
Abstract
Hope is a vital coping mechanism, enabling individuals to effectively confront life’s challenges. This study proposes a technique employing Natural Language Processing (NLP) tools like Linguistic Inquiry and Word Count (LIWC), NRC-emotion-lexicon, and vaderSentiment to analyze social media posts, extracting psycholinguistic, emotional, and sentimental features from a hope speech dataset. The findings of this study reveal distinct cognitive, emotional, and communicative characteristics and psycholinguistic dimensions, emotions, and sentiments associated with different types of hope shared in social media. Furthermore, the study investigates the potential of leveraging this data to classify different types of hope using machine learning algorithms. Notably, models such as LightGBM and CatBoost demonstrate impressive performance, surpassing traditional methods and competing effectively with deep learning techniques. We employed hyperparameter tuning to optimize the models’ parameters and compared their performance using both default and tuned settings. The results highlight the enhanced efficiency achieved through hyperparameter tuning for these models.
Similar content being viewed by others

Introduction
Hope, in psychology, is regarded as a potent coping mechanism for individuals to confront and life challenges effectively1. Research on hope speech detection as a text classification task was initiated with two significant studies, each offering unique perspectives on the concept of hope. First, Chakravarthi2 modeled a binary hope speech classification task in which each YouTube comments were categorized into Hope and Not Hope. Chakravarthi2 defined hope as a mental state that intertwines present circumstances with future aspirations, emphasizing the inclination towards positive results. In other words, comments, where users shared support and positivity against their pairs, were identified as hope. e.g., sharing support for the LGBTQ community or sharing support for victims in war zones in times of conflicts between India and Pakistan2.
However, several researches also reported that individuals might occasionally hope for or seek a rational or irrational event or outcome when experiencing emotions like anger, sadness, or depression3,4,5.
Thus, it is evident that hope is not exclusively tied to positivity and can be influenced by or trigger other emotions and sentiments. Hence, Balouchzahi et al.6 presented another perspective for hope speech, addressing the limitations of the previous study by providing a more nuanced definition of hope based on psychology and considering potential negative emotions in the expression of hope. Balouchzahi et al.6 described hope as “an expectation, wish, or desire for something to happen or to be true”. In other words, hope was defined as a uniquely human faculty enabling individuals to visualize forthcoming events and their potential outcomes with adaptability6. Despite the remote possibility of desired outcomes, hope profoundly influences emotions, actions, and mental disposition7. In the PolyHope dataset developed by Balouchzahi et al.6, the hope speech detection task was modeled as a two-level, text classification task in which first, each English tweet was, first classified as Hope (as expectation) and Not Hope (absence of any expression of any expectation), then the pre-identified Hope tweets were further fine-grained into Generalized, Realistic, Unrealistic hopes. The definition of each type of hope is presented in Table 1 and some annotated samples from PolyHope dataset are presented in Table 2.
Several studies investigate various NLP techniques for detecting hope speech, as discussed in "Related work" section . These techniques range from n-grams with traditional machine learning models and word embeddings with neural networks to language models and transformers6,8.
However, no prior research has explored the psycholinguistic, emotional, and sentimental dimensions of hope despite acknowledging the significance of other emotions and psychological features linked to hope3,4,5. Thus, in this study, we introduce a feature extraction approach aimed at extracting the earlier mentioned features using tools such as LIWC9, NRC-emotion-lexicon10, and vaderSentiment11.
Social media provides a platform where users express not only positive aspirations but also a range of complex emotions, from realistic hopes to irrational desires influenced by negative emotions such as anger or sadness3,4,5. By focusing on hope as a central concept, this study aims to capture the emotional depth of social media interactions, where hope is not limited to optimism but is intertwined with the psychological states and emotional contexts users experience in their daily lives. Understanding these manifestations can offer valuable insights into how individuals use social platforms to express and manage emotional resilience and expectations.
The main contributions of the current study are listed as follows,
-
Exploration of Hope Variability Investigating how different types of hope manifest distinct psycholinguistic dimensions, emotional expressions, and associated sentiment.
-
Computational Approach Development Developing and demonstrating the efficacy of computational methods in leveraging psycholinguistic dimensions, emotional expressions, and sentiment features for distinguishing between various types of hope and training machine learning models.
-
Performance Evaluation Assessing the performance of machine learning models utilizing psycholinguistic dimensions, emotional expressions, and sentiment features in comparison to models relying solely on linguistic features.
-
Benchmarking Against Deep Learning Models Comparing the performance of machine learning models employing psycholinguistic dimensions, emotional expressions, and sentiment features with that of state-of-the-art deep learning and transformer-based models in the context of hope speech detection.
Tools
These tools were used to extract psycholinguistic, emotional, and sentimental features to examine the association between various types of hope. Subsequently, the extracted features were employed to test the performance of machine learning models in distinguishing different types of hope using these features. LIWC: The introduction of the LIWC model represented a significant leap forward in psychological research, elevating the strength, accessibility, and scientific integrity of language data analysis. The recent LIWC-2212 explores over 100 textual dimensions rigorously validated by esteemed research institutions globally13. With over 20,000 scientific publications utilizing LIWC, it has become a highly esteemed and indispensable tool in the field of NLP14,15.
-
VaderSentiment VaderSentiment11 is a valuable tool for swiftly and automatically evaluating sentiment in text data, rendering it applicable across various domains such as social media monitoring, customer feedback analysis, and market research16. Utilizing a pre-existing lexicon comprising thousands of words, each accompanied by polarity (positive or negative) and intensity scores, VADER continuously updates and refines this lexicon to enhance its accuracy11.
-
NRC Emotion Lexicon NRC Emotion Lexicon10 provides a structured framework for analyzing and understanding the emotional content of the text. It manually annotates words with binary values representing their associations with eight basic emotions: anger, anticipation, disgust, fear, joy, sadness, surprise, and trust. Using contextual usage, words are scored based on their semantic connections to each emotion.
