
Abstract
With the rapid development of investment markets and the diversification of investment products, accurate prediction of stock price trends is particularly important for investors and researchers. The complexity of the stock market and the nonlinear characteristics of the data make it difficult for traditional prediction models to meet the demand for high-precision predictions. Although some existing machine learning methods and deep learning models perform well in certain cases, they still face limitations in handling high-dimensional data and time dependencies. To overcome these problems, we propose a novel hybrid quantum neural network model, BLS-QLSTM, which combines broad learning system (BLS) and quantum long short-term memory (QLSTM) network for chaotic time series prediction. Initially, the Cao method and mutual information approach are employed to determine the embedding dimensions and time delays, facilitating the reconstruction of the phase space of the original time series. Subsequently, BLS is introduced to enhance the feature representation of the data, while the gating structures within the long short-term memory (LSTM) network are replaced by variational quantum circuits (VQCs) to form QLSTM, thereby further improving prediction accuracy. BLS-QLSTM is a generalized prediction framework, which can be used to predict the price fluctuations of stocks based on historical data. Extensive experiments on three real stock indices—CSI 300, SSEC, and CSI 500—demonstrate that the BLS-QLSTM model outperforms traditional LSTM and QLSTM models in six performance evaluation metrics: the root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), coefficient of determination (R2), precision, and accuracy. The results validate the effectiveness and superiority of the BLS-QLSTM model in handling chaotic financial time series data and predicting stock index price trends.
Similar content being viewed by others

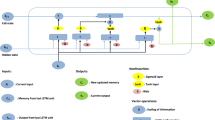

Introduction
Amid the increasing globalization and financialization of the world economy, capital markets have emerged as key drivers of global economic growth (Chen et al., 2022). The stock market, as a crucial component of capital markets, is widely regarded as a barometer of a nation’s economic health (Xie et al., 2021). It plays an indispensable role in facilitating capital formation, optimizing resource allocation, serving the real economy, and supporting national development (An et al., 2024). Stock prices are a direct reflection of market trends and have a profound impact on investor decision-making and government macroeconomic regulation (Li & Zhao, 2022; Shen et al., 2011). Therefore, developing effective stock price prediction methods is not only a significant research topic in academia but also an urgent need in the financial industry (Kumar et al., 2024).
The price fluctuation of stock market is affected by various external factors, such as the macroeconomic environment, corporate financial performance, and international political events, leading to highly nonlinear and chaotic characteristics in its behavior (Chen et al., 2024). Traditional statistical models, such as autoregressive moving average (ARMA), autoregressive integrated moving average (ARIMA), generalized autoregressive conditional heteroskedasticity (GARCH), and their variants, have demonstrated certain effectiveness in addressing specific financial time series problems. However, these models typically rely on assumptions such as data stationarity and linearity (Zhao et al., 2023; Lin, 2018; Mondal et al., 2014). In practice, stock market data often deviate from these assumptions, thereby limiting the applicability and performance of traditional models in complex market environments.
In recent years, machine learning methods have become mainstream tools for financial time series forecasting due to their ability to learn patterns from data without requiring strict statistical assumptions. Compared with traditional statistical approaches, machine learning exhibits superior capability in handling nonlinear data, achieving significant advancements in prediction accuracy. However, it is worth noting that these methods still face limitations in capturing long-term dependencies and local information within time series data, particularly when dealing with highly complex temporal datasets (Sharma et al., 2023; Zhou et al., 2019).
To address these challenges, researchers have further advanced deep learning techniques, particularly the long short-term memory (LSTM) network, an improved version of the recurrent neural network (RNN). LSTM has been widely applied in stock market prediction due to its powerful time series modeling capabilities, effectively capturing long-term dependencies, and has become a common approach in financial time series forecasting (Fischer & Krauss, 2018). However, despite its outstanding performance in handling temporal data, LSTM still faces challenges in extracting local feature information, mitigating data noise, and optimizing model generalization. To overcome these limitations, this study proposes a novel hybrid model, BLS-QLSTM, which combines the strengths of the broad learning system (BLS) and quantum neural networks to address the shortcomings of previous models, thereby significantly enhancing the accuracy of stock price predictions.
Inspired by chaotic time series analysis, three stock indices, CSI 300, SSEC and CSI 500, were selected as the experimental data. The Cao method and mutual information method were first employed to determine the embedding dimension and time delay of the original time series data (Zhang Shu-Qing et al., 2010), followed by phase space reconstruction. The data features were then enhanced using BLS to build a quantum long short-term memory model (QLSTM) for prediction. The effectiveness of the proposed model was validated using the above three real stock indices. The main contributions of our work can be summarized as follows:
-
(1)
A novel quantum neural network model, called BLS-QLSTM, is proposed for predicting financial time series data. The introduction of BLS and variational quantum circuits (VQCs) significantly improves predictive performance.
-
(2)
The BLS-QLSTM model utilizes the cascade structure of BLS to enhance feature representation. Additionally, it exploits the advantages of quantum properties and quantum computation by artfully integrating VQCs with LSTM, effectively mitigating the impact of data noise and rapidly extracting local temporal features.
-
(3)
The BLS-QLSTM model is well-suited for chaotic financial time series data prediction. Empirical analysis on CSI 300, SSEC, and CSI 500 stock indices demonstrated excellent results.
The remainder of the paper is structured as follows: “Literature review reviews” the latest research on related methods. “Preliminaries” presents the background theory, providing a brief explanation of the key techniques used in the model. “Framework of BLS-QLSTM modeling” describes the overall framework and computational process of the proposed innovative model. “Experimental results and analysis” discusses the empirical analysis results based on three real stock index datasets. Finally, “Conclusion” concludes the study.
Literature review
Stock price data is inherently high-noise, nonlinear, dynamic, and complex chaotic time series data, making stock price prediction a challenging task. In recent years, researchers have proposed various methods to address this issue, which can be broadly categorized into three types: statistical methods, machine learning methods, and deep learning methods.
Traditional statistical methods rely on systematically observing historical data, performing curve fitting, parameter estimation, and residual analysis to construct models and predict future trends. The ARIMA model, which integrates the advantages of ARMA, transforms non-stationary time series into stationary ones, making it suitable for short-term time series forecasting. Majumder et al. (2019) applied feedforward neural networks, linear models, the Holt-Winter method, and ARIMA to predict the stock index of Bangladesh, where ARIMA demonstrated the highest prediction accuracy. However, the general ARIMA model assumes residuals to be white noise, neglecting the volatility clustering characteristic, leading to the adoption of GARCH model for non-stationary time series forecasting. Lu et al. (2023) applied the GARCH type model to the Chinese nickel industry index, successfully predicting the volatility patterns of this stock index, providing valuable insights for risk management in the nickel market. Nonetheless, some researchers argue that such statistical models rely on specific assumptions and offer limited prediction accuracy, making them unsuitable for modeling and analyzing the complex, non-stationary nature of stock market data.
