
Abstract
This study aims to predict IDH wt with TERTp-mut gliomas using multiparametric MRI sequences through a novel fusion model, while matching model classification metrics with patient risk stratification aids in crafting personalized diagnostic and prognosis evaluations.Preoperative T1CE and T2FLAIR sequences from 1185 glioma patients were analyzed. A MultiChannel_2.5D_DL model and a 2D DL model, both based on the cross-scale attention vision transformer (CrossFormer) neural network, along with a Radiomics model, were developed. These were integrated via ensemble learning into a stacking model. The MultiChannel_2.5D_DL model outperformed the 2D_DL and Radiomics models, with AUCs of 0.806-0.870. The stacking model achieved the highest AUC (0.855-0.904) across validation sets. Patients were stratified into high-risk and low-risk groups based on stacking model scores, with significant survival differences observed via Kaplan–Meier analysis and log-rank tests. The stacking model effectively identifies IDH wt TERTp-mutant gliomas and stratifies patient risk, aiding personalized prognosis.
Similar content being viewed by others
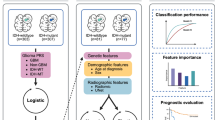


Introduction
Glioma is the most common primary malignant tumor of the central nervous system(CNS), characterized by high heterogeneity1, with a median survival time of less than 21 months2,3. Adult diffuse gliomas are graded as CNS World Health Organization(WHO) grades 2, 3, or 4 according to the degree of malignancy; the higher the grade, the more malignant, and the poorer the prognosis4. The reported median survival of grades 2, 3, and 4 gliomas are ~5–17 years, 2–8 years, and <1 year, respectively2.
In recent decades, research has confirmed that glioma subtypes of the same grade exhibit distinct biological behaviors5,6,7,8. IDH wild-type (IDH wt) gliomas demonstrate stronger proliferation and invasiveness, and patients with IDH wild-type gliomas generally have poorer prognoses than those with IDH-mutant gliomas9,10. TERT promoter mutation (TERTp-mut) is another molecular marker of gliomas, occurring in 70–80% of primary Glioblastomas(GBMs) and ~70% of oligodendrogliomas, but less frequently in grade 2 and 3 astrocytomas11,12. The presence of TERTp-mut has been linked to unfavorable clinical prognosis in GBMs13, however, its specific clinical significance and biological attributes in gliomas of grades 2 and 3 remain unclear14. The 2021 revision of the WHO CNS classification has incorporated molecular markers as crucial biomarkers for grading and enhancing prognosis assessment across diverse tumor types4. This signifies a shift from the sole reliance on histological grading, as previously practiced, to a more comprehensive approach that integrates molecular parameters to refine grade assignments15,16. Contemporary investigations delving into prognostic indicators in IDH wild-type diffuse astrocytomas, spanning CNS WHO grades 2 to 4, have underscored the significance of TERTp mutations as a poor prognostic biomarker. Specifically, in IDH wild-type diffuse astrocytomas of grades 2 and 3, the presence of TERTp mutations has been directly correlated with reduced patient survival, emphasizing its value in augmenting histological evaluations for more accurate prognosis17,18. Gliomas with both IDH wt and TERTp-mut exhibit worse prognoses and stronger invasiveness. The most commonly used methods for detecting IDH and TERT are sequencing based on tumor tissue samples obtained through biopsy or surgical resection19. However, factors such as poor health status preventing invasive procedures, the requirement for specialized technicians, and the cost of specialized equipment and materials often pose obstacles to biopsy and surgical resection20,21,22. Therefore, preoperative non-invasive and precise prediction of IDH wt with TERTp-mut gliomas is of great significance for providing diagnostic and prognostic information prior to surgery.
In the field of predicting the genetic and molecular biology of gliomas, the integration of MRI radiomics and traditional convolutional neural networks (CNNs) deep learning methods has achieved remarkable results in predicting molecular subtypes such as IDH mutation with 1p/19q co-deletion and IDH mutation with CDKN2A/B homozygous deletion20,23,24,25,26. Meanwhile, Yang et al.27 have also attracted widespread attention for their high-risk molecular classification of adult diffuse gliomas by integrating multiple molecular markers using the habitat imaging technology based on diffusion kurtosis imaging (DKI). However, despite the powerful capabilities of Transformer models, which have surpassed CNNs in many non-medical computer vision tasks in recent years, the majority of Transformer-based deep learning models remain underutilized in medical computer vision tasks. This study utilizes multi-dimensional images to construct a Cross-Scale Attention Vision Transformer (CrossFormer)28 deep learning model. To our knowledge, this is the first application of the CrossFormer model in glioma molecular subtyping. Additionally, we have developed a vertical fusion model in conjunction with traditional radiomics methods, linking the classification metrics of the model to patient risk stratification. This is crucial for enhancing the individualized diagnosis and treatment of glioma patients.
Results and discussion
Patient characteristics analysis
Our study included a total of 1185 glioma patients, with 562 cases in the training set, 510 cases in the external validation set 1, and 113 cases in the external validation set 2. Among them, there were 220 (18.6%) patients with IDH wt with TERTp-mut and 965 (81.4%) patients with non-IDH wt with TERTp-mut. In each set, the proportions of IDH wt with TERTp-mut patients in the training set, external validation set 1, and external validation set 2 were 30.2, 6.27, and 15.9%, respectively, with the lowest proportion observed in external validation set 2. Within each set, there were significant differences in baseline WHO grades characteristics between the IDH wt with TERTp-mut group and the non-IDH wt with TERTp-mut group, while no significant differences were observed in sex. For the training set and external validation set 2, there were significant differences in age between the IDH wt with TERTp-mut group and the Non-IDH wt with TERTp-mut group, whereas no significant difference in age was found in external validation set 1(As detailed in Table 1).