Related work
Hope speech detection
Chakravarthi2 developed the Hope Speech for Equality, Diversity, and Inclusion (HopeEDI) dataset by gathering user comments from YouTube. They manually labeled these comments as containing hopeful content or not, resulting in 28,451 comments in English, 20,198 in Tamil, and 10,705 in Malayalam. The comments in languages other than the intended ones were labeled as “other languages”. Detailed statistics of this dataset are presented in Table 3. They employed various machine learning algorithms such as Support Vector Machine (SVM), Multinomial Naive Bayes (MNB), K-Nearest Neighbors (KNN), Decision Tree (DT), and Logistic Regression (LR). The results show that DT, with average weighted F1 scores of 0.46 and 0.56, outperformed other models for English and Malayalam, respectively. However, for Tamil texts, LR achieved the highest average weighted F1 score of 0.55.
García-Baena et al.17 following the same perspective as2 presented a Spanish Twitter dataset, called SpanishHopeEDI, that has been constructed specifically targeting hope and support for the LGBT community. This dataset comprises Spanish tweets collected using the Twitter API from June 27, 2021, to July 26, 2021. The dataset includes annotations categorizing tweets as Hope Speech (HS) and non-Hope Speech (NHS), with 825 tweets labeled HS and 1,301 as NHS. Furthermore, several experiments have been conducted to establish baseline performance on this dataset. The best result was achieved using transformers, yielding an average F1 score of 85.12%
Further, the aforementioned datasets2,17 were publicly shared in several shared tasks that summary of models submitted there are presented in Table 4. It shows different learning approaches combined with various features were used for the task of binary hope speech detection in HopeEDI2 and SpanishHopeEDI17. The comparison of average marco F1 scores shows higher performance for Spanish data, which could be due to a more balanced dataset.
Among the models submitted in these shared tasks, Balouchzahi et al.19 presented two models employing deep learning and traditional machine learning approaches. They utilized TF-IDF Vectorizer to vectorize the character and word n-grams extracted from the texts. They only used the 30,000 most frequent from each n-gram type. The authors further proposed a feature selection method employing an ensemble method. Two DT models were combined with one RF model to produce feature importance for the extracted features. These selected features were then used alone and combined with psycholinguistic features from LIWC26 for binary hope speech detection in English and Spanish texts. The best-performing achieved with the deep learning model with a weighted average F1 score of 0.870 with only LIWC features, securing the second rank for English. However, when combining LIWC features with word and character n-grams, the team attained the third rank for Spanish text with a weighted average F1 score of 0.790.
In another study, Gowda et al.18 addressed the imbalance distribution of labels in HopeEDI2 dataset for English text. The proposed methodology employs re-sampling techniques and led to attaining the 1st rank for the English language, achieving a macro-averaged F1 score of 0.550 and a weighted averaged F1-score of 0.860 with the 1D Conv-LSTM model.
Balouchzahi et al.6 introduced PolyHope, the first multiclass hope speech detection dataset in English. The statistics of this dataset are presented in Table 5 and details are given in “Dataset” section . To benchmark the dataset’s performance, the study evaluated several baseline models utilizing diverse learning approaches, such as traditional machine learning, deep learning, and transformer-based methods. Table 6 presents the results for the top-performing models for each learning approach, showcasing the average macro F1 scores for both binary and multiclass classification tasks on the PolyHope dataset.
Psychologistics and emotion analysis
Butt et al.27 examined the psycholinguistic dimensions of rumors circulated on online social media (OSM). Utilizing the PHEME dataset28, which encompasses news events. The researchers scrutinized both source tweets (rumor and non-rumor) and response tweets. They incorporated various psycholinguistic features, including LIWC, SenticNet29, readability indices, and emotions, to unveil patterns in user behavior. It was observed that rumor source tweets tended to employ language indicative of the past, prepositions, and motivations associated with reward, risk, and power. Conversely, non-rumor source tweets exhibited affective and cognitive processes, language-oriented towards the present, and motivations linked to affiliation and achievement. Emotional analysis revealed that non-rumor tweets tended towards neutrality, while rumor-source tweets elicited fear and grief, subsequently provoking anger and fear in reactions.
Shahiki Tash et al.30 conducted a thorough investigation into the psycholinguistic and emotional dimensions of English tweets, discussing nine prominent cryptocurrencies. They analyzed co-mentions among these cryptocurrencies and meticulously processed a dataset of 832,559 tweets, refining it to 115,899 tweets from September 2021 to March 2023. Utilizing tools such as LIWC, Emotion analysis, Sentiment analysis, and Readability analysis, they examined linguistic characteristics and sentiment patterns associated with different cryptocurrencies. Their findings underscored significant variations in psycholinguistic traits, sentiment expressions, readability levels, and co-mentions across different cryptocurrencies. The study provided valuable insights into user perceptions and interactions regarding cryptocurrencies on social media platforms by employing psycholinguistic scrutiny, emotion analysis, and co-mention examinations.
In their study, Ali et al.16 explore the emotions and motivations associated with nonmedical prescription drug use (NMPDU). They looked at social media posts about NMPDU, analyzing a huge dataset of 137 million posts from 87,718 users. They aimed to understand the feelings, sentiments, worries, and reasons behind NMPDU. They developed NMPDU classification models using RoBERTa and achieved an accuracy of 82.32% on a binary classification of NMPDU and non-NMPDU tweets31. To analyze, they also gathered data on the genders of non-NMPDU users (the control group) from Twitter32,33. They used various tools for their analysis: for emotion analysis, they used a lexicon from the National Research Council of Canada10, while for sentiment analysis of NMPDU tweets, they employed VADER34,35. Personal and social concerns were analyzed using LIWC26, and statistical testing was done using the Mann-Whitney U test36,37. They also utilized LDA for topic modeling38. Their findings reveal that NMPDU users express more negative emotions and fewer positive ones compared to a control group, with heightened concerns about family, the past, and body and reduced concerns about work, leisure, home, money, religion, health, and achievement. NMPDU-related posts display high emotional polarization, indicating potential emotional triggers. Gender-specific analysis shows that female NMPDU users express more positive emotions, anticipation, sadness, joy, and concerns about family, friends, home, health, and the past compared to males, with consistent patterns across different prescription drug categories such as opioids, benzodiazepines, stimulants, and polysubstance.
