.G.T: Supervision, Resources, Editing; A.S: Supervision, Resources, Editing; E.B.A: Methodology, Original Draft, Experiments; P.K.: Methodology, Original Draft, Experiments, Funding.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Adegboye, O.R., Feda, A.K., Tejani, G.G. et al. Salp Navigation and Competitive based Parrot Optimizer (SNCPO) for efficient extreme learning machine training and global numerical optimization. Sci Rep 15, 13704 (2025). https://doi.org/10.1038/s41598-025-97661-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-97661-5