Feature extraction and selection
A total of 3122 radiomic features, 512 2.5D deep learning features, and 1024 2D deep learning features were extracted. After performing the LASSO feature selection, we identified 19 2.5D deep learning features, 4 2D deep learning features, and 15 radiomic features, respectively. Among the various types of selected features, 2.5D deep learning features are the most numerous, and each feature has a relatively high weight. This could be attributed to the fact that 2.5D deep learning is able to capture image information more comprehensively compared to 2D deep learning and radiomics, resulting in extracted features that have more significant correlations with the target. Among the selected radiomic features, there are 7 features derived from T1CE and eight features from T2FLAIR, T1CE_intra_square_gldm_DependenceNonUniformity and T2FLAIR_intra_wavelet_HLL_firstorder_Skewness contributing the most significantly. Additionally, the small number of selected 2D deep learning features could be attributed to the fact that the 2D CrossFormer model only utilizes the minimum rectangular ROI containing the largest tumor area as input, failing to capture more information from the image that is relevant to the target. This limitation results in the extracted 2D deep learning features lacking strong correlations with the target variable. See the Fig. 1 for the weight visualization of various features.

a–c Represent the weights visualization for 2.5D deep learning features, 2D deep learning features, and radiomic features, respectively.
Development and performance of models
For the three individual feature sets, seven classifiers were used, and ultimately, GradientBoosting demonstrated the best prediction performance for each. Based on the output scores of these three individual models, AdaBoost showed the best prediction performance. The ROC curves for the seven classifiers in each model can be found in supplementary information (1). The performance metrics of the predictive models across various research sets are summarized in Table 2. Among the three single-modality models, the MultiChannel_2.5D_DL model achieved the highest AUC values across all study sets (training set: 0.870, external validation set 1: 0.840, external validation set 2: 0.806) (Fig. 2). Furthermore, the Radiomics model consistently demonstrated higher AUCs in all study sets (training set: 0.868, external validation set 1: 0.727, external validation set 2: 0.772) compared to the 2D_DL model (training set: 0.800, external validation set 1: 0.720, external validation set 2: 0.760). Notably, the stacking model, which integrates the three individual modalities, achieved the highest AUC in all study sets (training set: 0.904, external validation set 1: 0.855, external validation set 2: 0.859). Significant differences in AUC were observed between the MultiChannel_2.5D_DL model and the 2D_DL model, as well as between the 2D_DL model and the stacking model in external validation set 1. In external validation set 2, there was a significant difference in AUC between the Radiomics model and the stacking model (see Fig. 3). The DCA curves in the study sets indicate that the stacking model offers a greater net benefit. Additionally, the calibration curves of the three single-modality models demonstrate good agreement across a wider range of probabilities compared to the stacking model. The DCA curves and calibration curves for the study sets are provided in Figs. 4, 5.

a–c Represent the ROC curves for the models in the training set, external validation set 1, and external validation set 2, respectively.

a–c Represent the Delong tests between the models in the training set, external validation set 1, and external validation set 2, respectively.

a–c Represent the DCA curves for the models in the training set, external validation set 1, and external validation set 2, respectively. The stacking model exhibits the best net benefit in the study set.

a–c Represent the calibration curves for the models in the training set, external validation set 1, and external validation set 2, respectively. The black diagonal line represents the ideal standard, with closer proximity indicating better evaluation performance.
Prognostic risk stratification assessment based on stacking classification model
Based on the output scores of the stacking model trained on the training set, we uniformly divided the study set into high-risk and low-risk groups (Fig. 6). The Log-rank test indicated that in both the training set and the external validation set 2, the overall survival (OS) could be significantly stratified according to the output scores of the stacking model. The Cox regression analysis results revealed the P value was 0.04, with a hazard ratio of 4.92, and a 95% confidence interval ranging from 1.106 to 21.87, suggesting that the score is indeed an independent prognostic factor for stratifying patients into different risk groups. In this study, density plots(supplementary information (2)) were used to visualize the score distributions of the IDH wt TERTp-mut group and the non-IDH wt TERTp-mut group. In both the training set and external validation set 2, the boundary between the dominant regions of the two groups was near the median score of the training set (0.462). This indicates that this value is highly sensitive in distinguishing between the two groups and provides a reasonable and sufficient explanation for its effectiveness in risk stratification. It also demonstrates the significant prognostic incremental value of the stacking classification model.

Results show that the p values for both the training set (a) and the validation set (b) are <0.05, indicating statistically significant differences.
Discussion
In this study, we developed MultiChannel_2.5D_DL, 2D_DL and Radiomics models based on the MRI images of primary tumor, for the prediction of IDH wt with TERTp-mut gliomas. The results show that MultiChannel_2.5D_DL can extract better spatial features from big data and exhibit better predictive performance compared to 2D_DL and Radiomics models. In addition, we have also constructed a multi-___domain fusion model using an ensemble learning strategy, namely the stacking model, which exhibits the best performance among all models (training set: 0.904, external validation set 1: 0.855, external validation set 2: 0.859). To our knowledge, the CrossFormer deep learning model has not been applied to the study of glioma molecular classification currently. This study on glioma patients using multi-dimensional CrossFormer deep learning marks the first large-scale multi-center study to show that CrossFormer deep learning has significant value in the molecular typing of gliomas.