Wuraola et al.39 introduces a method to analyze language and cultural differences in tweets about climate change from the UK and Nigeria. They gathered 81,507 tweets in English, with 44,071 from the UK and 37,436 from Nigeria. The researchers combined transformer networks with linguistic analysis using LIWC-2212 to address the small dataset size and identify cultural nuances. Findings reveal that Nigerians tend to use more leadership language and informal words when discussing climate change on platform X, emphasizing its importance. On the other hand, climate change discourse in the UK is more formal, logical, and features longer sentences. The study also confirms the tweet’s origin using DistilBERT with an 83% accuracy rate.
Methodology
The methodology employed in the present study comprises two primary phases: feature extraction and model construction. Various psycholinguistic, emotional, and sentiment features were extracted from the text to initially analyze their associations with different types of hope. These features were then fed into machine learning classifiers to determine if they could computationally classify hope into different categories. First, we discuss the dataset used in this study, followed by feature analysis and experiments.
Dataset
The Polyhope dataset used in this study was collected by6. The authors utilized Tweepy API for data collection and filtered tweets based on parameters such as date, language, and content quality. They collected around around 100,000 English tweets based on keywords from the first half of 2022. The PolyHope dataset covers a broad spectrum of topics, including discussions on women’s child abortion rights, black people’s rights, religion, and politics, offering a comprehensive view of contemporary social discourse. After collection, the dataset underwent processing to ensure data integrity. Incomplete, duplicate, and excessively brief tweets were removed, resulting in a refined dataset comprising approximately 23,000 original tweets. After that, these tweets were shuffled, and a sample of 10,000 tweets was randomly taken for the annotation process. The final statistical properties of the dataset after annotations are summarized in Table 5.
Feature analysis
This section describes the psycholinguistic, emotional, and sentiment features employed in this study and presents their association with different types of hope.
LIWC
We utilized a comprehensive array of exit analysis features, covering Summary Variables, Linguistic Dimensions, Drives, Cognition, Affect, Social Processes, Culture, Lifestyle, Physical Attributes, States, Motives, Perception, and Conversation from LIWC. The average statistics regarding their associations with different types of hope are presented in Table 7. The description and summary of what these features provide is outlined below:
-
Word count Word count (WC) is used to assess user engagement and fluency in a conversation. In other words, this feature presents, how divers could be the vocabulary and words used to express an idea. Our findings indicate that unrealistic hope typically garners lower scores than other categories. This suggests that individuals expressing unrealistic hope use fewer words to express their expectations and may have less expertise on the topic, resulting in fewer words. Conversely, individuals discussing realistic or general hope possess more comprehensive knowledge and express their expectations with longer text and more diverse vocabulary. The statistics in Table 7 show that there are different ratios of association between this feature and different types of hope. Therefore, the WC could effectively be used as a feature to distinguish between Generalized, Realistic, and Unrealistic Hope.
-
Function words The function words in LIWC encompass various linguistic elements such as total pronouns, impersonal pronouns, articles, prepositions, auxiliary verbs, common adverbs, conjunctions, and negations. Pronouns offer valuable insights into users’ personalities, revealing their communication styles and interactions with others40,41,42. We have grouped this information and calculated the average value for each type of hope. Higher scores for function words in Table 7, especially in Unrealistic Hope, indicate more frequent use of linguistic elements, suggesting a complex communication style. In contrast, lower scores in Generalized or Realistic Hope imply a simpler, more direct communication style, possibly reflecting a pragmatic approach to expressing hopeful perspectives.
Drives refer to a broad dimensions encompassing a range of needs and motivations43. The data presented in Table 7 indicates that higher scores are associated with realistic hope, while lower scores are linked to unrealistic hope. This suggests that individuals with lower motivation tend to exhibit more unrealistic hope, highlighting a direct correlation between realistic hope and motivation.
Cognition provides an understanding of the rationale and disparities in the thought processes of the writer41,44. Based on Table 7, the “Cognition” feature has yielded the following scores: generalized hope (4.40), realistic hope (4.20), and unrealistic hope (4.60). These results suggest that individuals expressing unrealistic hope often engage in cognitive processes that involve imagining favorable outcomes that may seem improbable or unlikely. Unlike realistic hope, where expectations are grounded in what is feasible and achievable, unrealistic hope ventures into the realm of the improbable or even fantastical. Therefore, unrealistic hope may lead to higher levels of cognitive engagement due to its imaginative nature, and it is essential to recognize the potential drawbacks, such as the risk of disappointment, if desired outcomes fail to materialize.
Affect covers diverse emotional aspects, comprising positive and negative emotions, anxiety, anger, sadness, and swear words45. The high score for generalized hope in the Affect feature indicates that individuals expressing generalized hope may exhibit a higher frequency of affective language than other types of hope. This means that individuals with generalized hope are more likely to convey their emotional states, such as joy, optimism, enthusiasm, or determination. This suggests that the Affect feature could be a valuable indicator for distinguishing between different types of hope.
Social processes discuss various linguistic expressions representing human interactions, including personal pronouns and verbs indicating engagement, which contribute to understanding social dynamics45. The high score for generalized hope within social processes suggests a substantial presence of language related to human interactions and social dynamics, implying a robust association between generalized hope and social engagement.
Culture category includes three cultural domains: Politics, Ethnicity, and Technology, including words related to political discourse, ethnic identities, and scientific advancements, respectively9. The high score for realistic hope compared to the rest of them within the Culture category suggests that individuals expressing realistic hope tend to use more language related to politics, ethnicity, and technology than other types of hope. This indicates that their expressions of hope may be influenced by or intertwined with cultural, political, ethnic, and technological factors.
The definition of Lifestyle contains aspects such as work, home, school, and employment9. The high score for realistic hope within the Lifestyle category suggests that expressions of this type of hope is closely associated with various aspects of daily life, including work, home, school, and employment. This indicates that individuals expressing realistic hope may have a strong focus on practical and tangible elements of their lifestyle.
The Physical dimension includes health-related terms categorized into subcategories such as illness, wellness, mental health, and substances, encompassing a wide range of physical and mental health aspects9. The scores for generalized (0.29), realistic (0.2), and unrealistic hopes (0.42) in the “physical” dimension show that individuals talking about health issues tend to express more unrealistic hopes that could be out of sadness and disappointment.
States encompass numerous short-term or fleeting internal conditions capable of influencing behaviors, as detailed in studies such as46,47. The similar results for all three types of hope in the States category indicate the internal states associated with these different types of hope are relatively consistent across the board.