Machine learning methods exhibit certain advantages in handling nonlinear and non-stationary data, demonstrating strong performance in various prediction tasks, including weather forecasting (Yang et al., 2024), traffic flow prediction (Luo et al., 2023), stock price prediction, and energy prediction (Wang et al., 2023). In stock price prediction, various machine learning algorithms have been applied to real stock indices. Madge and Bhatt (2015) attempted to use support vector machine (SVM) to predict the prices of 34 technology stocks. Their study indicated that while the accuracy of short-term predictions was very low, the long-term prediction accuracy of SVM ranged between 55% and 60%. Parray et al. (2020) converted data from the National Stock Exchange of India’s 50-stock index into a time-series supervised learning format and applied algorithms such as SVM, Perceptron, and Logistic Regression to predict price trends. Compared to trend predictions using unprocessed data, this approach improved prediction accuracy by an average of 2%. Relevant research has focused on enhancing model performance through optimized feature engineering. Nahil and Lyhyaoui (2018) introduced kernel principal component analysis (KPCA) to reduce feature dimensions, integrating it with support vector regression (SVR) to improve stock price prediction. Their results showed that the SVR model with feature extraction using KPCA outperformed SVR model without feature extraction in terms of generalization performance. Yun et al. (2021) proposed using genetic algorithm (GA) as a data optimizer to select optimal features and expand the feature set, with the extreme gradient boosting (XGBoost) model serving as the primary model for stock price prediction. Statistics indicate that multiple techniques such as principal component analysis (PCA) (Chen & Hao, 2018), wavelet transform (WT) (Kao et al., 2013), and particle swarm optimization (PSO) (Rustam & Kintandani, 2019) have also been employed in preprocessing to form integrated models, enhancing the predictive performance of the original machine learning models.
In current research across various fields, employing deep learning models as benchmark methods has become a prevailing trend. Deep learning, a branch of machine learning, has achieved groundbreaking results in numerous tasks (Janiesch et al., 2021). It can identify hidden nonlinear relationships and extract relevant features from complex data without relying on manual processing or statistical assumptions, enabling efficient performance. Consequently, convolutional neural network (CNN), RNN, and LSTM have been widely applied to stock market prediction. CNN employs learnable convolutional layers and downsampling layers as core feature extractors, automatically learning effective feature representations during the training process. Persio and Honchar (2016) used a CNN which took a one-dimensional input for making predictions only based on the historical closing prices while ignoring other possible influencing variables. Ma and Yan (2022) applied CNN to predict stock price changes in the Chinese stock market, and the inclusion of social media sentiment variables effectively improved the model prediction accuracy. However, CNN is unable to use possible correlations between stock price data as a source of predictive information (Hoseinzade & Haratizadeh, 2019). In contrast, RNN and LSTM exhibit greater flexibility in terms of input-output relationships. Their network architectures have the ability to iteratively process time-series data in sequence, allowing them to learn and understand sequential patterns effectively. Rizvi and Khalid (2024) compared various models and concluded that LSTM is the most accurate and reliable model for stock price prediction. Other studies similarly indicate that the improved LSTM model, through the use of memory cells and gates, can effectively learn long-term dependencies. The model largely overcome the challenges of vanishing or exploding gradients, exhibiting superior performance in chaotic time series prediction (Md et al., 2023; Bhandari et al., 2022; Chhajer et al., 2022). However, when dealing with complex time series data, increasing the depth of LSTM network is not always an effective strategy. LSTM still faces challenges in extracting local feature information, addressing data noise, and optimizing model generalization. Jailani et al. (2023) argued that the capability of a single benchmark model is limited. Although hybrid LSTM models require longer training times, they can achieve higher prediction accuracy. The combination of intelligent algorithms or other deep learning networks with LSTM to create hybrid models has become increasingly common, yielding significant improvements (Cai et al., 2024; Yuan et al., 2023).
Quantum computing, leveraging the properties of quantum state superposition and entanglement, possesses powerful parallel computing capabilities. Current literature suggests that research on quantum models primarily focuses on three paradigms: pure quantum machine learning, quantum-inspired machine learning, and hybrid classical-quantum machine learning based on VQCs (Sergioli et al., 2019; Havlíček et al., 2019; Rebentrost et al., 2014). Among these, the use of VQCs to enhance neural networks has emerged as the mainstream development approach. Most quantum neural network models are applied in the field of cryptography (Peral-García et al., 2024; Wang et al., 2023), with only a few utilized for time series prediction. Chen et al. (2020) pioneered the QLSTM architecture, skillfully integrating VQCs with LSTM. This approach utilizes the exponentially growing dimensionality of Hilbert space for data representation and computation, showcasing the potential of hybrid quantum-LSTM models in time series forecasting. Khan et al. (2024) applied a hybrid quantum-LSTM model to forecast solar power generation, while Li et al. (2018) proposed a quantum weighted long short-term memory neural network (QWLSTMNN) for predicting the degradation trends of rotating machinery. Experimental results consistently demonstrate that neural network model incorporating VQCs address certain limitations of classical LSTM model, achieving faster convergence, improved prediction accuracy, and enhanced computational efficiency.
Additionally, BLS with its horizontal expansion capability, effectively enhances feature representation and offers advantages in efficient modeling. BLS has been widely applied across various fields, including image classification (Liu et al., 2021), feature representation (Tang et al., 2021), and fault diagnosis (Fu et al., 2022; Wang et al., 2019). Integrating BLS with other networks results in BLS variants, further improving its efficiency (Zhang et al., 2022). For chaotic time series prediction, Xiong et al. (2024) proposed a novel model based on BLS, which employs a cascade network with frozen weights to rapidly extract features from reconstructed data, thereby maximizing the preservation of chaotic properties and nonlinear relationships. Su et al. (2023) developed a new model framework, which combines the cascade structure of BLS with the attention mechanism of Transformers. This integration enhances feature representation for time series data, achieving superior prediction performance. Some researchers have also applied this approach to stock price prediction. Li et al. (2022) utilized stock price data filtered by the pearson correlation coefficient (PCC) for BLS training to enable rapid extraction of information features. Compared to various machine learning methods, the models built using BLS demonstrated superior performance and fitting capability.
Preliminaries
Phase space reconstruction
Stock data exhibits characteristics of nonlinearity, non-stationarity and high noise, which have been confirmed to be a time series with chaotic properties. The theory of phase space reconstruction (PSR) illustrates the interdependence among the evolution of each component of the system state. The method is based on Takens’ embedding theorem, which states that to ensure the phase space in which the attractor is embedded must reach \(m\ge 2d+1\) if the original attractor resides in an a d-dimensional space (Takens, 1981). It can be further explained that when mapping a one-dimensional chaotic time series from a real-world problem to a higher-dimensional space, the dimensionality of the higher-dimensional space must be greater than or equal to 3 in order to effectively represent the original dynamical system information. For a certain observed time series \(\{x(t),t=1,2,\cdots ,N\}\), once the embedding dimension m and time delay τ are determined, the phase point sequence after phase space reconstruction is given as Eq. (1).
Where \({t}_{i}={N}_{1},{N}_{1}+1,\cdots ,N\); \({N}_{1}=1+(m-1)\tau\). This reconstructed time series can be further defined as {X, Y}, as shown in Eqs. (2) and (3).
Where the embedding dimension m and time delay τ, calculated using the Cao method and the mutual information method, p correspond to the number of samples. In the reconstructed phase space trajectory, each phase point exists a smooth mapping \({\mathcal F} :{R}^{m}\to R\), denoted as \(Y= {\mathcal F} (X)\), which can then be approximated by building a deep learning model to obtain the mapping \({\mathcal F}\).