Previous studies have demonstrated the feasibility of using artificial intelligence methods to predict IDH and TERT status in gliomas based on preoperative MRI, achieving encouraging results. On the one hand, progress has been made in predicting the status of IDH or TERT individually. Kim M et al.29 extracted radiomic features based on DWI, PWI, and conventional MRI, and employed logistic regression to predict the IDH status of LGGs, achieving an AUC of 0.795 in the validation set. Choi YS et al.24 proposed a structure combining radiomics and CNN image features to predict IDH mutation status in diffuse gliomas, achieving AUCs of 0.96, 0.94, and 0.86 in internal and external test sets, respectively. Buz-Yalug B et al.30 leveraged deep learning based on rCBV images to predict IDH mutations, TERTp mutations, and the TERTp-only subgroup in gliomas. The best-performing CNN model achieved prediction accuracies of 88, 70, and 84% for the IDH mutation subgroup, TERTp mutation subgroup, and TERTp-only subgroup, respectively. On the other hand, some studies have combined IDH and TERT status for prediction. Arita H et al.31 established a LASSO regression model based on conventional MRI radiomics to predict IDH and TERTp-mutant gliomas, achieving an overall diagnostic accuracy of 0.56 in the validation set. Wang et al.32 developed a radiomics prediction model for IDH-mutant and TERTp-mutant gliomas based on multimodal MRI, achieving AUCs of 0.971 and 0.952 in the test set and independent validation set, respectively. However, there are still some limitations: Among IDH wild-type gliomas, particularly the TERTp-only subgroup, it is a marker of poor prognosis, associated with worse outcomes and increased aggressiveness. Yet, current research has not integrated low-grade and high-grade gliomas to accurately predict the IDH wt TERTp-mut subgroup. Additionally, the relatively small number of patients in previous studies may raise concerns about the validity of the models, despite their high performance in some cases. In contrast, our study utilized a multi-center dataset of 1185 patients, including both low-grade and high-grade gliomas, with 623 cases allocated to the validation set, making our models for predicting IDH and TERT status more robust and convincing than those established in previous studies.
Transformer models have risen as competitors to CNNs in non-medical computer vision tasks, demonstrating superior performance. However, to our knowledge, they have yet to be broadly adopted for medical image classification despite their potential. Jiang et al.33 employed ViT-B/16 and traditional CNNs as the backbone networks to predict the prognosis of rectal cancer patients, and the results showed that Vision Transformers achieved better performance than traditional CNNs (OS C-index, 0.82 vs 0.67 [ResNet]; P = 0.02). Wagner SJ et al.34 developed a novel transformer-based pipeline for biomarker prediction from routine pathology slides of colorectal cancer (CRC). This pipeline combines a pre-trained transformer encoder with a transformer network for patch aggregation, enabling end-to-end biomarker prediction from pathology slides. In predicting microsatellite instability (MSI) in surgical resection specimens, it achieved a sensitivity of 0.99 and a negative predictive value exceeding 0.99. However, traditional vision transformers lack the ability to establish interactions between features at different scales, which is perceptually important for visual inputs. There are two main reasons for this: (1) The input embeddings at each layer are of equal scale, making it impossible to extract cross-scale features; (2) In order to decrease computational expenses, certain Vision Transformers integrate neighboring embeddings within the self-attention module, which unfortunately leads to the loss of small-scale (detailed) embedding features and makes cross-scale interactions ineffective. To address this, Wang et al.28 proposed the cross-scale embedding layer (CEL) and long-short distance attention (LSDA). Based on the cross-scale attention module, they constructed CrossFormer, which can accommodate inputs of different sizes. Numerous experiments have demonstrated that CrossFormer surpasses other vision transformers in various tasks, including image classification, object detection, instance segmentation, and semantic segmentation. This study places a significant emphasis on referencing their network model architecture. When 2D or 2.5D data inputs are fed into CrossFormer, extracting deep learning features and subsequently using them for machine learning modeling has achieved excellent results.