Motives are fundamental internal states that propel, direct or attract an individual’s behavior9. The high score for generalized hope and the lowest score for realistic hope in the Motives category suggests that individuals with realistic hope may approach their goals with a more tempered or practical mindset, perhaps guided by a balanced assessment of possibilities and limitations.
Perception includes various elements such as attention, motion, space, visual, auditory, and feeling9. The consistent results across different types of hope suggest that there may be similarities in certain aspects or dimensions among them, indicating potential commonalities in the underlying factors or characteristics associated with each type of hope.
Conversation comprises components like Netspeak, Assent, Nonfluencies, and Fillers9. The low score for realistic hope compared to other types of hope in the Conversation feature, along with similar scores among the other types, suggests that realistic hope appears to be less frequently expressed or communicated within conversational settings than other types of hope. This could indicate that individuals with realistic hope may be less inclined to vocalize their aspirations or may approach conversations with a more reserved or pragmatic demeanor, resulting in fewer instances of verbal expression related to hope.
Sentiments
VaderSentiment11 was applied to perform sentiment analysis on the PolyHope dataset.
Table 8 presents a sentiment analysis, delineating positive, neutral, and negative correlations with different hope categories. The data predominantly reflects neutral or positive sentiments, with a minority expressing negativity, implying an optimistic or balanced perspective on hope. This finding suggests the potential presence of hope even amidst negative sentiments. Additionally, the table illustrates that positive sentiments are more associated with generalized and realistic hope. In contrast, negative sentiments correlate more with unrealistic hope, aligning with psychological researchers’ earlier definitions of unrealistic hope3,4,5. A graphical presentation of this analysis is presented in Fig. 1.

Sentiments and Hopes.
Emotions
In this study, NRC Emotion Lexicon10 was used for emotion analysis of various types of hope. As presented in Table 9, generalized and realistic hope exhibit higher levels of positive emotions, such as anticipation, joy, and trust, while displaying lower values of negative emotions compared to unrealistic hope. Conversely, unrealistic Hope was more associated with negative emotions like anger, fear, and sadness and lower frequencies in positive emotions.
This emotion analysis reveals stark differences in the emotional experiences associated with each type of hope. While generalized and realistic hope is characterized by positivity and optimism, unrealistic hope is marked by a mixture of negative emotions and a lack of positive emotional expression. Understanding these emotional nuances provides valuable insights into the psychological dynamics underlying different types of hope and their impact on individuals’ emotional well-being.
A graphical representation of different emotions associated with different types of hope is presented in Fig. 2.

Emotions and Hopes.
Experiments
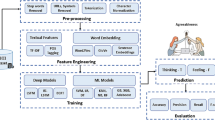
Gradient boosting methods have demonstrated efficacy across a spectrum of machine learning and text classification tasks48. The gradient boosting algorithms, such as XGBoost, LightGBM, and CatBoost, prioritize both speed and accuracy. XGBoost stands out as a scalable ensemble technique renowned for its reliability and efficiency in tackling machine learning challenges. LightGBM, on the other hand, prioritizes speed without compromising accuracy, achieved through selective sampling of high gradient instances during training. CatBoost introduces a novel approach by adjusting gradient computation to mitigate prediction shifts, thereby enhancing model accuracy49. Hence, in this work, we have utilized these three gradient boosting algorithms for hope speech classification using features discussed in "Feature analysis" section. The experiments have several steps, as shown in Fig. 3 and described below:

Overview of proposed methodology for hope speech classifications.
-
Preprocessing Initially, text preprocessing involved converting emojis and emoticons into textual data using the emot library (https://pypi.org/project/emot/). Subsequently, abbreviations were expanded to their full forms using a predefined dictionary, and punctuations as well as stopwords were eliminated.
-
Feature extraction We extracted various psycholinguistic and emotional features, as well as sentiment features, utilizing LIWC26, the NRC Emotion Lexicon10, and VaderSentiment11. We used this feature to create a vector space for each text so that each tweet is presented with a feature vector of their psychological, emotional, and sentiment scores. Additionally, we extracted n-gram features to facilitate comparison across different feature combinations. The feature size statistics are presented in Table 10.
-
Feature selection Utilizing character and word ngrams significantly increases the feature dimensions in the text classification experiments50. To improve interpretability, reduce overfitting, and lower dimensionality, thereby enhancing model performance51, we utilized SelectFromModel from the sklearn.feature_selection library as a simple feature selection method, focusing solely on n-grams features. This meta-transformer selects features based on their importance weights, simplifying models by highlighting the most informative features, thus promoting efficiency and improving interpretability. The feature selection was done based on the feature importance values obtained from a random forest classifier integrated with the SelectFromModel module.
-
Hyperparameter tuning Hyperparameter tuning is a crucial step in optimizing the performance of machine learning models. It assists in adjusting complexity and controlling the learning process of the model, thereby resulting in optimized performance and efficient use of resources52. In this work, we used Bayesian Optimization techniques, which is a well-known strategy for hyperparameter tuning for many machine learning tasks53,54. It automates the tuning process, and improves performance by finding optimized values for all hyperparameters55. Some studies argue that Bayesian Optimization is superior to random search for machine learning hyperparameter tuning56. The objective is to identify the optimal values for the parameters of machine learning models. To achieve this, we provide a range of values for each parameter and utilize the proposed algorithm to determine the optimized one. Table 11 outlines the specific algorithms used (LightGBM, CatBoost, XGBoost) along with their corresponding parameters and search ranges. For each algorithm, we used Bayesian Optimization to explore the search space efficiently. We allowed a maximum of 10 trials for LightGBM, 10 trials for CatBoost, and 20 trials for XGBoost. These settings helped balance the exploration of the parameter space while ensuring computational efficiency. Table 12 presents the default and optimized values for each feature set and machine learning model.
-
Model training and predictions We employed a 5-fold cross-validation technique in all experiments. The evaluation and comparison were based on the average weighted and macro scores of all folds. The results are detailed in “Results” section.
Results
This section provides details on the performance of the proposed methodology in binary and multiclass hope speech detection. We present the performance of each classifier using three feature sets: only n-grams, exclusively psycholinguistic, emotional, and sentiment features, and combinations of all features.