Broad learning system
The broad learning system, an enhancement of the random vector functional-link neural network (RVFLNN) (Pao et al., 1994), is an incremental learning method that does not require a deep architecture. The structure of BLS is shown in Fig. 1. BLS exhibits strong generalization capabilities and allows for quick reconfiguration of the network without requiring retraining if expansion is needed (Han et al., 2021). Moreover, its computational speed surpasses that of deep networks. For datasets with limited features and stringent real-time prediction demands, BLS can effectively enhance prediction accuracy through transversal incremental expansion, which enhances feature expression. The specific operation process of BLS is as follows.

BLS is an efficient incremental learning system that does not require deep structures. It initially maps input data to the mapping layer, followed by the augmentation layer. The output layer is connected to both the augmentation and mapping layers.
In the initial step, input data \(X\)\((X\in {R}^{p\times m})\) to n mapped node groups (each group has q mapped features), then the mapped feature of the i-th group of mapped nodes is defined as Eq. (4).
Where Wei and βei represent randomly generated weights and bias, respectively. ϕ(*) is the activation function of the mapped layer.
In the subsequent step, these mapped features \({Z}_{1},{Z}_{2},\cdots ,{Z}_{n}\) are multiplied by a set of random weights plus the bias and processed with the activation function to create enhanced nodes, denoted as \({H}_{1},{H}_{2},\cdots ,{H}_{m}\), as shown in Eq. (5).
Where \({W}_{hj}\) and \({\beta }_{hj}\) represent randomly generated weights and bias, respectively. \(\xi (\ast )\) is the activation function of the enhanced layer.
In the final step, \({Z}_{1},{Z}_{2},\cdots ,{Z}_{n}\) merge with \({H}_{1},{H}_{2},\cdots ,{H}_{m}\) to obtain the enhanced data features, denoted as Eq. (6).
Meanwhile, the output data of BLS is \(Y=A{W}_{out}\), where \({W}_{out}\) is the weight matrix that needs to be optimized and can be computed through the pseudoinverse.
Variational quantum circuit
Variational quantum circuit (VQC), also known as parameterized quantum circuit, is a kind of quantum gate circuit with free parameters, which is the main part of the quantum computation model. The main process of quantum computing involves using a series of quantum gates to modify the state of qubits (quantum bits, the fundamental units of quantum information), followed by measuring the computation results at the end of the circuit. The structure of the VQC is shown in Fig. 2, which consists of three parts: the encoding layer, the variational layer, and the measurement layer.

VQC is a kind of quantum gate circuit with free parameters. It consists of three main components: the encoding layer, the variational layer, and the measurement layer.
-
(1)
Encoding layer: classical data is encoded into quantum states and loaded into quantum circuit by changing the states in which the qubits are by \(H\) gate, \({R}_{y}\) gate, and \({R}_{z}\) gate. This study utilizes angle encoding, which demonstrates superior performance compared to base-state encoding and amplitude encoding. Moreover, the method of angle encoding is simpler. Initially, the \(H\) gate transforms the initialized quantum state into an entangled state. Subsequently, classical information \(\overrightarrow{x}={({x}_{1},{x}_{2},\cdots ,{x}_{N})}^{T}\) is applied to the parameters of the rotation gate \({R}_{y}\) and \({R}_{z}\), ultimately converted into a quantum state \(|\overrightarrow{x}\rangle ={\otimes }_{i}^{n}R(\arctan (\theta ))|{0}^{n}\rangle\), where \(\theta ={x}_{i}\) in the rotating gate \({R}_{y}\) and \(\theta ={x}_{i}^{2}\) in the \({R}_{z}\).
-
(2)
Variational layer: using multiple \(CNOT\) gates and R gates, these qubits are entangled and rotated to the target state. The parameters of the VQC optimization update are derived from the 3 rotation angles α, β, and γ of the R gate of the variational layer along the x, y, and z axes, respectively, which are iteratively optimized by the gradient descent method.
-
(3)
Measurement layer: set at the end of VQC, its main purpose is to measure the expectation value of each qubit by Pauli Z to realize the transformation of quantum information into classical information.
Long short-term memory
RNN is known to suffer from the gradient vanishing or exploding problem and is limited in its capacity to store long-term effective information. To address these issues, Hochreiter and Schmidhuber jointly proposed LSTM in 1997. LSTM builds upon the foundational structure of RNN by incorporating a gating mechanism that controls the information transmission path within the network, thereby enabling the selective forgetting or retention of information (Hochreiter & Schmidhuber, 1997). This functionality has made LSTM extensively applicable in various fields such as natural language processing and time series prediction. In the forward transfer learning process of LSTM, the architecture comprises four crucial components: the forget gate, input gate, output gate, and the cell state, as depicted in Fig. 3. The specific transfer formulas are shown in Eqs. (7)–(12).
Where \(\sigma\) is the activation function; \({W}_{f}\) is the weight matrix; \({b}_{f}\) is the bias vector; \({f}_{t}\) represents the output of the forgetting gate, whose main purpose is to control whether the state of the memory unit at the previous moment needs to be forgotten or not. The output range is [0,1].
Where \({W}_{i}\) represents the input matrix; \({W}_{c}\) represents the state matrix; \({i}_{t}\) represents the input gate output, \(\tilde{{C}_{t}}\) represents the temporary state of the memory cell at the current moment. The input gate portion is mainly used to control the extent to which new information is updated by the memory cell.
Where \({C}_{t}\) is the state output of the current memory cell, which is the superposition of the information of the previous moment and the new information of the current moment.
Where \({W}_{o}\) is the output matrix, \({b}_{o}\) is the bias vector and \({h}_{t}\) is the hidden state at the current time step.

LSTM has a chain-like structure with a repeating module. This module consists of four interacting neural network layers, designed in a very special way to manage and maintain long-term dependencies in the data.
Framework of BLS-QLSTM modeling
Motivation for modeling
Chaotic time series are different from general time series. In order to recover their original dynamical system, phase space reconstruction is required to map them into a high-dimensional space. However, traditional deep learning models might encounter the curse of dimensionality with increasing data dimensions. In contrast, the capabilities of BLS and VQC can effectively mitigate this issue and enhance model performance.
-
(1)
Enhanced feature representation by BLS: BLS employs a simple cascade structure that facilitates information reuse and enriches feature representation. The approach avoids the complex residual connections typical in deep learning models while preserving the integrity of the original information.
-
(2)
Quantum State Representation and Quantum Parallel Computing: VQC introduces quantum state representation of the original data, which is instrumental in capturing the microstate of chaotic system. Moreover, VQC leverages the inherent parallelism of quantum computing, enabling more efficient handling of high-dimensional data. It achieves parallel computing through quantum superposition, significantly enhancing the learning capabilities of the model.
Architecture of the QLSTM model
QLSTM is an innovative model that integrates VQCs with classical LSTM network. The QLSTM architecture, as proposed by Chen et al., which comprises six VQC blocks. Experimental results had demonstrated that the hybrid quantum-classical LSTM model not only learns faster but also achieves more stable convergence (Chen et al., 2020). Building on this foundation, Cao et al. (2023) introduced a linear-enhanced quantum LSTM model (L-QLSTM), which added a shared linear embedding layer prior to each VQC within the standard QLSTM framework. This addition enhanced the quantum benefits, improving model learning performance and the accuracy of carbon price predictions. Numerous studies have proved that the introduction of VQCs is beneficial to the performance of classical neural networks. In the study, four VQCs are strategically employed to replace the gates in the recurrent unit of the LSTM network, instead of using the traditional weight matrix. The modification facilitates the construction of a new QLSTM model, whose architecture is illustrated in Fig. 4. The specific operational formula for the QLSTM is provided in Eq. (13).