Given that 3D Transformers need substantial datasets to learn intricate spatial characteristics effectively, a lack of sufficient data can result in suboptimal performance or the occurrence of overfitting. On the other hand, relying solely on 2D data for training deep learning models tends to overfit due to the inability to capture the full spectrum of information within images. In this study, the 2D_DL model exhibited the lowest performance among all models. Furthermore, after LASSO screening, only four key features remained out of the 1024 2D deep learning features. This may be attributed to the high degree of redundancy among the 2D deep learning features. The feature screening results indicated that after conducting a Spearman correlation analysis (where only one feature is retained if the correlation coefficient between features is greater than 0.9), only 218 2D deep learning features were retained, with the vast majority of features being eliminated due to excessive internal correlations. These findings all suggest that 2D deep learning has certain limitations. As a result, the acquisition of 2.5D data has garnered significant interest among researchers. Kim H et al.35 have constructed a 2.5D DenseNet model by analyzing axial, coronal, and sagittal slices of lung CT scans, which outperformed 3D DenseNet models in predicting lung cancer. Similarly, Kim Y et al.36 generated 2.5D data by converting 3D hip CT scans into 2D digital X-ray reconstruction images (DRRs) in frontal, lateral, and axial views, and their 2.5D DenseNet model demonstrated a higher C-index (0.73) for predicting subsequent fractures compared to other image-based models. Li et al.37 created a 2.5D DCNN model using the largest ROI mask along with adjacent slices from multi-sequence MRI as 2.5D data, achieving accuracies ranging from 0.74 to 0.83 in independent validation sets, surpassing radiomics models across all tasks. This integrates 2.5D data from T1CE and T2FLAIR into a 6-channel image input for the deep learning model37,38,39. This study aligns with previous research findings. MultiChannel_2.5D_DL adopts a novel approach for acquiring 2.5D data and leverages the unique cross-scale attention mechanism of CrossFormer, which can more comprehensively reflect the dynamic changes of tumors and better capture their complex spatial characteristics in a more holistic manner, significantly enhancing the model’s predictive performance. The activation maps of features recognized and focused by the MultiChannel_2.5D_DL model for IDH wt with TERTp-mut and Non-IDH wt with TERTp-mut gliomas were shown in Fig. 7. The results indicate that compared to patients with Non-IDH wt with TERTp-mut gliomas, the model exhibits stronger attention distribution towards the heterogeneity and marginal areas of gliomas in patients with IDH wt with TERTp-mut gliomas. Additionally, the tumor areas demonstrate a broader range of activation regions. This enhances the biological interpretability of deep learning. Additionally, In 2.5D models, Grad-CAM activation points appear as corners or squares, emphasizing high activations at image edges. This suggests the model captures specific features in these regions. Tumor edge areas, containing crucial morphological information and high contrast, may be more easily detected by the model due to their strong gradient responses. Furthermore, 2.5D models process 3D data through multichannel inputs, extracting information from adjacent slices. This leads the model to focus more on edge areas when integrating slice information, explaining Grad-CAM activations there. Additionally, corners or edges may show strong spatial consistency across slices, making them significant features for the model.

a, b denote the activation maps produced by the MultiChannel_2.5D_DL model, specifically for gliomas characterized as Non-IDH wild-type with TERTp-mut. Conversely, c, d represent the activation maps of features identified and emphasized by the same MultiChannel_2.5D_DL model, but this time for gliomas exhibiting IDH wild-type (wt) with TERT promoter mutation (TERTp-mut).
Data fusion is the process of combining multiple data modalities, each of which provides a different perspective on common phenomena to solve reasoning problems. The purpose of fusion technology is to effectively utilize the collaboration and complementary features of different modes. While most biomedical research adopts an early fusion strategy, it is not necessarily the optimal practice40. Wang et al.41 in their study on predicting occult lymph node metastasis in laryngeal squamous cell carcinoma using CT-based ResNet and clinical data, discovered that a late fusion strategy produced optimal performance. Similarly, Huang et al.42 in their research on predicting pathological complete response to neoadjuvant chemotherapy in breast cancer based on MRI, discovered that combining multiple feature sets through ensemble learning yielded the optimal diagnostic performance (with average AUCs of 0.895, 0.918, and 0.891), echoing our findings. In this study, the performance of the stacking model was significantly higher than that of the three single-modality models. This phenomenon suggests that the stacking model more comprehensively integrates the image information relevant to the target variable extracted by the three individual modality models, enabling the machine learning model to predict IDH wt TERTp-mut gliomas with greater accuracy.
This study contributes to the clinical application by facilitating precise preoperative diagnosis and informed treatment decision-making for gliomas. In a clinical setting, the model will be integrated into the hospital’s diagnostic workflow. Preprocessed images will be input into the model, and based on the model’s output, patients with potentially high-risk conditions will be identified. In the clinical deployment scenario, the DCA will help determine the optimal risk threshold for identifying high-risk patients. Additionally, sensitivity is crucial for ensuring that the model correctly identifies as many high-risk patients as possible, while specificity will ensure that the model does not overclassify patients as high-risk, thereby avoiding unnecessary treatments and reducing the burden on healthcare resources. In summary, by integrating the model into the clinical workflow and linking its predictions to DCA, sensitivity, and specificity, it can effectively support clinical decision-making and improve patient survival outcomes.
Our study has several limitations. Firstly, it is a retrospective analysis, and prospective multi-center cases are needed to validate our findings. Secondly, the prognostic information of patients is incomplete, limiting our ability to conduct a quantitative assessment of the prognostic value of the classification model’s output scores for all patients. Thirdly, in this study, the IDH wt TERTp-mut gliomas is the primary focus, while all other combinations are labeled as Non-IDH wt TERTp-mut gliomas. Different genetic alteration combinations are more prevalent in various types of gliomas and are associated with distinct prognoses. Due to the limited volume of training data in this study, the proportion of cases with different genetic combinations is relatively small. Training a deep learning model with such a limited number of cases may raise concerns about overfitting or poor generalization. This study plans to continue collecting multi-center data in subsequent research. Once a sufficient volume of data is achieved, the model will be trained on glioma cases with different genetic combinations. This approach holds significant promise for further enhancing the development of personalized treatment plans and improving patient prognosis assessment. Furthermore, 2D deep learning models have a limited ability to capture global information from images, which makes it challenging to extract features significantly correlated with the target variables. This could be one of the reasons for the relatively modest performance of the 2D deep learning model in this study. On the other hand, 3D deep learning, due to its more complex model architecture, demands higher requirements for both data volume and data quality. It can only fully leverage its unique advantages when trained on a larger and more comprehensive dataset. In subsequent research, we plan to continue collecting multi-center data and standardize it to obtain a high-quality multi-center dataset. We will also employ state-of-the-art foundational models for training, aiming to enhance the robustness and generalization capabilities of the model. Lastly, we only used conventional MRI sequences to build our model. In the future, we plan to incorporate additional modalities of medical images, including functional MRI and whole slide images from pathology, to improve our model.