Binary hope speech detection
Tables 13 and 14 present the average weighted and macro scores for binary hope speech detection using default and fine-tuned hyperparameters, respectively. The results clearly demonstrate that incorporating psycholinguistic, emotional, and sentiment features significantly enhances the model’s ability to differentiate between hope and non-hope tweets. Additionally, the combination of these features with linguistic n-grams yields superior performance across all machine learning models, further emphasizing the synergistic effect of diverse feature sets in this task.
The LightGBM model, in particular, stands out as the best-performing model when all features are used together, achieving an average macro F1 score of 0.8161. This result underscores the robustness of the LightGBM model in handling complex feature interactions, especially when enriched with both linguistic and psycholinguistic inputs. Similarly, both CatBoost and XGBoost also demonstrate solid performance improvements with the use of combined features, although slightly trailing behind LightGBM.
A key element in the improved performance is the role of hyperparameter tuning. When comparing the default parameter results in Table 13 with the fine-tuned results in Table 14, it is evident that fine-tuning hyperparameters leads to measurable gains across all models. For example, precision, recall, and F1 scores see consistent, albeit slight, improvements. This highlights the importance of finding the optimal set of hyperparameters to maximize the model’s learning capacity and generalization power.
Multiclass hope speech detection
Similar to the binary classification results, the multiclass hope speech classification results reveal the positive impact of hyperparameter tuning on model performance. Comparing the results with fine-tuned parameters in Table 16 to those generated with default settings in Table 15, we observe noticeable differences in all evaluation metrics.
For example, in the fine-tuned results, LightGBM achieved a macro F1-score of 0.5800 when using a combination of LIWC Emotions, Sentiments, and N-grams, whereas the default settings showed a lower macro F1-score of 0.5600. This trend is consistent across all models, where the precision, recall, and F1-scores are consistently higher with tuned parameters.
The improvements highlight how hyperparameter tuning allows models to better capture the nuances within multiclass hope speech detection, especially when dealing with varied emotional and psycholinguistic features.
In contrast, models with default parameters suffer from underperformance, as reflected in Table 15. For instance, XGBoost’s weighted F1-score with default parameters dropped from 0.6534 (tuned) to 0.6293 (default), underscoring the importance of tuning in maximizing performance for multiclass tasks. These findings reiterate the critical role that hyperparameter optimization plays in improving model accuracy and generalization across all features and tasks in the hope speech classification.
Error analysis
In this segment, we delve into the potential causes behind misclassification within the proposed methodology. Due to constraints on page space, our analysis focuses solely on the best-performing model utilizing psychological dimensions, emotions, and sentiments features for the multiclass hope speech detection task. According to Table 16, this model, LightGBM, achieved an averaged macro F1 score of 0.5507 across all folds. Consequently, we proceeded to retrain the model with a 70–30% split for training and test sets. The breakdown of classwise results in Table 17 indicates that the model performed better in identifying GH and UH compared to RH. This discrepancy may stem from the following potential factors.
-
The imbalanced distribution of labels in the PolyHope dataset for the multiclass classification task; GH possesses a higher number of labels than other types of hope, while RH has fewer samples. Addressing this issue could involve experimenting with various techniques for handling imbalanced datasets, a consideration left for future exploration.
-
The confusion matrix depicted in Fig. 4 reveals that GH was rarely confused with the other two types of hopes, resulting in higher scores, whereas RH was frequently misclassified with both GH and UH, leading to lower scores compared to other types of hope. Ultimately, UH experienced fewer misclassifications compared to RH and was only misclassified with GH, resulting in more accurate predictions compared to RH.
Fig. 4 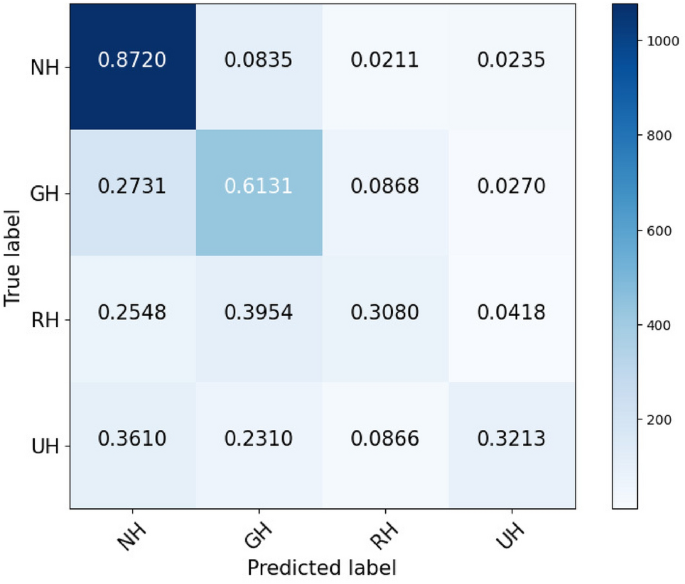
Confusion matrix for the best performing model (LightGBM) using psychological dimensions, emotions, and sentiments features.
-
In Table 18, we have compared the expression of various sentiments and emotions in both correctly classified and misclassified samples. It is evident that when texts exhibit fewer emotional and sentimental contexts, the model struggles with classification. This is understandable given that the model is trained on these data; insufficient sentiment and emotional context can lead to prediction failures. Conversely, in misclassified samples, there is a notable increase in the expression of positive sentiment and joy compared to correctly predicted samples. This observation aligns with insights from Figs. 1 and 2, which demonstrate that GH and RH are associated with higher levels of positive sentiments and emotions than UH. Additionally, considering the confusion matrix in Fig. 4, it’s apparent that these features may contribute to misclassification between GH and RH.

Discussion
The proposed methodology has several characteristics and limitations, as summarized below:
-
In “Feature analysis” section , this research computationally validated assertions made by psychologists and scholars regarding the correlation between diverse forms of hope and various emotions and sentiments. Moreover, it conducted a thorough examination of hope through multiple psychological dimensions, substantiating the utility of these features either independently or in conjunction with linguistic features for the training of machine learning models.