The QLSTM model integrates Variational Quantum Circuits (VQC) with classical LSTM. In this model, VQCs replace the traditional gates and cell state operations of the LSTM, enhancing the network’s performance and stability.
Architecture of the BLS-QLSTM model
Based on the preceding analysis, it is evident that the cascade structure of BLS enhances the feature representation of time series data, while VQC leverage the properties of quantum superposition and entanglement to enhance the learning capabilities of the model through parallel computing. Theoretically, it is feasible to integrate these two approaches to develop a BLS-QLSTM model for predicting chaotic time series. This model would combine the strengths of both components to significantly improve prediction accuracy.
Consequently, this paper proposed a hybrid quantum neural network model, the BLS-QLSTM model, whose framework is depicted in Fig. 5. The model is structured into three primary components: first, the phase space reconstruction module, which reconstructs the phase space of chaotic time series to restore the original dynamical system and convert it into predictable data; second, the broad learning module, where the acquired data is expanded into high-dimensional space through the cascade structure of BLS via random mapping; and third, the VQCs incorporation module, namely, it is the QLSTM module that uses the VQCs to replace the LSTM network gates and memory units in the loop, instead of the original weight matrix, QLSTM then predicts the input data. The operational workflow of the BLS-QLSTM model is detailed as follows:

The BLS-QLSTM model is an innovative composite prediction framework, consisting of three main components: phase space reconstruction, broad learning, and VQCs integration.
Step 1: Phase Space Reconstruction (PSR)
For the input original one-dimensional time series data \({x}_{t}\), phase space reconstruction is performed to obtain multidimensional data. Assuming embedding dimension \(m\) and time delay \(\tau\), the phase space reconstructed data \({X}_{t}\) is defined as Eq. (14).
Step 2: Broad Learning System (BLS)
-
(1)
Mapped node: define the output \({H}_{i}\) of the mapped node \(i\) as Eq. (15).
$${H}_{i}=\phi ({W}_{i}{X}_{t}+{b}_{i})$$(15)Where \({W}_{i}\) and \({b}_{i}\) are the weight and bias of the \(i\)-th mapped node, respectively. \(\phi (\ast )\) is the activation function.
-
(2)
Enhanced node: define the output \({E}_{j}\) of the enhanced node \(j\) as Eq. (16).
$${E}_{j}=\xi ({V}_{j}H+{c}_{j})$$(16)Where \({V}_{j}\) and \({c}_{j}\) are the weight and bias of the jth mapped node, respectively. \(\xi (\ast )\) is the activation function.
-
(3)
Feature merging: merge the outputs of all mapped and enhanced nodes to obtain the output \(F\) of BLS as shown in Eq. (17).
Step 3: Data Fusion
Splicing and fusing the phase space reconstructed data \({X}_{t}\) with the output of BLS \(F\) to get the multidimensional features to \({Z}_{t}\) in Eq. (18).
Step 4: QLSTM network prediction
Process the final input data \({Z}_{t}\) using QLSTM to obtain the predicted output \({y}_{t}\) in Eq. (19).
Where \({h}_{t-1}\) and \({C}_{t-1}\) represent the QLSTM hidden state and cell state at the previous moment, respectively.
Experimental results and analysis
Data sources
The research objects selected for this paper are three representative stock indices in China: the CSI 300 Index (CSI 300, Index code: 000300), the SSE Composite Index (SSEC, Index code: 000001), and the CSI Smallcap 500 Index (CSI 500, Index Code: 000905), whose time series data are the daily closing prices from January 4, 2013 to December 29, 2023, excluding holidays. Each index has a total of 2,672 data points, which were retrieved from the official Investing website (https://cn.investing.com). The closing price data for these indices are illustrated in Fig. 6, while the statistical description are presented in Table 1.

A graphical representation of the original data for three stock indices: CSI 300 Index, SSEC Index, and CSI 500 Index.
Data processing
Phase space reconstruction of data
The closing price data of the three selected stock indices, CSI 300, SSEC, and CSI 500, have no outliers or missing values. Initially, we employ the Cao method and mutual information method to ascertain the embedding dimension \(m\) and time delay \(\tau\) for each stock index, which are the key parameters for the phase space reconstruction of the data. After calculation, the time delay of the closing price data of the CSI 300 index is \(\tau =16\) and the embedding dimension is \(m=7\); the time delay of the closing price data of the SSEC index is \(\tau =20\) and the embedding dimension is \(m=6\); the time delay of the closing price data of the CSI 500 index is \(\tau =25\) and the embedding dimension is \(m=8\). The time delay \(\tau\) and embedding dimension \(m\) of each stock index data are known, the following phase space reconstruction is performed to recover the original dynamical system information, which helps the short-term prediction of stock index data.
As outlined in “Phase Space Reconstruction”, phase space reconstruction involves converting original one-dimensional time series data into a multidimensional state space. This transformation enables a more profound comprehension of the dynamical characteristics and underlying patterns of the data. After phase space reconstruction, the one-dimensional closing price data of CSI 300 index is reconstructed into a two-dimensional matrix data of 2576 × 7; the one-dimensional closing price data of SSEC index is reconstructed into a two-dimensional matrix data of 2572 × 6; and the one-dimensional closing price data of CSI 500 index is reconstructed into a two-dimensional matrix data of 2497 × 8.
Broad learning of data
Instead of training layer by layer like a deep network structure, BLS uses a cascade structure to quickly learn and expand the feature data. The parameters within the BLS used in this paper are set as follows: the mapped node in the mapped layer is map_num=3, the mapped feature is map_fea_num=2, the enhanced node is enh_num=1 and the enhanced feature is enh_fea_num=10. The feature data obtained from the phase space reconstruction of each stock index is further processed by broad learning as a way to expand the dimension of the features. Finally, the feature data of each stock index is expanded to 16 dimensions.
Data fusion and standardization
In the further analysis process, the feature data derived from phase space reconstruction is concatenated and integrated with the expanded feature data from broad learning. The approach horizontally combines the feature sets obtained from both methods. This way not only increases the dimensionality of the data but also merges information extracted from diverse perspectives, enhancing the expressiveness and accuracy of the final model.
To ensure equitable comparisons among different stock indices and to augment the performance of subsequent models, it is imperative to standardize the fused data. Standardization, a pivotal data preprocessing technique, rescales the data values to achieve a mean of 0 and a standard deviation of 1. This process helps to eliminate the differences in the magnitude of the data, making the learning process more efficient during model training. The standardized formula is Eq. (20).
Where \(X\) represents the fused stock index data, \({X}_{std}\) denotes the standardized data. \(\mu\) and σ are the mean and standard deviation of the original data, respectively.
Furthermore, in order to revert the data to its original scale, the output predictions must also undergo inverse standardization, as depicted in Eq. (21).
Where \(\hat{y}\) indicates the predicted value post-output and inverse standardization by the QLSTM neural network.