In conclusion, The stacking fusion model based on ensemble learning strategy, which integrates Multichannel_2.5D_DL, 2D_DL and Radiomics data, can be adopted to predict gliomas with IDH wild-type TERT promoter mutations, and has a significant effect on risk stratification of patients. This could potentially provide clinicians and patients with more precise technical support for treatment decision-making and prognostic evaluation.
Methods
Patient population
The research flowchart is illustrated in Fig. 8. We retrospectively collected preoperative MRI images of post-contrast enhanced T1-weighted(T1CE) and T2-weighted fluid attenuation inversion recovery(T2FLAIR) sequences from a total of 1185 patients with gliomas. From January 2011 to September 2023, the training set (n = 562) was collected from three affiliated hospitals of Shanxi Medical University: First Hospital of Shanxi Medical University, Shanxi Provincial People’s Hospital, and Shanxi Bethune Hospital. The inclusion criteria were as follows: (1) histopathologically defined adult-type diffuse gliomas according to WHO CNS tumor classification 2021; (2) available preoperative MRI T1CE and T2FLAIR images; (3) molecularly confirmed IDH and TERTp status. The exclusion criteria were as follows: (1) history of biopsy or surgery for a brain tumor; (2) the absence of T1CE or T2FLAIR images; (3) complications caused by other central nervous system diseases, such as cerebral hemorrhage, cerebral infarction, Alzheimer’s disease, and similar conditions; (4) unknown IDH or TERTp status. According to the same inclusion and exclusion criteria, a total of 510 consecutive patients from October 2018 to December 2021 were from Beijing Tiantan Hospital (external validation set 1) and 113 patients from The TCGA dataset (external validation set 2). The patient enrollment process is shown in supplementary information (3). In the training set, 311 patients were identified with complete and matched prognosis information, while in the external validation set 2, this number was 109 patients. Overall survival(OS) is defined as the time from surgical pathology confirmation to patient death or the last follow-up. The list of patients included from TCGA is detailed in the supplementary information (4).

Step1-Step6 sequentially integrate image pre-processing, tumor segmentation, model development and evaluation for 2D_DL, Radiomics, MultiChannel_2.5D_DL, and stacking model, as well as for prognostic value assessment.
Ethics statement
The study was conducted in accordance with the Declaration of Helsinki. It involved the First Hospital of Shanxi Medical University, Shanxi Provincial People’s Hospital, and Shanxi Bethune Hospital, all affiliated with Shanxi Medical University, with approval number 2021-K-K073. Beijing Tiantan Hospital provided approval with the number KYSQ 2021-202-01. This study received approval from the Institutional Ethics Review Board of all participating institutions. The requirement for informed consent was waived by the institutional review boards.
Detection of IDH and TERTp mutation status
We used Sanger sequencing to detect the mutation status of IDH and TERTp. Detailed detection methods and the kits used are shown in the supplementary information (5).
MRI image processing and segmentation
All preoperative MRI images were acquired from 1.5-T or 3.0-T scanners. The detailed scanning agreement is shown in the supplementary information (6).
Rigid registration of T2FLAIR images was accomplished using T1CE as a reference template. Considering the differences in image resolution arising from different scanner models and scanning protocols, the MRI images were resampled to achieve a voxel size of 1 × 1 × 1 mm³. The ITK software (version 3.6.0) was utilized to manually delineate the regions of interest (ROIs) on the MRI images. Specifically, the tumor area was selected as the ROI on the T1CE image, with careful exclusion of the surrounding edema region. The ROI delineation was performed by a neuroradiologist with over a decade of experience. To ensure accuracy and consistency, a second neuroradiologist with over 15 years of experience reviewed the delineated ROIs, cross-checked the results, and provided additional insights when necessary. Both radiologists delineated and inspected the ROIs on the MRI images without access to the patients’ clinical, pathological, or molecular information.
Radiomics analysis
We employed the Pyradiomics module (http://pyradiomics.readthedocs) for feature extraction, utilizing eight different filters, specifically LoG (Laplacian of Gaussian), wavelet, LBP3D (local binary patterns in 3D), exponential, square, square root, logarithm, and gradient. These filters were used to facilitate the extraction of additional information from MRI images. Radiomic features can be divided into seven types: (i) 14 shape-based features; (ii) 306 first-order features; (iii) 238 gray-level dependence matrix (GLDM) features; (iv) 272 gray-level size zone matrix (GLSZM) features; (v) 85 neighboring gray-tone difference matrix (NGTDM) features; (vi) 272 gray-level run-length matrix (GLRLM) features; (vii) 374 gray-level co-occurrence matrix (GLCM) features. A total of 1561 radiomic features were extracted from each ROI and its corresponding sequence. A total of 3122 radiomic features were obtained for each patient.