-
Comparisons presented in Fig. 5 demonstrate that machine learning models utilizing all feature sets effectively distinguished between hope and not hope tweets in a binary classification task. This comparison highlights that the suggested combination of psycholinguistic, emotional, and sentiment features can achieve comparable, if not marginally superior, performance compared to solely using n-gram features. However, the enhanced efficacy of these features is further evident in Fig. 6, where experiments illustrate that machine learning models incorporating these proposed features, both individually and in conjunction with n-grams, significantly outperformed other experiments in the multiclass classification of hopeful speech texts.
-
In Table 19, a comparison is made between the top-performing machine learning models employing the suggested feature set and the conventional machine-learning models utilizing TF-IDF features used in6. The results show that our proposed approach achieves a 4% higher averaged macro F1 score in multiclass hope speech detection, outperforming the traditional models.
-
When we compare the results of our proposed methodology with those of deep learning models, we find that our approach performs competitively. However, there is a noticeable gap when compared to state-of-the-art transformer models. This suggests that when equipped with appropriate feature sets, simpler machine learning models can achieve comparable results to more complex deep learning models that use embeddings but with fewer resource requirements. Nevertheless, the lower performance compared to transformers indicates that transformers, with their access to broader contextual information, still outperform our approach.
-
The findings from comparing models with default and tuned parameters suggested that the careful selection of features, combined with hyper parameter optimization, plays a crucial role in achieving enhanced results in the hope speech detection tasks. The improvements, though subtle, demonstrate how tuning can enhance model performance and drive more accurate classification outcomes in sentiment analysis tasks such as this. In particular, the tuning process allowed for better calibration of parameters such as the number of leaves, learning rate, and max depth in LightGBM, as well as equivalent parameters in CatBoost and XGBoost. These adjustments enable the models to capture more nuanced patterns in the data, resulting in better precision and recall, especially in cases where the default settings might have underfit or overfit the data.
-
Despite their numerous advantages in text analysis, the libraries used in this study to extract emotions, sentiments, and psychological dimensions have notable limitations. One such limitation is LIWC’s reliance on predefined linguistic categories, which may not fully capture the nuanced variations and complexity inherent in natural language. This becomes particularly problematic when dealing with subtle forms of language such as sarcasm, irony, or culturally specific idiomatic expressions, which these tools may misinterpret or fail to detect altogether. Similarly, VaderSentiment and other lexicon-based tools may introduce bias, especially when applied to diverse datasets where linguistic conventions and emotional expressions vary widely across cultures and contexts. Such biases could lead to inaccuracies in the classification of text, particularly in cases where emotions like hope are intertwined with more complex or ambiguous language. These limitations highlight the need for more sophisticated tools, such as large language models (LLMs), which can better capture linguistic nuances, though current challenges like resource constraints and the hallucination problem in LLMs make their adoption in this study infeasible. Future work could explore the integration of these advanced models to improve the detection and interpretation of emotional and psychological dimensions in hope speech.
-
The choice of models in this study was significantly influenced by resource limitations, particularly in terms of available memory (RAM) and GPU capabilities. Transformer-based models, while offering superior performance due to their ability to capture long-range dependencies and nuanced language patterns, require substantial computational power, making them less feasible for resource-constrained environments. Furthermore, the focus of our research was primarily on analyzing how emotions affect different types of hope, rather than solely achieving state-of-the-art performance. As a result, we opted for traditional machine learning models, which, when combined with psycholinguistic, emotional, and sentiment features, offer competitive performance while providing valuable insights into the emotional dimensions of hope, all at a fraction of the computational cost.
-
Expanding on the practical applications of our findings, the proposed methodology for hope speech detection could be highly valuable in real-world scenarios, particularly in mental health interventions and marketing strategies. In the context of mental health, analyzing hope-related speech on social media platforms could assist in identifying individuals expressing various types of hope, including those with unrealistic expectations or signs of emotional distress. This information could enable timely interventions by mental health professionals, providing targeted support to individuals in need. Additionally, the insights gained from understanding emotional expressions of hope could inform marketing strategies, particularly in campaigns focused on consumer well-being, motivation, or resilience. Brands could leverage this data to craft messages that resonate with audiences’ psychological states, enhancing engagement and fostering positive connections. Expanding on these potential applications would underscore the broader societal and commercial impact of this research.
-
The dataset used in this study plays a crucial role in shaping the findings, as the nature and quality of the data directly impact the model’s performance and generalizability. Since the dataset is focused on hope speech in specific contexts, such as social media platforms, the results may reflect particular linguistic patterns, emotional expressions, or cultural nuances that are unique to these environments. As a result, the findings may be influenced by the dataset’s limitations in capturing the full diversity of language use across different communities or contexts. Future work could address this by expanding the dataset to include more varied sources and languages, enhancing the robustness of the conclusions.
-
Table 20 provides a concise overview of the distinct characteristics associated with each type of hope based on the findings. It highlights differences in cognitive engagement, emotional expression, communication style, and focus areas across Unrealistic, Generalized, and Realistic Hope.

Averaged macro F1 score comparison of machine learning models using various feature sets for binary hope speech detection.

Averaged macro F1 score comparison of machine learning models using various feature sets for multiclass hope speech detection.
Conclusion
This study delved into the psycholinguistic, emotional, and sentiment dimensions of different types of hope computationally. Additionally, we proposed a method for detecting hope speech in tweets by utilizing features derived from these dimensions. Through computational validation, we established a connection between different forms of hope and emotions/sentiments, demonstrating the effectiveness of these features for machine learning models.
The results and analysis justified the fact that different types of hope have different ratios of association with various psycholinguistic dimensions, emotions, and sentiments. We also showed that this information can be used as features for distinguishing between different types of hope using machine learning models. Notably, the LightGBM model, when integrated with the proposed feature sets, outperformed other experiments, emphasizing the significance of incorporating psycholinguistic, emotional, and sentiment features for precise classification.