Experimental environment and parameter settings
The processor of the experimental environment in this paper is 12th Gen Intel(R) Core(TM) i5-12500H, the operating system is Windows 11 (64-bit), the deep learning development environment is Pytorch 2.0.1+cpu, and the Python version is 3.10.
In order to verify the predictive ability of the constructed BLS-QLSTM model, this paper selects three real stock index data of the CSI 300 index, SSEC index, and CSI 500 index for experiments and compares the errors with the QLSTM model without introducing BLS as well as the single model LSTM. Due to the chaotic nature of stock index data, the original one-dimensional closing price data must be input after phase space reconstruction. The key parameters in this phase of phase space reconstruction are the embedding dimension \(m\) and the time delay \(\tau\), which can be determined by the Cao method and the mutual information method, respectively, as shown in Table 2. The parameter settings for BLS are shown in Table 3.
Given the modest dataset size, comprising only 2672 data points per stock index and the relatively low task complexity, thus a single-layer QLSTM was employed. Through continuous trial and error experiments and analyses, the data batch size is 1, the number of iterations is 20, the learning rate is 0.0004. The number of layers of LSTM is also 1 with 16 neurons in a single layer, and the learning rate is 0.00007. All models choose the Adam optimization algorithm for weight and bias adjustments, and use MSE as the loss function. The data partitioning strategy allocates 75% of the samples to training and the remaining 25% to testing.
In the stock index prediction experiment, the labels of up or down were generated based on the percentage change in the daily closing price, setting a threshold of 1%. If the daily price change exceeds 1%, it is labeled as “up”; if the decrease exceeds 1%, it is labeled as “down”; otherwise, it is considered stable. To concentrate on the capacity of models to predict significant movements in different stock indices, the “stable” data points were filtered out, ensuring that the analysis centered on clear upward and downward trends in the indices. Subsequently, the predicted daily closing prices of the model were compared with the actual prices from the previous day to generate up or down prediction labels, and these predictions were analyzed in comparison with the actual outcomes.
Evaluation indicators
In order to explore the accuracy of models, the root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and coefficient of determination (R2) are selected as prediction evaluation indices in this paper to evaluate and compare the predictive effect of models. Additionally, two categorical evaluation metrics, precision and accuracy, were introduced to measure the performance of models in predicting the direction of stock price movements.
In the above formulas, \(\widehat{{y}_{i}}\) is the predicted value, \({y}_{i}\) is the true value, \(\overline{{y}_{i}}\) is the sample mean, \(n\) is the number of samples. Among them, RMSE, MAE, MAPE measure the deviation between the predicted value and the real value. Lower values of these metrics indicate reduced prediction errors, thereby reflecting greater accuracy in the results. The coefficient of determination, R2, when approaching 1, indicates a higher degree of model fit, signifying that the predicted values closely align with the real observations, thereby denoting superior model performance.
2. The formulas for the selected classification indicators are shown in Eqs. (26)–(27).
In the aforementioned formulas, TP represents true positives, referring to the number of samples correctly predicted as positive by the model; FP denotes false positives, indicating the number of samples incorrectly predicted as positive by the model; TN stands for true negatives, representing the number of samples correctly predicted as negative; and FN signifies false negatives, referring to the number of samples incorrectly predicted as negative. Precision measures the proportion of true positives among all samples predicted as positive, with a higher value indicating greater reliability of the model in predicting positive cases. Accuracy, on the other hand, assesses the overall predictive accuracy of the model, defined as the proportion of correctly predicted samples out of the total number of samples, with a higher value indicating better overall model performance.
BLS-QLSTM, QLSTM and LSTM comparison experiments
In this section, we conduct experimental comparisons using data from three major stock indices—CSI 300, SSEC, and CSI 500—to thoroughly analyze the predictive performance of three models: LSTM, QLSTM, and BLS-QLSTM. The experiments are primarily evaluated along two dimensions: one focuses on the analysis of forecasting evaluation metrics, while the other centers on the analysis of classification evaluation metrics. Stock index price forecasting is fundamentally a time series prediction problem, typically analyzed using forecasting evaluation metrics. However, in practical applications, investors are concerned not only with the accuracy of price forecasting but also with the ability of models to predict market trends. Therefore, we introduce classification evaluation metrics to comprehensively assess the performance of the proposed model across different stock index datasets.
Experimental results of CSI 300 based on various models
(1) Prediction Evaluation Metrics Results
The BLS-QLSTM model performs best on all four evaluation metrics selected for forecasting the CSI 300 index (See Table 4). Compared to the traditional LSTM model, the BLS-QLSTM achieved a 21.6% reduction in RMSE and demonstrated a 6.3% improvement over the QLSTM model, underscoring its significant advantage in accurately capturing market dynamics. The reduction in MAE further confirms the effectiveness of BLS-QLSTM in minimizing prediction bias, while its robust performance in MAPE highlights the precision of model in reflecting stock market volatility. Additionally, the R2 value increased to 0.99570, indicating a high degree of fit in modeling the overall trend of the stock index. The forecasting results of CSI 300 and the overall model presentation are shown in Fig. 7.

A graphical representation of the forecasting result of the CSI 300 Index using three models: LSTM, QLSTM, and BLS-QLSTM.
(2) Classification Evaluation Metrics Results
The classification prediction results for the upward and downward trends of the CSI 300 index demonstrate that the BLS-QLSTM model achieved the best performance in both precision and accuracy metrics (See Table 5). Specifically, the precision of the BLS-QLSTM model reached 0.72505, which is significantly higher than the 0.52401 of the LSTM model and the 0.53579 of the QLSTM model. This indicates that the BLS-QLSTM model has superior accuracy in predicting market uptrends. Additionally, the accuracy of the BLS-QLSTM model was 0.72865, representing an improvement of 23 percentage points compared to the 0.49708 of the LSTM model and an increase of 22 percentage points compared to the 0.51111 of the QLSTM model. These results suggest that the BLS-QLSTM model offers greater reliability and stability in overall trend prediction. A comparison of the confusion matrices for the classification results of the CSI 300 index is illustrated in Fig. 8.

Visualization of the confusion matrix comparison for predicting the CSI 300 Index’s up and down movements based on LSTM, QLSTM, and BLS-QLSTM models. a LSTM Confusion Matrix; b QLSTM Confusion Matrix; c BLS-QLSTM Confusion Matrix.
Experimental results of SSEC based on various models
(1) Prediction Evaluation Metrics Results
The BLS-QLSTM model continues to maintain its leading position in the SSEC forecasting analysis (See Table 6), with a significant reduction in RMSE, being 23.3% lower than that of the LSTM model and 13.3% lower than that of the QLSTM model. This reduction demonstrates the remarkable ability of the model to synthesize market information and enhance the quality of forecasts. The performance of the model on the MAE metric underscores its robustness in reducing mean errors, while the slight variations in the MAPE metric remain within a reasonable range, showcasing the adaptability of the model to specific market conditions. The improvement in the R2 metric to 0.99344 further validates the explanatory power of the BLS-QLSTM model and confirms its utility in market forecasting practice. The forecasting results of SSEC and the overall model presentation are shown in Fig. 9.

A graphical representation of the forecasting result of the SSEC Index using three models: LSTM, QLSTM, and BLS-QLSTM.