2D DL model development and feature extraction
The deep learning model was trained using the CrossFormer framework. In 2D deep learning, a bounding box represented the rectangular area outlining the largest tumor cross-section, which was used for isolating the largest tumor ROI. The deep learning model processed various inputs, including T1CE and T2FLAIR MRI images. Data enhancement strategies, including random horizontal and vertical flipping and cropping to a size of 256 × 256 pixels, were applied. The input image dimension was fixed at 256 × 256 pixels, with multiple patches from the same patient sharing identical labels. These labeled images of primary tumors were fed into the 2D CrossFormer as input. To update the parameters of the 2D CrossFormer using the Adam optimizer, we employed a batch size of 64 and incorporated Dropout regularization to prevent overfitting. Additionally, we leveraged CrossFormer to extract 512 deep-learning features for each patch from the penultimate average pooling layer of CrossFormer, resulting in a total of 1024 features acquired for each patient.
MultiChannel 2.5D DL model development and feature extraction
Recognizing the limitations of 2D CrossFormer in capturing the full extent of 3D structures, we developed a MultiChannel 2.5D DL model, specifically tailored for the discrimination of IDH wt with TERTp-mut gliomas. Specifically, the slice with the largest tumor area was first identified, which was assumed to be the nth slice of the input volume. Then, the (n-2)th and (n + 2)th slices were extracted. .The six slices obtained from the T1CE and T2FLAIR sequences were regarded as six channels. A minimal rectangle that could cover the tumor area in all six slices was defined as the ROI for the MultiChannel 2.5D input. Subsequently, the ROI was cropped out from these slices and resized to 256 × 256 pixels. We adopted the same data enhancement strategy as was used for the training of 2D deep learning models. When optimizing the CrossFormer model, we employed the Adam optimizer with a batch size of 64. To prevent overfitting, we implemented Dropout regularization. The learning rate is set to 0.001. To obtain the MultiChannel 2.5D deep learning features for a single patient, we extracted a total of 512 features from the average pooling layer, which is the penultimate layer of the 2.5D CrossFormer model, for the tumor images. The model structure is shown in Fig. 9 and a detailed description of the model is provided in supplementary information (7).

The red rectangle and the blue rectangle represent the slices obtained from the T1CE and T2FLAIR sequences, respectively, while the purple rectangle indicates the smallest rectangle that covers the tumor area in all six slices (i.e., the defined ROI as a 2.5D input). The input size is H0 × W0. The size of the feature maps at each stage is indicated at the top, and Stage-i specifically comprises a CEL (convolutional embedding layer) and ni CrossFormer blocks. The number within the CEL denotes the kernel size utilized for patch sampling.
Features selection and single-modality model construction
Since radiomic and deep learning features carry different levels of importance in distinguishing IDH wt from TERTp-mut gliomas, we conducted feature selection separately for the radiomic, 2D DL, and MultiChannel 2.5D DL features. Initially, We calculated the Intraclass Correlation Coefficient (ICC) to evaluate the reproducibility of the features and ultimately retained those with an ICC greater than 0.80. Mann–Whitney U-tests were conducted independently for each of the three feature categories, retaining solely those features exhibiting a p value below 0.05. Subsequently, Spearman’s rank correlation coefficients were computed among the highly reproducible features to evaluate their interdependencies. In cases where the correlation coefficient between any two features exceeded 0.9, only one of them was retained. To enhance the descriptive capability of the features, a greedy recursive elimination approach was adopted for feature refinement, involving iterative removal of the most redundant feature. Ultimately, the least absolute shrinkage and selection operator (LASSO) regression method was applied to pinpoint the optimal feature subset. This subset comprised key features with nonzero coefficients, corresponding to the optimal tuning parameter k, determined through a tenfold cross-validation process. After LASSO feature selection, the final selected subsets of the three types of features were input into seven classifiers: Logistic regression (LR), support vector machine (SVM), RandomForest, ExtraTrees, AdaBoost, LightGBM, and GradientBoosting. The classifier that exhibited the best performance for each feature set was then chosen to construct the Radiomics, MultiChannel_2.5D_DL, and 2D_DL models, respectively.
Stacking model construction and assessment of models
Using the selected radiomic and deep learning features, we constructed three single-modality models. The model construction was based on the supervised task of identifying IDH wt with TERTp-mut labels. Furthermore, we incorporated an ensemble learning strategy to more accurately predict IDH wt with TERTp-mut gliomas. The output scores of the single-modality models were acquired, and the same seven classifiers mentioned earlier were used. The classifier with the best performance was then selected to construct the stacking model. To ensure the robustness of the models, we repeated the entire construction process 1000 times using bootstrapping. The model that performed best in the training set was then utilized to test the external validation sets. Receiver operating characteristic (ROC) curves, calibration curves, and decision curves analysis (DCA) were utilized to visually validate the predictive abilities of the models. Diagnostic metrics for the three single-modality models and the stacking model were calculated, including the area under the curve (AUC), 95% CI, specificity, sensitivity, accuracy, positive predictive value (PPV), and negative predictive value (NPV). Detailed information on the machine learning process can be found in the supplementary information (8).
Assessment of the incremental prognostic value of the stacking model
Based on the median output scores (0.462) of the stacking model from the training set, we uniformly divided patients with complete follow-up data in both the training set and external validation set 2 into high-risk and low-risk groups. To evaluate the validity of the output scores of the stacking classification model as a prognosis-related label, we compared the survival differences between the high-risk and low-risk groups using Kaplan–Meier (K–M) survival analysis and the log-rank test. Then we conducted a Cox regression analysis focusing on the score to observe whether it serves as an independent prognostic factor influencing patient risk stratification.