These findings carry numerous implications across various domains. In psychology and mental health, understanding the emotional profiles linked with different types of hope could guide therapeutic interventions to foster realistic and constructive hope patterns while mitigating harmful ones. Moreover, in communication and persuasion, acknowledging the emotional foundations of hope might inform strategies for effectively conveying messages of optimism and motivation. Additionally, recognizing hope-related emotional patterns could facilitate empathy and comprehension among individuals with differing viewpoints on social dynamics and conflict resolution. Furthermore, in fields like marketing and product development, leveraging emotional insights about hope could improve the design of advertisements and products that resonate with consumers’ aspirations and desires. These findings provide valuable insights into the intricate relationship between hope and emotions, with implications extending from individual well-being to broader societal interactions and marketing strategies.
In future endeavors, we intend to explore the potential integration and collaboration of these features with more sophisticated learning approaches. Moreover, future work could involve investigating advanced techniques for handling imbalanced datasets, improving feature extraction methods through deep learning-based embeddings, and exploring multimodal approaches to enrich the comprehension of hope speech in diverse contexts. Further, in future research we plan to investigate the generalizability of these findings by applying the proposed methodology to more diverse datasets, including those spanning various languages and cultural contexts.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Snyder, C.R. Handbook of Hope: Theory, Measures, and Applications (Academic Press, 2000).
Chakravarthi, B.R. Hopeedi: A multilingual hope speech detection dataset for equality, diversity, and inclusion. In Proceedings of the Third Workshop on Computational Modeling of People’s Opinions, Personality, and Emotion’s in Social Media, 41–53 (2020).
Eliott, J. & Olver, I. The discursive properties of “hope’’: A qualitative analysis of cancer patients’ speech. Qual. Health Res. 12, 173–193 (2002).
Links, M. & Kramer, J. Breaking bad news: Realistic versus unrealistic hopes. Support. Care Cancer 2, 91–93 (1994).
Webb, D. Modes of hoping. Hist. Hum. Sci. 20, 65–83 (2007).
Balouchzahi, F., Sidorov, G. & Gelbukh, A. Polyhope: Two-level hope speech detection from tweets. Expert Syst. Appl. 225, 120078 (2023).
Bruininks, P. & Malle, B. F. Distinguishing hope from optimism and related affective states. Motiv. Emot. 29, 324–352 (2005).
Sidorov, G., Balouchzahi, F., Butt, S. & Gelbukh, A. Regret and hope on transformers: An analysis of transformers on regret and hope speech detection datasets. Appl. Sci. 13, 3983 (2023).
Boyd, R.L., Ashokkumar, A., Seraj, S. & Pennebaker, J.W. The development and psychometric properties of liwc-22. Austin, TX: University of Texas at Austin 1–47 (2022).
Mohammad, S. M. & Turney, P. D. Crowdsourcing a word-emotion association lexicon. Comput. Intell. 29, 436–465 (2013).
Hutto, C. & Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media 8, 216–225 (2014).
LIWC. LIWC: A Linguistic Inquiry and Word Count Standard. (2024). Available at https://www.liwc.app/download (2024).
Lyu, S., Ren, X., Du, Y. & Zhao, N. Detecting depression of Chinese microblog users via text analysis: Combining linguistic inquiry word count (LIWC) with culture and suicide related lexicons. Front. Psych. 14, 1121583 (2023).
LIWC. Linguistic inquiry and word count (liwc). LIWC (2024).
Bojić, L. The patterns of influence: Liwc analysis of leading news portals’ impact and communication accommodation theory on twitter. Issues Ethnol. Anthropol. 18 (2023).
Ali, A.-G., LoveJennifer, S. et al. Large-scale social media analysis reveals emotions associated with nonmedical prescription drug use. Health Data Sci. (2022).
García-Baena, D., García-Cumbreras, M. Á., Jiménez-Zafra, S. M., García-Díaz, J. A. & Valencia-García, R. Hope speech detection in Spanish: The lgbt case. Lang. Resour. Eval. 57, 1487–1514 (2023).
Gowda, A., Balouchzahi, F., Shashirekha, H. & Sidorov, G. Mucic@ lt-edi-acl2022: Hope speech detection using data re-sampling and 1d conv-lstm. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, 161–166 (2022).
Balouchzahi, F., Butt, S., Sidorov, G. & Gelbukh, A. CIC@ LT-EDI-ACL2022: Are transformers the only hope? hope speech detection for spanish and english comments. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, 206–211 (2022).
Surana, H. & Chinagundi, B. ginius@ lt-edi-acl2022: Aasha: transformers based hope-edi. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, 291–295 (2022).
Bharathi, B., Srinivasan, D., Varsha, J., Durairaj, T. et al. Ssncse_nlp@ lt-edi-acl2022: hope speech detection for equality, diversity and inclusion using sentence transformers. In Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion, 218–222 (2022).
Ngo, A. & Tran, H. T. H. Zootopi at hope2023iberlef: Is zero-shot chat-gpt the future of hope speech detection. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2023), co-located with the 39th Conference of the Spanish Society for Natural Language Processing (SEPLN 2023), CEURWS. org (2023).
Ahani, Z., Sidorov, G., Kolesnikova, O. & Gelbukh, A. Zavira at hope2023@ iberlef: Hope speech detection from text using tf-idf features and machine learning algorithms. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2023), co-located with the 39th Conference of the Spanish Society for Natural Language Processing (SEPLN 2023), CEURWS. org (2023).
Shahiki-Tash, M., Armenta-Segura, J., Kolesnikova, O., Sidorov, G. & Gelbukh, A. Lidoma at hope2023iberlef: Hope speech detection using lexical features and convolutional neural networks. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2023), co-located with the 39th Conference of the Spanish Society for Natural Language Processing (SEPLN 2023), CEUR-WS. org (2023).
Pan, R., Alcaraz-Mármol, G. & Garcıa-Sánchez, F. Umuteam at hope2023iberlef: Evaluation of transformer model with data augmentation for multilingual hope speech detection. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2023), co-located with the 39th Conference of the Spanish Society for Natural Language Processing (SEPLN 2023), CEUR-WS. org (2023).
Tausczik, Y. R. & Pennebaker, J. W. The psychological meaning of words: Liwc and computerized text analysis methods. J. Lang. Soc. Psychol. 29, 24–54 (2010).
Butt, S., Sharma, S., Sharma, R., Sidorov, G. & Gelbukh, A. What goes on inside rumour and non-rumour tweets and their reactions: A psycholinguistic analyses. Comput. Hum. Behav. 135, 107345 (2022).