(2) Classification Evaluation Metrics Results
In the classification prediction of the SSEC trend, the performance of different models is presented in Table 7. It is evident that the BLS-QLSTM model significantly outperforms the LSTM and QLSTM models in both precision and accuracy, which are two critical metrics. Specifically, in the SSEC trend classification prediction experiment, the BLS-QLSTM model achieved a precision of 0.82102, compared to 0.55789 and 0.53257 for the LSTM and QLSTM models, respectively. Additionally, the BLS-QLSTM model also attained an accuracy of 0.78933, whereas the LSTM and QLSTM models recorded accuracies of 0.53371 and 0.52809, respectively. These results indicate that the BLS-QLSTM model offers higher accuracy and reliability in classifying the SSEC trend, effectively identifying market changes and reducing the occurrence of misclassifications. A comparison of the confusion matrices for the classification results of the SSEC index is shown in Fig. 10.

Visualization of the confusion matrix comparison for predicting the SSEC Index’s up and down movements based on LSTM, QLSTM, and BLS-QLSTM models. a LSTM Confusion Matrix; b QLSTM Confusion Matrix; c BLS-QLSTM Confusion Matrix.
Experimental results of CSI 500 based on various models
(1) Prediction Evaluation Metrics Results
The experimental results of the CSI 500 index highlight the superiority of the proposed BLS-QLSTM model for complex financial data processing (See Table 8). Its RMSE decreases by 36.5% compared to the LSTM model and 19.8% compared to the QLSTM model, this significant reduction not only shows the absolute advantage of the model in reducing the prediction error, but also highlights its insight in mastering the chaotic attributes of the financial market. The significant improvement in MAE and MAPE further confirms the stability and reliability of the BLS-QLSTM model in maintaining the prediction accuracy. The significant improvement in MAE and MAPE further confirms the stability and reliability of the BLS-QLSTM model in maintaining forecast accuracy, and the significant improvement in the R2 of the BLS-QLSTM model to 0.99404 demonstrates the high ability to capture the intrinsic dynamics of the data. The forecasting results of CSI 500 and the overall model presentation are shown in Fig. 11.

A graphical representation of the forecasting result of the CSI 500 Index using three models: LSTM, QLSTM, and BLS-QLSTM.
(2) Classification Evaluation Metrics Results
In the classification prediction experiment for the CSI 500 Index trend, the BLS-QLSTM model once again demonstrated its superior performance (See Table 9). From the perspective of two key classification metrics, precision and accuracy, the BLS-QLSTM model significantly outperformed the LSTM and QLSTM models. Specifically, the BLS-QLSTM model achieved a precision of 0.80079, which is considerably higher than the 0.53047 and 0.55935 recorded by the LSTM and QLSTM models, respectively. Moreover, the BLS-QLSTM model also surpassed the other two models in accuracy, reaching 0.77545, showcasing the exceptional capability of the model in accurately classifying the market trends of the CSI 500 Index. A comparison of the confusion matrices for the classification results of the CSI 500 index is shown in Fig. 12.

Visualization of the confusion matrix comparison for predicting the CSI 500 Index’s up and down movements based on LSTM, QLSTM, and BLS-QLSTM models. a LSTM Confusion Matrix; b QLSTM Confusion Matrix; c BLS-QLSTM Confusion Matrix.
Conclusion
Developing efficient and accurate stock price prediction models has long been a central focus in financial research. Previous studies such as Lin (2018) and Mondal et al. (2014) have indicated that statistical models such as ARIMA and GARCH possess certain short-term forecasting capabilities, but they typically rely on assumptions of linearity and stationarity, limiting their adaptability to chaotic financial time series. While machine learning methods exhibit advantages in handling nonlinear relationships, they often fall short in capturing long-term dependencies within time series data and show limited modeling capacity for high-dimensional datasets. In recent years, mainstream studies have increasingly adopted deep learning models such as LSTM to improve the accuracy of time series forecasting. However, challenges remain, including insufficient extraction of local features and weak noise resistance. These limitations suggest that relying solely on a single model is inadequate to fully exploit the complex intrinsic structure of stock index data. Accordingly, we attempt to reform the traditional LSTM and propose a hybrid quantum neural network model, BLS-QLSTM, which incorporates modular design and technological integration to achieve multidimensional enhancements in feature extraction, prediction accuracy, and model robustness.
The BLS-QLSTM model is composed of three main modules: the phase-space reconstruction module, the BLS module, and the QLSTM module. The phase-space reconstruction module employs embedding dimension and time delay techniques to reconstruct chaotic time series data, extracting latent dynamic features and enhancing the nonlinear representational capacity of the data, thus providing higher-quality inputs for subsequent modeling. The BLS module utilizes a cascade structure for efficient feature expansion, enriching stock indices prediction feature space with accurately enhanced features in high-dimensional space, significantly improving the model’s generalization ability. The QLSTM module integrates the parallelism of quantum computing, offering robust noise resistance, and further optimizes the model’s capability to capture short-term and long-term dynamics as well as high-dimensional feature representation efficiency compared to traditional LSTM models. Through the synergistic interaction of these three modules, the BLS-QLSTM model theoretically bridges the research gap in the integration of quantum computing and deep learning for financial time series prediction.
The effectiveness of BLS-QLSTM was validated on three real-world Chinese stock indices: CSI 300, SSEC, and CSI 500. For instance, on the CSI 500 dataset, BLS-QLSTM achieved a 36.5% reduction in RMSE compared to traditional LSTM and a 19.8% reduction compared to QLSTM. The model also showed consistent improvements in MAE and MAPE, while the R2 value reached 0.99404, indicating excellent fit and trend reconstruction ability. In terms of directional classification, the model achieved a classification accuracy of 0.77545 on CSI 500, outperforming LSTM and QLSTM by approximately 24.5% and 21.6%, respectively. Similar performance gains were observed on the CSI 300 and SSEC datasets, further demonstrating the model’s robustness and generalizability across diverse market conditions. These findings confirm that BLS-QLSTM not only enhances numerical prediction performance but also improves the recognition of stock price movement trends, offering a novel and practical approach to modeling chaotic financial time series.
The BLS-QLSTM model demonstrates significant value in both academic research and practical applications. For investors, the model offers precise price forecasting and trend analysis, serving as a scientific tool for optimizing asset allocation, improving investment decisions, and mitigating risks. For market regulators, the model excels in identifying market fluctuations, effectively aiding in the formulation of more precise regulatory policies, enhancing market stability and transparency, and supporting the healthy functioning of financial systems.
Despite the superior performance of the BLS-QLSTM model, there are certain limitations to this study. The maturity of current quantum computing hardware is insufficient to support large-scale applications. Additionally, the high cost of quantum computing restricts the model’s application to small-scale experimental studies. Furthermore, the interpretability of the model requires further enhancement to improve its usability and transparency in practical scenarios. Future research directions include optimizing the model architecture to reduce computational costs and enhance its interpretability and stability; exploring its application potential in other complex domains such as energy, healthcare, and transportation; and leveraging the continuous advancements in quantum computing technology to enable the large-scale implementation of the model in practice.
Data availability
The datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request.