Statistical analysis
Chi-square test or Fischer test was used to compare between categorical variables, Mann–Whitney U- test or independent T-test was used for continuous variables. The AUC, accuracy, sensitivity, specificity, PPV, and NPV were used to assess the performance of the predictive model. The Delong test was used to compare AUCs. In R language, the “Survival” package is used to perform Kaplan–Meier (K–M) survival analysis. All statistical tests were two-sided, with P < 0.05 considered statistically significant. All statistical analyses were performed using the R language (version 4.2.2) and the scikit-learn package (version:0.18) in Python 3.70.
Data availability
The image data from the TCGA public database, as an external validation set 2, can be obtained at https://www.cancerimagingarchive.net/. Clinical information of patients can be accessed at https://www.cancer.gov/ccg/research/genome-sequencing/tcga. The specific patient IDs included in this study are detailed in the supplementary information(4). The data from the training set and external validation set 1 cannot be publicly released due to patient privacy concerns but can be obtained from the corresponding author on reasonable request approved by the institutional review board of all enrolled centers. The training code for the CrossFormer deep learning model used in this study is publicly available at https://github.com/radiology111/Glioma_CrossFormer.git. The code for feature selection and machine learning modeling can be accessed on the Onekey AI platform (https://github.com/OnekeyAI-Platform).
Code availability
The training code for the CrossFormer deep learning model used in this study is publicly available at https://github.com/radiology111/Glioma_CrossFormer.git. The code for feature selection and machine learning modeling can be accessed on the Onekey AI platform (https://github.com/OnekeyAI-Platform).
References
Nicholson, J. G. & Fine, H. A. Diffuse glioma heterogeneity and its therapeutic implications. Cancer Discov. 11, 575–590 (2021).
Ostrom, Q. T., Cioffi, G., Waite, K., Kruchko, C. & Barnholtz-Sloan, J. S. CBTRUS statistical report: primary brain and other central nervous system tumors diagnosed in the United States in 2014-2018. Neuro Oncol. 23, iii1–iii105 (2021).
Śledzińska, P., Bebyn, M. G., Furtak, J., Kowalewski, J. & Lewandowska, M. A. Prognostic and predictive biomarkers in gliomas. Int. J. Mol. Sci. 22, 10373 (2021).
Louis, D. N. et al. The 2021 WHO classification of tumors of the central nervous system: a summary. Neuro Oncol. 23, 1231–1251 (2021).
Aoki, K. et al. Prognostic relevance of genetic alterations in diffuse lower-grade gliomas. Neuro Oncol. 20, 66–77 (2018).
Komori, T. Grading of adult diffuse gliomas according to the 2021 WHO classification of tumors of the central nervous system. Lab Invest. 102, 126–133 (2022).
Gore, S., Chougule, T., Jagtap, J., Saini, J. & Ingalhalikar, M. A review of radiomics and deep predictive modeling in glioma characterization. Acad. Radiol. 28, 1599–1621 (2021).
Weller, M. et al. EANO guidelines on the diagnosis and treatment of diffuse gliomas of adulthood. Nat. Rev. Clin. Oncol. 18, 170–186 (2021).
Corrigendum to: IDH-wildtype lower-grade diffuse gliomas: the importance of histological grade and molecular assessment for prognostic stratification. Neuro Oncol. 25, 1011–1012 (2023).
Yan, H. et al. IDH1 and IDH2 mutations in gliomas. N. Engl. J. Med. 360, 765–773 (2009).
Labussière, M. et al. TERT promoter mutations in gliomas, genetic associations and clinico-pathological correlations. Br. J. Cancer 111, 2024–2032 (2014).
Yang, P. et al. Classification based on mutations of TERT promoter and IDH characterizes subtypes in grade II/III gliomas. Neuro Oncol. 18, 1099–1108 (2016).
Tang, F. et al. TERT mutations-associated alterations in clinical characteristics, immune environment and therapy response in glioblastomas. Discov. Oncol. 14, 148 (2023).
Xue, B. et al. Survival outcome and predictors of WHO grade 2 and 3 insular gliomas: a classification based on the tumor spread. Cancer Med. 13, e7377 (2024).
Agarwal, A. et al. Molecular GBM versus histopathological GBM: radiology-pathology-genetic correlation and the new WHO 2021 definition of glioblastoma. AJNR Am. J. Neuroradiol. 45, 1006–1012 (2024).
Wang, W. et al. Neuropathologist-level integrated classification of adult-type diffuse gliomas using deep learning from whole-slide pathological images. Nat. Commun. 14, 6359 (2023).
Cimino, P. J. & Holland, E. C. Targeted copy number analysis outperforms histologic grading in predicting patient survival for WHO grades II/III IDH-mutant astrocytomas. Neuro Oncol. 21, 819–821 (2019).
Ceccarelli, M. et al. Molecular profiling reveals biologically discrete subsets and pathways of progression in diffuse glioma. Cell 164, 550–563 (2016).
Lu, V. M. et al. The prognostic significance of CDKN2A homozygous deletion in IDH-mutant lower-grade glioma and glioblastoma: a systematic review of the contemporary literature. J. Neurooncol. 148, 221–229 (2020).
Zhang, L. et al. A novel MRI-based deep learning networks combined with attention mechanism for predicting CDKN2A/B homozygous deletion status in IDH-mutant astrocytoma. Eur. Radiol. 34, 391–399 (2024).