Kochkina, E., Liakata, M. & Zubiaga, A. All-in-one: Multi-task learning for rumour verification. arXiv preprint arXiv:1806.03713 (2018).
Cambria, E., Gelbukh, A., Poria, S. & Kwok, K. Sentic API: A common-sense based API for concept-level sentiment analysis. In CEUR Workshop Proceedings, vol. 1141, 19–24 (CEUR-WS, 2014).
Shahiki Tash, M., Kolesnikova, O., Ahani, Z. & Sidorov, G. Psycholinguistic and emotion analysis of cryptocurrency discourse on x platform. Scientific Reports (2024).
Al-Garadi, M. A. et al. Text classification models for the automatic detection of nonmedical prescription medication use from social media. BMC Med. Inform. Decis. Mak. 21, 1–13 (2021).
Volkova, S., Wilson, T. & Yarowsky, D. Exploring demographic language variations to improve multilingual sentiment analysis in social media. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1815–1827 (2013).
Liu, W. & Ruths, D. Using first names as features for gender inference in twitter. Analyzing Microtext (2013).
Fan, R. et al. The minute-scale dynamics of online emotions reveal the effects of affect labeling. Nat. Hum. Behav. 3, 92–100 (2019).
Lu, X. et al. User perceptions of different electronic cigarette flavors on social media: Observational study. J. Med. Internet Res. 22, e17280 (2020).
Weiner, I.B. & Craighead, W.E. The Corsini Encyclopedia of Psychology, vol. 4 (Wiley, 2010).
Nachar, N. et al. The Mann-Whitney U: A test for assessing whether two independent samples come from the same distribution. Tutor. Quant. Methods Psychol. 4, 13–20 (2008).
Blei, D. M., Ng, A. Y. & Jordan, M. I. Latent dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022 (2003).
Wuraola, I., Dethlefs, N. & Marciniak, D. Linguistic pattern analysis in the climate change-related tweets from UK and Nigeria. In Proceedings of the 2023 CLASP Conference on Learning with Small Data (LSD), 90–97 (2023).
Baddeley, J. L. & Singer, J. A. Telling losses: Personality correlates and functions of bereavement narratives. J. Res. Pers. 42, 421–438 (2008).
Arguello, J. et al. Talk to me: Foundations for successful individual-group interactions in online communities. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 959–968 (2006).
Simmons, R. A., Chambless, D. L. & Gordon, P. C. How do hostile and emotionally overinvolved relatives view relationships?: What relatives’ pronoun use tells us. Fam. Process 47, 405–419 (2008).
Pennebaker, J.W., Francis, M.E. & Booth, R.J. Linguistic inquiry and word count: Liwc 2001. Mahway: Lawrence Erlbaum Associates 71, 2001 (2001).
Batten, S. V., Follette, V. M., Hall, M. L. R. & Palm, K. M. Physical and psychological effects of written disclosure among sexual abuse survivors. Behav. Ther. 33, 107–122 (2002).
Pennebaker, J.W., Boyd, R.L., Jordan, K. & Blackburn, K. The development and psychometric properties of liwc2015 (2015).
Kenrick, D. T., Neuberg, S. L., Griskevicius, V., Becker, D. V. & Schaller, M. Goal-driven cognition and functional behavior: The fundamental-motives framework. Curr. Dir. Psychol. Sci. 19, 63–67 (2010).
Schaller, M., Kenrick, D. T., Neel, R. & Neuberg, S. L. Evolution and human motivation: A fundamental motives framework. Soc. Pers. Psychol. Compass 11, e12319 (2017).
Al Daoud, E. Comparison between XGBoost, LightGBM and CatBoost using a home credit dataset. Int. J. Comput. Inf. Eng. 13, 6–10 (2019).
Bentéjac, C., Csörgő, A. & Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 54, 1937–1967 (2021).
Balouchzahi, F., Sidorov, G. & Shashirekha, H. L. Fake news spreaders profiling using n-grams of various types and shap-based feature selection. J. Intell. Fuzzy Syst. 42, 4437–4448 (2022).
Ming, H. & Heyong, W. Filter feature selection methods for text classification: A review. Multimed. Tools Appl. 83, 2053–2091 (2024).
Elboq, R., Fri, M., Hlyal, M. & Alami, J. E. Modeling lean and six sigma integration using deep learning: Applied to a clothing company. AUTEX Res. J. 23, 1–10. https://doi.org/10.2478/aut-2021-0043 (2023).
Turner, R. et al. Bayesian optimization is superior to random search for machine learning hyperparameter tuning: Analysis of the black-box optimization challenge 2020. In NeurIPS 2020 Competition and Demonstration Track, 3–26 (PMLR, 2021).
Wang, L., Dernoncourt, F. & Bui, T. Bayesian optimization for selecting efficient machine learning models. arXiv:2008.00386 (2020).
Victoria, A. H. & Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 12, 217–223 (2021).
Wu, J. et al. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 17, 26–40 (2019).
Acknowledgements
The work was done with partial support from the Mexican Government through the grant A1-S-47854 of CONACYT, Mexico, grants 20241816, 20241819, and 20240951 of the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional, Mexico. The authors thank the CONACYT for the computing resources brought to them through the Plataforma de Aprendizaje Profundo para Tecnologías del Lenguaje of the Laboratorio de Supercómputo of the INAOE, Mexico and acknowledge the support of Microsoft through the Microsoft Latin America PhD Award.
Author information
Authors and Affiliations
Contributions
M.A.: Conceptualization, Methodology, Visualization; Roles/Writing—original draft; M.S.T.: Formal analysis; Roles/Writing—original draft, and Writing—review & editing; A.J.: Formal analysis; Roles/Writing—original draft, and Writing—review & editing; I.A.: Investigation, and Writing—review & editing; F.U.: Investigation, and Writing—review & editing; J.K.: Supervision, Validation, Writing—review & editing; A.G.: Data curation, Funding acquisition, Supervision; Validation; F.B.: Data curation, Writing—review & editing, Supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Arif, M., Shahiki Tash, M., Jamshidi, A. et al. Analyzing hope speech from psycholinguistic and emotional perspectives. Sci Rep 14, 23548 (2024). https://doi.org/10.1038/s41598-024-74630-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-74630-y