References
An Z, Wu Y, Hao F, Chen Y, He X (2024) A novel hierarchical feature selection with local shuffling and models reweighting for stock price forecasting. Expert Syst Appl 249:123482. https://doi.org/10.1016/j.eswa.2024.123482
Bhandari HN, Rimal B, Pokhrel NR, Rimal R, Dahal KR, Khatri RKC (2022) Predicting stock market index using LSTM. Mach Learn Appl 9:100320. https://doi.org/10.1016/j.mlwa.2022.100320
Cai S, Gao H, Zhang J, Peng M (2024) A self-attention-LSTM method for dam deformation prediction based on CEEMDAN optimization. Appl Soft Comput 159:111615. https://doi.org/10.1016/j.asoc.2024.111615
Cao Y, Zhou X, Fei X, Zhao H, Liu W, Zhao J (2023) Linear-layer-enhanced quantum long short-term memory for carbon price forecasting. Quantum Mach Intell 5(2):26. https://doi.org/10.1007/s42484-023-00115-2
Chen SY-C, Yoo S, Fang Y-LL (2020) Quantum Long Short-Term Memory (arXiv:2009.01783). arXiv. https://doi.org/10.48550/arXiv.2009.01783
Chen Y, Hao Y (2018) Integrating principle component analysis and weighted support vector machine for stock trading signals prediction. Neurocomputing 321:381–402. https://doi.org/10.1016/j.neucom.2018.08.077
Chen Y, Wu J, Wu Z (2022) China’s commercial bank stock price prediction using a novel K-means-LSTM hybrid approach. Expert Syst Appl 202:117370. https://doi.org/10.1016/j.eswa.2022.117370
Chen Y, Xu X, Lan T, Zhang S (2024) The predictability of stock price: empirical study on tick data in Chinese Stock Market. Big Data Res 35:100414. https://doi.org/10.1016/j.bdr.2023.100414
Chhajer P, Shah M, Kshirsagar A (2022) The applications of artificial neural networks, support vector machines, and long–short term memory for stock market prediction. Decis Anal J 2:100015. https://doi.org/10.1016/j.dajour.2021.100015
Fischer T, Krauss C (2018) Deep learning with long short-term memory networks for financial market predictions. Eur J Oper Res 270(2):654–669. https://doi.org/10.1016/j.ejor.2017.11.054
Fu Y, Cao H, Chen X, Ding J (2022) Task-incremental broad learning system for multi-component intelligent fault diagnosis of machinery. Knowl -Based Syst 246:108730. https://doi.org/10.1016/j.knosys.2022.108730
Han M, Li W, Feng S, Qiu T, Chen CLP (2021) Maximum information exploitation using broad learning system for large-scale chaotic time-series prediction. IEEE Trans Neural Netw Learn Syst 32(6):2320–2329. https://doi.org/10.1109/TNNLS.2020.3004253
Havlíček V, Córcoles AD, Temme K, Harrow AW, Kandala A, Chow JM, Gambetta JM (2019) Supervised learning with quantum-enhanced feature spaces. Nature 567(7747):209–212. https://doi.org/10.1038/s41586-019-0980-2
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Hoseinzade E, Haratizadeh S (2019) CNNpred: CNN-based stock market prediction using a diverse set of variables. Expert Syst Appl 129:273–285. https://doi.org/10.1016/j.eswa.2019.03.029
Jailani NLM, Dhanasegaran JK, Alkawsi G, Alkahtani AA, Phing CC, Baashar Y, Capretz LF, Al-Shetwi AQ, Tiong SK (2023) Investigating the power of LSTM-based models in solar energy forecasting. Processes 11(5):1382. https://doi.org/10.3390/pr11051382
Janiesch C, Zschech P, Heinrich K (2021) Machine learning and deep learning. Electron Mark 31(3):685–695. https://doi.org/10.1007/s12525-021-00475-2
Kao L-J, Chiu C-C, Lu C-J, Chang C-H (2013) A hybrid approach by integrating wavelet-based feature extraction with MARS and SVR for stock index forecasting. Decis Support Syst 54(3):1228–1244. https://doi.org/10.1016/j.dss.2012.11.012
Khan SZ, Muzammil N, Ghafoor S, Khan H, Zaidi SMH, Aljohani AJ, Aziz I (2024) Quantum Long Short-Term Memory (QLSTM) vs Classical LSTM in Time Series Forecasting: A Comparative Study in Solar Power Forecasting. Front Phys 12:1439180. https://doi.org/10.3389/fphy.2024.1439180
Kumar S, Pal N, Tripathi AM (2024) Improving Long Short-Term Memory (LSTM)-Based Stock Market Price Predictions in the Machine Learning Era. 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), 923–928. https://doi.org/10.1109/IC2PCT60090.2024.10486391
Li F, Xiang W, Wang J, Zhou X, Tang B (2018) Quantum weighted long short-term memory neural network and its application in state degradation trend prediction of rotating machinery. Neural Netw 106:237–248. https://doi.org/10.1016/j.neunet.2018.07.004
Li G, Zhang A, Zhang Q, Wu D, Zhan C (2022) Pearson Correlation Coefficient-Based Performance Enhancement of Broad Learning System for Stock Price Prediction. IEEE Trans Circuits Syst II: Express Briefs 69(5):2413–2417. https://doi.org/10.1109/TCSII.2022.3160266
Li Z, Zhao J (2022) Stock price prediction based on ARIMA-PCA-BP hybrid model. 2022 2nd International Signal Processing, Communications and Engineering Management Conference (ISPCEM), 259–264. https://doi.org/10.1109/ISPCEM57418.2022.00058
Lin Z (2018) Modelling and forecasting the stock market volatility of SSE Composite Index using GARCH models. Future Gener Comput Syst 79:960–972. https://doi.org/10.1016/j.future.2017.08.033
Liu R, Liu Y, Zhao Y, Chen X, Cui S, Wang F, Yi L (2021) Multi-feature broad learning system for image classification. Int J Pattern Recognit Artif Intell 35(15):2150033. https://doi.org/10.1142/S0218001421500336
Lu L, Lei Y, Yang Y, Zheng H, Wang W, Meng Y, Meng C, Zha L (2023) Assessing nickel sector index volatility based on quantile regression for Garch and Egarch models: Evidence from the Chinese stock market 2018–2022. Resour Policy 82:103563. https://doi.org/10.1016/j.resourpol.2023.103563
Luo J, Wen C, Peng Q, Qin Y, Huang P (2023) Forecasting the effect of traffic control strategies in railway systems: A hybrid machine learning method. Phys A: Stat Mech Its Appl 621:128793. https://doi.org/10.1016/j.physa.2023.128793
Ma C, Yan S (2022) Deep learning in the Chinese stock market: The role of technical indicators. Financ Res Lett 49:103025. https://doi.org/10.1016/j.frl.2022.103025
Madge S, Bhatt S (2015) Predicting Stock Price Direction using Support Vector Machines. https://api.semanticscholar.org/CorpusID:43966173
Majumder, Md MR, Hossain, Md I, Hasan MK (2019) Indices prediction of Bangladeshi stock by using time series forecasting and performance analysis. Int Conf Electr, Comput Commun Eng (ECCE) 2019:1–5. https://doi.org/10.1109/ECACE.2019.8679480
Md AQ, Kapoor SAV, Sivaraman CJ, Tee AK (2023) Novel optimization approach for stock price forecasting using multi-layered sequential LSTM. Appl Soft Comput 134:109830. https://doi.org/10.1016/j.asoc.2022.109830. K. F., H., S., & N., J