Hass, R., von der Ohe, J. & Ungefroren, H. Impact of the tumor microenvironment on tumor heterogeneity and consequences for cancer cell plasticity and stemness. Cancers 12, 3716 (2020).
Zeng, C. et al. Dissection of transcriptomic and epigenetic heterogeneity of grade 4 gliomas: implications for prognosis. Acta Neuropathol. Commun. 11, 133 (2023).
Cheng, J., Liu, J., Kuang, H. & Wang, J. A fully automated multimodal MRI-based multi-task learning for glioma segmentation and IDH genotyping. IEEE Trans. Med. Imaging 41, 1520–1532 (2022).
Choi, Y. S. et al. Fully automated hybrid approach to predict the IDH mutation status of gliomas via deep learning and radiomics. Neuro Oncol. 23, 304–313 (2021).
Decuyper, M., Bonte, S., Deblaere, K. & Van Holen, R. Automated MRI based pipeline for segmentation and prediction of grade, IDH mutation and 1p19q co-deletion in glioma. Comput. Med. Imaging Graph. 88, 101831 (2021).
van der Voort, S. R. et al. Combined molecular subtyping, grading, and segmentation of glioma using multi-task deep learning. Neuro Oncol. 25, 279–289 (2023).
Yang, X. et al. Diffusion kurtosis imaging-based habitat analysis identifies high-risk molecular subtypes and heterogeneity matching in diffuse gliomas. Ann. Clin. Transl. Neurol. 11, 2073–2087 (2024).
Wang, W. et al. CrossFormer++: a versatile vision transformer hinging on cross-scale attention. IEEE Trans. Pattern Anal. Mach. Intell. 46, 3123–3136 (2024).
Kim, M. et al. Diffusion- and perfusion-weighted MRI radiomics model may predict isocitrate dehydrogenase (IDH) mutation and tumor aggressiveness in diffuse lower grade glioma. Eur. Radiol. 30, 2142–2151 (2020).
Buz-Yalug, B. et al. Identification of IDH and TERTp mutations using dynamic susceptibility contrast MRI with deep learning in 162 gliomas. Eur. J. Radiol. 170, 111257 (2024).
Arita, H. et al. Lesion ___location implemented magnetic resonance imaging radiomics for predicting IDH and TERT promoter mutations in grade II/III gliomas. Sci. Rep. 8, 11773 (2018).
Wang, H. et al. Radiomic study on preoperative multi-modal magnetic resonance images identifies IDH-mutant TERT promoter-mutant gliomas. Cancer Med. 12, 2524–2537 (2023).
Jiang, X. et al. An MRI deep learning model predicts outcome in rectal cancer. Radiology 307, e222223 (2023).
Wagner, S. J. et al. Transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study. Cancer Cell. 41, 1650–1661.e4 (2023).
Kim, H. et al. CT-based deep learning model to differentiate invasive pulmonary adenocarcinomas appearing as subsolid nodules among surgical candidates: comparison of the diagnostic performance with a size-based logistic model and radiologists. Eur. Radiol. 30, 3295–3305 (2020).
Kim, Y. et al. A CT-based deep learning model for predicting subsequent fracture risk in patients with hip fracture. Radiology 310, e230614 (2024).
Li, Y. et al. Molecular subtyping of diffuse gliomas using magnetic resonance imaging: comparison and correlation between radiomics and deep learning. Eur. Radiol. 32, 747–758 (2022).
Lan, T. et al. MRI-based deep learning and radiomics for prediction of occult cervical lymph node metastasis and prognosis in early-stage oral and oropharyngeal squamous cell carcinoma: a diagnostic study. Int. J. Surg. 110, 4648–4659 (2024).
Liu, B. et al. IVIM using convolutional neural networks predicts microvascular invasion in HCC. Eur. Radiol. 32, 7185–7195 (2022).
Mohsen, F., Ali, H., El Hajj, N. & Shah, Z. Artificial intelligence-based methods for fusion of electronic health records and imaging data. Sci. Rep. 12, 17981 (2022).
Wang, W. et al. Comparing three-dimensional and two-dimensional deep-learning, radiomics, and fusion models for predicting occult lymph node metastasis in laryngeal squamous cell carcinoma based on CT imaging: a multicentre, retrospective, diagnostic study. EClinicalMedicine 67, 102385 (2024).
Huang, Y. et al. Longitudinal MRI-based fusion novel model predicts pathological complete response in breast cancer treated with neoadjuvant chemotherapy: a multicenter, retrospective study. EClinicalMedicine 58, 101899 (2023).
Acknowledgements
This work was supported by the Basic Research Project of Shanxi Province (202303021211204) and the National Natural Science Foundation of China (U21A20386 and 82371941).
Author information
Authors and Affiliations
Contributions
W.N. and G.Y. conceived and designed the study. J.Y., M.H., T.L., C.L., Q.L., Z.L., Y.S., and B.P. collected the data. W.N. and Y.Z. developed and validated the deep learning networks. W.N., Y.Z., and G.Y. accessed and verified the underlying data. W.N. wrote the original manuscript. Y.T., X.W., L.W., H.Z., and G.Y. reviewed and edited the manuscript. All authors read and approved the final manuscript. All authors had full access to the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis as well as the decision to submit for publication.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Niu, W., Yan, J., Hao, M. et al. MRI transformer deep learning and radiomics for predicting IDH wild type TERT promoter mutant gliomas. npj Precis. Onc. 9, 89 (2025). https://doi.org/10.1038/s41698-025-00884-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41698-025-00884-y