Mondal P, Shit L, Goswami S (2014) Study of effectiveness of time series modeling (Arima) in forecasting stock prices. Int J Comput Sci, Eng Appl 4(2):13–29. https://doi.org/10.5121/ijcsea.2014.4202
Nahil A, Lyhyaoui A (2018) Short-term stock price forecasting using kernel principal component analysis and support vector machines: The case of Casablanca stock exchange. Procedia Comput Sci 127:161–169. https://doi.org/10.1016/j.procs.2018.01.111
Pao Y-H, Park G-H, Sobajic DJ (1994) Learning and generalization characteristics of the random vector functional-link net. Neurocomputing 6(2):163–180. https://doi.org/10.1016/0925-2312(94)90053-1
Parray IR, Khurana SS, Kumar M, Altalbe AA (2020) Time series data analysis of stock price movement using machine learning techniques. Soft Comput 24(21):16509–16517. https://doi.org/10.1007/s00500-020-04957-x
Peral-García D, Cruz-Benito J, García-Peñalvo FJ (2024) Systematic literature review: Quantum machine learning and its applications. Comput Sci Rev 51:100619. https://doi.org/10.1016/j.cosrev.2024.100619
Persio LD, Honchar O (2016) Artificial Neural Networks architectures for stock price prediction: Comparisons and applications. https://api.semanticscholar.org/CorpusID:7679322
Rebentrost P, Mohseni M, Lloyd S (2014) Quantum support vector machine for big data classification. Phys Rev Lett 113(13):130503. https://doi.org/10.1103/PhysRevLett.113.130503
Rizvi DR, Khalid M (2024) Performance analysis of stocks using deep learning models. Procedia Comput Sci 233:753–762. https://doi.org/10.1016/j.procs.2024.03.264
Rustam Z, Kintandani P (2019) Application of support vector regression in indonesian stock price prediction with feature selection using particle swarm optimisation. Model Simul Eng 2019:1–5. https://doi.org/10.1155/2019/8962717
Sergioli G, Giuntini R, Freytes H (2019) A new quantum approach to binary classification. PLOS ONE 14(5):e0216224. https://doi.org/10.1371/journal.pone.0216224
Sharma P, Dadheech P, Aneja N, Aneja S (2023) Predicting agriculture yields based on machine learning using regression and deep learning. IEEE Access 11:111255–111264. https://doi.org/10.1109/ACCESS.2023.3321861
Shen W, Guo X, Wu C, Wu D (2011) Forecasting stock indices using radial basis function neural networks optimized by artificial fish swarm algorithm. Knowl -Based Syst 24(3):378–385. https://doi.org/10.1016/j.knosys.2010.11.001
Su L, Xiong L, Yang J (2023) Multi-Attn BLS: Multi-head attention mechanism with broad learning system for chaotic time series prediction. Appl Soft Comput 132:109831. https://doi.org/10.1016/j.asoc.2022.109831
Takens F (1981) Detecting strange attractors in turbulence. In D. Rand & L-S Young (Eds.), Dynamical Systems and Turbulence, Warwick 1980 (898, pp. 366–381). Springer Berlin Heidelberg. https://doi.org/10.1007/BFb0091924
Tang H, Dong P, Shi Y (2021) A construction of robust representations for small data sets using broad learning system. IEEE Trans Syst Man Cybern: Syst 51(10):6074–6084. https://doi.org/10.1109/TSMC.2019.2957818
Wang M, Ge Q, Jiang H, Yao G (2019) Wear fault diagnosis of aeroengines based on broad learning system and ensemble learning. Energies 12(24):4750. https://doi.org/10.3390/en12244750
Wang Q, Chen D, Li M, Li S, Wang F, Yang Z, Zhang W, Chen S, Yao D (2023) A novel method for petroleum and natural gas resource potential evaluation and prediction by support vector machines (SVM). Appl Energy 351:121836. https://doi.org/10.1016/j.apenergy.2023.121836
Wang W-J, Jiang M-M, Wang S-M, Qu Y-J, Ma H-Y, Qiu T-H (2023) Quantum image chaos encryption scheme based on quantum long-short term memory network. Acta Phys Sin 72(12):120301. https://doi.org/10.7498/aps.72.20230242
Xie C, Rajan D, Chai Q (2021) An interpretable Neural Fuzzy Hammerstein-Wiener network for stock price prediction. Inf Sci 577:324–335. https://doi.org/10.1016/j.ins.2021.06.076
Xiong L, Su L, Wang X, Pan C (2024) Dynamic adaptive graph convolutional transformer with broad learning system for multi-dimensional chaotic time series prediction. Appl Soft Comput 157:111516. https://doi.org/10.1016/j.asoc.2024.111516
Yang R, Hu J, Li Z, Mu J, Yu T, Xia J, Li X, Dasgupta A, Xiong H (2024) Interpretable machine learning for weather and climate prediction: A review. Atmos Environ 338:120797. https://doi.org/10.1016/j.atmosenv.2024.120797
Yuan M, Li Z, Zhang C, Zheng L, Mao K, Pei F (2023) Research on real-time prediction of completion time based on AE-CNN-LSTM. Comput Ind Eng 185:109677. https://doi.org/10.1016/j.cie.2023.109677
Yun KK, Yoon SW, Won D (2021) Prediction of stock price direction using a hybrid GA-XGBoost algorithm with a three-stage feature engineering process. Expert Syst Appl 186:115716. https://doi.org/10.1016/j.eswa.2021.115716
Zhang L, Li J, Lu G, Shen P, Bennamoun M, Shah SAA, Miao Q, Zhu G, Li P, Lu X (2022) Analysis and variants of broad learning system. IEEE Trans Syst, Man, Cybern: Syst 52(1):334–344. https://doi.org/10.1109/TSMC.2020.2995205
Zhang S, Jia J, Gao M, Han X (2010) Study on the parameters determination for reconstructing phase-space in chaos time series. Acta Phys Sin 59(3):1576. https://doi.org/10.7498/aps.59.1576
Zhao C, Wu M, Liu J, Duan Z, Li J, Shen L, Shangguan X, Liu D, Wang Y (2023) Progress and prospects of data-driven stock price forecasting research. Int J Cogn Comput Eng 4:100–108. https://doi.org/10.1016/j.ijcce.2023.03.001
Zhou F, Zhang Q, Sornette D, Jiang L (2019) Cascading logistic regression onto gradient boosted decision trees for forecasting and trading stock indices. Appl Soft Comput 84:105747. https://doi.org/10.1016/j.asoc.2019.105747
Acknowledgements
This paper was supported by 23 Key Research Projects in Humanities and Social Sciences of Chongqing Municipal Education Commission (23SKGH251).
Author information
Authors and Affiliations
Contributions
SL: Conceptualization, Methodology, Project administration, Writing – review & editing, Fund acquisition. LD: Software, Formal analysis, Validation, Data curation, Visualization, Writing–original draft, Writing–review & editing. QD: Visualization, Investigation, Validation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Su, L., Li, D. & Qiu, D. BLS-QLSTM: a novel hybrid quantum neural network for stock index forecasting. Humanit Soc Sci Commun 12, 1011 (2025). https://doi.org/10.1057/s41599-025-05348-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-025-05348-z
